

目录
素材:
一、模块开发——数据预处理
1、分析预处理的数据
2、实现数据的预处理
(1)创建Maven项目,添加相关依赖
(2)创建JavaBean对象,封装日志记录
(3)创建MapReduce程序,执行数据预处理
二、模块开发——数据仓库开发
1、上传文件
2、实现数据仓库
三、模块开发——数据分析
四、模块开发——数据导出
五、模块开发——日志分析系统报表展示
1、搭建日志分析系统
(1)创建项目,添加相关依赖
(2)编写配置文件
2、实现报表功能展示
(1)创建持久化类
(2)实现DAO层
(3)实现Service层
(4)实现Controller层
(5)实现页面功能
3、系统功能模块展示
编辑
参考书籍:
素材:
http://链接: https://pan.baidu.com/s/1aNxbVjNq1z1A-oOIYy_E4Q?pwd=gjpt 提取码: gjpt http://链接: https://pan.baidu.com/s/1aNxbVjNq1z1A-oOIYy_E4Q?pwd=gjpt 提取码: gjpt
http://链接: https://pan.baidu.com/s/1aNxbVjNq1z1A-oOIYy_E4Q?pwd=gjpt 提取码: gjpt
一、模块开发——数据预处理
1、分析预处理的数据
在收集的日志文件中,通常情况下,不能直接将日志文件进行数据分析,这是因为日志文件中有许多不合法的数据(比如日志数据在网络传输过程中发送数据丢失)。
在数据预处理阶段,主要目的就是对收集的原始数据进行清洗和筛选,因此使用MapReduce 技术就可以轻松实现。在实际开发中,数据预处理过程通常不会直接将不合法的数据直接删除,而是对每条数据添加标识字段,从而避免其他业务使用时丢失数据。
另外,此次数据预处理只是清洗和筛选不合法的数据信息,会读取每行日志文件数据并最终输出一条数据,不会进行其他操作,因此在使用MapReduce技术进行处理过程中,只会涉及 Map 阶段,不会涉及Reduce 阶段。在默认情况下,ReduceTask值为1,因此在主运行函数中,需要设置 Job.setNumReduceTasks(0)。
2、实现数据的预处理
(1)创建Maven项目,添加相关依赖
pom.xml文件配置如下:
4.0.0
cn.itcast
HadoopDataReport
1.0-SNAPSHOT
org.apache.hadoop
hadoop-common
2.10.1
org.apache.hadoop
hadoop-client
2.10.1
org.apache.hadoop
hadoop-hdfs
2.10.1
org.apache.hadoop
hadoop-mapreduce-client-core
2.10.1
(2)创建JavaBean对象,封装日志记录
收集的日志数据中,每一行代表一条日志记录,并且包含有多个用空格分隔的字段信息,为了方便后续数据处理,创建一个 JavaBean 对象对每条数据进行封装。
WebLogBean.java
package cn.itcast.weblog.bean;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 对接外部数据的层,表结构定义最好跟外部数据源保持一致
* 同时实现序列号,方便网络数据传播
*/
public class WebLogBean implements Writable {
private boolean valid = true; //标记数据是否合法
private String remote_addr; //访客IP地址
private String remote_user; //记录访客用户信息,忽略属性“-”
private String time_local; //记录访问时间与时区
private String request; //记录请求的URL
private String status; //请求状态
private String body_bytes_sent; //记录发送给客户端文件主体内容大小
private String http_referer; //记录从哪个页面链接访问过来的
private String http_user_agent; //记录客户浏览器的相关信息
//设置 WebLogBean 进行字段数据封装
public void setBean(boolean valid, String remote_addr, String remote_user,
String time_local, String request, String status,
String body_bytes_sent,
String http_referer, String http_user_agent) {
this.valid = valid;
this.remote_addr = remote_addr;
this.remote_user = remote_user;
this.time_local = time_local;
this.request = request;
this.status = status;
this.body_bytes_sent = body_bytes_sent;
this.http_referer = http_referer;
this.http_user_agent = http_user_agent;
}
public boolean isValid() {
return valid;
}
public void setValid(boolean valid) {
this.valid = valid;
}
public String getRemote_addr() {
return remote_addr;
}
public void setRemote_addr(String remote_addr) {
this.remote_addr = remote_addr;
}
public String getRemote_user() {
return remote_user;
}
public void setRemote_user(String remote_user) {
this.remote_user = remote_user;
}
public String getTime_local() {
return time_local;
}
public void setTime_local(String time_local) {
this.time_local = time_local;
}
public String getRequest() {
return request;
}
public void setRequest(String request) {
this.request = request;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public String getBody_bytes_sent() {
return body_bytes_sent;
}
public void setBody_bytes_sent(String body_bytes_sent) {
this.body_bytes_sent = body_bytes_sent;
}
public String getHttp_referer() {
return http_referer;
}
public void setHttp_referer(String http_referer) {
this.http_referer = http_referer;
}
public String getHttp_user_agent() {
return http_user_agent;
}
public void setHttp_user_agent(String http_user_agent) {
this.http_user_agent = http_user_agent;
}
//重写 toString() 方法,使用 Hive 默认分隔符进行分隔,为后续导入 Hive 表提供便利
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(valid);
sb.append("01").append(this.getRemote_addr());
sb.append("01").append(this.getRemote_user());
sb.append("01").append(this.getTime_local());
sb.append("01").append(this.getRequest());
sb.append("01").append(this.getStatus());
sb.append("01").append(this.getBody_bytes_sent());
sb.append("01").append(this.getHttp_referer());
sb.append("01").append(this.getHttp_user_agent());
return sb.toString();
}
//序列化方法
@Override
public void readFields(DataInput dataInput) throws IOException {
this.valid = dataInput.readBoolean();
this.remote_addr = dataInput.readUTF();
this.remote_user = dataInput.readUTF();
this.time_local = dataInput.readUTF();
this.request = dataInput.readUTF();
this.status = dataInput.readUTF();
this.body_bytes_sent = dataInput.readUTF();
this.http_referer = dataInput.readUTF();
this.http_user_agent = dataInput.readUTF();
}
// 反序列化方法(注意与序列化方法顺序保持一致)
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeBoolean(this.valid);
dataOutput.writeUTF(this.remote_addr);
dataOutput.writeUTF(this.remote_user);
dataOutput.writeUTF(this.time_local);
dataOutput.writeUTF(this.request);
dataOutput.writeUTF(this.status);
dataOutput.writeUTF(this.body_bytes_sent);
dataOutput.writeUTF(this.http_referer);
dataOutput.writeUTF(this.http_user_agent);
}
}(3)创建MapReduce程序,执行数据预处理
创建 JavaBean 实体类后,接下来开始编写 MapReduce 程序,进行数据预处理。
WebLogPreProcess.java
package cn.itcast.weblog.preproces;
import cn.itcast.weblog.bean.WebLogBean;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
/**
* 日志数据处理:数据清洗、日期格式转换、缺失字段填充默认值、字段添加合法标记
*/
public class WebLogPreProcess {
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WebLogPreProcess.class);
job.setMapperClass(WebLogPreProcessMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//此次案例测试数据不是非常大,所以使用本地路径
//(实际情况会对 HDFS 上存储的文件进行处理)
FileInputFormat.setInputPaths(job, new Path("/home/huanganchi/Hadoop/实训项目/HadoopDemo/textHadoop/weblog/input"));
FileOutputFormat.setOutputPath(job, new Path("/home/huanganchi/Hadoop/实训项目/HadoopDemo/textHadoop/weblog/output"));
//将 ReduceTask 属设置为 0,不需要 Reduce 阶段
job.setNumReduceTasks(0);
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
//mapreduce 程序 map 阶段
public static class WebLogPreProcessMapper extends Mapper {
//用来存储网站 URL 分类数据
Set pages = new HashSet();
Text k = new Text();
NullWritable v = NullWritable.get();
/**
* 设置初始化方法, 用来表示用户请求的是合法数据
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
pages.add("/about");
pages.add("/black-ip-list");
pages.add("/cassendra-cluster/");
pages.add("/finance-rhive-repurchase");
pages.add("/hadoop-family-roadmad");
pages.add("/hadoop-hive-intro/");
pages.add("/hadoop-zookeeper-intro");
pages.add("/hadoop-mahout-roadmap");
}
/**
* 重写 map()方法,对每行记录重新解析转换并输出
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行数据
String line = value.toString();
//调用解析类 WebLogParser 解析日志数据,最后封装为 WebLogBean 对象
WebLogBean webLogBean = WebLogParser.parser(line);
if (webLogBean != null) {
//过滤 js/图片/css 等静态资源
WebLogParser.filtStaticResource(webLogBean, pages);
k.set(webLogBean.toString());
context.write(k, v);
}
}
}
}
WebLogParser.java
package cn.itcast.weblog.preproces;
import cn.itcast.weblog.bean.WebLogBean;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Locale;
import java.util.Set;
public class WebLogParser {
//定义时间格式
public static SimpleDateFormat df1 = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss", Locale.US);
public static SimpleDateFormat df2 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss", Locale.US);
/**
* 根据采集的数据字段信息进行解析封装
*/
public static WebLogBean parser(String line) {
WebLogBean webLogBean = new WebLogBean();
//把一行数据以空格字符切割并存入数组arr中
String[] arr = line.split(" ");
//如果数组长度小于等于11,说明这条数据不完整,因此可以忽略这条数据
if (arr.length > 11) {
//满足条件的数据逐个赋值给webLogBean对象
webLogBean.setRemote_addr(arr[0]);
webLogBean.setRemote_user(arr[1]);
String time_local = formatDate(arr[3].substring(1));
if (null == time_local || "".equals(time_local)) time_local = "-invalid_time-";
webLogBean.setTime_local(time_local);
webLogBean.setRequest(arr[6]);
webLogBean.setStatus(arr[8]);
webLogBean.setBody_bytes_sent(arr[9]);
webLogBean.setHttp_referer(arr[10]);
//如果useragent元素较多,拼接useragent
if (arr.length > 12) {
StringBuilder sb = new StringBuilder();
for (int i = 11; i = 400) {
webLogBean.setValid(false);
}
if ("-invalid_time-".equals(webLogBean.getTime_local())) {
webLogBean.setValid(false);
}
} else {
webLogBean = null;
}
return webLogBean;
}
//对请求路径资源是否合法进行标记
public static void filtStaticResource(WebLogBean bean, Set pages) {
if (!pages.contains(bean.getRequest())) {
bean.setValid(false);
}
}
//格式化时间方法
public static String formatDate(String time_local) {
try {
return df2.format(df1.parse(time_local));
} catch (ParseException e) {
return null;
}
}
}
运行结果:
二、模块开发——数据仓库开发
1、上传文件
在启动了Hadoop的Linux系统root目录下创建目录weblog,并将预处理产生的结果文件上传到 weblog 目录下。
cd
mkdir weblog
cd weblog
执行 rz 文件上传命令在HDFS上创建目录,用于存放预处理过的数据,并上传数据到HDFS。
hadoop fs -mkdir -p /weblog/preprocessed
hadoop fs -put part-m-00000 /weblog/preprocessed2、实现数据仓库
启动Hive数据仓库,执行以下操作:
--创建数据仓库
DROP DATABASE IF EXISTS weblog;
CREATE DATABASE weblog;
USE weblog;
--创建表
CREATE TABLE ods_weblog_origin (
valid string, --有效标志
remote_addr string, --来源IP
remote_user string, --用户标志
time_local string, --访问完整时间
request string, --请求的URL
status string, --响应码
body_bytes_sent string, --传输字节数
http_referer string, --来源URL
http_user_agent string --客户终端标志
)
partitioned by (datestr string)
row format delimited fields terminated by '01';
--导入数据
load data inpath '/weblog/preprocessed' overwrite into table ods_weblog_origin partition(datestr='20130918');
--生成明细表
--1. 创建明细表 ods_weblog_detwail
CREATE TABLE ods_weblog_detwail (
valid string, --有效标志
remote_addr string, --来源IP
remote_user string, --用户标志
time_local string, --访问完整时间
daystr string, --访问日期
timestr string, --访问时间
month string, --访问月
day string, --访问日
hour string, --访问时
request string, --请求的URL
status string, --响应码
body_bytes_sent string, --传输字节数
http_referer string, --来源URL
ref_host string, --来源的host
ref_path string, --来源路径
ref_query string, --来源参数query
ref_query_id string, --来源参数query的值
http_user_agent string --客户终端标志
)
partitioned by (datestr string);
--2. 创建临时中间表 t_ods_tmp_referurl
CREATE TABLE t_ods_tmp_referurl as SELECT a.*, b.*
FROM ods_weblog_origin a LATERAL VIEW
parse_url_tuple(regexp_replace(http_referer, """, ""),'HOST', 'PATH', 'QUERY', 'QUERY:id') b
as host, path, query, query_id;
--3. 创建临时中间表 t_ods_tmp_detail
CREATE TABLE t_ods_tmp_detail as
SELECT b.*, substring(time_local, 0, 10) as daystr,
substring(time_local, 12) as tmstr,
substring(time_local, 6, 2) as month,
substring(time_local, 9, 2) as day,
substring(time_local, 11, 3) as hour
FROM t_ods_tmp_referurl b;
--4. 修改默认动态分区参数
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
--5. 向 ods_weblog_detwail 表中加载数据
insert overwrite table ods_weblog_detwail partition(datestr)
SELECT DISTINCT otd.valid, otd.remote_addr, otd.remote_user,
otd.time_local, otd.daystr, otd.tmstr, otd.month, otd.day, otd.hour,
otr.request, otr.status, otr.body_bytes_sent,
otr.http_referer, otr.host, otr.path,
otr.query, otr.query_id, otr.http_user_agent, otd.daystr
FROM t_ods_tmp_detail as otd, t_ods_tmp_referurl as otr
WHERE otd.remote_addr = otr.remote_addr
AND otd.time_local = otr.time_local
AND otd.body_bytes_sent = otr.body_bytes_sent
AND otd.request = otr.request; 
三、模块开发——数据分析
--数据分析
--流量分析
--创建每日访问量表dw_pvs_everyday
CREATE TABLE IF NOT EXISTS dw_pvs_everyday(pvs bigint, month string, day string);
--从宽表 ods_weblog_detwail 获取每日访问量数据并插入维度表 dw_pvs_everyday
INSERT INTO TABLE dw_pvs_everyday
SELECT COUNT(*) AS pvs, owd.month AS month, owd.day AS day
FROM ods_weblog_detwail owd GROUP BY owd.month, owd.day;
--人均浏览量分析
--创建维度表dw_avgpv_user_everyday
CREATE TABLE IF NOT EXISTS dw_avgpv_user_everyday (day string, avgpv string);
--从宽表 ods_weblog_detwail 获取相关数据并插入维度表 dw_avgpv_user_everyday
INSERT INTO TABLE dw_avgpv_user_everyday
SELECT '2013-09-18', SUM(b.pvs)/COUNT(b.remote_addr) FROM
(SELECT remote_addr, COUNT(1) AS pvs FROM ods_weblog_detwail WHERE
datestr = '2013-09-18' GROUP by remote_addr) b;
INSERT INTO TABLE dw_avgpv_user_everyday
SELECT '2013-09-19', SUM(b.pvs)/COUNT(b.remote_addr) FROM
(SELECT remote_addr, COUNT(1) AS pvs FROM ods_weblog_detwail WHERE
datestr = '2013-09-19' GROUP by remote_addr) b;
INSERT INTO TABLE dw_avgpv_user_everyday
SELECT '2013-09-20', SUM(b.pvs)/COUNT(b.remote_addr) FROM
(SELECT remote_addr, COUNT(1) AS pvs FROM ods_weblog_detwail WHERE
datestr = '2013-09-20' GROUP by remote_addr) b;
INSERT INTO TABLE dw_avgpv_user_everyday
SELECT '2013-09-21', SUM(b.pvs)/COUNT(b.remote_addr) FROM
(SELECT remote_addr, COUNT(1) AS pvs FROM ods_weblog_detwail WHERE
datestr = '2013-09-21' GROUP by remote_addr) b;
INSERT INTO TABLE dw_avgpv_user_everyday
SELECT '2013-09-22', SUM(b.pvs)/COUNT(b.remote_addr) FROM
(SELECT remote_addr, COUNT(1) AS pvs FROM ods_weblog_detwail WHERE
datestr = '2013-09-22' GROUP by remote_addr) b;
INSERT INTO TABLE dw_avgpv_user_everyday
SELECT '2013-09-23', SUM(b.pvs)/COUNT(b.remote_addr) FROM
(SELECT remote_addr, COUNT(1) AS pvs FROM ods_weblog_detwail WHERE
datestr = '2013-09-23' GROUP by remote_addr) b;
INSERT INTO TABLE dw_avgpv_user_everyday
SELECT '2013-09-24', SUM(b.pvs)/COUNT(b.remote_addr) FROM
(SELECT remote_addr, COUNT(1) AS pvs FROM ods_weblog_detwail WHERE
datestr = '2013-09-24' GROUP by remote_addr) b;四、模块开发——数据导出
1. 创建 MySql 数据库和表
--数据导出
--创建数据仓库
DROP DATABASE IF EXISTS sqoopdb;
CREATE DATABASE sqoopdb;
USE sqoopdb;
--创建表
CREATE TABLE t_avgpv_num (
dateStr VARCHAR(255) DEFAULT NULL,
avgPvNum DECIMAL(6,2) DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
2. 执行数据导出命令
sqoop export
--connect jdbc:mysql://hadoop01.bgd01:3306/sqoopdb
--username root
--password 123456
--table t_avgpv_num
--columns "dateStr,avgPvNum"
--fields-terminated-by '01'
--export-dir /user/hive/warehouse/weblog.db/dw_avgpv_user_everyday
五、模块开发——日志分析系统报表展示
1、搭建日志分析系统
(1)创建项目,添加相关依赖
创建一个Java Web 框架的Maven工程
pom.xml
4.0.0
cn.itcast
Weblog
1.0-SNAPSHOT
war
org.springframework
spring-context
4.2.4.RELEASE
org.springframework
spring-beans
4.2.4.RELEASE
org.springframework
spring-webmvc
4.2.4.RELEASE
org.springframework
spring-jdbc
4.2.4.RELEASE
org.springframework
spring-aspects
4.2.4.RELEASE
org.springframework
spring-jms
4.2.4.RELEASE
org.springframework
spring-context-support
4.2.4.RELEASE
org.mybatis
mybatis
3.2.8
org.mybatis
mybatis-spring
1.2.2
com.github.miemiedev
mybatis-paginator
1.2.15
mysql
mysql-connector-java
5.1.32
com.alibaba
druid
1.0.9
jstl
jstl
1.2
javax.servlet
servlet-api
2.5
provided
javax.servlet
jsp-api
2.0
provided
junit
junit
4.12
com.fasterxml.jackson.core
jackson-databind
2.4.2
${project.artifactId}
src/main/java
**/*.properties
**/*.xml
false
src/main/resources
**/*.properties
**/*.xml
false
org.apache.maven.plugins
maven-compiler-plugin
3.2
1.8
1.8
UTF-8
org.apache.tomcat.maven
tomcat7-maven-plugin
2.2
/
8080
8
8
UTF-8
(2)编写配置文件
applicationContext.xml
db.properties
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://192.168.8.201:3306/sqoopdb?characterEncoding=utf-8
jdbc.username=root
jdbc.password=123456springmvc.xml
web.xml
Weblog
index.html
contextConfigLocation
classpath:spring/applicationContext.xml
org.springframework.web.context.ContextLoaderListener
CharacterEncodingFilter
org.springframework.web.filter.CharacterEncodingFilter
encoding
utf-8
CharacterEncodingFilter
/*
data-report
org.springframework.web.servlet.DispatcherServlet
contextConfigLocation
classpath:spring/springmvc.xml
1
data-report
/
404
/WEB-INF/jsp/404.jsp
SqlMapConfig.xml
2、实现报表功能展示
(1)创建持久化类
TAvgpvNum.java
package cn.itcast.pojo;
import java.math.BigDecimal;
public class TAvgpvNum {
private String datestr;// 日期
private BigDecimal avgpvnum;// 平均PV数量
public String getDatestr() {
return datestr;
}
public void setDatestr(String datestr) {
this.datestr = datestr == null ? null : datestr.trim();
}
public BigDecimal getAvgpvnum() {
return avgpvnum;
}
public void setAvgpvnum(BigDecimal avgpvnum) {
this.avgpvnum = avgpvnum;
}
}AvgToPageBean.java
package cn.itcast.pojo;
public class AvgToPageBean {
private String[] dates;
private double[] data;
public String[] getDates() {
return dates;
}
public void setDates(String[] dates) {
this.dates = dates;
}
public double[] getData() {
return data;
}
public void setData(double[] data) {
this.data = data;
}
}
(2)实现DAO层
TAvgpvNumMapper.java
package cn.itcast.mapper;
import java.util.List;
import cn.itcast.pojo.TAvgpvNum;
public interface TAvgpvNumMapper {
public List selectByDate(String startDate, String endDate);
}TAvgpvNumMapper.xml
select *
from t_avgpv_num
where dateStr between #{0} and #{1} order by dateStr asc;
(3)实现Service层
AvgPvService.java
package cn.itcast.service;
public interface AvgPvService {
//根据日期查询数据
public String getAvgPvNumByDates(String startDate, String endDate);
}AvgPvServiceImpl.java
package cn.itcast.service.impl;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import cn.itcast.mapper.TAvgpvNumMapper;
import cn.itcast.pojo.AvgToPageBean;
import cn.itcast.pojo.TAvgpvNum;
import cn.itcast.service.AvgPvService;
@Service
public class AvgPvServiceImpl implements AvgPvService {
@Autowired
private TAvgpvNumMapper mapper;
@Override
public String getAvgPvNumByDates(String startDate, String endDate) {
//调用查询方法
List lists = mapper.selectByDate(startDate, endDate);
// 数组大小
int size = 7;
//保存日期数据
String[] dates = new String[size];
//保存人均浏览页面数据
double[] datas = new double[size];
int i = 0;
for (TAvgpvNum tAvgpvNum : lists) {
dates[i] = tAvgpvNum.getDatestr();
datas[i] = tAvgpvNum.getAvgpvnum().doubleValue();
i++;
}
//定义AvgToPageBean对象,用于前台页面展示
AvgToPageBean bean = new AvgToPageBean();
bean.setDates(dates);
bean.setData(datas);
//Jackson提供的类,用于把对象转换成Json字符串
ObjectMapper om = new ObjectMapper();
String beanJson = null;
try {
beanJson = om.writeValueAsString(bean);
} catch (JsonProcessingException e) {
e.printStackTrace();
}
//返回Json格式的对象
return beanJson;
}
}
(4)实现Controller层
IndexController.java
package cn.itcast.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import cn.itcast.service.AvgPvService;
@Controller
public class IndexController {
@Autowired
private AvgPvService pvService;
@RequestMapping("/index")
public String showIndex() {
return "index";
}
@RequestMapping(value = "/avgPvNum", produces = "application/json;charset=UTF-8")
@ResponseBody
public String getChart() {
System.out.println("获取平均pv数据..");
String data = pvService.getAvgPvNumByDates("2013-09-18", "2013-09-24");
return data;
}
}
(5)实现页面功能
index.jsp
流量运营分析 - pinyougou®itcast全站数据平台
ITCAST PINYOUGOU
全站流量运营分析
-
 ADMIN BLACK
ADMIN BLACK
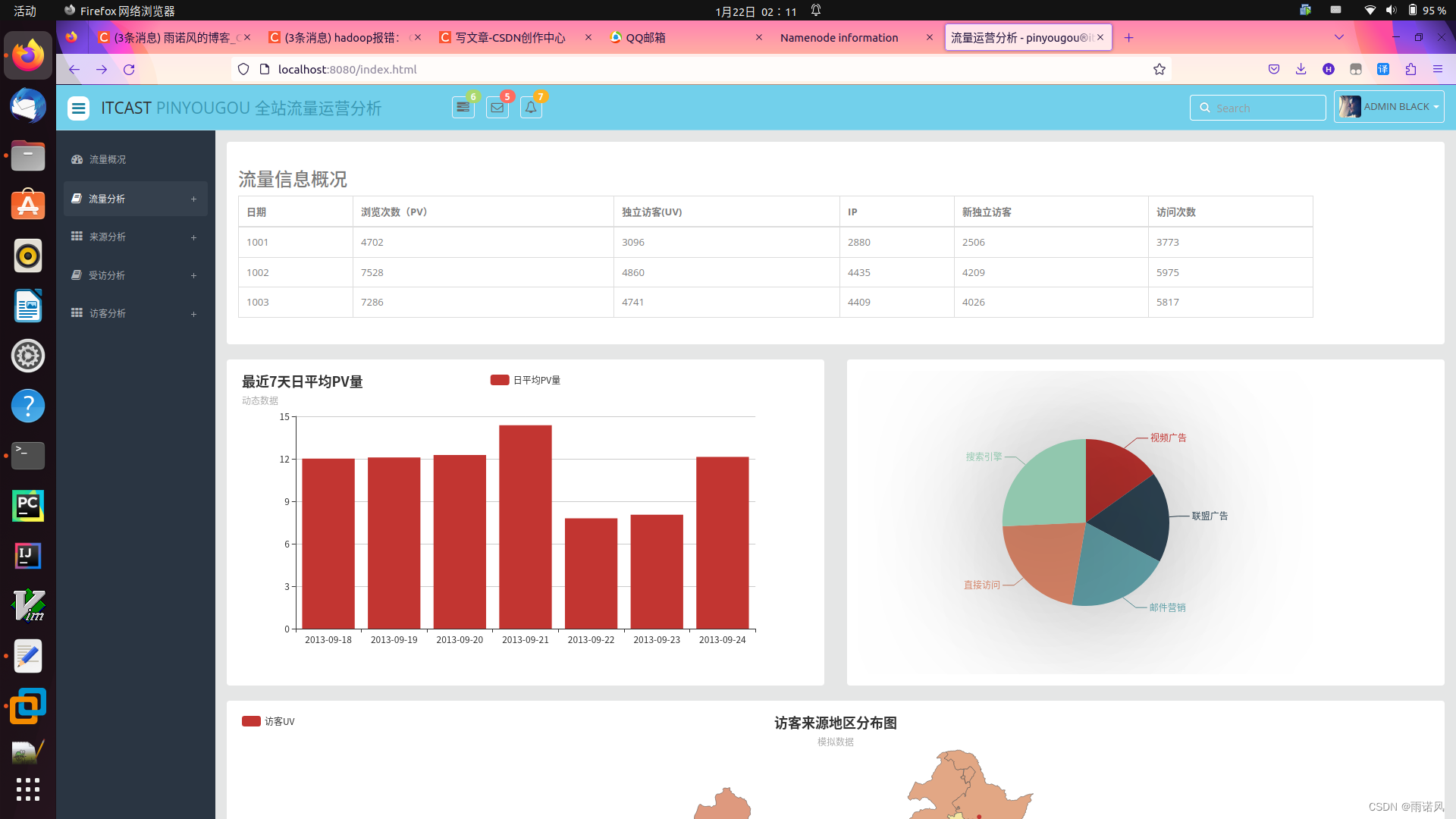
流量信息概况
日期
浏览次数(PV)
独立访客(UV)
IP
新独立访客
访问次数
1001
4702
3096
2880
2506
3773
1002
7528
4860
4435
4209
5975
1003
7286
4741
4409
4026
5817
$(document)
.ready(
function() {
var myChart = echarts
.init(document
.getElementById('main1'));
// 显示标题,图例和空的坐标轴
myChart
.setOption({
title : {
text : '最近7天日平均PV量',
subtext : '动态数据'
},
tooltip : {},
legend : {
data : [ '日平均PV量' ]
},
xAxis : {
data : []
},
yAxis : {},
series : [ {
name : '日平均PV量',
type : 'bar',
data : []
} ]
});
//loading 动画
myChart.showLoading();
// 异步加载数据
$.get('http://localhost:8080/avgPvNum').done(function(data) {
//填入数据
myChart.setOption({
xAxis : {
data : data.dates
},
series : [ {
// 根据名字对应到相应的系列
name : 'PV量',
data : data.data
} ]
});
//数据加载完成后再调用 hideLoading 方法隐藏加载动画
myChart.hideLoading();
});
});
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document
.getElementById('main2'));
myChart
.setOption({
series : [ {
name : '访问来源',
type : 'pie',
radius : '55%',
data : [ {
value : 235,
name : '视频广告'
}, {
value : 274,
name : '联盟广告'
}, {
value : 310,
name : '邮件营销'
}, {
value : 335,
name : '直接访问'
}, {
value : 400,
name : '搜索引擎'
} ]
} ],
itemStyle : {
normal : {
// 阴影的大小
shadowBlur : 200,
// 阴影水平方向上的偏移
shadowOffsetX : 0,
// 阴影垂直方向上的偏移
shadowOffsetY : 0,
// 阴影颜色
shadowColor : 'rgba(0, 0, 0, 0.5)'
}
}
})
// 基于准备好的dom,初始化echarts实例
var myChart3 = echarts.init(document
.getElementById('main3'));
option = {
title : {
text : '访客来源地区分布图',
subtext : '模拟数据',
x : 'center'
},
tooltip : {
trigger : 'item'
},
legend : {
orient : 'vertical',
x : 'left',
data : [ '访客UV' ]
},
dataRange : {
min : 0,
max : 2500,
x : 'left',
y : 'bottom',
text : [ '高', '低' ], // 文本,默认为数值文本
calculable : true
},
toolbox : {
show : true,
orient : 'vertical',
x : 'right',
y : 'center',
feature : {
mark : {
show : true
},
dataView : {
show : true,
readOnly : false
},
restore : {
show : true
},
saveAsImage : {
show : true
}
}
},
roamController : {
show : true,
x : 'right',
mapTypeControl : {
'china' : true
}
},
series : [
{
name : '访客UV',
type : 'map',
mapType : 'china',
roam : false,
itemStyle : {
normal : {
label : {
show : true
}
},
emphasis : {
label : {
show : true
}
}
},
data : [
{
name : '北京',
value : Math
.round(Math
.random() * 1000)
},
{
name : '天津',
value : Math
.round(Math
.random() * 1000)
},
{
name : '上海',
value : Math
.round(Math
.random() * 1000)
},
{
name : '重庆',
value : Math
.round(Math
.random() * 1000)
},
{
name : '河北',
value : Math
.round(Math
.random() * 1000)
},
{
name : '河南',
value : Math
.round(Math
.random() * 1000)
},
{
name : '云南',
value : Math
.round(Math
.random() * 1000)
},
{
name : '辽宁',
value : Math
.round(Math
.random() * 1000)
},
{
name : '黑龙江',
value : Math
.round(Math
.random() * 1000)
},
{
name : '湖南',
value : Math
.round(Math
.random() * 1000)
},
{
name : '安徽',
value : Math
.round(Math
.random() * 1000)
},
{
name : '山东',
value : Math
.round(Math
.random() * 1000)
},
{
name : '新疆',
value : Math
.round(Math
.random() * 1000)
},
{
name : '江苏',
value : Math
.round(Math
.random() * 1000)
},
{
name : '浙江',
value : Math
.round(Math
.random() * 1000)
},
{
name : '江西',
value : Math
.round(Math
.random() * 1000)
},
{
name : '湖北',
value : Math
.round(Math
.random() * 1000)
},
{
name : '广西',
value : Math
.round(Math
.random() * 1000)
},
{
name : '甘肃',
value : Math
.round(Math
.random() * 1000)
},
{
name : '山西',
value : Math
.round(Math
.random() * 1000)
},
{
name : '内蒙古',
value : Math
.round(Math
.random() * 1000)
},
{
name : '陕西',
value : Math
.round(Math
.random() * 1000)
},
{
name : '吉林',
value : Math
.round(Math
.random() * 1000)
},
{
name : '福建',
value : Math
.round(Math
.random() * 1000)
},
{
name : '贵州',
value : Math
.round(Math
.random() * 1000)
},
{
name : '广东',
value : Math
.round(Math
.random() * 1000)
},
{
name : '青海',
value : Math
.round(Math
.random() * 1000)
},
{
name : '西藏',
value : Math
.round(Math
.random() * 1000)
},
{
name : '四川',
value : Math
.round(Math
.random() * 1000)
},
{
name : '宁夏',
value : Math
.round(Math
.random() * 1000)
},
{
name : '海南',
value : Math
.round(Math
.random() * 1000)
},
{
name : '台湾',
value : Math
.round(Math
.random() * 1000)
},
{
name : '香港',
value : Math
.round(Math
.random() * 1000)
},
{
name : '澳门',
value : Math
.round(Math
.random() * 1000)
} ]
},
]
};
myChart3.setOption(option);
// 基于准备好的dom,初始化echarts实例
var myChart4 = echarts.init(document
.getElementById('main4'));
// 指定图表的配置项和数据
option = {
title : {
text : '近一周访客数量变化趋势',
subtext : '动态数据'
},
tooltip : {
trigger : 'axis'
},
legend : {
data : [ '独立访客', '新独立访客' ]
},
toolbox : {
show : true,
feature : {
mark : {
show : true
},
dataView : {
show : true,
readOnly : false
},
magicType : {
show : true,
type : [ 'line', 'bar' ]
},
restore : {
show : true
},
saveAsImage : {
show : true
}
}
},
calculable : true,
xAxis : [ {
type : 'category',
boundaryGap : false,
data : []
} ],
yAxis : [ {
type : 'value',
axisLabel : {
formatter : '{value} 人'
}
} ],
series : [ {
name : '独立访客',
type : 'line',
data : [],
markPoint : {
data : [ {
type : 'max',
name : '最大值'
}, {
type : 'min',
name : '最小值'
} ]
},
markLine : {
data : [ {
type : 'average',
name : '平均值'
} ]
}
}, {
name : '新独立访客',
type : 'line',
data : [],
markPoint : {
data : [ {
type : 'max',
name : '最大值'
}, {
type : 'min',
name : '最小值'
} ]
},
markLine : {
data : [ {
type : 'average',
name : '平均值'
} ]
}
} ]
};
// 使用刚指定的配置项和数据显示图表。
myChart4.setOption(option);
myChart4.showLoading();
// 异步加载数据
$.get('http://localhost:8080/flowNum')
.done(function(data) {
// 填入数据
myChart4.setOption({
xAxis : {
data : data.dates
},
series : [ {
name : '独立访客',
data : data.uvs
}, {
name : '新独立访客',
data : data.new_uvs
} ]
});
myChart4.hideLoading();
});
Profit
Expansion
//knob
$(".knob").knob();
3、系统功能模块展示
参考书籍:
《Hadoop大数据技术原理与应用》
