

由于缺乏良好的规划,有开发人员直接在公有云采购一个容量超过100TB的NAS存储,使用过程中,数据的存储也没有规划,业务数据一股脑的写入到同一个目录,下边的子目录没有规律,用用户的图片、视频、访问日志、甚至还有备份。因应用日趋增多,公有云的使用成本急剧上升,考虑到成本及可控性,决定把公有云的NAS及所有应用迁移到自建的Proxmox VE超融合集群。
于是在Proxmox VE集群创建虚拟机,并给此虚拟机分配40T的磁盘空间,以单独的分区进行挂载。本来不愿意这样操作,建议使用者先清理掉无用的数据,对方答复,当前任务紧,文件目录又没规律,暂时无法进行操作,只能一锅端将公有云NAS上的数据复制到Proxmox VE上的虚拟机。托管机房及公有云对等开了300M的带宽,复制了将近一个月,才基本复制完。运行过程中,突遇Proxmox VE集群服务器全部同时重启,悲剧,Ceph OSD故障!用指令“ceph pg repair“,无效。因为集群上已经有业务在运行,如果重建ceph pool,再重新从公有云的NAS复制数据,完全不可能了。因为虚拟机分配的单分区太大,用各种方法,都不好使,最后只能等Ceph自己恢复。一共等了快一个月,才自动恢复成功。
为解决共享存储问题,购买了专门的设备,就是普通服务器插很多硬盘,SSD安装系统,NVME做缓存,部署TrueNAS,然后将Proxmox VE集群上的那个大分区的数据迁移,彻底排除集群的隐患。
这几天,开始释放这个巨大巨大无比的虚拟机,删除起来还很费时,差不多24小时,才进行到40%多。
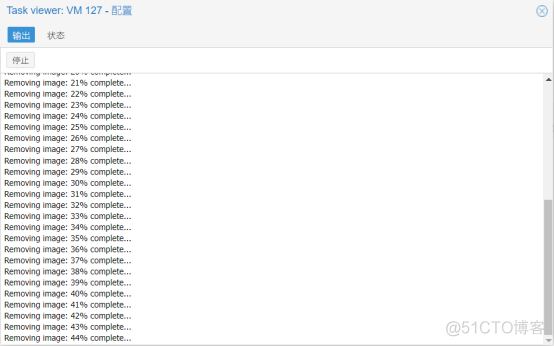
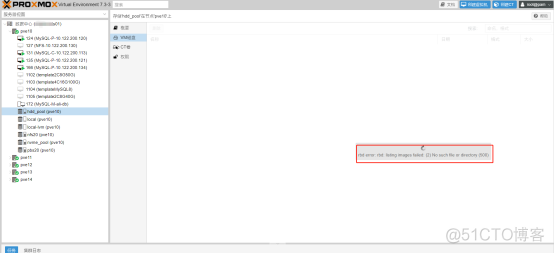
我嫌这样释放太慢了,打算在Proxmox VE Web管理后台直接删掉VM磁盘,但不行的是,报错了,无法进行操作。
登录集群任意节点宿主系统,命令行下执行“rbd ls -l hdd_pool”,看是否存在异常的虚拟机磁盘镜像。
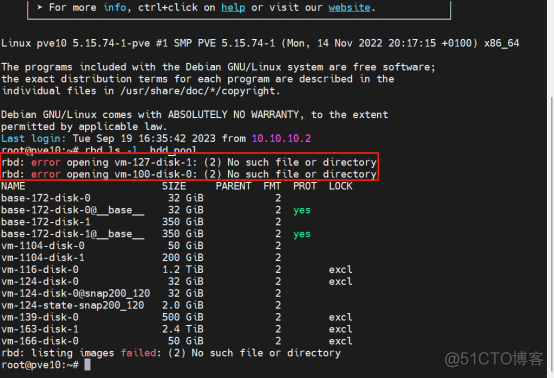
由输出可知,确实存在有问题的虚拟机磁盘镜像。用命令“rbd rm vm-100-disk-0 -p hdd_pool”进行清理。

同样的方法,将另一个异常的磁盘镜像“vm-127-disk-1”清理掉,再运行“rbd ls -l hdd_pool”,就可以看到虚拟机镜像磁盘的正常显示。
