

BladeLLM是阿里云PAI平台提供的大模型推理引擎,致力于让用户轻松部署高性能、低成本的大语言模型服务。BladeLLM对LLM推理和服务的全链路进行了深度的性能优化和工程优化,确保不同模型在不同设备上都达到最优性价比。
除了在常规上下文长度下的极致性能优化之外,BladeLLM还突破了现有LLM推理系统上下文长度的极限,能够支持更长的输入长度以及文本生成长度等,使得LLM能够解锁更多的应用场景,并且BladeLLM在超长上下文下依然保持极致的性能,相比于其他LLM推理服务系统有显著的性能优势。
本文主要介绍BladeLLM在超长上下文方面具有的优势,包括支持的最大上下文长度以及超长上下文的推理性能。
背景
超长上下文是LLM发展的必然趋势
超长上下文推理能力是LLM涌现的重要能力之一,该能力促生了一系列具有巨大潜在价值的应用场景,包括个性化的聊天机器人(Character.AI)、文学创作工具(Jasper)、文章摘要工具(ChatPaper)等。个性化的聊天机器人会和用户进行持续性的交互,给予用户工作、情感、学习等多方面的帮助。LLM会在交流过程中记忆完整的聊天内容,模型输入长度逐次递增,在多次交互后形成超长输入文本序列;文学创作工具借助LLM的能力批量生成长篇文本,如小说、故事和剧本等。相比传统的手工创作过程,LLM文学创作工具可以在短时间内生成大量的背景、情节和对话,在大幅度提升作家和编剧的创作效率的同时为读者提供更加丰富且多样的阅读材料。LLM涌现的超长上下文推理能力被认为是通往AGI的必经之路,该能力的意义主要体现在以下几个方面:
- 探索更多应用场景:超长文本生成的支持使得LLM可以应用于更多的应用场景,如个性化聊天机器人、生成长篇小说、技术文档、学术论文等。这些应用场景通常需要生成较长的文本内容。
- 生成更具上下文连贯性的文本:LLM的目标是生成与给定上下文相关的自然语言文本。当生成序列限制较短时,可能会导致生成的文本与上下文的连贯性不足,影响生成文本的质量。而LLM支持超长文本生成,可以更好地保持上下文的完整性,生成的文本更加连贯,从而提升生成文本的质量。
- 提升生成多样性:较长的生成序列能提供更多的空间来探索不同的文本可能性,从而提高生成文本的多样性。LLM支持超长文本生成,可以更好地捕捉上下文的细微变化,生成更多样化、丰富的文本内容。
随着相关应用场景的铺开,支持超长上下文的模型层出不穷,其中包括支持84K上下文的MPT StoryWriter、200K上下文的Claude 2以及256K上下文的LongLLaMA等等(见下图)。系统层面虽然已经有部分框架(如DeepSpeed)针对超长上下文进行支持和优化,但是依然集中于训练阶段。而在推理阶段,流行的框架无不面临超长输入输出无法运行或运行效率低下的问题,可以说超长文本的输入和输出对大模型推理引擎带来新的挑战。 
超长上下文的挑战
首先,现有的LLM推理引擎难以满足大模型处理超长上下文信息的需求,这些系统对于存储资源的配置方案以及计算算子的设计会极大地限制模型的最大输入输出长度。因此,大规模的上下文支持需要更高效的存储和计算策略;此外,更长的上下文信息使得推理时间急剧增长,引起成本上升和用户体验的下降,这个问题在现有的LLM推理引擎中尤为明显。推理时间增长的主要原因是LLM的Attention机制,它需要计算每个Token与其他Token之间的相对重要性,随着上下文长度的增加,Attention计算需要处理更多的Token从而导致更长的计算时间,因此更快速高效的Attention计算方法是加速LLM超长文本生成的关键。
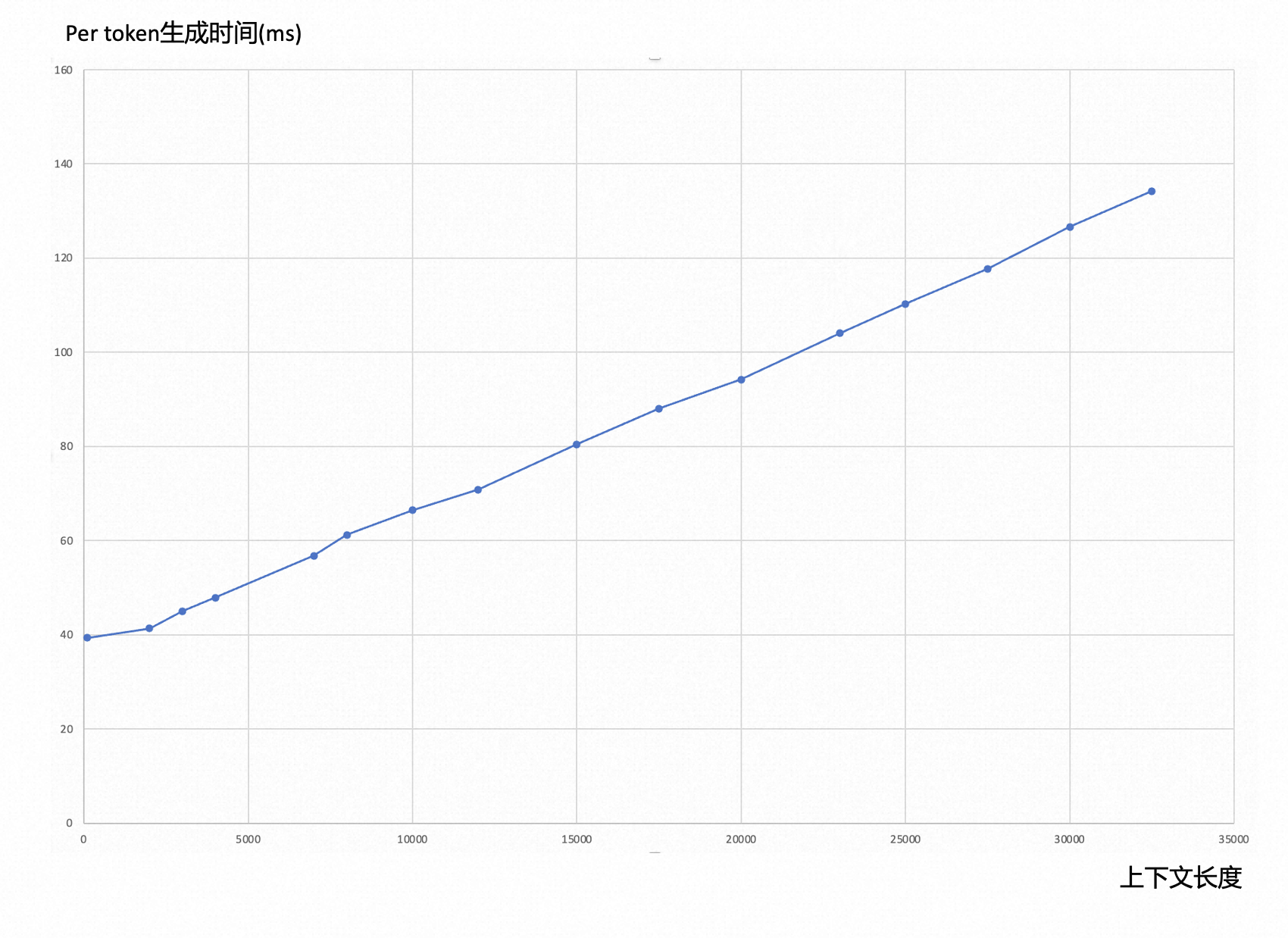
以HuggingFace Llama2-13B模型为例,随着上下文长度的增加,生成一个token的时间显著增加,具体增长趋势如下图所示。上下文长度34K时HuggingFace开源模型生成一个token的时间是上下文长度1K时的3.5倍.
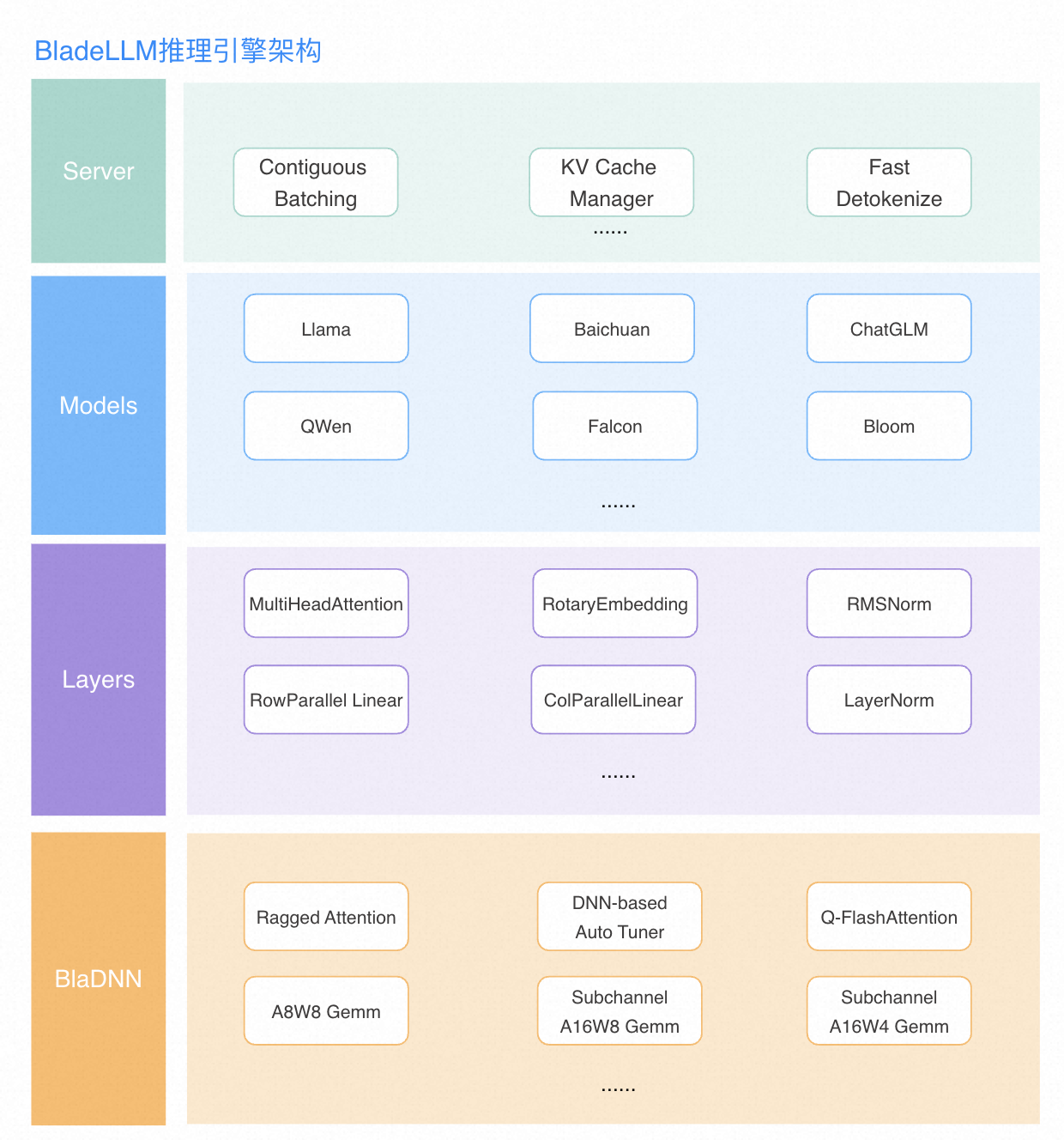
技术方案
以下是BladeLLM推理引擎的技术架构图,包含了很多核心组件,本文主要介绍其中的RaggedAttention和DNN-based AutoTuner.
RaggedAttention
近期,关于Transformer Multi Head Attention计算有两个颇具影响力的工作即FlashAttention和PagedAttention, 它们对LLM训练和推理系统的设计范式产生了深远的影响。
PagedAttention受到操作系统中虚拟内存和分页思想的启发,在不连续的显存空间中存储连续的keys和values. PagedAttention将每个sequense的kv cache划分为块,每个块包含固定数量的tokens的keys和values。由于这些块在显存中不必连续,从而极大地减少了显存碎片,并且无需为每个sequense提前预留大量的显存,使得宝贵的显存资源得到了最充分的利用。极致的显存利用率配合上Contiguous Batching,极大地提升了LLM推理服务的吞吐。相应地也带来一个缺点,不连续的显存块在一定程度上影响了kernel访存效率,从而影响了性能。
同期BladeLLM自研的RaggedAttention虽然要解决的问题与PagedAttention类似,但是在实现方法上存在一定差异,具体来说就是在kernel性能与显存利用率之间有着不同的tradeoff。
RaggedAttention的名字是受Tensorflow框架中RaggedTensor的启发。Ragged是不规则的意思,这意味着RaggedAttention的kv cache不是规则的Tensor,而是允许其中每个sequence的长度各不相同,从而能够和Contiguous Batching高效配合,提升系统吞吐。但是和PagedAttention不同的是,RaggedAttention保证同一个sequence的key和value cache是连续存储的,因此能够提升kernel的访存效率和进而提升性能。同样地,连续存储会造成一定的显存碎片和显存预留问题,从而影响了显存利用率。这是一个典型的工程上的tradeoff,没有标准答案,因为不同的算力显存配比、不同的输入输出长度、甚至不同业务对于延时的不同要求都会导致系统瓶颈的差异。作为AI平台,BladeLLM致力于为不同模型、不同设备、不同workload、不同业务场景以自动化的方式寻求最适合的配置。
例如对于变化范围极大的上下文长度,借助于下一小节将要介绍的AutoTuner,RaggedAttention在不同上下文长度下都能保持高效的计算和访存,我们实测上下文长度从1变化到512000,RaggedAttention都能获得极致的性能。
DNN-based AutoTuner
LLM推理属于典型的强Dynamic Shape场景,不仅Batch Size维度会动态变化,Sequence Length维度变化幅度更为巨大。Dynamic Shape场景下追求Kernel极致性能的主要方法之一是基于实际运行尺寸进行Tuning调优,即针对每一组特定的输入尺寸都通过实际运行和测量选取Best Schedule,采用这种方法的工作包括AutoTVM, Ansor等。 这种方法虽然可以达到很极致的性能,但是存在Tuning开销大的问题,特别是Tuning结果只能对特定Shape适用,对于Dynamic Shape场景非常不友好:如果离线预先针对所有可能的shape都tune一遍,需要花费的tuning时间以及计算资源非常巨大;如果在线对每组新shape实时进行tuning,会对线上性能产生严重的性能扰动。
针对以上痛点,BladeLLM采用了DNN-based AutoTuner,完全依赖DNN模型预测的结果而无需实际运行测量来选取Best Schedule. 我们在训练数据收集、模型结构、特征提取、Loss函数设计等方面进行了大量的探索和尝试,不断提升DNN模型的预测准确率,目前基于DNN-based AutoTuner的GPU计算密集算子的平均性能达到基于实际运行测量的Tuning调优性能的99.39%.
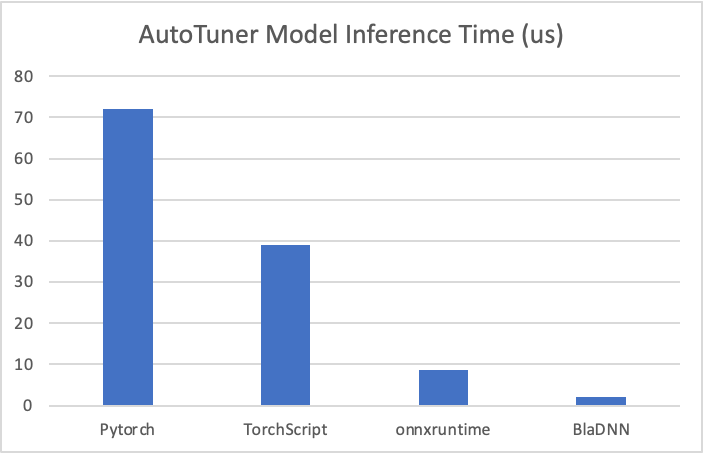
在解决了预测准确率之后,降低DNN预测模型的运行时间和占用的计算资源成为该技术应用于高实时性在线推理场景的关键挑战。直接使用已有框架和引擎(如PyTorch, TorchScript, OnnxRuntime等)搭建预测模型无法满足服务的高实时性需求,我们通过模型系统联合优化,使得AutoTuner DNN模型预测延时降低至2us. 极致的系统优化使得预测模型性能相比于用PyTorch, TorchScript, OnnxRuntime搭建的模型分别提升36倍,19.5倍和4.3倍(见下图),并且推理过程占用的系统资源极低,预测模型只使用一个CPU Core而非GPU资源以确保不对服务的GPU模型自身性能造成任何干扰。因为微秒级的低预测时延和99%以上的预测准确率,AutoTuner不仅被应用于LLM在线推理服务,还成功服务于包括搜推广、语音识别、Stable Diffusion等Dynamic Shape业务场景。
结果对比
我们以最大文本生成长度以及相应的生成时间为例来对比不同LLM推理系统最大能支持的上下文长度以及相应的性能,结果如下:
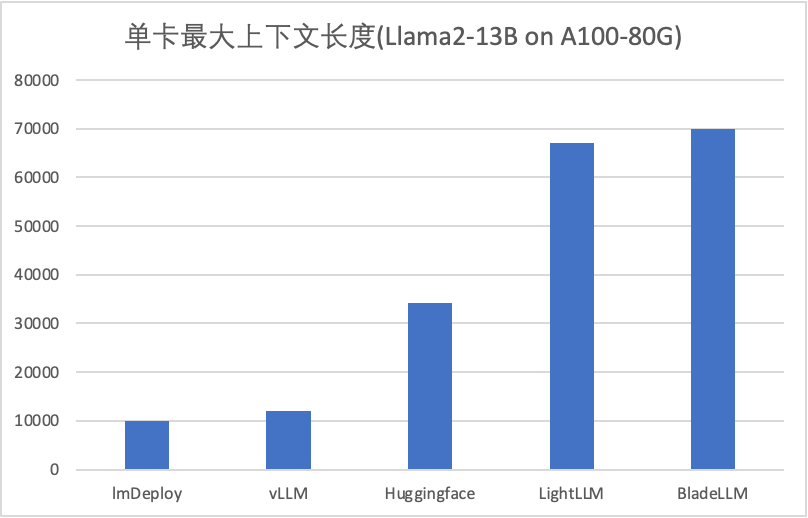
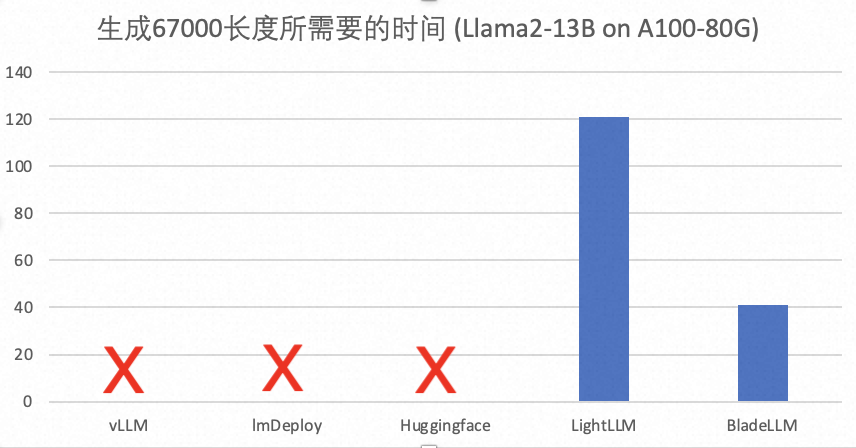
- lmDeploy(基于FasterTransformer)在生成长度超过10K之后会Hang住
- vLLM在生成长度超过12K之后出现illegal address错误
- Huggingface原始的Llama模型在生成长度超过34K后OOM
- LightLLM最大生成长度(67K)和BladeLLM(70K)接近,但是所需要的时间是BladeLLM的3倍
注:为了对比的公平性,以上结果均基于fp16权重和fp16 kv cache测量,BladeLLM现已支持kv cache量化,可进一步将单卡最大支持的上下文长度提升至280K;以上所有的测量均未采用投机采样;以上测量在8月份完成,目前业界LLM推理引擎都还在快速发展中,我们期待更新的结果对比,同时BladeLLM支持更长上下文、更高性能的新版本开发也接近尾声,有了新的结果我们会继续和大家分享。
总结
超长上下文是LLM发展的必然趋势,而当前主流的LLM推理和服务引擎所支持的上下文长度以及超长上下文的推理性能都远远不够,以上分享了一些关于BladeLLM对超长上下文的支持以及超长上下文推理性能,欢迎大家交流讨论。此外,除了关注超长上下文场景,BladeLLM也会持续关注推理的多个技术方向,包括低比特量化压缩、多轮对话、极致内核优化、编译优化等,后续我们也会有更多的技术分享对外公开,欢迎大家持续关注!
