


更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
背景介绍
Notebook 解决的问题
- 部分任务类型(python、spark等)在创建配置阶段,需要进行分步调试;
- 由于探索查询能力较弱,部分用户只能通过其他平台 or 其他途径进行开发调试,但部署到 Dorado时,又发现行为不一致等问题(运行环境问题),整体体验较差,需要提升探索查询模块的能力;
- 目前探索查询仅支持 SQL,可支持更多语言类型,扩展数据开发手段;
总体架构介绍
火山引擎DataLeap notebook 主要是基于 JupyterHub、notebook、lab、enterprise kernel gateway 等开源项目实现,并在这些项目的基础上进行深度修改与定制化,以满足 火山引擎DataLeap用户的需求。
基础组件方面,主要是基于 TCE、YARN、MYSQL、TLB、TOS。
核心目标是提供支持大规模用户、稳定的、容易扩展的 Notebook 服务。
系统总体架构如下图所示,主要包括 Hub、notebook server(nbsvr)、kernel gateway(eg) 等组件。
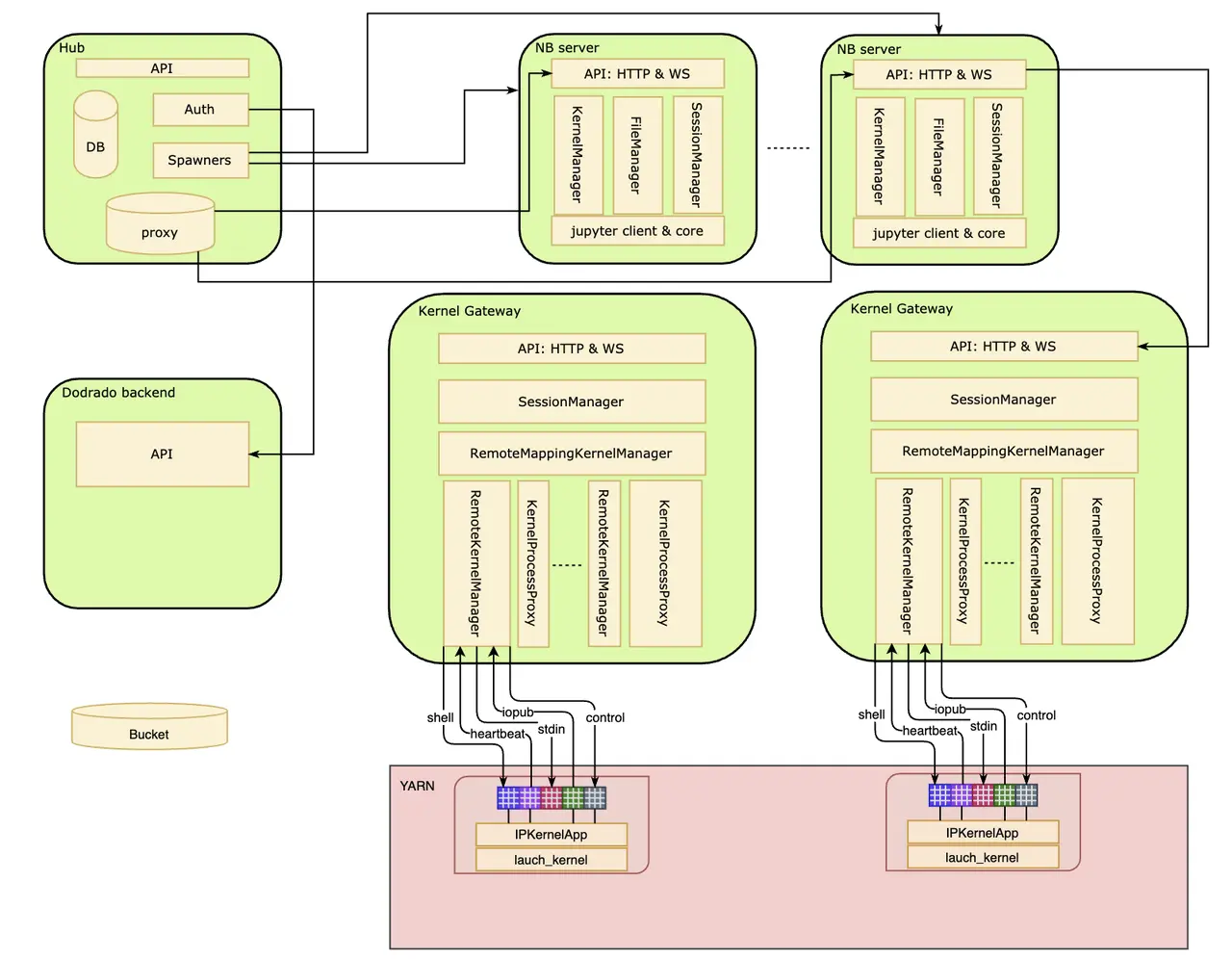
多用户管理
Hub
JupyterHub 是一个支持 “多用户” notebook 的 Server,通过管理 & 代理多个单用户的 notebook server 实现多用户 notebook。
JupyterHub 服务主要三个组件构成:
- a Hub (tornado process), which is the heart of JupyterHub;
- a configurable http proxy (node-http-proxy): 动态路由用户的请求到 Hub 或者 Notebook server;
- multiple single-user Jupyter notebook servers (Python/IPython/tornado) that are monitored by Spawners;
- an authentication class that manages how users can access the system;
整个系统架构图如下所示:
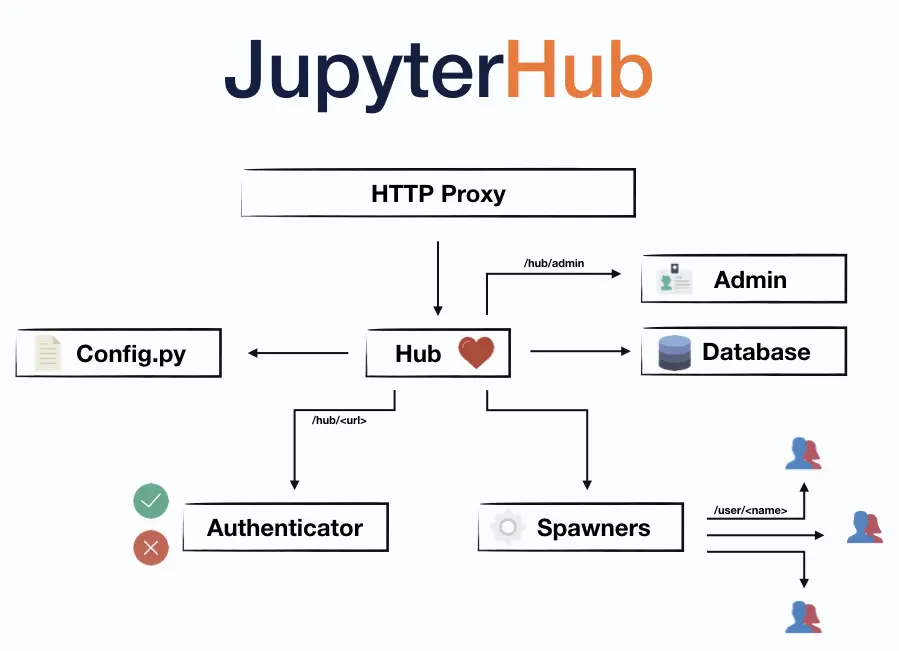
用户通过 IP 地址或者域名访问 JupyterHub,基本流程为:
- 启动 Hub 服务,Hub 会启动 proxy 进程;
- 用户请求 Hub,请求会被打到 proxy,proxy 维护了 proxy table,每条 mapping 记录为用户请求到 target IP 或者 域名的映射;proxy table 不存在当前请求的 mapping 时,proxy 默认把请求全部打到 Hub;
- Hub 处理用户认证与鉴权,同时 Hub spawner 启动一个 Notebook server;
- Hub 配置 proxy,路由该该用户的请求到创建的 notebook server 处;
1、火山引擎DataLeap authentication Hub 原生地支持 authentication,主要是用来解决多租户的问题。Hub 里主要是使用 authenticator 类来进行 authenticate 。
Hub 原生支持的 authenticator 主要有一下几个:
- Local authenticator, work with local Linux/UNIX userst
- PAM authenticator, authenticate local UNIX users with PAM
- Dummy authenticator, any username + password is allowed for testing
考虑到方案1需要开发量大、维护成本高,我们采用了方案2。
采用了方案2的整个认证 & 鉴权步骤如下所示:
- 用户在 web 页面访问了 火山引擎DataLeap notebook,frontend 会带上 session 信息请求 hub post /api/users/{name}/tokens api 获取一个 token,该流程需要 authenticate & authroization,包括:
- 通过 titan 认证该 sessionid 对应的 user;
- 通过 火山引擎DataLeap backend ProjectControl /project/canedit api 验证用户是否具有项目权限;
- 后续该用户的访问均会带上 token,Hub 会使用该 token 进行用户认证。
- 每次生成的 token 会保存到 db;
- 认证时也是从 db 进行匹配;
- Token 存在 expire time,expired 的会被从 db 清理掉;
2、TCE Spawner Spawner 负责启动 single-user notebook server,其本质是一个进程的抽象表示,一个定制化的 spawner 实现下面三个方法:
- start the process
- poll whether the process is still running
- stop the process More info on custom Spawners. See a list of custom Spawners on the wiki.
目前我们的服务不是运行在物理机上,所以不会通过 k8s 管理 server & kernel。考虑到运维 & 扩展,我们考虑使用 TCE 作为 notebook server 的载体,因此我们需要实现 TCE Spawner。
设计 TCE spawner 时,有以下几点考虑:
- Spawner.state 需要包含 service id、cluster id、psm、api token 等信息,这些信息会持久化在 db 中;hub 重启 或者 server 关闭后,重新启动 notebook server 时,保证同一个用户映射到之前该用户启动的那个 sever(same user same server);
- 为了加快启动过程,spawner 确认 tce 实例启动时,一旦发起了 tce cluster deployment 后就开始 sd lookup psm 确认 server 是否正常启动,不通过 poll deployment status 确认是否部署完成,这可以加快启动过程,因为 tce 部署过程中包括健康检查等步骤,占时较长;
- Stop 中,并不真正 kill tce 实例,这样下次启动基本不消耗时间;
- Poll server 状态时,需要考虑 升级 & migrate 带来的状态变化,一旦发现立刻返回 异常状态,这样 hub 就会认为这个 notebook server not running,就会异常 该 spawner,后续新的请求到来时会重新启动 spawner,由于此时已经非第一次启动,过程极快,用户不感知。
整个 TCE spawner,主要用到了 tce 的两个特性:
- Psm 唯一对应了一个服务;
- 通过 psm 发现 ip & port;
- 通过 tce 的 api 获取 server 状态;
- 方便运维(升级 & 迁移);
题外话: 最近调研了 server on yarn ,有点类似 k8s 的感觉,本质上都是走资源调度,但是 yarn 资源调度有个缺点:每个 application 调度到 yarn 时,都需要伴随一个 Application Master。虽然 AM 大多数时候主要是用来和 RM 保持心跳,只需要 0.5 核即可,但是总感觉很别扭,或者说多了一个不稳定的因素。
3、State isolated
(1) Hub migration
原生 jupyter hub 的升级或者实例迁移时,需要把所有的 spawner & server 关闭掉。这意味着,hub 实例变化后,之前的 server & kernel 都会被关闭。
由于当前系统采用了 remote server + remote kernel,且不会主动 shutdown kernel,因此当 hub 实例发生变化时, server & kernel 实例不会被关闭。但是新 hub 实例启动后,所有的 server 都将连接不到新的 hub 实例上,会产生幽灵 server & kernel。
我们提供了如下解决方案:
- 在 notebook server 里增加定时检查线程,根据 hub 的 psm 检查对应的 ip & port 是否发生改变;
- 如果发生改变,则切换 hub_activity_url & hub_api_url。如此,notebook server 就可以连接到新的 hub 实例了。
(2) Notebook server migration
如果 notebook server 实例升级或者迁移了,hub 也需要能及时感知,并能正确关闭 spawner。
这个目前是通过 tce spawner poll 实现,poll 里会 check 对应的 notebook server 的 ip & port 是否发生变化,如果发生了变化则返回非零状态,表示 server 异常,此时 hub 感知到并关闭 spawner。后续,用户的请求到来时,会重新创建 spawner 并连接到同一个 notebook server。
Resource pool
Pool 的设计有两个考虑:
- Tce 资源无法独占;
- Server 启动慢;
由于 notebook server 是启动在 TCE 上的,TCE 上启动一个 server 需要经历如下几个关键阶段: 新建 service -> 新建 cluster -> 部署(构建镜像、部署)-> 一些检查 整个过程耗时较长,预计耗时3-5分钟,如果每个 server 的启动过程都需要这么久,显然是无法接受的。
于是,我们申请了新建了一堆 tce 实例构建成 tce resource pool。每次新项目接入,Hub spawner 按照如下流程处理:
- 去 tce resource pool 中检查是否存在未被占用的实例,有则挑一个
- 否则,走原新建流程;
目前 pool 的建立是手动操作的,后期会支持自动检测扩容:
- 定时线程,检测当前 pool 的容量是否少于 30 (例如);
- 少于则新建并加入 pool 中;
另一个问题是:pool 里的每个实例均需要支持 psm 服务发现,那么在 server 被分配前,他们处于什么状态呢?被分配后,如何按照 user 对应的配置启动 server 呢? Pool 里的实例,均是启动了一个 idle server(原生的 notebook server)(该方式可以让该实例成功启动,并且能被服务发现),同时存在一个定时线程,不断去检查 tos 对应的配置文件是否 ready,ready 后 shutdown idle server,按照 tos 配置文件启动 single user notebook server。
这种方式后,启动时间从 3min+ 降到 8s,8s 为 single user notebook server 启动并稳定提供服务的时间。
Kernel 管理
book 存储
Notebook 中的代码和输出文本主要是通过后缀为 .ipynb 的 json 文件存储的,因此 notebook server 需要负责 ipynb 文件的新建、删除等管理。
Notebook server 对 notebook 的存储是通过 FileManager 来实现的,FileManager 主要负责 ipynb 的创建、保存、删除、重命名等文件操作,另外还会进行 ipynb 文件的 format 检查以保证格式正确。
FileManger 保存文件是通过 local filesystem 实现的。为了持久化存储 ipynb 文件,我们在 FileManager 中嵌入了 tos 文件存储的功能。具体过程为:
- 首次创建时,在本地生成 ipynb 后,并往 tos 上 put 一份;
- 每次更新保存时,在本地更新后往 tos put 一份;
- 每次打开 ipynb 时,首先判断本地是否存在对应的 ipynb 文件,如果不存在则从 tos 拉取;如果存在则不做拉取操作;
- 删除操作只是删除了本地的文件,没有删除 tos 的那份。
kernel 管理
当我们在页面上打开一个 notebook 任务时,notebook server 会尝试启动一个 kernel 来执行你点击运行的代码。火山引擎DataLeap上每个 task 都和一个 kernel 对应,notebook server 负责维护每个任务的 kernel。
Notebook server 是通过 KernelManager 来维护 kernel 信息的,KerneManager 负责 kernel 的启动、重启、删除等操作。
默认情况下,Kernel 是启动在 notebook server 所在的运行容器里,这种情况下单个 server 里无法支撑起大规模 kernel。
代理
如上一节所述,notebook server local 模式不支持大规模 kernel 的扩展,适用于小范围使用,主要原因有如下两点;
- kernel 都是在 notebook server host 内启动的,单机必然无法容纳大规模 kernel ;
- Kernel 间没有隔离,只是进程间的隔离,资源 & 执行环境等没有很好的隔离与定制化;
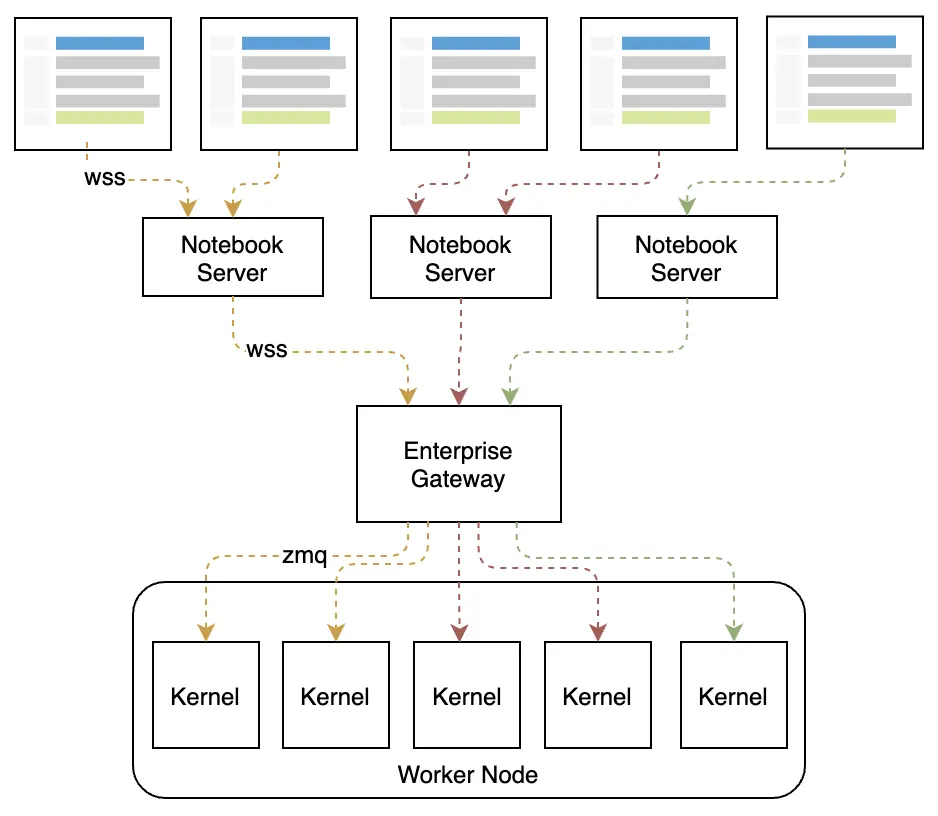
Enterprise kernel gateway (简称 EG)主要致力于解决上述问题,采用了 EG 的系统架构如下所示:
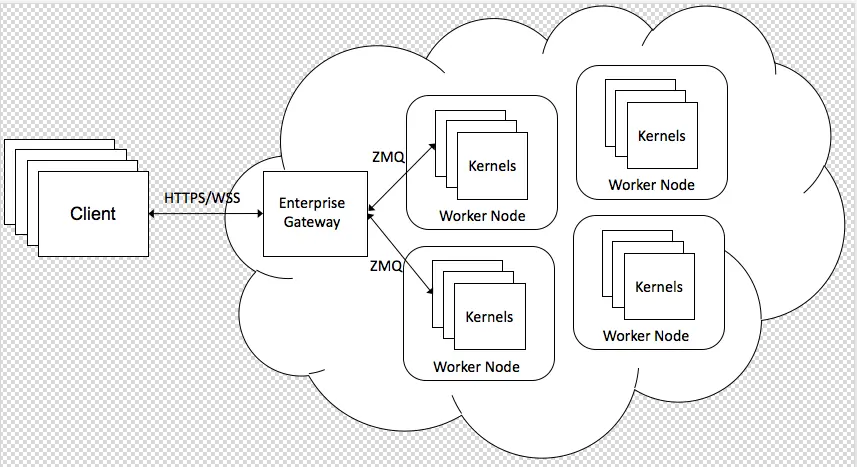
技术上来讲,EG 部分扩展了 notebook server 的功能,然后作出了如下改动:
- 复用 notebook server 中的 API (kernel 管理部分);
- 提供了 WS 的管理;
- 基于 notebook server 中 MultiKernelManager & KernelManager & SessionManager,做出扩展,提供了 RemoteMappingKernelManager;
从图中可以看出,client 并非是 notebook 相关的系统,也可以是其他系统,这意味着可以直接把 EG 当成 Code Execution Server,只需要其 ws client 遵循 Jupyter msg protocol。
代理架构
在 火山引擎DataLeap notebook 系统中,上图中的 client 即为 notebook server,此时 notebook server 只负责管理 notebook 文件(创建、读写、保存、删除),kernel 部分的操作全部转发给 EG 进行处理(注意这里的转发包含 http 转发与 ws 转发)。详细如下图所示:
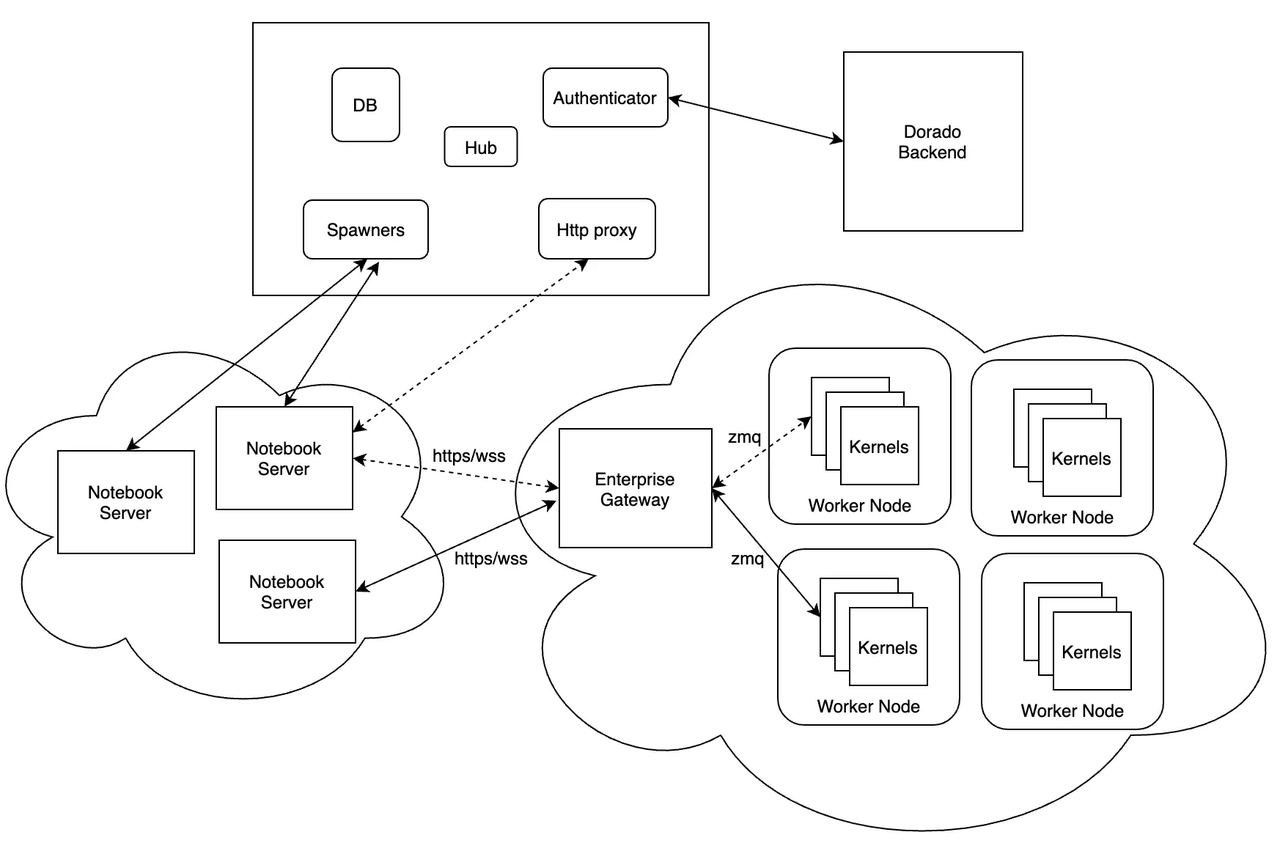
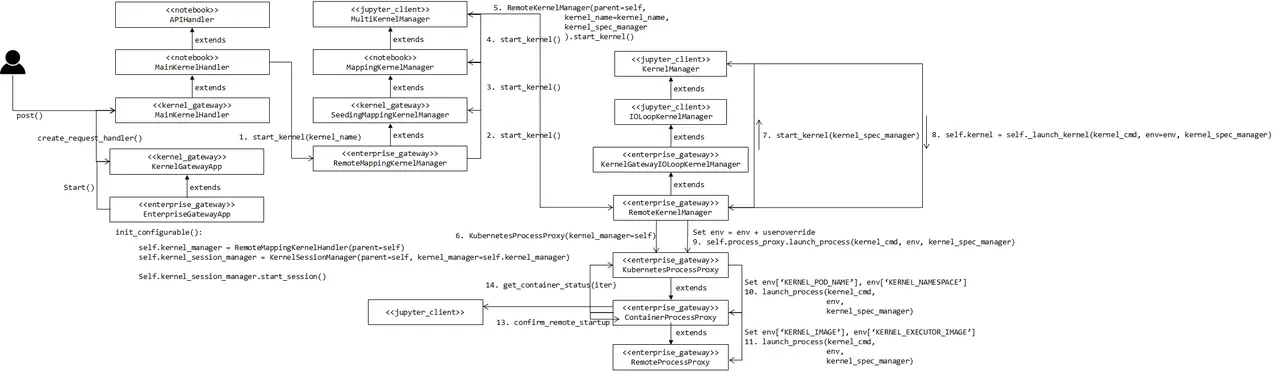
用户在浏览器运行一段代码,整个交互流程如下图所示:
EG proxy 的详细过程参考:
当前 EG 支持往 yarn、k8s 等业界常用资源管理系统提交 kernel 。 我们当前只支持 remote kernel on yarn ,后续考虑支持 k8s。
远程 Kernel
1、Remote kernel on yarn
开源 EG 往 yarn 上提交任务主要是使用 yarn_client,该 client 基于 yarn rm restful api 进行资源探查 & 任务的提交 & 状态轮询 & kill 等操作。公司内并非开放相应的 rest api,因此需要基于 YAOP 进行相应的改造。
2、Kernel configuration
开源 EG 往 yarn 上提交任务暂不支持指定动态参数,比如队列选择、镜像选择等等 yarn 参数。 我们进行了简单的改造,可以支持用户设置更为丰富的 yarn 参数,来定制个性化执行环境。
3、Async
开源社区的版本没有完全异步化,为了单 eg server 支持更多的 kernel,我们做了完全的异步化改造。 优化前,只能支持 10+ kernel,优化后,能够支持 100+ kernel(上限没具体测试过)。
4、image
支持用户选择自定义镜像启动 kenrel,该特性支持用户在 kernel 中安装自己需要的环境,极大地提高了 kernel 使用的场景。
定时调度
调度原理
Notebook 调度执行不同于每个 cell 里的人工调试执行,它需要定时自动执行,每次都是直接 run all cell,并且把执行结果保存在 notebook 里。
Jupyter 提供了可以直接执行一个 ipynb 文件的工具:nbconvert。nbconvert 会根据 ipynb 里的 kernel 信息启动对应的 kernel 来执行 ipynb 里的每个 cell,其本质上执行了 notebook kernel 启动 + run each cell 的功能。
但是 nbconvert 只能启动 local kernel,而目前系统是 remote kernel on yarn,这可以通过把 nbconvert 提交到 yarn 上,然后在 yarn 上运行上述过程。当然,这其中涉及到了 pyspark 任务的提交原理,总的来说,notebook 任务具备和 dorado 上其他任务一样的定时调度功能。
更多特性
1、Version control 支持 notebook 的版本控制。
2、Workflow debug 工作流支持 notebook 任务,并且支持整体调试。
3、Parameterized 支持 notebook 参数化。
4、Executed notebook view 支持定时调度运行结果展示。
结束语
Jupyter Notebook 诞生至今,已数年有余,期间不断出现 Zeppelin、PolyNote、Deepnote。尽管如此, Jupyter Notebook 仍然拥有最大量的用户群体与比较完整的技术生态,因此我们选择了 Jupyter Notebook 做深度定制与改造来服务用户。
当前 火山引擎DataLeap Notebook 已经基本具备了离线数据探索的能力,这些能力已经帮助了很多用户更好的进行数据探索、任务开发调试、可视化等。随着平台对流式数据开发的支持,我们也希望借助 Notebook 实现用户对流式数据的探索、流式任务的调试、可视化等功能的需求。相信不久的将来,Notebook 能够实现流批一体化,来服务更加广泛的用户群体。
点击跳转大数据研发治理套件 DataLeap了解更多
