

问题现象
团队核心应用每次发布完之后,内存会逐步占用,不重启或者重新部署就会导致整体内存占用率超过90%。
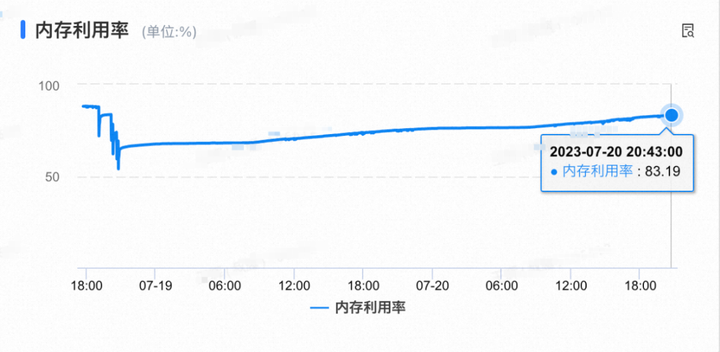
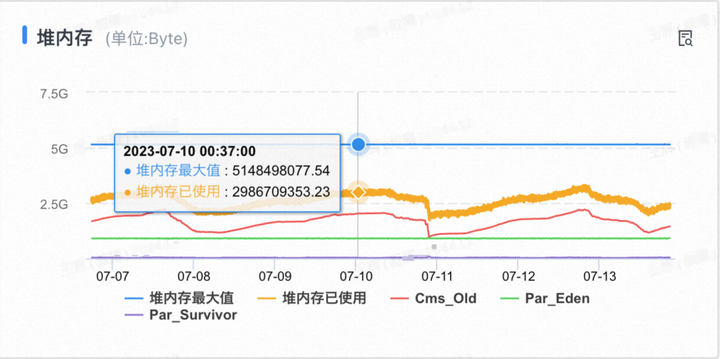
发布2天后的内存占用趋势
探索原因一
堆内找到原因
出现这种问题,第一想到的就是集群中随意找一台机器,信手dump一下内存,看看是否有堆内存使用率过高的情况。
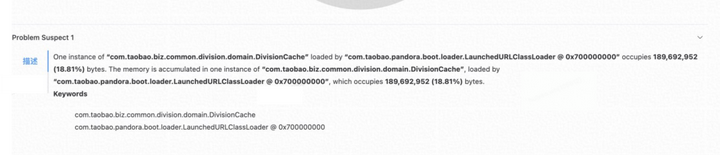
内存泄露
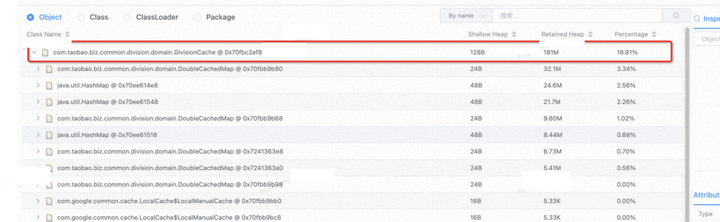
泄露对象占比
发现 占比18.8%
问题解决
是common-division这个包引入的
暂时性修复方案
- 当前加载俄罗斯(RU)国际地址库,改为一个小国家地址库 以色列(IL)
- 当前业务使用场景在补发场景下会使用,添加打点日志,确保是否还有业务在使用该服务,没人在用的话,直接下掉(后发现,确还有业务在用呢 )。
完美解决问题,要的就是速度!!发布 ~~上线!!顺道记录下同一台机器的前后对比。
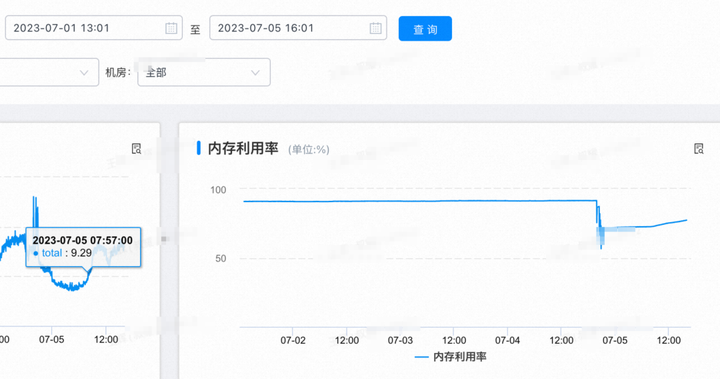
发布后短时间内有个内存增长实属正常,后续在做观察。
发布第二天,顺手又dump一下同一台机器的内存
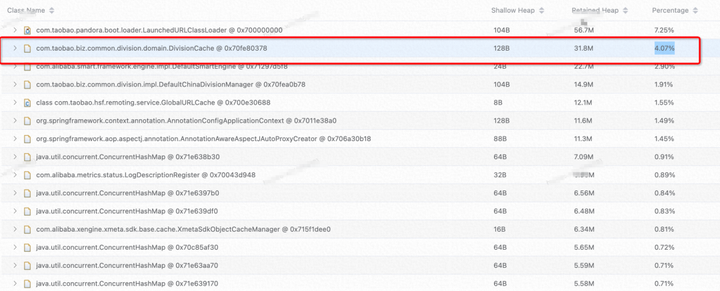
由原来的18.8%到4.07%的占比,降低了14%,牛皮!!
傻了眼,内存又飙升到86%~~ 该死的迷之自信!!
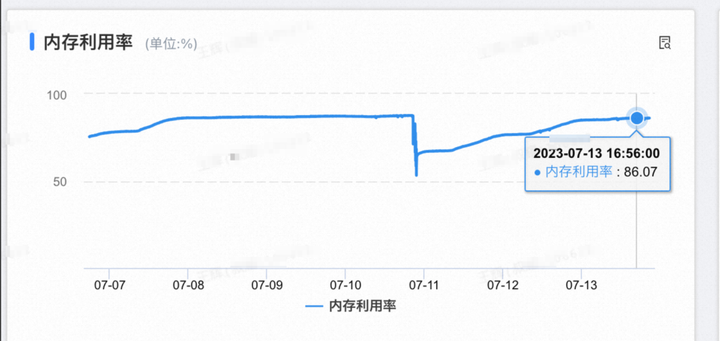
发布后内存使用率
探索原因二
没办法汇报了~~~但是问题还是要去看看为什么会占用这么大的内存空间的~
查看进程内存使用
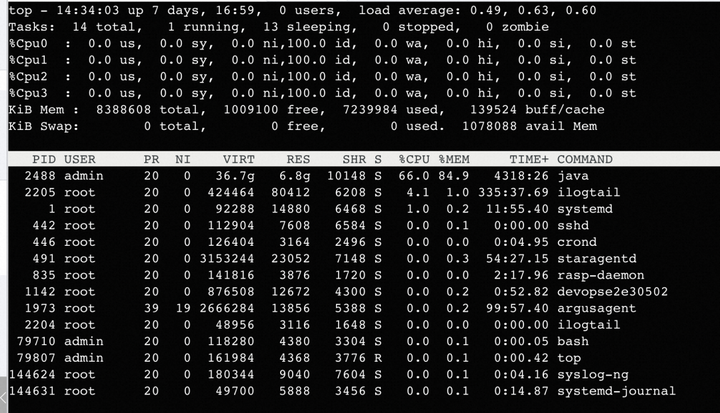
java 进程内存使用率 84.9%,RES 6.8G。
查看堆内使用情况
当期机器配置为 4Core 8G,堆最大5G,堆使用为不足3G左右。
使用arthas的dashboard/memory 命令查看当前内存使用情况:
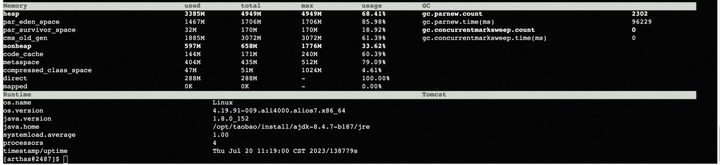
当前堆内+非堆内存加起来,远不足当前RES的使用量。那么是什么地方在占用内存??
开始初步怀疑是『堆外内存泄露』
开启NMT查看内存使用
笔者是预发环境,
正式环境开启需谨慎,本功能有5%-10%的性能损失!!!
-XX:NativeMemoryTracking=detail
jcmd pid VM.native_memory
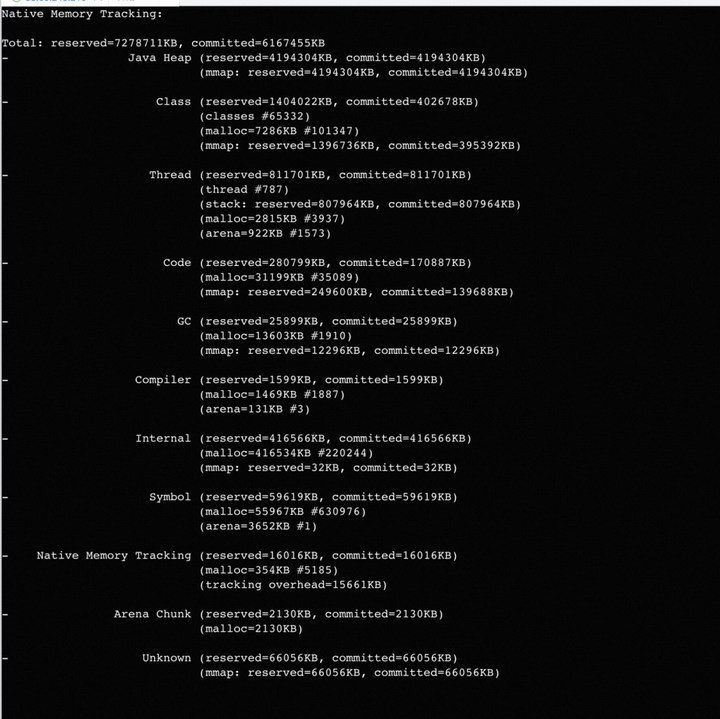
如图有很多内存是Unknown(因为是预发开启,相对占比仍是很高)。
概念
NMT displays
“committed” memory, not “resident” (which you get through the ps command). In other words, a memory page can be committed without considering as a
resident (until it directly accessed).
rssAnalyzer 内存分析
笔者没有使用,因为本功能与NMT作用类似,暂时没有截图了~
rssAnalyzer(内部工具),可以通过oss在预发/线上下载。
通过NMT查看内存使用,基本确认是堆外内存泄露。剩下的分析过程就是确认是否堆外泄露,哪里在泄露。
堆外内存分析
查了一堆文档基本思路就是
- pmap 查看内存地址/大小分配情况
- 确认当前JVM使用的内存管理库是哪种
- 分析是什么地方在用堆外内存。
内存地址/大小分配情况
pmap 查看
pmap -x 2531 | sort -k 3 -n -r
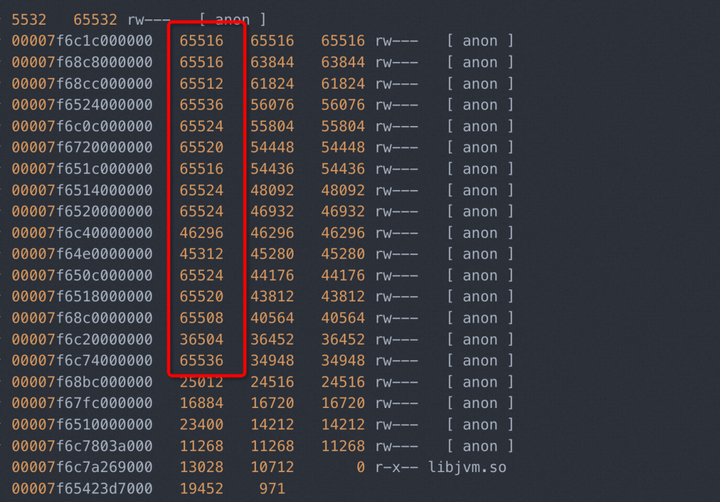
剧透:
32位系统中的话,多为1M64位系统中,多为64M。
strace 追踪
由于系统对内存的申请/释放是很频繁的过程,使用strace的时候,无法阻塞到自己想要查看的条目,推荐使用pmap。
strace -f -e”brk,mmap,munmap” -p 2853
原因: 对 heap 的操作,操 作系统提供了 brk()函数,C 运行时库提供了 sbrk()函数;对 mmap 映射区域的操作,操作系 统提供了 mmap()和 munmap()函数。sbrk(),brk() 或者 mmap() 都可以用来向我们的进程添 加额外的虚拟内存。Glibc 同样是使用这些函数向操作系统申请虚拟内存。

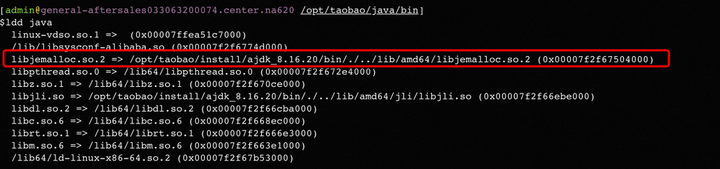
查看JVM使用内存分配器类型
发现很大量为[anon](匿名地址)的64M内存空间被申请。通过附录参考的一些文档发现很多都提到64M的内存空间问题(glibc内存分配器导致的),抱着试试看的态度,准备看看是否为glibc。
cd /opt/taobao/java/bin
ldd java

glibc为什么会有泄露

我们当前使用的glibc的版本为2.17。说到这里可能简单需要介绍一下glibc的发展史。
『
V1.0时代』Doug Lea Malloc 在Linux实现,但是在多线程中,存在多线程竞争同一个分配分配区(arena)的阻塞问题。
『
V2.0时代』Wolfram Gloger 在 Doug Lea 的基础上改进使得 Glibc 的 malloc 可以
支持多线程——ptmalloc。
glibc内存释放机制(可能出现泄露时机)
调用free()时空闲内存块可能放入 pool 中,不一定归还给操作系统。
.收缩堆的条件是当前 free 的块大小加上前后能合并 chunk 的大小大于 64KB、,并且 堆顶的大小达到阈值,才有可能收缩堆,把堆最顶端的空闲内存返回给操作系统。
『V2.0』为了支持多线程,多个线程可以从同一个分配区(arena)中分配内存,ptmalloc 假设线程 A 释放掉一块内存后,线程 B 会申请类似大小的内存,但是 A 释放的内 存跟 B 需要的内存不一定完全相等,可能有一个小的误差,就需要不停地对内存块 作切割和合并。

为什么是64M
回到前面说的问题,为什么会创建这么多的64M的内存区域。这个跟glibc的内存分配器有关下的,间作介绍。
V2.0版本的glibc内存分配器,将分配区域分配主分配区(main arena)和非主分配区(non main arena)(在v1.0时代,只有一个主分配区,每次进行分配的时候,需要对主分配区进行加锁,2.0支持了多线程,将分配区通过环形链表的方式进行管理),每一个分配区利用互斥锁使线程对于该分配区的访问互斥。
主分配区:可以通过sbrk/mmap进行分配。
非主分配区,只可以通过mmap进行分配。
其中,mmap每次申请内存的大小为HEAP_MAX_SIZE(32 位系统上默认为 1MB,64 位系统默 认为 64MB)。
哪里在泄露
既然知道了存在堆外内存泄露,就要查一下到低是什么地方的内存泄露。参考历史资料,可以使用jemalloc工具进行排查。
配置dump内存工具(jemalloc)
由于系统装载的是glibc,所以可以自己在不升级jdk的情况下编译一个jemalloc。
github下载比较慢,上传到oss,再做下载。
sudo yum install -y git gcc make graphviz
wget -P /home/admin/general-aftersales https://xxxx.oss-cn-zhangjiakou.aliyuncs.com/jemalloc-5.3.0.tar.bz2 &&
mkdir /home/admin/general-aftersales/jemalloc &&
cd /home/admin/general-aftersales/ &&
tar -jxcf jemalloc-5.3.0.tar.bz2 &&
cd /home/admin/xxxxx/jemalloc-5.3.0/ &&
./configure --enable-prof &&
make &&
sudo make install
export LD_PRELOAD=/usr/local/lib/libjemalloc.so.2 MALLOC_CONF="prof:true,lg_prof_interval:30,lg_prof_sample:17,prof_prefix:/home/admin/general-aftersales/prof_prefix
核心配置
- make之后,需要启用prof,否则会出现『: Invalid conf pair: prof:true』类似的关键字
- 配置环境变量
- LD_PRELOAD 挂载本次编译的库
- MALLOC_CONF 配置dump内存的时机。
- “lg_prof_sample:N”,平均每分配出 2^N 个字节 采一次样。当 N = 0 时,意味着每次分配都采样。
- “lg_prof_interval:N”,分配活动中,每流转 1 « 2^N 个字节,将采样统计数据转储到文件。
重启应用
./appctl restart
监控内存dump文件
如果上述配置成功,会在自己配置的prof_prefix 目录中生成相应的dump文件。
然后将文件转换为svg格式
jeprof --svg /opt/taobao/java/bin/java prof_prefix.36090.9.i9.heap > 36090.svg
然后就可以在浏览器中浏览了
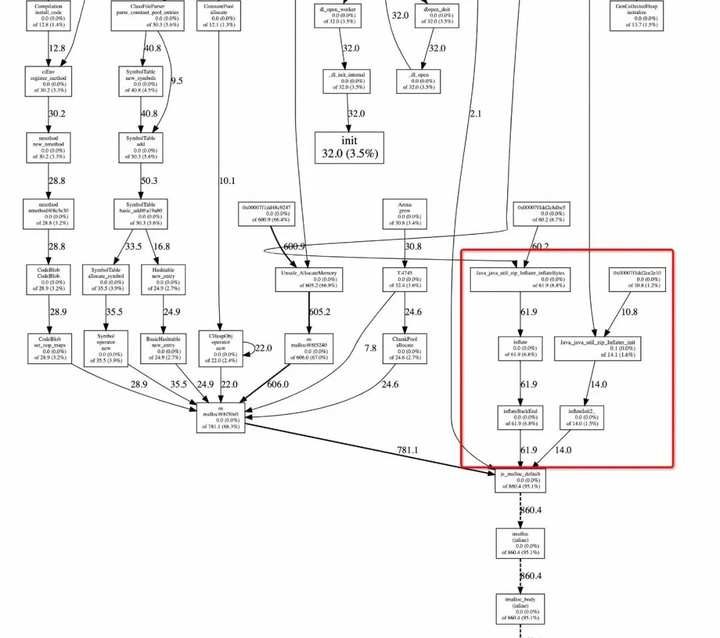
与参阅文档中结果一致,有通过
Java java.util.zip.Inflater 调用JNI申请内存,进而导致了内存泄露。
既然找到了哪里存在内存泄露,找到使用的地方就很简单了。
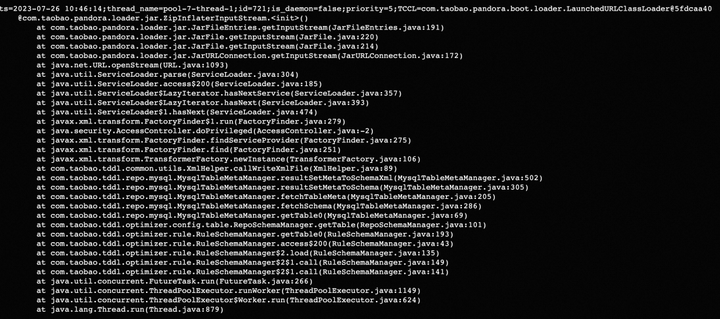
发现元凶
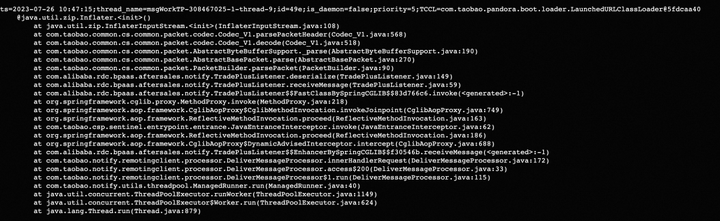
通过arthas 的stack命令查看某个方法的调用栈。
statck java.util.zip.Inflater
java.util.zip.InflaterInputStream
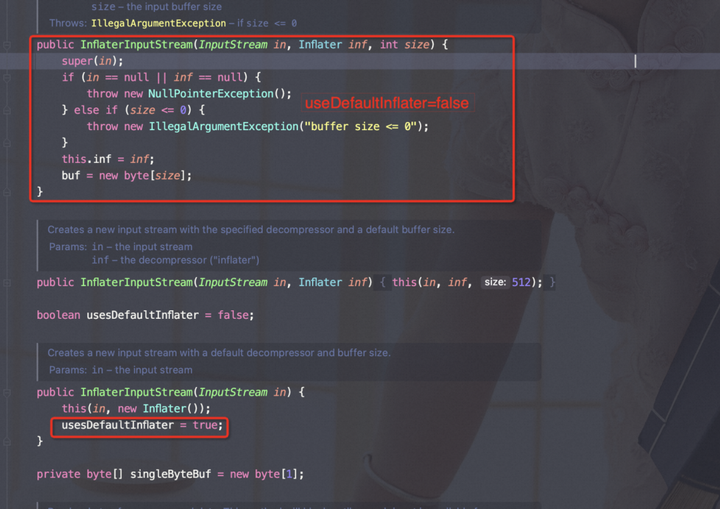
如上源码可以看出,如果使用InflaterInputStream(InputStream in) 来构造对象usesDefaultInflater=true, 否则全部为false;
在流关闭的时候。
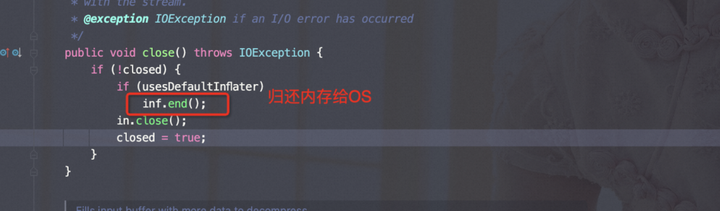
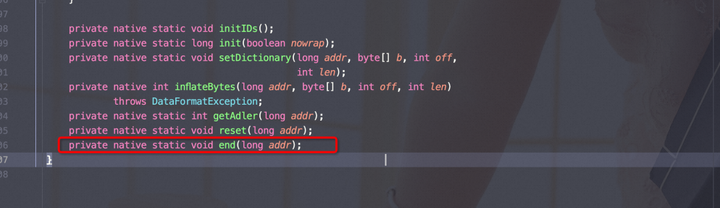
end()是native方法。
只有在『usesDefaultInflater=true』的时候,才会调用free()将内存归尝试归还OS,依据上面的内存释放机制,可能不会归还,进而导致内存泄露。
comp.taobao.pandora.loader.jar.ZipInflaterInputStream
二方包扫描
ZipInflaterInputStream 的流关闭使用的是父类java.util.zip.InflaterInputStream,构造器使用public InflaterInputStream(InputStream in, Inflater inf, int size)
这样如上『usesDefaultInflater=false』,在关闭流的时候,不会调用end()方法,导致内存泄露。
com.taobao.pandora.loader.jar.ZipInflaterInputStream 源自pandora ,咨询了相关负责人之后,发现2年前就已经修复此内存泄露问题了。
最低版本要求
sar包里的 pandora 版本,要大于等于 2.1.17
问题解决
升级ajdk版本
需要咨询一下jdk团队的同学,需要使用jemalloc作为内存分配器的版本。
升级pandora版本
如上所说,版本高于2.1.17即可。
我们是团队是统一做的基础镜像,找相关的同学做了dockerfile from的升级。
发布部署&观察
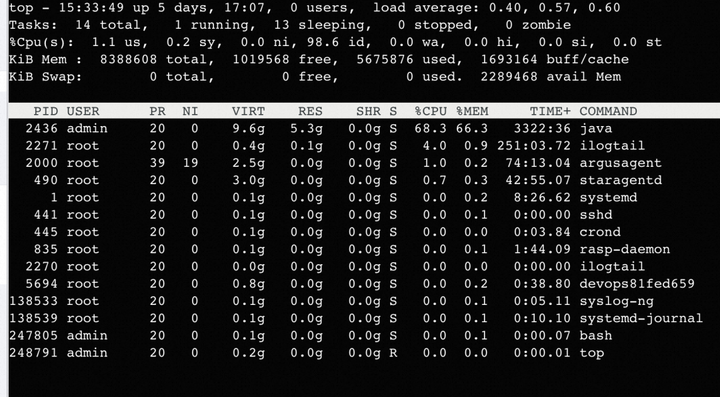
这此真的舒服了~
总结
探究了glibc的工作原理之后,发现相比jemalloc的内存使用上确实存在高碎片率的问题,但是本次问题的根本还是在应用层面没有正确的关闭流加剧的堆外内存的泄露。
总结的过程,也是学习的过程,上述分析过程欢迎评论探讨。
作者|叔耀
点击立即免费试用云产品 开启云上实践之旅!
原文链接
本文为阿里云原创内容,未经允许不得转载
