


作者 | Jane
导读
生成式模型的解码方法主要有2类:确定性方法(如贪心搜索和波束搜索)和随机方法。确定性方法生成的文本通常会不够自然,可能存在重复或过于简单的表达。而随机方法在解码过程中引入了随机性,以便生成更多样化、更自然的文本。两种常见的随机方法是:
1、Top-k 采样:在每个解码步骤中,模型会选择可能性排名在前的前 k 个单词,然后从这些单词中随机选择一个作为下一个生成的单词。这样可以增加文本的多样性,但仍然保持一定的可控性。
2、核采样(Top-p 采样):在这种方法中,模型会根据累积概率从词汇表中选择下一个单词。累积概率是指按照概率从高到低排列的单词概率之和。这可以减少重复性,并且相对于固定的 k 值,它可以自适应地选择更少或更多的候选词。
虽然核采样可以生成(缓解)没有重复的文本,但生成文本的语义一致性并不是很好,这种语义不一致的问题可以通过降低温度 (temperature) 来部分解决。降低温度是一个可以影响随机性的参数。较高的温度会导致更均匀的分布,使得生成的文本更多样化,而较低的温度会使分布更集中,更接近于确定性。这就引入了一个权衡,因为较高的温度可能会导致文本语义不一致,而较低的温度可能会失去一些多样性。
在实际应用中,要根据任务和期望的文本输出特性来选择合适的解码方法、随机性参数和温度值。不同的方法和参数组合可能适用于不同的情况,以平衡生成文本的多样性、准确性和一致性。
全文3646字,预计阅读时间10分钟。
01 对比搜索(contrastive_search)
对比搜索给定前缀文本(x_{,按如下公式输出token(x_{t}):
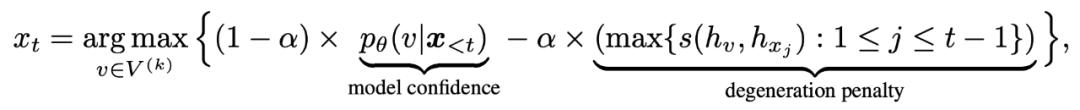
语言模型输出的概率分布(p_{theta}(v|x_{表示下一个可能的token的预测概率,上式中(V^{(k)})表示概率分布中 k 个概率最大的候选token的集合。
-
第一项,即 模型置信度 (model confidence),是语言模型预测的每个候选词元 v 的概率。
-
第二项, 退化惩罚 (degeneration penalty),用于度量候选token v 与上文(x{中每个token的相似性, v 的向量表征(h_{v})与其上文(x {中每个token的向量表征计算余弦相似度,相似度最大值被用作退化惩罚。直观上理解,如果 v 的退化惩罚较大意味着它与上文更相似 (在表示空间中),因此更有可能导致模型退化问题。超参数 (alpha)用于在这两项中折衷。当时(alpha=0),对比搜索退化为纯贪心搜索。
总结来说,对比搜索在生成输出时会同时考虑:
-
语言模型预测的概率,以保持生成文本和前缀文本之间的语义连贯性。
-
与上文的相似性以避免模型退化。
# generate the result with contrastive search
output = model.generate(
input_ids,
penalty_alpha=0.6, # 对比搜索中的超参 $alpha$
top_k=4, # 对比搜索中的超参 $k$。
max_length=512
)
02 贪心搜索(greedy_search)**
贪心搜索在每个时间步 都简单地选择概率最高的词作为当前输出词:(w_t = argmax_{w}P(w | w_{1:t-1}))
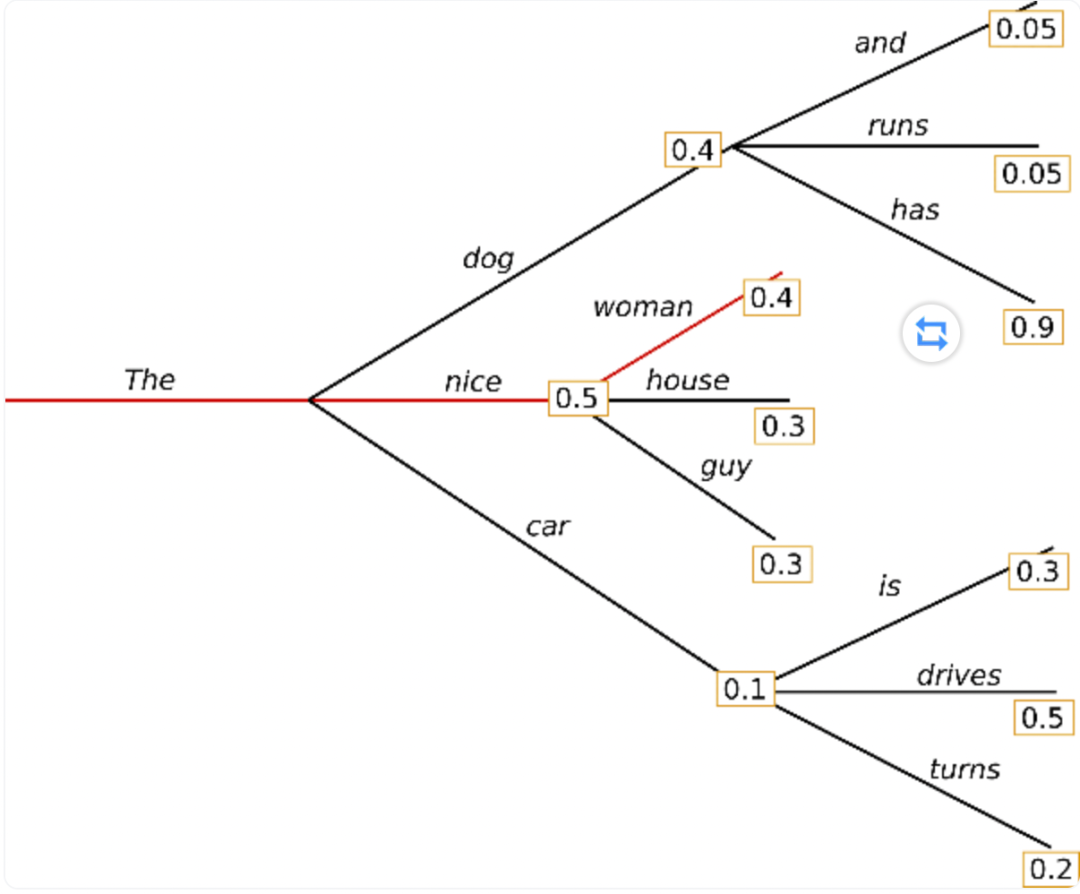
△贪心搜索
问题:
-
容易输出重复的文本,这在语言生成中是一个非常普遍的问题,在贪心搜索和波束搜索中似乎更是如此
-
主要缺点是它错过了隐藏在低概率词后面的高概率词:The -> dog -> has (0.4*0.9=0.36),The -> nice -> wman (0.5*0.4=0.20),波束搜索可以缓解此类问题
03 波束搜索(beam_search)
波束搜索整个过程可以总结为: 分叉、排序、剪枝,如此往复。波束搜索通过在每个时间步保留最可能的 num_beams 个词,并从中最终选择出概率最高的序列来降低丢失潜在的高概率序列的风险。
下图示例 num_beams=2:
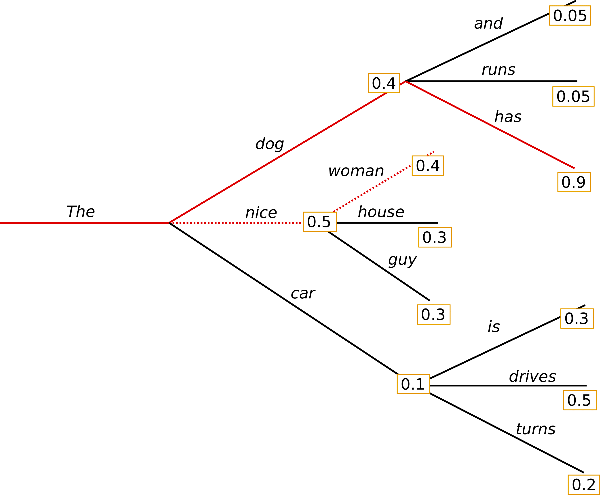
△波束搜索 num_beams=2
波束搜索一般都会找到比贪心搜索概率更高的输出序列,但仍不保证找到全局最优解。
虽然结果比贪心搜索更流畅,但输出中仍然包含重复。一个简单的补救措施是引入 n-grams (即连续 n 个词的词序列) 惩罚:最常见的 n-grams 惩罚是确保每个 n-gram 都只出现一次,方法是如果看到当前候选词与其上文所组成的 n-gram 已经出现过了,就将该候选词的概率设置为 0。通过设置 no_repeat_ngram_size=2 来试试,这样任意 2-gram 不会出现两次:
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2, # n-grams
early_stopping=True
)
但是,n-gram 惩罚使用时必须谨慎,如一篇关于纽约这个城市的文章就不应使用 2-gram 惩罚,否则,城市名称在整个文本中将只出现一次!
波束搜索已被证明依然会存在重复生成的问题。在『故事生成』这样的场景中,很难用 n-gram 或其他惩罚来控制,因为在“不重复”和最大可重复 n-grams 之间找到一个好的折衷需要大量的微调。正如 Ari Holtzman 等人 (2019) (https://arxiv.org/abs/1904.09751) 所论证的那样,高质量的人类语言并不遵循最大概率法则。这是因为人类语言具有创造性和惊喜性,而不仅仅是简单的预测性。
因此,引入随机性和创造性元素是生成更有趣和多样性文本的关键。
04 采样(sampling)
4.1 采样
使用采样方法时文本生成本身不再是确定性的(do_sample=True)。
# activate sampling and deactivate top_k by setting top_k sampling to 0
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0
)
对单词序列进行采样时的问题:模型通常会产生不连贯的乱码,缓解这一问题的一个技巧是通过降低 softmax的“温度”使分布(P(w|w_{1:t-1}))更陡峭。而降低“温度”,本质上是增加高概率单词的似然并降低低概率单词的似然。
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0,
temperature=0.7
)
虽然温度可以使分布的随机性降低,但极限条件下,当“温度”设置为 0 时,温度缩放采样就退化成贪心解码了,因此会遇到与贪心解码相同的问题。
4.2 Top-k 采样
在 Top-K 采样中,概率最大的 K 个词会被选出,然后这 K 个词的概率会被重新归一化,最后就在这重新被归一化概率后的 K 个词中采样。GPT2 采用了这种采样方案,这也是它在故事生成这样的任务上取得成功的原因之一。
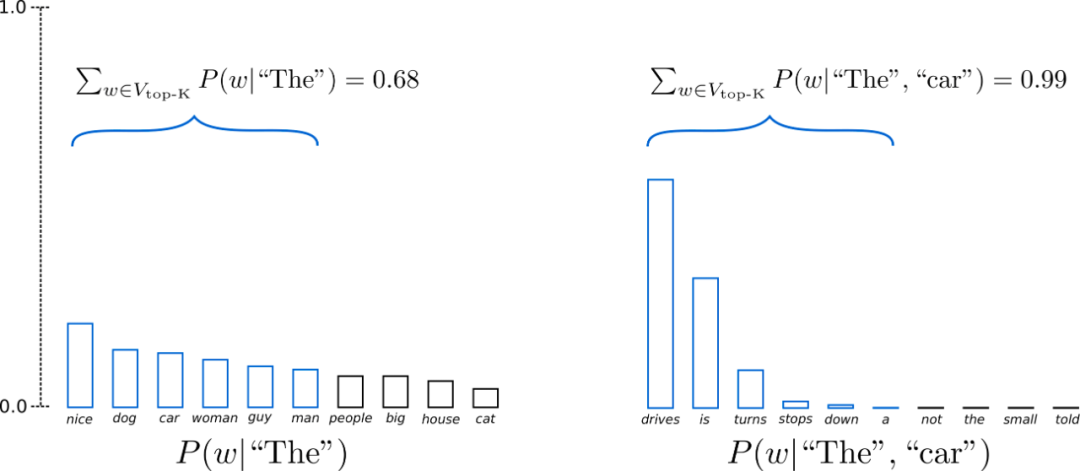
假设 p=0.92,Top-p 采样对单词概率进行降序排列并累加,然后选择概率和首次超过 p=92% 的单词集作为采样池,定义为(V_{text{top-p}})。在 t=1 时(V_{text{top-p}})有 9 个词,而在 t=2 时它只需要选择前 3 个词就超过了 92%。
可以看出,在单词比较不可预测时(例如更平坦的左图),它保留了更多的候选词,如(P(w | text{“The”})),而当单词似乎更容易预测时(例如更尖锐的右图),只保留了几个候选词,如(P(w | text{“The”}, text{“car”}))。
# deactivate top_k sampling and sample only from 92% most likely words
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92,
top_k=0
)
虽然从理论上讲, Top-p 似乎比 Top-K 更优雅,但这两种方法在实践中都很有效。Top-p 也可以与 Top-K 结合使用,这样可以避免排名非常低的词,同时允许进行一些动态选择。如果 k 和 p 都启用,则 p 在 k 之后起作用。
# 配置 top_k = 50 、 top_p = 0.95 、 num_return_sequences = 3
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50,
top_p=0.95,
num_return_sequences=3
)
——END——
参考资料:
[1]一种简单有效的解码策略:Contrastive Search
[2]HF:如何生成文本: 通过 Transformers 用不同的解码方法生成文本
[3]https://docs.cohere.ai/docs/controlling-generation-with-top-k-top-p
[4]https://docs.cohere.ai/docs/temperature
推荐阅读:
百度工程师浅析强化学习
浅谈统一权限管理服务的设计与开发
百度APP iOS端包体积50M优化实践(五) HEIC图片和无用类优化实践
百度知道上云与架构演进
百度APP iOS端包体积50M优化实践(四)代码优化
百度App启动性能优化实践篇
