

目录
一、常用的数据类型
二、数据库索引
什么是数据库索引
索引的作用
索引是否越多越好
索引的分类
三、sql语句
插入
更新
删除
查询
普通查询
子查询
连表查询
四、常用的一些函数
group by 分组
order by 排序
HAVING 子句 根据条件过滤组
格式化日期或时间——date_format()
limit
count()
IN & BETWEEN
AVG()
DISTINCT 去重
SQL 注入(Injection)
一、常用的数据类型
int
存储的范围:-2**32~2**32-1
bigint
数字范围:-2**63 – 2**63-1
float
float(m,d),其中m表示有效位,d表示小数位
有效位就是把当前的小数:12345.12 转变成科学计数法:1.234512*10**5
m的最大值为7
double
double(m,d)其中m表示有效位,d表示小数位
m的最大值为15
decimal
涉及到金额的时候,使用decimal
decimal(m,d),其中m表示有效位,d表示小数位
m的最大值为65
好处:不会产生精度问题,因为decimal存储的本质是因为它存在的是字符串,所以不会有精度损失的问题
char
表示固定长度的字符串,长度为255个字节。中文字符占据3-4个字节
varchar
表示不定长度字符串,长度为 0-65525 个字节
text
长文本类型,最大长度为64KB
longtext
极大文本类型,最大长度占据4GB
datetime
如果当前时区发生更改,datetime类型不会发生更改,与存入的日期保持一致
timestamp
如果时区发生更改,timestamp类型会耕者失去更改
二、数据库索引
-
什么是数据库索引
数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询,更新数据库中表的数据。除了数据之外,数据库系统还维护为满足特定查找算法的数据结构,这些数据结构以某种方式引用数据,这种数据结构就是索引。简言之,索引就类似于书本,字典的目录。如果将本文看做一个数据库,那么顶部的目录就相当于索引
-
索引的作用
-
主要目的就是查询过程中的系统性
-
通过创建唯一索引,可以保证数据库中索引对应字段的唯一性
-
在使用分组和排序子句进行数据检索时,可以减少查询中分组和排序的时间
-
-
索引是否越多越好
首先:索引并不是创建的越多越好
-
创建索引和维护索引要耗费时间,而且时间随着数据量的增加而增
-
索引需要占物理空间,如果创建的是聚簇索引,占据的空间会更大
-
在对表中数据做增删改的操作时,会消耗跟多的时间,因为索引也需要维护
-
-
索引的分类
1、主键索引:数据库设置为主键后,会自动创建索引
#随表一起建索引:
CREATE TABLE customer (id INT(10) UNSIGNED ,customer_no VARCHAR(200)
PRIMARY KEY(id)
);
#使用AUTO_INCREMENT关键字的列必须有索引(只要有索引就行)。
CREATE TABLE customer2 (id INT(10) UNSIGNED AUTO_INCREMENT, customer_no VARCHAR(200),
PRIMARY KEY(id)
);
#单独建主键索引:
ALTER TABLE customer add PRIMARY KEY customer(customer_no);
#删除建主键索引:
ALTER TABLE customer drop PRIMARY KEY ;
#修改建主键索引:
#必须先删除掉(drop)原索引,再新建(add)索引
2、普通索引(单列索引):一个索引只包含单个列,一个数据表可以有多个单列索引
#随表一起建索引:
CREATE TABLE customer (id INT(10) UNSIGNED AUTO_INCREMENT ,customer_no VARCHAR(200),customer_name VARCHAR(200),
PRIMARY KEY(id), # 主键索引
KEY (customer_name) # 单列索引
);
#随表一起建立的索引 索引名同 列名(customer_name)
#单独建单值索引:
CREATE INDEX idx_customer_name ON customer(customer_name); # 创建名称为 “idx_customer_name” 的普通索引
#删除索引: 删除名称为“idx_customer_name” 的普通索引
DROP INDEX idx_customer_name ;
3、唯一索引:索引的值必须唯一,但是允许有空值
“UNIQUE” 字段:约束唯一标识数据库表中的每条记录。
#随表一起建索引:
CREATE TABLE customer (id INT(10) UNSIGNED AUTO_INCREMENT ,customer_no VARCHAR(200),customer_name VARCHAR(200),
PRIMARY KEY(id),
KEY (customer_name),
UNIQUE (customer_no) # 唯一性约束
);
#建立 唯一索引时必须保证所有的值是唯一的(除了null),若有重复数据,会报错。
#单独建唯一索引:
CREATE UNIQUE INDEX idx_customer_no ON customer(customer_no);
#删除索引:
DROP INDEX idx_customer_no on customer ;
4、复合索引:一个索引包含多个列;
在数据库操作期间,相比于多个单列索引,复合索引所需要的开销更小。
使用场景:如果一个表中的数据在查询时有多个字段总是同时出现则这些字段就可以作为复合索引,形成索引覆盖可以提高查询的效率!
-- 随表一起建索引:
CREATE TABLE customer (id INT(10) UNSIGNED AUTO_INCREMENT ,customer_no VARCHAR(200),customer_name VARCHAR(200),
PRIMARY KEY(id), # 主键索引
KEY (customer_name), # 单列索引
UNIQUE (customer_name), # 单列索引唯一值约束
KEY (customer_no,customer_name) # 复合索引
);
#单独建索引:
CREATE INDEX idx_no_name ON customer(customer_no,customer_name);
#删除索引:
DROP INDEX idx_no_name on customer ;
5、聚簇索引与非聚簇索引
6、稠密索引与稀疏索引
7、聚集索引于非聚集索引
太多了,从来没有在实际工作中碰到过,我也不知道有什么用,等到哪天如果真的涉及到这些索引的时候,在做具体补充吧
三、sql语句
插入
-- 普通插入
insert into table values('xx','xx','xx')
-- 查询插入
insert into student(name, age, class) select `name`, `age`, `class` from student
更新
-- 和where条件搭配使用
update table set column1_name = value1 where 条件
-- 更新多个列
update table set column1_name = value1, column2_name = value2,...WHERE condition;
删除
-- 删除表
drop 表名
-- 清空表里的内容:删除所有数据,保留表结构,不能撤销还原,速度快
truncate table 表名
-- 删除表,表数据和表结构一起删除,速度快
drop form 表名
-- 删除表里的部分内容:逐行删除,不适合大量数据删除,速度慢
delete from 表名 where 列名="value "
查询
普通查询
-- 简单查询
Select * from 表名
Select * from 表名 where 条件子查询
-- 子查询
-- 子sql查询出来的结果是主sql的条件
Select * from 表名 where(select * from 表名 where 条件)连表查询
-- 左连接(left join)
-- 左连接以左表为主,会展示左表所有的数据,右表只展示符合条件的数据
Select t1.字段1,t2.字段2 From table1 t1
Left join table2 t2 on t1.id = t2.id
-- 右连接(right join)
-- 右连接以右表为主,会展示右表所有数据,左表数据只展示符合条件的数据
Select t1.字段1,t2.字段2 From table1 t1
right join table2 t2 on t1.id = t2.id
-- 内连接(inner join)
-- 主要是获取两个表中字段匹配关系的表。查询关联字段共同拥有的数据,用两个表相同的字段和内容相关联起来。
select * from table1 as 别名1
inner join table2 as 别名2
on 别名1.字段名1=别名2.字段名1;
select * from user as u
inner join student as s on u.id=s.id;。
-- 全连接(FULL JOIN )
-- 返回连接的表中的所有数据,不管是否匹配
-- 交叉连接(CROSS JOIN)
如果在连接两个表时未指定连接条件,则数据库系统会将第一个表的每一行与第二个表的每一行合并。这种连接称为交叉连接或笛卡尔乘积四、常用的一些函数
group by 分组
GROUP BY子句与SELECT语句和聚合函数结合使用,以按通用列值将行分组在一起
SELECT t1.dept_name, count(t2.emp_id) AS total_employees
FROM departments AS t1
LEFT JOIN employees AS t2
ON t1.dept_id = t2.dept_id
GROUP BY t1.dept_name;order by 排序
通常,当您使用SELECT语句从表中获取数据时,结果集中的行没有任何特定的顺序。如果要按特定顺序排列结果集,则可以在语句末尾指定ORDER BY子句,该子句告诉程序如何对查询返回的数据进行排序。默认排序顺序为升序。
SELECT column_list FROM table_name ORDER BY column_name ASC|DESC;
HAVING 子句 根据条件过滤组
HAVING子句通常与 GROUP BY 子句一起使用,以指定组或集合的过滤条件。HAVING 子句只能与 SELECT 语句一起使用
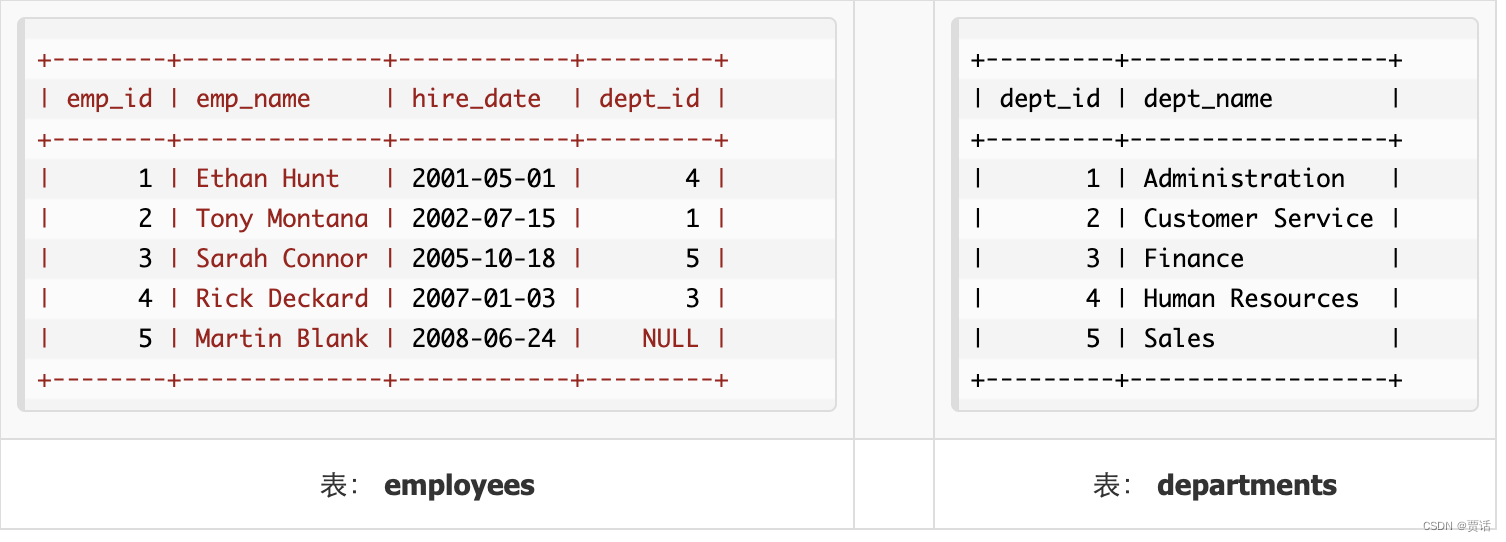
例如:现在,不只是查找员工及其部门的名称,还要查找没有员工的部门的名称。
SELECT t1.dept_name, count(t2.emp_id) AS total_employees
FROM departments AS t1
LEFT JOIN employees AS t2
ON t1.dept_id = t2.dept_id
GROUP BY t1.dept_name
HAVING total_employees = 0;格式化日期或时间——date_format()
SELECT name, DATE_FORMAT(birth_date, '%M %e, %Y') FROM users;limit
1、当limit使用一个参数时
例如:limit 10
则表示将表中的前10条数据查询出来,–检索前10行数据
2、当limit使用两个参数时
例如:limit 2,5
第一个参数表示从第几行数据开始查,第二个参数表示查几条数据,”limit 2,5″;表示从第3行数据开始,取5条数据
***当指定了两个参数时,第一个参数指定要返回的第一行的偏移量,即起点,而第二个参数指定要返回的最大行数。初始行的偏移量是0(不是1)。
count()
COUNT() 函数返回匹配指定条件的行数。
1、COUNT(column_name)
函数返回指定列的值的数目(NULL 不计入):
SELECT COUNT(column_name) FROM table_name;
2、SQL COUNT(DISTINCT column_name) 语法
COUNT(DISTINCT column_name) 函数返回指定列的不同值的数目:
SELECT COUNT(DISTINCT column_name) FROM table_name;
count总结:
count(*):统计行数,不会忽略null
count(列名):单独一列符合条件的行数,会忽略空值
count(1):统计行数,会忽略空值
count 的执行效率

IN & BETWEEN
1、IN运算符是逻辑运算符,用于检查一组值中是否存在特定值。 其基本语法可以通过以下方式给出:
SELECT column_list FROM table_name
WHERE column_name IN (value1, value1,...);2、between
如果列中的值落在特定范围内,有时您想选择一行。处理数字数据时,这种类型的条件很常见。
要基于这种条件执行查询,您可以利用BETWEEN运算符。它是一个逻辑运算符,可让您指定要测试的范围,如下所示:
SELECT column1_name, column2_name, columnN_name
FROM table_name
WHERE column_name BETWEEN min_value AND max_value;AVG()
AVG() 函数返回数值列的平均值。
SELECT AVG(column_name) FROM table_name
DISTINCT 去重
从数据库表中获取数据时,结果集可能包含重复的行或值。 如果要删除这些重复的值,可以在SELECT关键字之后直接指定关键字DISTINCT,如下所示:
SELECT DISTINCT column_list FROM table_name;
SQL 注入(Injection)
什么是sql注入
SQL注入是一种攻击,攻击者可以通过浏览器向应用程序服务器输入的数据(例如Web表单输入)注入或执行恶意SQL代码。
SQL 注入(Injection) – 基础教程在线
