


阿里云ODPS系列产品以MaxCompute、DataWorks、Hologres为核心,致力于解决用户多元化数据的计算需求问题,实现存储、调度、元数据管理上的一体化架构融合,支撑交通、金融、科研、等多场景数据的高效处理,是目前国内最早自研、应用最为广泛的一体化大数据平台。
本期将重点介绍
ꔷ Hologres推出计算组实例
ꔷ Hologres支持JSON数据
ꔷ Hologres向量计算+大模型能力
ꔷ Hologres数据同步新能力
ꔷ Hologres数据分层存储
新功能—Hologres推出计算组实例
计算组实例支持将计算资源分解为不同的计算组,更好的服务于高可用部署。
应用场景:
- 资源隔离: 针对不同企业场景间相互影响带来查询抖动,例如写写之间、读写之间、大小查询间的相互影响,以及在线服务、多维分析、即席分析等之间的相互影响;某些大数据引擎并不是存算分离架构通过复制多副本去实现隔离等高成本业务场景。
- 高可用能力: 针对无服务级高可用、 容灾和多活的方案,企业通过双/多链路来实现高可用、容灾和多活,其中涉及人力、计算资源等高成本业务场景。
- 灵活扩缩容 : 针对企业对业务灵活能力的高诉求:业务流量突然增长能及时扩容扛住流量,在业务低峰时能及时缩容,减少业务资损,降低成本。
功能特性:
- 天然物理资源隔离: 每个计算组之间是天然的物理资源隔离,企业使用可避免计算组之间的相互影响,减少业务抖动等。
- 按需灵活扩缩容: 计算和存储高度可扩展,具有双重弹性,企业可按时或按需拉起(Scale Out);按需热扩缩容(Scale Up)。
- 降低成本: 基于物理Replication实现,物理文件完全复用,企业可按需弹性使用资源,成本可控制到最低 。
产品Demo演示-计算组实例
跳转Hologres控制台,通过SQL创建新计算组并赋予对应的Table group(数据)权限——更改计算组,innit warehouse更改为刚创建的read warehouse——执行查询,整个负载就转到read warehouse上。同时可以按需去启停计算组,停止或者启动操作都可以使用SQL实现,也可以在界面上通过可视化的去操作。同时也能够按需调整计算组的资源,可以在页面可视化操作或者使用CPO去操作——在计算组不需要使用时及时的释放,不占用任何资源。
查看产品Demo视频
新功能—Hologres 支持JSON数据
支持列式JSONB存储,提升查询效率
应用场景:
- 查询效率: 对于半结构化不能提前固定Schema,主要是用行存,在大规模数据计算时,需要扫描大量数据的问题。查询效率要满足企业业务需求。
- 存储效率: 对于无法使用列存的压缩能力,导致压缩率低,存储空间大的问题。存储效率要满足企业业务需求
- 数据处理: 对于半结构化数据的处理过程相对复杂的问题,需要进行数据清洗、提取和转换等操作。需要满足企业更全面的函数支持业务需求。
功能特性:
JSON数据处理方式: JSON作为常见半结构化数据类型,数据处理的方式有两种:
- 导入式,即解析数据结构,将数据按照强schema的方式进行存储。这种方式的优势在于存储到数据库时已经是强schema的数据,对于查询性能和存储性能都较好。缺点在于解析过程中,都需要在加工过程中去把数据转化成强scheme,丧失了JSON数据的灵活性。如果JSONkey新增或者减少,则需要修改解析程序。
- 另一种方式是直接将这一层数据写入数据库,查询时用JSON函数做解析。这种方式的优势在于最大程度的保留了JSON数据的灵活性,劣势在于查询性能不佳,每次选用适合的处理函数和方法,开发复杂。
针对JSON数据处理方式,Hologres优化JSON数存储能力,可以按照其劣势的方式存储。JSON数据系统会根据写入的key和value值推导出可以存储的数据类型。
- 灵活易用: 有别于方案1的提前将数据强Schema化, 最大程度保留了JSON数据的灵活性。
- 压缩率高: 使用列式存储,能够有效提升压缩率,节约存储空间。
- 查询性能强: 使用列式存储,减小扫描数据,提高IO效率, 提升查询效率。
产品Demo演示-列式JSON功能
基于以JSON形式存储的公开样例数据,其中包含JSON形式存储的key value的这种数据,每一行都会有key和value用来表示不同的业务含义。——使用这一段C口去查询每年每月关闭的issue的数量,系统开始执行——传统的这种执行方式和查询方式,一行一行去扫描,把一个个key和value取出来,共耗时55秒。——此时开启数据列存化,结束后即可查询,共耗时1.47秒,查询效率大大提升。
查看产品Demo视频
新能力—Hologres向量计算+大模型能力
高性能向量计算,结合大模型构建专属知识库
应用场景:
部署企业级大模型知识库难题:
企业进行模型部署时,会存在计算与存储资源、资源弹性、大模型部署等成本高的问题;
业务处理语料时,会存在原始语料处理流程复杂, 语料数据较多时,对向量数据库的写入能力和实时性有较高要求 ,知识库问答QPS较高时,对向量数据库的查询能力有较高要求等需求 ;
企业在大模型知识库搭建时,会遇见流程长、涉及产品多,整体架构串联成本高,架构打通难的问题。
功能特性:
Hologres + Proxima整体优势:
Proxima为达摩院自研向量引擎,稳定性、性能优于Faiss等开源产品。 Hologres与达摩院自研向量引擎Proxima深度集成,提供高PQS、低延时的向量计算服务 。其具体优势为以下三方面:
- 高性能: 通过一体化数仓,提供低延时、高吞吐的在线向量查询服务; 支持向量数据实时写入与更新,写入即可查
- 高易用性: 统一SQL查询接口查询向量数据,兼容PostgreSQL生态; 支持复杂过滤条件向量检索
- 企业级能力: 向量计算与存储资源灵活水平扩展; 支持主从实例架构、计算组实例架构,支持计算资源物理隔离,实现企业级高可用能力
Hologres+PAI部署大模型知识库架构及优势:
架构主要分为三个层级
- 预数据预处理层: 针对原始语料数据,经加载分析形成文本Chunks,再经过Embedding向量化,从而生成语料向量数据,最终写入实时数Hologres中。
- 文本生成层: 针对用户原始问题,首先将问题Embedding成为问题向量,从而Hologres中进行Top K向量检索,
- 最终生成层: Top K语料作为大模型输入,结合大模型其他输入,包括聊天历史、Prompt的最终推理,求解出最后的答案。这里的大模型可以通过机器学习平台派来进行统一部署。
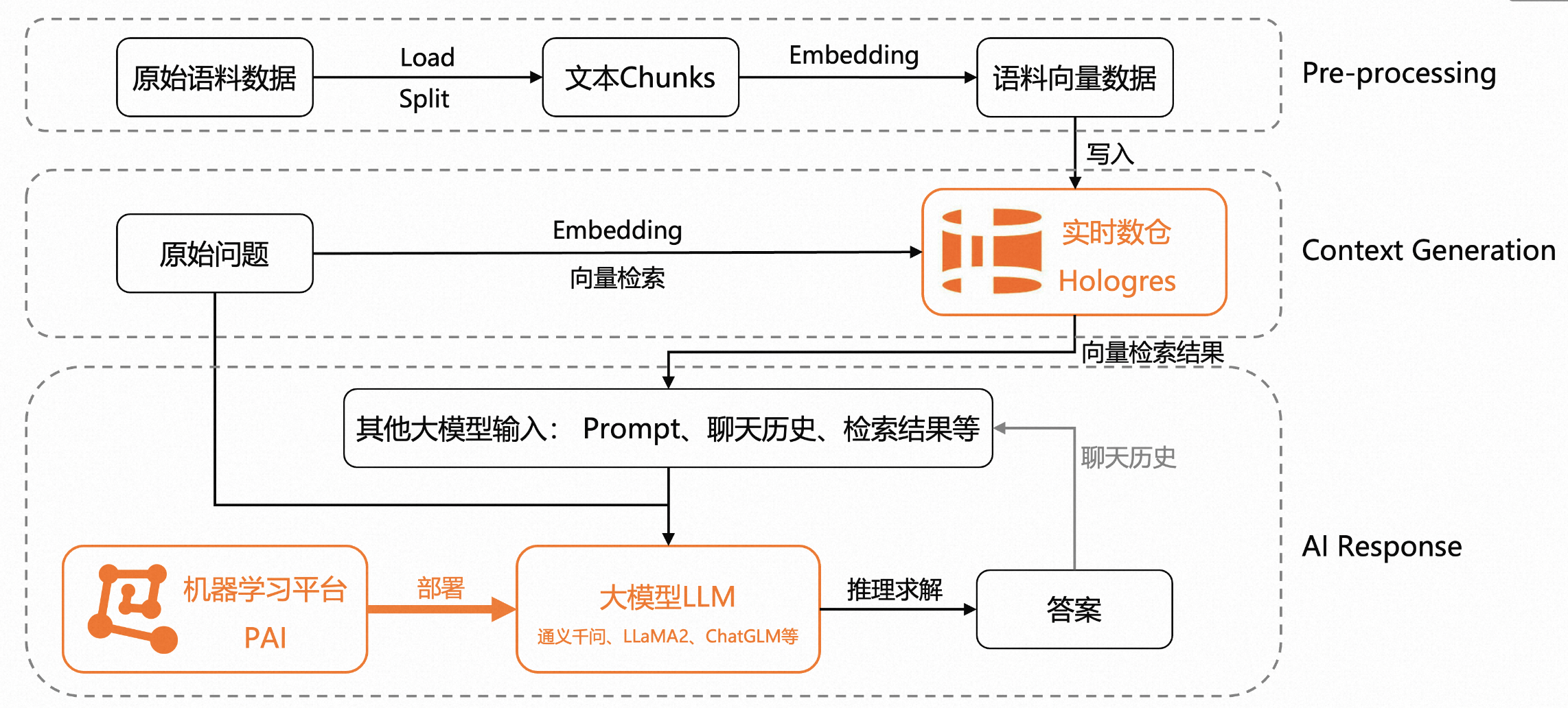
架构优势:
- 简化模型部署: 通过模型在线服务PAI-EAS 一键部署LLM大模型推理服务
- 简化语料处理与查询: 一键语料数据加载、切块、向量化、导入Hologres ;同时基于Hologres低延时、高吞吐向量检索能力,为用户带来更快更好的向量检索服务。
- 一站式知识库搭建: 无需手动串联,在一个平台完成大模型部署、 WebUI部署、语料数据处理、大模型微调。
产品Demo演示-Hologres+PAI部署大模型知识库
开通Hologres实例,在实例的详情页网络信息中记录实例的域。点击登录实例按钮,进入HoloWeb——在原数据管理页面创建一个数据库,并记录数据库户名——点击安全中心,进入用户管理页面,创建自定义用户并授权,同时记录创建用户名与密码——进行大模型的部署工作,可以使用PAI-EAS部署一个LLM大模型,记录大模型调用信息——Demo中使用PAI-EAS部署langchain的WebUI服务,点击查看web应用,可以进入web UI页面。在setting页面中设置Embedding模型,可以设置刚刚部署的LLM大模型,以及Hologres向量存储。上述文件可以通过Json文件一键配置——点击解析,将相关配置信息一键填入。同时点击Connect Hologres测试连通性——进入upload页面进行语料数据的处理。上传语料数据,设置文本切块相关参数,点击upload即可将数据导入Hologres向量表中——返回HoloWeb编辑器进行刷新,语料数据已经作为向量导入到Hologres中。我们回到刚刚的web UI页面,进入Chat页面,先试用原生ChaGLM大模型,询问“什么是Hologres“,结果并不理想——再使用Hologres对大模型进行微调,询问相同问题,结果正确——返回langchain chatbot页面,通过调用信息即可完成上述方案的API调用。
查看产品Demo视频
新能力—Hologres数据同步新能力
新增支持ClickHouse、kafka、Postgres等数据源同步至Hologres
应用场景:
- 同步性能: 企业数据来源多,产生不同数据需求,例如整库同步、全增量同步、分库分表合并、实时同步等;
- 企业搭建数据平台。需要每个数据源去做一定的适配,因此要实现高性能写入,开发同学需要具备一定的同步调优能力。
- 同步成本: 数据来源多,客户端做相应开发会导致开发同学上手成本高;同步性能无法满足业务需求,短时间内不断追加资源,成本随之增加;数据同步时元数据管理难
- 业务运维: 自建数据平台,开发、调试、部署、运维等整个生命周期,全部都是由开发同学去做管理。其整个过程非常繁琐,数据不一致整个链路需要做一一排查,排查成本较高;某点数据出问题,将会涉及数据做回刷,回刷来源不一样,导致运维过程非常困难
功能特性:
Hologres数据同步能力概览
Hologres有着非常开放的生态,支持Flink、DataWorks数据集成、Holo client、JDBC等多种方式将数据同步至Hologres,满足多种业务的数据同步、数据迁移需求,实现更实时、更高效的数据分析和数据服务能力
- Flink全面兼容: 可以实现数据的实时写入维表关联,读取等
- DataWorks数据集成高度适配: 与DataWorks数据集成做高度适配,例如DataWorks支持的各种数据源,基本上都能够支持同步到Hologres中。
- Holo Client、Holo Shipper开箱即用: 可以通过Holo Client来实现高性能的数据检查与高性能点写更新等。同时Holo Shipper可以实现数据的实例的整库的迁移。
- 标准JDBC/ODBC接口: 提供标准JDBC/ODBC接口,开箱即用。
持续演进, Hologres数据同步新能力
为了满足不同业务需要,Hologres不断迭代更新数据同步能力,其新能力具有以下特征:
- ClickHouse整库离线迁移: 其依托于DataWorks数据集成来实现,整体离线迁移分为两大部分:一是元数据自动识别与映射;二是整库数据一次性同步 ,无需如以前一张表写一个任务,大大减少开发运维各种不方便地方,实现ClickHouse 数据快速迁移到Hologres中。
- Kafak实时订阅: Kafak实时订阅可以通过两种方式实现:一是Flink订阅Kafka,实时写入Hologres中,在数仓分层中实现实时数仓的流式ETL;二是通过DataWorks数据集成实时消费Kafka,消息变更自动同步,随之直接自动写入Hologres中,Kafak数据可以实现快速接入。
- PostgreSQL实时同步 : 通过DataWorks数据集成将PostgreSQL数据实时同步到Hologres中,不仅支持单表实时同步,在这基础上也支持DDL能力配置,整库实时同步,库和表结构的自动映射,以及全量和实时增量的数据同步大大减少开发同步难题。
产品Demo演示-ClickHouse整库同步
在DataWorks数据集成界面,配好ClickHouse与Hologres数据源,并对数据源连通性做出检测,检测通过可进行下一步——选择ClickHouse中需要同步的表,选择高级配置,例如独端任务速度,并发度,运行等配置勾选表并一次性同步到Hologres中——目标表的映射,点击批量刷新按钮实现表结构的映射——启动同步任务,等待两分钟左右——数据同步完成后,页面已经刷新,可以根据写入数据条数去对上游数据进行验证,看数据是否都通过——Hologres做数据验证,可以对表做一个简单的查询,查询完成。
查看产品Demo视频
新能力—Hologres数据分层存储
应用场景:
- 电商订单: 近几个月订单高频访问,RT敏感度高 ;历史数据访问频次低,延时不敏感
- 行为分析: 近期流量数据的高频查询,时效性要求高 ;历史数据查询频次低但要求随时可查
- 日志分析: 近期数据高频查询 ;历史数据需长时间保存以保证后续的审计和回溯工
功能特性:
- 标准存储: 标准存储为全SSD热存储,是Hologres默认存储,主要适用于全表数据被频繁访问,且对访问性能有较高要求的场景。
- 低频访问存储: 时间推移访问频度也会降低,而逐渐变为冷数据。例如某些日志数据在今年后不能访问,随之需要将数据从标准存储迁移到低频存储来降低成本,若基于基于规则的自动的数据冷热转换的能力,那我们就会可以大大的降低我们的维护成本,适用于数据体量大,访问频次低,需要减少存储成本的场景
- 分区动态冷热分层: 通过动态分区能力设置冷热分区流转规则,实现分区的动态冷热分层 ;并且冷热分层成本,以北京包年包月为例,它的标准存储是一块钱每GB每月,然后低频保存储是0.144元每GB每月,成本上大概是有七倍的差距。性能上基于标准的TPC至ETB的数据测的测试集的结果来看,大概是有一个3到4倍的一个差距。
产品Demo演示-创建冷存表语句及设置分区表
如Demo中建表语句,在建表的时候设置一个science table property表明,点击运行就可以创建一张冷存表——通过查询HG table storages status这张系统表来看下表的存储策略是否符合预期。——表的进度状态是cold,这是一张存表。对于系统里面已经存在的这种标准存储的热存表,通过单独执行,按照命令,指定表点击运行,设置冷存成功——表的存在状态中数据都已经完整搬迁到冷存低频存储介质里——对于分区表分两大部分来看,第一部分是创建一个普通的分区表的冷存表,那在创建分区表这个语句中同样设置这个表的storage mode ,分区表的分区子表会默认记成库表的存储策略,不需要单独设置。——另一方面想要修改某个分区的属性,在假设我们想要修改某个分区的一个属性,那么在在在在table property指定分区子表的表名,然后设置存储策略,把某一个分区子表改成了我们想要的这个冷热属性。那对于动态分区表,我们需要额外设置一些其他的属性。
查看产品Demo视频
领取Hologres5000CU时免费试用:https://free.aliyun.com/?pipCode=hologram
领取DataWorks免费试用:https://free.aliyun.com/?pipCode=dide
领取MaxCompute5000CU时免费使用:https://free.aliyun.com/?pipCode=odps
