

目录
一.索引的概念
1.1索引的简介
1.2.索引的优缺点
二.MySQL索引语法
2.1查看索引
2.2创建索引
2.2.1 创建表时创建索引
2.2.2存在的表上创建索引
2.3删除索引
三.索引的数据结构
3.1B+tree索引
3.2Hash索引
3.4Hash索引和B+tree索引的对比
🎁个人主页:tq02的博客_CSDN博客-C语言,Java,Java数据结构领域博主
🎥 本文由 tq02 原创,首发于 CSDN🙉
🎄 本章讲解内容:MySQL索引🎁欢迎各位→点赞👍 + 收藏⭐ + 评论📝+关注✨
🎥学习专栏: C语言 JavaSE MySQL基础

一.索引的概念
1.1索引的简介
索引是什么?本质而言是一种数据结构, 实现通常使用B树及其变种B+树 。
抽象点:我们把索引比作一本书的目录,而目录的作用就是使我们迅速地找到我们需要的内容,而为什么需要索引?当数据表中含有上亿条数据时,我们进行查询是通过遍历表,一条一条筛选时,是不现实的,但是我们可以使用索引,就可知我们需要的数据大概的位置。
常见的索引方式:字典,可以有两种方式进行查询,第一种是拼音,第二种是部首,而这就是两种不同的索引方式。
1.2.索引的优缺点
优点:
- 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
- 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
缺点:
- 创建索引需要消耗额外的空间
- 有可能会拖慢 增删改 的速度,试想一下,当你修改了数据表的信息时,你的目录也就是索引也可能需要修改的。
结:个人而言,缺点相比较与优点,我们还是利大于弊的,在很多情况下,我们都是以查询操作为主,而增删改较少。
二.MySQL索引语法
索引分为:普通索引、唯一索引、全文索引、单列索引、多列索引、空间索引
2.1查看索引
查看索引,有人会问,我未创建索引,也会有索引嘛?在数据库中有三种约束类型存在时会自动生成索引,因此在查询时,即使未创建索引,若有这种条件存在,依然会生成索引。
三种约束类型:主键、unique、外键
也称:主键索引、唯一索引
语法:show index from 表名;
存在主键时
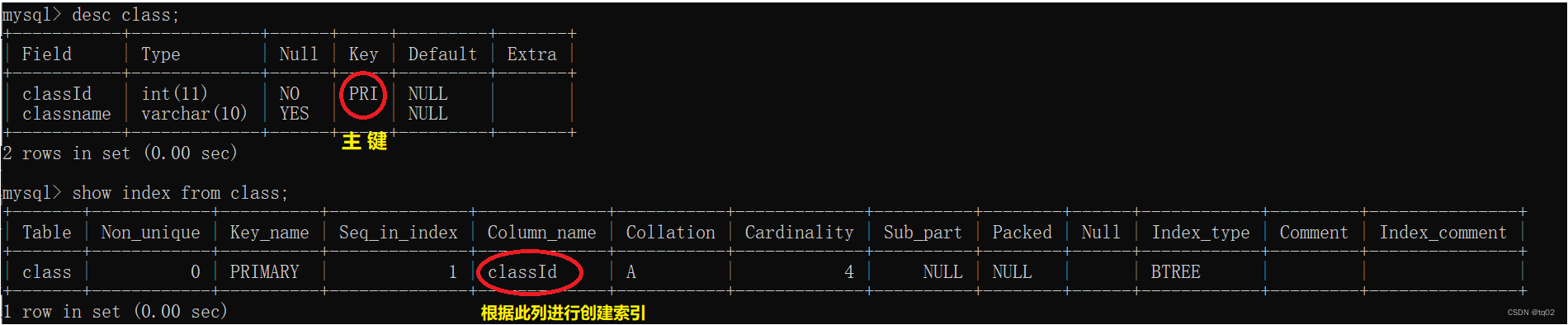
主键不允许重复,因此进行插入或者修改时,需要先查询,查看插入/修改后结果是否存在。
存在unique时

存在外键约束时

当然除了以上的三种,我们还可以查看到手动创建的索引。
2.2创建索引
- 索引创建分为2种,第一种是创建表时创建索引,第二种是给存在的表创建索引
- 索引的创建,前提是表中的数据较少或者无数据,若含有大量数据会引起非常大规模的硬盘IO操作,进一步导致数据库卡死。
2.2.1 创建表时创建索引
语法格式: CREATE TABLE 表名(
字段名称 字段类型 [完整性约束条件],
…,
[UNIQUE / FULLTEXT / SPATIAL] INDEX / KEY [索引名称](字段名称[(长度)] [ASC|DESC])
);
- 创建普通索引
创建了2个索引,分别为id和username
CREATE TABLE test1(
id int,
username varchar(20),
index in_id(id),
KEY in_username(username)
);- 创建唯一索引
CREATE TABLE test2(
id int,
username varchar(20) unique; //自动生成
);
- 创建全文索引
CREATE TABLE test3(
id int
username VARCHAR(20) ,
FULLTEXT INDEX full_userDese(username)
);
- 创建单列索引
CREATE TABLE test4(
id int UNSIGNED AUTO_INCREMENT KEY,
test1 VARCHAR(20) NOT NULL,
test2 VARCHAR(20) NOT NULL,
INDEX in_test1(test1),
UNIQUE in_test1(test1)
);
- 创建多列索引
CREATE TABLE test4(
id int UNSIGNED AUTO_INCREMENT KEY,
test1 VARCHAR(20) NOT NULL,
test2 VARCHAR(20) NOT NULL,
test3 VARCHAR(20) NOT NULL,
INDEX mul_t1_t2_t3(test1,test2,test3)
UNIQUE KEY mul_t1_t2_t3(test1,test2,test3) //二者都可以
);
- 创建空间索引
CREATE TABLE test1(
id TINYINT UNSIGNED AUTO_INCREMENT KEY,
SPATIAL INDEX spa_test(test)
)ENGINE=MyISAM;2.2.2存在的表上创建索引
概念:在存在的表上创建索引,可以直接创建,也可以将某列修改为某种索引
直接创建:CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX 索引名称 ON 表名 {字段名称[(长度)] [ASC|DESC]};
简化:create index 索引名 on 表名(字段名) //其他条件不设置
修改表方式创建:ALTER TABLE 表名 ADD [UNIQUE|FULLTEXT|SPATIAL] INDEX 索引名称](字段名称[(长度)] [ASC|DESC]); //将某个列修改为索引
- 创建普通索引
1、CREATE INDEX 索引名 ON 表名(列名);
2、ALTER TABLE 表名 ADD INDEX 索引名(列名);
- 创建唯一索引
1、CREATE UNIQUE INDEX 索引名 ON 表名(列名);
2、ALTER TABLE 表名 ADD UNIQUE INDEX 索引名(列名);
- 创建全文索引
1、CREATE FULLTEXT INDEX 索引名 ON 表名(列名);
- 创建多列索引
1、ALTER TABLE 表名 add INDEX 索引名(列名,列名…..);
2.3删除索引
- 索引的删除,只能删除手动创建的索引,而自动生成的索引无法删除哦
语法:drop index 索引名 on 表名;
三.索引的数据结构
MySQL的索引的数据结构到底是什么样的呢?其实并不是定式的,取决于MySQL使用的存储引擎。
- 存储引擎: 在mysql程序中,拥有很多模块,有的负责解析sql语句、有的负责网络通信、有的负责存储数据等等。存储引擎就是负责存储数据的,本质而言就是代码中的一个模块(包含了若干个代码文件…以及一大堆具体的代码)
具体如何存储数据,MySQL提供了多种存储方案。而目前最为流行的便是Innodb存储引擎。而Innodb引擎选择使用B+tree索引结构。而至于为什么不选别的索引结构呢?下解:
适合索引的数据结构有 B+tree索引、Hash索引等。
3.1B+tree索引
B+tree数据结构的演变:二叉树–>红黑树–>B-tree树–>B+tree树,而之所以会逐渐演变,是因为有缺点存在,而为了提高效率,就不断演化。
1.二叉树的缺点
- 顺序插入时,会形成一个链表,查询性能大大降低。
- 大数据量情况下,层级较深,检索速度慢。
2.红黑树的缺点
- 大数据量情况下,层级较深,检索速度慢。
3.B-tree树
又名:B-树,是一种多叉路衡查找树,对比二叉树,B-树每个结点可以存放多个数值,也就是说一个结点有多个分支,即多叉。
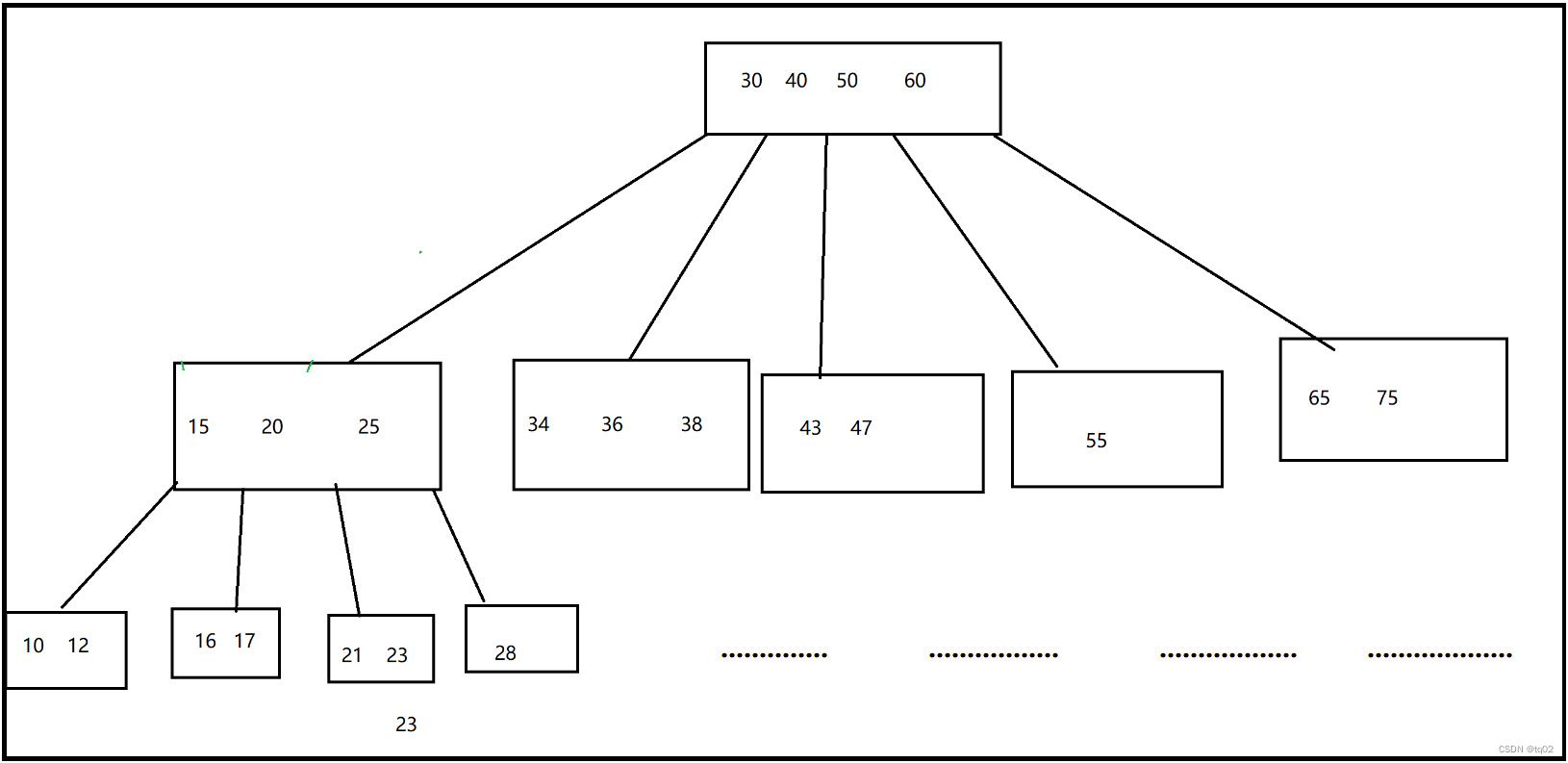 如图:B-树更趋向于区间查找,根结点是30、40、50、60,所以对应的孩子结点范围为[最小值,30)、[30,40)、[40,50)、[50,60)、[60,最大值].
如图:B-树更趋向于区间查找,根结点是30、40、50、60,所以对应的孩子结点范围为[最小值,30)、[30,40)、[40,50)、[50,60)、[60,最大值].
查询方法:例如查询23,在根结点中找到区间小于30,往下个结,[15,25]区间,找然后又落在了[20,25]区间,再往下找,最终找到叶子结点[21,23],存在。
优点:高度低于红黑树,查询效率更高
缺点:无法进行范围查询
4.B+tree树
B+Tree是B-Tree的变种,所有的数据都会出现在叶子节点。 叶子节点形成一个单向链表。所有的数据都会出现在叶子节点。 叶子节点形成一个单向链表。
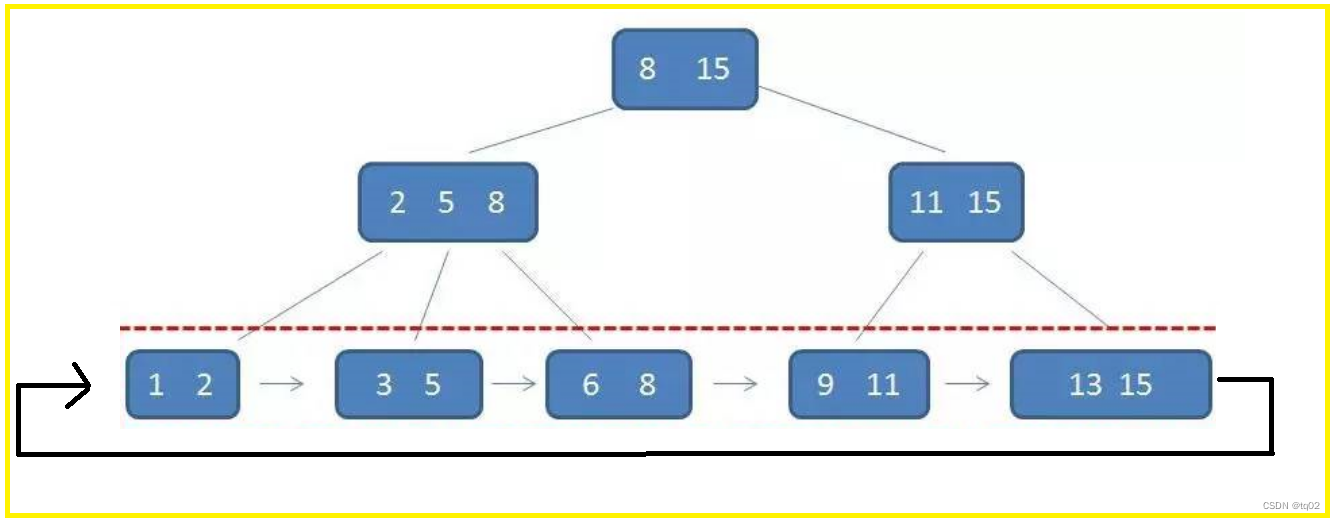
叶子结点,会按照链表的方式,首尾相连,注链表是双向链表,画是单向的,因此只要得到开头和结尾,然后将这段链表单独拉出来便是查询的结果
优点:擅长范围查询,查询速度不快不慢,但是很稳定。
3.2Hash索引
哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在 hash表中。如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称为hash碰撞),可以通过链表来解决。
缺点:
- Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,
- 无法利用索引完成排序操作
优点:查询效率高,通常(不存在hash冲突的情况)只需要一次检索就可以了,效率通常要高于B+tree索引
3.4Hash索引和B+tree索引的对比
因此InnoDB存储引擎选择使用B+tree索引结构的原因:
- 层级更少,搜索效率高
- 相对Hash索引,B+tree支持范围匹配及排序操作;
- 对于B-tree,无论是叶子节点还是非叶子节点,都会保存数据,但是存储索引结构的一个页的大小有限,这样导致一页中存储 的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低;
当你看到这里时,MySQL的索引知识就已经完成了,本文需要细心理解。
—————懒惰的tq02
