

文章目录
- 一、MongoDB简介
-
- 1、MongoDB介绍
- 2、MongoDB中三个概念
- 3、MongoDB优势
- 二、环境搭建
-
- 1、下载
- 2、安装
- 3、安装失败问题解决
- 4、启动
- 5、图形化工具
-
- 1)下载
- 2)连接客户端
- 3)基本操作
- 三、基础入门
-
- 1、基础命令
- 2、集合命令
- 3、数据类型
- 4、注意点
- 5、插入数据
- 6、简单查询
- 7、保存数据
- 8、修改数据
- 9、删除数据
- 四、高级查询
-
- 1、数据查询
- 2、比较运算符
- 3、范围运算符
- 4、逻辑运算符
- 5、正则表达式
- 6、limit和skip
- 7、自定义查询
- 8、投影
- 9、排序
- 10、统计个数
- 11、去除重复
- 五、聚合和管道
-
- 1、聚合简介
- 2、常用管道
- 3、表达式
- 4、$group
- 5、$project
- 6、$match
- 7、$sort
- 8、$limit
- 9、$skip
- 10、$unwind
- 六、索引
-
- 1、创建索引
- 2、索引操作
- 七、备份和恢复
-
- 1、备份
- 2、恢复
一、MongoDB简介
1、MongoDB介绍
MongoDB是为快速开发互联网Web应用而设计的数据库系统。
MongoDB的设许目标是极简、灵活、作为Web应用栈的一部分。
MongoDB的数据模型是面向文档的, 所谓文档是一种类似于JSON的结构,简单理解MongoDB这个数据库中存的是各种各样的JSON。( BSON )
2、MongoDB中三个概念
数据库( database ):数据库是一个仓库,在仓库中可以存放集合。
集合( collection ):集合类似于数组,在集合中可以存放文档。
文档( document ):文档数据库中的最小单位,我们存储和操作的内容都是文档。
3、MongoDB优势
易扩展: NoSQL数据库种类繁多, 但是⼀个共同的特点都是去掉关系数据库的关系型特性。 数据之间⽆关系, 这样就⾮常容易扩展
⼤数据量, ⾼性能: NoSQL数据库都具有⾮常⾼的读写性能, 尤其在⼤数据量下, 同样表现优秀。 这得益于它的⽆关系性, 数据库的结构简单
灵活的数据模型: NoSQL⽆需事先为要存储的数据建⽴字段, 随时可以存储⾃定义的数据格式。 ⽽在关系数据库⾥, 增删字段是⼀件⾮常麻烦的事情。 如果是⾮常⼤数据量的表, 增加字段简直就是⼀个噩梦
二、环境搭建
1、下载
官网下载地址:https://www.mongodb.com/try/download
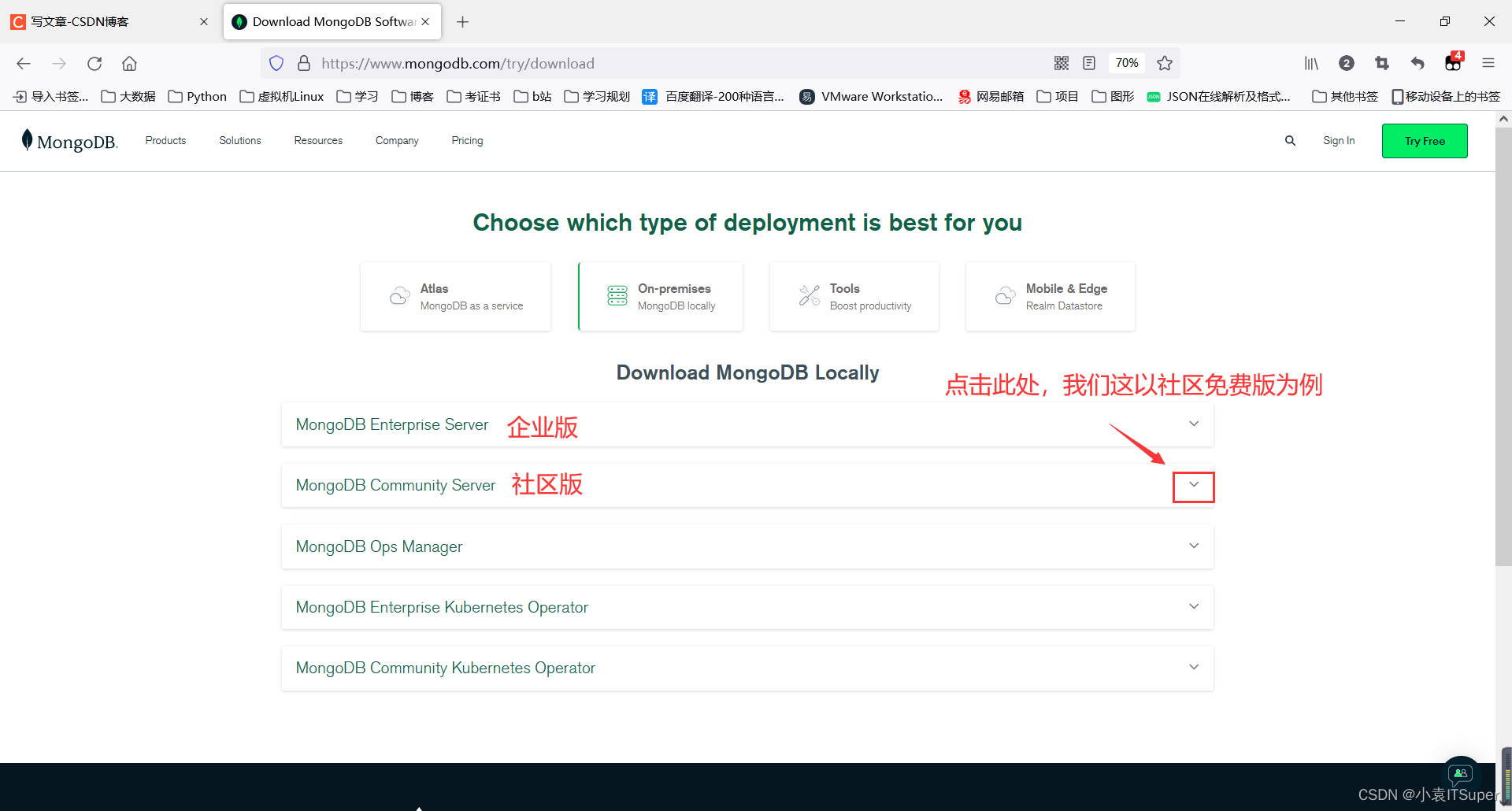
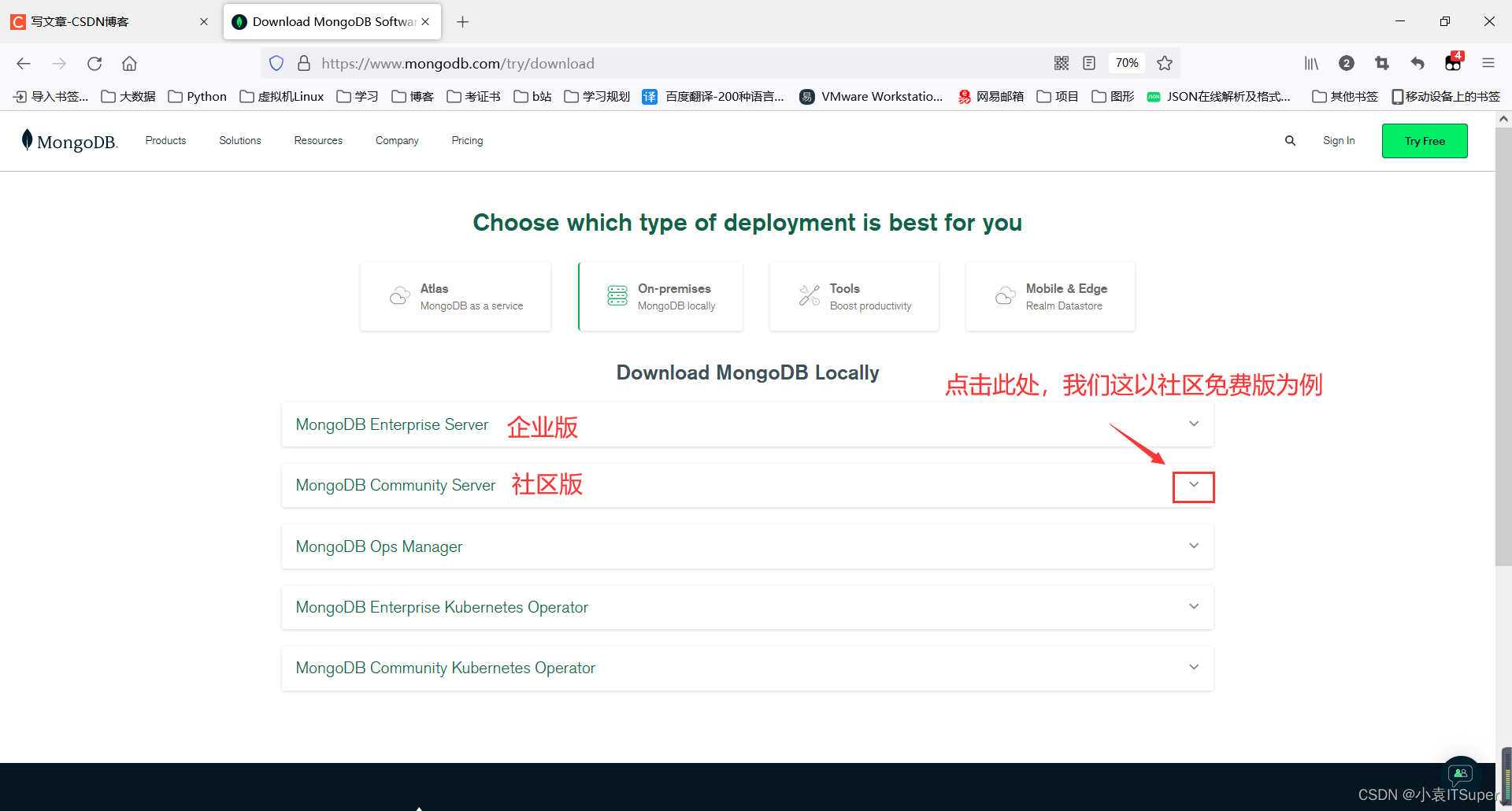
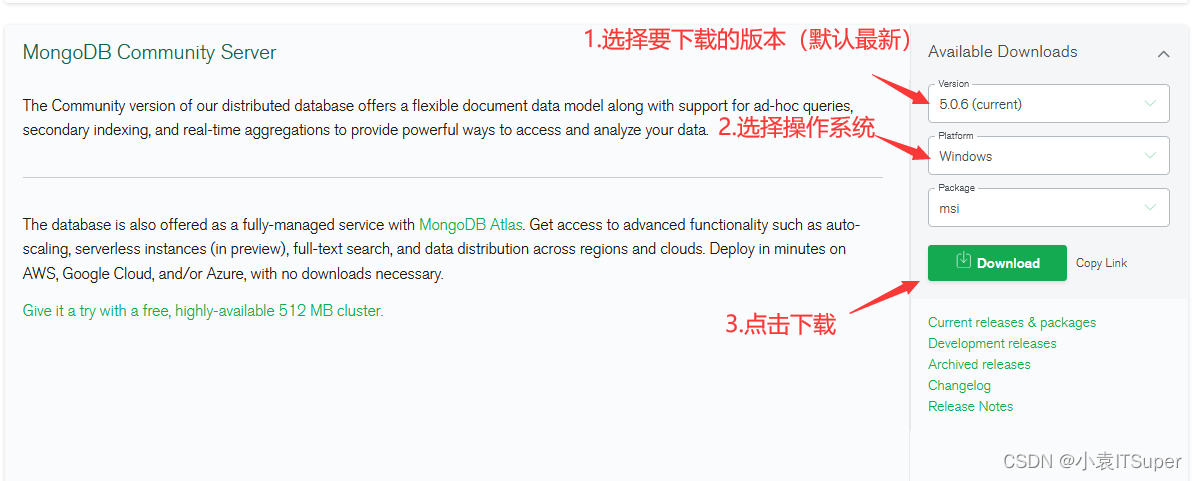
注意:在MongoDB版本的版本偶数版为稳定版通常用于生产环境,如3.2.x、3.4.x、3.6.x,奇数版本为开发版本:3.1.x、3.3.x、3.5.x表示开发版
2、安装
点击开始安装
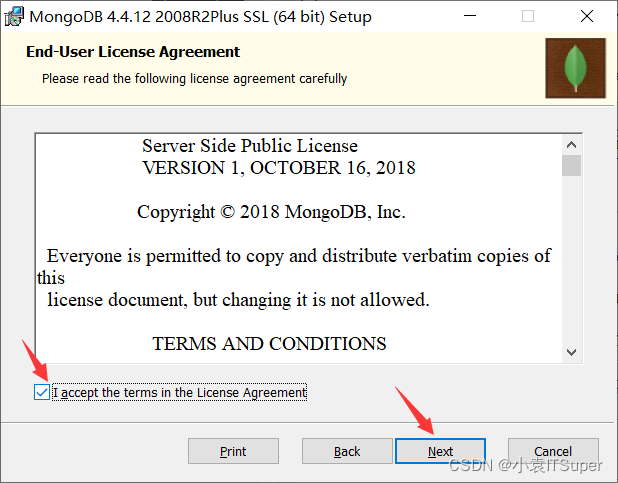
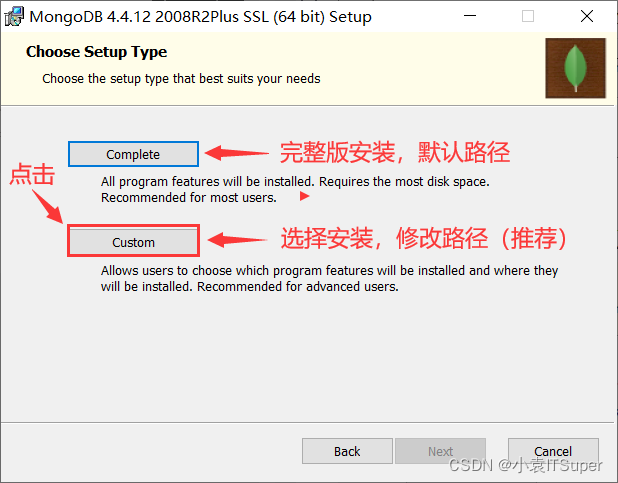
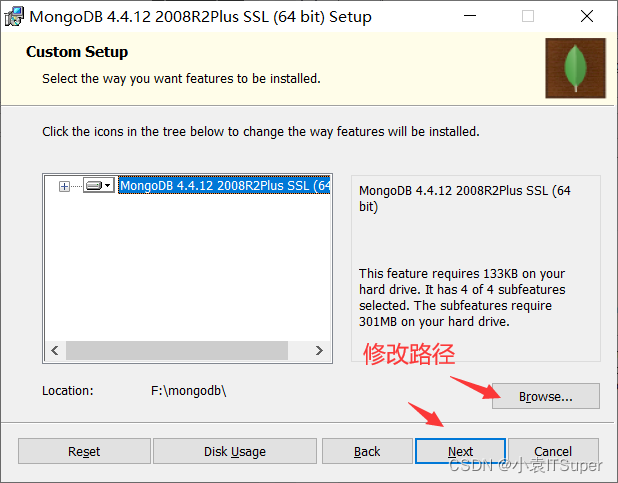
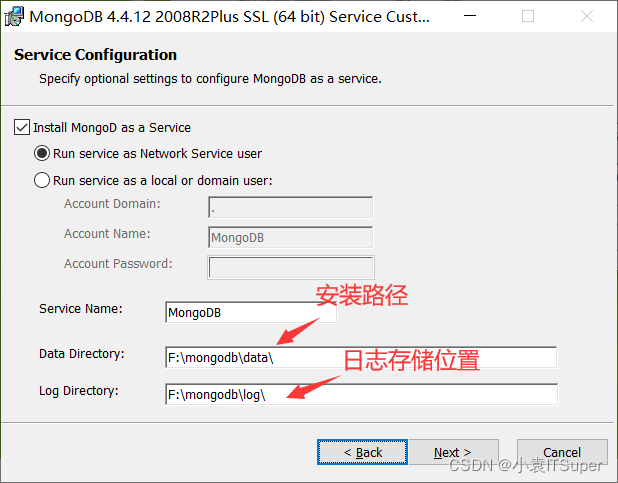
3、安装失败问题解决
在安装MongoDB数据库的时候,有可能出现安装速度较慢,然后取消安装以后,再一次重新去安装的时候,在安装的最后一步可能会出现无法启动服务的现象
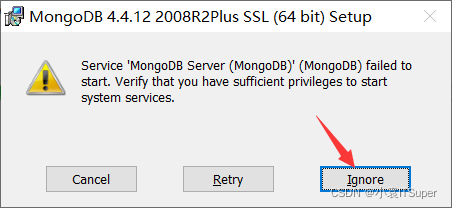
这种情况直接点击Ignore,完成安装以后
以管理员身份运行命令行窗口,使用该命令将MongDB服务删除掉
sc delete MongoDB
删除以后我们自己在data目录下创建一个db文件夹;log目录下创建一个MongoDB.log文件,如下:
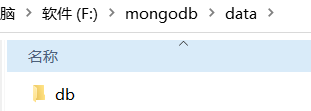
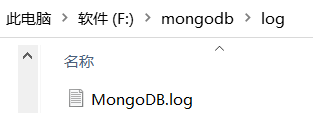
重新装一个MongoDB服务就可以了,在安装目录的bin中打开控制台窗口输入命令:
mongod --dbpath=F:mongodbdatadb --logpath=F:mongodblogMongoDB.log --install --serviceName "MongoDB"
注意:第一个路径表示的是数据存放地址;第二个路径表示日志存放文件
如图所示:

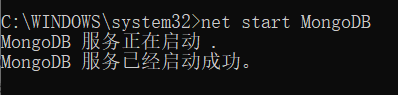
再输入 net start MongoDB启动服务
执行结果如下图:
设置环境变量
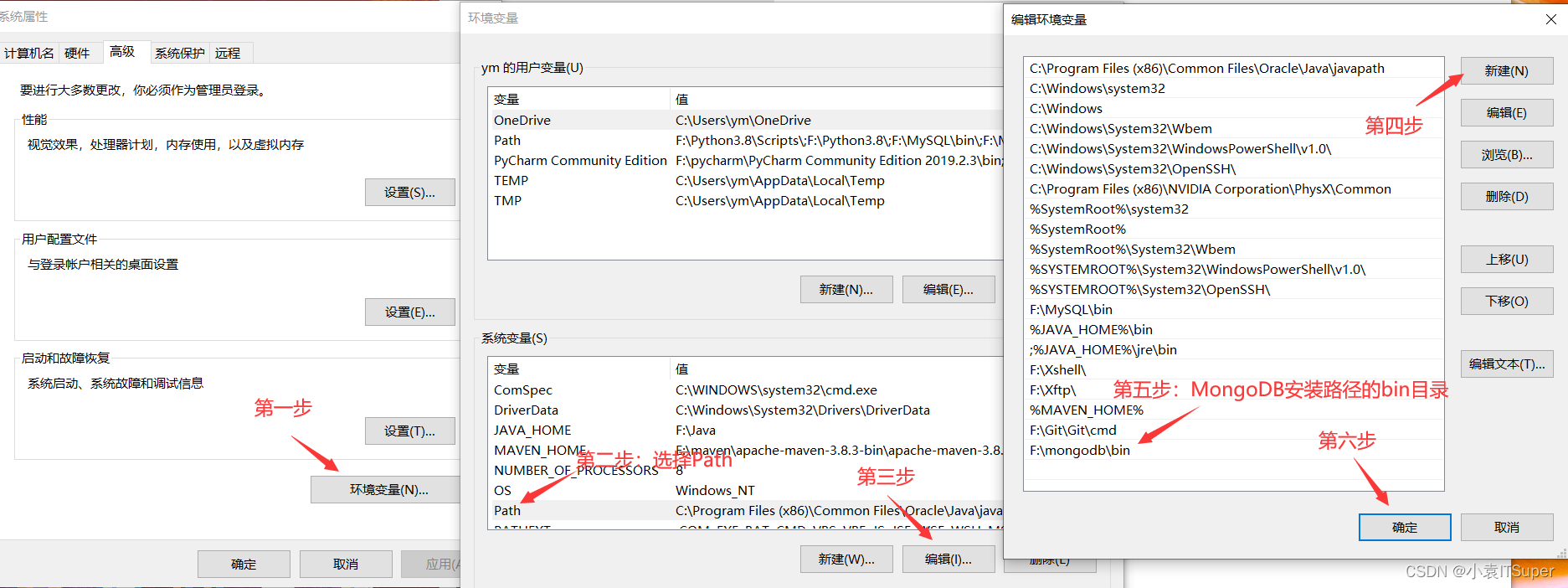
设置完毕后,需要重启一下电脑
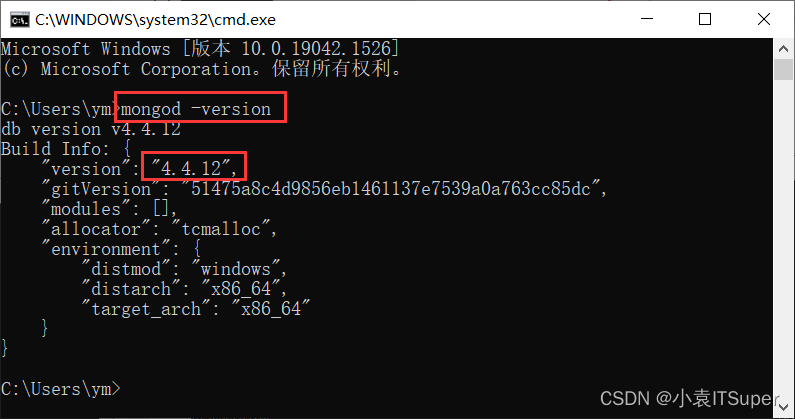
在cmd控制输入,mongod -version,出现版本号表示安装成功
4、启动
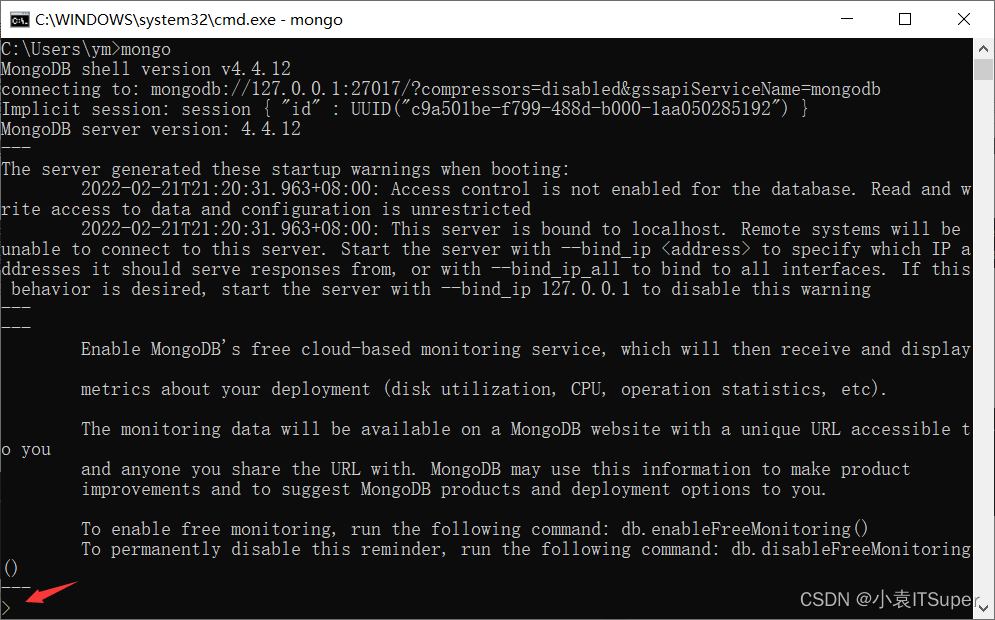
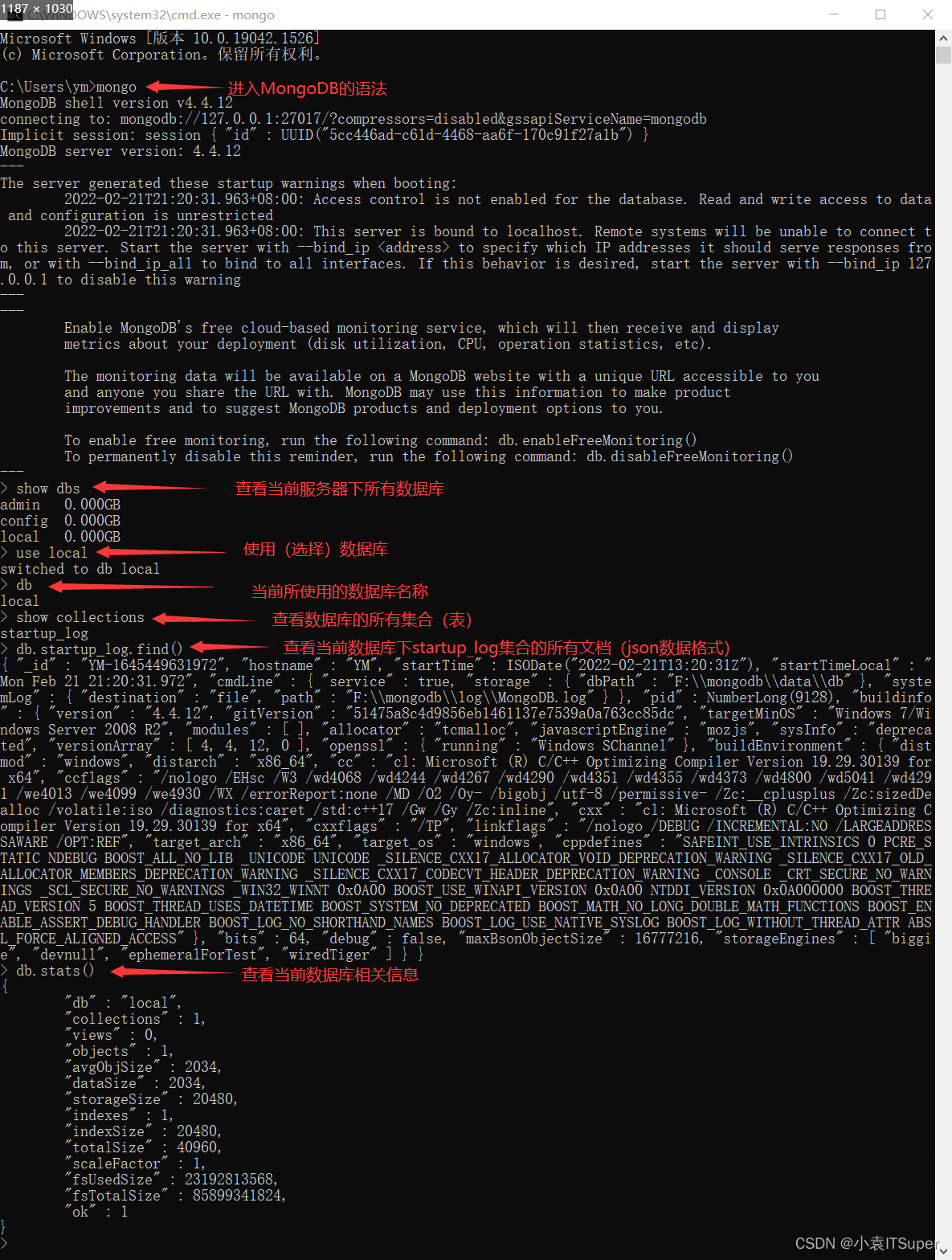
cmd控制输出: mongo回车,出现大于符号表示进入MongoDB数据库了
5、图形化工具
1)下载
官网下载地址(英文版,试用14天):https://www.mongodbmanager.com/download ( 傻瓜式安装,一路next到完成即可)
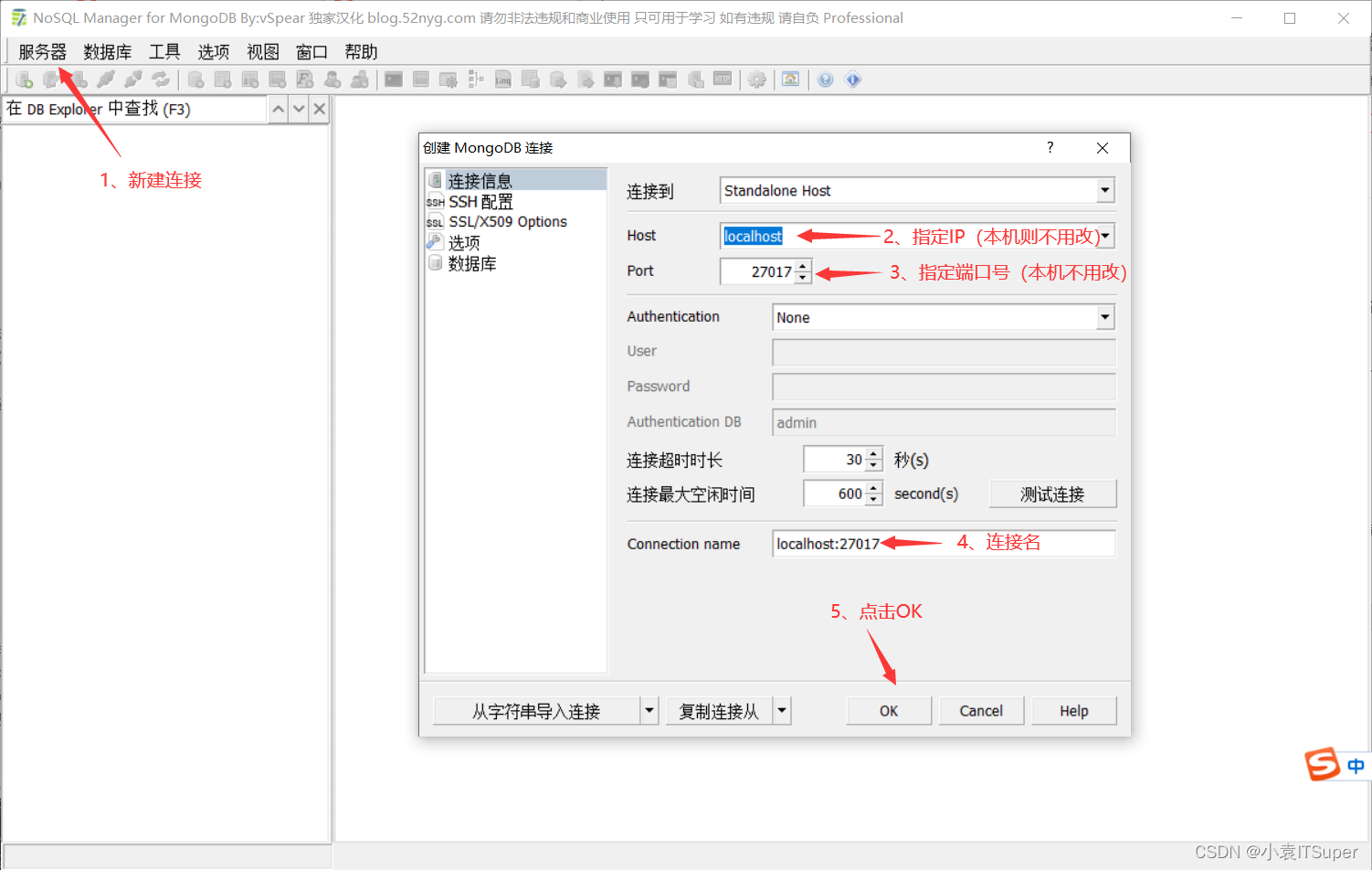
2)连接客户端
1、确保mongodb已经启动
2、如果没有特别设置账户权限,默认情况下无需修改新建连接信息
3)基本操作
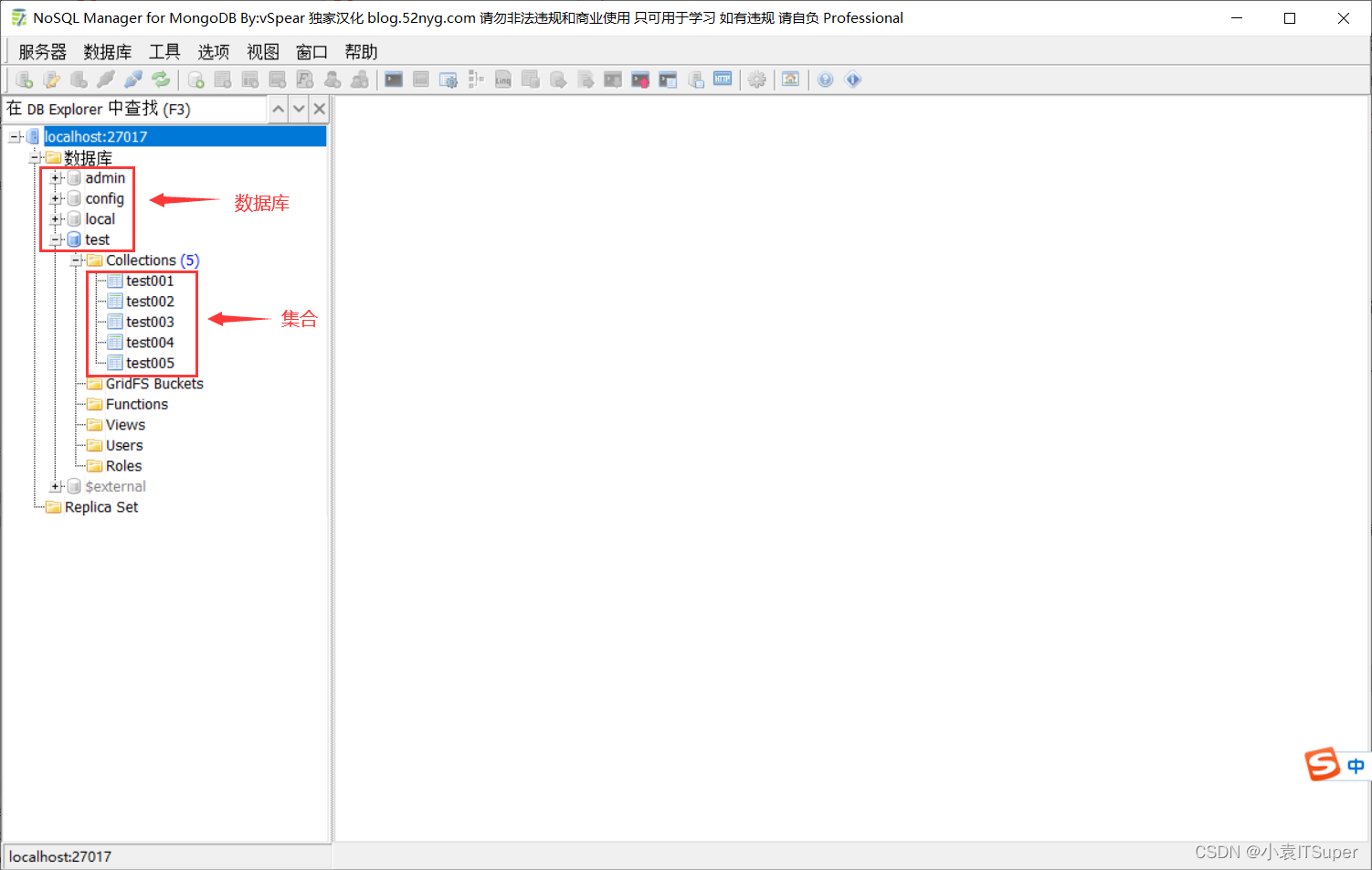
1、点击+展开数据库集合
2、输入sql语句
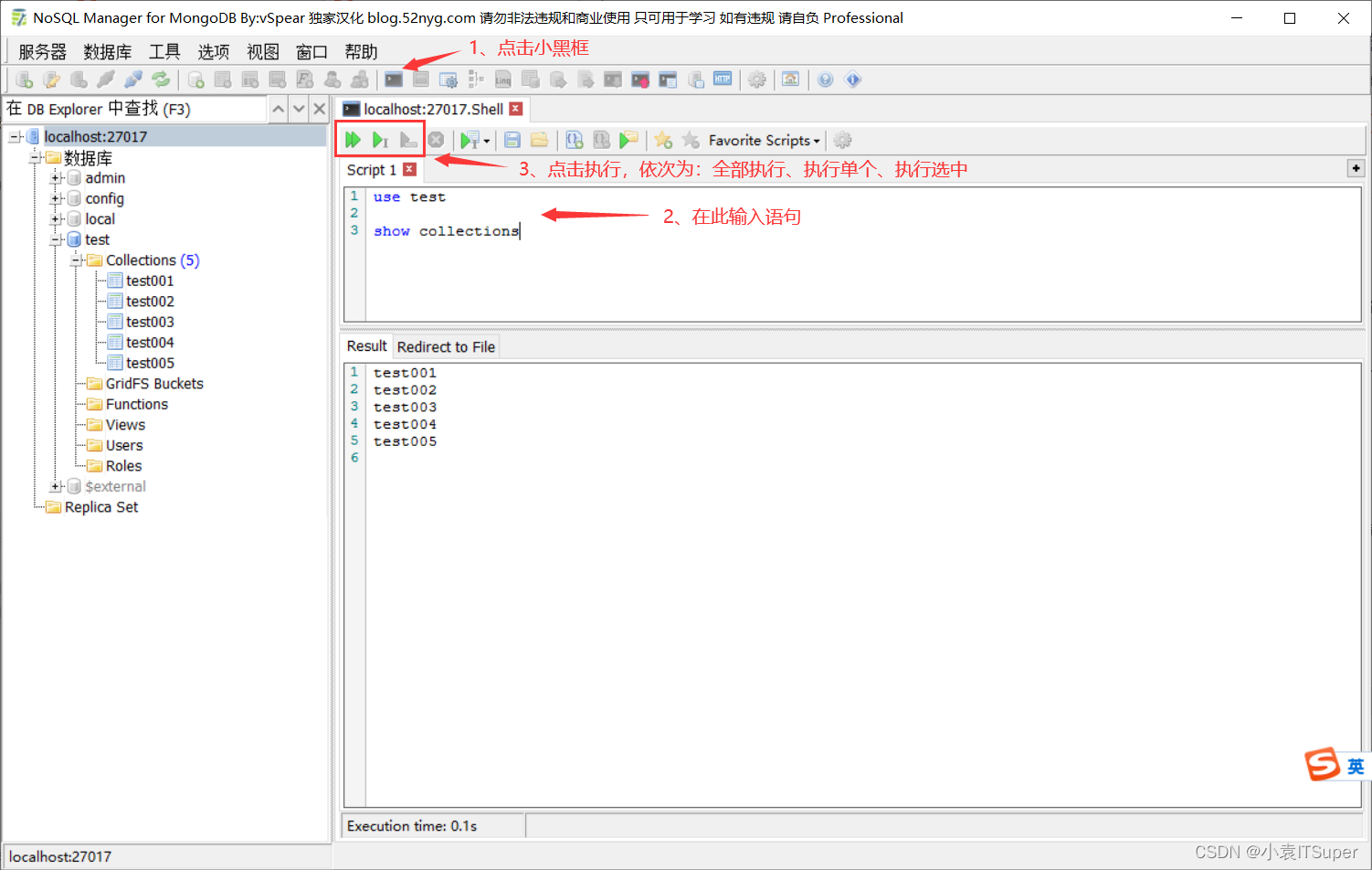
3、操作集合
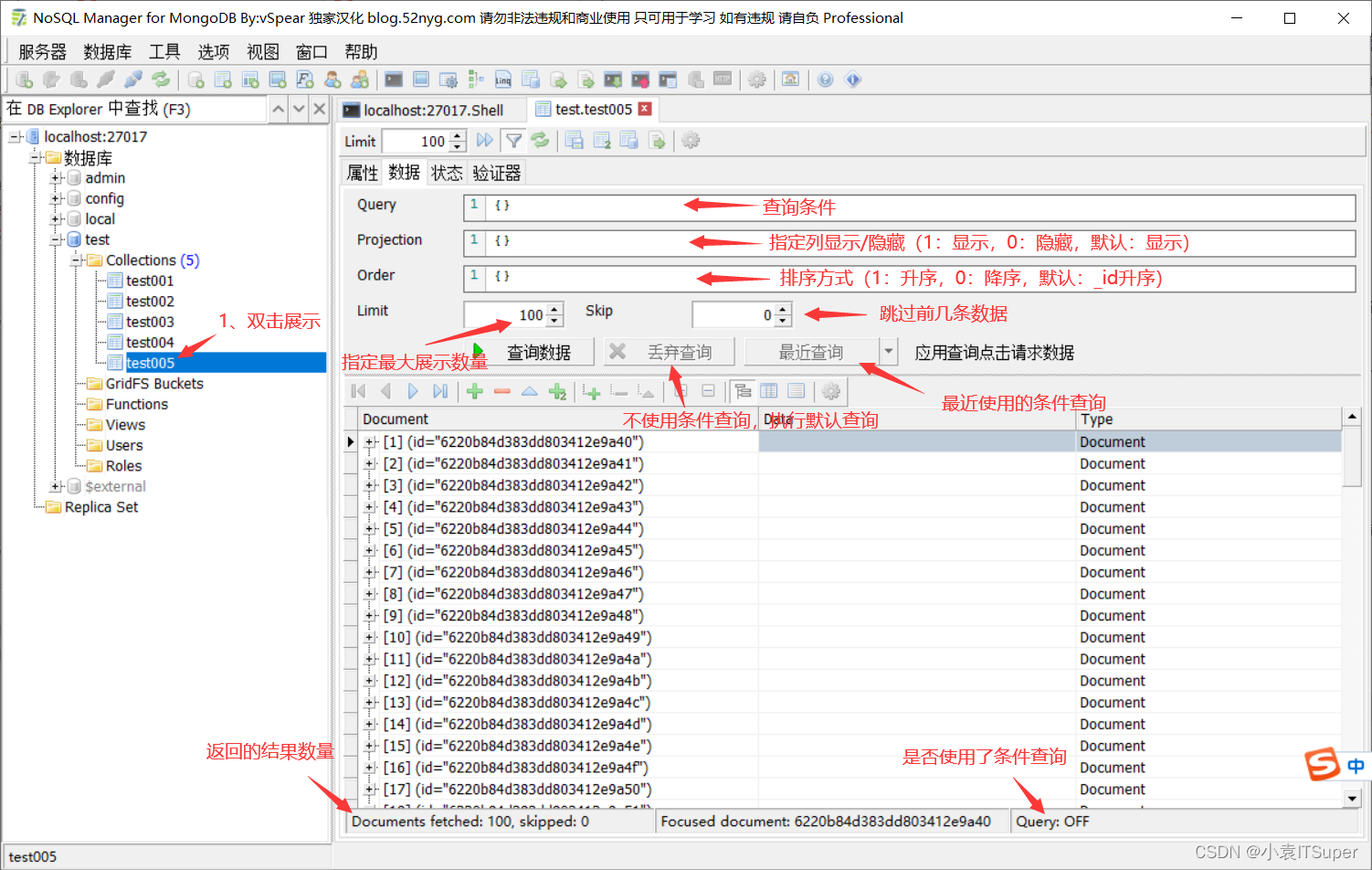
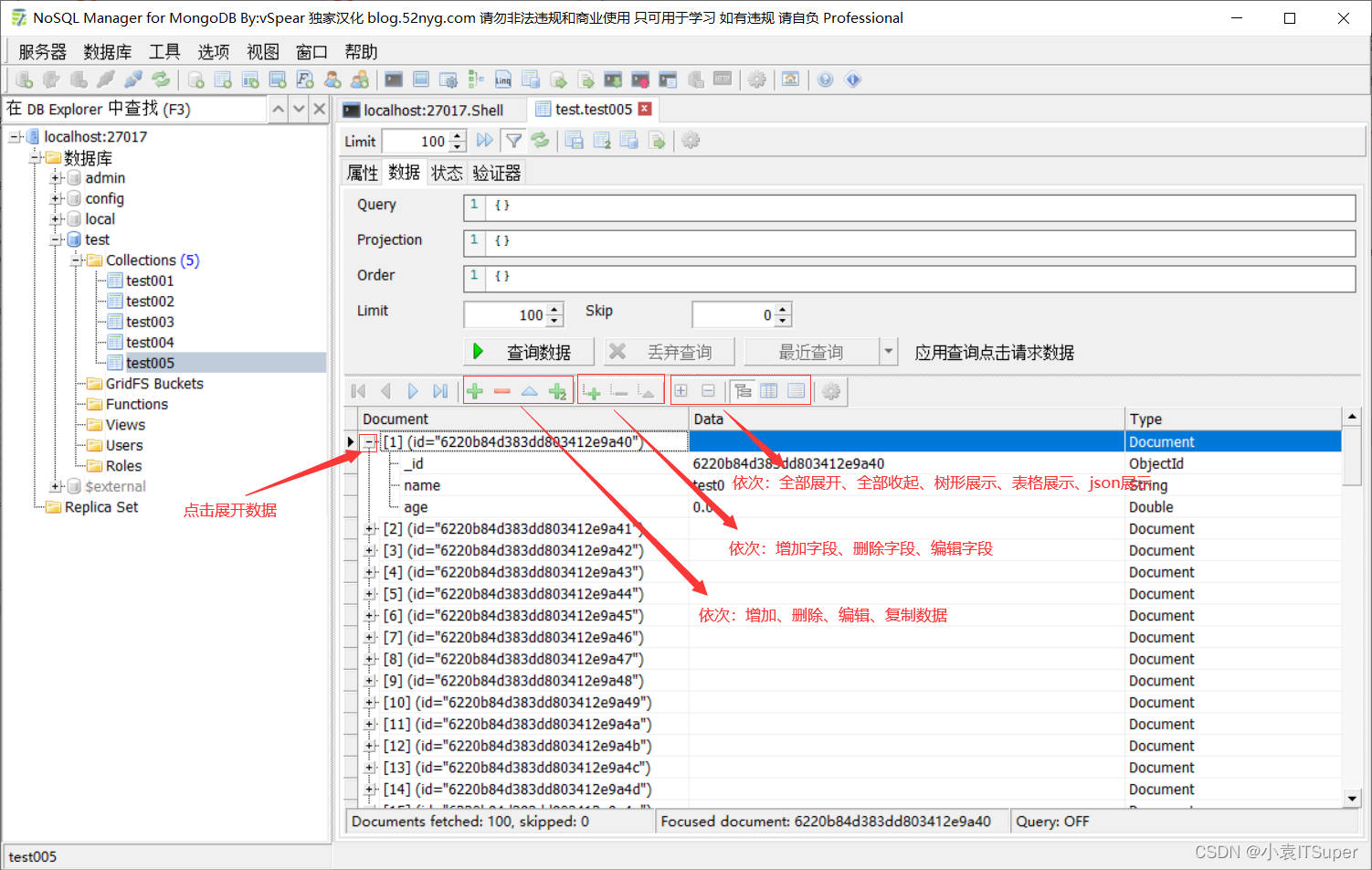
4、集合其他操作
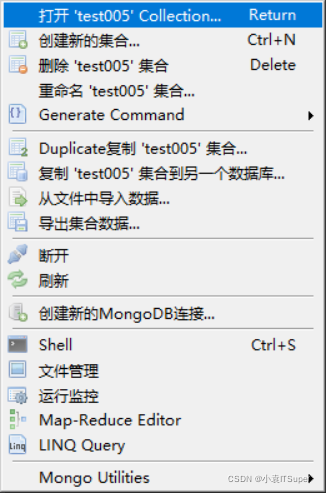
选择集合并右击
三、基础入门
1、基础命令
- 查看所有的数据库:
show dbs /show databases - 切换数据库:
use db_name - 查看使用当前的数据库:
db - 删除当前的数据库:
db.dropDatabase() - 查看数据库中所有集合(表):
show collections - 查看指定集合下所有文档(JSON数据):
db.集合名称.find()
2、集合命令
不手动创建集合:向不存在的集合中第⼀次加⼊数据时, 集合会被创建出来
手动创建结合:
-
db.createCollection(name,options) -
db.createCollection("stu") -
db.createCollection("sub", { capped : true, size : 10 } ) -
参数capped: 默认值为false表示不设置上限,值为true表示设置上限
-
参数size: 当capped值为true时, 需要指定此参数, 表示上限⼤⼩,当⽂档达到上限时, 会将之前的数据覆盖, 单位为字节
查看集合:show collections
删除集合:db.集合名称.drop()
3、数据类型
| 数据类型 | 介绍 |
|---|---|
| Object ID | ⽂档ID |
| String | 字符串, 最常⽤, 必须是有效的UTF-8 |
| Boolean | 存储⼀个布尔值, true或false |
| Integer | 整数可以是32位或64位, 这取决于服务器 |
| Double | 存储浮点值 |
| Arrays | 数组或列表, 多个值存储到⼀个键 |
| Object | ⽤于嵌⼊式的⽂档, 即⼀个值为⼀个⽂档 |
| Null | 存储Null值 |
| Timestamp | 时间戳, 表示从1970-1-1到现在的总秒数 |
| Date | 存储当前⽇期或时间的UNIX时间格式 |
4、注意点
创建⽇期语句如下 :参数的格式为YYYY-MM-DD
new Date('2017-12-20')
每个⽂档都有⼀个属性, 为_id, 保证每个⽂档的唯⼀性
可以⾃⼰去设置_id插⼊⽂档,如果没有提供, 那么MongoDB为每个⽂档提供了⼀个独特的_id, 类型为objectID
objectID是⼀个12字节的⼗六进制数:
- 前4个字节为当前时间戳
- 接下来3个字节的机器ID
- 接下来的2个字节中MongoDB的服务进程id
- 最后3个字节是简单的增量值
5、插入数据
语法如下:
-
db.集合名称.insert(JSON对象) -
插入1条数据:
db.集合名称.insertOne(JSON对象) -
插入多条数据:
db.集合名称.insertMany([JSON 1,JSON 2,JSON 3,...JSON n]) -
指定
_id参数:db.集合名称.insert({_id:"001", name:"gj", gender:1})
注意:
- 插入数据时不需要专门去创建集合(表),因为插入数据时会自动创建集合
- 插⼊⽂档时, 如果不指定_id参数, MongoDB会为⽂档分配⼀个唯⼀的ObjectId
- 如果⽂档的_id已经存在则报错
案例:
// 插入1条数据
db.test001.insert({name: "张三", age: 18, sex: "男", hobby: "美女"});
db.test001.insertOne({name: "张三", age: 18, sex: "男", hobby: "美女"});
// 插入多条数据
db.test001.insertMany([
{name: "张三", age: 18, sex: "男", hobby: "美女"},
{name: "李四", age: 20, sex: "男", hobby: "跑车"},
{name: "王五", age: 21, sex: "男", hobby: "黑丝"},
]);
6、简单查询
查看当前集合所有数据(json文件)
格式:db.集合名称.find()
案例:
> db.test001.find()
{ "_id" : ObjectId("62177e62cec136e6f853bbe9"), "name" : "张三", "age" : 18, "sex" : "男", "hobby" : "美女" }
{ "_id" : ObjectId("62177e62cec136e6f853bbea"), "name" : "李四", "age" : 20, "sex" : "男", "hobby" : "跑车" }
{ "_id" : ObjectId("62177e62cec136e6f853bbeb"), "name" : "王五", "age" : 21, "sex" : "男", "hobby" : "黑丝" }
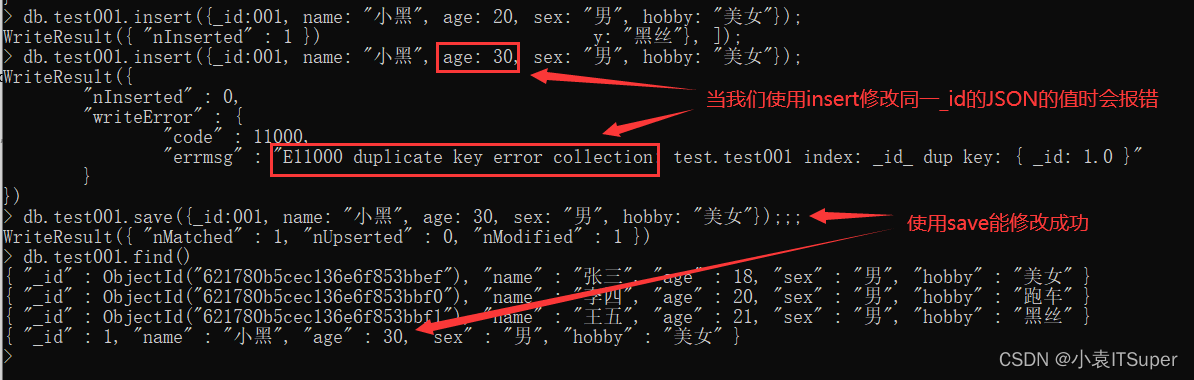
7、保存数据
格式:db.集合名称.save(document)
注意:如果⽂档的_id已经存在则修改, 如果⽂档的_id不存在则添加
案例:
8、修改数据
语法格式:
-
db.集合名称.update( ,,{multi: }) -
更新一条(字段全部替换):
db.集合名称.update({name:'原始数据'},{name:'修改后数据'}) -
更新一条(仅更新一个字段):
db.集合名称.update({name:'原始数据'},{$set:{name:'修改后数据'}}),推荐使用 -
更新全部:
db.集合名称.update({name:'原始数据'},{$set:{name:'修改后数据'}},{multi:true}) -
参数query:查询条件
-
参数update:更新操作符
-
参数multi:可选, 默认是false,表示只更新找到的第⼀条记录, 值为true表示把满⾜条件的⽂档全部更新
注意:{multi:true}需要和$set配合使用
案例1:
//把名字为小黑的更新为小白
> db.test001.update({name: '小黑'},{name:'小白'})))
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.test001.find()
{ "_id" : ObjectId("621780b5cec136e6f853bbef"), "name" : "张三", "age" : 18, "sex" : "男", "hobby" : "美女" }
{ "_id" : ObjectId("621780b5cec136e6f853bbf0"), "name" : "李四", "age" : 20, "sex" : "男", "hobby" : "跑车" }
{ "_id" : ObjectId("621780b5cec136e6f853bbf1"), "name" : "王五", "age" : 21, "sex" : "男", "hobby" : "黑丝" }
{ "_id" : 1, "name" : "小白" }
- 注意:这种写法会替换掉其他的字段(全部替换),age、sex、hobby都没有了
案例2:
//把名字为王五的更新为小王
> db.test001.update({name:'王五'},{$set:{name:'小王'}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.test001.find() '}})
{ "_id" : ObjectId("621780b5cec136e6f853bbef"), "name" : "张三", "age" : 18, "sex" : "男", "hobby" : "美女" }
{ "_id" : ObjectId("621780b5cec136e6f853bbf0"), "name" : "李四", "age" : 20, "sex" : "男", "hobby" : "跑车" }
{ "_id" : ObjectId("621780b5cec136e6f853bbf1"), "name" : "小王", "age" : 21, "sex" : "男", "hobby" : "黑丝" }
{ "_id" : 1, "name" : "小白" }
- 可以看出加上
$set:后仅更新了name一个字段
案例3:
//修改所有人的性别
> db.test001.update({sex: '男'},{$set:{sex: '女'}},{multi:true})
WriteResult({ "nMatched" : 0, "nUpserted" : 0, "nModified" : 0 })
> db.test001.find() ) })) })
{ "_id" : ObjectId("621780b5cec136e6f853bbef"), "name" : "张三", "age" : 18, "sex" : "女", "hobby" : "美女" }
{ "_id" : ObjectId("621780b5cec136e6f853bbf0"), "name" : "李四", "age" : 20, "sex" : "女", "hobby" : "跑车" }
{ "_id" : ObjectId("621780b5cec136e6f853bbf1"), "name" : "小王", "age" : 21, "sex" : "女", "hobby" : "黑丝" }
{ "_id" : 1, "name" : "小白" }
-
{multi:true}:起到全部JSON替换的功能
9、删除数据
格式:db.集合名称.remove(,{justOne: })
- 参数query:可选,删除的⽂档的条件
- 参数justOne:可选, 如果设为true或1, 则只删除⼀条, 默认false, 表示删除多条
案例:
//先删除一条数据
> db.test001.remove({sex: '女'}, {justOne:true})
WriteResult({ "nRemoved" : 1 })
> db.test001.find()
{ "_id" : ObjectId("621780b5cec136e6f853bbf0"), "name" : "李四", "age" : 20, "sex" : "女", "hobby" : "跑车" }
{ "_id" : ObjectId("621780b5cec136e6f853bbf1"), "name" : "小王", "age" : 21, "sex" : "女", "hobby" : "黑丝" }
{ "_id" : 1, "name" : "小白" }
// 全部删除
> db.test001.remove({sex: '女'})
WriteResult({ "nRemoved" : 2 })
> db.test001.find() )
{ "_id" : 1, "name" : "小白" }
四、高级查询
数据准备(三国争霸):
db.test002.insertMany([
{name: "张飞", hometown: "蜀国", age: 30, sex: "男"},
{name: "关羽", hometown: "蜀国", age: 40, sex: "男"},
{name: "刘备", hometown: "蜀国", age: 50, sex: "男"},
{name: "曹操", hometown: "魏国", age: 45, sex: "男"},
{name: "司马懿", hometown: "魏国", age: 45, sex: "男"},
{name: "孙权", hometown: "吴国", age: 50, sex: "男"}
]);
1、数据查询
-
条件查询:
db.集合名称.find({条件⽂档}) -
查询只返回第⼀个:
db.集合名称.findOne({条件⽂档}) -
将结果格式化:
db.集合名称.find({条件⽂档}).pretty()
案例1:
// 查询年龄为50
> db.test002.find({age:50})
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e7"), "name" : "刘备", "hometown" : "蜀国", "age" : 50, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3ea"), "name" : "孙权", "hometown" : "吴国", "age" : 50, "sex" : "男" }
// 查询年龄为45
> db.test002.find({age:45})
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e8"), "name" : "曹操", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e9"), "name" : "司马懿", "hometown" : "魏国", "age" : 45, "sex" : "男" }
案例2:
//查询一个年龄为50
> db.test002.findOne({age:50})
{
"_id" : ObjectId("6219a246d1ca96a61ceca3e7"),
"name" : "刘备",
"hometown" : "蜀国",
"age" : 50,
"sex" : "男"
}
//查询一个年龄为45
> db.test002.findOne({age:45})
{
"_id" : ObjectId("6219a246d1ca96a61ceca3e8"),
"name" : "曹操",
"hometown" : "魏国",
"age" : 45,
"sex" : "男"
}
案例3:
//美化输出年龄为50
> db.test002.find({age:50}).pretty()
{
"_id" : ObjectId("6219a246d1ca96a61ceca3e7"),
"name" : "刘备",
"hometown" : "蜀国",
"age" : 50,
"sex" : "男"
}
{
"_id" : ObjectId("6219a246d1ca96a61ceca3ea"),
"name" : "孙权",
"hometown" : "吴国",
"age" : 50,
"sex" : "男"
}
2、比较运算符
等于: 默认是等于判断, 没有运算符
⼩于:$lt (less than)
⼩于等于:$lte (less than equal)
⼤于:$gt (greater than)
⼤于等于:$gte
不等于:$ne
格式:db.集合名称.find({age:{$gte:18}})
案例:
//年龄小于45
> db.test002.find({age:{$lt:45}})
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e5"), "name" : "张飞", "hometown" : "蜀国", "age" : 30, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e6"), "name" : "关羽", "hometown" : "蜀国", "age" : 40, "sex" : "男" }
//年龄小于等于45
> db.test002.find({age:{$lte:45}})
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e5"), "name" : "张飞", "hometown" : "蜀国", "age" : 30, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e6"), "name" : "关羽", "hometown" : "蜀国", "age" : 40, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e8"), "name" : "曹操", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e9"), "name" : "司马懿", "hometown" : "魏国", "age" : 45, "sex" : "男" }
//年龄大于45
> db.test002.find({age:{$gt:45}})
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e7"), "name" : "刘备", "hometown" : "蜀国", "age" : 50, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3ea"), "name" : "孙权", "hometown" : "吴国", "age" : 50, "sex" : "男" }
//年龄大于等于45
> db.test002.find({age:{$gte:45}})
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e7"), "name" : "刘备", "hometown" : "蜀国", "age" : 50, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e8"), "name" : "曹操", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e9"), "name" : "司马懿", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3ea"), "name" : "孙权", "hometown" : "吴国", "age" : 50, "sex" : "男" }
//年龄不等于45
> db.test002.find({age:{$ne:45}})
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e5"), "name" : "张飞", "hometown" : "蜀国", "age" : 30, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e6"), "name" : "关羽", "hometown" : "蜀国", "age" : 40, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e7"), "name" : "刘备", "hometown" : "蜀国", "age" : 50, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3ea"), "name" : "孙权", "hometown" : "吴国", "age" : 50, "sex" : "男" }
3、范围运算符
判断是否在某个范围内:使⽤$in, $nin
格式:db.集合名字.find({age:{$in:[18,28]}})
案例:
//年龄为30,40,50
> db.test002.find({age:{$in:[30,40,50]}})
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e5"), "name" : "张飞", "hometown" : "蜀国", "age" : 30, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e6"), "name" : "关羽", "hometown" : "蜀国", "age" : 40, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e7"), "name" : "刘备", "hometown" : "蜀国", "age" : 50, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3ea"), "name" : "孙权", "hometown" : "吴国", "age" : 50, "sex" : "男" }
//年龄不为30,40,50
> db.test002.find({age:{$nin:[30,40,50]}})
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e8"), "name" : "曹操", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e9"), "name" : "司马懿", "hometown" : "魏国", "age" : 45, "sex" : "男" }
4、逻辑运算符
and:在json中写多个条件即可
格式:db.集合名称.find({条件1, 条件2})
or:使⽤$or, 值为数组, 数组中每个元素为json
格式:db.集合名词.find({$or:[{条件1}, {条件2}]})
案例:
//年龄为40的蜀国人
> db.test002.find({age: 40, hometown: "蜀国"})
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e6"), "name" : "关羽", "hometown" : "蜀国", "age" : 40, "sex" : "男" }
//年龄小于50或者为吴国人
> db.test002.find({$or:[{age:{$lt:50}}, {hometown: "吴国"}]})
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e5"), "name" : "张飞", "hometown" : "蜀国", "age" : 30, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e6"), "name" : "关羽", "hometown" : "蜀国", "age" : 40, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e8"), "name" : "曹操", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e9"), "name" : "司马懿", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3ea"), "name" : "孙权", "hometown" : "吴国", "age" : 50, "sex" : "男" }
5、正则表达式
使⽤//或$regex编写正则表达式
格式1:db.集合名称.find({name:/^张/})
格式2:db.集合名词.find({name:{$regex:'^张'}})
案例:
//查询姓名以张开头
> db.test002.find({name:/^张/})
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e5"), "name" : "张飞", "hometown" : "蜀国", "age" : 30, "sex" : "男" }
> db.test002.find({name:{$regex:'^张'}})
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e5"), "name" : "张飞", "hometown" : "蜀国", "age" : 30, "sex" : "男" }
6、limit和skip
⽤于读取指定数量的⽂档:db.集合名称.find().limit(number)
⽤于跳过指定数量的⽂档:db.集合名称.find().skip(number)
同时使用:
db.集合名称.find().limit(number).skip(number)
或
db.集合名称.find().skip(number).limit(number) //推荐使用效率会更高
案例:
//查询前两条数据
> db.test002.find().limit(2)
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e5"), "name" : "张飞", "hometown" : "蜀国", "age" : 30, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e6"), "name" : "关羽", "hometown" : "蜀国", "age" : 40, "sex" : "男" }
//查询除前两条以外的数据
> db.test002.find().skip(2)
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e7"), "name" : "刘备", "hometown" : "蜀国", "age" : 50, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e8"), "name" : "曹操", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e9"), "name" : "司马懿", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3ea"), "name" : "孙权", "hometown" : "吴国", "age" : 50, "sex" : "男" }
//查询前五条数据中后两条
> db.test002.find().limit(5).skip(3)
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e8"), "name" : "曹操", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e9"), "name" : "司马懿", "hometown" : "魏国", "age" : 45, "sex" : "男" }
//查询后三条数据中的前两条
> db.test002.find().skip(3).limit(2)
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e8"), "name" : "曹操", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e9"), "name" : "司马懿", "hometown" : "魏国", "age" : 45, "sex" : "男" }
7、自定义查询
使⽤$where后⾯写⼀个函数, 返回满⾜条件的数据
格式:
db.集合名称.find({
$where:function() {
return this.条件;}
})
案例:
//查询年龄大于40
> db.test002.find({
$where:function() {
return this.age>40;}
})
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e7"), "name" : "刘备", "hometown" : "蜀国", "age" : 50, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e8"), "name" : "曹操", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e9"), "name" : "司马懿", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3ea"), "name" : "孙权", "hometown" : "吴国", "age" : 50, "sex" : "男" }
8、投影
在查询到的返回结果中, 只选择必要的字段:db.集合名称.find({条件(可省略)},{字段名称:1,...})
-
参数为字段与值, 值为1表示显示, 不显示则不用写
-
特殊: 对于_id列默认是显示的, 如果不显示需要明确设置为0
案例1:
//显示name和age字段
> db.test002.find({},{name:1, age:1})
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e5"), "name" : "张飞", "age" : 30 }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e6"), "name" : "关羽", "age" : 40 }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e7"), "name" : "刘备", "age" : 50 }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e8"), "name" : "曹操", "age" : 45 }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e9"), "name" : "司马懿", "age" : 45 }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3ea"), "name" : "孙权", "age" : 50 }
- 可以看出
_id列默认是显示的
案例2:
//仅显示name字段
> db.test002.find({},{name:1, _id:0})
{ "name" : "张飞" }
{ "name" : "关羽" }
{ "name" : "刘备" }
{ "name" : "曹操" }
{ "name" : "司马懿" }
{ "name" : "孙权" }
9、排序
对集合进⾏排序:db.集合名称.find().sort({字段:1,...})
-
参数1为升序排列
-
参数-1为降序排列
案例:
//根据年龄升序排序
> db.test002.find().sort({age:1})
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e5"), "name" : "张飞", "hometown" : "蜀国", "age" : 30, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e6"), "name" : "关羽", "hometown" : "蜀国", "age" : 40, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e8"), "name" : "曹操", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e9"), "name" : "司马懿", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e7"), "name" : "刘备", "hometown" : "蜀国", "age" : 50, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3ea"), "name" : "孙权", "hometown" : "吴国", "age" : 50, "sex" : "男" }
//根据年龄降序排序
> db.test002.find().sort({age:-1})
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e7"), "name" : "刘备", "hometown" : "蜀国", "age" : 50, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3ea"), "name" : "孙权", "hometown" : "吴国", "age" : 50, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e8"), "name" : "曹操", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e9"), "name" : "司马懿", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e6"), "name" : "关羽", "hometown" : "蜀国", "age" : 40, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e5"), "name" : "张飞", "hometown" : "蜀国", "age" : 30, "sex" : "男" }
//根据name降序,再根据age降序
> db.test002.find().sort({name:-1, age:-1})
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e8"), "name" : "曹操", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e5"), "name" : "张飞", "hometown" : "蜀国", "age" : 30, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3ea"), "name" : "孙权", "hometown" : "吴国", "age" : 50, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e9"), "name" : "司马懿", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e7"), "name" : "刘备", "hometown" : "蜀国", "age" : 50, "sex" : "男" }
{ "_id" : ObjectId("6219a246d1ca96a61ceca3e6"), "name" : "关羽", "hometown" : "蜀国", "age" : 40, "sex" : "男" }
10、统计个数
统计结果集中⽂档条数:
db.集合名称.find({条件}).count()db.集合名称.count({条件})
案例:
//统计蜀国人个数
> db.test002.find({hometown: "蜀国"}).count()
3
> db.test002.count({hometown: "蜀国"})
3
注意:如果有find(),需要在find()中写条件
11、去除重复
数据进⾏去重:db.集合名称.distinct('去重字段',{条件})
案例:
//对hometown去重
> db.test002.distinct('hometown')
[ "吴国", "蜀国", "魏国" ]
//对age去重
> db.test002.distinct('age')
[ 30, 40, 45, 50 ]
//对age去重,并且为蜀国人
> db.test002.distinct('age',{hometown:"蜀国"})
[ 30, 40, 50 ]
五、聚合和管道
数据准备:
db.test003.insertMany([
{name: "张飞", hometown: "蜀国", age: 30, sex: "男"},
{name: "关羽", hometown: "蜀国", age: 40, sex: "男"},
{name: "刘备", hometown: "蜀国", age: 50, sex: "男"},
{name: "曹操", hometown: "魏国", age: 45, sex: "男"},
{name: "司马懿", hometown: "魏国", age: 45, sex: "男"},
{name: "孙权", hometown: "吴国", age: 50, sex: "男"},
{name: "貂蝉", hometown: "未知", age: 18, sex: "女"},
{name: "西施", hometown: "越国", age: 18, sex: "女"},
{name: "王昭君", hometown: "西汉", age: 18, sex: "女"},
{name: "杨玉环", hometown: "唐朝", age: 18, sex: "女"}
]);
1、聚合简介
聚合(aggregate)是基于数据处理的聚合管道,每个文档通过一个由多个阶段(stage)组成的管道,可以对每个阶段的管道进行分组、过滤等功能,然后经过一系列的处理,输出相应的结果。
语法格式:db.集合名称.aggregate({管道:{表达式}})
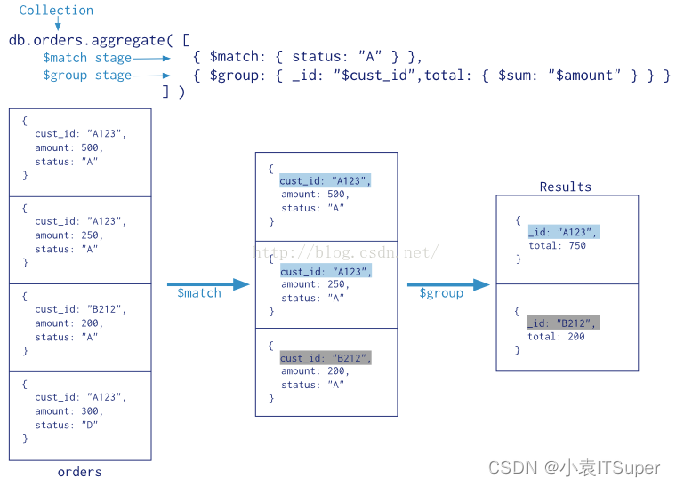
2、常用管道
在mongodb中,⽂档处理完毕后, 通过管道进⾏下⼀次处理
常用管道如下:
$group: 将集合中的⽂档分组, 可⽤于统计结果
$match: 过滤数据, 只输出符合条件的⽂档
$project: 修改输⼊⽂档的结构, 如重命名、 增加、 删除字段、 创建计算结果
$sort: 将输⼊⽂档排序后输出
$limit: 限制聚合管道返回的⽂档数
$skip: 跳过指定数量的⽂档, 并返回余下的⽂档
$unwind: 将数组类型的字段进⾏拆分
3、表达式
处理输⼊⽂档并输出
语法格式:表达式:'$列名'
常⽤表达式:
$sum: 计算总和, $sum:1 表示以⼀倍计数
$avg: 计算平均值
$min: 获取最⼩值
$max: 获取最⼤值
$push: 在结果⽂档中插⼊值到⼀个数组中
$first: 根据资源⽂档的排序获取第⼀个⽂档数据
$last: 根据资源⽂档的排序获取最后⼀个⽂档数据
4、$group
将集合中的文档分组,可用于统计结果
_id表示分组的依据,使用某个字段的格式为’$字段’
案例:
// 返回sex有哪些值
> db.test003.aggregate(
{$group:{
_id:"$sex"
}
}
)
{ "_id" : "男" }
{ "_id" : "女" }
//统计男生、女生分别的总人数
> db.test003.aggregate(
{$group:
{
_id:"$sex",
count:{$sum:1}
}
}
)
{ "_id" : "男", "count" : 6 }
{ "_id" : "女", "count" : 4 }
//统计男、女分别的平均年龄
> db.test003.aggregate(
{$group:
{
_id:"$sex",
count:{$sum:1},
avg_age:{$avg:"$age"}
}
}
)
{ "_id" : "男", "count" : 6, "avg_age" : 43.333333333333336 }
{ "_id" : "女", "count" : 4, "avg_age" : 18 }
//按照hometown进行分组,获取不同组的平均年龄
> db.test003.aggregate(
{$group:
{
_id:"$hometown",
avg_age:{$avg:"$age"}
}
}
)
{ "_id" : "蜀国", "avg_age" : 40 }
{ "_id" : "唐朝", "avg_age" : 18 }
{ "_id" : "越国", "avg_age" : 18 }
{ "_id" : "吴国", "avg_age" : 50 }
{ "_id" : "西汉", "avg_age" : 18 }
{ "_id" : "未知", "avg_age" : 18 }
{ "_id" : "魏国", "avg_age" : 45 }
//统计不同性别的人物名字
> db.test003.aggregate(
{$group:
{
_id:"$sex",
name:{$push:"$name"}
}
}
)
{ "_id" : "男", "name" : [ "张飞", "关羽", "刘备", "曹操", "司马懿", "孙权" ] }
{ "_id" : "女", "name" : [ "貂蝉", "西施", "王昭君", "杨玉环" ] }
// 使用$$ROOT可以将文档内容加入到结果集的数组中
> db.test003.aggregate(
{$group:
{
_id:"$sex",
name:{$push:"$$ROOT"}
}
}
)
{ "_id" : "男", "name" : [ { "_id" : ObjectId("621cbd0aea5c14fd51410b33"), "name" : "张飞", "hometown" : "蜀国", "age" : 30, "sex" : "男" }, { "_id" : ObjectId("621cbd0aea5c14fd51410b34"), "name" : "关羽", "hometown" : "蜀国", "age" : 40, "sex" : "男" }, { "_id" : ObjectId("621cbd0aea5c14fd51410b35"), "name" : " 刘备", "hometown" : "蜀国", "age" : 50, "sex" : "男" }, { "_id" : ObjectId("621cbd0aea5c14fd51410b36"), "name" : "曹操", "hometown" : "魏国", "age" : 45, "sex" : "男" }, { "_id" : ObjectId("621cbd0aea5c14fd51410b37"), "name" : "司马懿", "hometown" : "魏国", "age" : 45, "sex" : "男" }, { "_id" : ObjectId("621cbd0aea5c14fd51410b38"), "name" : "孙权", "hometown" : "吴国", "age" : 50, "sex" : "男" } ] }
{ "_id" : "女", "name" : [ { "_id" : ObjectId("621cbd0aea5c14fd51410b39"), "name" : "貂蝉", "hometown" : "未知", "age" : 18, "sex" : "女" }, { "_id" : ObjectId("621cbd0aea5c14fd51410b3a"), "name" : "西施", "hometown" : "越国", "age" : 18, "sex" : "女" }, { "_id" : ObjectId("621cbd0aea5c14fd51410b3b"), "name" : " 王昭君", "hometown" : "西汉", "age" : 18, "sex" : "女" }, { "_id" : ObjectId("621cbd0aea5c14fd51410b3c"), "name" : "杨玉环", "hometown" : "唐朝", "age" : 18, "sex" : "女" } ] }
_id:null:将集合中所有文档分为一组
案例:求总人数、平均年龄
> db.test003.aggregate(
{$group:
{
_id:null,
count:{$sum:1},
avg_age:{$avg:"$age"}
}
}
)
{ "_id" : null, "count" : 10, "avg_age" : 33.2 }
总结:
-
$group对应的字典中有几个键,结果中就有几个键 - 分组依据需要放到
_ id后面 - 取不同的字段的值需要使用
$,如:$hometown、$age、$sex - 取字典嵌套的字典中值的时候
$_id.字段名 - 同时取多个键进行分组:
{$group:{_id:{字段名1:"$字段名1",字段名2:"字段名2"}}};输出结果:{_id:{字段名1:"",字段名2:""}
5、$project
修改输入文档的结构,如重命名、增加、删除字段、创建计算结果;简单来说就是修改输入输出的值
案例1:查询姓名、年龄
> db.test003.aggregate({$project:{_id:0, name:1, age:1}})
{ "name" : "张飞", "age" : 30 }
{ "name" : "关羽", "age" : 40 }
{ "name" : "刘备", "age" : 50 }
{ "name" : "曹操", "age" : 45 }
{ "name" : "司马懿", "age" : 45 }
{ "name" : "孙权", "age" : 50 }
{ "name" : "貂蝉", "age" : 18 }
{ "name" : "西施", "age" : 18 }
{ "name" : "王昭君", "age" : 18 }
{ "name" : "杨玉环", "age" : 18 }
案例2:查询男、女人数,输出人数
> db.test003.aggregate(
{$group:{_id:'$sex', count:{$sum:1}}},
{$project:{_id:0, count:1}}
)
{ "count" : 4 }
{ "count" : 6 }
6、$match
用于过滤数据,只输出符合条件的文档
- 使用MongoDB的标准查询操作
-
match是管道命令,能将结果交给后一个管道,但是find不可以
案例1:查询年龄大于20的
> db.test003.aggregate(
{$match:{age:{$gt:20}}}
)
{ "_id" : ObjectId("621cbd0aea5c14fd51410b33"), "name" : "张飞", "hometown" : "蜀国", "age" : 30, "sex" : "男" }
{ "_id" : ObjectId("621cbd0aea5c14fd51410b34"), "name" : "关羽", "hometown" : "蜀国", "age" : 40, "sex" : "男" }
{ "_id" : ObjectId("621cbd0aea5c14fd51410b35"), "name" : "刘备", "hometown" : "蜀国", "age" : 50, "sex" : "男" }
{ "_id" : ObjectId("621cbd0aea5c14fd51410b36"), "name" : "曹操", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("621cbd0aea5c14fd51410b37"), "name" : "司马懿", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("621cbd0aea5c14fd51410b38"), "name" : "孙权", "hometown" : "吴国", "age" : 50, "sex" : "男" }
案例2:查询年龄大于等于18的男生、女生人数
> db.test003.aggregate(
{$match:{age:{$gte:18}}},
{$group:{_id:'$sex',count:{$sum:1}}}
)
{ "_id" : "男", "count" : 6 }
{ "_id" : "女", "count" : 4 }
7、$sort
将输入文档排序后输出
例1:查询学生信息,按年龄升序
> db.test003.aggregate({$sort:{age:1}})
{ "_id" : ObjectId("622080a6d0f7b3df134da712"), "name" : "貂蝉", "hometown" : "未知", "age" : 18, "sex" : "女" }
{ "_id" : ObjectId("622080a6d0f7b3df134da713"), "name" : "西施", "hometown" : "越国", "age" : 18, "sex" : "女" }
{ "_id" : ObjectId("622080a6d0f7b3df134da714"), "name" : "王昭君", "hometown" : "西汉", "age" : 18, "sex" : "女" }
{ "_id" : ObjectId("622080a6d0f7b3df134da715"), "name" : "杨玉环", "hometown" : "唐朝", "age" : 18, "sex" : "女" }
{ "_id" : ObjectId("622080a6d0f7b3df134da70c"), "name" : "张飞", "hometown" : "蜀国", "age" : 30, "sex" : "男" }
{ "_id" : ObjectId("622080a6d0f7b3df134da70d"), "name" : "关羽", "hometown" : "蜀国", "age" : 40, "sex" : "男" }
{ "_id" : ObjectId("622080a6d0f7b3df134da70f"), "name" : "曹操", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("622080a6d0f7b3df134da710"), "name" : "司马懿", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("622080a6d0f7b3df134da70e"), "name" : "刘备", "hometown" : "蜀国", "age" : 50, "sex" : "男" }
{ "_id" : ObjectId("622080a6d0f7b3df134da711"), "name" : "孙权", "hometown" : "吴国", "age" : 50, "sex" : "男" }
例2:查询男生、女生人数,按人数降序
> db.test003.aggregate(
{$group:{_id:'$sex',counter:{$sum:1}}},
{$sort:{age:-1}}
)
{ "_id" : "男", "counter" : 6 }
{ "_id" : "女", "counter" : 4 }
8、$limit
限制聚合管道返回的文档数量
案例:查询2条学生信息
> db.test003.aggregate({$limit:2})
{ "_id" : ObjectId("622080a6d0f7b3df134da70c"), "name" : "张飞", "hometown" : "蜀国", "age" : 30, "sex" : "男" }
{ "_id" : ObjectId("622080a6d0f7b3df134da70d"), "name" : "关羽", "hometown" : "蜀国", "age" : 40, "sex" : "男" }
9、$skip
跳过指定数量的文档,并返回余下的文档
例1:查询从第3条开始:人物信息
> db.test003.aggregate({$skip:2})
{ "_id" : ObjectId("622080a6d0f7b3df134da70e"), "name" : "刘备", "hometown" : "蜀国", "age" : 50, "sex" : "男" }
{ "_id" : ObjectId("622080a6d0f7b3df134da70f"), "name" : "曹操", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("622080a6d0f7b3df134da710"), "name" : "司马懿", "hometown" : "魏国", "age" : 45, "sex" : "男" }
{ "_id" : ObjectId("622080a6d0f7b3df134da711"), "name" : "孙权", "hometown" : "吴国", "age" : 50, "sex" : "男" }
{ "_id" : ObjectId("622080a6d0f7b3df134da712"), "name" : "貂蝉", "hometown" : "未知", "age" : 18, "sex" : "女" }
{ "_id" : ObjectId("622080a6d0f7b3df134da713"), "name" : "西施", "hometown" : "越国", "age" : 18, "sex" : "女" }
{ "_id" : ObjectId("622080a6d0f7b3df134da714"), "name" : "王昭君", "hometown" : "西汉", "age" : 18, "sex" : "女" }
{ "_id" : ObjectId("622080a6d0f7b3df134da715"), "name" : "杨玉环", "hometown" : "唐朝", "age" : 18, "sex" : "女" }
例2:查询从第3条开始,取第二条数据
> db.test003.aggregate(
{$skip:2},
{$limit:1}
)
{ "_id" : ObjectId("622080a6d0f7b3df134da70e"), "name" : "刘备", "hometown" : "蜀国", "age" : 50, "sex" : "男" }
- 注意顺序:先写skip, 再写limit
10、$unwind
将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值
语法格式:db. 集合名称.aggregate({$unwind:'$字段名称’})
案例:
> db.test004.insert({_id:1, item:'t-shirt', size:['S','M','L']})
WriteResult({ "nInserted" : 1 })
> db.test004.aggregate({$unwind: '$size'})
{ "_id" : 1, "item" : "t-shirt", "size" : "S" }
{ "_id" : 1, "item" : "t-shirt", "size" : "M" }
{ "_id" : 1, "item" : "t-shirt", "size" : "L" }
练习:数据库中有一条数据:{“username”:“Alex”,“tags”: [‘C#’,‘Java’,‘C++’]},如何获取该tag列表的长度?
//先插入数据
> db.test004.insert({"username":"Alex","tags": ['C#','Java','C++']})
WriteResult({ "nInserted" : 1 })
//查看数据
> db.test004.find()
{ "_id" : ObjectId("6220b04d383dd803412e9a3f"), "username" : "Alex", "tags" : [ "C#", "Java", "C++" ] }
//拆分数据
> db.test004.aggregate({$match:{username:"Alex"}},{$unwind:"$tags"})
{ "_id" : ObjectId("6220b04d383dd803412e9a3f"), "username" : "Alex", "tags" : "C#" }
{ "_id" : ObjectId("6220b04d383dd803412e9a3f"), "username" : "Alex", "tags" : "Java" }
{ "_id" : ObjectId("6220b04d383dd803412e9a3f"), "username" : "Alex", "tags" : "C++" }
//把上面得三条结果给$group,然后统计条数
> db.test004.aggregate({$match:{username:"Alex"}},{$unwind:"$tags"},{$group:{_id:null, sum:{$sum:1}}})
{ "_id" : null, "sum" : 3 }
属性
preserveNullAndEmptyArrays值为true表示保留属性值为空的⽂档;值为false表示丢弃属性值为空的⽂档
用法:

六、索引
1、创建索引
索引:以提升查询速度
测试:插入10万条数据到数据库中
> for(i=0;i100000;i++){db.test005.insert({name:'test'+i,age:i})}
WriteResult({ "nInserted" : 1 })
> db.test005.find().count()
100000
查询运行时间:语句后面+.explain('executionStats')
//案例
> db.test005.find({name:'test10000'}).explain('executionStats')
建立索引语法:db.集合名称.ensureIndex({字段名:1});其中 1 表示升序, -1 表示降序
建立索引之后对比:
> db.test005.ensureIndex({name:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
> db.test005.find({name:'test10000'}).explain('executionStats')

2、索引操作
查看当前集合的所有索引:
> db.test005.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_"
},
{
"v" : 2,
"key" : {
"name" : 1
},
"name" : "name_1"
}
]
删除索引:db.集合名称.dropIndex({'索引名称'})
> db.test005.dropIndex({'name':1})
{ "nIndexesWas" : 2, "ok" : 1 }
//再次查看全部索引
> db.test005.getIndexes()
[ { "v" : 2, "key" : { "_id" : 1 }, "name" : "_id_" } ]
创建唯一索引(索引的值是唯一的;在默认情况下索引字段的值可以相同):
> db.test005.ensureIndex({"name":1}, {"unique":true})
{
"ok" : 0,
"errmsg" : "Index build failed: eab854cd-330b-414f-ae86-9cfb317efbf5: Collection test.test005 ( 45744ab1-2a71-4722-8f84-99812ccc9ffb ) :: caused by :: E11000 duplicate key error collection: test.test005 index: name_1 dup key: { name: "test0" }",
"code" : 11000,
"codeName" : "DuplicateKey",
"keyPattern" : {
"name" : 1
},
"keyValue" : {
"name" : "test0"
}
}
建立联合索引(什么时候需要联合索引)
> db.test005.ensureIndex({name:1, age:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
> db.test005.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_"
},
{
"v" : 2,
"key" : {
"name" : 1,
"age" : 1
},
"name" : "name_1_age_1"
}
]
七、备份和恢复
1、备份
备份的语法:mongodump -h dbhost -d dbname -o dbdirectory
-
-h: 指定服务器地址;如果是当前本机数据库可以去掉-h -
-port:指定端口号;如果是默认端口可以去掉 -
-d: 需要备份的数据库名称;如果不指定则导出所有数据库 -
-o: 备份的数据存放位置, 此⽬录中存放着备份出来的数据 -
-c: 指定集合名称;如果不指定则全部导出 -
-u: 用户名;如果没有用户,可以不用指定 -
-p: 密码;如果没有密码,可以不用指定
注意:
- 命名需要在终端输出,而不是数据库命令行
- 每个参数前后是有空格
mongodump -h 192.168.196.128:27017 -d test1 -o ~/Desktop/test1bak
案例:
//保存本地数据库中test库在桌面
mongodump -d test -o ~C:UsersymDesktop
2、恢复
恢复语法:mongorestore -h dbhost -d dbname --dir dbdirectory
-
-h: 服务器地址 -
-d: 需要恢复的数据库实例 -
--dir: 备份数据所在位置
mongorestore -h 192.168.196.128:27017 -d test2 –dir ~/Desktop/test1bak/test1
