

编者按:在实际部署大模型的过程中可能会面临资源限制的问题。通过轻量化大模型微调技术,可以将大型预训练语言模型适配到特定领域、特定任务,并减小其模型尺寸和计算量需求,提高性能和效率。
在上一篇文章中,我们分享了大语言模型的主要微调技术总览。接下来,本文将介绍轻量化大模型微调技术,重点关注Prompt Tuning和Prefix Tuning。
以下是译文,Enjoy!
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://magazine.sebastianraschka.com/p/understanding-parameter-efficient
作者 | SEBASTIAN RASCHKA, PHD
编译 | 岳扬
01 Prompt Tuning
Prompt Tuning是一种通过改变输入提示语(input prompt)以获得更优模型效果的技术。举个例子,如果我们想将一条英语句子翻译成德语,可以采用多种不同的方式向模型提问,如下图所示:

这是一个hard prompt tuning示例,通过尝试多种输入提示来获得更好的输出效果。
这个案例采用的是硬提示调优(hard prompt tuning) 方法,因为它直接修改了离散的输入标记(input tokens),而这些标记是不可再分的。
> 译者注:在自然语言处理领域,一般将文本进行分词处理,将一个句子拆分为一个个离散的单词或标点符号作为input token。每个token代表一个离散的语义单位,模型可以根据这些token进行语义理解和生成回复。 > > 例如,对于句子 “你好,很高兴见到你!”,可以将其分解为以下离散的input token: > > [ “你”, “好”, “,”, “很”, “高兴”, “见到”, “你”, “!” ] > > 这些离散的token可以作为模型的输入,用于训练或生成对话回复。注意,在使用离散的input token时需要将其转换为对应的向量表示(如词嵌入表示),以便模型能够对其进行处理和学习。
与硬提示调优(hard prompt tuning)相反,软提示调优(soft prompt tuning)方法(Lester等人,2021年[1])将输入标记(input tokens)的嵌入(embeddings)与可通过反向传播算法(backpropagation)进行优化的可训练张量(tensor)连接起来,以提高模型在目标任务上的性能。
伪代码如下所示:

说明soft prompting相关概念的伪代码
与离散的文本prompt不同,软提示(soft prompts)是通过反向传播算法(back-propagation)获得的,因此可以根据已标注数据集的损失函数反馈(loss feedback)进行调整。
相较于全参数微调(full-finetuning),软提示调优(soft prompt tuning)具有更高的参数效率(more parameter-efficient),但使用软提示调优的模型性能可能稍逊一筹,如下图所示。

该图来自提出soft prompting的论文,https://arxiv.org/abs/2104.08691
另一方面,如果模型参数为11B,则根据上图所示,软提示调优(soft prompt tuning)可以达到全参数微调(full fine tuning)的性能水平(需要注意的是,LLaMA模型的最小参数规模为7B,最大参数规模为65B)。
存储效率
如果我们想要将大模型应用于特定任务,并因此需要微调预训练模型,通常需要为每个任务保存整个模型的副本。然而,如果使用prompt tuning,我们只需要为每个任务保存一个小小的task-specific soft prompt。例如,对于T5 “XXL”模型,每个微调模型副本需要110亿个参数。相比之下,假设prompt长度为5个tokens,嵌入的size为4096维(4096-dimensional),对于每个每个任务,通过prompt tuning只需要20480个参数,这相当于减少了五个数量级以上的参数量。
02 从Prompt Tuning到Prefix Tuning
目前,有一种特殊的、被独立开发的prompt tuning方式被称为前缀调优(prefix tuning) (Li & Liang 2021[2])。其思想是将可训练的张量(trainable tensors)添加到每个Transformer块中,而非像soft prompt tuning中那样只添加输入嵌入(input embeddings)。同时,通过全连接层(fully connected layers,两层并且具有非线性激活函数的小型多层感知机)获取soft prompt embedding。
> 译者注: 在使用深度学习模型进行自然语言处理任务时,input embeddings常作*为模型的第一层进行使用,将离散的input token转换为连续的向量表示,从而实现对文本的有效建模和处理。* > > 前缀调优技术将预定义的prompt嵌入到模型中,以影响模型的生成行为。这项技术可以改变模型对输入的解释方式,使得模型能够更好地根据prompt生成相应的输出。
下图说明了常规Transformer块和经过前缀(prefix)修改的Transformer块之间的区别。
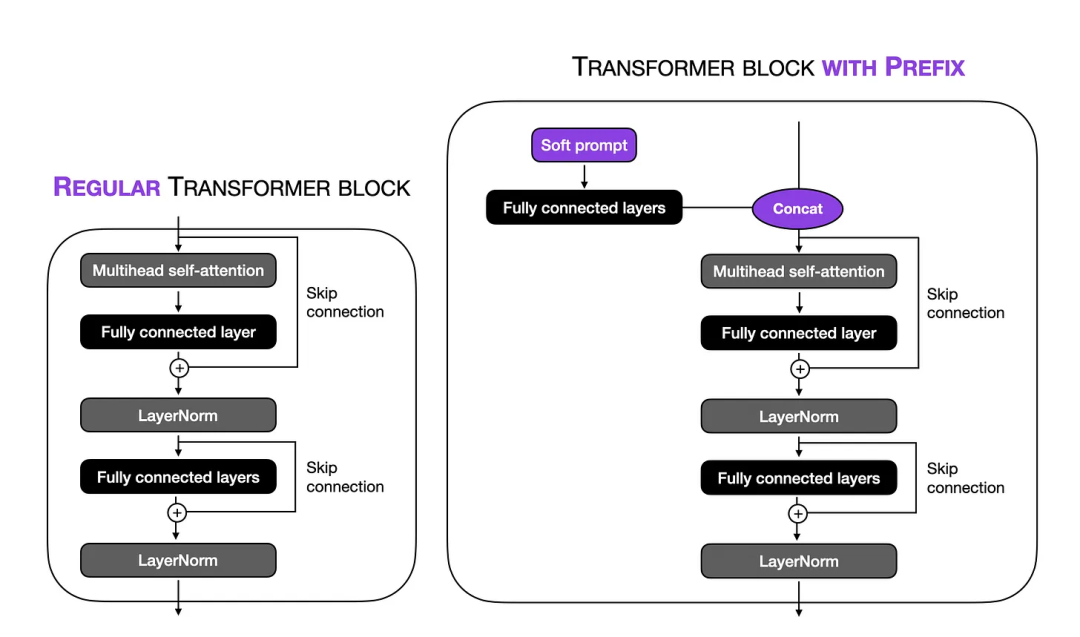
Illustration of prefix tuning
请注意,在上图中,“全连接层”是指一个小型多层感知机(由两个全连接层和一个非线性激活函数组成)。这些全连接层将soft prompt嵌入到一个与transformer块输入具有相同维度的特征空间(feature space)中,以确保两层连接时的兼容性。
使用Python伪代码,可以说明常规Transformer块和经过前缀(prefix)修改的Transformer块之间的区别:
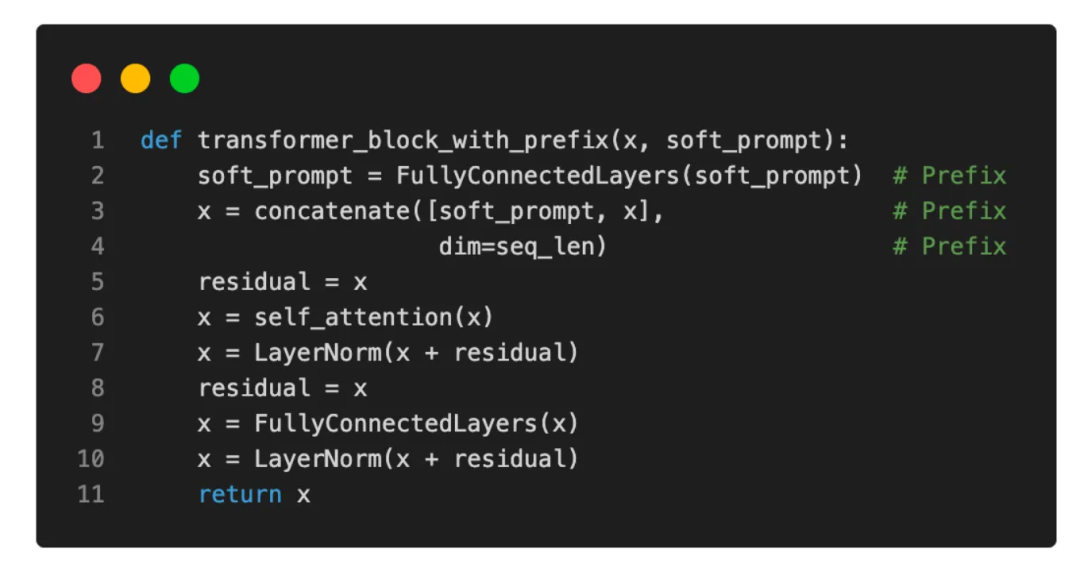
prefix tuning的伪代码图示
根据提出prefix tuning的论文,该方法在仅训练0.1%的参数的情况下,实现了与微调所有层相当的模型性能(该实验基于GPT-2模型)。此外,在大多数情况下,prefix tuning的表现甚至优于微调所有层,可能是因为该方法涉及的参数较少,有助于减少对较小目标数据集的过拟合问题。
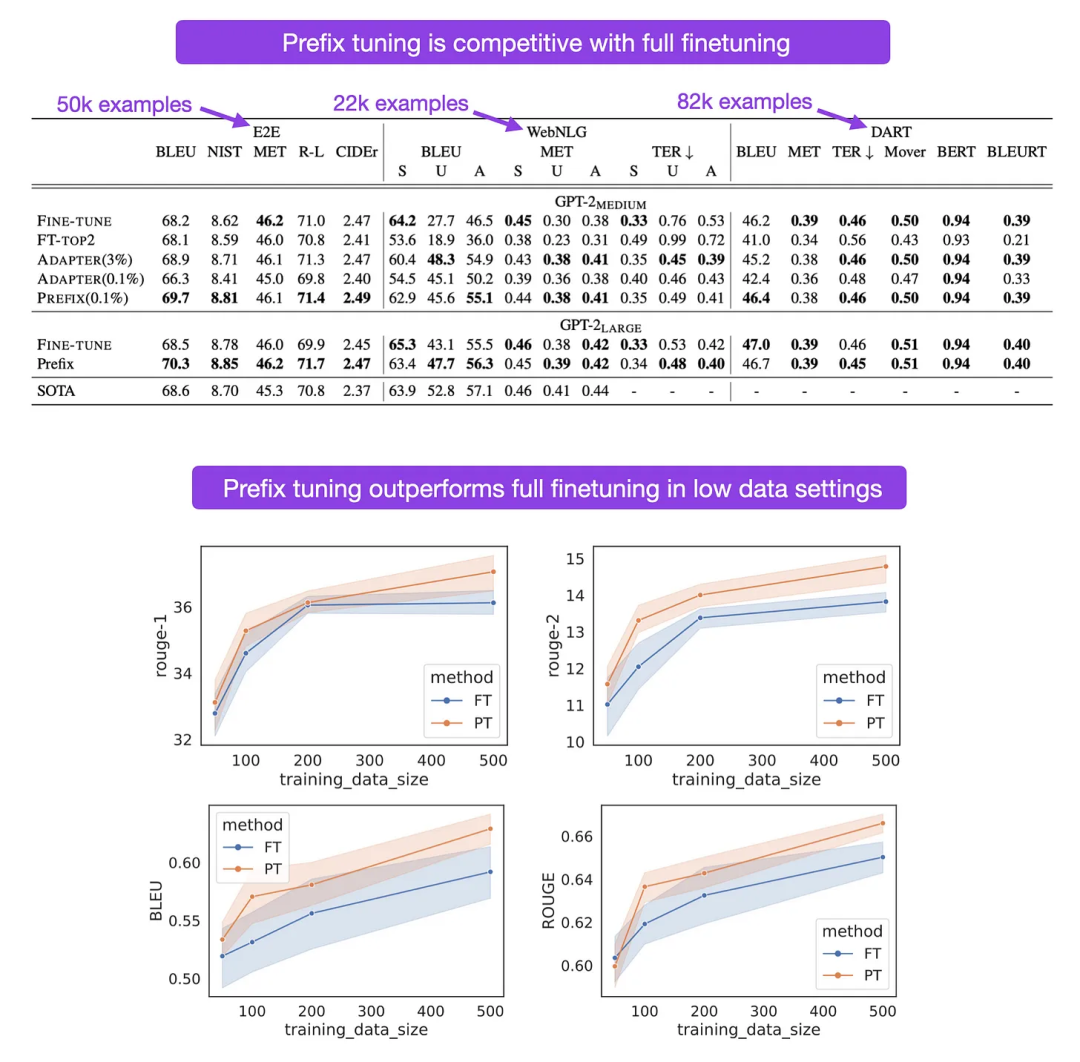
由Li and Liang发表的Prefix Tuning相关论文中的注释图
最后,为了澄清推理过程中soft prompts的使用方式,请注意以下几点:在学习了soft prompts后,在我们针对特定任务对模型进行微调时,我们必须将其(soft prompts)作为前缀(prefix)提供。这样做可以使模型根据特定任务自定义其回答。此外,我们可以拥有多个soft prompts,每个对应于不同的任务,并且在推理过程能够提供相应的前缀,以最好地去处理特定任务。
03 Prefix与Prompt Tuning
在性能方面,soft prompt tuning和prefix tuning孰强孰弱?不幸的是,就性能而言,目前尚无直接比较soft prompt tuning和prefix tuning的研究结果,因为这它们是独立开发并同时发布的方法,各自的论文中未进行直接的比较。此外,在我查阅参数高效型大语言模型(parameter-efficient LLM)的最新文献中,并没有找到同时包含这两种方法的基准测试(benchmark) 。
在prefix tuning这种方法中,通过向输入序列(input sequence)插入特定任务的前缀(a task-specific prefix)来修改模型的更多层、,因此需要微调更多的参数。另一方面,soft prompt tuning仅涉及对input prompt embeddings进行微调,因此更新的参数较少。这使得soft prompt tuning可能比prefix tuning更轻量化(parameter-efficient),但也可能限制了其适应更广泛目标任务的能力。
就性能方面而言,我们可以合理地期望prefix tuning可能表现得更好,因为它能够调整更多的模型参数以便适应更广泛的新任务。然而,这可能是以增加计算资源的消耗和提高模型出现过拟合的风险为代价的。另一方面,soft prompt tuning可能具有更高的计算效率,但由于微调的参数较少,可能会导限制模型的性能。
04 总结
该文章介绍了两种轻量化微调技术:soft prompt tuning 和 prefix tuning。与全参数微调(full finetuning)相比,这两种方法仅需调整很少的参数。
对于开发者来说,soft prompt tuning可以更具有吸引力,因为他们只需要修改input embeddings,而不需像prefix tuning那样修改内部transformer块。
在你开始尝试使用这些技术微调大模型之前,我建议你持续关注其他更有趣的轻量化微调(parameter-efficient finetuning)技术:Adapters,LLaMA-Adapter(与常规的Adapter有关但也有所不同)以及Low-Rank Adaptation(LoRA) 等等。这些技术可能会提供更多选择,并且可以根据你的具体需求进行更好的调整。
END
参考资料
1. https://arxiv.org/abs/2104.08691
2. https://arxiv.org/abs/2101.00190
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://magazine.sebastianraschka.com/p/understanding-parameter-efficient
相关文章推荐
落地领域大模型应知必会 (1) :主要微调方法总览
大模型的三大法宝:Finetune, Prompt Engineering, Reward
Prompt Learning: ChatGPT也在用的NLP新范式
