

作者 :wuziheng
背景介绍
最近,基于生成式AI技术批量产出真/像/美的个人写真应用非常受欢迎。同时,随着 Stable Diffusion 领域开源社区的快速发展,社区也涌现了类似 FaceChain 的开源项目,帮助开发者开发个性化的真人写真生成应用。越来越多开发者对这个方向投来关注,希望得到更多灵活的开发方式。
EasyPhoto项目介绍
作为FaceChain-Inpaint功能的开发团队,我们快速上线了一款基于 SD WebUI 插件生态的个性化写真生成开源插件 EasyPhoto。这款插件允许用户通过上传几张同一个人的照片,快速训练Lora模型,然后结合用户自定义的模板图片,生成 真/像/美的写真图片。

图1
项目地址: https://github.com/aigc-apps/sd-webui-EasyPhoto
欢迎大家多多提ISSUE,一同优化,让每个AIGCer都拥有自己的AI写真相机!
原理介绍
AI真人写真是一个基于 StableDiffusion和AI人脸相关技术,实现的定制化人像Lora模型训练和指定图像生成链路的集合,这里我们简单介绍我们在EasyPhoto中实现的相关技术,下图是EasyPhoto的生成链路介绍,
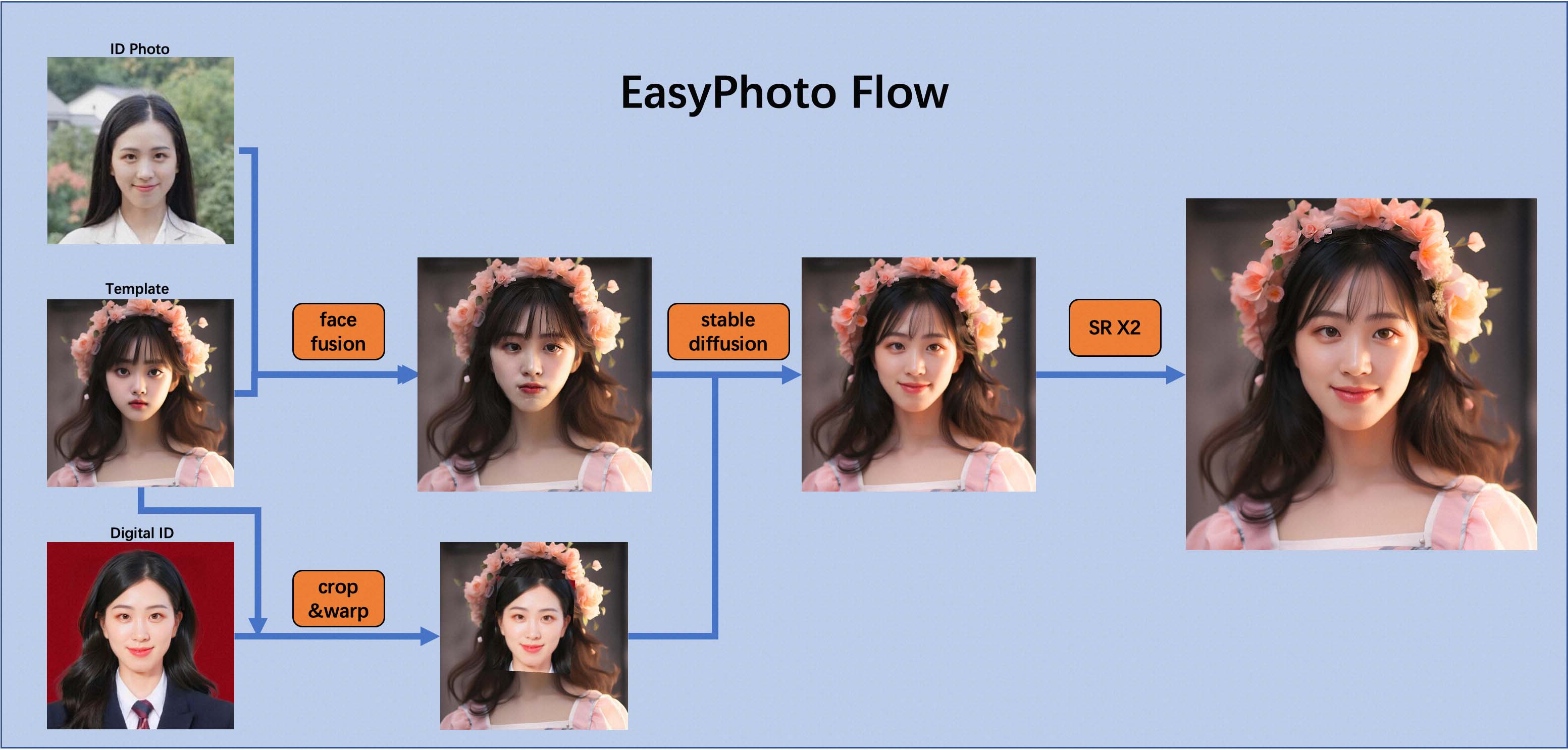
图2
EasyPhoto整体分为训练和推理两个阶段, 下文图3详细展示了训练阶段,上图2展示了生成阶段。
EasyPhoto生成
EasyPhoto生成采用基于开源模型StableDiffusion + 人物定制Lora的方式 + ControlNet 的方式完成艺术照生成
- 使用人脸检测模型对输入的指定模板进行人脸检测(crop & warp)并结合数字分身进行模板替换。
- 采用FaceID模型挑选用户输入的最佳ID Photo和模板照片进行人脸融合(face fusion)。
- 使用融合后的图片作为基底图片,使用替换后的人脸作为control条件,加上数字分身对应的Lora,进行图到图局部重绘生成。
- 采用基于StableDiffusion + 超分的方式进一步在保持ID的前提下生成高清结果图。
EasyPhoto训练!
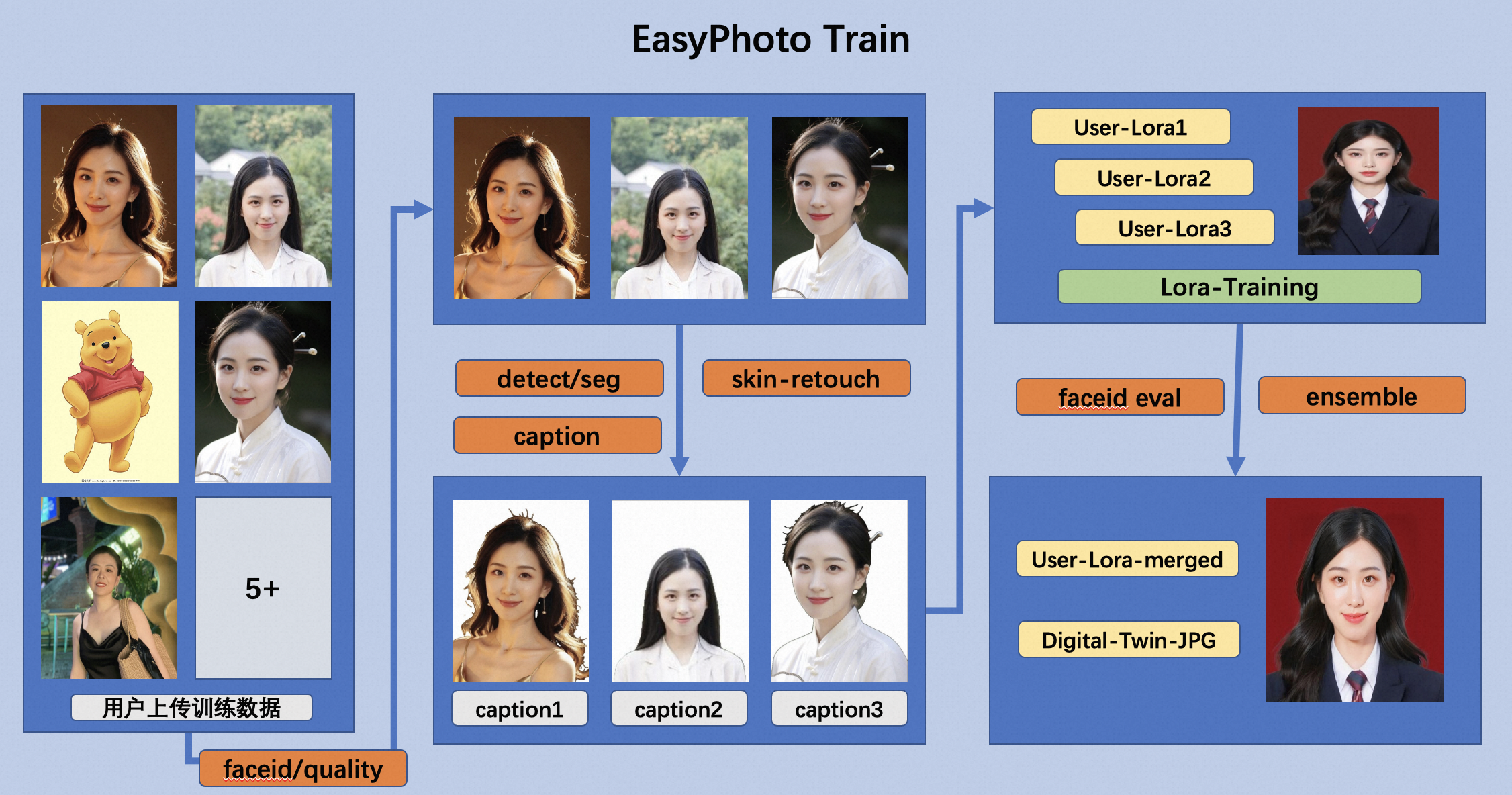
图3
EasyPhoto训练采用了大量的人脸预处理技术,用于把用户上传的图片进行筛选和预处理,并引入相关验证和模型融合技术,参考图3.
- 采用FaceID和图像质量分数对所有图片进行聚类和评分,筛选非同ID照片。
- 采用人脸检测和主体分割,抠出1筛选后的人脸图片进行人脸检测抠图,并分割去除背景。
- 采用美肤模型优化部分低质量人脸,推升训练数据的图片质量。
- 采用单一标注的方案,对处理后的训练图片进行打标,并使用相关的Lora 训练。
- 训练过程中采用基于FaceID的验证步骤,间隔一定的step保存模型,并最后根据相似度融合模型。
我们将从在后续的章节简单介绍涉及到的相关技术的原理,更多细节也欢迎大家参考Repo的代码。(如果你已经对这一技术路线非常熟悉,欢迎直接跳到第三章 EasyPhoto & SDWebUI)
文图生成(SD/Control/Lora)
StableDiffusion
StableDiffusion作为Stability-AI开源图像生成模型,通常分为SD1.5/SD2.1/SDXL等版本, 是通过对海量的图像文本(LAION-5B)对进行训练结合文本引导的扩散模型(DiffusionModel),使用训练后的模型,通过对输入的文字进行特征提取,引导扩散模型在多次的迭代中生成高质量且符合输入语义的图像。感兴趣的同学可以参考 《stable diffusion原理解读通俗易懂,史诗级万字爆肝长文,..》, 下面的图像就是 stablediffusion 官网 Repo 贴出来的他们的效果。
ControlNet/Lora
针对使用文本控制的StableDiffusion模型,如何对生成的图像内容进行更好的控制,一直是学术界和工业界试图解决的问题,本小节介绍的ControlNet和Lora就是常用的两种技术。也是图2中使用的部分技术,用于控制边缘连贯性和指定ID生成。
ControlNet : 由《Adding Conditional Control to Text-to-Image Diffusion Models》提出的通过添加部分训练过的参数,对StableDiffsion模型进行扩展,用于处理一些额外的输入信号,例如骨架图/边缘图/深度图/人体姿态图等等输入,从而完成利用这些额外输入的信号,引导扩散模型生成与信号相关的图像内容。例如我们在官方 Repo 可以看到的,使用Canny边缘作为信号,控制输出的小狗。
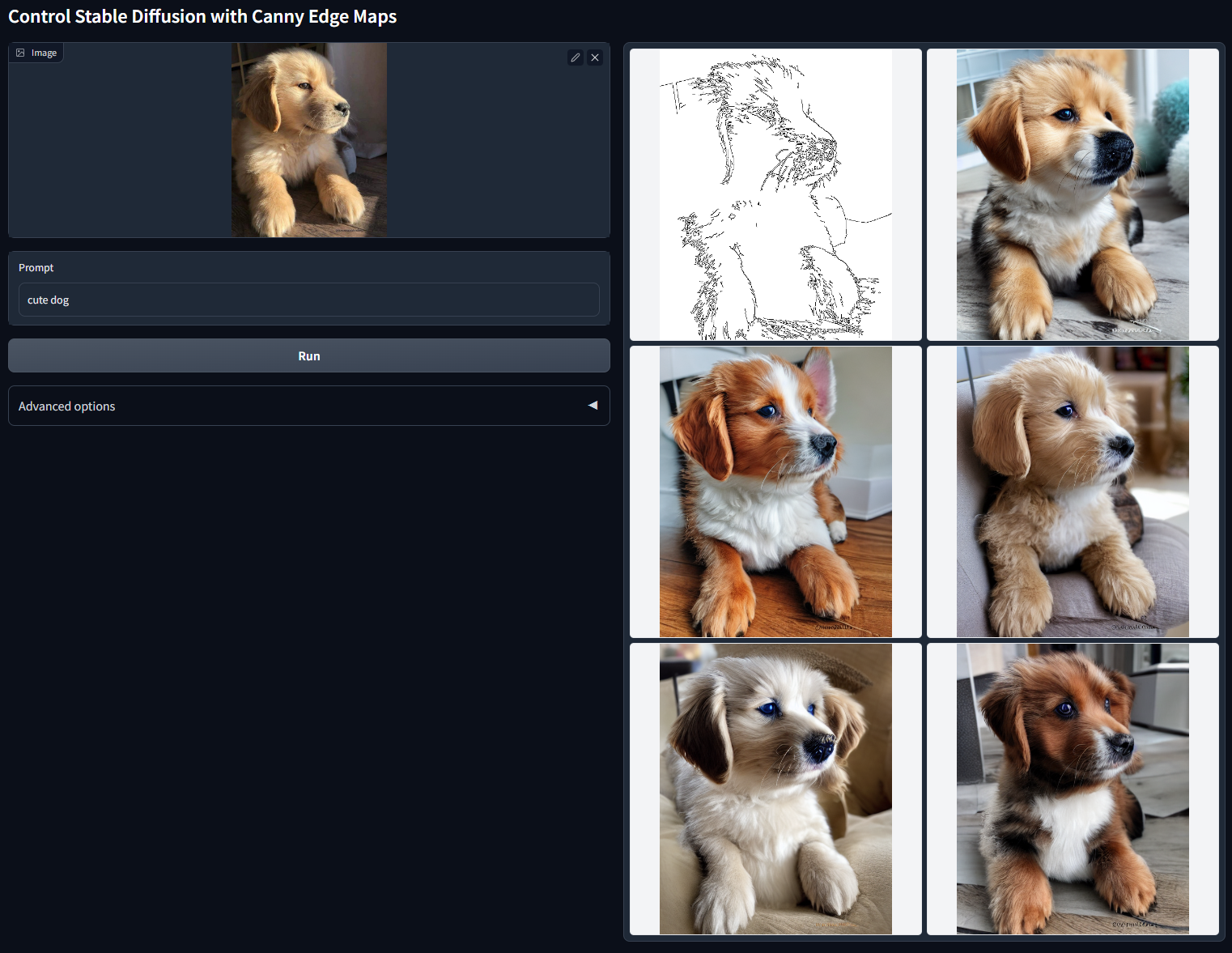
图4
我们在图2中看到 StableDiffusion有2个输入,其中一个部分就是用于控制边缘连贯性和脸型提示的ControlNet,我们使用了部分的Canny边缘和OpenPose人体姿态。
Lora : 由《LoRA: Low-Rank Adaptation of Large Language Models》 提出的一种基于低秩矩阵的对大参数模型进行少量参数微调训练的方法,广泛引用在各种大模型的下游使用中。AI真人写真需要保证最后生成的图像和我们想要生成的人是相像的,这就需要我们使用Lora 技术,对输入的少量图片,进行一个简单的训练,从而使得我们可以得到一个小的指定人脸(ID)的模型。当然这一技术也可以广泛用于,风格,物品等其他指定形象的Lora模型训练,大家可以在civitai.com等相关网页上寻找自己想要的Lora模型。
人脸相关AI模型
针对AI写真这一特定领域,如何使用尽量少的图片,快速的训练出又真实又相像的人脸Lora模型,是我们能够产出高质量AI写真的关键,网络上也有大量的文章和视频资料为大家介绍如何训练。这里我们介绍一些在这个过程中,我们使用的开源AI模型,用于提升最后人脸Lora训练的效果。
在这个过程中我们大量的使用了 ModelScope 和其他Github的开源模型,用于完成如下的人脸功能
| 人脸模型 | 模型卡片 | 功能 | 使用 |
|---|---|---|---|
| FaceID | https://github.com/deepinsight/insightface | 对矫正后的人脸提取特征,同一个人的特征距离会更接近 | EasyPhoto图片预处理,过滤非同ID人脸 ;EasyPhoto训练中途验证模型效果;EasyPhoto预测挑选基图片 |
| 人脸检测 | cv_resnet50_face | 输出一张图片中人脸的检测框和关键点 | 训练预处理,处理图片并抠图; 预测定位模板人脸和关键点 |
| 人脸分割 | cv_u2net_salient | 显著目标分割 | 训练预处理,处理图片并去除背景 |
| 人脸融合 | cv_unet-image-face-fusion | 融合两张输入的人脸图像 | 预测,用于融合挑选出的基图片和生成图片,使得图片更像ID对应的人 |
| 人脸美肤 | cv_unet_skin_retouching_torch | 对输入的人脸进行美肤 | 训练预处理:处理训练图片,提升图片质量;预测:用于提升输出图片的质量。 |
EasyPhoto & SDWebUI
SDWebUI [Repo]是社区最常用的StableDiffusion开发工具,从年初开源至今,已在Github 拥有100k 的star,我们提到的文图生成/ControlNet/Lora等功能,都被社区开发者贡献到这一工具中,用于大家快速部署一个可以调试的文图生成服务,所以我们也在SDWebUI下实现了EasyPhoto插件,将上述原理提到的 人脸预处理/训练/艺术照生成全部集成到了这一插件中。
项目地址:https://github.com/aigc-apps/sd-webui-EasyPhoto
用户可以参考SDWebUI的插件使用方式进行安装使用。
EasyPhoto插件简介
EasyPhoto是一款Webui UI插件,用于生成AI肖像画,该代码可用于训练与用户相关的数字分身。
- 建议使用 5 到 20 张肖像图片进行训练,最好是半身照片且不要佩戴眼镜(少量可以接受)。
- 训练完成后,EasyPhoto可以在推理部分生成图像。
- EasyPhoto支持使用预设模板图片与上传自己的图片进行推理。
图1, 图5这些是插件的生成结果,从生成结果来看,插件的生成效果还是非常不错的:

图5
每个图片背后都有一个模板,EasyPhoto会对模板进行修改使其符合用户的特征。在EasyPhoto插件中,Inference侧已经预置了一些模板,可以用插件预置的模板进行体验;另外,EasyPhoto同样可以自定义模板,在Inference侧有另外一个tab页面,可以用于上传自定义的模板。如下图所示。
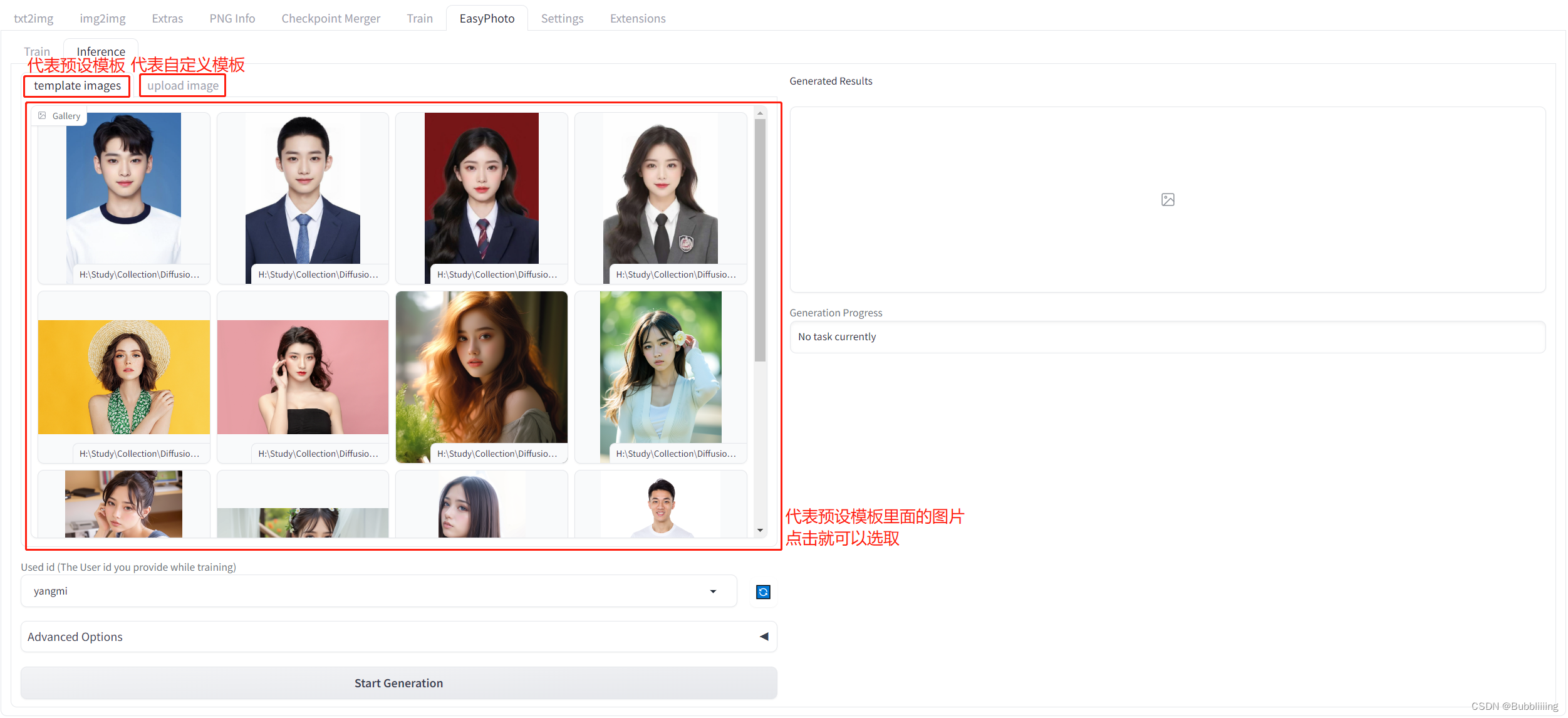
图6
而在Inference预测前,我们需要进行训练,训练需要上传一定数量的用户个人照片,训练的产出是一个Lora模型。该Lora模型会用于Inference预测。
总结而言,EasyPhoto的执行流程非常简单:1、上传用户图片,训练一个与用户相关的Lora模型; 2、选择模板进行预测,获得预测结果。
安装方式一: SDWebUI界面安装
网络良好的情况下!!!在SDWebUI中跳转到Extentions,然后选择install from URL。输入https://github.com/aigc-apps/sd-webui-EasyPhoto,点击下方的install即可安装。
在安装过程中,会自动安装依赖包,这个需要耐心等待一下。安装完需要重启WebUI。
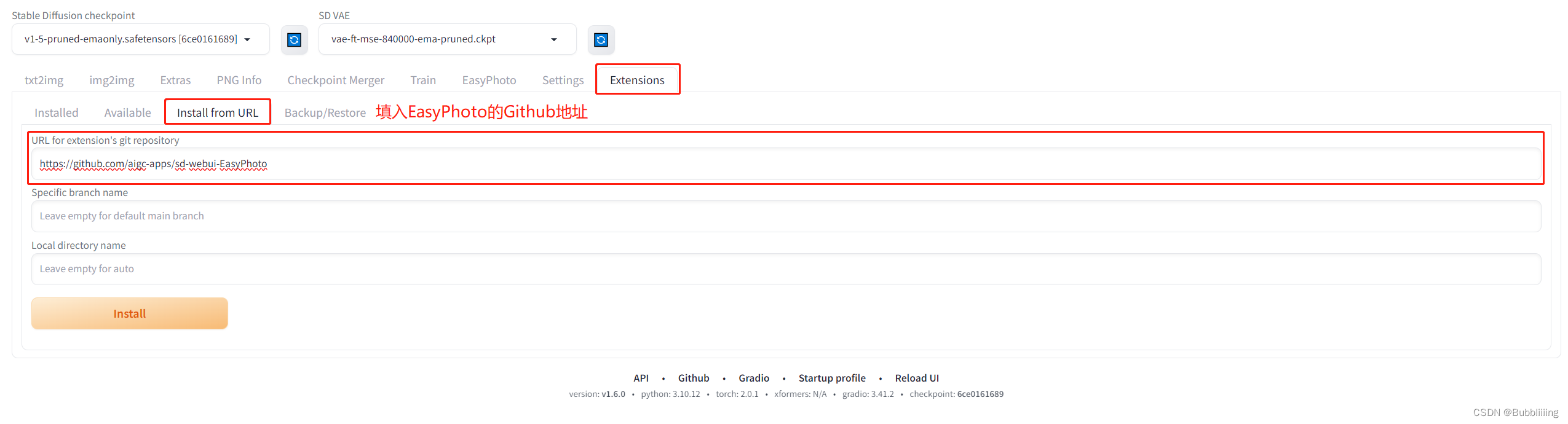
图7
安装方式二:源码安装
如果你想要使用项目源码安装,直接进入到Webui的extensions文件夹,打开git工具,git clone即可。下载完成后,重新启动webui,便会检查需要的环境库并且安装。

图8
其他安装项:ControlNet
EasyPhoto需要SDWebUI支持ControlNet,具体使用的相关插件是Mikubill/sd-webui-controlnet。在使用 EasyPhoto 之前,您需要安装这个软件源。
- 此外,我们至少需要三个 Controlnets 用于推理。因此,您需要设置 Multi ControlNet: Max models amount (requires restart) 。
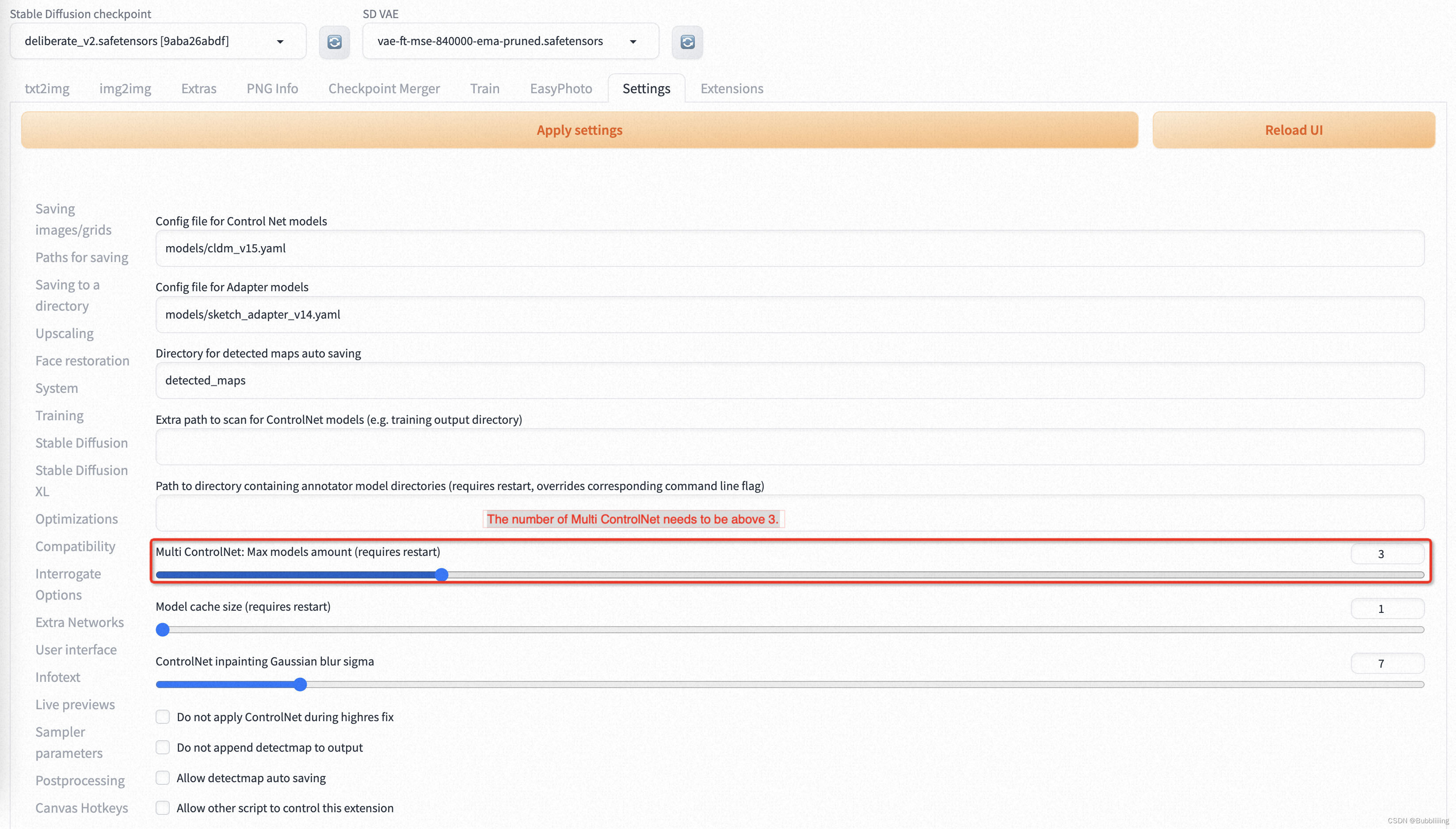
图9
EasyPhoto训练
EasyPhoto训练包含如下2个步骤 1. 上传个人图片 2. 调整训练参数 3点击训练并设置ID, 整体界面如下
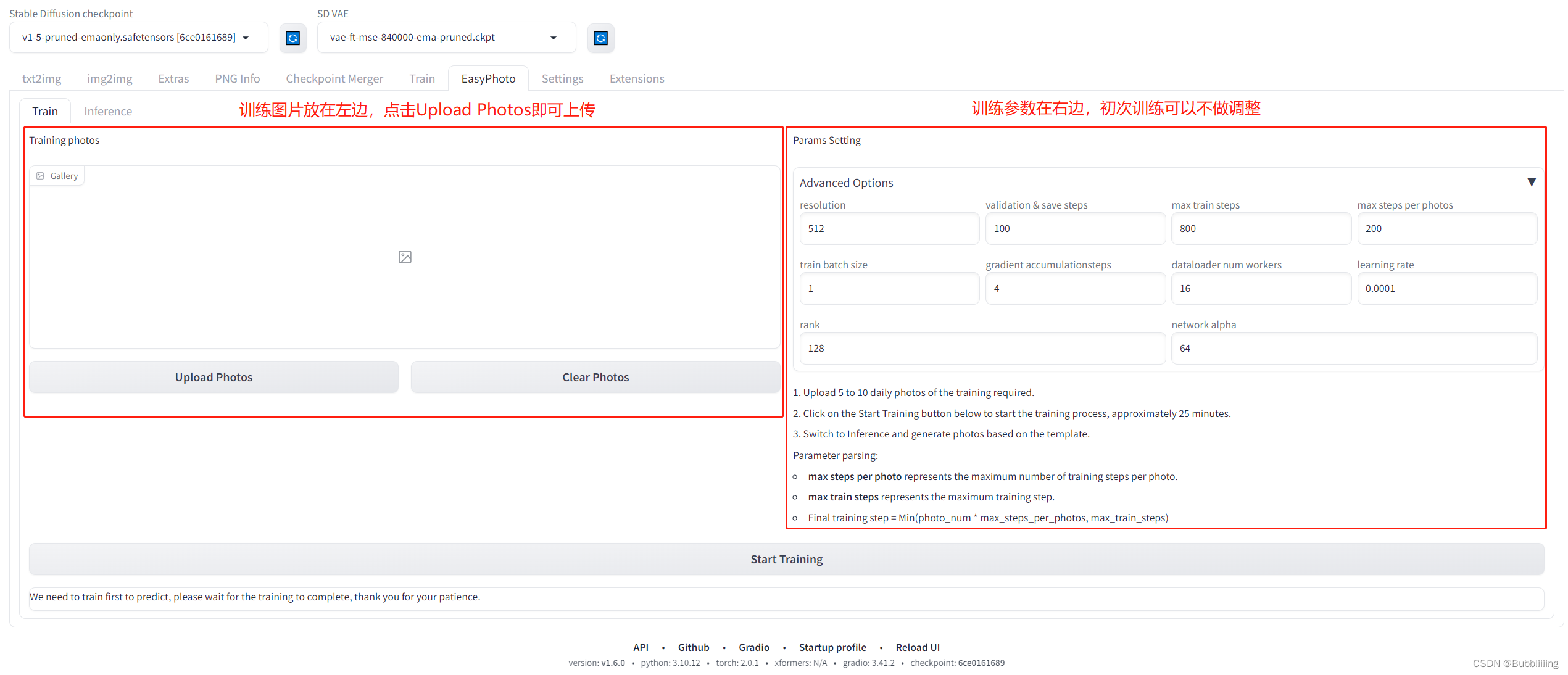
图10
上传训练图片
左边是训练图片,点击Upload Photos即可上传图片,点击Clear Photos可以删除已经上传的图片
调整训练参数
上传完图片后,右边是训练参数,初次训练可不做参数调整。 图11
图11
这里我们也对参数进行一个介绍
| 参数名 | 含义 |
|---|---|
| resolution | 训练时喂入网络的图片大小,默认值为512 |
| validation & save steps | 验证图片与保存中间权重的steps数,默认值为100,代表每100步验证一次图片并保存权重 |
| max train steps | 最大训练步数,默认值为800 |
| max steps per photos | 每张图片的最大训练数,默认为200,与max train steps结合取小。 |
| train batch size | 训练的批次大小,默认值为1 |
| gradient accumulationsteps | 进行梯度累计,默认值为4,train batch size=1的时候,每个step相当于喂入四张图片 |
| dataloader num workers | 数据加载的works数量,windows下不生效,因为设置了会报错,Linux正常设置 |
| learning rate | 训练Lora的学习率,默认为1e-4 |
| rank Lora | 权重的特征长度,默认为128 |
| network alpha | Lora训练的正则化参数,一般为rank的二分之一,默认为64 |
根据上述表格最终训练步数的计算公式也比较简单。
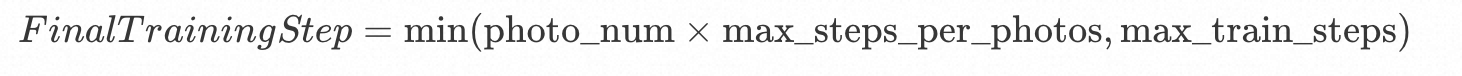
简单来理解就是: 图片数量少的时候,训练步数为photo_num * max_steps_per_photos。 图片数量多的时候,训练步数为max_train_steps。
训练&设置ID
完成设置后,点击下方的开始训练,此时需要在上方填入一下User ID,比如 用户的名字,然后就可以开始训练了。

图12
观察训练
!!初次训练时会从我们预备的oss(公用)上下载一部分预训练模型的权重,我们耐心等待即可,下载进度需要关注终端。
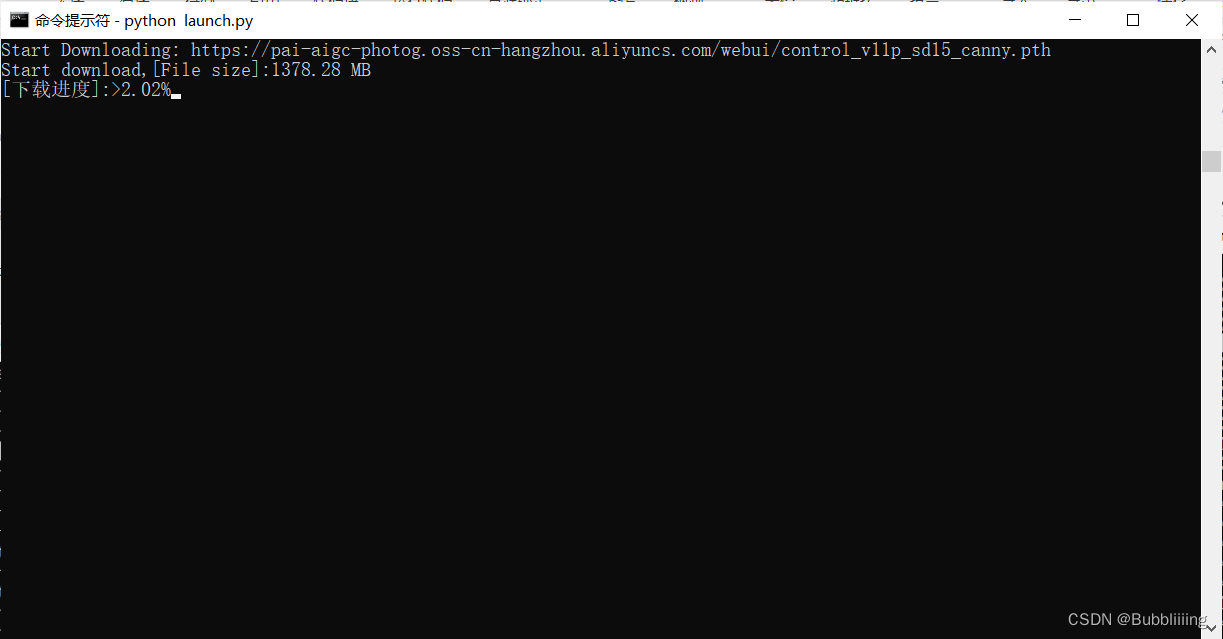
图13
训练正常开始的相关log
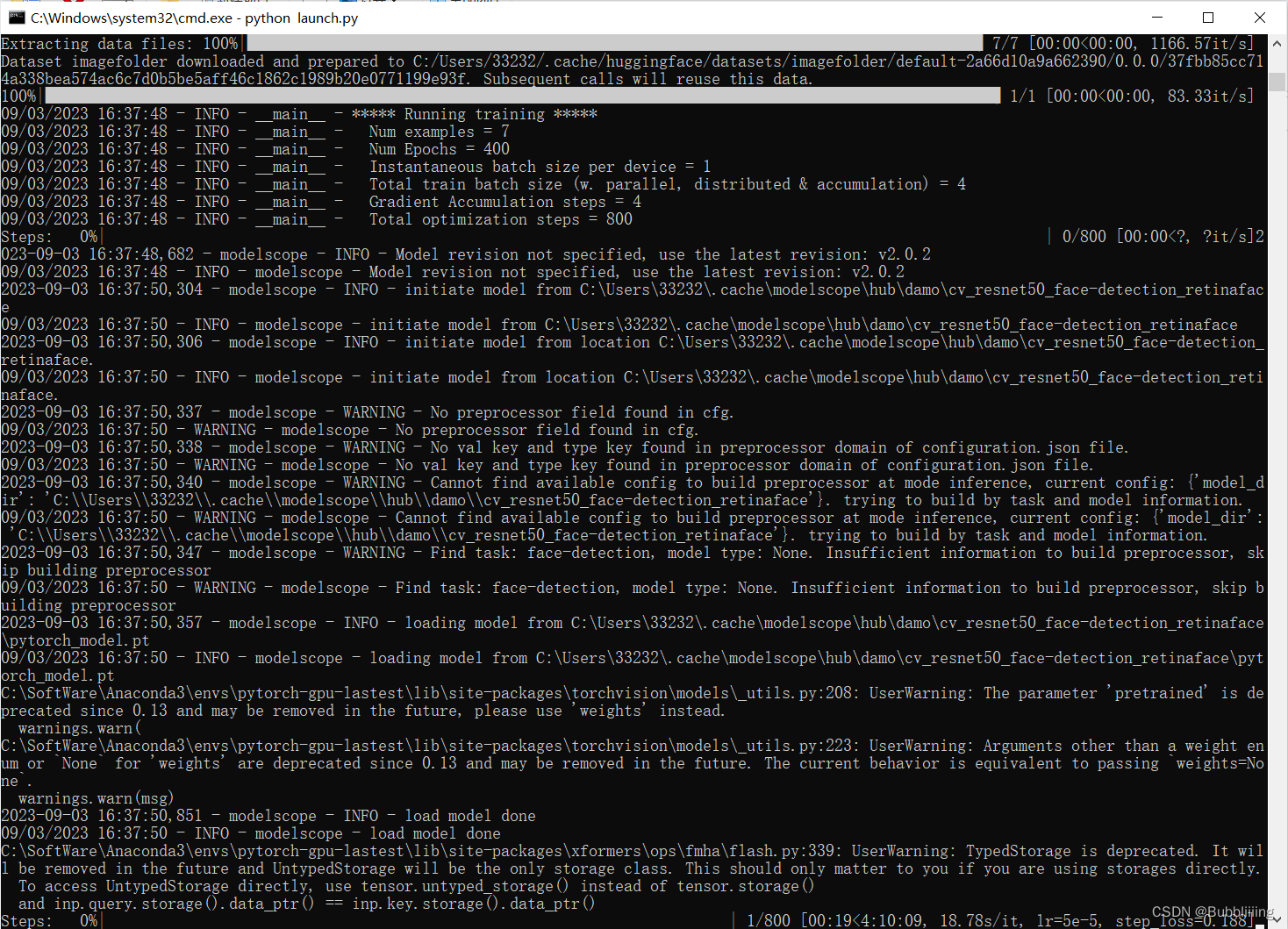
图14
终端显示成这样就已经训练完了,最后这步是在计算验证图像与用户图像之间的人脸 ID 差距,从而实现 Lora 融合,确保我们的 Lora 是用户的完美数字分身。
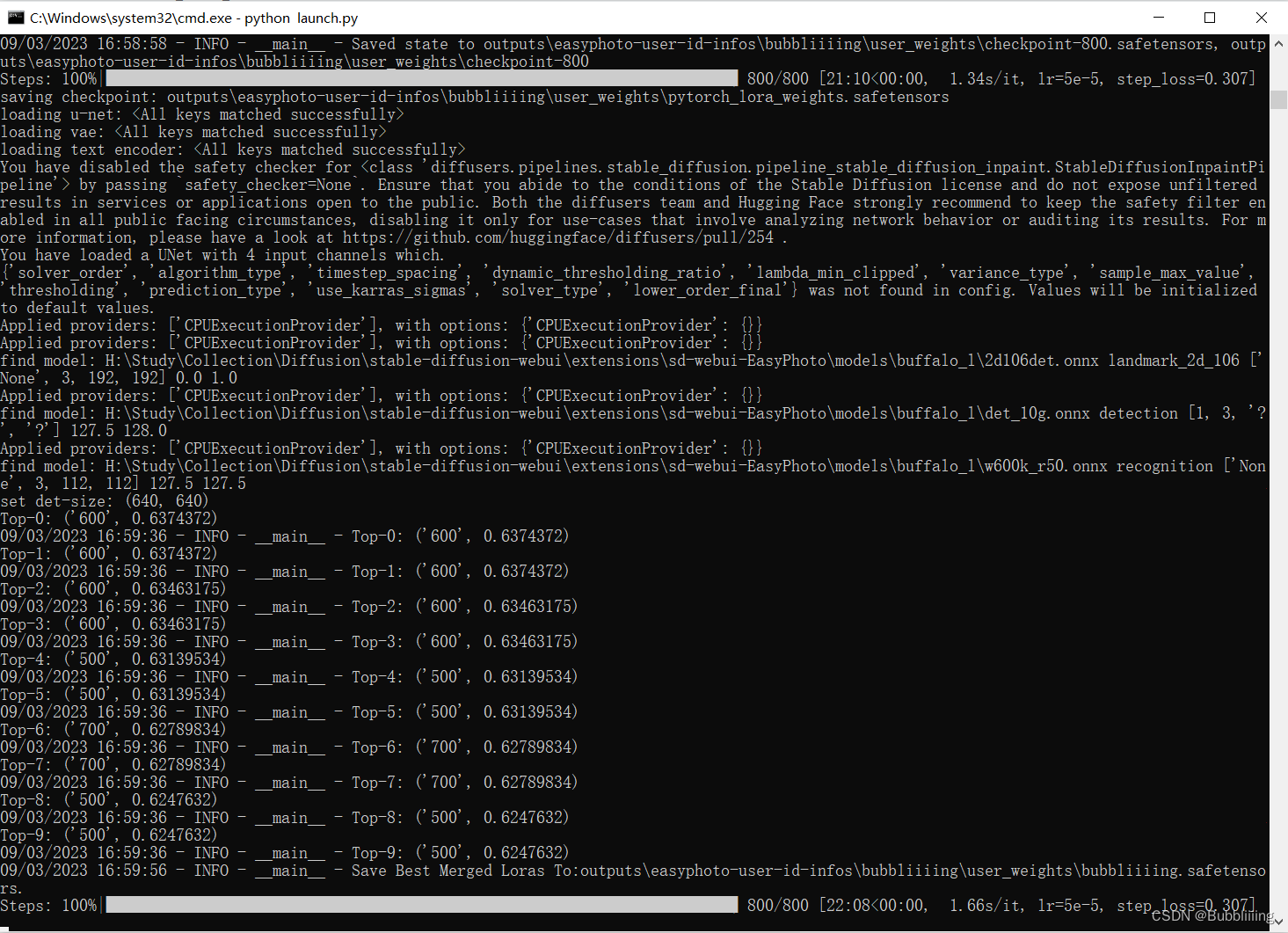
图15
EasyPhoto预测
训练完后,我们需要将tab页转到Inference。由于Gradio的特性,刚训练好的模型不会自动刷新,可以点击Used id旁的蓝色旋转按钮进行模型刷新。
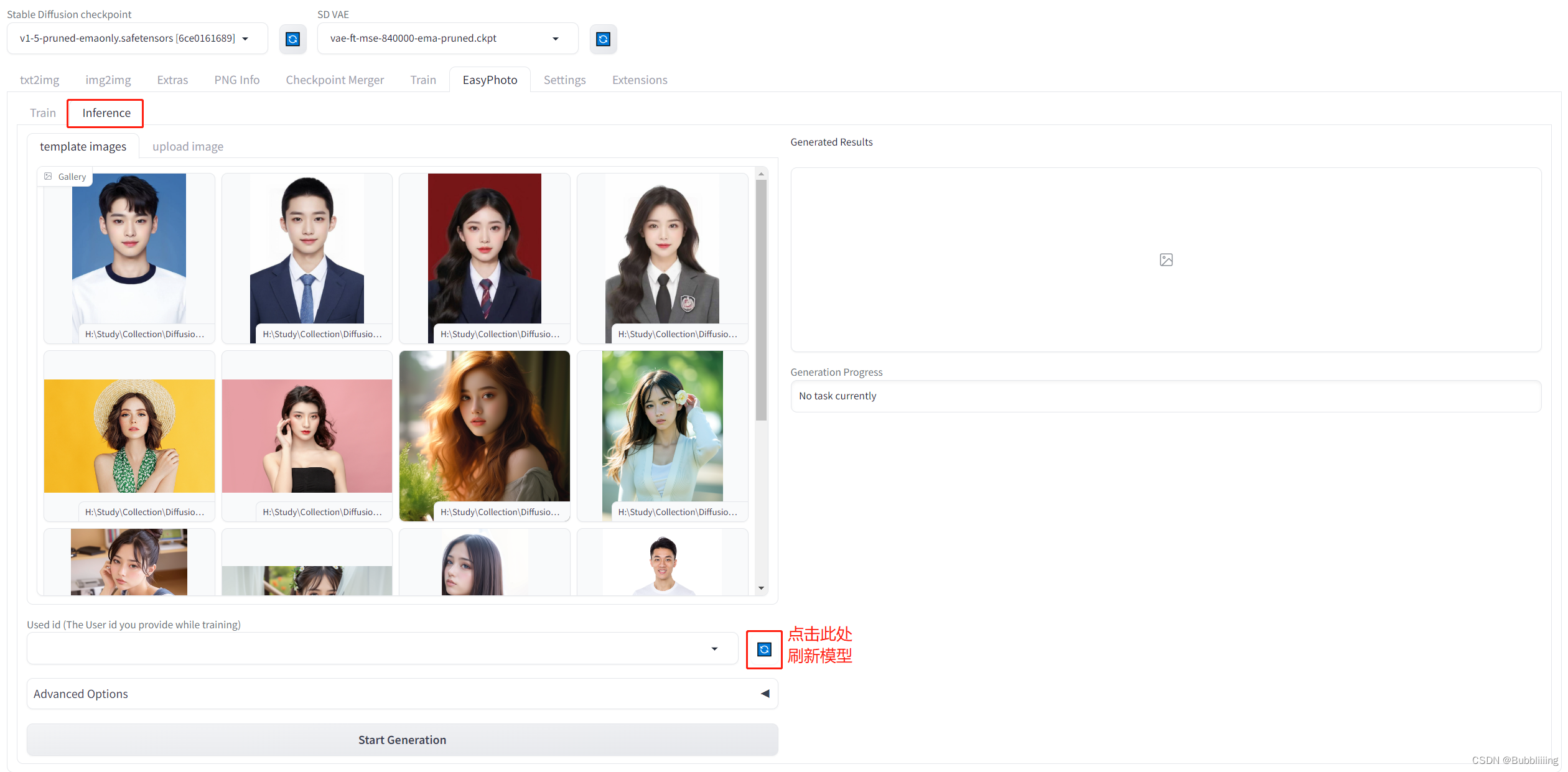
图16
- 刷新完后选择刚刚训练的模型,然后选择对应的模板即可开始预测。
- 初次预测需要下载一些modelscope的模型,耐心等待一下即可。
预置了部分模板,也可以切到upload image,直接自己上传模板进行预测。然后我们就可以获得预测结果了。
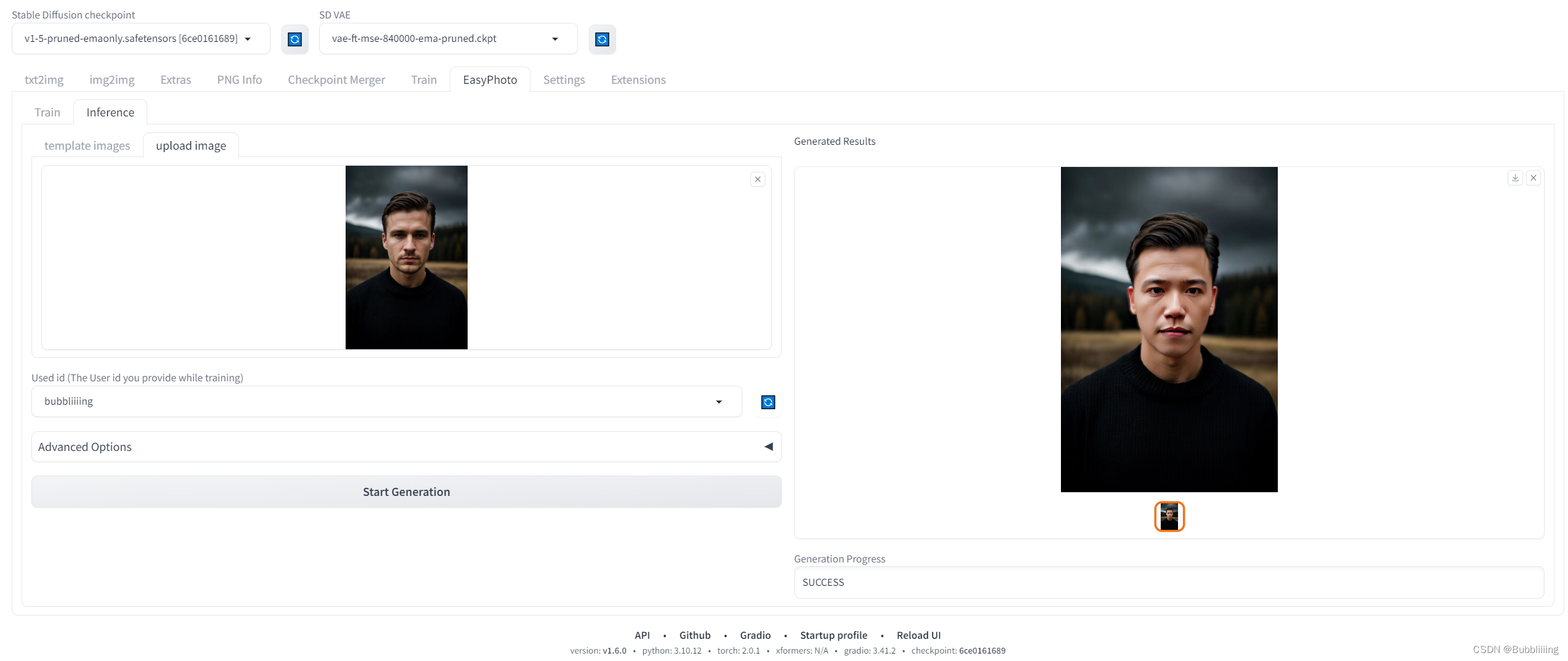
图17
预测参数说明
关于预测界面的部分参数说明
| 参数名 | 含义 |
|---|---|
| After Face Fusion Ratio | 第二次人脸融合的比例,越大代表越像 |
| First Diffusion steps | 第一次Stable Diffusion的步数 |
| First Diffusion denoising strength | 第一次Stable Diffusion重建的比例 |
| Second Diffusion steps | 第二次Stable Diffusion的步数 |
| Second Diffusion denoising strength | 第二次Stable Diffusion重建的比例 |
| Crop Face Preprocess | 是否先裁剪人脸后再进行处理,适合大图 |
| Apply Face Fusion Before | 是否进行第一次人脸融合 |
| Apply Face Fusion After | 是否进行第一次人脸融合 |
写在最后
EasyPhoto全部使用来自开源社区的模型和相关技术,旨在探讨StableDiffusion在AIGC X 真人写真领域的技术和相关应用,文章所有涉及的图片仅做演示使用,如有侵权请及时联系我们,也请大家引用时表明转载!!!。
非常欢迎大家下载试用,并参与开发,共建真像美的AI写真!
