

作者 | 我爱吃海米
导读
移动端开发中,IO密集问题在很多时候没有得到充足的重视和解决,贸然的把IO导致的卡顿放到异步线程,可能会导致真正的问题被掩盖,前人挖坑后人踩。其实首先要想的是,数据存储方式是否合理,数据的使用方式是否合理。本文介绍度加剪辑对MMKV的使用和优化。
全文14813字,预计阅读时间38分钟。
01 一切皆文件-移动端IO介绍
移动端的App程序很多情况是IO密集型,比如说聊天信息的读取和发送、短视频的下载和缓存、信息流应用的图文缓存等。
相对于计算密集,IO密集场景更加多样,比如系统SharedPreferences和NSUserDefault自带的一些问题、Android中繁忙的binder通信、文件磁盘读取和写入、文件句柄泄露、主线程操作Sqlite导致的卡顿等,处理起来相当烫手。
IO不繁忙的情况下,主线程低频次的调用IO函数是没什么问题的。然而在IO繁忙时,IO性能急剧退化,任何IO操作都可能是压死骆驼的最后一根稻草。在平常开发测试中很难遇到IO卡顿,到了线上后才会暴露出来,iOS/Android双端基本都是如此:常用的open系统调用,线下测试只需要4ms,线上大把用户执行时间超过10秒;就连获取文件长度、检查文件是否存在这种常规操作,竟然也能卡顿。
以Android线上抓到的卡顿为例(>5秒):
at libcore.io.Linux.access(Native Method)
at libcore.io.ForwardingOs.access(ForwardingOs.java:128)
at libcore.io.BlockGuardOs.access(BlockGuardOs.java:76)
at libcore.io.ForwardingOs.access(ForwardingOs.java:128)
at android.app.ActivityThread$AndroidOs.access(ActivityThread.java:8121)
at java.io.UnixFileSystem.checkAccess(UnixFileSystem.java:281)
at java.io.File.exists(File.java:813)
at com.a.b.getDownloaded(SourceFile:2)
at libcore.io.Linux.stat(Native Method)
at libcore.io.ForwardingOs.stat(ForwardingOs.java:853)
at libcore.io.BlockGuardOs.stat(BlockGuardOs.java:420)
at libcore.io.ForwardingOs.stat(ForwardingOs.java:853)
at android.app.ActivityThread$AndroidOs.stat(ActivityThread.java:8897)
at java.io.UnixFileSystem.getLength(UnixFileSystem.java:298)
at java.io.File.length(File.java:968)
具体源码可以参考 :
https://android.googlesource.com/platform/libcore/+/master/luni/src/main/native/libcore_io_Linux.cpp
最终是在C++中发起了系统调用access()和stat()。
IO问题在很多时候被轻视,贸然的把IO导致的卡顿放到异步线程,可能会导致真正的问题被掩盖,前人挖坑后人踩。其实首先要想的是,数据存储方式是否合理,数据的使用方式是否合理。
作为一款视频剪辑工具,度加剪辑在内存、磁盘、卡顿方面有大量的技术挑战,同时也积累了大量的技术债。我从隔壁做图片美化工具的团队那得到了双端的IO卡顿数据,可以说是难兄难弟,不分伯仲:有卧龙的地方,十步以内必有凤雏。
下面简单介绍度加剪辑App中对文件磁盘IO这部分的使用和优化,本文是有关MMKV。
(广告时间:度加剪辑是一款音视频剪辑软件,针对口播用户开发了很多贴心功能,比如说快速剪辑,各类素材也比较丰富,比如贴纸、文字模板等,欢迎下载使用。)
02 高性能kv神器-MMKV
MMKV是基于mmap的高性能通用key-value组件,性能极佳,让我们在主线程使用kv成为了可能,堪称移动端的Redis,实际上这两者在设计上也能找到相似的影子。
mmap是使用极其广泛的内存映射技术,对内存的读写约等于对磁盘的读写,内存中的字节与文件中的字节相映成趣,一一对应。像Kafka和RocketMQ等消息中间件都使用了mmap,避免了数据在用户态跟内核态大量的拷贝切换, 所谓零拷贝。
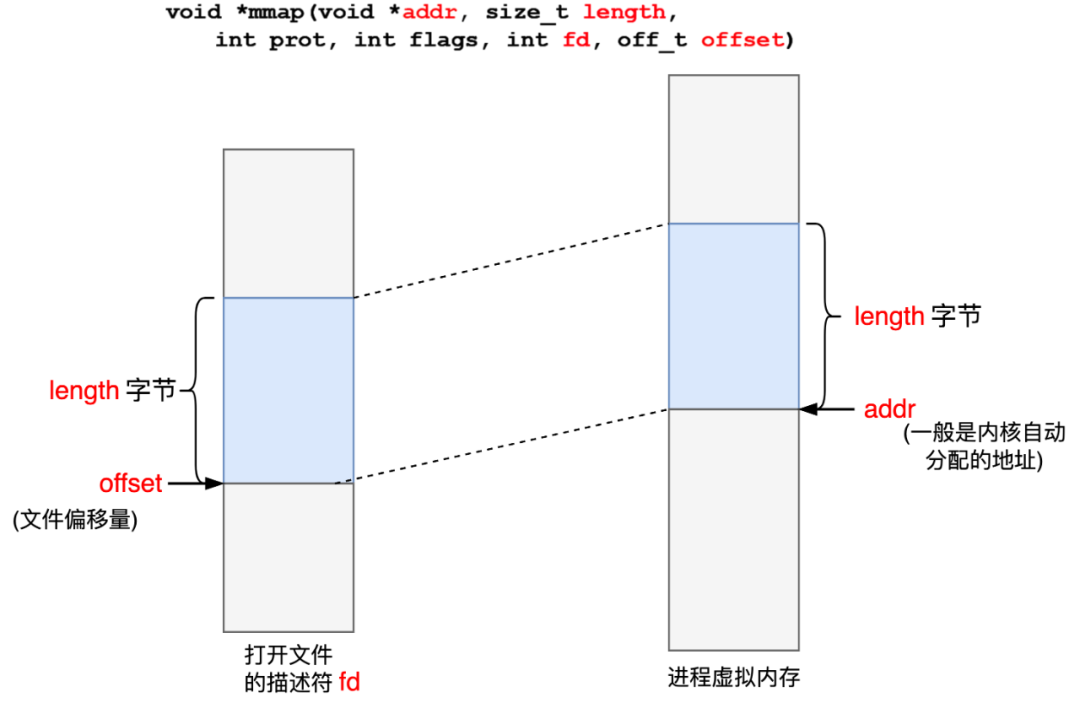
为了提高性能,度加逐渐从SharedPreferences向MMKV迁移,关于Sp的卡顿逐渐消失,性能提升效果十分哇塞。

然而,MMKV依然有不少IO操作发生在主线程,这些函数在用户缓冲区都没有buffer(对比fread和fwrite等f打头的带有缓冲的函数),且磁盘相对是低速设备,同步时效率较低,有时难免会出现性能问题。
度加剪辑作为MMKV的重度甚至变态用户,随着使用越来越频繁,陆续发现了线上很多和MMKV相关的有趣问题,下面抛砖引玉简单介绍。
03 setX/encodeX卡顿-占度加剪辑总卡顿的1.2%
at com.tencent.mmkv.MMKV.encodeString(Native Method)
at com.tencent.mmkv.MMKV.encode(Proguard:8)
经过分析,卡顿基本都发生IO繁忙时刻。度加App在使用中充满了大量的磁盘IO,在编辑页面会读取大量的视频文件、贴纸、字体等各种文件,像降噪、语音转文字等大量场景都需要本地写入;导出页面会在短时间内写入上G的视频到磁盘中:为了保证输出视频的清晰度,度加App设置了极高的视频和音频码率。
不可避免,当磁盘处于大规模写入状态,在视频合成导出、视频文件读取和下载、各类素材的下载过程中很容易发现MMKV卡顿的身影;通过增加研发打点数据以及其他辅助手段后,我大体归纳了两种卡顿发生的典型场景。
1、存储较长的字符串,例如云控json
这个卡顿大部分是MMKV的重写和扩容机制引起,首先简单介绍MMKV的数据存储布局。(https://github.com/Tencent/MMKV/wiki/design)
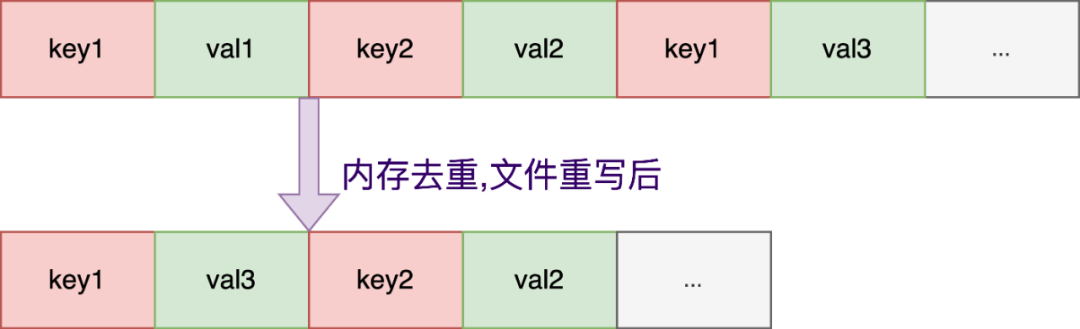
MMKV在创建一个ID时,例如默认的mmkv.default,会为这个ID单独创建两个4K大小(操作系统pagesize值)的文件,存放内容的文件和CRC校验文件。
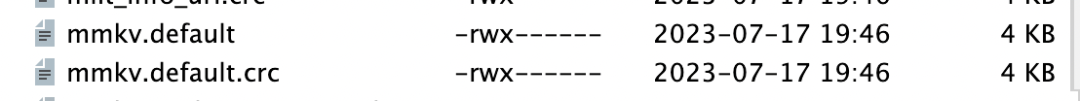
每次插入新的key-value,以append模式在内容文件的尾部追加,取值以最后插入的数据为准,即使是已有相同的key-value,也直接append在文件末尾;key与value交替存储,与Redis的AOF十分类似。
便于理解方便,省去了key长度和value长度等其他字段:
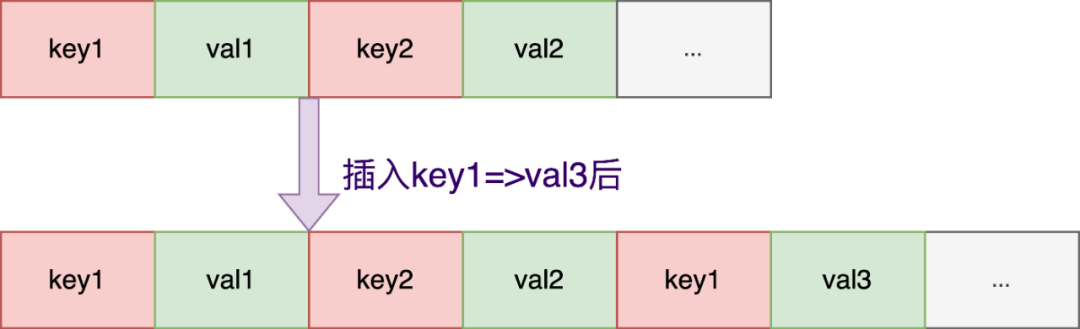
此时MMKV的dict中有两对有效的key=>value数据: {“key1″:”val3”, “key2”, “val2”}
重写:Append模式有个问题,当一个相同的key不断被写入时,整个文件有部分区域是被浪费掉的,因为前面的value会被后面的代替掉,只有最后插入的那组kv对才有效。所以当文件不足以存放新增的kv数据时,MMKV会先尝试对key去重,重写文件以重整布局降低大小,类似Redis的bgrewriteaof。(重写后实际上是key2在前key1在后。)
扩容:在重写文件后,如果空间还是不够,会不断的以2倍大小扩容文件直到满足需要:JAVA中ArrayList的扩容系数是1.5,GCC中std::vector扩容系数是2,MMKV的扩容系数也是2。
size_t oldSize = fileSize;
do {
fileSize *= 2;
} while (lenNeeded + futureUsage >= fileSize);
重写和扩容都会涉及到IO相关的系统调用,重写会调用msync函数强制同步数据到磁盘;而扩容时逻辑更为复杂,系统调用次数更多:
1、ftruncate修改文件的名义大小。
2、修改文件的实际大小。Linux上ftruncate会造成“空洞文件”,而不是真正的去申请磁盘block,在磁盘已满或者没有权限时会有奇怪的错误甚至是崩溃。MMKV不得不使用lseek+write系统调用来保证文件一定扩容成功,测试和确认文件在磁盘中的实际大小,以防止后续MMKV的写入可能出现SIGBUS等错误信号。
3、确认了文件真正的长度满足要求后,调用munmap+mmap,重新对内存和文件建立映射。在解除绑定时,munmap也会同步内存数据脏页到磁盘(msync),这也是个耗时操作。
if (::ftruncate(m_diskFile.m_fd, static_cast(m_size)) != 0) {
MMKVError("fail to truncate [%s] to size %zu, %s", m_diskFile.m_path.c_str(), m_size, strerror(errno));
m_size = oldSize;
return false;
}
if (m_size > oldSize) {
// lseek+write 保证文件一定扩容成功
if (!zeroFillFile(m_diskFile.m_fd, oldSize, m_size - oldSize)) {
MMKVError("fail to zeroFile [%s] to size %zu, %s", m_diskFile.m_path.c_str(), m_size, strerror(errno));
m_size = oldSize;
return false;
}
}
if (m_ptr) {
if (munmap(m_ptr, oldSize) != 0) {
MMKVError("fail to munmap [%s], %s", m_diskFile.m_path.c_str(), strerror(errno));
}
}
auto ret = mmap();
if (!ret) {
doCleanMemoryCache(true);
}
由此可见,MMKV在重写和扩容时,会发生一定次数的系统调用,是个重型操作,在IO繁忙时可能会导致卡顿;而且相比较重写操作,扩容的成本更高,至少有5个IO系统调用,出现性能问题的概率也更大。
所以解决此问题的核心在于,要尽量减少和抑制MMKV的重写和扩容次数,尤其是扩容次数。针对度加App的业务特点,我们做了几点优化。
(1)某些key-value不经常变动(比如云控参数),在写入前先比较是否与原值相同,值不相同再插入数据。 上面提过,即使是已有相同的key-value,也直接append在文件末尾,其实这次插入没有什么用处。但字符串或者内存的比较(strcmp或者memcmp)也需要消耗点资源,所以业务方可以根据实际情况做比较,增加命中率,提高性能。
我从文心一言随机要了一首英文诗,测试30万次的插入性能差异
auto mmkv = [MMKV mmkvWithID:@"test0"];
NSString *key = [NSString stringWithFormat: @"HelloWorld!"];
NSString *value = [NSString stringWithFormat:
@"There are two roads in the forest
One is straight and leads to the light
The other is crooked and full of darkness
Which one will you choose to walk?
The straight road may be easy to follow
But it may lead you to a narrow path
The crooked road may be difficult to navigate
But it may open up a world of possibilities
The choice is yours to make
Decide wisely and with a open heart
Walk the path that leads you to your dreams
And leaves you with no regrets at the end of the day"];
double start = [[NSDate date] timeIntervalSince1970] * 1000;
for(int i = 0; i 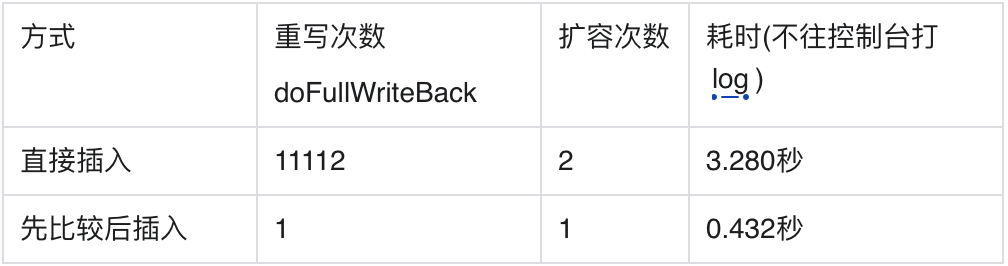
运行环境:MacBook Pro (Retina, 15-inch, Mid 2015) 12.6.5
可见此方案对于值没有任何变化的极端情况,有不小的性能提升。实际在生产环境,尤其是在配置较低的手机设备或磁盘IO繁忙时,这两者的运行时间差距可能会被无限放大。
如果,这个先判断再插入的逻辑,由MMKV来自动完成就更好了;但对于频繁变化的键值对,会多出求value长度和比较字符串内容的“多余操作”,可能小小的影响MMKV的插入性能。目前可以根据自己业务特点和数据变动情况合适选择策略。
或者,MMKV考虑增加一组方法,可以叫个setWithCompare()之类的的名字,如果开发者认为key-value变动的概率不大,可以调用这个函数来降低扩容重写文件的概率。就像C++20新增的likely和unlikely关键字一样,提高命中率,均摊复杂度会变低,综合性价比会变高。
(https://en.cppreference.com/w/cpp/language/attributes/likely)
(2)提前在闲时或者异步时扩容。 这个方案我没在线上试过,但是个可行方案。假如我们能够预估MMKV可能存放数据的大小,那么完全可以在闲时插入一组长度接近的占位key1-value1数据,先扩容好;当插入真正的数据key1-value2时,理想情况下至多触发一次重写,而不会再触发扩容。
腾笼换鸟。
MMKV *mmkv = [MMKV mmkvWithID:@"mmkv_id1"];
NSString *s = [NSString stringWithFormat:@""];
for (int i = 0; i 其实说到这,就不难想到,这个思路跟Java中的ArrayList,或者STL中的vector的有参构造函数是一个意思,既然已经知道要存放数据的大体量级了,那么在初始化的时候不妨直接就一次性的申请好,没必要再不断的*2去扩容了。
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
// 3. 构造函数将n个elem拷贝给容器本身
vector v3(10, 2);
printV(v3);
// 2 2 2 2 2 2 2 2 2 2
目前MMKV默认创建时都是先创建4K的文件,就算我们明确知道要插入的是100K的数据,也丝毫没有办法,只能忍受一次扩从4K->128K的扩容。如果能支持构造器中直接指定预期文件大小,好像是更好的方案。
mmkv::getFileSize(m_fd, m_size);
// round up to (n * pagesize)
if (m_size 于是向MMKV提了pr,构造函数支持设置文件初始大小 (https://github.com/Tencent/MMKV/discussions/1135) pr_(https://github.com/Tencent/MMKV/pull/1138/files)_
插一句,MMKV支持的平台很多,包括Android、iOS、Flutter、Windows、POSIX(Linux/UNIX/MacOS)等,哪怕想加一个小小的功能,也得花上不少时间去测试:光凑齐这么多测试设备,也不是一件很容易的事儿。
说到底,MMKV毕竟不是为大kv设计的方案。不是他不优秀,实在是老铁的要求太多了。
(3)使用gzip等压缩数据,大幅降低重写和扩容概率。
(4)大字符串或者数据从MMKV切换成数据库,异步处理。
(3)和(4)在下章深入描述。
2、新ID第一次存储key-value数据
这个问题困扰了我很久。原本以为,只有长字符串才会导致卡顿,但万万没想到,不到50字节的key-value也会频繁的卡顿,实在是让人费解。有时候想直接把他丢到异步线程算了,但又有点不甘心。于是我又胡乱添加了几个研发打点,发版后经过瞎分析,一个有趣的现象引起了我的注意:卡顿基本都发生在某个MMKV_ID的第一次写入,也就是文件内容(key-value对)从0到1的过程。
为什么?
我怀疑是某个IO的系统调用导致的卡顿,借助frida神器,我在demo中用撞大运式编程法挨个尝试,有了新发现:这个过程竟然出现了msync系统调用。上面说过,mmap能够建立文件和内存的映射,由操作系统负责数据同步。但有些时候我们想要磁盘立刻马上去同步内存的信息,就需要主动调用msync来强制同步,这是个耗时操作,在IO繁忙时会导致卡顿。

在分析MMKV源码,断点调试和增加log后,我基本确定这是MMKV的“特性”:MMKV在文件长度不足、或者是clear所有的key时(clearAll())会主动的重写文件。其中在从0到1时第一次插入key-value时,会误触发一次msync。
优化代码:(https://github.com/Tencent/MMKV/discussions/1136)和pr(https://github.com/Tencent/MMKV/pull/1110/files),这个优化可能在一段时间后随新版本发出。
msync() flushes changes made to the in-core copy of a file that
was mapped into memory using mmap(2) back to the filesystem.
Without use of this call, there is no guarantee that changes are
written back before munmap(2) is called.
考虑到老版本的升级周期问题,这个bug还可以用较为trick的方式规避: 在MMKV_ID创建时,趁着IO空闲时不注意,赶紧写入一组小的占位数据,提前走通从0到1的过程。这样在IO繁忙时就不会再执行msync。
// 保证至少有一个key-value
if (!TextUtils.equals(mmkv.decodeString("a")), "b") {
mmkv.encodeString("a", "b");
}
这段“垃圾代码”提交后迅速喜迎好几个code review的 -1,求爹告奶后总算是通过了。好在上线后,这个卡顿几乎销声匿迹:就算是一张卫生纸都有它的用处,更何况是几行垃圾代码呢。
另外,继续追查卡顿时,发现了另外十分有趣的bug:第一次插入500左右字节的数据,会引发一次多余的扩容。也一并修复
issue_(https://github.com/Tencent/MMKV/issues/1120 )和pr(https://github.com/Tencent/MMKV/pull/1121/files)_
而且我还有新的发现:很多同学因为编程习惯问题以及对MMKV不了解,度加剪辑有很多MMKV_ID只包含一组(key=>value),存在巨大浪费。上面说过,每个MMKV_ID都对应着两个4K的文件,不仅占据了8K的磁盘,还消耗了8K的内存,其实里面就存着几十字节的内容。更合理的做法是做好统一规范和管理,根据业务场景的划分来创建对应的MMKV实例,数量不能太多也不能太少,更不是想在哪创建就在哪创建。
度加剪辑存在很多一个ID里就存放一对key=>value的情况,需要统一治理。
04 getMMKV卡顿—占度加总卡顿的0.5%
at com.tencent.mmkv.MMKV.getMMKVWithID(Native Method)
at com.tencent.mmkv.MMKV.mmkvWithID(Proguard:2)
此卡顿也大多发生在IO繁忙时。通过上面提到的frida神器,以及查看源码,MMKV在初始化一个MMKV_ID文件时,会调用lstat检测文件夹是否存在,若不存在就执行mkdir(第一次)创建文件夹。然后调用open函数打开文件,依然可能会导致卡顿。

if (rootPath) {
MMKVPath_t specialPath = (*rootPath) + MMKV_PATH_SLASH + SPECIAL_CHARACTER_DIRECTORY_NAME;
if (!isFileExist(specialPath)) { // lstat系统调用
mkPath(specialPath); // stat和mkdir系统调用
}
MMKVInfo("prepare to load %s (id %s) from rootPath %s", mmapID.c_str(), mmapKey.c_str(), rootPath->c_str());
}
m_fd = ::open(m_path.c_str(), OpenFlag2NativeFlag(m_flag), S_IRWXU);
if (!isFileValid()) {
MMKVError("fail to open [%s], %d(%s)", m_path.c_str(), errno, strerror(errno));
return false;
}
open系统调用在平常测试中基本不怎么耗时,但内部可能存在分配inode节点等操作,在IO繁忙时也可能卡住。无独有偶,我在Sqlite的官网上也看到了一篇关于Sqlite和文件读写性能对比的文章,这里面提到,open、close比read、write的操作更加耗时。

于是我又做了一个测试:
char buf[500 * 1024];
void testOpenCloseAndWrite() {
for (int i = 0; i 1、当只有open/close调用时,在一加8Pro上只创建1000个”空”文件,需要3920ms(多次取平均)。
2、将第14行代码取消注释后,执行write系统调用,写入500k的数据后,共4150ms,也就是说,多出1000次的写操作,只增加了230毫秒,每次写只需要0.23ms,和open比确实是快多了。Sqlite诚不我欺。
3、当文件已经存在,再次执行open系统调用耗时明显要少一些,这也意味着第一次打开MMKV实例时会相对的慢。
度加线上抓到的open系统调用卡顿(libcore辗转反侧,最终执行了open系统调用)
07-29 06:48:47.316
at libcore.io.Linux.open(Native Method)
at libcore.io.ForwardingOs.open(ForwardingOs.java:563)
at libcore.io.BlockGuardOs.open(BlockGuardOs.java:274)
at libcore.io.ForwardingOs.open(ForwardingOs.java:563)
at android.app.ActivityThread$AndroidOs.open(ActivityThread.java:7980)
at libcore.io.IoBridge.open(IoBridge.java:560)
at java.io.FileInputStream.(FileInputStream.java:160)
此问题可以通过预热MMKV解决—在IO不繁忙时提前加载好MMKV(得益于MMKV内部的各种锁,甚至还可以放心大胆的在异步线程初始化,和提前在异步线程加载SharedPreferences一样)。不过要注意,没必要过早加载,尤其是在App刚启动时一股脑的初始化了所有的MMKV_ID。对于使用频率不高的ID,毕竟加载MMKV也就意味着内存的浪费,也意味着占据着一个文件句柄。举个栗子,某些ID只在度加剪辑的导出视频后使用,我们不妨就在刚进入导出页面时去预热,而不是在进程创建的时候或者MainActivity创建的时候加载,太早了会浪费内存。
来得早不如来得巧。
05 存储膨胀-MMKV不是数据库
在排查其他线上问题时,偶然发现了两个不当使用MMKV的情况:
第一是只增不删,key=>value只增不减;这种情况会导致大量垃圾数据产生,对内存消耗和磁盘占用都是浪费。下一篇会重点说说及时清理空间的问题,这里不再赘述。
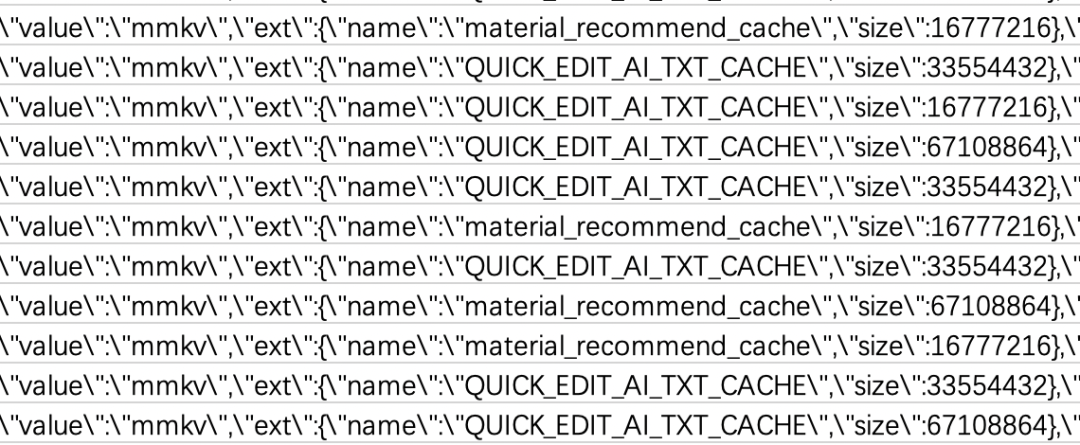
第二是用MMKV存储大量缓存数据,导致文件很大,通过分析研发打点数据,不少用户的MMKV文件体积最大的有512M了!
此外,MMKV为了避免频繁的扩容,会根据平均的key-value长度,预留至少8个键值对的空间,这也加重了内存和文件的空间冗余:
auto sizeOfDic = preparedData.second;
size_t lenNeeded = sizeOfDic + Fixed32Size + newSize;
size_t dicCount = m_crypter ? m_dicCrypt->size() : m_dic->size();
size_t avgItemSize = lenNeeded / std::max(1, dicCount);
// 预留至少8个键值对的空间
size_t futureUsage = avgItemSize * std::max(8, (dicCount + 1) / 2);
度加之前是把语音转字幕的识别结果(ID:QUICK_EDIT_AI_TXT_CACHE)放到了MMKV里缓存,但是从来不会主动删除,只会越来越多;如果不早点处理,积重难返,总有一天App的内存会全部被这些大文件吃掉。
因为MMKV是典型的空间换时间,磁盘大小≈内存大小:磁盘占据着512M,也意味着虚拟内存同时也会增加512M,大幅增加了OOM的风险。
Redis性能瓶颈揭秘:如何优化大key问题?(https://zhuanlan.zhihu.com/p/622474134)其实这这和Redis的大Key问题如出一辙,解决方案也十分类似:压缩数据、数据切割分片、设置过期时间、更换其他数据存储方式。
1、压缩
如果非要将很多大内容存储在MMKV里,对value做压缩可能也是一个不差的选择。
MMKV存储整数等短value采取了类似protobuf的变长整数压缩,比如,一个int整形可以用1-5个字节表示(其实Redis的RDB也用了类似的变长编码,不过看起来和UTF8的思路更为接近),本身来讲,MMKV对pb并没有直接的依赖。
MMKV对字符串没有压缩,将MMKV的二进制文件用vim(vim作者Bram Moolenaar于2023年8月3号去世,致敬大佬)当做文本格式直接打开,还是能看出来key和value都是以字符串的原始形式保存的。
MMKV *mmkv = [MMKV mmkvWithID: @"mm1"];
[mmkv setString: @"This is value" forKey:@"I am Key"];
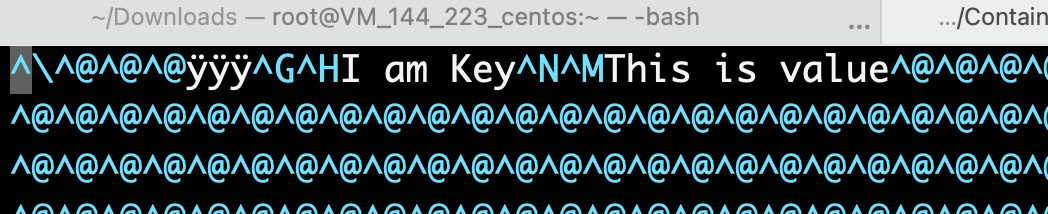
看到这不得不说句容易挨打的话:哪怕是把key改短点,也能很有效的降低扩容概率。比如说度加剪辑某个key,从”key_draft_crash_project_id” 缩短为 “kdcpi”后,就降低了不少卡顿。是的,我试过了确实有效果,但我不建议你这么做,毕竟代码可读性也十分重要。
而Protobuf本身就有对字符串压缩的支持
GzipOutputStream::Options options;
options.format = GzipOutputStream::GZIP;
options.compression_level = _COMPRESSION_LEVEL;
GzipOutputStream gzipOutputStream(&outputFileStream, options);
Redis在保存RDB文件时,也有对字符串的压缩支持,采取的是LZF压缩算法
/* Try LZF compression - under 20 bytes it's unable to compress even
* aaaaaaaaaaaaaaaaaa so skip it */
if (server.rdb_compression && len > 20) {
n = rdbSaveLzfStringObject(rdb,s,len);
if (n == -1) return -1;
if (n > 0) return n;
/* Return value of 0 means data can't be compressed, save the old way */
}
自己动手丰衣足食。
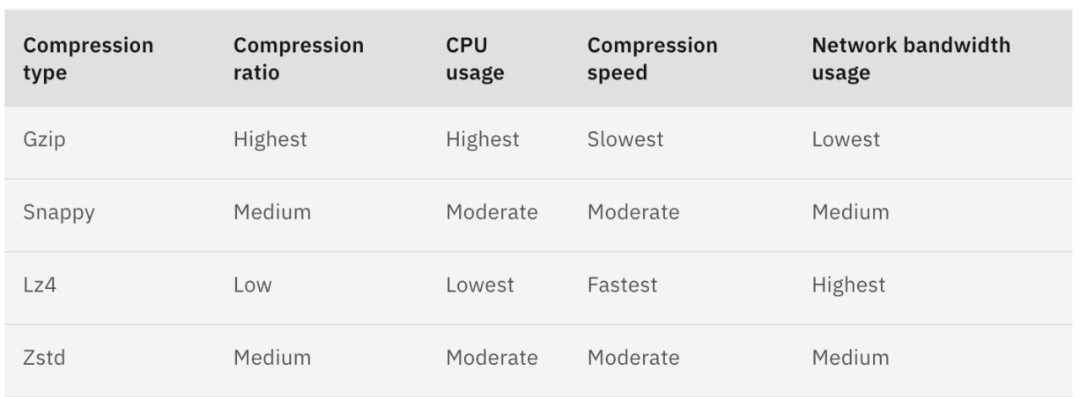
既然MMKV对字符串没有压缩,那就先自己实现。对部分长字符串进行压缩解压后,线上数据显示,文本json的gzip压缩率在9-11倍左右,这就意味着文件体积会缩小至十分之一,并且内存消耗也缩小至十分之一。想象一下,50M的文件在主动压缩后,瞬间变成5M,对磁盘和内存是多么大的解放。当然,压缩和解压缩是消耗CPU资源的操作,一加8Pro上测试,338K的JSON文本使用Java自带的GZIPOutputStream压缩需要4ms,压缩后体积是25K;通过GZIPInputStream解压(注意buffer要设置成4096以上,太少会增加耗时)的时间也是4ms,有一定耗时,但也能接受;看起来,有时候反其道而行之,用时间换空间好像也是值得的!如果想要压缩速度更快,可以换lz4、snappy等压缩算法,但压缩率也会随之降低,应当基于自己的业务特点来选择最合适的压缩算法,在压缩率和压缩速度上找到平衡点。
估计有的同学会有疑问:既然用MMKV是空间换时间,那为什么还要反过来用时间换空间,岂不是瞎折腾,玩儿呢?
关键就在于:
1、IO文件操作作用在磁盘,运行时间不稳定,抽起风来很要命,少则几毫秒,多则几十秒,所以我们愿意用空间换时间来削掉波峰,提升稳定性。
2、而CPU操作的运行时间大体上比较稳定,一般只在CPU由大核切换小核、手机没快电、温度太高、CPU降频等少数情况才会劣化,且劣化趋势不明显,为了节约内存,所以用CPU换空间。
2、设置合理的过期时间。
为大key设置过期时间,以便在数据失效后自动清理,避免长时间累积,尾大不掉。MMKV 1.3.0已经支持了过期设置,到期自动清理。
3、更换数据存储方式,例如Sqlite
用户产生的可无限增长的大规模数据,用数据库(Sqlite等)更加合理。数据库的访问速度相比MMKV虽然要慢,但是内存等资源消耗不大,只要合理运用异步线程并处理好线程冲突的问题,数据库的性能和稳定性也相当靠谱。
度加剪辑对在编辑页面和导出页面对内存的需求较高,我们的内存优化方案也比较激进,大体上遵循了以下4点:
1、不把MMKV当数据库用,复杂和大规模的缓存数据考虑从MMKV切换到Sqlite或者他数据库
2、必须要用MMKV存储字符串等大数据的情况,使用gzip等算法压缩后存储,使用时解压
3、对于只是一次性的读取和写入MMKV,操作完之后及时close该MMKV_ID的实例,以释放虚拟内存
4、MMKV的数据要做到不用的时候立即删除,有始有终。
06 总结
自从切换成MMKV后,就再也不想用Sp了,回忆过去的苦难,回想今天的幸福生活,MMKV带来的这点卡顿,跟Sp导致的卡顿比,就是”小巫见大巫“,直接可以忽略不计。
我分析了应用商店top级别的应用,有不少App在使用MMKV时也多少存在度加剪辑遇到的问题。大家使用MMKV主要存储的内容是云控的参数、以及AB实验的参数(千万不要小瞧,大厂的线上实验贼多,且实验的参数一点也不简单),文件大小超过1M的场景相当的多。
不过让我更为好奇的是,部分头部App既没有引入MMKV,我也没发现类似的二进制映射文件,特别想了解这些顶级App是如何来处理key-value的,十分期待大佬们的分享。
MMKV作为极其优秀的存储组件,最后用这张图片来描述TA与开发者的关系:

—— END ——
参考资料:
[1]https://www.clear.rice.edu/comp321/html/laboratories/lab10/
[2]https://developer.ibm.com/articles/benefits-compression-kafka-messaging/
[3]https://github.com/Tencent/MMKV
[4]《Linux系统编程手册》
[5]《UNIX环境高级编程》
[6]《Android开发高手课》
推荐阅读:
百度工程师浅析解码策略
百度工程师浅析强化学
浅谈统一权限管理服务的设计与开发
百度APP iOS端包体积50M优化实践(五) HEIC图片和无用类优化实践
百度知道上云与架构演进
