

大家好,我是飘渺。今天我们继续更新DDD(领域驱动设计) & 微服务系列。
在之前的文章中,我们探讨了如何在DDD中结构化应用程序。我们了解到,在DDD中通常将应用程序分为四个层次,分别为用户接口层(Interface Layer),应用层(Application Layer),领域层(Domain Layer),和基础设施层(Infrastructure Layer)。此外,在用户注册的主题中,我们简要地提及了资源库模式。然而,那时我们并没有深入探讨。今天,我将为大家详细介绍资源库模式,这在DDD中是一个非常重要的概念。
1. 传统开发流程分析
首先,让我们回顾一下传统的以数据库为中心的开发流程。
在这种开发流程中,开发者通常会创建Data Access Object(DAO)来封装对数据库的操作。DAO的主要优势在于它能够简化构建SQL查询、管理数据库连接和事务等底层任务。这使得开发者能够将更多的精力放在业务逻辑的编写上。然而,DAO虽然简化了操作,但仍然直接处理数据库和数据模型。
值得注意的是,Uncle Bob在《代码整洁之道》一书中,通过一些术语生动地描述了这个问题。他将系统元素分为三类:
硬件(Hardware): 指那些一旦创建就不可(或难以)更改的元素。在开发背景下,数据库被视为“硬件”,因为一旦选择了一种数据库,例如MySQL,转向另一种数据库,如MongoDB,通常会带来巨大的成本和挑战。
软件(Software): 指那些创建后可以随时修改的元素。开发者应该致力于使业务代码作为“软件”,因为业务需求和规则总是在不断变化,因此代码也应该具有相应的灵活性和可调整性。
固件(Firmware): 是那些与硬件紧密耦合,但具有一定的软性特点的软件。例如,路由器的固件或Android固件。它们为硬件提供抽象,但通常只适用于特定类型的硬件。
通过理解这些术语,我们可以认识到数据库应视为“硬件”,而DAO在本质上属于“固件”。然而,我们的目标是使我们的代码保持像“软件”那样的灵活性。但是,当业务代码过于依赖于“固件”时,它会受到限制,变得难以更改。
让我们通过一个具体的例子来进一步理解这个概念。下面是一个简单的代码片段,展示了一个对象如何依赖于DAO(也就是依赖于数据库):
private OrderDAO orderDAO;
public Long addOrder(RequestDTO request) {
// 此处省略很多拼装逻辑
OrderDO orderDO = new OrderDO();
orderDAO.insertOrder(orderDO);
return orderDO.getId();
}
public void updateOrder(OrderDO orderDO, RequestDTO updateRequest) {
orderDO.setXXX(XXX); // 省略很多
orderDAO.updateOrder(orderDO);
}
public void doSomeBusiness(Long id) {
OrderDO orderDO = orderDAO.getOrderById(id);
// 此处省略很多业务逻辑
}
上面的代码片段看似无可厚非,但假设在未来我们需要加入缓存逻辑,代码则需要改为如下:
private OrderDAO orderDAO;
private Cache cache;
public Long addOrder(RequestDTO request) {
// 此处省略很多拼装逻辑
OrderDO orderDO = new OrderDO();
orderDAO.insertOrder(orderDO);
cache.put(orderDO.getId(), orderDO);
return orderDO.getId();
}
public void updateOrder(OrderDO orderDO, RequestDTO updateRequest) {
orderDO.setXXX(XXX); // 省略很多
orderDAO.updateOrder(orderDO);
cache.put(orderDO.getId(), orderDO);
}
public void doSomeBusiness(Long id) {
OrderDO orderDO = cache.get(id);
if (orderDO == null) {
orderDO = orderDAO.getOrderById(id);
}
// 此处省略很多业务逻辑
}
可以看到,插入缓存逻辑后,原本简单的代码变得复杂。原本一行代码现在至少需要三行。随着代码量的增加,如果你在某处忘记查看缓存或忘记更新缓存,可能会导致轻微的性能下降或者更糟糕的是,缓存和数据库的数据不一致,从而导致bug。这种问题随着代码量和复杂度的增长会变得更加严重,这就是软件被“固化”的后果。
因此,我们需要一个设计模式来隔离我们的软件(业务逻辑)与固件/硬件(DAO、数据库),以提高代码的健壮性和可维护性。这个模式就是DDD中的资源库模式(Repository Pattern)。
2. 深入理解资源库模式
在DDD(领域驱动设计)中,资源库起着至关重要的作用。资源库的核心任务是为应用程序提供统一的数据访问入口。它允许我们以一种与底层数据存储无关的方式,来存储和检索领域对象。这对于将业务逻辑与数据访问代码解耦是非常有价值的。
2.1 资源库模式在架构中的位置
资源库是一种广泛应用的架构模式。事实上,当你使用诸如Hibernate、Mybatis这样的ORM框架时,你已经在间接地使用资源库模式了。资源库扮演着对象的提供者的角色,并且处理对象的持久化。让我们看一下持久化:持久化意味着将数据保存在一个持久媒介,比如关系型数据库或NoSQL数据库,这样即使应用程序终止,数据也不会丢失。这些持久化媒介具有不同的特性和优点,因此,资源库的实现会依据所使用的媒介有所不同。
资源库的设计通常包括两个主要组成部分:定义和实现。定义部分是一个抽象接口,它只描述了我们可以对数据执行哪些操作,而不涉及具体如何执行它们。实现部分则是这些操作的具体实现。它依赖于一个特定的持久化媒介,并可能需要与特定的技术进行交互。
2.2 领域层与基础设施层
根据DDD的分层架构,领域层包含所有与业务领域有关的元素,包括实体、值对象和聚合。领域层表示业务的核心概念和逻辑。
另一方面,基础设施层包含支持其他层的通用技术,比如数据库访问、文件系统交互等。
资源库模式很好地适用于这种分层结构。资源库的定义部分,即抽象接口,位于领域层,因为它直接与领域对象交互。而资源库的实现部分则属于基础设施层,它处理具体的数据访问逻辑。
以DailyMart系统中的CustomerUser为例
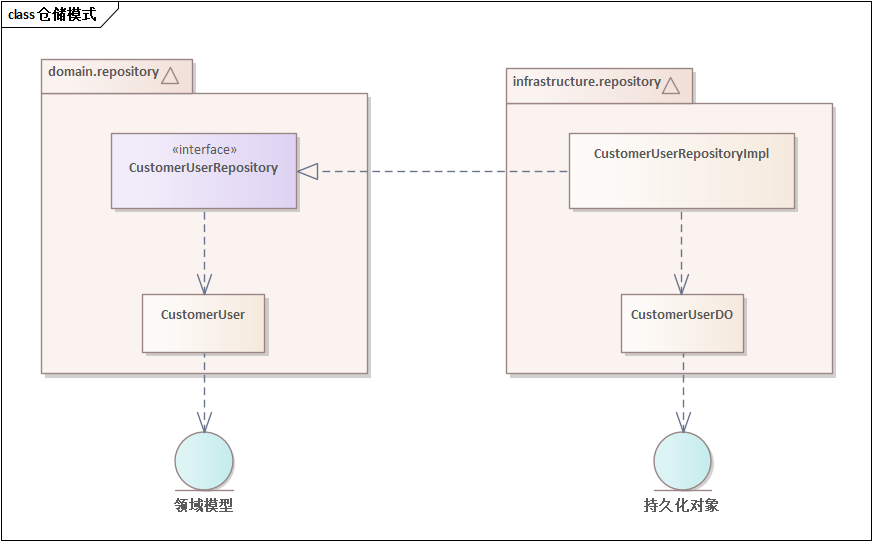
如上图所示,CustomerUserRepository是资源库接口,位于领域层,操作的对象是CustomerUser聚合根。CustomerUserRepositoryImpl是资源库的实现部分,位于基础设施层。这个实现部分操作的是持久化对象,这就需要在基础设施层中有一个组件来处理领域对象与数据对象的转换,在之前的文章中已经推荐使用工具mapstruct来实现这种转换。
2.3 小结
资源库是DDD中一个强大的概念,允许我们以一种整洁和一致的方式来处理数据访问。通过将资源库的定义放在领域层,并将其实现放在基础设施层,我们能够有效地将业务逻辑与数据访问代码解耦,从而使应用程序更加灵活和可维护。
3. 仓储接口的设计原则
上文曾经讲过,传统Data Mapper(DAO)属于“固件”,和底层实现(DB、Cache、文件系统等)强绑定,如果直接使用会导致代码“固化”。所以为了在Repository的设计上体现出“软件”的特性,主要需要注意以下三点:
-
接口名称不应该使用底层实现的语法: 我们常见的insert、select、update、delete都属于SQL语法,使用这几个词相当于和DB底层实现做了绑定。相反,我们应该把 Repository 当成一个中性的类 似Collection 的接口,使用语法如 find、save、remove。在这里特别需要指出的是区分 insert/add 和 update 本身也是一种和底层强绑定的逻辑,一些储存如缓存实际上不存在insert和update的差异,在这个 case 里,使用中性的 save 接口,然后在具体实现上根据情况调用 DAO 的 insert 或 update 接口。
-
出参入参不应该使用底层数据格式: Repository接口位于领域层,根本看不到也不关心基础设施层的实现,当底层的存储技术改变时,领域模型不需要做任何修改。仓储接口操作的对象是实体,实际上应该是聚合根(Aggregate Root)对象。
-
应该避免所谓的“通用”Repository模式: 很多 ORM 框架都提供一个“通用”的Repository接口,然后框架通过注解自动实现接口,比较典型的例子是Spring Data、Entity Framework等,这种框架的好处是在简单场景下很容易通过配置实现,但是坏处是基本上无扩展的可能性(比如加定制缓存逻辑),在未来有可能还是会被推翻重做。当然,这里避免通用不代表不能有基础接口和通用的帮助类,具体如下。
-
明确的事务边界:在大多数情况下,事务应该在应用服务层开始和结束,而不是在仓储层。
通过遵循上述原则和最佳实践,我们可以创建一个仓储接口,不仅与底层数据存储解耦,还能支持领域模型的演变和应用程序的可维护性。
4. Repository的代码实现
在DailyMart项目中,为了实现DDD开发的最佳实践,我们创建一个名为dailymart-ddd-spring-boot-starter的组件模块,专门存放DDD相关的核心组件。这种做法简洁地让其他模块通过引入此公共模块来遵循DDD原则。
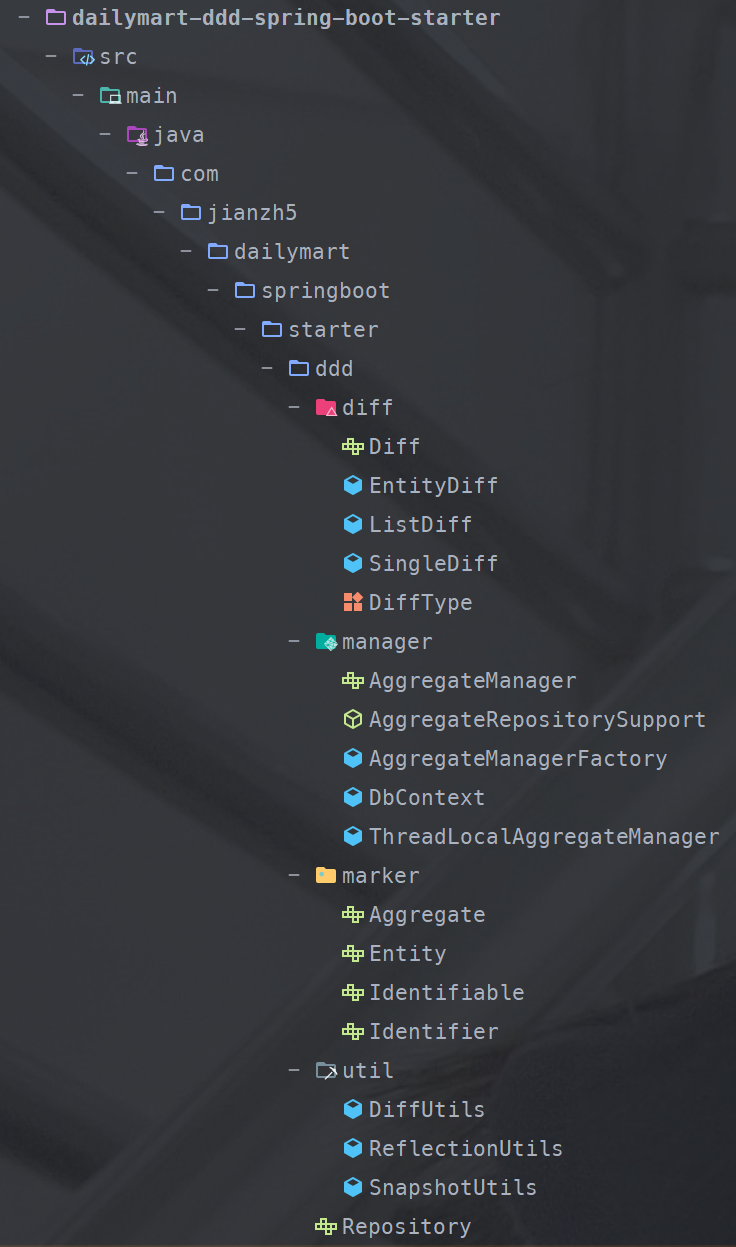
4.1 制定Marker接口类
Marker接口主要为类型定义和派生类分类提供标识,通常不包含任何方法。我们首先定义几个核心的Marker接口。
public interface Identifiable> extends Serializable {
ID getId();
}
public interface Identifier extends Serializable {
T getValue();
}
public interface Entity> extends Identifiable { }
public interface Aggregate> extends Entity { }
这里,聚合会实现Aggregate接口,而实体会实现Entity接口。聚合本质上是一种特殊的实体,这种结构使逻辑更加清晰。另外,我们引入了Identifier接口来表示实体的唯一标识符,它将唯一标识符视为值对象,这是DDD中常见的做法。如下面所示的案例
public class OrderId implements Identifier {
@Serial
private static final long serialVersionUID = -8658575067669691021L;
public Long id;
public OrderId(Long id){
this.id = id;
}
@Override
public Long getValue() {
return id;
}
}
4.2 创建通用Repository接口
接下来,我们定义一个基础的Repository接口。
public interface Repository , ID extends Identifier>> {
T find(ID id);
void remove(T aggregate);
void save(T aggregate);
}
业务特定的接口可以在此基础上进行扩展。例如,对于订单,我们可以添加计数和分页查询。
public interface OrderRepository extends Repository {
// 自定义Count接口,在这里OrderQuery是一个自定义的DTO
Long count(OrderQuery query);
// 自定义分页查询接口
Page query(OrderQuery query);
}
请注意,Repository的接口定义位于Domain层,而具体的实现则位于Infrastructure层。
4.3 实施Repository的基本功能
下面是一个简单的Repository实现示例。注意,OrderRepositoryNativeImpl在Infrastructure层。
@Repository
@RequiredArgsConstructor(onConstructor = @__(@Autowired))
@Slf4j
public class OrderRepositoryNativeImpl implements OrderRepository {
private final OrderMapper orderMapper;
private final OrderItemMapper orderItemMapper;
private final OrderConverter orderConverter;
private final OrderItemConverter orderItemConverter;
@Override
public Order find(OrderId orderId) {
OrderDO orderDO = orderMapper.selectById(orderId.getValue());
return orderConverter.fromData(orderDO);
}
@Override
public void save(Order aggregate) {
if(aggregate.getId() != null && aggregate.getId().getValue() > 0){
// update
OrderDO orderDO = orderConverter.toData(aggregate);
orderMapper.updateById(orderDO);
}else{
// insert
OrderDO orderDO = orderConverter.toData(aggregate);
orderMapper.insert(orderDO);
aggregate.setId(orderConverter.fromData(orderDO).getId());
}
}
...
}
这段代码展示了一个常见的模式:Entity/Aggregate转换为Data Object(DO),然后使用Data Access Object(DAO)根据业务逻辑执行相应操作。在操作完成后,如果需要,还可以将DO转换回Entity。代码很简单,唯一需要注意的是save方法,需要根据Aggregate的ID是否存在且大于0来判断一个Aggregate是否需要更新还是插入。
4.4 Repository复杂实现
处理单一实体的Repository实现通常较为直接,但当聚合中包含多个实体时,操作的复杂性会增加。主要的问题在于,在单次操作中,并不是聚合中的所有实体都需要变更,而使用简单的实现会导致许多不必要的数据库操作。
以一个典型的场景为例:一个订单中包含多个商品明细。如果修改了某个商品明细的数量,这会同时影响主订单的总价,但对其他商品明细则没有影响。
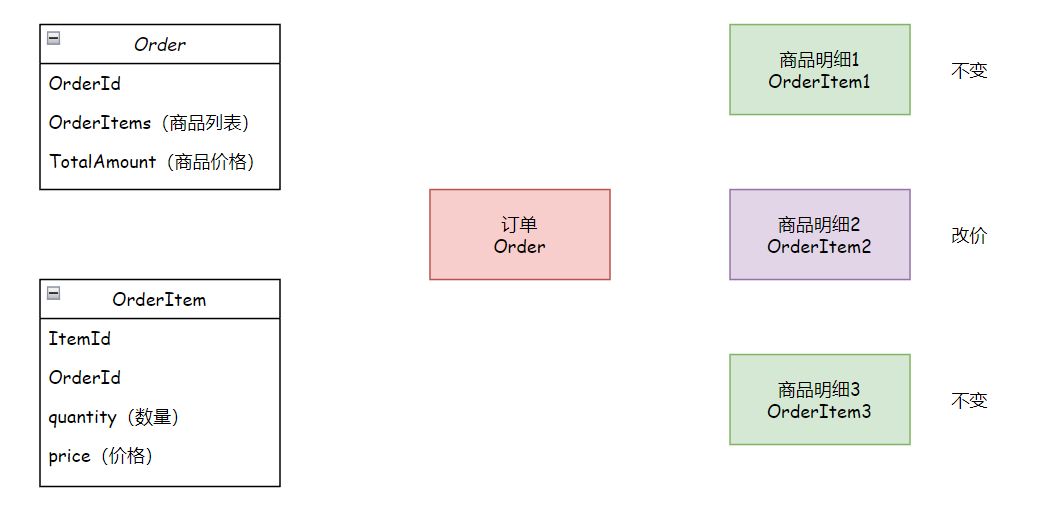
若采用基础的实现方法,会多出两个不必要的更新操作,如下所示:
@Repository
@RequiredArgsConstructor(onConstructor = @__(@Autowired))
@Slf4j
public class OrderRepositoryNativeImpl implements OrderRepository {
//省略其他逻辑
@Override
public void save(Order aggregate) {
if(aggregate.getId() != null && aggregate.getId().getValue() > 0){
// 每次都将Order和所有LineItem全量更新
OrderDO orderDO = orderConverter.toData(aggregate);
orderMapper.updateById(orderDO);
for(OrderItem orderItem : aggregate.getOrderItems()){
save(orderItem);
}
}else{
//省略插入逻辑
}
}
private void save(OrderItem orderItem) {
if (orderItem.getId() != null && orderItem.getId().getValue() > 0) {
OrderItemDO orderItemDO = orderItemConverter.toData(orderItem);
orderItemMapper.updateById(orderItemDO);
} else {
OrderItemDO orderItemDO = orderItemConverter.toData(orderItem);
orderItemMapper.insert(orderItemDO);
orderItem.setItemId(orderItemConverter.fromData(orderItemDO).getId());
}
}
}
在此示例中,会执行4个UPDATE操作,而实际上只需2个。通常情况下,这个额外的开销并不严重,但如果非Aggregate Root的实体数量很大,这会导致大量不必要的写操作。
4.5 变更追踪(Change-Tracking)
针对上述问题,核心在于Repository接口的限制使得调用者只能操作Aggregate Root,而不能单独操作非Aggregate Root的实体。这与直接调用DAO的方式有显著差异。
一种解决方案是通过变更追踪能力来识别哪些实体有变更,并且仅对这些变更过的实体执行操作。这样,先前需要手动判断的代码逻辑现在可以通过变更追踪来自动实现,让开发者真正只关注聚合的操作。以前面的示例为例,通过变更追踪,系统可以判断出只有OrderItem2和Order发生了变化,因此只需要生成两个UPDATE操作。
变更追踪有两种主流实现方式:
-
基于快照Snapshot的方案: 数据从数据库提取后,在内存中保存一份快照,然后在将数据写回时与快照进行比较。Hibernate是采用此种方法的常见实现。
-
基于代理Proxy的方案: 当数据从数据库提取后,通过织入的方式为所有setter方法增加一个切面来检测setter是否被调用以及值是否发生变化。如果值发生变化,则将其标记为“脏”(Dirty)。在保存时,根据这个标记来判断是否需要更新。Entity Framework是一个采用此种方法的常见实现。
代理Proxy方案的优势是性能较高,几乎没有额外成本,但缺点是实现起来比较复杂,而且当存在嵌套关系时,不容易检测到嵌套对象的变化(例如,子列表的增加和删除),可能会导致bug。
而快照Snapshot方案的优势是实现相对简单,成本在于每次保存时执行全量比较(通常使用反射)以及保存快照的内存消耗。
由于代理Proxy方案的复杂性,业界主流(包括EF Core)更倾向于使用基于Snapshot快照的方案。
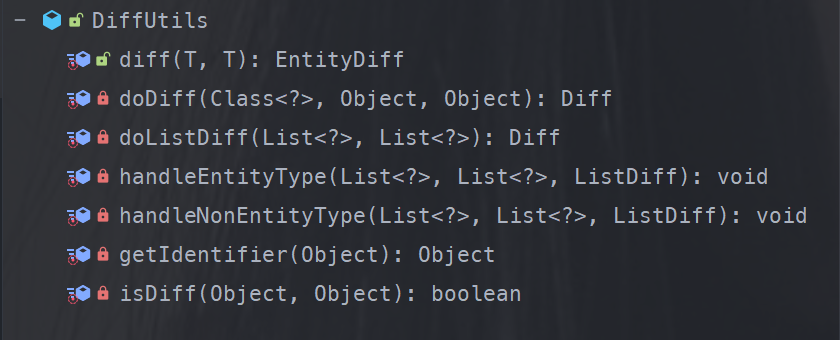
此外,通过检测差异,我们能识别哪些字段发生了改变,并仅更新这些发生变化的字段,从而进一步降低UPDATE操作的开销。无论是否在DDD上下文中,这个功能本身都是非常有用的。在DailyMart示例中,我们使用一个名为DiffUtils的工具类来辅助比较对象间的差异。
public class DiffUtilsTest {
@Test
public void diffObject() throws IllegalAccessException, IOException, ClassNotFoundException {
//实时对象
Order realObj = Order.builder()
.id(new OrderId(31L))
.customerId(100L)
.totalAmount(new BigDecimal(100))
.recipientInfo(new RecipientInfo("zhangsan","安徽省合肥市","123456"))
.build();
// 快照对象
Order snapshotObj = SnapshotUtils.snapshot(realObj);
snapshotObj.setId(new OrderId(2L));
snapshotObj.setTotalAmount(new BigDecimal(200));
EntityDiff diff = DiffUtils.diff(realObj, snapshotObj);
assertTrue(diff.isSelfModified());
assertEquals(2, diff.getDiffs().size());
}
}
详细用法可以参考单元测试com.jianzh5.dailymart.module.order.infrastructure.util.DiffUtilsTest
通过变更追踪的引入,我们能够使聚合的Repository实现更加高效和智能。这允许开发人员将注意力集中在业务逻辑上,而不必担心不必要的数据库操作。
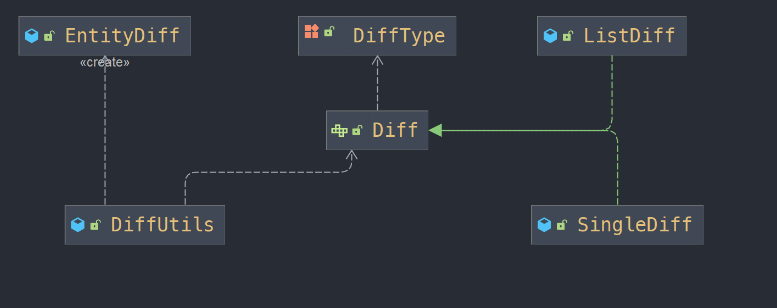
5 在DailyMart中集成变更追踪
DailyMart系统内涵盖了一个订单子域,该子域以Order作为聚合根,并将OrderItem纳入为其子实体。两者之间构成一对多的联系。在对订单进行更新操作时,变更追踪显得尤为关键。
下面展示的是DailyMart系统中关于变更追踪的核心代码片段。值得注意的是,这些代码仅用于展示如何在仓库模式中融入变更追踪,并非订单子域的完整实现。
AggregateRepositorySupport 类
该类是聚合仓库的支持类,它管理聚合的变更追踪。
@Slf4j
public abstract class AggregateRepositorySupport, ID extends Identifier>> implements Repository {
@Getter
private final Class targetClass;
// 让 AggregateManager 去维护 Snapshot
@Getter(AccessLevel.PROTECTED)
private AggregateManager aggregateManager;
protected AggregateRepositorySupport(Class targetClass) {
this.targetClass = targetClass;
this.aggregateManager = AggregateManagerFactory.newInstance(targetClass);
}
/** Attach的操作就是让Aggregate可以被追踪 */
@Override
public void attach(@NotNull T aggregate) {
this.aggregateManager.attach(aggregate);
}
/** Detach的操作就是让Aggregate停止追踪 */
@Override
public void detach(@NotNull T aggregate) {
this.aggregateManager.detach(aggregate);
}
@Override
public T find(@NotNull ID id) {
T aggregate = this.onSelect(id);
if (aggregate != null) {
// 这里的就是让查询出来的对象能够被追踪。
// 如果自己实现了一个定制查询接口,要记得单独调用attach。
this.attach(aggregate);
}
return aggregate;
}
@Override
public void remove(@NotNull T aggregate) {
this.onDelete(aggregate);
// 删除停止追踪
this.detach(aggregate);
}
@Override
public void save(@NotNull T aggregate) {
// 如果没有 ID,直接插入
if (aggregate.getId() == null) {
this.onInsert(aggregate);
this.attach(aggregate);
return;
}
// 做 Diff
EntityDiff diff = null;
try {
//todo 从数据加载对象
//aggregate = this.onSelect(aggregate.getId());
find(aggregate.getId());
diff = aggregateManager.detectChanges(aggregate);
} catch (IllegalAccessException e) {
//todo 优化 异常
//throw new RuntimeException("Failed to detect changes", e);
e.printStackTrace();
}
if (diff.isEmpty()) {
return;
}
// 调用 UPDATE
this.onUpdate(aggregate, diff);
// 最终将 DB 带来的变化更新回 AggregateManager
aggregateManager.merge(aggregate);
}
/** 这几个方法是继承的子类应该去实现的 */
protected abstract void onInsert(T aggregate);
protected abstract T onSelect(ID id);
protected abstract void onUpdate(T aggregate, EntityDiff diff);
protected abstract void onDelete(T aggregate);
}
OrderRepositoryDiffImpl 类
这个类继承自 AggregateRepositorySupport 类,并实现具体的订单存储逻辑。
@Repository
@Slf4j
@Primary
public class OrderRepositoryDiffImpl extends AggregateRepositorySupport implements OrderRepository {
//省略其他逻辑
@Override
protected void onUpdate(Order aggregate, EntityDiff diff) {
if (diff.isSelfModified()) {
OrderDO orderDO = orderConverter.toData(aggregate);
orderMapper.updateById(orderDO);
}
Diff orderItemsDiffs = diff.getDiff("orderItems");
if ( orderItemsDiffs instanceof ListDiff diffList) {
for (Diff itemDiff : diffList) {
if(itemDiff.getType() == DiffType.REMOVED){
OrderItem orderItem = (OrderItem) itemDiff.getOldValue();
orderItemMapper.deleteById(orderItem.getItemId().getValue());
}
if (itemDiff.getType() == DiffType.ADDED) {
OrderItem orderItem = (OrderItem) itemDiff.getNewValue();
orderItem.setOrderId(aggregate.getId());
OrderItemDO orderItemDO = orderItemConverter.toData(orderItem);
orderItemMapper.insert(orderItemDO);
}
if (itemDiff.getType() == DiffType.MODIFIED) {
OrderItem line = (OrderItem) itemDiff.getNewValue();
OrderItemDO orderItemDO = orderItemConverter.toData(line);
orderItemMapper.updateById(orderItemDO);
}
}
}
}
}
ThreadLocalAggregateManager 类
这个类主要通过ThreadLocal来保证在多线程环境下,每个线程都有自己的Entity上下文。
public class ThreadLocalAggregateManager, ID extends Identifier>> implements AggregateManager {
private final ThreadLocal> context;
private Class extends T> targetClass;
public ThreadLocalAggregateManager(Class extends T> targetClass) {
this.targetClass = targetClass;
this.context = ThreadLocal.withInitial(() -> new DbContext(targetClass));
}
@Override
public void attach(T aggregate) {
context.get().attach(aggregate);
}
@Override
public void attach(T aggregate, ID id) {
context.get().setId(aggregate, id);
context.get().attach(aggregate);
}
@Override
public void detach(T aggregate) {
context.get().detach(aggregate);
}
@Override
public T find(ID id) {
return context.get().find(id);
}
@Override
public EntityDiff detectChanges(T aggregate) throws IllegalAccessException {
return context.get().detectChanges(aggregate);
}
@Override
public void merge(T aggregate) {
context.get().merge(aggregate);
}
}
SnapshotUtils 类
SnapshotUtils 是一个工具类,它利用深拷贝技术来为对象创建快照。
public class SnapshotUtils {
@SuppressWarnings("unchecked")
public static > T snapshot(T aggregate)
throws IOException, ClassNotFoundException {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(aggregate);
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (T) ois.readObject();
}
}
这个类中的 snapshot 方法采用序列化和反序列化的方式来实现对象的深拷贝,从而为给定的对象创建一个独立的副本。注意,为了使此方法工作,需要确保 Aggregate 类及其包含的所有对象都是可序列化的。
6. 小结
在本文中,我们深入探讨了DDD(领域驱动设计)的一个核心构件 —— 仓储模式。借助快照模式和变更追踪,我们成功解决了仓储模式仅限于操作聚合根的约束,这为后续开发提供了一种实用的模式。
在互联网上有丰富的DDD相关文章和讨论,但值得注意的是,虽然许多项目宣称使用Repository模式,但在实际实现上可能并未严格遵循DDD的关键设计原则。以订单和订单项为例,一些项目在正确地把订单项作为订单聚合的一部分时,却不合理地为订单项单独创建了Repository接口。而根据DDD的理念,应当仅为聚合根配备对应的仓储接口。通过今天的探讨,我们应该更加明确地理解和运用DDD的原则,以确保更加健壮和清晰的代码结构。
DDD&微服务系列源码已经上传至GitHub,如果需要获取源码地址,请关注公号 java日知录 并回复关键字 DDD 即可!
