;
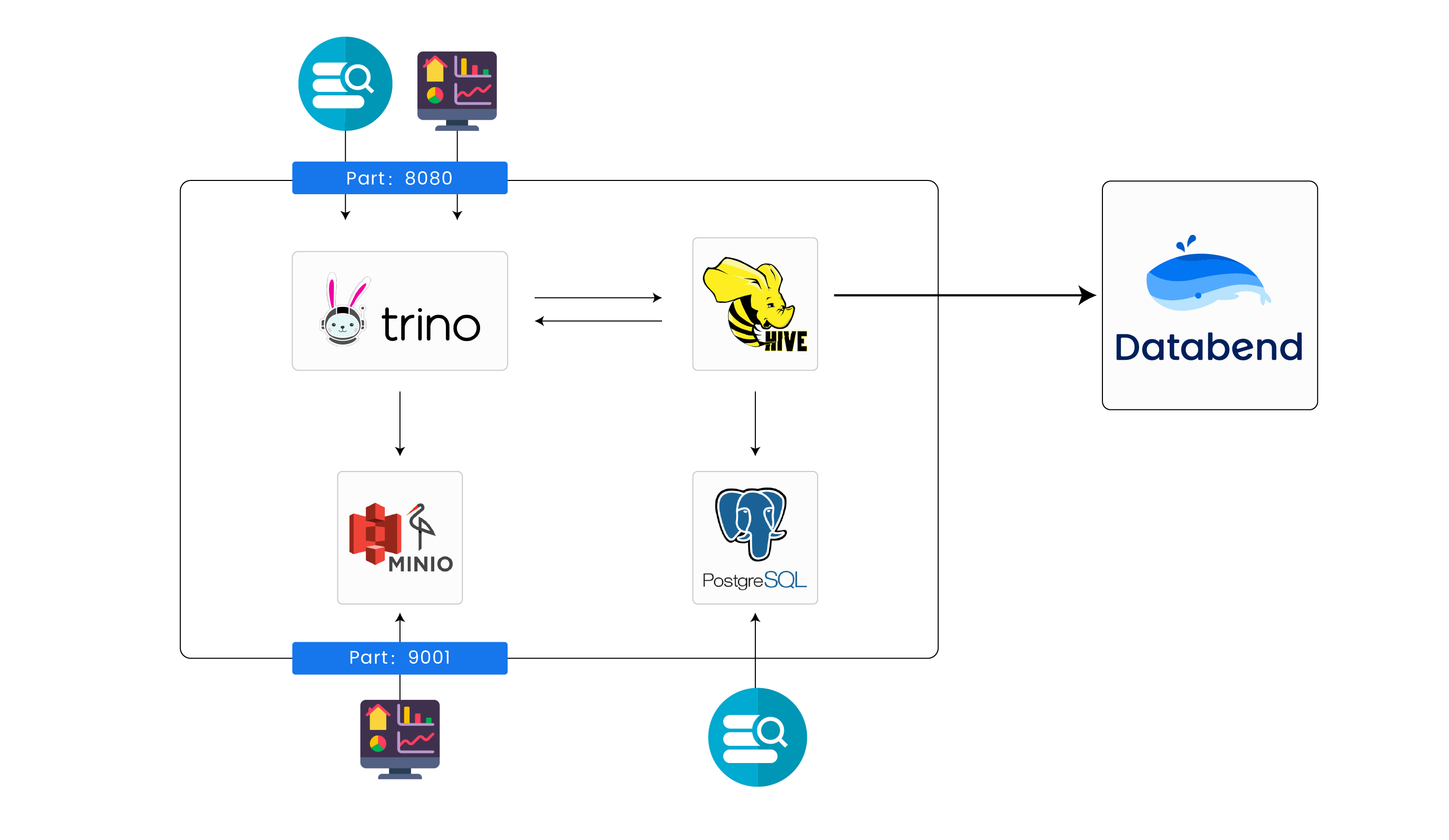
通过这种形式,用户无需向 Databend 中导入数据,就可以直接查询位于 Hive/Iceberg Catalog 中的数据,并获得 Databend 的性能保证。
Workshop :使用 Databend 加速 Hive 查询
接下来,让我们通过两个例子,了解 Databend 是如何加速不同存储服务下的 Hive 查询的。
使用 HDFS 存储
Hive + HDFS 的实验环境可以使用 https://github.com/PsiACE/databend-workshop/tree/main/hive-hdfs 中的环境搭建
docker-compose up -d
接下来,让我们一起准备数据:
- 进入 hive-server ,使用 beeline 连接:
docker-compose exec hive-server bash
beeline -u jdbc:hive2://localhost:10000
- 创建数据库、表和数据,注意,需要以 Parquet 格式存储:
CREATE DATABASE IF NOT EXISTS abhighdb;
USE abhighdb;
CREATE TABLE IF NOT EXISTS alumni(
alumni_id int,
first_name string,
middle_name string,
last_name string,
passing_year int,
email_address string,
phone_number string,
city string,
state_code string,
country_code string
)
STORED AS PARQUET;
INSERT INTO abhighdb.alumni VALUES
(1,"Rakesh","Rahul","Pingle",1994,"rpingle@nps.gov",9845357643,"Dhule","MH","IN"),
(2,"Abhiram","Vijay","Singh",1994,"asingh@howstuffworks.com",9987654354,"Chalisgaon","MH","IN"),
(3,"Dhriti","Anay","Rokade",1996,"drokade@theguardian.com",9087654325,"Nagardeola","MH","IN"),
(4,"Vimal","","Prasad",1995,"vprasad@cmu.edu",9876574646,"Kalwadi","MH","IN"),
(5,"Kabir","Amitesh","Shirode",1996,"kshirode@google.co.jp",9708564367,"Malegaon","MH","IN"),
(6,"Rajesh","Sohan","Reddy",1994,"rreddy@nytimes.com",8908765784,"Koppal","KA","IN"),
(7,"Swapnil","","Kumar",1994,"skumar@apache.org",8790654378,"Gurugram","HR","IN"),
(8,"Rajesh","","Shimpi",1994,"rshimpi@ucoz.ru",7908654765,"Pachora","MH","IN"),
(9,"Rakesh","Lokesh","Prasad",1993,"rprasad@facebook.com",9807564775,"Hubali","KA","IN"),
(10,"Sangam","","Mishra",1994,"smishra@facebook.com",9806564775,"Hubali","KA","IN"),
(11,"Sambhram","Akash","Attota",1994,"sattota@uol.com.br",7890678965,"Nagpur","MH","IN");
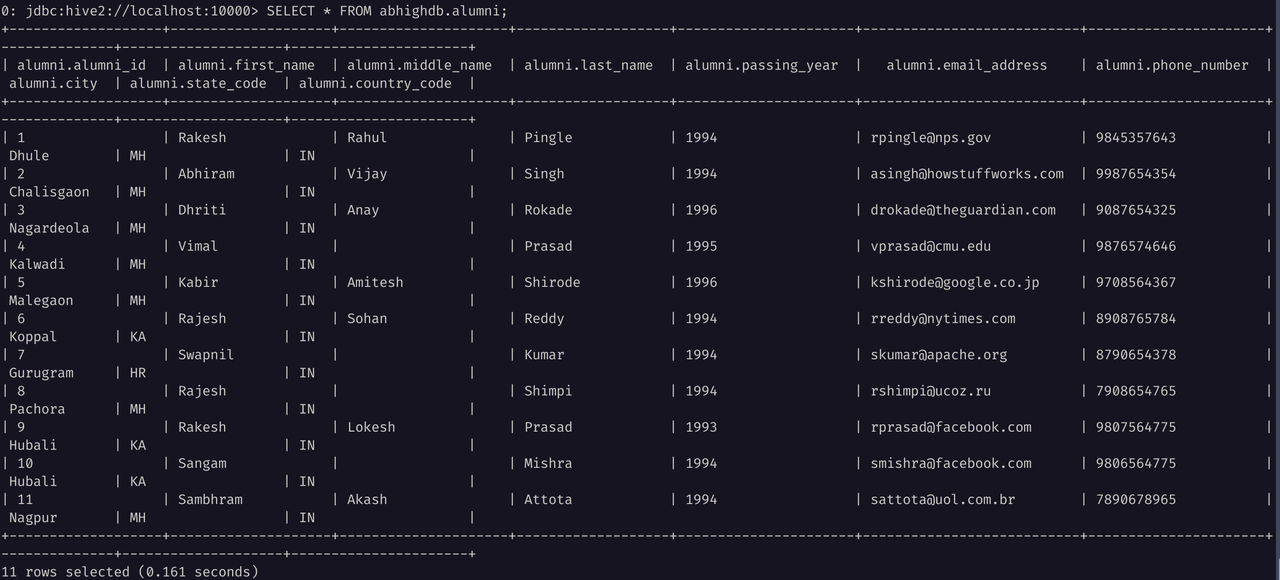
SELECT * FROM abhighdb.alumni;
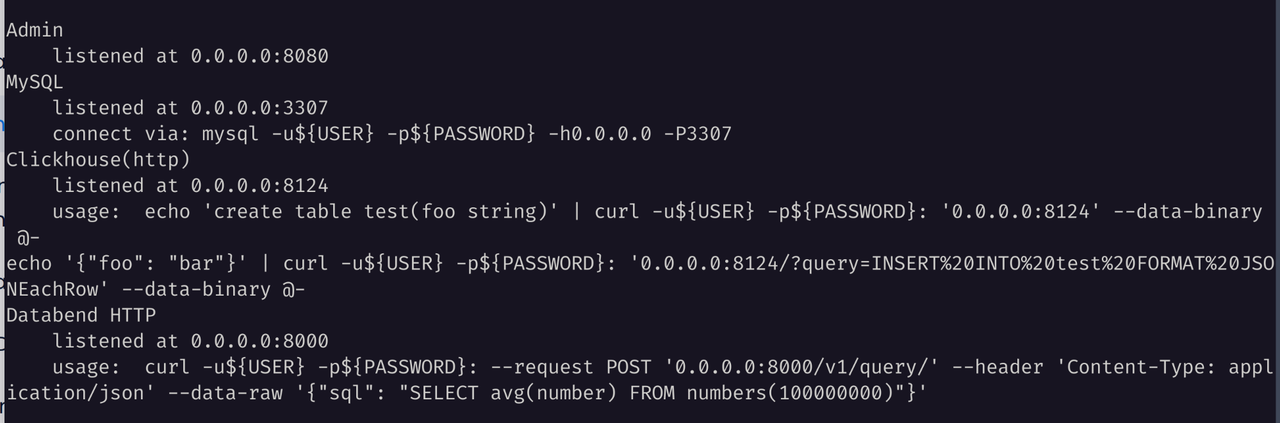
由于 HDFS 支持需要使用 libjvm.so 和 Hadoop 的若干 Jar 包,请确保你安装了正确的 JDK 环境并配置相关的环境变量:
export JAVA_HOME=/path/to/java
export LD_LIBRARY_PATH=${JAVA_HOME}/lib/server:${LD_LIBRARY_PATH}
export HADOOP_HOME=/path/to/hadoop
export CLASSPATH=/all/hadoop/jar/files
参考 Deploying a Standalone Databend ,使用带有 HDFS 特性的 Databend 分发(databend-hdfs-*),部署一个单节点的 Databend 实例。
通过 BendSQL 连接这个 Databend 实例,然后创建对应的 Hive Catalog ,记得要通过 CONNECTION 字段为其配置对应的存储后端:
CREATE CATALOG hive_hdfs_ctl TYPE = HIVE CONNECTION =(
METASTORE_ADDRESS = '127.0.0.1:9083'
URL = 'hdfs:///'
NAME_NODE = 'hdfs://localhost:8020'
);
在上面的语句中,我们创建了一个底层存储使用 HDFS 的 Hive Catalog:
让我们尝试运行一个简单的 SELECT 查询,验证其是否能够正常工作:
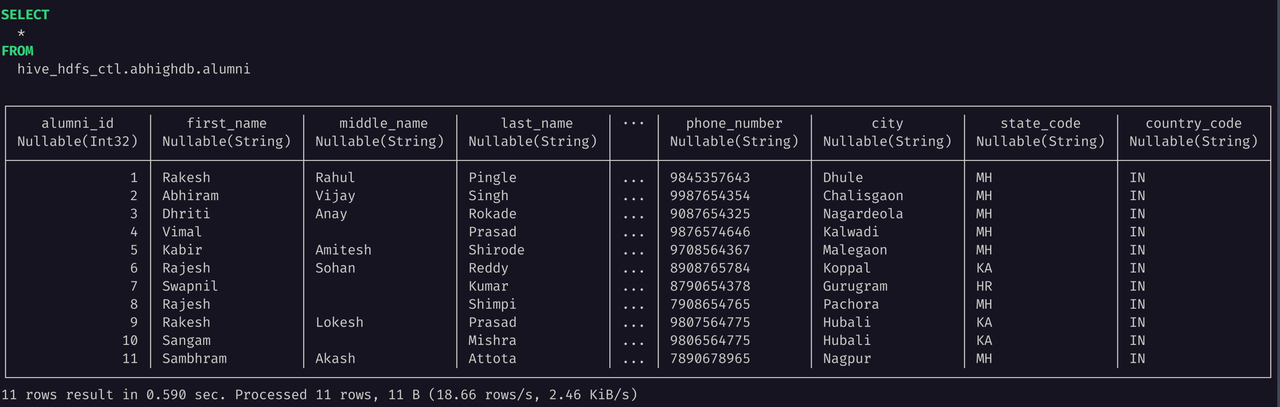
SELECT * FROM hive_hdfs_ctl.abhighdb.alumni;
使用 S3-like 对象存储
Trino + Hive + MinIO 的实验环境可以使用 https://github.com/sensei23/trino-hive-docker/ 进行搭建。
cd docker-compose
docker build -t my-hive-metastore .
docker-compose up -d
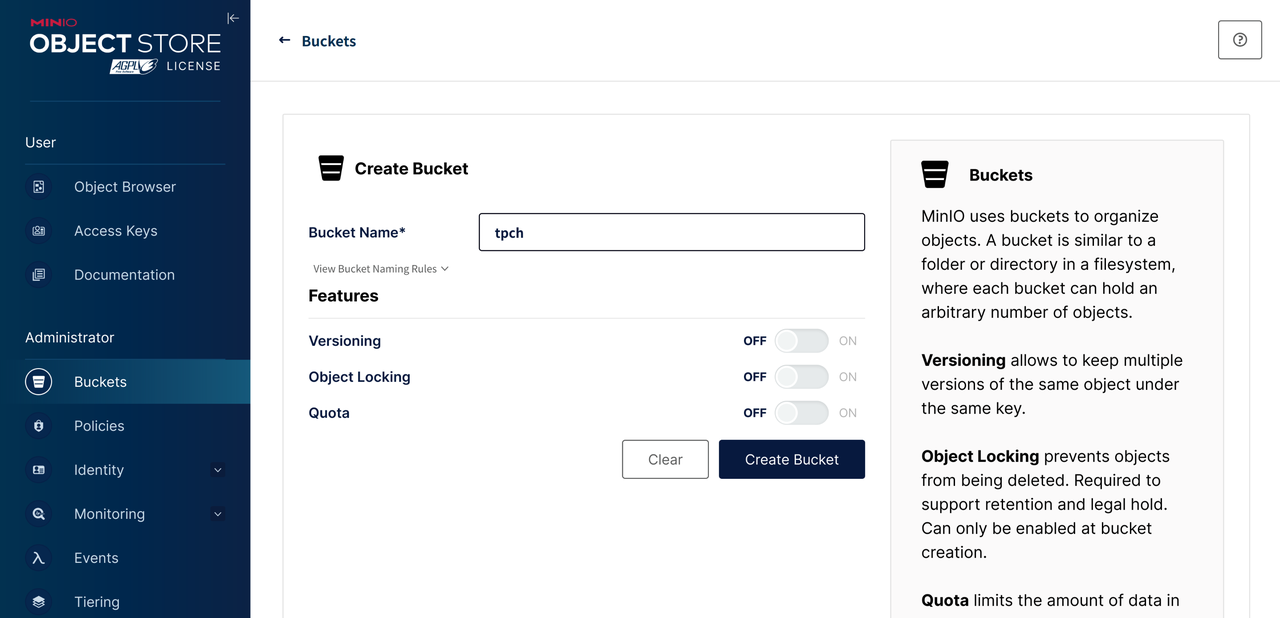
在执行完 docker-compose up -d 等前置步骤后,先进入 MinIO 控制面板,创建一个名为 tpch 的 Bucket 。
运行下述命令可以打开 trino 命令行工具:
docker container exec -it docker-compose-trino-coordinator-1 trino
接着创建一个小型的 TPCH 客户表。注意,为了满足 Databend 使用要求,这里需要使用 Parquet 格式:
CREATE SCHEMA minio.tpch
WITH (location = 's3a://tpch/');
CREATE TABLE minio.tpch.customer
WITH (
format = 'PARQUET',
external_location = 's3a://tpch/customer/'
)
AS SELECT * FROM tpch.tiny.customer;
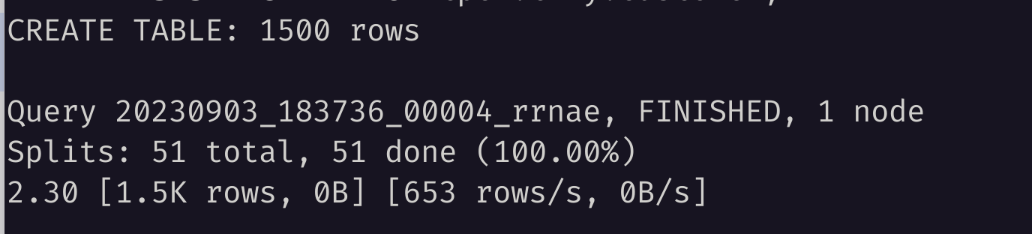
查询对应的 Hive 元数据,可以看到像下面这样的信息:
DB_ID | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE | CTLG_NAME
-------+---------------------------+----------+------------+------------+-----------
1 | file:/user/hive/warehouse | default | public | ROLE | hive
3 | s3a://tpch/ | tpch | trino | USER | hive
参考 Deploying a Standalone Databend 部署一个单节点的 Databend 实例。
通过 BendSQL 连接这个 Databend 实例,然后创建对应的 Hive Catalog ,记得要通过 CONNECTION 字段为其配置对应的存储后端:
CREATE CATALOG hive_minio_ctl
TYPE = HIVE
CONNECTION =(
METASTORE_ADDRESS = '127.0.0.1:9083'
URL = 's3://tpch/'
AWS_KEY_ID = 'minio'
AWS_SECRET_KEY = 'minio123'
ENDPOINT_URL = 'http://localhost:9000'
);
在上面的语句中,我们创建了一个底层存储使用 MinIO 的 Hive Catalog:
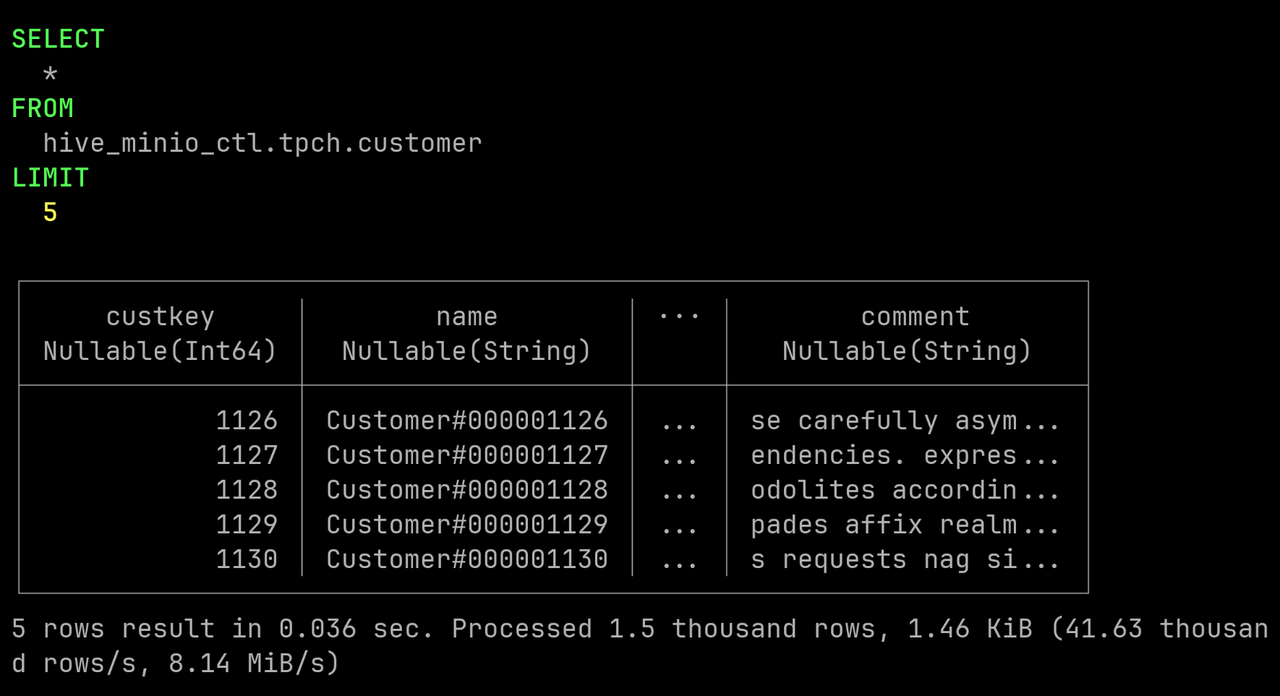
让我们尝试运行一个简单的 SELECT 查询,验证其是否能够正常工作:
SELECT * FROM hive_minio_ctl.tpch.customer LIMIT 5;
提示
- 要使用 SQL 语句创建带有多种存储支持的 Hive Catalog,推荐使用 v1.2.100-nightly 及以后版本。
- 不再需要从 toml 文件进行配置就可以获得多源数据目录能力。
- 如果需要获取 HDFS 存储服务支持,则需要部署或者编译带有 HDFS 特性的 Databend ,比如 databend-hdfs-v1.2.100-nightly-x86_64-unknown-linux-gnu.tar.gz 。
- 对于 Hive Catalog ,Databend 目前只支持查询 Parquet 格式的数据,且只支持 SELECT,不支持其他 DDL 、DML 和 UDFs 。
- Databend 的语法与 Hive 并不完全兼容,关于 SQL 兼容性相关的内容,可以查看 Docs | SQL Conformance 。
展开阅读全文
PHP、.NET 和 Java 到底谁遥遥领先,看评论区见高低!
Svelte 造了个“新轮子”—— runes
Windows 版 AI Copilot 将于 9 月 26 日推出
思科 280 亿美元收购 Splunk
网易国产开源分布式存储系统 —— Curve
OpenAI 发布 DALL-E 3,支持使用 ChatGPT 生成提示词
Netty 4.1.98.Final 发布,Java 网络应用框架
国内首家!阿里云 Elasticsearch 8.9 版本释放 AI 搜索新动能
Jenkins 使用不安全权限创建临时插件
MyBatis-Flex v1.6.6 发布,已支持 JDK 21
开源免费的低代码平台 — JeecgBoot v3.5.5 版本发布,性能大升级版本
开源免费的低代码报表 — JimuReport 积木报表 v1.6.2 版本正式发布
开源 MQTT GUI 客户端 MqttInsight 发布 v1.0.1
Go 1.22 将修复 for 循环变量错误
Bee 2.1.8 支持多表增删改,自动生成带 Swagger 的 Javabean(更新 Maven)
百灵快传(B0Pass)大文件传输工具 v2.0.2 - 百灵快传专用安卓 App 发布
Linux 内核 LTS 期限将从 6 年恢复至 2 年
ModStartCMS v7.3.0,富文本 MP3支持,后台组件优化
英伟达的 AI 霸主地位会持久吗?
deepin 官宣正式接入大模型
开源之夏 2023 | 欢迎报名openEuler sig-Compatibility-Infra和sig-CICD开发任务
一步到位,详解 Milvus 2.3
首添机密计算创新成果!龙蜥首获 ACM SIGSOFT 杰出论文奖
大模型升级与设计之道:ChatGLM、LLAMA、Baichuan及LLM结构解析
快来看看多样性计算领域有哪些SIG报名参加SIG组开放工作会议吧!
AIGC 加持 Cocos,游戏开发需要几步?
不方便在Gitee上提交PR?你还可以这样提交代码
大淘宝技术斩获NTIRE 2023视频质量评价比赛冠军(内含夺冠方案)
如何在 Jupyter Notebook 用一行代码启动 Milvus?
安全日报(2023.03.31)
CVE-2023-42442:JumpServer未授权访问漏洞通告
阿里云 MSE + ZadigX ,无门槛实现云原生全链路灰度发布
在线找 K8s 学习搭子,急!
适配各类大模型应用!手把手教你选择 Zilliz Cloud 实例类型
Solon2 forward 和 redirect 的区别
Oracle中如下用于创建PRODUCTS表的SQL语句,以下哪个陈述是正确的?
实时数仓浪潮来袭,这些宝藏开源CDC工具助您破壁 | StoneDB数据库观察 第9期
每日好店——店品排序探索模型升级
议题征集|Flink Forward Asia 2023 正式启动
波司登云原生微服务治理探索
基于阿里云 Serverless 容器服务轻松部署企业级 AI 应用
白鲸调度系统助力国内头部券商打造国产信创化 DataOps 平台
盘点!国内隐私计算学者在 USENIX Security 2023 顶会上的成果
CVE-2023-37582:Apache RocketMQ 远程代码执行漏洞通告
LLM 落地电商行业的最佳实践来了?Zilliz X AWS 有话说
大咖来啦!6月30日ACDU 中国行 · 深圳站不见不散
探索 Hertz 中间件:用法、生态及实现原理
Open Payment Platform——基于 CloudWeGo 实现 API Gateway
精彩回顾|湖南大学openEuler技术小组成立!共话嵌入式技术创新未来
春去夏来,火热发版:StoneDB-8.0-v1.0.1-beta 版本正式发布!
Epinio:Kubernetes 的应用程序开发引擎
每周新闻—2023年4月19日
ZadigX 与 Apollo 结合,智能配置管理新解法
安全日报(2023.08.28)
一次解决三大成本问题,升级后的 Zilliz Cloud 如何造福 AIGC 开发者?
用户案例 | 蜀海供应链基于 Apache DolphinScheduler 的数据表血缘探索与跨大版本升级经验
限时福利|“5.20”溪塔记录属于元宇宙的时间与故事
免费、安全、可靠!一站式构建平台 ABS 介绍及实例演示 | 龙蜥技术
2023大淘宝技术工程师推荐书单
DPU 厂商大禹智芯加入龙蜥社区,共建领先的 IT 基础设施
基于组合优化的3D家居布局生成看千禧七大数学难题之NP问题
oepkgs 社区开放软件包服务正式上线!亮相openEuler Developer Day 2023
《区块链+》系列技术报告发布 赋能“星火·链网”规模化发展
我借助AI神器,快速学习《阿里的Java开发手册》,比量子力学还夸张
数据仓库、数据集市、数据湖,你的企业更适合哪种数据管理架构?
阿里云 MSE 助力开迈斯实现业务高增长背后带来的服务挑战
开放原子基金会的导师和项目---双向奔赴,相互成就
日增320TB数据,从ClickHouse迁移至ByConity后,查询性能十分稳定!
基于AIGC的3D场景创作引擎概述
寻找注册配置中心最佳评测官,赢取丰厚奖品 | 测评开启,开发者请速速集结
openEuler Developer Day 2023成功召开!发布嵌入式商业版本及多项成果
SeaTunnel StarRocks 连接器的使用及原理介绍
数据库厂商智臾科技加入龙蜥社区,打造多样化的数据底座
数据库厂商云和恩墨加入龙蜥社区,打造安稳易用的 IT 运行环境
龙蜥白皮书精选:开源 RISC-V 技术支持软硬件全栈平台
Spring Boot自动配置原理详解和自定义封装实现starter
CVE-2023-32233:Linux Kernel 权限提升漏洞通告
使用 OpenTelemetry 构建可观测性 06 - 生态系统
我是 Zadig GPT 万能助手:我的名字叫 Pilot 猫
阿里云蝉联 Forrester FaaS 领导者象限丨云原生 7 月产品技术动态
preCICE耦合方案介绍(一)
龙蜥社区用户案例征集开始啦,欢迎投稿!
判断题 | pg数据库中,命令c可以切换数据库
拈花云科基于 Apache DolphinScheduler 在文旅业态下的实践
Last Week in Milvus
一文了解openEuler Developer Day2023亮点!
助力产教融合, Cocos 出席北理工虚拟交互艺术设计教学成果展
安全日报(2023.05.19)
Flink MongoDB CDC 在 XTransfer 的生产实践|Flink CDC 专题
API7 助力头部券商实现数字化转型
在oracle中,哪种操作符返回两个查询所选定的不重复的行?
PostgreSQL 每周新闻 2023-5-31
这款产品,竟然用了几千年才爆火
Oracle数据库当创建控制文件的时候,数据库一定要?
安全日报(2023.09.11)
新老用户看过来~最实用的 Milvus 迁移手册来啦!
WhaleStudio 完成与偶数科技云原生分布式数据库 OushuDB 的产品兼容性认证
如果想让优化器首先访问T2,之后在关联T1。可以通过下面哪种写法?
云原生时代的流量发动机
时速云使用 Higress 替换 Ngnix Ingress + Spring Cloud Gateway 的生产实践
©OSCHINA(OSChina.NET)
工信部
开源软件推进联盟
指定官方社区
社区规范
深圳市奥思网络科技有限公司版权所有
粤ICP备12009483号
.codeBlock:hover .oscCode{display: block !important;} .codeBlock{z-index: 2;position: fixed;right: 20px;bottom: 57px; overflow: hidden; margin-bottom: 4px;padding: 8px 0 6px;width: 40px;height: auto;box-sizing: content-box;cursor: pointer;border: 1px solid #ddd;background: #f5f5f5;text-align: center;transition: background 0.4s ease;}
@media only screen and (max-width: 767px){ .codeBlock{display: none;}}
/*
html{
-webkit-filter: grayscale(100%);
-moz-filter: grayscale(100%);
-ms-filter: grayscale(100%);
-o-filter: grayscale(100%);
filter:progid:DXImageTransform.Microsoft.BasicImage(grayscale=1);
_filter:none;
}
*/
(function(){
var bp = document.createElement('script');
var curProtocol = window.location.protocol.split(':')[0];
if (curProtocol === 'https'){
bp.src = 'https://zz.bdstatic.com/linksubmit/push.js';
}
else{
bp.src = 'http://push.zhanzhang.baidu.com/push.js';
}
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();
var _hmt = _hmt || [];
_hmt.push(['_requirePlugin', 'UrlChangeTracker', {
shouldTrackUrlChange: function (newPath, oldPath) {
return newPath && oldPath;
}}
]);
(function() {
var hm = document.createElement("script");
hm.src = "https://hm.baidu.com/hm.js?a411c4d1664dd70048ee98afe7b28f0b";
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();
{
"@context": "https://ziyuan.baidu.com/contexts/cambrian.jsonld",
"@id": "https://my.oschina.net/u/5489811/blog/10112566",
"appid": "1653861004982757",
"title":"使用 Databend 加速 Hive 查询 - Databend的个人空间",
"images": ["https://oscimg.oschina.net/oscnet/up-33fea8bdaf55ae1c1c0bdb0ff3d3907d618.png"],
"description":"作者:尚卓燃(PsiACE) 澳门科技大学在读硕士,Databend 研发工程师实习生 Apache OpenDAL(Incubating) Committer https://github.com/PsiACE 随着架构的不断迭代和更新,大数据系统的查询目标也从大吞吐量查询逐...",
"pubDate": "2023-09-21T17:54:00+08:00",
"upDate":"2023-09-21T17:54:00+08:00",
"lrDate":""
}
<!--
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', 'G-TK89C9ZD80');
-->
window.goatcounter = {
path: function(p) { return location.host + p }
}
(function(){
var el = document.createElement("script");
el.src = "https://lf1-cdn-tos.bytegoofy.com/goofy/ttzz/push.js?2f2c965c87382dadf25633a3738875e5ccd132720338e03bf7e464e2ec709b9dfd9a9dcb5ced4d7780eb6f3bbd089073c2a6d54440560d63862bbf4ec01bba3a";
el.id = "ttzz";
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(el, s);
})(window)
// 动弹话题页面描述加链接
$(function () {
const el = $('.www-tweet .tweet-form-header .topic-desc');
if (el && el.length > 0) {
const desc = el.html();
el.html(desc.replace(/http(s?)://[wd-./?=]+/, url => `${url}`));
}
});


























































点击引领话题📣
发布并加入讨论🔥