

作者:
vivo 互联网服务器团队 – Liu Zhen、Ye Wenhao
服务器内存问题是影响应用程序性能和稳定性的重要因素之一,需要及时排查和优化。本文介绍了某核心服务内存问题排查与解决过程。首先在JVM与大对象优化上进行了有效的实践,其次在故障转移与大对象监控上提出了可靠的落地方案。最后,总结了内存优化需要考虑的其他问题。
一、问题描述
音乐业务中,core服务主要提供歌曲、歌手等元数据与用户资产查询。随着元数据与用户资产查询量的增长,一些JVM内存问题也逐渐显露,例如GC频繁、耗时长,在高峰期RPC调用超时等问题,导致业务核心功能受损。
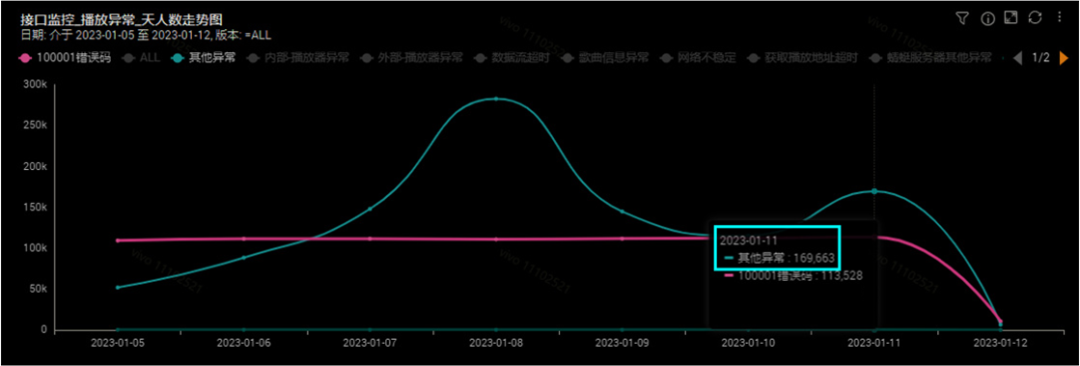
图1 业务异常数量变化
二、分析与解决
通过对日志,机器CPU、内存等监控数据分析发现:
YGC平均每分钟次数12次,峰值为24次,平均每次的耗时在327毫秒。FGC平均每10分钟0.08次,峰值1次,平均耗时30秒。可以看到GC问题较为突出。
在问题期间,机器的CPU并没有明显的变化,但是堆内存出现较大异常。图2,黄色圆圈处,内存使用急速上升,FGC变的频繁,释放的内存越来越少。
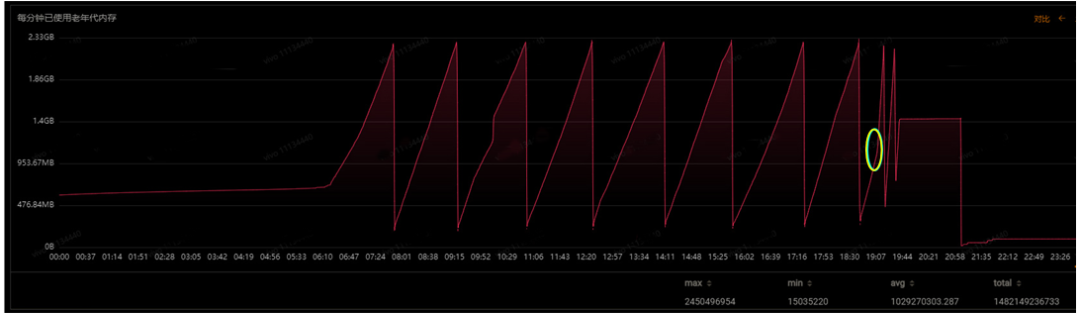
图2 老年代内存使用异常
因此,我们认为业务功能异常是机器的内存问题导致的,需要对服务的内存做一次专项优化。
步骤1 JVM优化
以下是默认的JVM参数:
-Xms4096M -Xmx4096M -Xmn1024M -XX:MetaspaceSize=256M -Djava.security.egd=file:/dev/./urandom -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data/{runuser}/logs/other如果不指定垃圾收集器,那么JDK 8默认采用的是Parallel Scavenge(新生代) +Parallel Old(老年代),这种组合在多核CPU上充分利用多线程并行的优势,提高垃圾回收的效率和吞吐量。但是,由于采用多线程并行方式,会造成一定的停顿时间,不适合对响应时间要求较高的应用程序。然而,core这类的服务特点是对象数量多,生命周期短。在系统特点上,吞吐量较低,要求时延低。因此,默认的JVM参数并不适合core服务。
根据业务的特点和多次对照实验,选择了如下参数进行JVM优化(4核8G的机器)。该参数将young区设为原来的1.5倍,减少了进入老年代的对象数量。将垃圾回收器换成ParNew+CMS,可以减少YGC的次数,降低停顿时间。此外还开启了CMSScavengeBeforeRemark,在CMS的重新标记阶段进行一次YGC,以减少重新标记的时间。
-Xms4096M -Xmx4096M -Xmn1536M -XX:MetaspaceSize=256M -XX:+UseConcMarkSweepGC -XX:+CMSScavengeBeforeRemark -Djava.security.egd=file:/dev/./urandom -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data/{runuser}/logs/other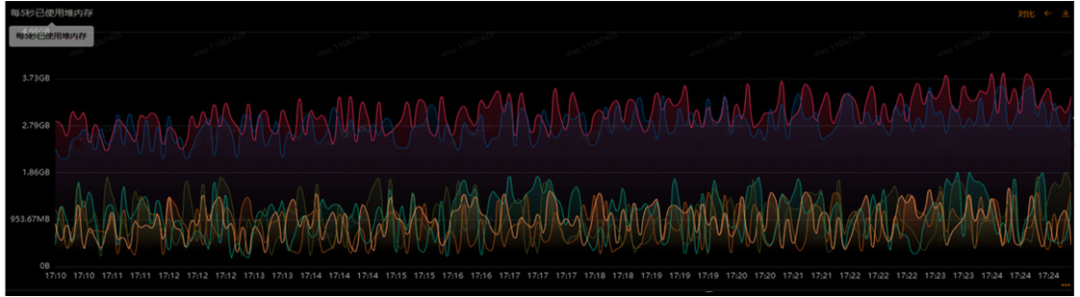
图3 JVM优化前后的堆内存对比
优化后效果如图3,堆内存的使用明显降低,但是Dubbo超时仍然存在。
我们推断,在业务高峰期,该节点出现了大对象晋升到了老年代,导致内存使用迅速上升,并且大对象没有被及时回收。那如何找到这个大对象及其产生的原因呢?为了降低问题排查期间业务的损失,提出了临时的故障转移策略,尽量降低异常数量。
步骤2 故障转移策略
在api服务调用core服务出现异常时,将出现异常的机器ip上报给监控平台。然后利用监控平台的统计与告警能力,配置相应的告警规则与回调函数。当异常触发告警,通过配置的回调函数将告警ip传递给api服务,此时api服务可以将core服务下的该ip对应的机器视为“故障”,进而通过自定义的故障转移策略(实现Dubbo的AbstractLoadBalance抽象类,并且配置在项目),自动将该ip从提供者集群中剔除,从而达到不去调用问题机器。图 4 是整个措施的流程。在该措施上线前,每当有机器内存告警时,将会人工重启该机器。
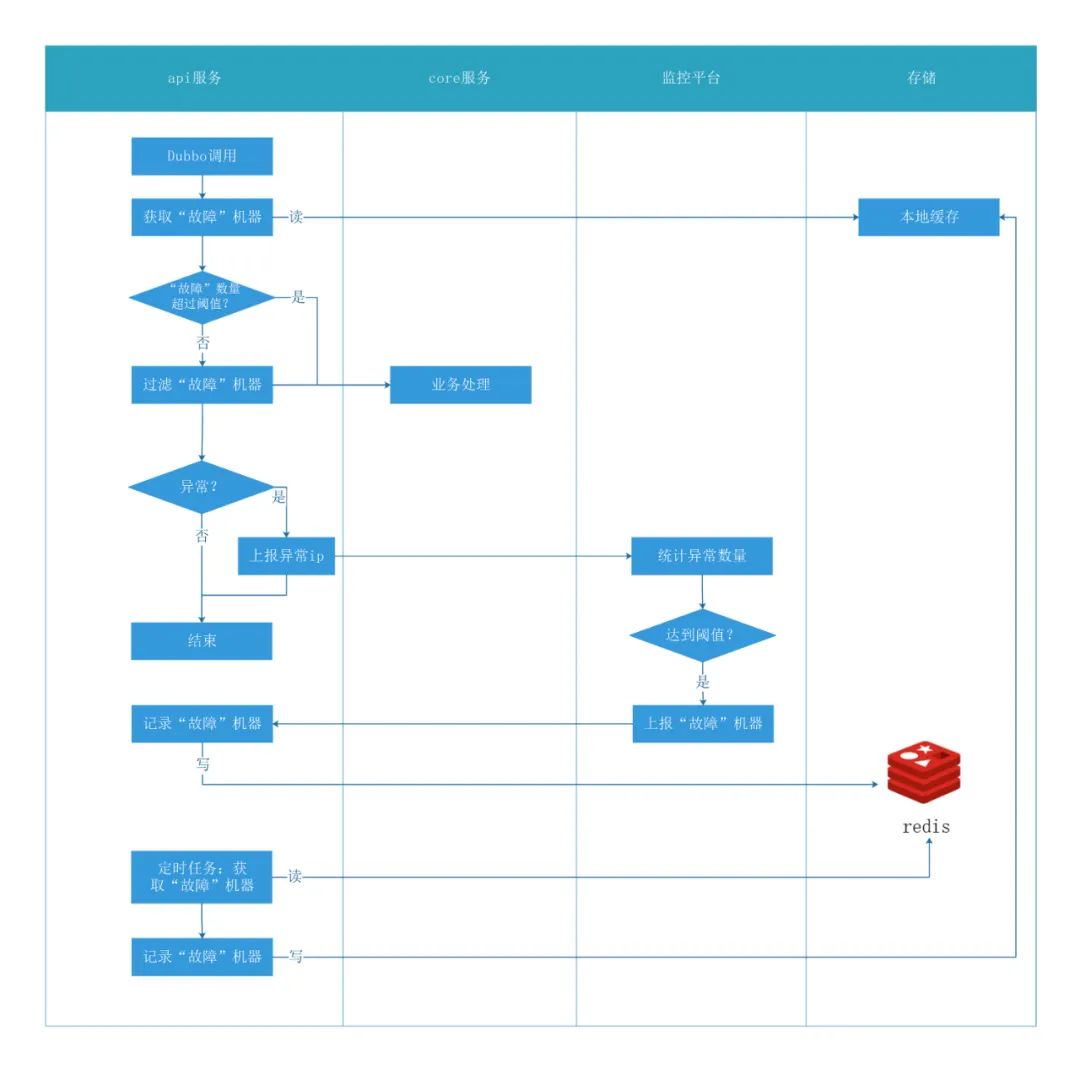
图4 故障转移策略
步骤3 大对象优化
大对象占用了较多的内存,导致内存空间无法被有效利用,甚至造成OOM(Out Of Memory)异常。在优化过程中,先是查看了异常期间的线程信息,然后对堆内存进行了分析,最终确定了大对象身份以及产生的接口。
(1) Dump Stack 查看线程
从监控平台上Dump Stack文件,发现一定数量的如下线程调用。
Thread 5612: (state = IN_JAVA)- org.apache.dubbo.remoting.exchange.codec.ExchangeCodec.encodeResponse(org.apache.dubbo.remoting.Channel, org.apache.dubbo.remoting.buffer.ChannelBuffer, org.apache.dubbo.remoting.exchange.Response) @bci=11, line=282 (Compiled frame; information may be imprecise)- org.apache.dubbo.remoting.exchange.codec.ExchangeCodec.encode(org.apache.dubbo.remoting.Channel, org.apache.dubbo.remoting.buffer.ChannelBuffer, java.lang.Object) @bci=34, line=73 (Compiled frame)- org.apache.dubbo.rpc.protocol.dubbo.DubboCountCodec.encode(org.apache.dubbo.remoting.Channel, org.apache.dubbo.remoting.buffer.ChannelBuffer, java.lang.Object) @bci=7, line=40 (Compiled frame)- org.apache.dubbo.remoting.transport.netty4.NettyCodecAdapter$InternalEncoder.encode(io.netty.channel.ChannelHandlerContext, java.lang.Object, io.netty.buffer.ByteBuf) @bci=51, line=69 (Compiled frame)- io.netty.handler.codec.MessageToByteEncoder.write(io.netty.channel.ChannelHandlerContext, java.lang.Object, io.netty.channel.ChannelPromise) @bci=33, line=107 (Compiled frame)- io.netty.channel.AbstractChannelHandlerContext.invokeWrite0(java.lang.Object, io.netty.channel.ChannelPromise) @bci=10, line=717 (Compiled frame)- io.netty.channel.AbstractChannelHandlerContext.invokeWrite(java.lang.Object, io.netty.channel.ChannelPromise) @bci=10, line=709 (Compiled frame)...
state = IN_JAVA 表示Java虚拟机正在执行Java程序。从线程调用信息可以看到,Dubbo正在调用Netty,将输出写入到缓冲区。此时的响应可能是一个大对象,因而在对响应进行编码、写缓冲区时,需要耗费较长的时间,导致抓取到的此类线程较多。另外耗时长,也即是大对象存活时间长,导致full gc 释放的内存越来越小,空闲的堆内存变小,这又会加剧full gc 次数。
这一系列的连锁反应与图2相吻合,那么接下来的任务就是找到这个大对象。
(2)Dump Heap 查看内存
对core服务的堆内存进行了多次查看,其中比较有代表性的一次快照的大对象列表如下,
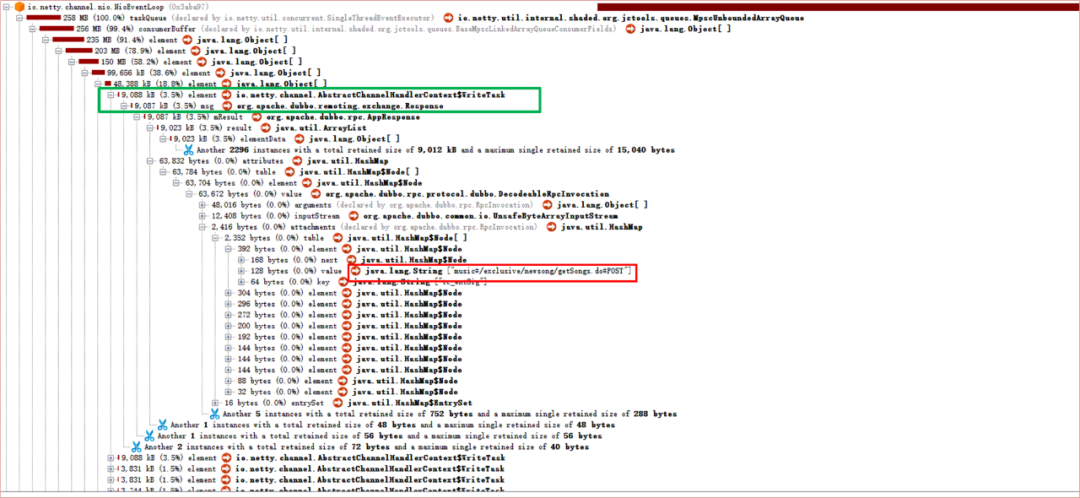
图5 core服务的堆内存快照
整个Netty的taskQueue有258MB。并且从图中绿色方框处可以发现,单个的Response竟达到了9M,红色方框处,显示了调用方的服务名以及URI。
进一步排查,发现该接口会通过core服务查询大量信息,至此基本排查清楚了大对象的身份以及产生原因。
(3)优化结果
在对接口进行优化后,整个core服务也出现了非常明显的改进。YGC全天总次数降低了76.5%,高峰期累计耗时降低了75.5%。FGC三天才会发生一次,并且高峰期累计耗时降低了90.1%。
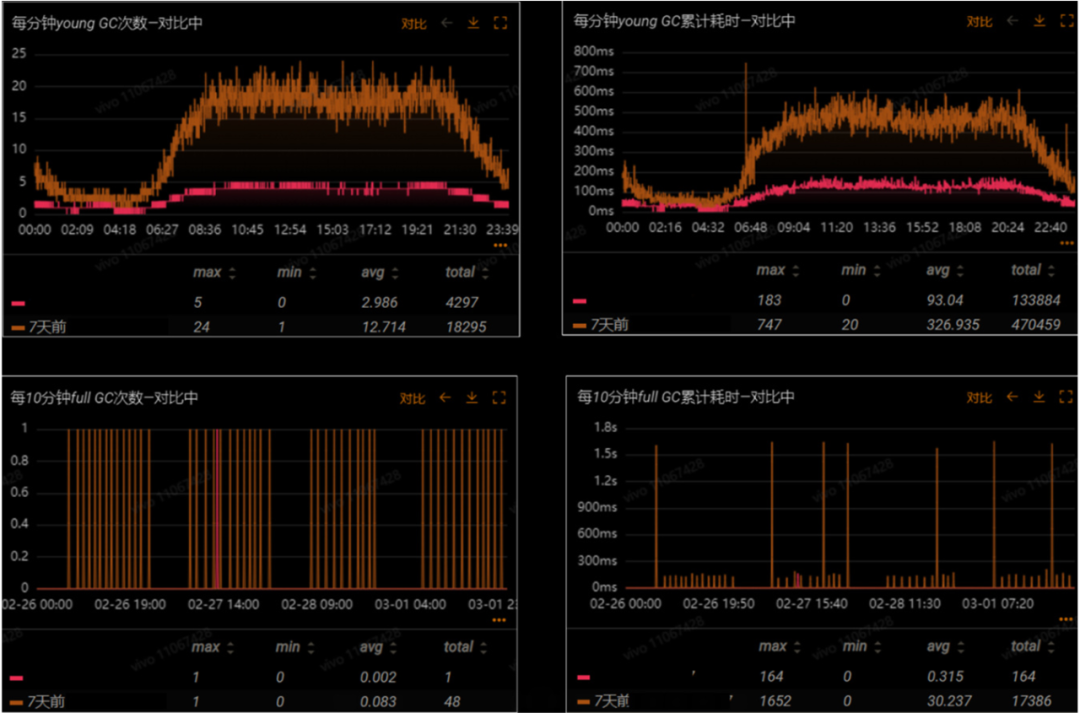
图6 大对象优化后的core服务GC情况
尽管优化后,因内部异常导致获取核心业务失败的异常请求数显著减少,但是依然存在。为了找到最后这一点异常产生的原因,我们打算对core服务内存中的对象大小进行监控。

图7 系统内部异常导致核心业务失败的异常请求数
步骤4 无侵入式内存对象监控
Debug Dubbo 源码的过程中,发现在网络层,Dubbo通过encodeResponse方法对响应进行编码并写入缓冲区,通过checkPayload方法去检查响应的大小,当超过payload时,会抛出ExceedPayloadLimitException异常。在外层对异常进行了捕获,重置buffer位置,而且如果是ExceedPayloadLimitException异常,重新发送一个空响应,这里需要注意,空响应没有原始的响应结果信息,源码如下。
//org.apache.dubbo.remoting.exchange.codec.ExchangeCodec#encodeResponseprotected void encodeResponse(Channel channel, ChannelBuffer buffer, Response res) throws IOException {//...省略部分代码try {//1、检查响应大小是否超过 payload,如果超过,则抛出ExceedPayloadLimitException异常checkPayload(channel, len);} catch (Throwable t) {//2、重置bufferbuffer.writerIndex(savedWriteIndex);//3、捕获异常后,生成一个新的空响应Response r = new Response(res.getId(), res.getVersion());r.setStatus(Response.BAD_RESPONSE);//4、ExceedPayloadLimitException异常,将生成的空响应重新发送一遍if (t instanceof ExceedPayloadLimitException) {r.setErrorMessage(t.getMessage());channel.send(r);return;}}}//org.apache.dubbo.remoting.transport.AbstractCodec#checkPayloadprotected static void checkPayload(Channel channel, long size) throws IOException {int payload = getPayload(channel);boolean overPayload = isOverPayload(payload, size);if (overPayload) {ExceedPayloadLimitException e = new ExceedPayloadLimitException("Data length too large: " + size + ", max payload: " + payload + ", channel: " + channel);logger.error(e);throw e;}}
受此启发,自定义了编解码类(实现org.apache.dubbo.remoting.Codec2接口,并且配置在项目),去监控超出阈值的对象,并打印请求的详细信息,方便排查问题。在具体实现中,如果特意去计算每个对象的大小,那么势必是对服务性能造成影响。经过分析,采取了和checkPayload一样的方式,根据编码前后buffer的writerIndex位置去判断有没有超过设定的阈值。代码如下。
/*** 自定义dubbo编码类**/public class MusicDubboCountCodec implements Codec2 {/*** 异常响应池:缓存超过payload大小的responseId*/private static Cache EXCEED_PAYLOAD_LIMIT_CACHE = Caffeine.newBuilder()// 缓存总条数.maximumSize(100)// 过期时间.expireAfterWrite(300, TimeUnit.SECONDS)// 将value设置为软引用,在OOM前直接淘汰.softValues().build();public void encode(Channel channel, ChannelBuffer buffer, Object message) throws IOException {//1、记录数据编码前的buffer位置int writeBefore = null == buffer ? 0 : buffer.writerIndex();//2、调用原始的编码方法dubboCountCodec.encode(channel, buffer, message);//3、检查&记录超过payload的信息checkOverPayload(message);//4、计算对象长度int writeAfter = null == buffer ? 0 : buffer.writerIndex();int length = writeAfter - writeBefore;//5、超过告警阈值,进行日志打印处理warningLengthTooLong(length, message);}//校验response是否超过payload,超过了,缓存idprivate void checkOverPayload(Object message){if(!(message instanceof Response)){return;}Response response = (Response) message;//3.1、新的发送过程:通过状态码BAD_RESPONSE与错误信息识别出空响应,并记录响应idif(Response.BAD_RESPONSE == response.getStatus() && StrUtil.contains(response.getErrorMessage(), OVER_PAYLOAD_ERROR_MESSAGE)){EXCEED_PAYLOAD_LIMIT_CACHE.put(response.getId(), response.getErrorMessage());return;}//3.2、原先的发送过程:通过异常池识别出超过payload的响应,打印有用的信息if(Response.OK == response.getStatus() && EXCEED_PAYLOAD_LIMIT_CACHE.getIfPresent(response.getId()) != null){String responseMessage = getResponseMessage(response);log.warn("dubbo序列化对象大小超过payload,errorMsg is {},response is {}", EXCEED_PAYLOAD_LIMIT_CACHE.getIfPresent(response.getId()),responseMessage);}}}
在上文中提到,当捕获到超过payload的异常时,会重新生成空响应,导致失去了原始的响应结果,此时再去打印日志,是无法获取到调用方法和入参的,但是encodeResponse方法步骤4中,重新发送这个Response,给了我们机会去获取到想要的信息,因为重新发送意味着会再去走一遍自定义的编码类。
假设有一个超出payload的请求,执行到自定编码类encode方法的步骤2(Dubbo源码中的编码方法),在这里会调用encodeResponse方法重置buffer,发送新的空响应。
(1)当这个新的空响应再次进入自定义encode方法,执行 checkOverPayload方法的步骤3.1时,就会记录异常响应的id到本地缓存。由于在encodeResponse中buffer被重置,无法计算对象的大小,所以步骤4、5不会起到实际作用,就此结束新的发送过程。
(2)原先的发送过程回到步骤2 继续执行,到了步骤3.2 时,发现本地缓存的异常池中有当前的响应id,这时就可以打印调用信息了。
综上,对于大小在告警阈值和payload之间的对象,由于响应信息成功写入了buffer,可以直接进行大小判断,并且打印响应中的关键信息;对于超过payload的对象,在重新发送中记录异常响应id到本地,在原始发送过程中访问异常id池识别是否是异常响应,进行关键信息打印。
在监控措施上线后,通过日志很快速的发现了一部分产生大对象的接口,当前也正在根据接口特点做针对性优化。
三、总结
在对服务JVM内存进行调优时,要充分利用日志、监控工具、堆栈信息等,分析与定位问题。尽量降低问题排查期间的业务损失,引入对象监控手段也不能影响现有业务。除此之外,还可以在定时任务、代码重构、缓存等方面进行优化。优化服务内存不仅仅是JVM调参,而是一个全方面的持续过程。
END
猜你喜欢
-
vivo 容器集群监控系统优化之道
-
高效构建 vivo 企业级网络流量分析系统
-
HBase Compaction 原理与线上调优实践
本文分享自微信公众号 – vivo互联网技术(vivoVMIC)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
