

01 服务网格数据面的演进
以 Istio 为代表的 Service Mesh 技术已经存在四五年的时间了,阿里云也是第一批支持 Service Mesh 云服务的厂商。在 Service Mesh 技术中,通过把服务治理的能力进行 Sidecar 化,实现与应用程序本身的解耦。这些若干个 Sidecar 代理就形成了一个网状的数据平面,通过该数据平面可以处理和观察所有应用服务间的流量。负责数据平面如何执行的管理组件称为控制平面。
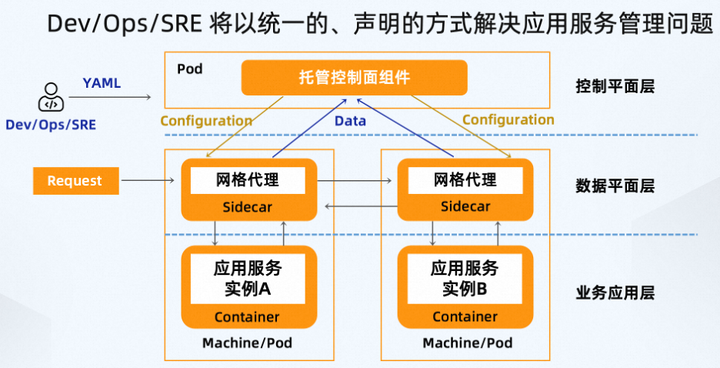
可以看到,控制平面是服务网格的大脑,它为网格使用人员提供公开 API,以便更容易地操纵网络行为。总之,通过 Service Mesh 技术,Dev/Ops/SRE 将以统一的、声明的方式解决应用服务管理问题。
服务网格作为一种应用感知的云原生基础设施,提供了云原生应用感知的网络管理能力。
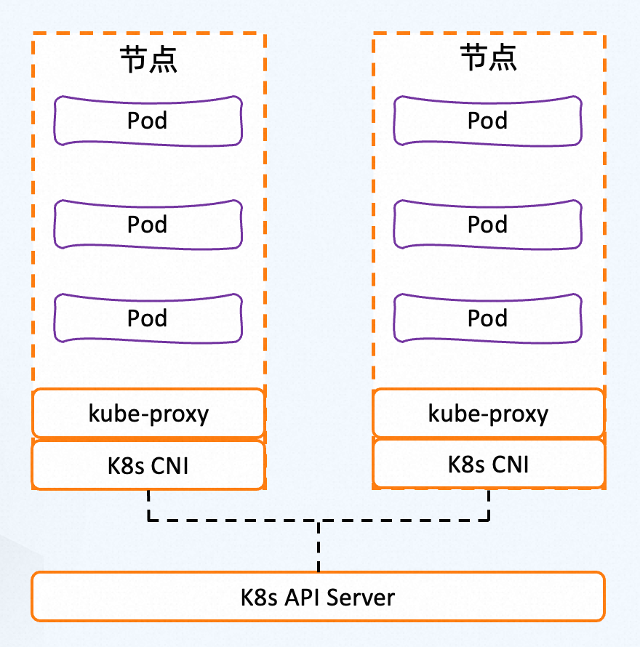
网络是 Kubernetes 的核心部分,涉及了 Pod 间通信、Pod 和服务间通信以及服务与外部系统间的通信等。Kubernetes 集群中使用 CNI 插件来管理其容器网络功能,使用 Kube-proxy 维护节点上的网络规则,譬如使发往 Service 的流量(通过ClusterIP 和端口)负载均衡到正确的后端 Pod。
容器网络成为用户使用 IaaS 网络的新界面,以阿里云 ACK Terway 网络为例,基于阿里云 VPC 网络直通弹性网卡,具备高性能特征;同时无缝地跟阿里云 IAAS 网络对接;
然而,kube-proxy 设置是全局的,无法针对每个服务进行细粒度控制;而且 kube-proxy 只是专在网络数据包级别上运行。它无法满足现代应用程序的需求,如应用层流量管理、跟踪、身份验证等。
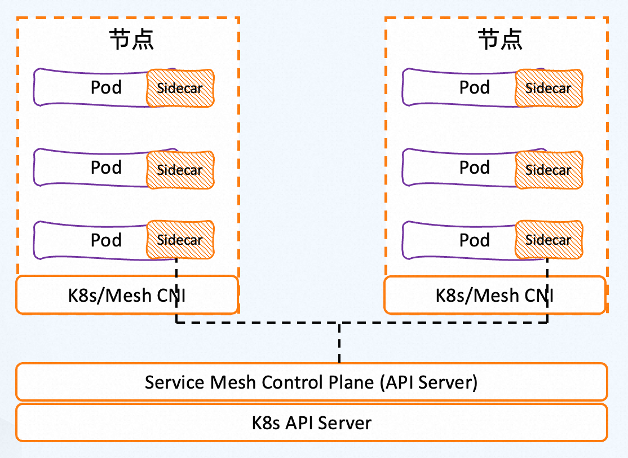
我们来看服务网格 Sidecar 代理模式下的云原生应用网络是如何解决这些问题的。服务网格通过 Sidecar 代理将流量控制从 Kubernetes 的服务层中解耦,将代理注入到每个 Pod;并通过控制平面操纵管理这些分布式代理,从而可以更加精细地控制这些服务之间的流量。
那么在 Sidecar 代理下的网络数据包的传输是怎样的过程?
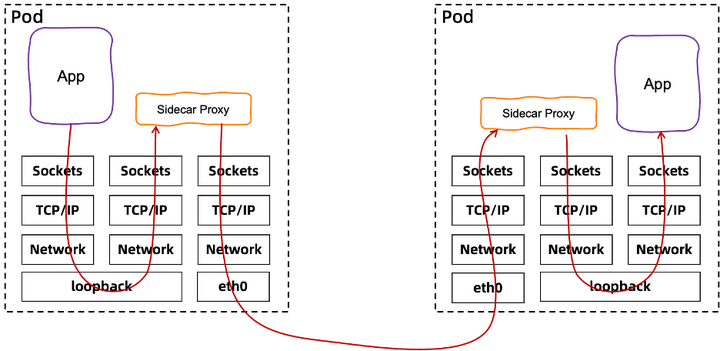
当前 Istio 实现中涉及了 TCP/IP 堆栈的开销,它使用了 Linux 内核的 netfilter 通过配置 iptables 来拦截流量,并根据配置的规则对进出 sidecar 代理的流量进行路由。客户端 pod 到服务器端 pod 之间的典型路径(即使在同一主机内)至少要遍历 TCP/IP 堆栈 3 次(出站、客户端 Sidecar Proxy 到服务器端 Sidecar Proxy、入站)。
为了解决这个网络数据路径问题,业界通过引入 eBPF 绕过 Linux 内核中的 TCP/IP 网络堆栈来实现网络加速,这不但降低了延迟,同时也提升了吞吐量。当然,eBPF 并不会替换 Envoy 的七层代理能力,在七层流量管理的场景下,仍然是 4 层 eBPF + 7 层 Envoy 代理的融合模式。只有针对 4 层流量网络的情况下,跳过代理 pod 直接进入网络接口。
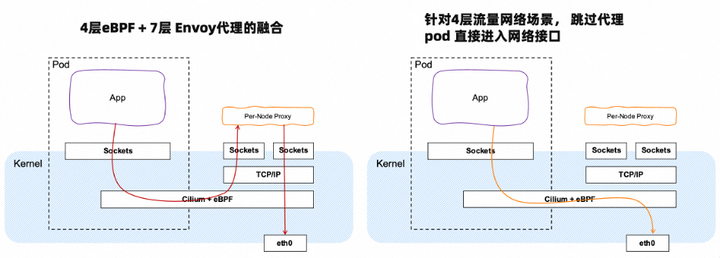
前面讲述的是传统的 Sidecar 代理模式,除此之外,业界开始在探索一种新型的数据平面模式。它的设计理念是:将数据平面分层,4 层用于基础处理,特点是低资源、高效率;7 层用于高级流量处理,特点是功能丰富,当然需要更多的资源。这样的话,用户可以根据所需功能的范围,以渐进增量的方式采用服务网格技术。具体来说:
在 4 层处理中,主要包括:
- 流量管理:TCP 路由
- 安全:面向 4 层的简单授权策略、双向 TLS
- 可观测:TCP 监控指标及日志
在 7 层处理中,则主要包括:
- 流量管理:HTTP 路由、负载均衡、熔断、限流、故障容错、重试、超时等
- 安全:面向 7 层的精细化授权策略
- 可观测:HTTP 监控指标、访问日志、链路追踪
那么数据面 L4 与 L7 代理的解耦模式下,Service Mesh 的网络拓扑将是什么形式?
一方面,将 L4 Proxy 能力下移到 CNI 组件中,L4 Proxy 组件以 DaemonSet 的形式运行,分别运行在每个节点上。这意味着它是为一个节点上运行的所有 pod 提供服务的共享基础组件。
另一方面,L7 代理不再以 Sidecar 模式存在,而是解耦出来,我们称之为 Waypoint Proxy, 它是为每一个 Service Account 创建的 7 层代理 pod。
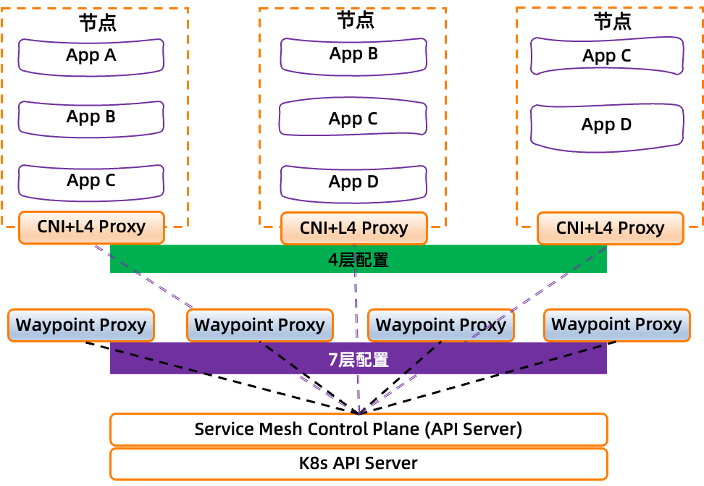
4 层和 7 层代理的配置仍然保持通过 Service Mesh 控制面组件来进行下发管理。
总之,通过这种解耦模式,实现了 Service Mesh 数据平面与应用程序之间的进一步解耦分离。
那么,在 Istio 的具体实现中,可以分为 3 个部分:
- Waypoint 代理L7 组件完全独立于应用程序运行,安全性更高;每个身份(Kubernetes 中的服务帐户)都有自己专用的 L7 代理(Waypoint 代理),避免多租户 L7 代理模式引入的复杂度与不稳定性;同时,通过 K8s Gateway CRD 定义触发启用;
- ztunnel将 L4 处理下沉到 CNI 级别,来自工作负载的流量被重定向到 ztunnel,然后ztunnel 识别工作负载并选择正确的证书来处理;
-
与 Sidecar 模式兼容
Sidecar 模式仍然是网格的一等公民,Waypoint 代理可以与部署了 Sidecar 的工作负载进行本地通信。
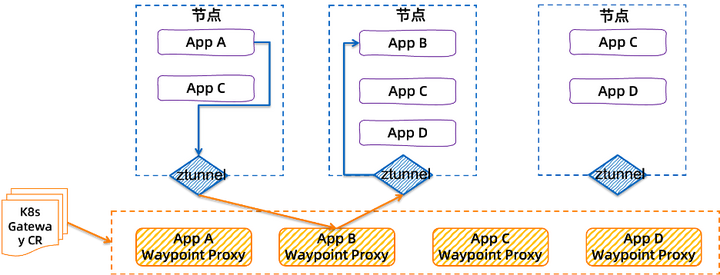
不影响应用程序是使 Ambient Mesh 比传统的 Sidecar 模式具备更少侵入性的原因之一。与采用 Sidecar 模式时必须将 Sidecar 代理注入到每个应用程序部署中相比,Ambient 模式下无需以任何方式重新部署或修改现有应用程序。通过不重新部署和直接修改应用程序,可以有效地降低落地风险并简化采用 Mesh 的落地曲线。
Ambient Mesh 的设计是非侵入式的,并且仅对存在特定标记的命名空间并使现有应用程序成为 Ambient Mesh 的一部分,可以逐步采用。一旦应用程序成为 Ambient Mesh 的一部分,它立即获得 mTLS 和 L4 可观察性功能。
02 网络 CNI 插件为节点进行网络命名空间配置
Sidecarless 模式中 CNI 插件在两个位置进行网络命名空间的配置,其中一个就是在所处的节点上,另一个是在 ztunnel pod 上。
具体如下:
- 节点:在每个节点上配置网络命名空间,以将进出节点的流量透明地路由到节点,并相应地将其路由到 ztunnel 代理。
- ztunnel:在 ztunnel pod 的网络命名空间中配置路由,将进出流量路由到 ztunnel 代理上的特定端口。
CNI 插件在每个节点上初始化路由并设置 iptables 和 ipset。
注意:与 Sidecar 模式下不同,CNI 插件所做的配置不会直接影响任何工作负载 pod。更改仅在节点网络命名空间和 ztunnel pod 的网络命名空间中进行,与流量重定向机制无关。
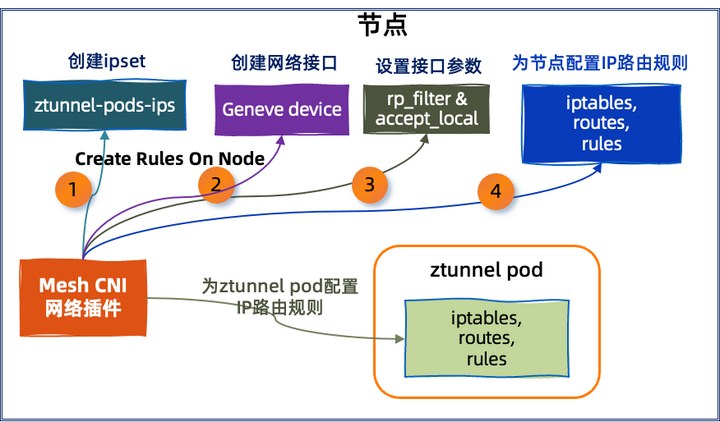
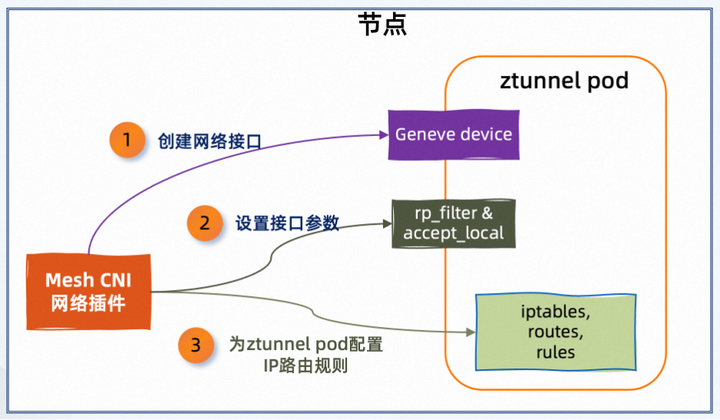
网格 CNI 插件为节点进行配置的内容可以分为 4 个部分:
1. 创建名为 ztunnel-pods-ips 的 IP 集(ipset)
2. 由 Mesh CNI 网络插件创建网络接口(Geneve Device)
3. 设置网络接口的参数
4. 设置 iptables、路由表和路由规则具体来说:
1. 创建名为 ztunnel-pods-ips 的 IP 集(ipset)
节点上创建了一个名为 ztunnel-pods-ips 的 IP 集,用于存储当前节点中启用Ambient 模式的 pod 的 IP 地址。每次添加一个 pod 时,CNI 插件将 pod 的 IP 地址添加到节点上的 ztunnel-pods-ips IP 集(ipset)中。
随着 pod 的添加或删除(即它们的 IP 地址发生变化),CNI 插件会让节点上的 ipset 保持最新。
在节点上可以通过运行 ipset list 命令查看作为 ipset 中的 IP 地址:
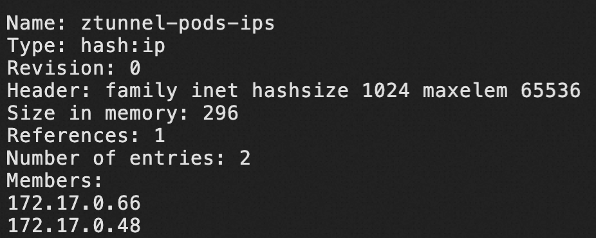
通过 kubectl 查看纳入到 Ambient 模式中的本节点下的 Pod 列表,例如:

对比分析可以看到,在节点 172.17.0.3 上,纳入到 Ambient 模式的 Pod 有 2 个,IP 地址分别为 172.17.0.48 和 172.17.0.66。这 2 个地址也被写入到 ztunnel-pods-ips IP 集 (ipset) 中。
2. 由 Mesh CNI 网络插件创建网络接口(Geneve Device)
在每个节点上,设置了两个虚拟网络接口(Geneve Device) – istioin 和 istioout。
由 Mesh CNI 网络插件创建:
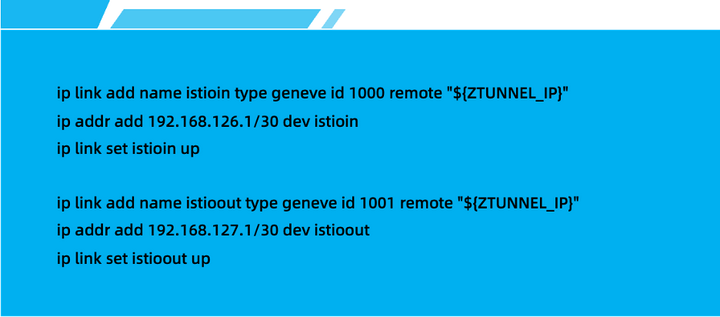
执行前面三行的命令后,Linux 系统会将 IP 地址 192.168.126.1 和子网掩码 255.255.255.252 添加到 istioin 网络接口中,以便该网络接口可以用于与该 IP 地址所在的子网中的其他主机进行通信。然后将 istioin 网络接口启用,以便该网络接口可以用于网络通信和数据传输。网络接口启用后,它可以接收和发送数据包,与其他网络设备进行通信和交换数据。
同样的,后面三行命名执行后,Linux 系统会将 IP 地址 192.168.127.1 和子网掩码 255.255.255.252 添加到 istioout 网络接口中,以便该网络接口可以用于与该 IP 地址所在的子网中的其他主机进行通信。然后将 istioout 网络接口启用,以便该网络接口可以用于网络通信和数据传输。网络接口启用后,它可以接收和发送数据包,与其他网络设备进行通信和交换数据。
在 Linux 系统中,网络接口启用后通常会被标记为 “UP” 状态,可以通过 ip link show 命令查看网络接口的状态信息。例如, 在节点上运行命令 ip link show,显示网络接口的链路层信息,可以得到类似如下内容:

- 结合节点上的 iptables 规则和路由表,确保来自 ambient pods 的流量被拦截,并根据方向(入站或出站)分别发送到 istioout 或 istioin。
- 使用下面的命令显示网络接口的网络层信息,可以查看节点上 istioin 网络接口的详细信息:

- 发送到这些接口的数据包最终会到达在同一节点上运行的 ztunnel pod 的 pistioout 或 pistioin。
- 使用下面的命令查看节点上 istioout 网络接口的详细信息,可以看到对应于同一节点上 ztunnel pod 的 IP 地址。

3. 设置网络接口的参数
- 将网络接口的 rp_filter 参数设置为 0,关闭反向路径过滤,绕过数据包源 IP 地址的校验;
- 将网络接口的 accept_local 参数设置为 1,以接受本地生成的数据包;

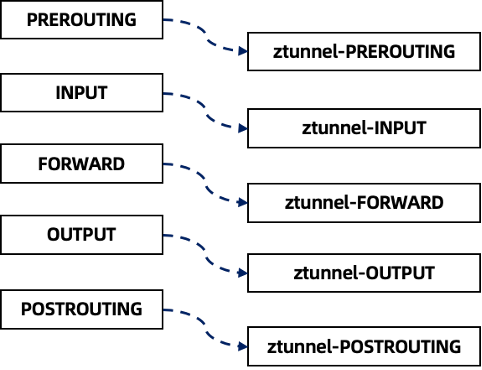
4. 设置 iptables、路由表和路由规则
节点上的另一个更改是 iptables 链,它将数据包从现有的表(NAT 和 MANGLE)中的标准链(例如 PREROUTING,OUTPUT 等)重定向到自定义的 ztunnel 链。如下图所示:
具体来说,对应执行如下命名:
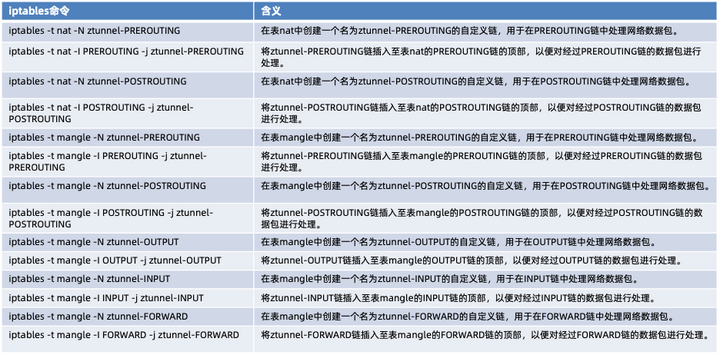
此外,通过执行如下命令,用于在 mangle 表和 nat 表中为自定义链 ztunnel-PREROUTING、ztunnel-FORWARD、ztunnel-INPUT、ztunnel-OUTPUT 和 ztunnel-POSTROUTING 添加一些规则,具体含义如下:
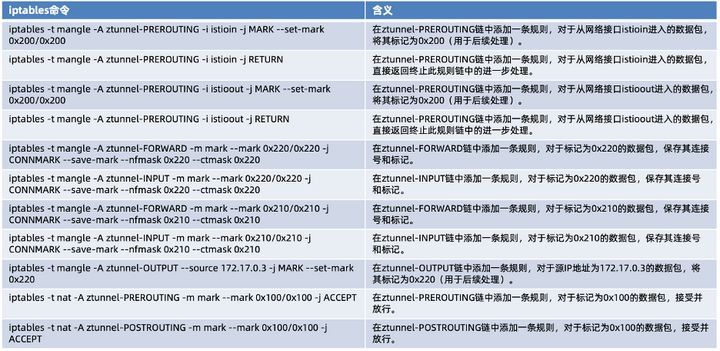
以及用于在 mangle 表中的自定义链 ztunnel-PREROUTING 中添加一些规则,具体含义如下:
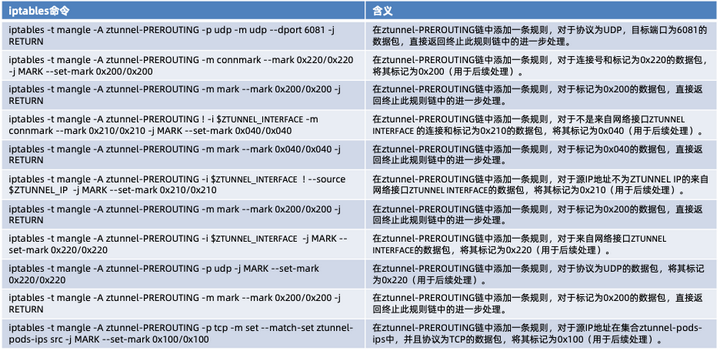
任何标记为 0x100/0x100 的数据包(即来自 Ambient pod)根据对应的路由表中的规则进行路由。创建这些路由表所需要执行的命令如下:

- 要查看路由表 100,请运行下面的命令:

- 要查看路由表 101,请运行下面的命令:

具体描述如下:
- 路由表项 default via 192.168.127.2 dev istioout :默认路由,通过 istioout 接口将流量发送到 IP 地址 192.168.127.2(ztunnel 上的 pistioout)。
- 路由表项 172.17.0.59 dev cali9af644900ca scope link :任何发送到 172.17.0.59 的流量(即 ztunnel pod 的 IP 地址)应直接通过虚拟接口(calixxxx)发送。
- istioout 接口(192.168.127.1)使用 GENEVE 隧道连接到在同一节点上运行的ztunnel上的接口 pistioout(IP 为 192.168.127.2)。也就是说,当通过istioout接口向 192.168.127.2 发送请求,数据包将最终到达称为 pistioout(注意前缀 p)的 ztunnel 出站接口,从而通过 ztunnel 路由网格中的 pod 的出站流量。
- 要查看路由表 102,请运行下面的命令:

- 第一行:所有目的 IP 地址不在本地子网中的数据包都会被路由到指定的下一跳路由器,该数据包会通过 ZTUNNELINTERFACE网络接口发送到下一跳路由器(地址为ZTUNNELINTERFACE网络接口发送到下一跳路由器(地址为{ZTUNNEL_INTERFACE} 网络接口发送到下一跳路由器(地址为 {ZTUNNEL_IP})。
- 第二行:所有目的 IP 地址为 ZTUNNELIP的数据包都会被路由到指定的下一跳路由器,该数据包会通过ZTUNNELIP的数据包都会被路由到指定的下一跳路由器,该数据包会通过{ZTUNNEL_IP} 的数据包都会被路由到指定的下一跳路由器,该数据包会通过 {ZTUNNEL_INTERFACE} 网络接口发送到下一跳路由器,该路由器位于本地网络中,不需要通过其他路由器进行转发。
配置 IP 路由规则
- ztunnel-pods-ips IP 集作为 iptables 规则的一部分,IP 地址会相应地被标记。例如,如果数据包来自 Ambient Pod,并通过 istioout 接口重定向到 ztunnel,则会使用 0x100/0x100 标记数据包。
- 在节点上可以使用 ip rule list 命令查看如何使用不同的标记设置路由表:
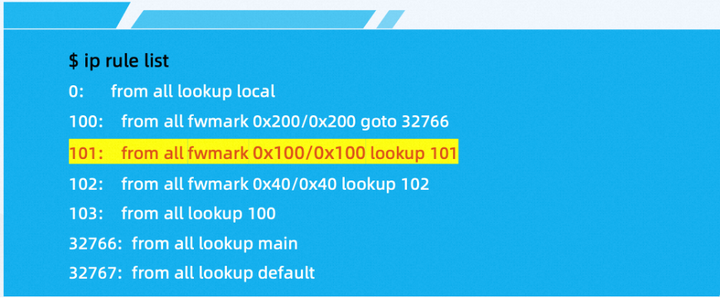
- 对应的添加命令如下:

具体来说,对于标记为 0x200/0x200 的数据包,跳转到主路由表(编号为 32766)进行路由。
对于标记为 0x100/0x100 的数据包,在路由表 101 中查找路由信息进行路由。
对于标记为 0x040/0x040 的数据包,在路由表 102 中查找路由信息进行路由。
将路由表 100 作为本地主机的默认路由表。
出站标记以及数据包标记的说明如下:

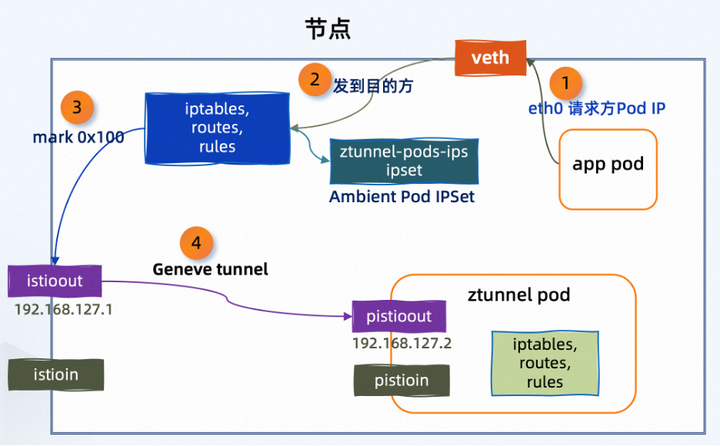
Ambient 网格内部 Pod 的流量请求所经过的数据包流向,大致如下:
- Ambient 模式下的应用 Pod 会被 CNI 插件将其 IP 地址写入到 ipset 中,当发起请求时,流量数据包进入到该节点上对应的 veth 接口。
- 数据包来自 Ambient Pod,会被 iptables 拦截。
- 使用 0x100/0x100 标记数据包,并进入到 istioout 网络接口。
- 通过 istioout 接口将流量透明劫持到 pistioout 网络接口,其中 pistioout 用于接收 Geneve 隧道中的发来的数据包。
03 网格 CNI 插件为 ztunnel Pod 配置网络命名空间
网格 CNI 插件为 ztunnel Pod 进行配置的内容可以分为 3 个部分:
1. 由 Mesh CNI 网络插件创建网络接口(Geneve Device)
2. 设置网络接口的参数
3. 为 ztunnel pod 设置 iptables、路由表和路由规则
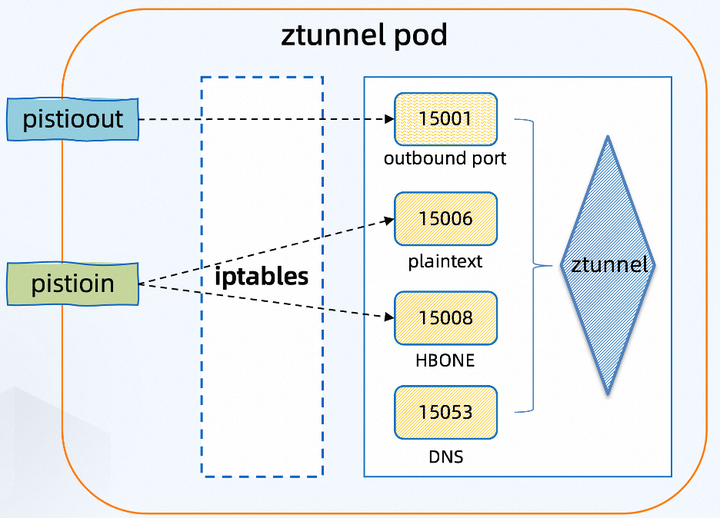
具体来说:
1. 由 Mesh CNI 网络插件创建网络接口(Geneve Device)
在每个 ztunnel Pod 上,设置了两个虚拟网络接口(Geneve Device)- pistioin 和 pistioout。由 Mesh CNI 网络插件在 ztunnel pod 里创建:

在 ztunnel Pod 里运行命令 ip link show,可以得到类似如下内容:

- 使用下面的命令查看 ztunnel Pod 里的 pistioin 网络接口的详细信息:

- 使用下面的命令查看 ztunnel Pod 里的 pistioout 网络接口的详细信息,可以看到对应节点的 IP 地址 172.17.0.3。

2. 设置网络接口的参数
类似地,网格 CNI 插件将为 ztunnel pod 设置网络接口,rp_filter 参数设置为 0,关闭反向路径过滤,绕过数据包源 IP 地址的校验;

3. 为 ztunnel pod 设置 iptables、路由表和路由规则
在 ztunnel pod 上,pistioin 接口接收到的任何内容都会被转发到端口 15008(HBONE)和 15006(纯文本)。
同样,pistioout 接口接收到的数据包最终会到达端口 15001。
ztunnel 还捕获端口 15053 上的 DNS 请求,以提高网格的性能和可用性。请注意,仅当在 DNS 代理中指定的 ISTIO_META_DNS_CAPTURE 设置为 true 时,才会创建配置到 15053 的路由规则。
- 网格 CNI 插件为 ztunnel Pod 里设置路由表,效果类似如下命令的执行结果:

- 要查看该路由表,请运行下面的命令:

网格 CNI 插件为 ztunnel Pod 里设置 ztunnel Pod 也设置了路由规则,可以使用 ip rule list 命令查看路由规则:
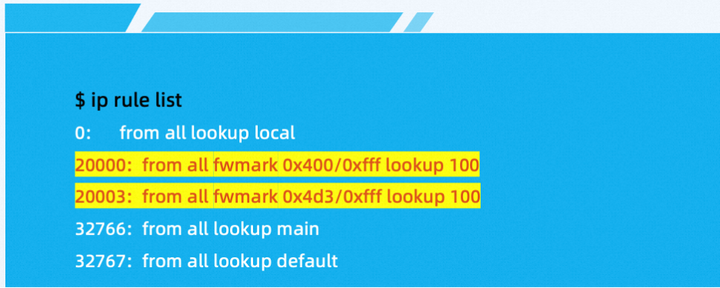
- 对应的添加命令如下:

对应的含义指,当数据包的标记值在 0x400~0xfff 范围内时,将会匹配这条规则,并将数据包发送到编号为 100 的路由表中进行操作,优先级为 20000。
当数据包的标记值恰好等于 0x4d3~0xfff 范围内时,将会匹配这条规则,并将数据包发送到编号为 100 的路由表中进行操作,优先级为 20003。
此外,网格 CNI 插件为 ztunnel 配置 iptables,定义如下:

可以看到,iptables 规则使用 TPROXY 标记(0x400/0xfff)标记来自入站或出站隧道的数据包,并将其定向到相应的 ztunnel 入站和出站端口。为什么使用 TPROXY 方式呢?TPROXY 是 Linux 内核的一个功能,允许在传输层透明地拦截和重定向网络流量,相比之下,使用 REDIRECT 目标修改数据包以更改目标地址。使用 TPROXY,这样请求从pod通过隧道到 ztunnel 代理的所有跳跃中,流量的原始源 IP 和端口被保留,允许目标服务器看到原始客户端的 IP 地址和端口。
04 节点与 ztunnel 通过 Geneve 隧道连接
Geneve(Generic Network Virtualization Encapsulation)是一种网络虚拟化封装(隧道)协议,它的设计的初衷是为了解决当前数据传输缺乏灵活性和安全性的问题。
Geneve 相较于 VXLAN 封装,具有更加灵活、安全、扩展和运维的特点,适用于更加复杂和安全性要求高的虚拟化网络环境。
veth 设备与 netlink 机制之间存在关联。netlink 是 Linux 内核中的一种通信机制,用于内核与用户空间之间的通信。通过 netlink 机制,用户空间可以向内核发送请求,获取网络设备、路由表、套接字等信息,实现网络配置和管理等功能。
在容器化技术中,veth 设备的创建和配置通常是通过 netlink 机制实现的。前面的介绍中提及可以使用以下类似命令创建一个名为 istioin 的 Geneve 设备:
ip link add name istioin type geneve id 1000 remote “${ZTUNNEL_IP}”
其中,type geneve 表示创建一个 Geneve 设备,id 1000 表示设备的虚拟网络标识符,remote IP 地址表示设备的远程目的地址。
CNI 插件在每个节点上初始化路由并设置 iptables 和 ipset 规则。在每个节点上,设置了两个虚拟接口 – istioin 和 istioout,用于处理节点上的入站 (istioin) 和出站 (istioout) 流量。其中,虚拟接口 istioin 和 istioout 的 IP 地址分别为 192.168.126.1 和 192.168.127.1。
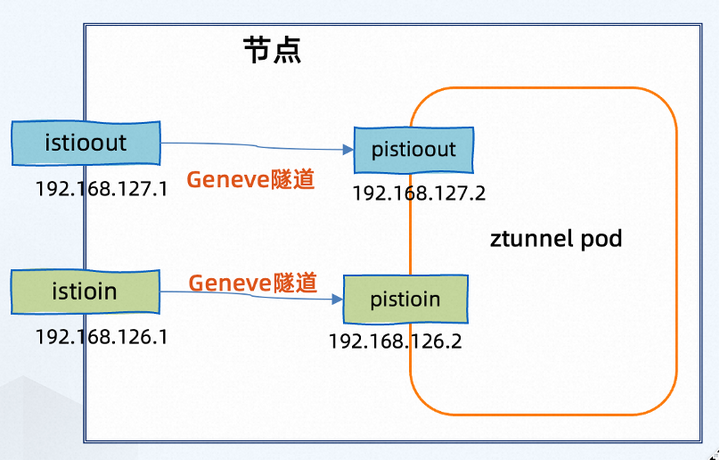
这两个接口使用 GENEVE(通用网络虚拟化封装)隧道连接到在同一节点上运行的 ztunnel pod 的接口 pistioin 和 pistioout 上。其中,虚拟接口 pistioin 和 pistioout的 IP 地址分别为 192.168.126.2 和 192.168.127.2。
结合节点上的 iptables 规则和路由表,确保来自 ambient pods 的流量被拦截,并根据方向(入站或出站)分别发送到 istioout 或 istioin。发送到这些接口的数据包最终会到达在同一节点上运行的 ztunnel pod 的 pistioout 或 pistioin。
具体来说,使用 Geneve 隧道连接到节点上的 istioout 接口 —> ztunnel 端的 pistioout 接口,如下所示:
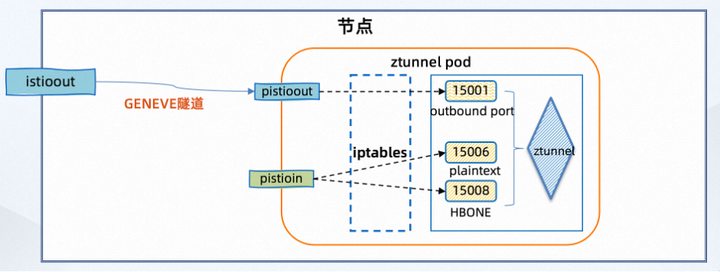
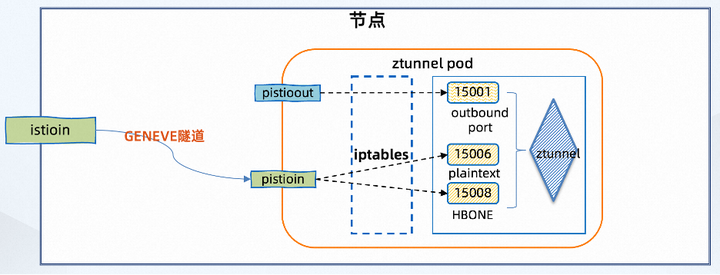
使用 Geneve 隧道连接到节点上的 istioin 接口 —> ztunnel 端的 pistioin 接口,如下所示:
05 L4 与 L7 的融合及端到端的流量路径
对于仅涉及到 4 层请求的业务场景来说,L4 请求处理下的端到端的流量路径如下所示:
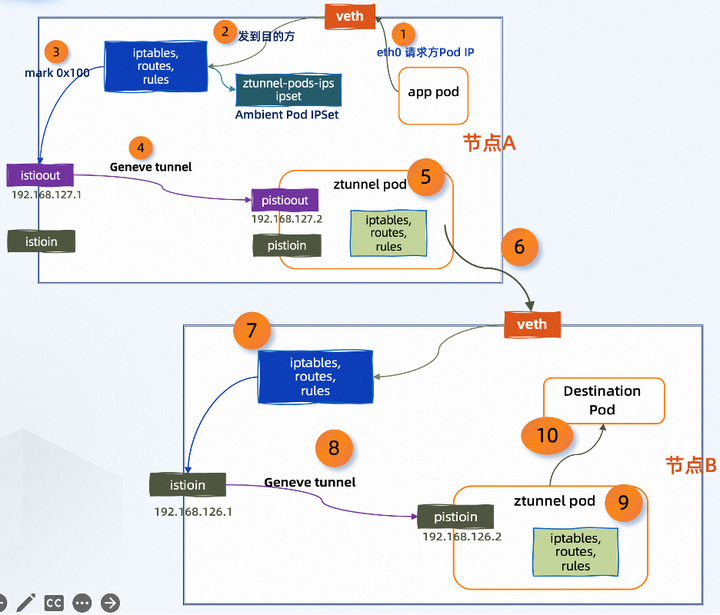
1. Ambient 模式下的应用 Pod 会被 CNI 插件将其 IP 地址写入到 ipset 中,当发起请求时,流量数据包进入到该节点上对应的 veth 接口。
2. sleep app pod 的请求被节点上的规则和 iptables 配置捕获。
3. 因为该 pod 是环境网格的一部分,它的 IP 地址被添加到节点上的 IP 集合中,并且数据包被标记为 0x100。
4. 节点上的规则指定任何标记为 0x100 的数据包都要通过 istio 出口接口定向到目标 192.168.127.2。
5. ztunnel 代理上的规则透明地代理来自 pistioout 的数据包到 ztunnel 出站端口 15001。
6. ztunnel 处理数据包并将其发送到目标服务(httpbin)的 IP 地址。该地址在节点 B 上为 httpbin创建专用接口 veth,请求在该接口上被捕获。
7. 入站流量的规则确保数据包被路由到 istioin 接口。
8. istioin 和 pistioin 之间的隧道使数据包落在 ztunnel pod 上。
9. iptables 配置捕获来自 pistioin 的数据包,并根据标记将它们定向到端口 15008。
10. ztunnel pod 处理数据包并将其发送到目标 pod。而如果涉及到 7 层请求的业务场景来说,端到端的流量路径则增加了 Waypoint Proxy 的部分,如下所示:
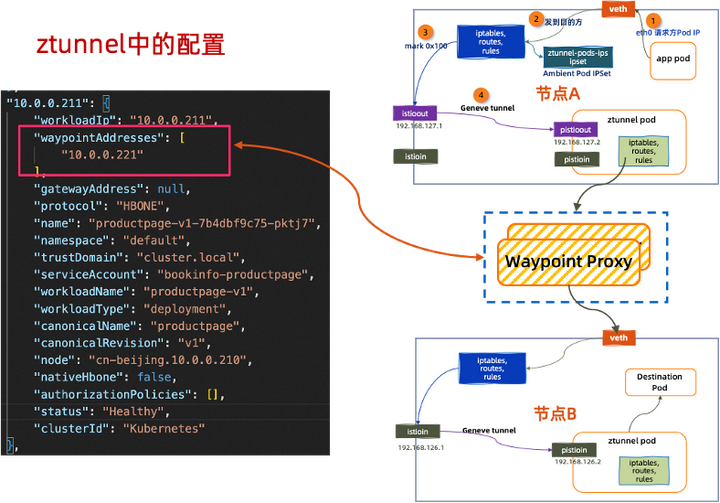
在 Waypoint Proxy 中执行的流程如下:
1. 进入到 waypoint proxy 之后, 通过流量总入口监听 connect_terminate 接收来自 HBONE 的流量,包括身份认证,HBONE 解包等。然后将流量转给 main_internal 这个主监听器。
2. 主监听器里面有匹配逻辑,根据 service ip + port 来匹配。匹配上之后,执行各种 L7 流量策略。然后转发给对应的 cluster。cluster 并没有把流量直接转发出去,而是转发给了connect_originate。
3. connect_originate 以 HBONE 的方式,向上游转发数据。
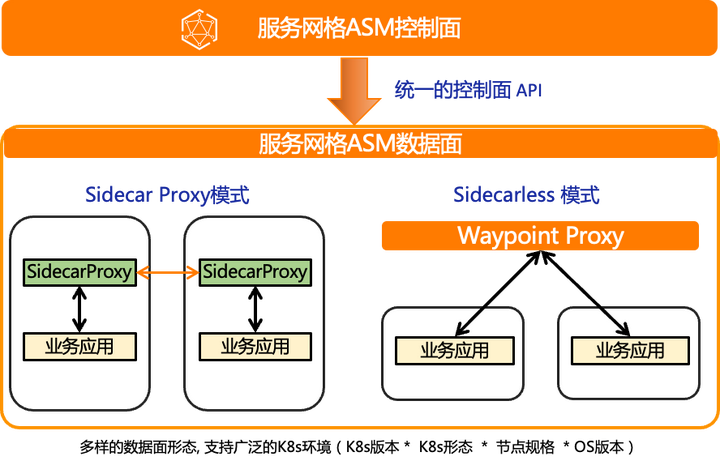
06 Sidecarless 与 Sidecar 模式融合的服务网格
作为业内首个全托管 Istio 兼容的阿里云服务网格 ASM 产品,在不同维度提供了企业级产品功能:
1)在控制面维度,实现了全面托管机制,为用户降低运维复杂度;为数据面提供了统一标准化的接入方式;支持开箱即用的 EnvoyFilter 插件市场,支持 Serverless/Knative 及 AI Serving/KServe 生态等。
2)在数据面维度,支持形态与功能多样化,支持不同形态的计算基础设施,包括 K8s 集群、Serverless ECI 节点、边缘集群、注册集群等;支持不同的数据面网络形态;支持异构服务统一治理、精细化的多协议流量控制与全链路灰度管理。
3)在性能维度,实现软硬一体的端到端网格优化,支持自适应配置推送优化,实现了 AVX 指令集提升 TLS 加解密、以及资源超卖模式下的支持等。更多内容可以参考:《企业级服务网格优化中心:优化 Service Mesh 以提高性能和高可用性》
近期阿里云服务网格 ASM 产品即将推出业界首个 Sidecarless 与 Sidecar 模式融合的服务网格平台,欢迎试用与交流!
可以通过:https://www.aliyun.com/product/servicemesh 查看具体的内容介绍。
作者:王夕宁 阿里云服务网格负责人,以下内容基于 2023 全球软件工程创新技术峰会的演讲内容整编而成
点击立即免费试用云产品 开启云上实践之旅!
原文链接
本文为阿里云原创内容,未经允许不得转载
