

作者:喜马拉雅 董道光
宣言:缓存不是万金油,更不是垃圾桶!!!
缓存作为喜马拉雅至关重要的基础组件之一,每天承载着巨大的业务请求量。一旦缓存出现故障,对业务的影响将非常严重。因此,确保缓存服务的稳定和高效运行始终是我们的重要目标。
下面是我们对喜马缓存历史故障复盘后总结的一套缓存使用规范,在此分享给大家,希望小伙伴们能在缓存选型和使用的过程中少踩坑。
1. 缓存选型
1.1 缓存类型介绍
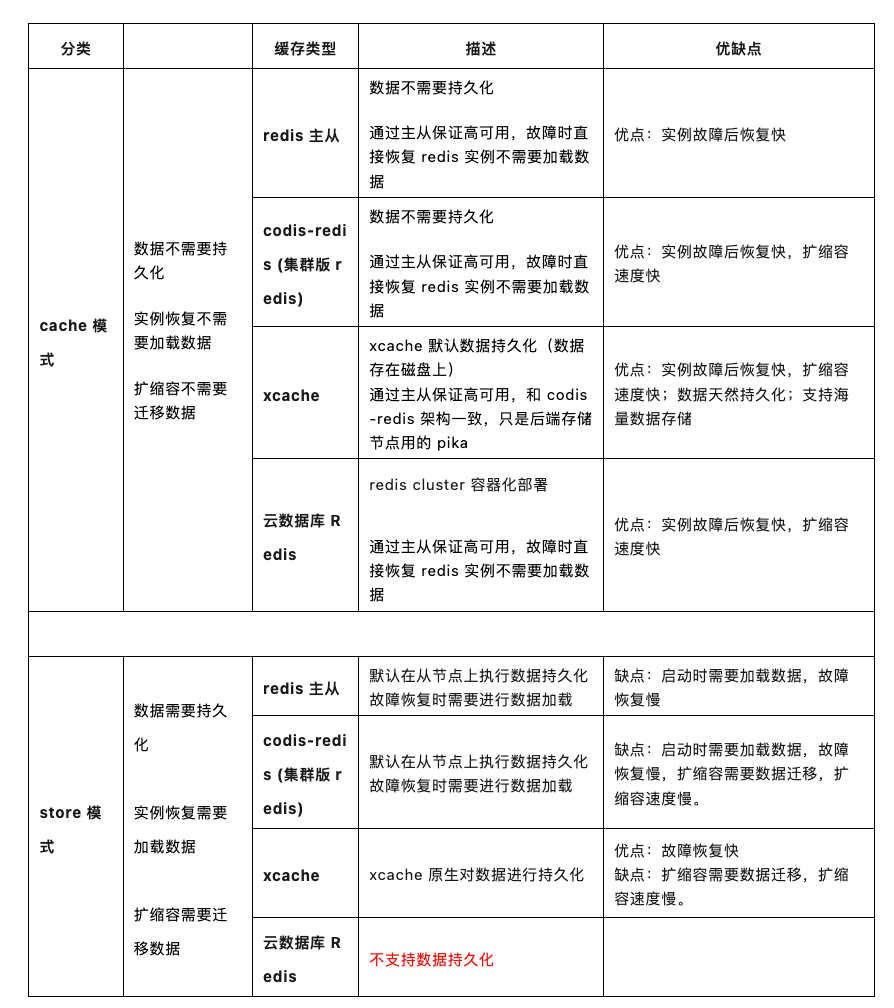
喜马线上缓存类型主要有 4 种:
1. redis 主从模式:官方原版
2.codis-redis:豌豆荚开源,redis 集群解决方案
3. 云数据库 redis:redis-cluster 容器化部署
4.xcache:基于 codis、pika、redis 自研的一套海量 KV 存储解决方案
1.2 缓存使用模式介绍
使用模式主要分为 2 种:
1.cache 模式:数据不需要持久化,实例恢复不需要加载数据,扩缩容不需要迁移数据
2.store 模式:数据需要持久化,实例恢复需要加载数据,扩缩容需要迁移数据
下面是对各种类型缓存做了简单对比:
2. 缓存使用军规
2.1 缓存类型使用规范
1)redis 集群模式首选云数据库 redis,海量 KV 存储首选 xcache
云数据库 redis 采用官方 redis cluster 模式,容器化部署,支持故障自动恢复和弹性伸缩,是当前 redis 集群的主推方案,但不支持数据持久化,如果必须要做数据持久化,并且对延时要求非常高,可以使用 codis redis。数据量非常大,并且对延时要求不是特别高,可以选择 xcache。
2)redis 不要当 db 使用,如果数据一定要做持久化,可以选择 xcache
redis 当 db 使用,故障恢复数据很慢,严重影响 SLA。并且如果主从全部挂掉,slave 机器无法恢复时,数据就会完全丢失。xcache 天然支持数据持久化
3)不要使用客户端分片模式
客户端分片模式不具备高可用和弹性伸缩能力,建议使用真正的集群模式,如 codis-redis、云数据库 redis、xcache
4)集群模式不支持 lua、redisson 客户端,如果业务必须使用,只能选择 redis 主从模式
5)redis 单节点容量不要超过 10GB,xcache 单节点容量不要超过 200GB
redis 单节点容量太大时,实例重启会比较慢,影响恢复时长
2.2 键值设计规范
1)key 尽量保持简洁性、可读性、可管理性
在保证语义的前提下,控制 key 的长度;以业务名 (或数据库名) 为前缀 (防止 key 冲突),用冒号分隔,比如业务名:表名:id;不要包含特殊字符
2)拒绝 bigkey,防止网卡流量过高、慢查询
string 类型控制在 10KB 以内,hash、list、set、zset 元素个数不要超过 5000
3)避免热点 key
热 key 会导致数据倾斜,以及单节点压力过大。建议业务侧将热 key 打散
4)控制 key 生命周期
缓存不是垃圾桶,最好对 key 都设置 ttl,并且将 key 的 ttl 打散,避免 key 集中过期
2.3 命令使用规范
1)慎用全量操作命令
禁用 `keys *` 命令,尽量不使用 hgetall、smembers 等命令。在获取 key 下的多个元素时,使用相应的 scan 命令,一次获取少量元素,分多次获取,建议一次 scan 不要超过 200 个
2)控制 mset、mget、hmset、hmget、*scan、*range 等命令单次操作元素数量,建议不要超过 200
3)控制 pipeline 中命令的数量,建议不要超过 100
4)redis 删除 key 时,不要用 del 命令,使用 unlink 命令
del 一个大 key 会直接导致 redis 卡住。使用 unlink 命令可以异步删除 key,不会对 redis 主线程产生影响,因此也不会影响业务流量
5)set 和 expire 命令合并成 setex 命令,减少服务端写压力
6)evalsha 代替 eval
redis-cluster 集群中使用 evalsha 代替 eval,减少网络 IO,同时也减小 redis 网络 IO 压力提高性能
2.4 业务缓存架构规范
1)redis 不要使用逻辑 db,只使用默认 db 0
可以通过实例隔离,不同业务的数据保存到不同的实例中。(只有 redis 主从可以选择逻辑 db,集群模式默认都使用 db0)
2)避免多业务复用同一缓存资源
不同业务的数据使用不同的集群,S 级应用不要和 B 级应用混用,过多业务复用同一资源要做拆分。业务尽量提供 rpc 接口给其它业务调用,而不是直接让其它业务访问数据源(如一个业务写,一个业务读)
3)xcache 尽量使用 string 类型
xcache 支持 string,hash,ehash,list,set,zset 六种数据类型,ehash 数据类型是对 hash 数据类型的扩展,支持对 field 设置过期时间。xcache 中 string 类型是速度最快的,其他数据类型都是由 string 进行组合变换而实现,六种数据的性能如下:
string > hash > set > ehash > list > zset
建议:尽量使用 string 类型
4)减少 lua 脚本使用
集群模式对 lua 支持有限制,必须保证 lua 中操作的 key 被 sharding 到同一个节点。所以尽量减少对 lua 的使用
5)lua 脚本中不跑复杂逻辑
复杂逻辑放在业务代码中,而不是 lua 脚本中
6)采用高效序列化方法和压缩方法
为了节省内存,如果 value 较大时,可以使用压缩工具(如 snappy 或 gzip),把数据压缩后再写入 redis
7)避免批量任务、定时任务、周期任务流量太大影响在线业务
批量任务、定时任务、周期任务业务上要做限速
8)业务变更,存储流量模型变化要先评估
业务模型变化,QPS、容量增加,O (N) 命令增多等都要先评估当前缓存是否抗的住,做到灰度上线,持续观察(尤其是流量高峰期)
9)不用的资源尽早申请回收
休眠资源回收不仅可以降低业务的存储成本,还可以把资源分配给真正需要的业务,可谓是双赢
补充:OpenAtom 开源大赛 Pika 赛题放出,奖金 50 万,请扫描如下二维码进行 报名:

大家也可以添加 Pika 助手,加入 Pika 微信群,了解更多动态消息:

