

本文主要是使用 Flex 和 Bison 工具实现一个简单的 SQL 解析器,最终生成抽象语法树!
下面先分别对 Flex 和 Biosn 原理进行介绍,然后给出 SQL 解析器的完整 Demo!
1.输入SQL语句
2. Flex词法分析器
2.1 Flex 原理
1、使用 flex 工具定义正则表达式规则来匹配不同类型的词法单元;例如,可以定义以下规则:
- 匹配关键字:SELECT、FROM、WHERE、HAVING等。
- 匹配标识符:由字母或下划线开头,后跟字母、数字或下划线组成。
- 匹配运算符:比如=、、+、等。
- 匹配常量:包括整数、浮点数、字符串等。
2、生成词法分析器代码:根据定义的词法规则,使用Flex工具生成对应的词法分析器代码;
3、输入查询字符串:将要解析的查询字符串作为输入提供给同法分析器;
4、扫描和匹配:词法分析器从输入字符串中逐个读取字符,并尝试将其与定义的词法规则进行匹配;
5、生成词法单元:当词法分析器匹配到一个词法规则时,它会生成相应的词法单元并返回给语法分析器。每个词法单元通常包含两部分信息:
- 词法单元类型(token type):表示该词法单元的种类,比如关键字、标识符、运算符等;
- 词法单元值(tokenvalue):表示该词法单元具体的取值;
6、继续扫描:词法分析器会持续从输入字符串中读取字符,并重复步骤4和步骤5,直到整个查询字符串被完全解析为一系列词法单元;
7、返回词法单元序列:当整个查询字符串都被解析后,词法分析器将返回一个包含所有词法单元的序列给语法分析器,供后续的语法分析处理;
2.2 Flex 文件代码结构
Flex文件代码如下:
%option noyywrap
%{
definition
%}
%%
rules
%%
Code
(1)%option 指定 flex 扫描时的一些特性。yywrap 通常在多文件扫描时定义使用。常用的一些选项有:
- Noyywrap:告诉flex不使用yywrap函数;
- yylineno:会告诉flex生成一个名为yylineno的整型变量来保存当前的行号;
- case-insensitive 正则表达式规则大小写无关;
(2)definitio部分为定义部分,包括引入头文件,变量声明,函数声明,注释等,这部分会被原样拷贝到输出的.c文件中。
(3)rules部分定义词法规则,使用正则表达式定义词法,后面{}内则是扫描到对应词法时的动作代码;“|”是一个特殊符号,表示下一个模式应用相同的动作;正则表达式后面不指定动作,则相应的模式会被忽略。
(4)code部分为C语言的代码。yylex为flex的函数,使用yylex开始扫描。
2.3 Flex 文件常用变量
(1)yytext:yytext 是 Flex 中的一个全局字符数组,用于存储当前匹配的词法单元的文本。在词法规则中,当匹配到某个模式时,可以通过 yytext 来获取匹配的文本。
(2)yylength:yylength 是 Flex 中的一个全局整数变量,用于存储当前匹配的词法单元的长度。在词法规则中,可以通过 yylength 来获取匹配的文本的长度。
(3)yylval:yylval 是 Bison 中的一个共用联合体(union),用于在词法分析器和语法分析器之间传递值。它可以存储不同类型的值,根据需要进行定义。在词法规则中,可以通过修改 yylval 的值来传递附加信息给语法分析器。
2.4 Flex 文件具体案例
1、创建一个名为 lexer.l 的文件,其中包含词法规则;
%{
#include
%}
%%
SELECT { printf("Keyword: SELECTn"); }
FROM { printf("Keyword: FROMn"); }
WHERE { printf("Keyword: WHEREn"); }
AND { printf("Keyword: ANDn"); }
OR { printf("Keyword: ORn"); }
[0-9]+ { printf("Number: %sn", yytext); }
[A-Za-z_][A-Za-z0-9_]* { printf("Identifier: %sn", yytext); }
[=>2、使用 flex 命令编译 lexer.l 文件,生成词法分析器代码
(1)执行下列语句生成词法分析器代码
flex lexer.l(2)词法分析器生成结果
lex.yy.c(3)编译生成的词法分析器代码,生成可执行文件
gcc -o lexer lex.yy.c -lfl(4)运行可执行文件并输入一些算术表达式进行测试
./lexer
输入:SELECT * FROM table;(5)执行结果如下
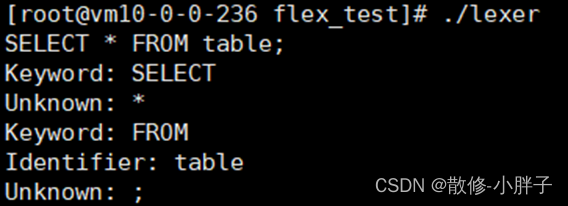
说明:
- -ll: 这是旧版本的Flex生成器(例如Flex 2.5.4)的链接选项。它指示链接器将使用名为 libl.a 或 libl.so 的库文件。在以前的版本中,Flex生成的词法分析器的默认名称是 lex.yy.c,而库文件的名称以 “l” 开头,因此使用 -ll 是一种传统的方式。
- -lg: 这是新版本的Flex生成器(例如Flex 2.5.35)的链接选项。类似于旧版本的 -ll,它指示链接器使用名为 libg.a 或 libg.so 的库文件。这种新方式是为了避免与其他工具和库发生命名冲突。
- -lfl: 这是一个与Flex生成的词法分析器库相关的选项。-lfl 表示链接器将使用名为 libfl.a 或 libfl.so 的库文件。这个库包含了Flex所需的运行时支持函数。
注意:
如果 flex 词法分析器对 .l 进行编译时报错:
/opt/h/devtoolset-11/root/usr/ibexec/gcex86.64-redhat-linux/11/ld: cannot find -lfn
解决方案:
该错误表明链接器无法找到名为 -if 的库文件。这通常是因为在您的系统上缺少libfl库,或者库文件的路径未正确配置。要解决这个问题,您可以尝试以下步骤:
1、确认库是否已安装:首先,请确保您的系统上已安装了libfl库。您可以尝试使用包管理器来安装它。在基于Red Hat的系统中,您可能需要执行类似于以下的命令:
yum install flex-devel2、检查库文件路径:如果库已安装,但链接器仍然找不到它,可能是因为库文件的路径未正确配置。您可以尝试手动指定库文件的路径。例如,假设libfl库文件位于/usr/lib64目录下,您可以使用以下方式链接:
gcc -o my program lex.yy.c -L/usr/lib64 -1f13、更新库文件缓存:如果您最近安装了libfl库,但链接器仍然找不到它,您可能需要更新库文件缓存。运行以下命令以更新库文件缓存:
sudo ldconfig3. Bison语法分析器
Bison(GNU Bison)是一个用于生成语法分析器的工具,它基于Yacc(Yet Another Compiler Compiler)工具的扩展版本。Bison接受一个上下文无关文法作为输入,并生成一个LALR(1)(Look-Ahead LR(1))语法分析器。
3.1 Bison原理
(1)定义文法:使用Bison的语法来定义上下文无关文法。这个文法描述了待分析的语言的语法规则。
(2)生成解析器代码:运行Bison工具,将定义的文法作为输入。Bison会根据文法生成一个解析器的C源代码文件。
(3)编译解析器:使用C编译器将生成的C源代码文件编译成可执行的解析器。
(4)运行解析器:将待分析的输入传递给生成的解析器,解析器会按照定义的文法进行分析。
(5)语法分析:解析器使用LALR(1)算法进行语法分析。它通过读取输入符号流并使用状态转换表来推导出输入的符号序列是否符合文法规则。
(6)语法错误处理:如果输入的符号序列不符合文法规则,解析器会检测到语法错误。此时,Bison会调用yyerror函数进行错误处理,你可以自定义yyerror函数来处理错误。
(7)语义动作:在解析过程中,可以在文法规则中指定语义动作。语义动作是在解析过程中执行的代码片段,用于构建抽象语法树、执行语义动作等。
(8)生成抽象语法树:通过语义动作,解析器可以构建抽象语法树(AST),表示输入符合文法规则的结构。
(9)后续处理:一旦解析器完成语法分析并生成了抽象语法树,你可以根据需要进行进一步的语义分析、代码生成等后续处理。
3.2 Bison文件代码结构
Bison文件代码如下:
%{
// C 代码和头文件的声明
#include
// 在这里可以定义全局变量和函数等
%}
// Bison 的选项部分
%option verbose // 控制 Bison 解析器的详细输出
// Bison 的声明部分
%token NAME // 定义终结符或标记的名称
%token NUMBER
%left ‘+’ ‘-‘ // 定义运算符的优先级和结合性
%left ‘*’ ‘/’
%{
// 在这里可以编写更多的 C 代码
%}// Bison 的规则部分
%%
// 语法规则的定义
expression : expression '+' expression
| expression '-' expression
| expression '*' expression
| expression '/' expression
| '(' expression ')'
| NUMBER ;
// 更多的语法规则...
%%
// C 代码部分(选项中的 %{ ... %} 和规则部分中的 %% 之间的部分)
// 在这里可以编写与语法规则相关的 C 代码
int main() {
yyparse(); // 调用 Bison 生成的解析函数
return 0;
}
bison文件的书写格式与flex文件的书写格式基本一致,只是规则的定义语法不同。
3.3 Bison文件常用特殊符号
(1)“文法”
“文法”是一组规则,用于描述编程语言或语言的语法结构。这些规则定义了语言的句法(syntax),即哪些组合是有效的、合法的语句和表达式,以及它们如何组合在一起。文法规则使用产生式(productions)的形式来表示,其中包含终结符(terminals)和非终结符(non-terminals)的组合。
文法规则在 Bison 文件中是使用 BNF(巴科斯-诺尔范式)或 EBNF(扩展巴科斯-诺尔范式)的形式表示的。BNF 是一种形式化的表示方法,用于定义上下文无关文法(Context-Free Grammar),这些文法用于指定编程语言的语法规则。
expression : expression '+' term
| expression '-' term
| term;(2) %start
%start 指令用于指定文法的起始非终结符。起始非终结符是语法分析的入口点,也就是从哪个语法规则开始构建解析树或语法分析树。
%start program
%%
statements : statement
| statements statement;
statement : assignment
| if_statement
| while_statement
| /* ... other statement types ... */ ;%start program 指定了起始非终结符为 program。这意味着语法分析将从 program 规则开始,逐步展开其他非终结符,最终构建解析树。在实际语法规则中,起始非终结符的选择取决于您想要分析的语言的语法结构。
(3)$
在语法规则中,$ 用于引用当前产生式的右侧的符号或值。例如,在产生式的右侧,$1 表示该产生式右侧的第一个元素(终结符或非终结符),$2表示第二个元素,依此类推。这些引用用于将产生式右侧的值传递给产生式左侧。注意:生产式的起始下标为1。
(4)$$
在语法规则中,$$ 用于引用当前产生式的结果。当 Bison 解析器完成一个产生式的分析并计算出其结果时,该结果会被赋值给 $$。这通常用于构建解析树的节点或为更高层次的语法规则提供结果。
(5)|
| 用于表示多个产生式之间的选择。它在上下文无关文法中用于定义非终结符的不同产生式形式。每个产生式通过竖线分隔,表示它们是该非终结符的可能形式之一。
3.4 bison文件具体案例
1、创建一个名为parser.l的文件,其中包含词法规则;
%{
#include
#include
%}
//定义终结符
%token SELECT INSERT UPDATE DELETE FROM WHERE
%token INTO VALUES SET
%token ID INT STRING
%%
//定义规则
statement: SELECT columns FROM table WHERE condition ';'
| INSERT INTO table '(' columns ')' VALUES '(' values ')' ';'
| UPDATE table SET assignments WHERE condition ';'
| DELETE FROM table WHERE condition ';'
;
columns: ID
| columns ',' ID
;
table: ID
;
assignments: ID '=' value
| assignments ',' ID '=' value
;
values: value
| values ',' value
;
value: INT
| STRING
;
condition: ID '=' value
;
%%
int main() {
yyparse();
return 0;
}
int yyerror(const char *s) {
printf("Error: %sn", s);
return 0;
}
2、使用 bison 命令编译 lexer.l 文件
bison -d parser.y这将生成 parser.tab.c 和 parser.tab.h 两个文件。接下来,你可以将这些文件与你的编译器项目一起编译,并链接到你的代码中。

4. SQL 解析器完整 Demo 演示
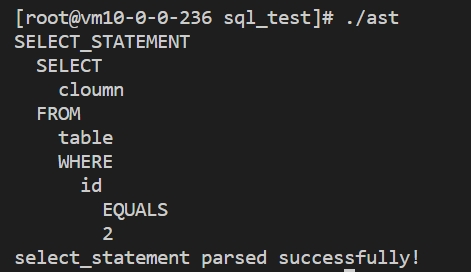
4.1 查询语句
SELECT cloumn FROM table WHERE id=2;查询语句语法分析结果如下所示:
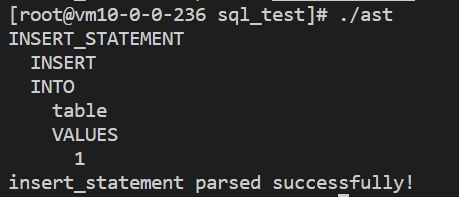
4.2 插入语句
INSERT INTO table VALUES(1);插入语句语法分析结果如下所示:
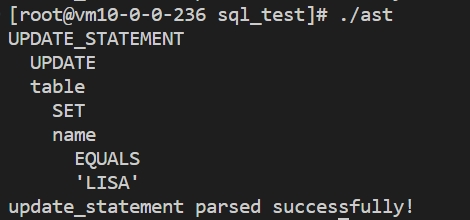
4.3 更新语句
UPDATE table SET name='LIST';更新语句语法分析结果如下所示:
4.4 删除语句
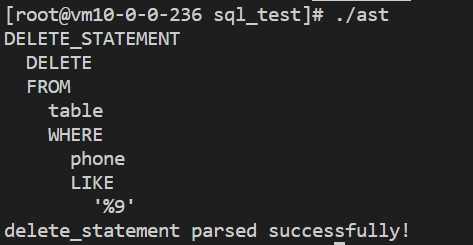
DELETE FROM table WHERE phone LIKE '%9';删除语句语法分析结果如下所示:
5. SQL解析器代码
5.1 SQL解析器主函数
#include
#include
extern FILE* yyin;
extern int yyparse();
int main() {
yyin = fopen("input.sql", "r"); // 打开待解析的 SQL 文件
if (yyin == NULL) {
fprintf(stderr, "Failed to open input file.n");
return 1;
}
//yypase()函数是bison自动生成的函数,是语法分析的入口函数,会自动调用flex中的yylex()函数
/* 返回值为 0:表示语法分析成功完成。
返回值为非零:表示语法分析过程中发生了错误。*/
if (yyparse() != 0) {
fprintf(stderr, "Parsing failed.n");
return 1;
}
fclose(yyin);
return 0;
}5.2 SQL解析器完整代码
完整代码:https://download.csdn.net/download/weixin_47156401/88265367?spm=1001.2014.3001.5503
说明:资源里面附带测试案例,非常适合初学者学习!
如果想了解抽象语法树的生成及编译原理中对应解析器部分,见下面链接:
https://mp.csdn.net/mp_blog/creation/editor/132252320
