

设想一下,作为一个开发人员,你现在所在的公司有一套线上的 Hadoop 集群。A部门经常做一些定时的 BI 报表,B部门则经常使用软件做一些临时需求。那么他们肯定会遇到同时提交任务的场景,这个时候到底应该如何分配资源满足这两个任务呢?是先执行A的任务,再执行B的任务,还是同时跑两个?
如果你存在上述的困惑,可以多了解一些 Yarn 的资源调度器。
Yarn 的三种调度器
从 Hadoop2 开始,官方把资源管理单独剥离出来,主要是为了考虑后期作为一个公共的资源管理平台,任何满足规则的计算引擎都可以在它上面执行。Yarn 作为一款 Hadoop 集群的资源共享,不仅可以跑 MapReduce,还可以跑 Spark,Flink。
在 Yarn 框架中,调度器是一块很重要的内容。有了合适的调度规则,就可以保证多个应用在同一时间有条不紊的工作。
最原始的调度规则就是 FIFO,即按照用户提交任务的时间来决定哪个任务先执行,但是这样很可能一个大任务独占资源,其他的资源需要不断的等待,也可能一堆小任务占用资源,大任务一直无法得到适当的资源,造成饥饿。所以 FIFO 虽然很简单,但是并不能满足我们的需求。
如下图所示,在 Yarn 中有三种调度器可以选择:FIFO Scheduler,Capacity Scheduler,Fair Scheduler。
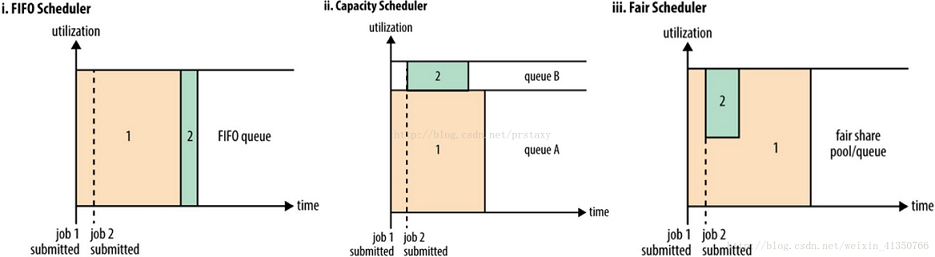
FIFO Scheduler
把应用按提交的顺序排成一个先进先出队列,在进行资源分配的时候,先给队列中最头部的应用进行分配资源,等到最头部的应用需求满足后再给下一个分配,以此类推。
FIFO Scheduler 是最简单也是最容易理解的调度器,它不需要任何配置,但不适用于共享集群中。大的应用可能会占用所有集群资源,从而导致其它应用被阻塞。
Capacity 调度器
允许多租户安全的共享集群资源,提供的核心理念就是 Queues(队列),它支持多个队列,每个队列可配置一定的资源量,以确保在其他 queues 允许使用空闲资源之前,资源可以在一个组织的 sub-queues 之间共享,且每个队列采用 FIFO 调度策略。为了在共享资源上,提供更多的控制和预见性,applications 在容量限制之下,可以及时的分配资源。
Fair 调度器
在 Fair 调度器中,我们不需要预先占用一定的系统资源,Fair 调度器会为所有运行的 job 动态的调整系统资源。当第一个大 job 提交时,只有这一个 job 在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair 调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
需要注意的是,从第二个任务提交到获得资源会有一定的延迟,因为它需要等待第一个任务释放占用的 Container。小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。最终的效果就是 Fair 调度器既得到了高的资源利用率又能保证小任务及时完成。
EasyMR 如何管理 Yarn 资源队列
最原始的调度规则就是 FIFO,即按照用户提交任务的时间来决定哪个任务先执行,但是这样可能会导致一个大任务独占资源,其他的资源需要不断的等待,也可能导致一堆小任务占用资源,大任务一直无法得到适当的资源,造成饥饿。
所以 FIFO 虽然很简单,但是并不能满足我们的需求。最常使用的是容量调度策略,但是运维人员在配置容量队列时,需要考虑队列资源利用率,队列的状态,修改完成后,亦无法校验配置是否正确。
EasyMR 出于简单高效原则,开放了资源队列管理功能。
以容量调度为例,为大家简单演示 EasyMR 中队列的使用。假设公司有个大数据部门,该部门下有个做数据同步的小组,队列树形图如下:
root
├── bigdata
|---dataSync
要创建这样层次的队列,首先需要在父级别下面创建 bigdata 队列,然后在 bigdata 下面划分一个子队列 dataSync,下文进行详细介绍。
创建队列
首先创建父队列 bigdata,设置最小容量20%,最大容量50%。
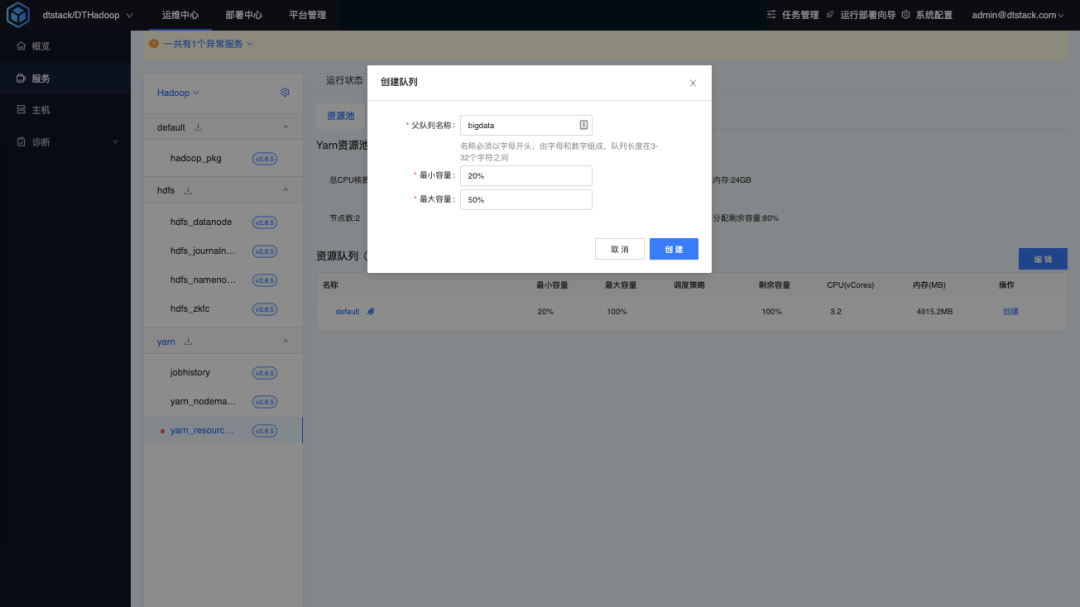
在父队列中添加 bigdata 队列名称。
yarn.scheduler.capacity.root.queues
default,bigdata
设置 bigdata 的容量调度配置。
yarn.scheduler.capacity.root.bigdata.capacity
20
yarn.scheduler.capacity.root.bigdata.maximum-capacity
50
yarn.scheduler.capacity.root.bigdata.user-limit-factor
1
yarn.scheduler.capacity.root.bigdata.state
RUNNING
创建子队列
在 bigdata 父队列下面,选择创建子队列,设置最小容量10%,最大容量30%。
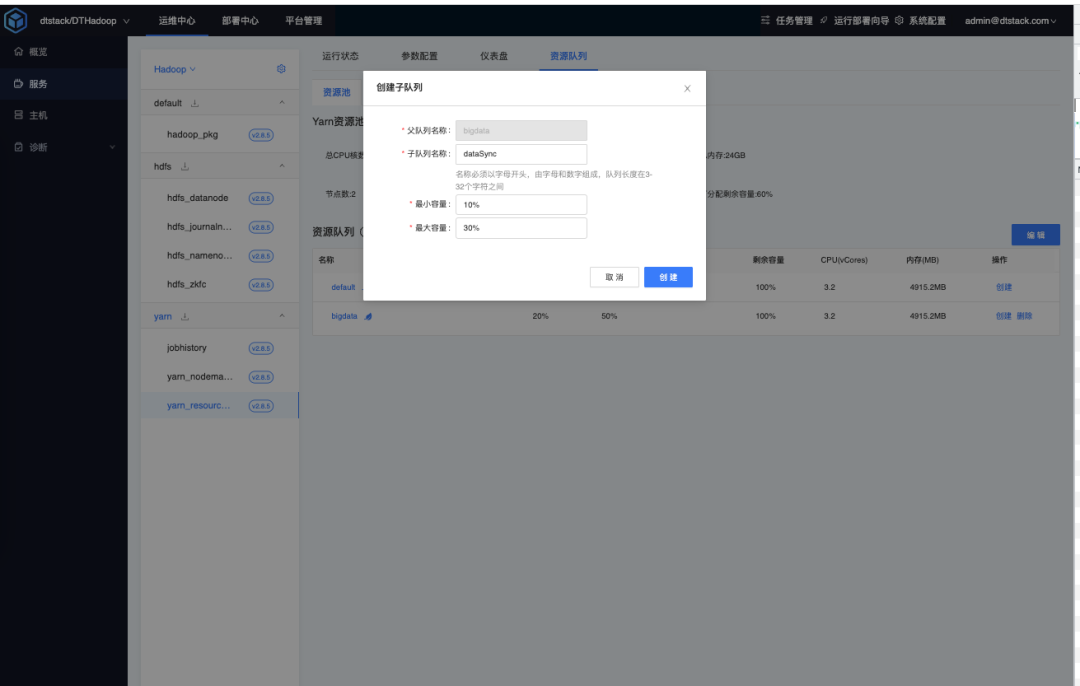
在 bigdata 队列中添加 dataSync 队列名。
yarn.scheduler.capacity.root.bigdata.queues
dataSync
设置 dataSync 队列的容量调度配置。
yarn.scheduler.capacity.root.bigdata.dataSync.capacity
10
yarn.scheduler.capacity.root.bigdata.dataSync.maximum-capacity
30
yarn.scheduler.capacity.root.bigdata.dataSync.user-limit-factor
1
yarn.scheduler.capacity.root.bigdata.dataSync.state
RUNNING
查看队列
创建完成后,可以在 EasyMR 资源队列查看队列详情。
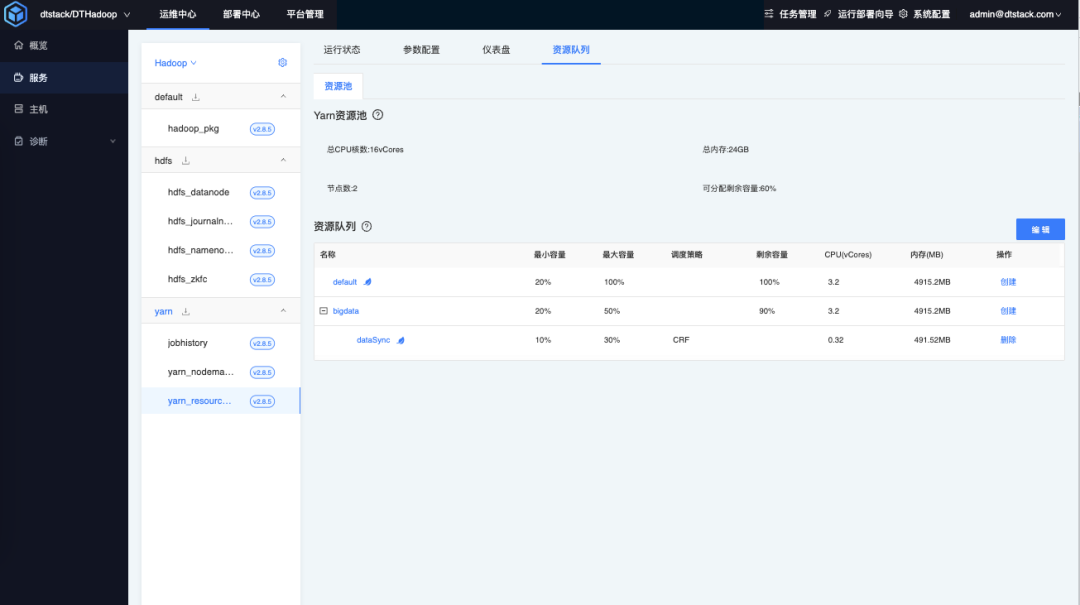
在 EasyMR 创建完成后,也可以在 yarn web 管理页面查看队列创建详情。
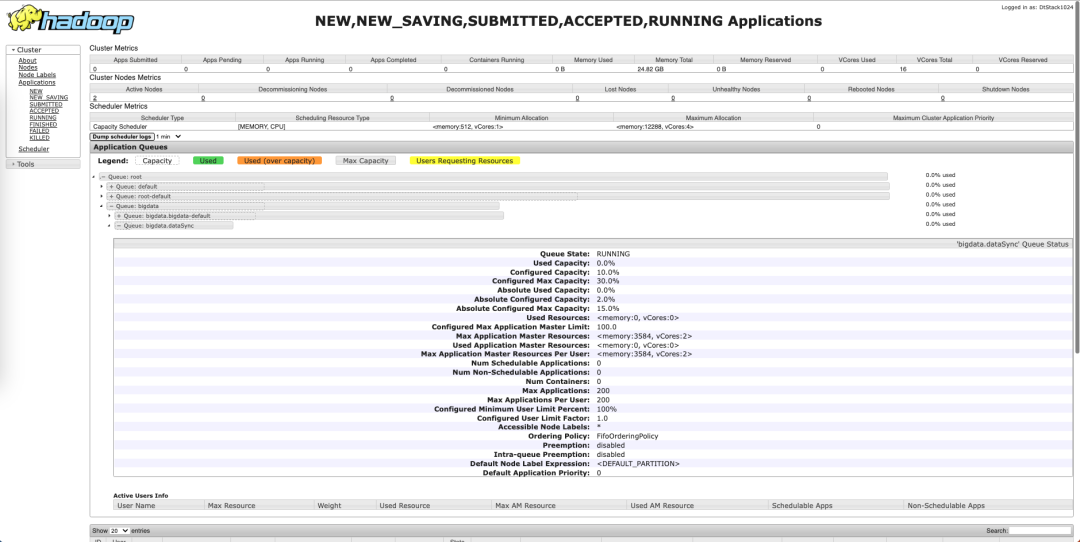
至此,Yarn 的一个简单容量调度就创建完成了。
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm 想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szkyzg
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
