

♥️作者:小刘在C站
♥️个人主页: 小刘主页
♥️努力不一定有回报,但一定会有收获加油!一起努力,共赴美好人生!
♥️学习两年总结出的运维经验,以及思科模拟器全套网络实验教程。专栏:云计算技术
♥️小刘私信可以随便问,只要会绝不吝啬,感谢CSDN让你我相遇!
目录
1 逻辑存储结构
1). 表空间
2). 段
3). 区
4). 页
5). 行
2 架构
2.1 概述
6.2.2 内存结构
1). Buffer Pool
2). Change Buffer
3). Adaptive Hash Index
4). Log Buffer
2.3 磁盘结构
1). System Tablespace
2). File-Per-Table Tablespaces
3). General Tablespaces
A. 创建表空间
B. 创建表时指定表空间
4). Undo Tablespaces
5). Temporary Tablespaces
6). Doublewrite Buffer Files
7). Redo Log
2.4 后台线程
1). Master Thread
2). IO Thread
3). Purge Thread
4). Page Cleaner Thread
1 逻辑存储结构
的逻辑存储结构如下图所示
:
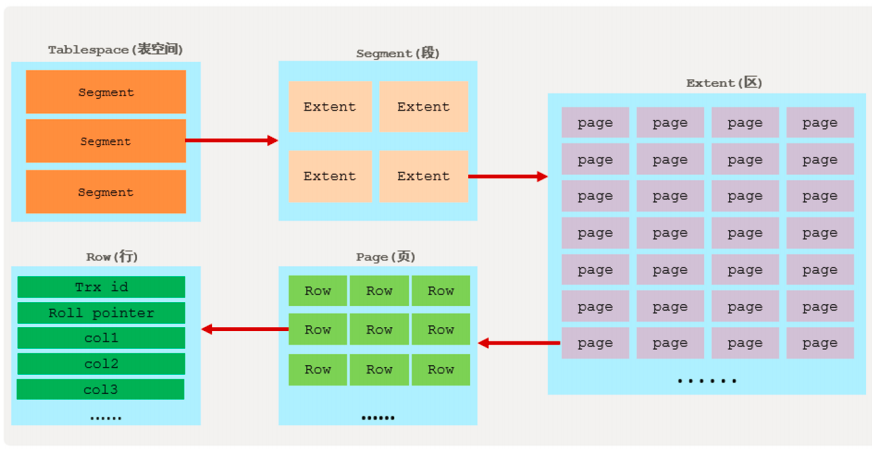
1). 表空间
InnoDB
存储引擎逻辑结构的最高层, 如果用户启用了参数
innodb_file_per_table(
在8.0
版本中默认开启
)
,则每张表都会有一个表空间(
xxx.ibd
),一个
mysql
实例可以对应多个表空
2). 段
Leaf node segment
)、索引段(
Non-leaf node segment
)、回滚段(
Rollback segment
),
InnoDB
是索引组织表,数据段就是
B+
树的叶子节点, 索引段即为
B+
树的
Extent
(区)。
3). 区
1M
。 默认情况下,
InnoDB
存储引擎页大小为
16K
, 即一
64
个连续的页。
4). 页
InnoDB
存储引擎磁盘管理的最小单元,每个页的大小默认为
16KB
。为了保证页的连续性,InnoDB
存储引擎每次从磁盘申请
4-5
个区。
5). 行
行,InnoDB 存储引擎数据是按行进行存放的。
:每次对某条记录进行改动时,都会把对应的事务
id
赋值给
trx_id
隐藏列。
:每次对某条引记录进行改动时,都会把旧的版本写入到
undo
日志中,然后这个
2 架构
2.1 概述
版本开始,默认使用
InnoDB
存储引擎,它擅长事务处理,具有崩溃恢复特性,在日常开发中使用非常广泛。下面是
InnoDB
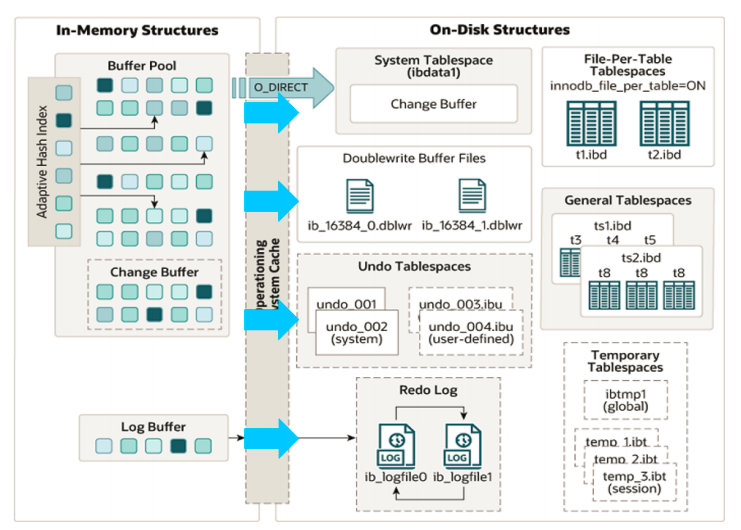
架构图,左侧为内存结构,右侧为磁盘结构。
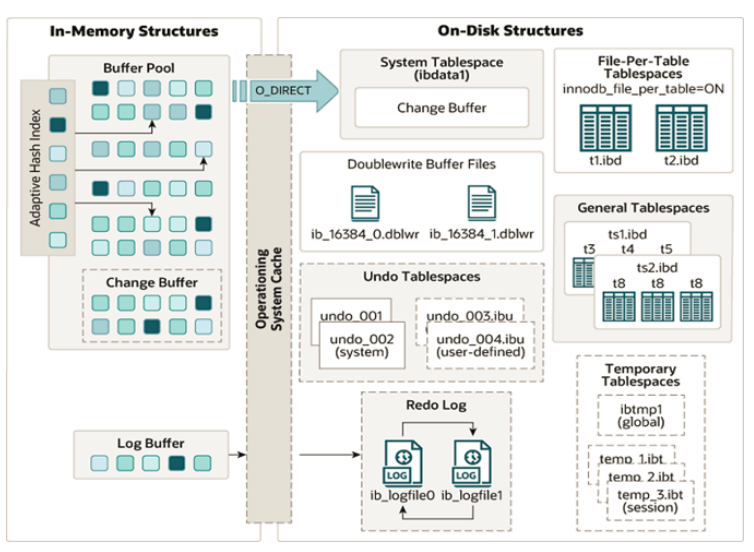
6.2.2 内存结构
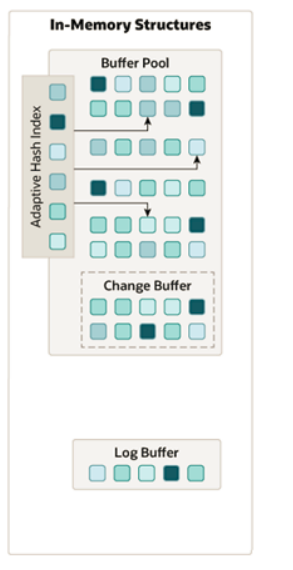
Buffer Pool
、
Change Buffer
、
Adaptive
、
Log Buffer
。 接下来介绍一下这四个部分。
1). Buffer Pool
存储引擎基于磁盘文件存储,访问物理硬盘和在内存中进行访问,速度相差很大,为了尽可能弥补这两者之间的
I/O
效率的差值,就需要把经常使用的数据加载到缓冲池中,避免每次访问都进行磁
盘
I/O
。
InnoDB
的缓冲池中不仅缓存了索引页和数据页,还包含了
undo
页、插入缓存、自适应哈希索引以及InnoDB
的锁信息等等。
Buffer Pool
,是主内存中的一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增
删改查操作时,先操作缓冲池中的数据(若缓冲池没有数据,则从磁盘加载并缓存),然后再以一定频
率刷新到磁盘,从而减少磁盘
IO
,加快处理速度。
Page
页为单位,底层采用链表数据结构管理
Page
。根据状态,将
Page
分为三种类型:
:空闲
page
,未被使用。
:被使用
page
,数据没有被修改过。
:脏页,被使用
page
,数据被修改过,也中数据与磁盘的数据产生了不一致。
80
%的物理内存分配给缓冲池 。参数设置:
show variables

2). Change Buffer
,更改缓冲区(针对于非唯一二级索引页),在执行
DML
语句时,如果这些数据
Page没有在
Buffer Pool
中,不会直接操作磁盘,而会将数据变更存在更改缓冲区
Change Buffer
Buffer Pool
中,再将合并后的数据刷新到磁盘中。
的意义是什么呢
?
先来看一幅图,这个是二级索引的结构图:

IO
。有了
ChangeBuffer
之后,我们可以在缓冲池中进行合并处理,减少磁盘
IO
。
3). Adaptive Hash Index
hash
索引,用于优化对
Buffer Pool
数据的查询。
MySQL
的
innoDB
引擎中虽然没有直接支持
索引,但是给我们提供了一个功能就是这个自适应
hash
索引。因为前面我们讲到过,
hash
索引在进行等值匹配时,一般性能是要高于
B+
树的,因为
hash
索引一般只需要一次
IO
即可,而
B+
树,可能需要几次匹配,所以
hash
索引的效率要高,但是
hash
索引又不适合做范围查询、模糊匹配等。
存储引擎会监控对表上各索引页的查询,如果观察到在特定的条件下
hash
索引可以提升速度,则建立
hash
索引,称之为自适应
hash
索引。
adaptive_hash_index
4). Log Buffer
:日志缓冲区,用来保存要写入到磁盘中的
log
日志数据(
redo log
、
undo log
),默认大小为
16MB
,日志缓冲区的日志会定期刷新到磁盘中。如果需要更新、插入或删除许多行的事务,增加日志缓冲区的大小可以节省磁盘
I/O
。
:
:缓冲区大小
:日志刷新到磁盘时机,取值主要包含以下三个:
1: 日志在每次事务提交时写入并刷新到磁盘,默认值。
0: 每秒将日志写入并刷新到磁盘一次。
2: 日志在每次事务提交后写入,并每秒刷新到磁盘一次。

2.3 磁盘结构
InnoDB
体系结构的右边部分,也就是磁盘结构:
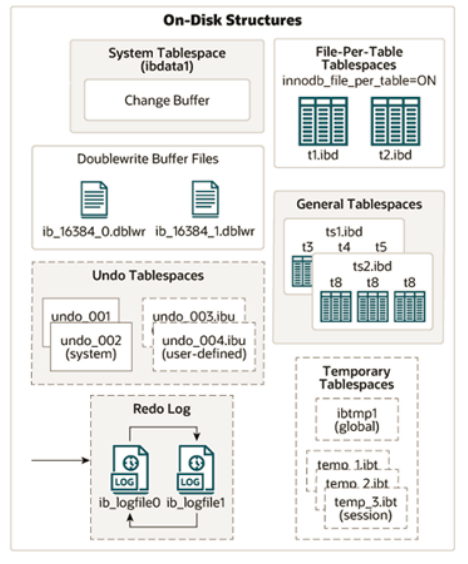
1). System Tablespace
(
在
MySQL5.x
版本中还包含
InnoDB
数据字典、
undolog
等
)
innodb_data_file_path

系统表空间,默认的文件名叫 ibdata1。
2). File-Per-Table Tablespaces
innodb_file_per_table
开关 ,则每个表的文件表空间包含单个
InnoDB
表的数据和索
innodb_file_per_table
,该参数默认开启。


3). General Tablespaces
CREATE TABLESPACE
语法创建通用表空间,在创建表时,可以指定该表空间。
A. 创建表空间
CREATE TABLESPACE ts_name ADD DATAFILE 'file_name' ENGINE = engine_name; 
B. 创建表时指定表空间
CREATE TABLE xxx ... TABLESPACE ts_name;
4). Undo Tablespaces
MySQL
实例在初始化时会自动创建两个默认的
undo
表空间(初始大小
16M
),用于存储undo log
日志。
5). Temporary Tablespaces
使用会话临时表空间和全局临时表空间。存储用户创建的临时表等数据。
6). Doublewrite Buffer Files
innoDB
引擎将数据页从
Buffer Pool
刷新到磁盘前,先将数据页写入双写缓冲区文件

7). Redo Log
redo log
)以及重做日志文件(
redo log
)
,
前者是在内存中,后者在磁盘中。当事务提交之后会把所
,
用于在刷新脏页到磁盘时
,
发生错误时
,
进行数据恢复使用。
以循环方式写入重做日志文件,涉及两个文件:

InnoDB
的内存结构,以及磁盘结构,那么内存中我们所更新的数据,又是如何到磁盘中的呢? 此时,就涉及到一组后台线程,接下来,就来介绍一些
InnoDB
中涉及到的后台线程。
2.4 后台线程
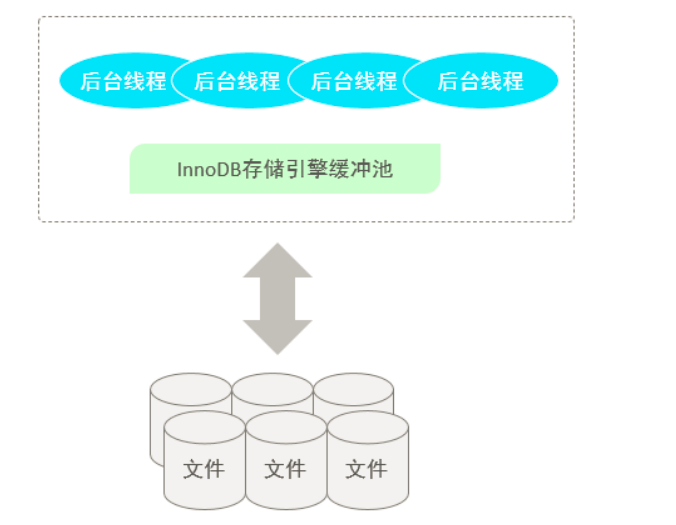
InnoDB
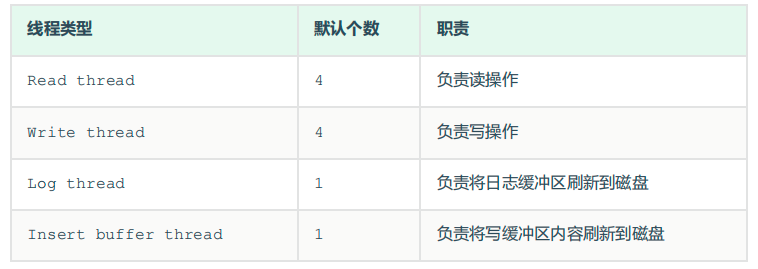
的后台线程中,分为
4
类,分别是:
Master Thread
、
IO Thread
、
Purge Thread
、
。
1). Master Thread
,
保持数据的一致性,还包括脏页的刷新、合并插入缓存、
undo
页的回收 。
2). IO Thread
InnoDB
存储引擎中大量使用了
AIO
来处理
IO
请求
,
这样可以极大地提高数据库的性能,而
IO
主要负责这些
IO
请求的回调。
我们可以通过以下的这条指令,查看到InnoDB的状态信息,其中就包含IO Thread信息。
show engine innodb status G;
3). Purge Thread
undo log
,在事务提交之后,
undo log
可能不用了,就用它来回
4). Page Cleaner Thread
Master Thread
刷新脏页到磁盘的线程,它可以减轻
Master Thread
的工作压力,减少阻
♥️关注,就是我创作的动力
♥️点赞,就是对我最大的认可
♥️这里是小刘,励志用心做好每一篇文章,谢谢大家
