

在使用rabbitmq时,我们有时需要查看消息队列生产/消费了那些消息,便于我们排错。rabbitmq中提供一个插件rabbitmq_tracing用于记录消息的日志,默认是未打开的,需要自己用命令打开
docker exec -it rabbitmq1 bash
# 查看打开的插件
rabbitmq-plugins list
# 启动日志插件
rabbitmq-plugins enable rabbitmq_tracing
# 开启rabbitmq的tracing插件
rabbitmqctl trace_on
# 如果添加到其他虚拟主机
# -p 参数前缀 加上你的虚拟主机名字
rabbitmqctl trace_on -p myhost
- 关闭trace功能
# 关闭trace功能
rabbitmqctl trace_off
# 关闭其他虚拟主机
rabbitmqctl trace_off -p myhost
- 停止tracing
rabbitmq-plugins disable rabbitmq_tracing
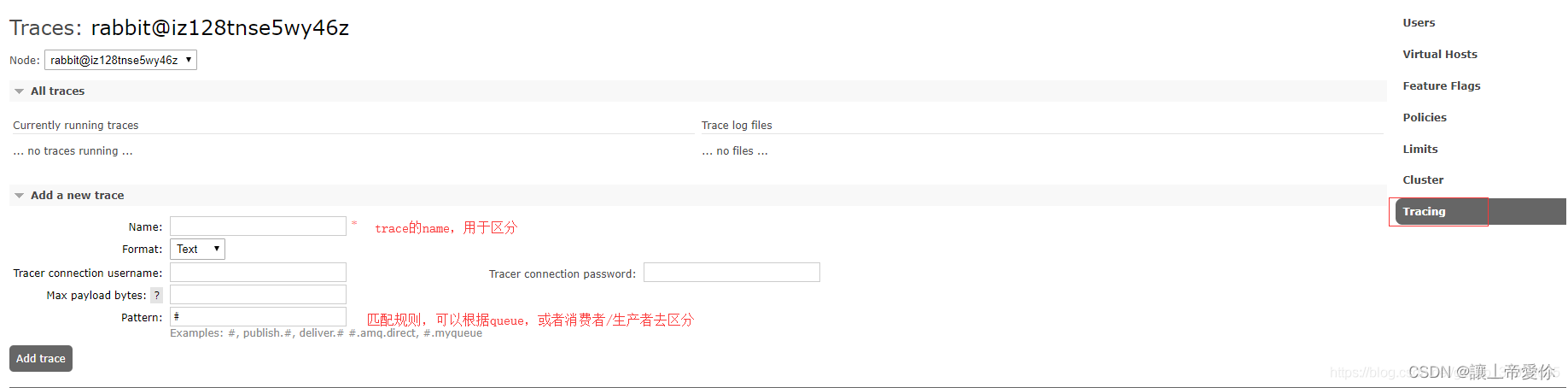
安装该插件后在控制台的管理tab页,在Admin中会发现右侧有多了一个Tracing选项
-
name:用于区分不同的track
-
Format:表示输出的消息日志格式,有Text和JSON两种,Text格式的日志方便人类阅读,JSON的方便程序解析
-
Pattern:用来设置匹配的模式,和Firehose的类似。如“#”匹配所有消息流入流出的记录;“publish.#”匹配所有消息流入的情况;“deliver.#”匹配所有消息流出的情况。
其中,最重要的是理解pattern的格式。一般来跟踪消息时会涉及到两个部分:有没有发布到MQ,有没有发出去。其抓包记录的格式如下:

publish是到exhange的时间;recevied是到queue的时候,并不是推送到消费者的时间,如果消费慢,那么积压是必然的,可能会很久后才被处理,这个只能在消费端跟踪。
官网
The firehose publishes messages to the topic exchange amq.rabbitmq.trace with
routing key either "publish.exchangename", for messages entering the broker, or "deliver.queuename", for messages leaving the broker;
也就是抓publish跟着exchangename走,抓消费跟着queuename走。
