

作者|NearFar X Lab 团队 洪守伟、陈超、周志银、左益、武超
整理|SelectDB 内容团队
导读: 无锡拈花云科技服务有限公司(以下简称拈花云科)是由中国创意文旅集成商拈花湾文旅和北京滴普科技有限公司共同孵化组建的。拈花云科以数字化思维为导向,致力于成为文旅目的地数智化服务商。2022 年底,拈花云科 NearFar X Lab 团队在数据需求的驱动下,开始调研并引进 Apache Doris 作为新架构下的数据仓库选型方案。本文主要介绍了拈花云科数据中台架构从 1.0 到 2.0 的演变过程,以及 Apache Doris 在交付型项目和 SaaS 产品中的应用实践,希望本文分享的内容能对大家有所启发。
业务背景
拈花云科的服务对象主要是国内各个景区、景点,业务范围涵盖文旅行业的多个板块,如票务、交通、零售、住宿、餐饮、演绎、游乐、影院、KTV、租赁、服务、会务、康乐、康养、电商、客服、营销、分销、安防等。多业务线条下用户对于数据使用的时效性需求差异较大,需要我们能够提供实时、准实时、T+1 的业务支撑能力。同时根据大部分景区为国有化的特点,我们也需要具备能够提供私有化交付部署及 SaaS 化数据中台产品解决方案的双重服务支撑能力。
数据中台 1.0 – Lambda
早期构建数据中台时,为了优先满足 B 端用户数据整合的需求,以稳定数据输出为出发点,因此我们基于行业中比较成熟的 Lambda 架构形成了数据中台 1.0 。

在数据中台 1.0 架构中分为三层,分别为 Batch Layer,Speed Layer 和 Serving Layer。其中,Batch Layer 用于批量处理全部的数据,Speed Layer 用于处理增量的数据,在 Serving Layer 中综合 Batch Layer 生成的 Batch Views 和 Speed Layer 生成的 Realtime Views,提供给用户查询最终的结果。
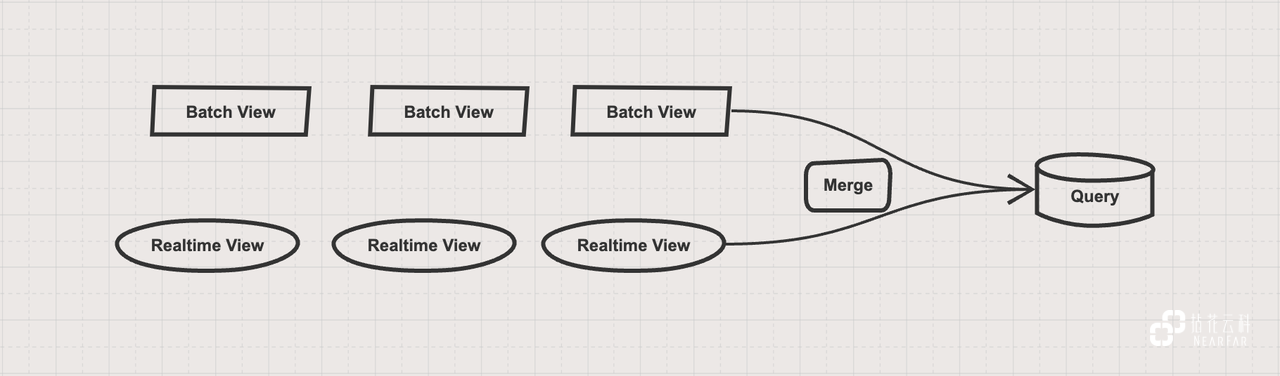
Batch Layer: 在我们早期的实施类项目中,单纯以离线 T+1 进行数据支持的项目占了绝大多数。但实施类项目在实现 Lambda 架构的过程中也会面临很多问题。比如数据采集环节,由于项目本身原因业务系统不能开放 DB 的 Binlog 供数据仓库采集,因此只能以 JDBC 的方式完成增量或全量的数据同步,而通过该方式同步的数据往往会由于系统人工补充数据、时间戳不规范等问题产生同步数据差异的情况发生,最终只能通过额外的数据对比逻辑进行校验,以保证其数据的一致性。
Speed Layer: 项目受成本约束较大,大面积基于流的实时计算对于不论是从硬件成本、部署成本还是实施成本、维护成本等角度均难以支撑。基于该原因,在实施类项目中只有部分业务会进行基于流的实时统计计算,同时满足流计算条件的业务上游系统也必须同时满足同步 Binlog 的使用需求。
Serving Layer: 大部分的预计算结果存储在 MySQL 中提供 Report 支持,部分实时场景通过 Merge Query 对外提供 Ad-Hoc 的查询支持。
随着时间的推移,大量的项目交付使用增多,架构的问题也逐渐开始显现:
- 开发和维护成本高:该架构需要维护两套代码,即批处理和实时处理的代码,这无疑增加了开发和维护的成本。
- 数据处理复杂度高:Lambda 架构需要处理多个层次的数据,包括原始数据、批处理数据和实时处理数据,需要对不同的数据进行清洗、转换和合并,数据处理的复杂度较高。
- 实时计算支持有限:业务方对于数据时效性要求越来越高,但是该架构能力有限,无法支持更多、更高要求的的实时计算。
- 资源利用率低:离线资源较多,但我们仅在凌晨后的调度时间范围内使用,资源利用率不高。
- 受成本制约:该架构对于我们部分用户而言使用成本较高,难以起到降低成本提高效率的作用。
新架构的设计目标
基于以上架构问题,我们希望实现一套更加灵活的架构方案,同时希望新的架构可以满足日益增高的数据时效性要求。在新方案实现之前,我们必须先对当前的业务应用场景和项目类型进行分析。
我们业务应用场景分为以下四类,这四类场景的特点和需求分别是:
- 看板类:包括 Web/移动端数据看板和大屏可视化,用于展示景区重要场所的数据,如业务播报(实时在园人数监控、车船调度管理等)、应急管理监控(客流密度监控、景区消防预警、景区能耗监控等)。其组成特点一般为业务汇总指标和监控指标报警,对数据时效性要求较高。
- 报表类:数据报表以图表形式展示,主要服务于各业务部门的一线业务人员。会更多关注垂直业务的数据覆盖程度,会有钻取需求(也可能通过不同报表来体现不同数据粒度)。一般以景区的业务部门为单位构建报表栏目和分析主题,除财务结算类报表外,一般可接受 T+1 的报表时效。
- 分析类:自助分析基于较好的数据模型表(数据宽表)实现,对分析人员有一定的数据理解和操作需求,基于我们提供的 BI 分析平台,业务人员可基于此数据范围通过拖拽的方式组合出自己的数据结果,灵活度较高。该场景对数据时效要求不高,更多关注业务数据沉淀和与往期历史数据的对比分析侧重架构的 OLAP 能力。
- 服务类:一般对接三方系统,由数据中台提供数据计算结果。如画像标签等数据,通过数据接口控制权限提供对外数据服务与其它业务系统集成,需要新架构能够提供稳定的数据服务。
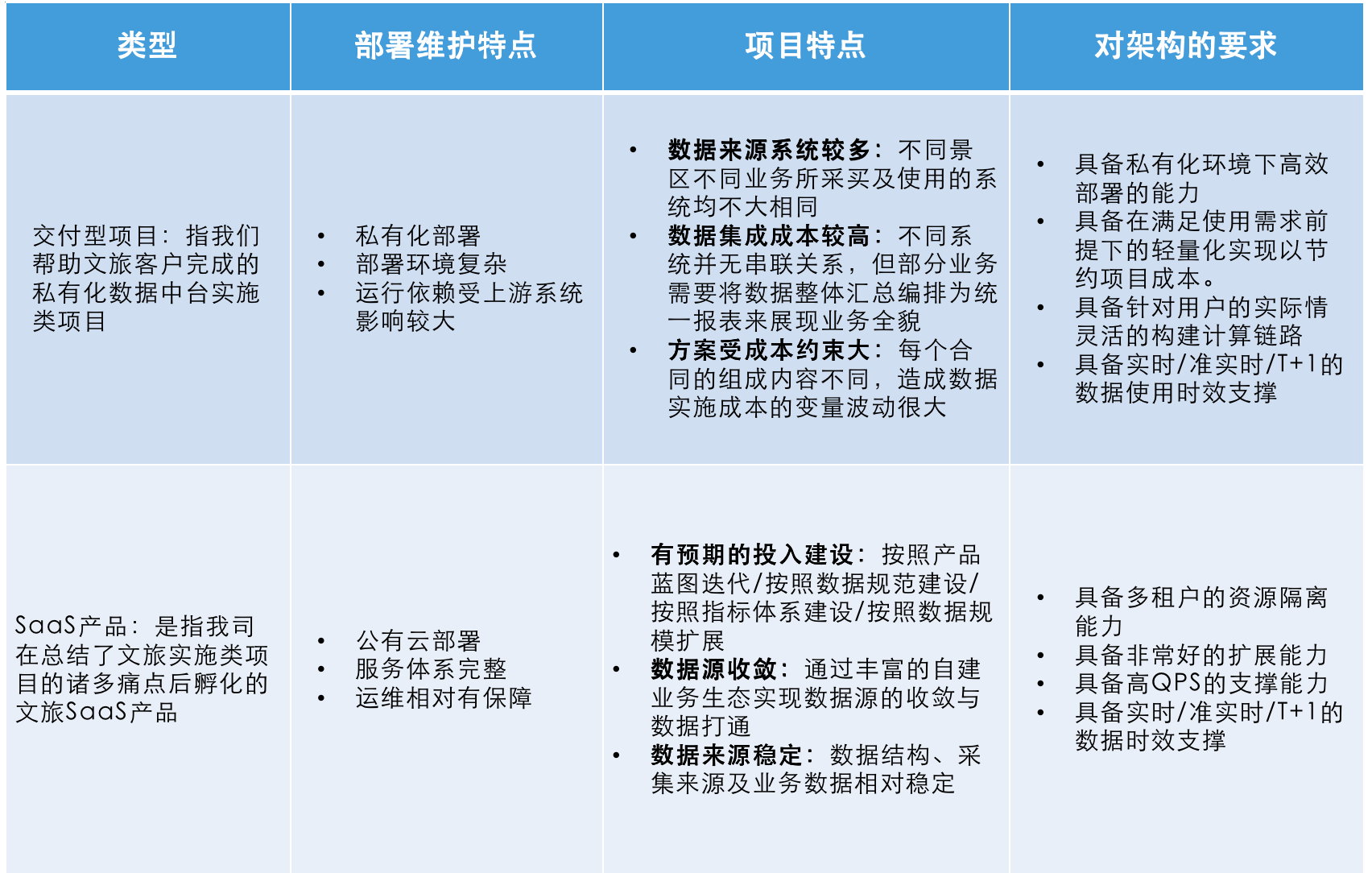
接着我们对项目类型的特点和需求也进行了分析,并确定新架构需要同时提供实施类项目和 SaaS 产品的数据中台支撑能力:
数据中台 2.0 – Apache Doris
结合以上需求,我们计划对原有架构进行升级,并对新架构的 OLAP 引擎进行选型。在对比了 ClickHouse 等 OLAP 引擎后(社区有非常多的对比文章参考,这里不过多赘述),最终选择了 Apache Doris 作为数据中台 2.0 的基座。同时,在数据的同步、集成及计算环节,我们也构建了多套方案来适配以 Apache Doris 为核心的计算链路,以应对不同类型的实施类项目及 SaaS 产品需求。
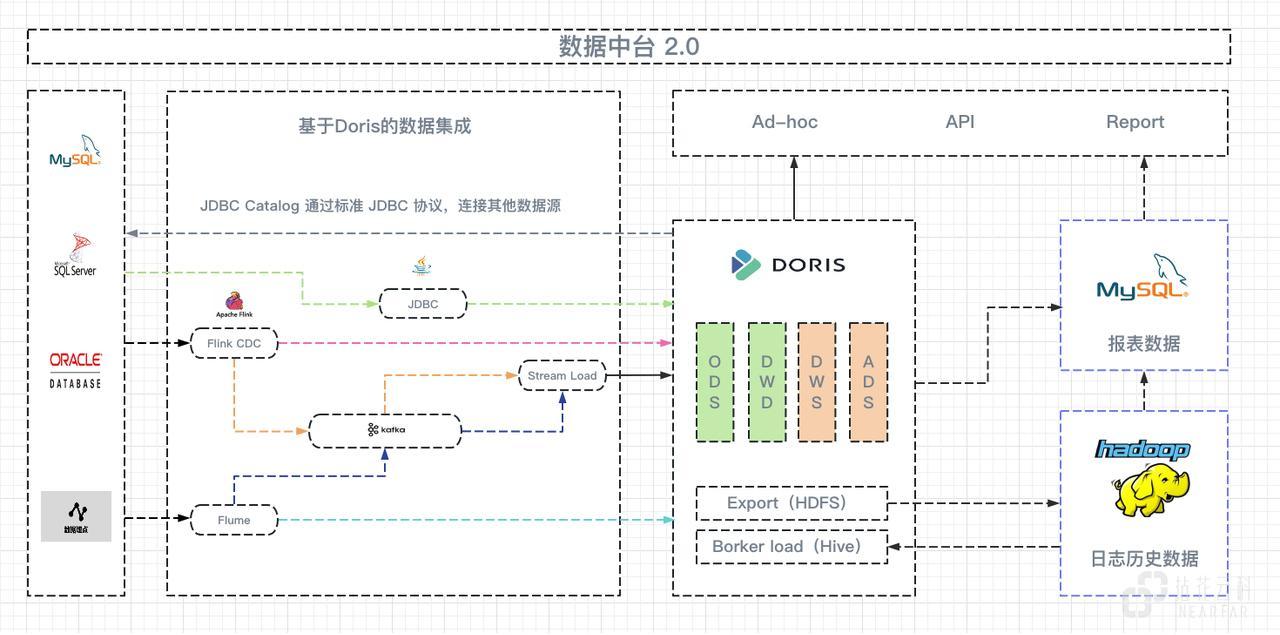
数据中台 2.0 的核心思路是将 Apache Doris 作为核心的数据仓库,并将其作为实时数据同步中心、核心数据计算中心。数据集成环节将专注于数据同步,而计算交由 Apache Doris 完成或由 Doris 辅助计算引擎完成。同时,我们将在提供多种数据同步至 Apache Doris 的方案以应对不同的项目需求。在这个架构下,我们支持实现实时、准实时、T+1 的计算场景支持,以满足不同业务场景的需求。
新架构数据流转:
- 数据同步集成:架构 2.0 有多种数据同步方式,我们主要借助 Doris Unique Key 模型完成数据的同步更新。
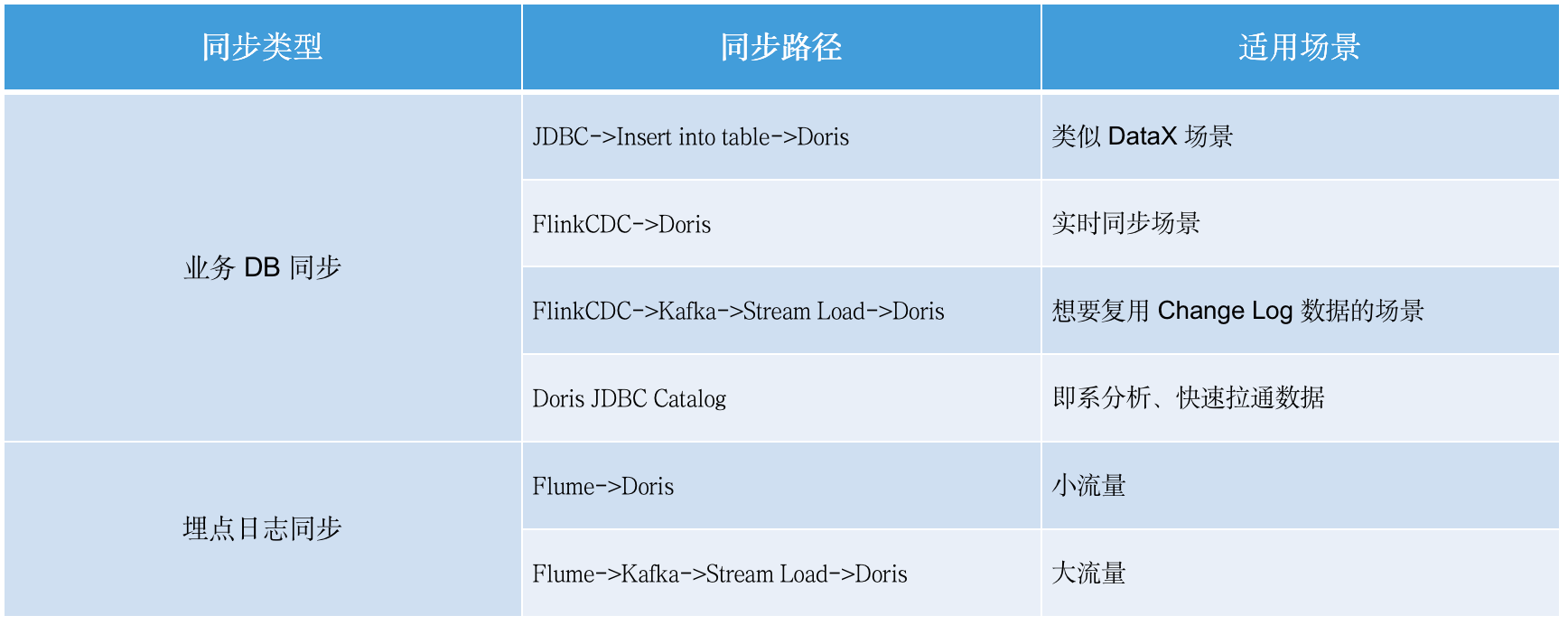
-
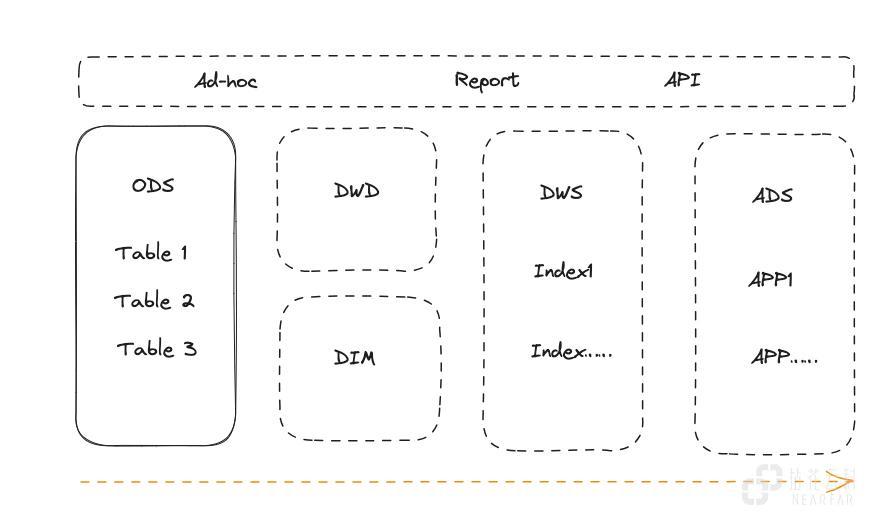
数仓分层计算:根据项目资源情况分 View/实体表单来构建后面的数据层级(DWD、DWS、ADS)。业务较轻或时效性很高时,通过 View 方式来实现逻辑层面的 DWD,通过这种方式为下游 Ad-hoc 提供宽表查询支持,Doris的谓词下推及 View 优化的能力为使用视图查询带来了便利。而当业务较重时,通过实体表单 + 微批任务进行实现,按照调度依赖关系逐层完成计算,针对使用场景对表单进行优化。
-
数据计算时效:新架构下的数据时效受具体数据计算链路中的三个方面限制,分别是数据采集时效、批次计算时效、数据查询耗时。在不考虑网络吞吐、消息积压、资源抢占的情况下:
(实施类项目经常会遇到第三方不提供 Binlog 的情况,所以这里把通过批次采集数据也作为一个 case 列出来)
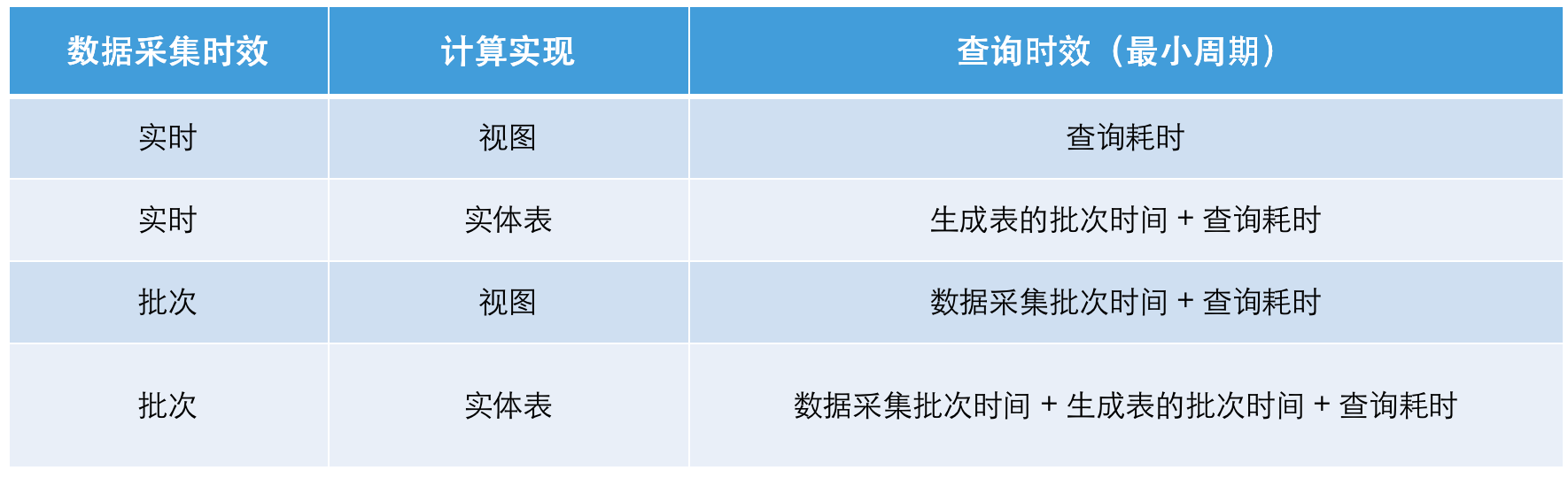
在 Doris 中为了达到更好的计算时效,基于 Doris 的数据计算流程相比在 Hive 中的计算流程可以进行一定的简化,这样可避免过多的冗余计算设计,以此提高计算产出效率。
- 补充架构能力:
- Hadoop:根据不同的项目资源及数据情况来决定是否引入 Hadoop 补充大规模离线计算场景。以实施类项目为例,Doris 可以涵盖大部分核心业务数据计算场景。
- MySQL:基于预计算的结果数据可以推送到下游 MySQL 中以供 Report 查询,从而分散 Doris 计算查询的资源消耗,这样可以将资源充分留给核心且时效性要求高的应用或高频批次任务。如果计算资源充足,Doris 也可以直接作为应用层的加速查询 DB,而无须引入其它 DB。
新架构收益
通过引入 Apache Doris,我们成功构建了高时效、低成本的数据中台 2.0,并成功满足了交付型项目和 SaaS 产品两种需求场景下的使用需求。新架构的收益如下:
- 数据时效性提升:架构 1.0 中大部分业务为 T+1 的支持方式,而在新架构下大部分业务都可实现实时或小时级计算支持。
- 资源利用率提高:在架构 1.0 中,离线资源在白天大部分时间处于闲置状态。而在新架构下,数据同步、计算(增量/全量)和查询均在同一集群下完成,从而提高了资源利用率。相较于部署一套 CDH,同等资源成本下,部署一套 Doris 可以带来更多的收益。
- 运维管理成本降低:在原有架构下,实时统计需求需要维护非常长的计算链路。而在新架构下,所有计算仅需在一个数据库中完成,更加简单、高效且易于维护。
- 易于业务扩展:Doris 的节点扩展操作非常便捷,这对于业务的增量支持非常友好。
新架构的落地实践
我们在 2022 年底首次在测试环境中部署了 Apache Doris 1.1.5 版本,并进行了一些业务数据的导入测试和新架构的可行性验证。在测试后,我们决定在生产环境中落地实践 Apache Doris。第一次生产环境部署时,我们使用了当时最新的 1.2.2 版本。目前,新项目已升级到 1.2.4 版本并使用。Apache Doris 作为新架构下的核心系统,在整个架构中发挥着重要的作用。下面我们将从模型选择、资源规划、表结构同步、计算场景实现、运维保障等几个角度分享我们基于 Doris 的项目落地经验,希望为正在准备落地 Doris 方案的读者带来一些参考。
模型选择
数据模型我们主要应用了 Doris 提供的 Unique 模型和 Aggregate 模型。
Unique 模型
对于 ODS 层的表单来说,我们需要 Doris Table 与源系统数据保持实时同步。为了保证数据同步的一致性,我们采用了 Unique 模型,该模型会根据主键来对数据进行合并。在 1.2.0 版本之前,Unique 模型是 Aggregate 模型的一种特例,使用了 Merge On Read 的实现方式,这种实现方式下 count(*)的查询效率较低。而在 1.2.0 版本推出之后,采用了新的 Merge On Write 的数据更新方式,在 Unique Key 写入过程中,Doris 会对新写入的数据和存量数据进行 Merge 操作,从而大幅优化查询性能。在 Merge 过程中,Doris 会查找 Unique Key 索引,并使用 Page Cache 来优化索引查找效率。因此在使用 1.2 版本中,建议打开 Doris BE 的 Page Cache(在 be.conf文件中增加配置项 disable_storage_page_cache = false)。另外在很多情况下,Unique 模型支持多种谓词的下推,这样表单也可以支持从源表直接建立视图的查询方式。
Aggregate 模型
在某些场景下(如维度列和指标列固定的报表查询),用户只关心最终按维度聚合后的结果,而不需要明细数据的信息。针对这种情况,我们建议使用 Aggregate 模型来创建表,该模型以维度列作为 Aggregate Key 建表。在导入数据时,Key 列相同的行会聚合成一行(目前 Doris 支持 SUM、REPLACE、MIN、MAX 四种聚合方式)。
Doris 会在三个阶段对数据进行聚合:
- 数据导入的 ETL 阶段,在每一批次导入的数据内部进行聚合;
- 底层 BE 进行数据 Compaction 的阶段;
- 数据查询阶段。
聚合完成之后,Doris 最终只会存储聚合后的数据,这种明细表单数据的预聚合处理大大减少了需要存储和管理的数据量。当新的明细数据导入时,它们会和表单中存储的聚合后的数据再进行聚合,以提供实时更新的聚合结果供用户查询。
资源管理
在生产环境中,我们使用一套 Doris 数据仓库支撑了多个下游数据应用系统的使用。这些应用系统对数据访问的资源消耗能力不同,对应的业务重要等级也不相同。为了能够更好管理应用资源的使用,避免资源冲突,我们需要对应用账号进行划分和资源规划,以保证多用户在同一 Doris 集群内进行数据操作时减少相互干扰。而 Doris 的多租户和资源隔离功能,可以帮助我们更合理地分配集群资源。Doris 对于资源隔离控制有两种方式,一是集群内节点级别的资源组划分,二是针对单个查询的资源限制。这里主要介绍下集群内节点级别的资源组划分过程。
第一步:需要梳理规划各场景的用途、重要等级及资源需求等,举例说明:
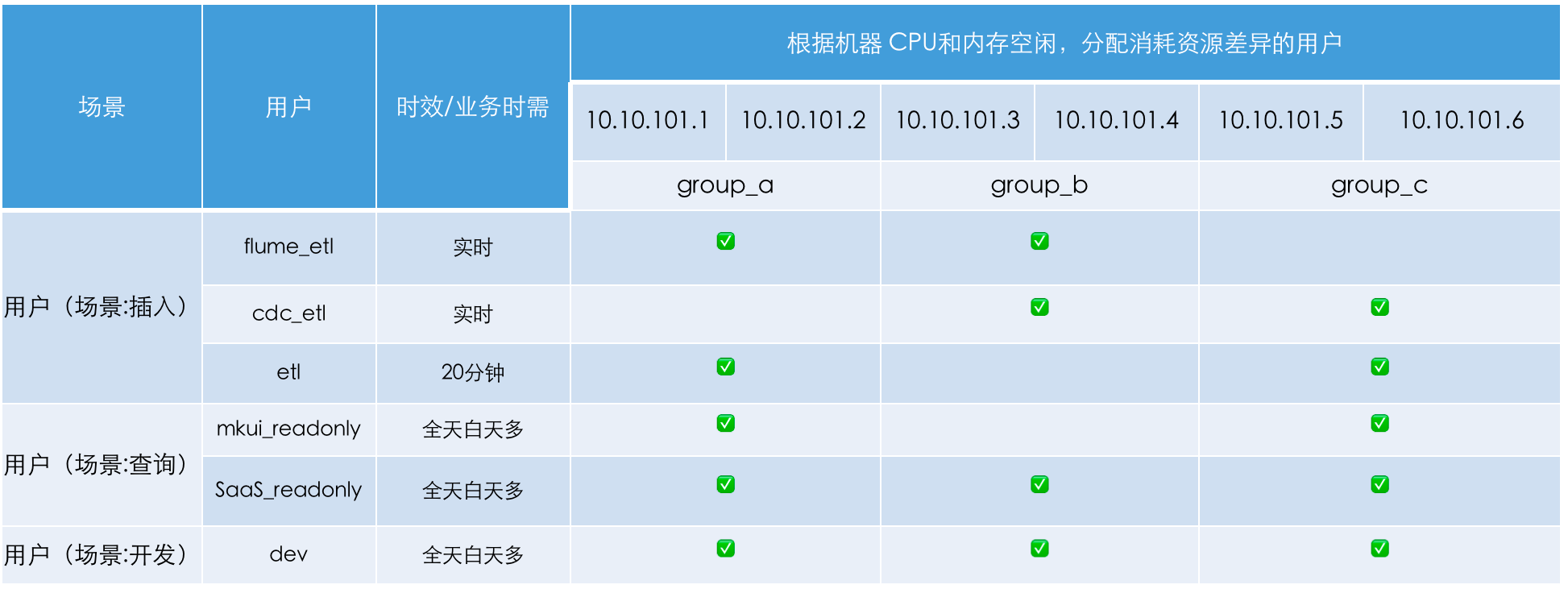
第二步:对节点资源进行划分、给节点打上 tag 标签:
alter system modify backend "10.10.101.1:9050" set ("tag.location" = "group_a");
alter system modify backend "10.10.101.2:9050" set ("tag.location" = "group_a");
alter system modify backend "10.10.101.3:9050" set ("tag.location" = "group_b");
alter system modify backend "10.10.101.4:9050" set ("tag.location" = "group_b");
alter system modify backend "10.10.101.5:9050" set ("tag.location" = "group_c");
alter system modify backend "10.10.101.6:9050" set ("tag.location" = "group_c");
第三步:给应用下的表单指定资源组分布,将用户数据的不同副本分布在不同资源组内
create table flume_etl(k1 int, k2 int) distributed by hash(k1) buckets 1 properties( "replication_allocation"="tag.location.group_a:2, tag.location.group_b:1" ) create table cdc_etl
``` "replication_allocation"="tag.location.group_b:2, tag.location.group_c:1" create table etl
``` "replication_allocation"="tag.location.group_a:1, tag.location.group_c:2" create table mkui_readonly
``` "replication_allocation"="tag.location.group_a:2, tag.location.group_c:1" create table SaaS_readonly
``` "replication_allocation"="tag.location.group_a:1, tag.location.group_b:1, tag.location.group_c:1" create table dev
``` "replication_allocation"="tag.location.group_a:1, tag.location.group_b:1, tag.location.group_c:1"
第四步:设置用户的资源使用权限,来限制某一用户的查询只能使用其指定资源组中的节点来执行。
set property for 'flume_etl' 'resource_tags.location' = 'group_a'; set property for 'cdc_etl' 'resource_tags.location' = 'group_b'; set property for 'etl' 'resource_tags.location' = 'group_c'; set property for 'mkui_readonly' 'resource_tags.location' = 'group_a'; set property for 'SaaS_readonly' 'resource_tags.location' = 'group_a, group_b, group_c'; set property for 'dev' 'resource_tags.location' = 'group_b';值得一提的是,与社区交流中我们得知在即将发布的 Apache Doris 2.0 版本中还基于 Pipeline 执行引擎增加了 Workload Group 能力。该能力通过对 Workload 进行分组管理,以保证内存和 CPU 资源的精细化管控。通过将 Query 与 Workload Group 相关联,可以限制单个 Query 在 BE 节点上的 CPU 和内存资源的百分比,并可以配置开启资源组的内存软限制。当集群资源紧张时,将自动 Kill 组内占用内存最大的若干个查询任务以减缓集群压力。当集群资源空闲时,一旦 Workload Group 使用资源超过预设值时,多个 Workload 将共享集群可用空闲资源并自动突破阙值,继续使用系统内存以保证查询任务的稳定执行。更详细的 Workload Group 介绍可以参考:https://doris.apache.org/zh-CN/docs/dev/admin-manual/workload-group/
create workload group if not exists etl_group properties ( "cpu_share"="10", "memory_limit"="30%", "max_concurrency" = "10", "max_queue_size" = "20", "queue_timeout" = "3000" );批量建表
初始化完成 Doris 的建表映射往往需要构建许多表单,而单独建表低效且易出错。为此,我们根据官方文档的建议使用 Cloudcanal 进行表结构同步来批量建表,大大提高了数据初始化的效率。
建表时需要注意的是:以 MySQL 为例,MySQL 数据源映射到 Doris 表结构的过程中需要进行一定的表结构调整。在 MySQL 中
varchar(n)类型的字段长度是以字符个数来计算的,而 Doris 是以字节个数计算的。因此,在建表时需要将 Doris varchar 类型字段的长度调整到 MySQL 对应字段长度的 3 倍。在使用 Unique 模型时需要注意建表时 UNIQUE KEY 列要放在 Value 列前面声明,且保证有序排列和设置多副本配置。
除了以上方式,日前新发布的 Doris-Flink-Connector 1.4.0 版本中已集成了 Flink CDC、实现了从 MySQL 等关系型数据库到 Apache Doris 的一键整库同步功能,用户无需提前在 Doris 中建表、可以直接使用 Connector 快速将多个上游业务库的表结构及数据接入到 Doris 中。推荐大家尝试使用。相关链接:https://mp.weixin.qq.com/s/Ur4VpJtjByVL0qQNy_iQBw
计算实现
根据我们对架构 2.0 的规划,我们将所有计算转移在 Doris 中完成。然而在支撑实时和准实时的场景下,具体的技术实现会有所不同,主要区别如下:
实时计算
如上文提到我们会以实时数据采集 + Doris 视图模型的方式提供实时计算结果,而为了在计算过程中达到更高的数据时效支持,应该尽量减少不必要的数据冗余设计。如传统数据仓库会按照 ODS->DWD->DWS->ADS 等分层逐层计算落表。而在实时计算场景下可以适当进行裁剪,裁剪的依据为整体查询时效的满足情况。此外,在实际的业务场景中也会有多层视图嵌套调用的情况。
准实时计算
在业务能接受的准实时场景下(10分钟、30分钟、小时级),可以通过实体表单 + 微批任务实现计算,计算过程按照调度层级依赖关系逐层完成。
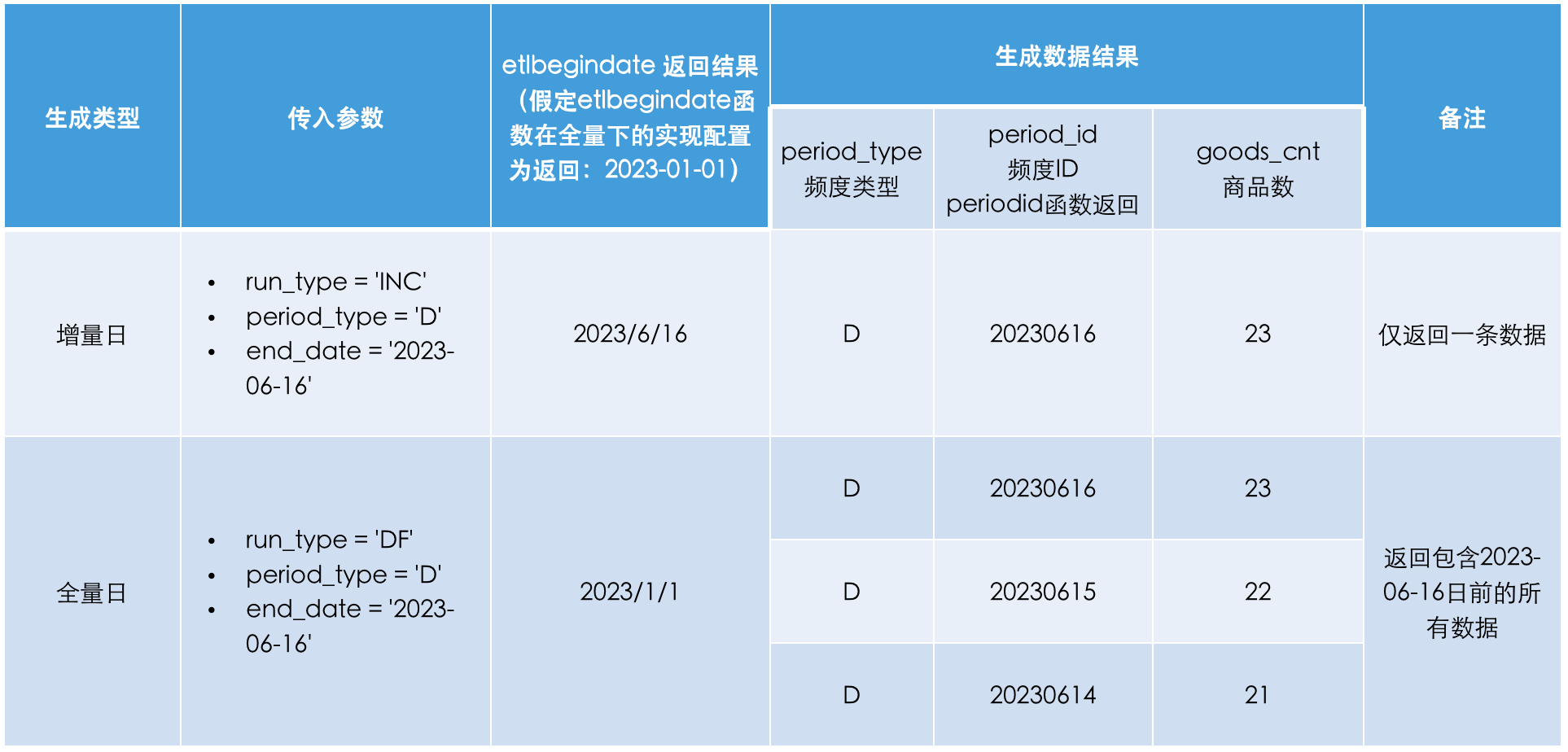
通过 Java UDF 生成增量/全量数据
在实际业务中,存在增量/全量的日、月、年等不同时间频度数据生成需求。我们通过 Doris 的 Java UDF 功能(1.2 版本后支持) + 调度系统传参的方式实现了一套脚本动态的生成增量/全量及日、月、年等不同的指标汇总。
实现思路:
period_type:计算频度 D/W/M/Y 代表计算日、周、月、年
run_type:INC(增量)/ DF(全量)是通过传递begin_date,end_datel来筛选business_date数据进行汇总。
- 增量满足:
begin_date(对应计算频度开始日期)
- 全量满足:
begin_date(写死一个业务最小日期)
基于以上思路实现
etlbegindate函数来返回不同计算频度下增量、全量的begin_dateetlbegindate(run_type,period_type,end_date)为了在统计不同频度时能够生成对应频度的识别
id字段,我们还需要实现一个periodid函数periodid(period_type,business_date)该函数的主要功能为:
- period_type = 'D' 返回 business_date 所在日, 'YYYYMMDD' 格式的 period_id 字段
- period_type = 'W' 返回 business_date 所在周的起始日期, 'YYYYMMDDYYYYMMDD' 格式的 period_id 字段
- period_type = 'M' 返回 business_date 所在月,'YYYYMM' 格式的 period_id 字段
- period_type = 'Y' 返回 business_date 所在年,'YYYY' 格式的 period_id 字段
结合
etlbegindate与periodid两个函数,假定当前时间为 2023 年 6 月 16 日则相应的实现如下:SQL 脚本使用函数示例
-- 示例Demo select ${period_type} as period_type -- 统计频度 D/W/M/Y ,period_id(${period_type},business_date) as period_id -- 时间频度ID ,count(goods_id) as goods_cnt -- 商品数 where business_date >= etlbegindate(${run_type},${period_type},${end_date}) and business_date运行调度前参数配置:
任务运行结果示例:W/M/Y 是的实现方式一致,只是数据返回的
period_id格式会按照上文描述的格式输出。
基于以上方法,我们高效地为公司 SaaS 产品构建了相应的数据指标库应用。
基于 Doris 的大表优化
我们的业务涉及基于用户页面访问和景区设备日志信息的统计分析业务,这类指标计算需要处理大量日志数据。接下来,我们将介绍如何利用 Doris 提供的功能对数据进行优化处理。
数据分区分桶:
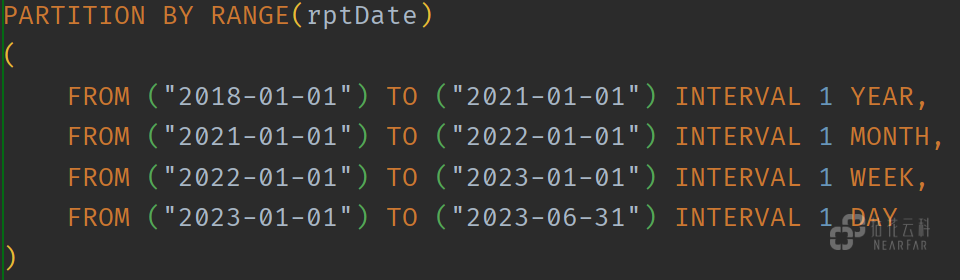
Doris 支持两级分区,第一级叫做 Partition,支持 Range Partitioning 和 List Partitioning 两种分区策略。第二级分区叫做 Bucket,支持 Hash Partitioning 分区策略。
对于用户浏览行为的埋点事件表,我们按照时间做为分区(Range Partitioning):
在实际应用中,业务的历史冷数据可以按年进行分区,而近期的热数据可以根据数据量增幅按照日、周、月等进行分区。另外,Doris 自 1.2.0 版本后支持批量创建 RANGE 分区,语法简洁灵活。
从 Doris 1.2.2 版本开始,Doris 支持了自动分桶功能,免去了在分桶上面的投入,一个分桶在物理层面为一个 Tablet,官方文档建议 Tablet 大小在 1GB - 10GB 之内,Y因此对于小数据量分桶数不应太多。自动分桶的开启只需要建表时新增一个属性配置:
DISTRIBUTED BY HASH(openid) BUCKETS AUTO PROPERTIES ("estimate_partition_size" = "1G")Like Query 和 SEQUENCE_COUNT 介绍
Like Query
在使用埋点日志数据进行漏斗分析时,需要针对某些特定 URL 数据进行汇总分析。这些 URL 中带有参数信息,以 String 或者 Varchar 类型存储为例,在计算过程中需要对含有特定参数的数据进行筛选。
根据该 Issue:https://github.com/apache/doris/pull/10355,我们了解到 Doris 对于 like/not like 有一定的优化处理,操作符可以下推到存储引擎进行数据过滤。因此在这个场景下,我们尝试使用 like 操作符对数据进行筛选处理。
另外在 Apache Doris 2.0 版本中将增加 Ngram BloomFilter 索引,使用该索引可以用来提升 Like Query 的性能,未我们也将进行升级使用。Doris 提供了
gram_size和bf_size两个参数进行配置,示例如下:CREATE TABLE `test_ngrambf` ( `id` int(11), `str` varchar(32), INDEX idx_str (`str`) USING NGRAM_BF PROPERTIES("gram_size"="3", "bf_size"="256") ) ENGINE=OLAP DUPLICATE KEY(`id`) DISTRIBUTED BY HASH(`id`) BUCKETS 10 PROPERTIES ( "replication_num" = "1" ); mysql> INSERT INTO test_ngrambf VALUES (1, 'hello world'), (2, 'ngram test'); Query OK, 2 rows affected (0.18 sec) {'label':'insert_fbc5d3eca7204d52_965ce9de51508dec', 'status':'VISIBLE', 'txnId':'11008'} mysql> SELECT * FROM test_ngrambf WHERE str LIKE '%hel%'; +------+-------------+ | id | str | +------+-------------+ | 1 | hello world | +------+-------------+ 1 row in set (0.03 sec) mysql> SELECT * FROM test_ngrambf WHERE str LIKE '%abc%'; Empty set (0.02 sec) mysql> SELECT * FROM test_ngrambf WHERE str LIKE '%llm%'; Empty set (0.04 sec)下面对 Ngram BloomFilter 索引的原理作简要介绍:
假如将
“hello world"存入 Bloom Filter 中,将gram_size配置为 3,这时会将"hello world"分为["hel", "ell", "llo",...]分别进行存储,每个 gram 通过 N 个哈希函数 h1, h2, ..., hn 映射到 Bloom Filter中,对应的索引值设为 1。当处理where column_name like 'hel'这样的查询语句时,'hel'会经过相同哈希函数的映射和 Bloom Filter 进行比较,如果映射出的索引和 Bloom Filter 的索引的值都是 1,那么判断'hel'在Bloom Filter 中(True Positive),但也存在一定概率会将本来不在 Bloom Filter 中的元素判断为在集合中(False Positive),比如上图中的'llm',但将其判断为不在 Bloom Filter 中的元素(True Negative)一定不会存在,比如图中的过滤条件like 'abc'。在实际使用 Ngram BloomFilter 索引时有一些注意事项:
- 使用 Ngram BloomFilter 索引时需要根据实际查询情况合理配置
gram_size的大小。小的gram_size支持搜索查询更多的 String,但是同时也带来更多数量的 ngram 和需要应用更多的哈希函数,这将会增大 False Positive 的概率。- 因为存在 False Positive 的可能性,Ngram BloomFilter 索引不能被用来处理
column_name != 'hello'或者column_name not like '%hello%'这样使用负运算符的过滤条件。SEQUENCE_COUNT
针对用户留存或漏斗分析等指标的计算,可以使用 Doris 提供的
SEQUENCE_COUNT(pattern, timestamp, cond1, cond2, ...)函数。这里pattern参数用来指定用户一系列浏览行为的事件链,比如:-- 计算用户浏览商品、加入购物车以及支付这一连串事件的数量 SELECT SEQUENCE_COUNT('(?1)(?2)(?3)', timestamp, event = 'view_product', event = 'add_cart', event = 'pay') FROM user_event;通过
SEQUENCE_COUNT可以非常方便地计算我们指定的事件链的数量。Doris Borker 的协同计算
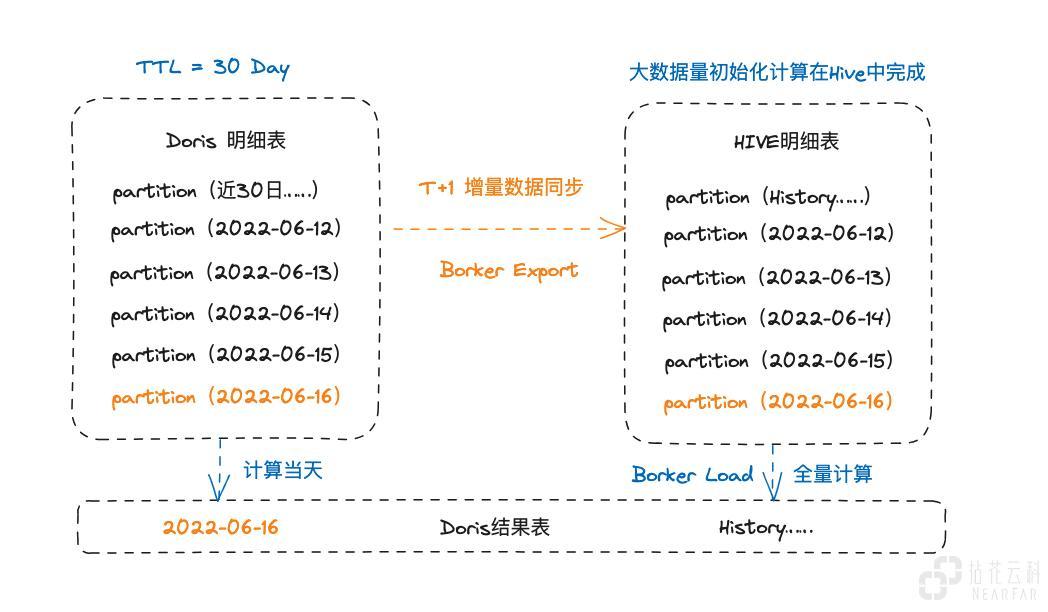
业务中存在部分大数据量的历史数据统计需求,针对这部分需求我们进行了协同计算处理
- FlinkCDC 读取 Binglog 实时同步数据到 Doris 明细表
- Doris 明细表会存储近 30 日热数据(需要进行 TTL 管理)
- Doris 每日通过 Borker Export 同步一份日增量数据至 HDFS,并加载至 Hive 中
- Hive 中储存所有明细数据,数据初始化生成计算结果在 Hive 中完成 Borker Load 至 Doris
- Doris 在生成结果数据时仅生成当前日期数据,每天的增量生成沉淀为历史结果
- 当业务有需要时通过 Borker Export 加载 Hive 全量计算结果刷新 Doris 结果表
- 当业务有基于此明细数据的新开发需求时,可在 Hive 中计算完成初始化结果至 Doris
数据导出(Export): Export 是 Doris 提供的一种将数据导出的功能。该功能可以将用户指定的表或分区的数据以文本的格式,通过 Broker 进程导出到远端存储上,如 HDFS 或对象存储(支持 S3 协议) 等。用户提交一个 Export 作业后,Doris 会统计这个作业涉及的所有 Tablet,然后对这些 Tablet 进行分组,每组生成一个特殊的查询计划。这些查询计划会读取所包含的 Tablet 上的数据,然后通过 Broker 将数据写到远端存储指定的路径中。
数据导入(Broker load): Broker Load 是 Doris 的一种异步数据导入方式,可以导入 Hive、HDFS 等数据文件。Doris 在执行 Broker Load 时占用的集群资源比较大,一般适合数据量在几十到几百 GB 级别下使用。同时需要注意的是单个导入 BE 最大的处理量为 3G,如果超过 3G 的导入需求就需要通过调整B roker Load 的导入参数来实现大文件的导入。
联邦查询在数据分析场景下的尝试
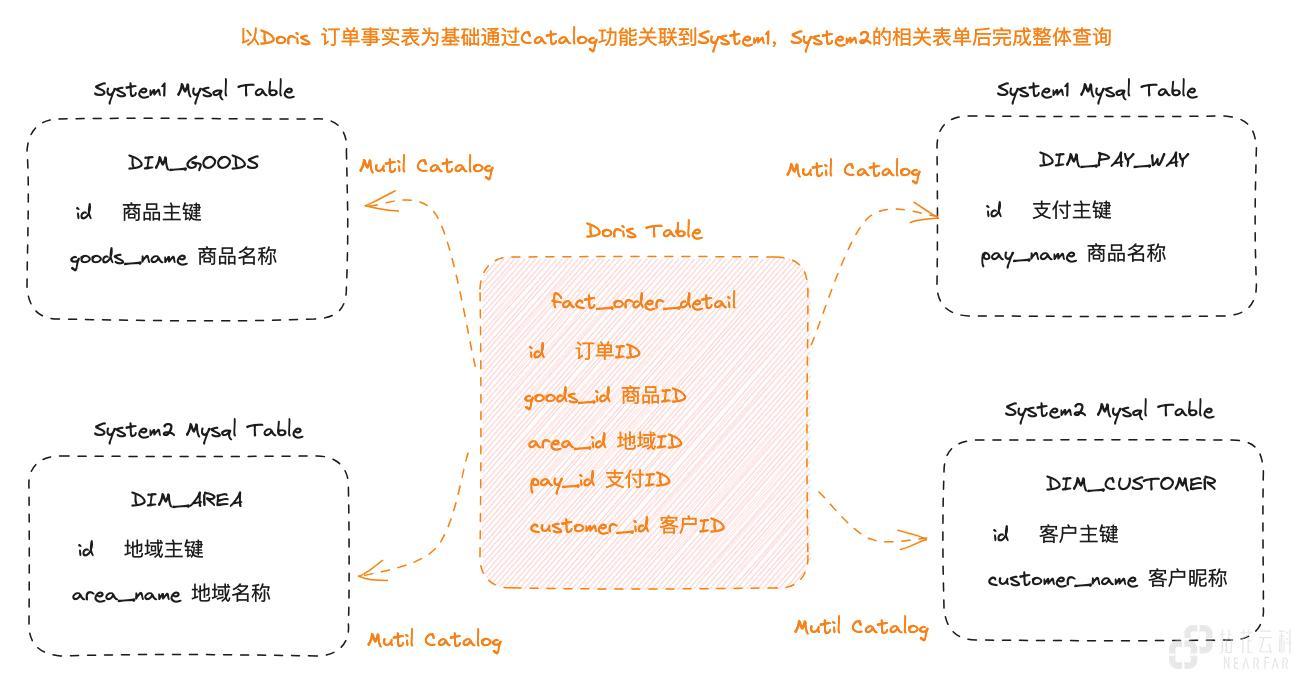
由于上游数据源较多,我们仅对常用的数据表单进行了数据仓库采集建模,以便更好地进行管理和使用。对于不常用到的数据表单,我们没有进行入仓,但业务方有时会临时提出未入仓数据的统计需求,针对这种情况,我们可以通过 Doris 的 Multi-Catalog 进行快速响应、完成数据分析 ,待需求常态化后再转换成采集建模的处理方式。
Multi-Catalog 是 Doris 1.2.0 版本中推出的重要功能。该功能支持将多种异构数据源快速的接入 Doris,包括 Hive、Iceberg、Hudi、MySQL、Elasticsearch 和 Greenplum 等。使用 Catalog 功能,可以在 Doris 中统一的完成异构数据源之间的关联计算。Doris 1.2.0 以后的版本官方推荐通过 Resource 来创建 Catalog,这样在多个使用场景下可以复用相同的 Resource。下面是 Doris 本地表与通过 Multi-Catalog 映射的远程表单组合完成关联计算的场景示例。
Multi-Catalog 带来的收益:
- 更高的灵活性:通过 Multi-Catalog,用户可以灵活地管理不同数据源的数据,并在不同的数据源之间进行数据交换和共享。这可以提高数据应用的可扩展性和灵活性,使其更适应不同的业务需求。
- 高效的多源管理:由于 Multi-Catalog 可以管理多个数据源,用户可以使用多个 Catalog 来查询和处理数据,解决了用户跨库访问不便的问题,从而提高数据应用的效率。
社区中已经有非常多的伙伴基于 Multi-Catalog 功能落地了应用场景。另外如果要深度使用该功能,建议建立专门用于联邦计算的 BE 节点角色,当查询使用 Multi-Catalog 功能时,查询会优先调度到计算节点。
运维保障
守护进程
为了保障 Doris 进程的持续运行,我们按照 Doris 官网的建议在生产环境中将所有实例都的守护进程启动,以保证进程退出后自动拉起。我们还安装部署了Supervisor 来进行进程管理,Supervisor 是用 Python 开发的一套通用的进程管理程序,可以将一个普通的命令行进程变为后台 Daemon 并监控进程状态,当进程异常退出时自动重启。使用守护进程后,Doris 的进程变成了 Supervisor 的子进程,Supervisor 以子进程的 PID 来管理子进程,并可以在异常退出时收到相应的信号量。
配置 Supervisor 时的注意事项:
- 通过
supervisorctl status查询出来的进程 id 不是 Fe、Be、Broker 的进程 ID,而是启动它们的 Shell 进程 ID。在start_xxx.sh中会启动真正的 Doris 进程,因此才有了进程树的说法。stopasgroup=true ;是否停止子进程、killasgroup=true ;是否杀死子进程,需要保证这两个参数为true,否则通过supervisorctl控制 Doris 的后台进程是无效的,这也是通过 Supervisor 守护 Doris 进程的关键。配置完 Supervisor 后则通过守护进程的方式来管理 FE、BE、Borker……
由于 Superviosr 自带的 Web UI 不支持跨机器管理,当多节点时管理非常不便,这里可以使用 Cesi 来对 Supervisor 进行合并管理:
Grafana 监控报警
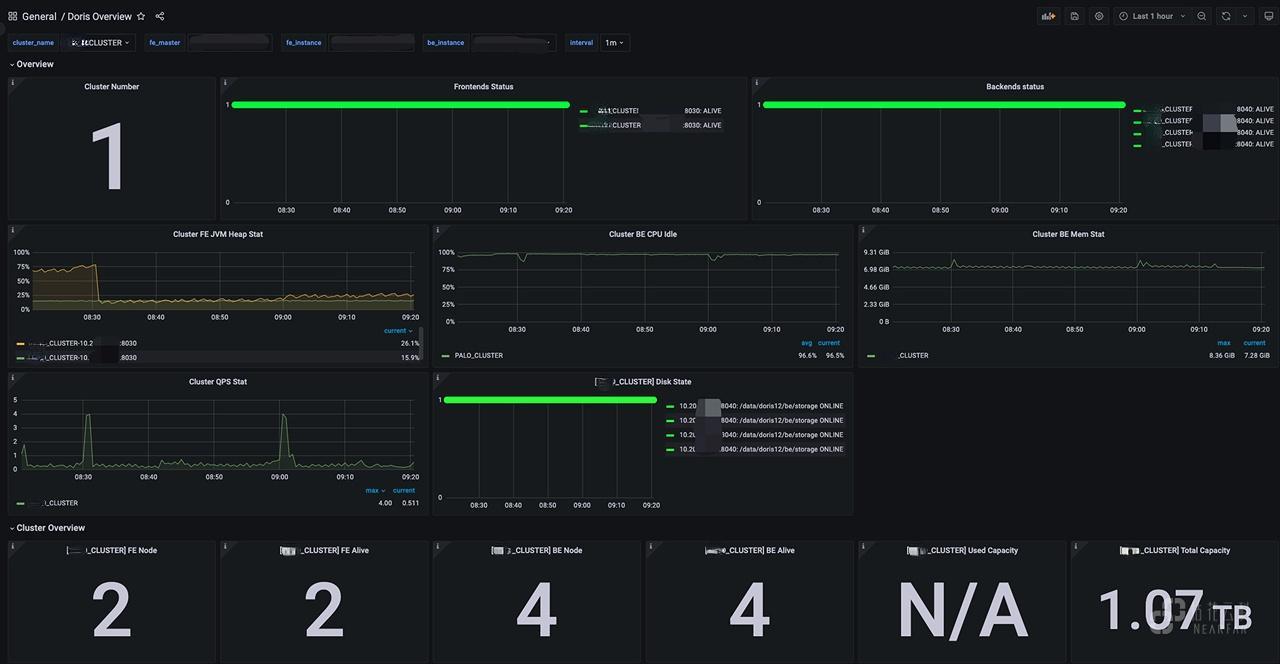
关于 Doris 的运行监控,我们按照官网相关内容部署了 Prometheus 和 Grafana ,并进行监控项的采集。同时对于一些关键指标进行了预报警,利用企微 Bot 完成信息推送。
以下为测试环境示例图:
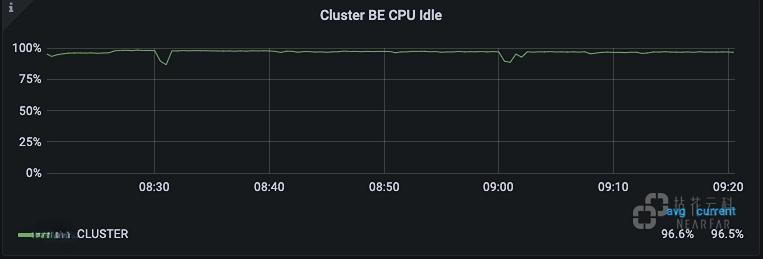
集群CPU空闲情况:
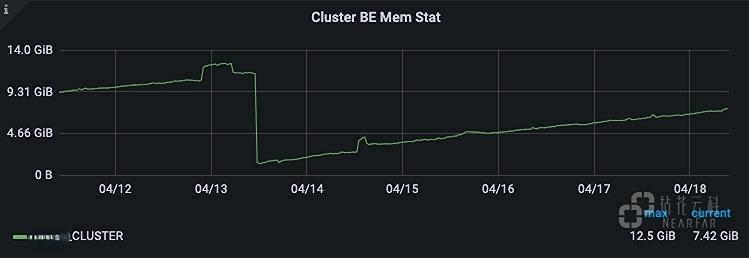
集群内存使用情况: 之前发现集群存在内存泄露
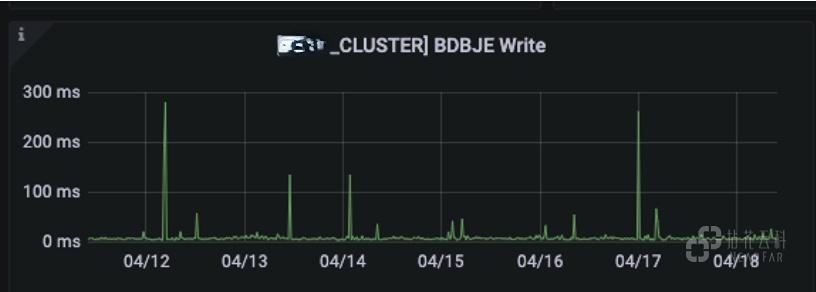
BDBJE 写入情况: 超过秒级可能会出现元数据写入延迟的问题
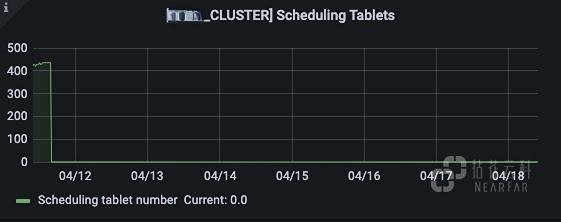
开始调度运行的 Tablet 数量: 正常情况该值基本为 0 或个位数,出现波动的 Tablet 说明可能在进行 Recovery 或 Balance。
除此之外,我们还使用 QPC/99th Latency……等指标来查看监测集群服务能力,建议可以在 Doris 监控的基础上额外加入集群机器的监控,因为我们的机器部署在VM中,曾经出现过硬盘问题、内存问题、网络波动、专线异常等情况,多一层报警机制就多一份稳定性保障。
总结收益
通过新架构的成功搭建,实现了以 Apache Doris 为核心数据仓库 + OLAP 引擎的使用方式(All in One),有效缩减了数据处理流程,大大降低了投递型项目的实施成本。在旧架构下,需要部署、适配、维护非常多的组件,无论是实施还是运维都会比较繁重。相比之下,新架构下的 Doris 易于部署、扩展和维护,组合方案也灵活多变。在我们近半年的使用时间内,Doris 运行非常稳定,为项目交付提供了强有力的计算服务保障能力。
此外,基于 Apache Doris 丰富的功能、完善的文档,我们可以针对离线和在线场景进行高效且细致的数据开发和优化。通过引入 Doris 我们在数据服务时效性方面也有了大幅提高,当前我们已经成功地落地了多个数据项目,并孵化出了一个基于 Doris 的 SaaS 产品。同时,Doris 拥有一个成熟活跃的社区,SelectDB 技术团队更是为社区提供了一支全职的技术团队,推动产品迭代、解决用户问题,也正是这强有力的技术支持,帮助我们更快上线生产,快速解决了我们在生产运用中遇到的问题。
未来规划
未来,我们将密切关注 Apache Doris 社区的发展,并计划构建基于 K8S 的 Doris 服务方式。在项目交付场景下,常常需要进行整套环境的部署。目前,我们已经在 K8S 上集成了 2.0 版本架构下除 Doris 以外的其他数据服务组件。随着 Doris 社区 2.0 版本全面支持 K8S 的计划,我们也会将方案集成到我们的新体系中,以方便后期的项目投递。除此之外,我们还将结合 Doris 的功能特性提炼基于 Doris 的数仓方法论,优化开发过程。Doris 是一个包容性非常好的存储计算引擎,而想要将原有的数据仓库开发内容全部适配在 Doris 上还需要不断的学习、优化与调整,以充分发挥 Doris 的优势,同时我们也将在此基础上沉淀一套与之相匹配的开发规范。
最后,我非常推荐大家使用 Apache Doris 作为数据项目的解决方案。它具有功能强大、包容性强、社区活跃、迭代更新快等优势,这些优势将助推你的项目达成目标。在此,我要感谢 Apache Doris 社区和 SelectDB 的同学们给予我们的支持和帮助,也祝愿 Apache Doris 社区越来越壮大。
© 著作权归作者所有
举报其他人还在看
更多精彩内容Antrea v1.12.1 发布,Kubernetes 网络解决方案BeetlSQL 3.23.4 发布,Oracle12 优化全球桌面浏览器市场份额排名,Safari 继续稳坐第二开源即时通讯应用 Tailchat v1.8.2 已发布, 插件化分布式 noIM 应用Linux 6.5 添加对 USB4 v2 协议的初始支持红帽为 RHEL 7 提供长达 4 年的延长生命周期支持JS 网页全自动翻译 v2.4 发布,增加TCDN翻译分发能力jar-protect —— Jar 包加壳工具Gitee 推荐 | HTAP 数据库基准测试工具 HyBench每日一博 | 图文结合带你搞懂 GreatSQL 体系架构OpenZFS 合并新 PR:Block CloningMatrixOne 0.8.0 开放公测,新一代超融合异构数据库开源实时监控 HertzBeat v1.3.2 发布, 更稳定更易用NineData 成为百度智能云主推的数据库工具Kiwi TCMS 12.5 发布,开源测试管理系统数据采集 ETL & 流批一体化框架 bboss v7.0.2 发布Jeepay v2.2.0 正式发布:一套完整的开源聚合支付系统Canonical 获得 LXD 的控制权谷歌更新隐私政策,未来将使用公共数据来训练其 AI推特的开源替代品 Mastodon 推出大力优化的 Android 应用# 文盘Rust -- tokio绑定cpu实践TICDC 数据同步至 MySQL初体验PostgreSQL 每周新闻 2023-5-31全球首发 | 《NGINX 完全指南》中文版浪潮 KaiwuDB x 大数据中心 | 数据驱动政府治理能力快速提升安全事件周报 2023-05-22 第21周PostgreSQL 每周新闻 2023-6-21Zilliz @ GOTC:大模型的记忆体——向量数据库的现在与未来安全日报(2023.06.12)Discovery Holdings 探索没有复杂性的多云机会7月8日活动|大语言模型时代,AI infra 长什么样?在 Debian 12 上安装 KubeSphere 实战入门得物App万米高空WiFi拦截记加入 " openEuler Call for X 计划",释放无限潜力!《开源工业软件白皮书—CAE软件集成框架》正式发布!KaiwuDB 受邀出席大型企业数字化转型峰会暨工赋山东济南峰会并发表演讲活动报名·南京 | openEuler高效运维交流专场,6月2日线下见!Last Week in Milvus安全日报(2023.06.29)热门评论
.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}F我根本没有用过MIPS架构,所以你一上来就让我多读书,说我无知,我只能认为你没素质,你可以说这不是一个东西,你还动不动就笑死了,来体现自己有多厉害,我也笑死了,我一点都不急,急得是你.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 这篇文章的核心关键点:无论是否基于 uni-app 开发,只要 App 的源码中包含安装 APK 的代码,即使采用原生开发,都会被 Google Play 下架。
这篇文章的核心关键点:无论是否基于 uni-app 开发,只要 App 的源码中包含安装 APK 的代码,即使采用原生开发,都会被 Google Play 下架。.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 不错啊,神奇的项目
不错啊,神奇的项目.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
岁靠嘴进入第一梯队吧.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 AI吹牛第一梯队
AI吹牛第一梯队.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 小问题?法盲吧?违反了《隐私保护法》和别人的肖像权了好吧?平台居然还有法盲…
小问题?法盲吧?违反了《隐私保护法》和别人的肖像权了好吧?平台居然还有法盲….comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 谷歌这简直就是霸凌啊
谷歌这简直就是霸凌啊.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
E我们为啥发展慢,明白了吧.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 这是什么游戏
这是什么游戏.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
感谢小米提供的资金和技术。.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 尬吹第一梯队?
尬吹第一梯队?.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 最重要的是,被坑的人只能忍了!认了!作为google政策变更前应当给一些时间让开发者自查修正。作为DCloud应当有风险意识给出说明和解决方法。但是他们都没有做。最后开发者辛苦积攒的成就被弄丢了!而且他们也不会做出任何赔偿!
最重要的是,被坑的人只能忍了!认了!作为google政策变更前应当给一些时间让开发者自查修正。作为DCloud应当有风险意识给出说明和解决方法。但是他们都没有做。最后开发者辛苦积攒的成就被弄丢了!而且他们也不会做出任何赔偿!.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 三哥刚抢了小米50亿,有钱了,说话口气就是不一样哈!
三哥刚抢了小米50亿,有钱了,说话口气就是不一样哈!.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 早就该限制了。 从贸易z开始的时候。打断他们产业链, 现在开始人家都不知道存储了多少了。
早就该限制了。 从贸易z开始的时候。打断他们产业链, 现在开始人家都不知道存储了多少了。.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 说明deepin团队的经费很足
说明deepin团队的经费很足.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
y受访者都是CS牛人,学习速度是真快.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
F你还真别说,google play上的国产APP,广告都少了很多,甚至没有广告,比如淘宝没有开屏广告,没有推送广告.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 完了,这一吹,A800也马上被禁了
完了,这一吹,A800也马上被禁了.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
我不厉害啊,但我起码查过相关资料再说人家是不是“增强版”,是不是“套壳”。“不懂就多查点资料再评价”我说的有问题吗?不懂不就是应该多了解再评价吗?再说了,你后面回的什么?“指令集还在更新呢”、“MIPS增强版有错吗”。说明你看新闻不仔细。另外,“有错”。因为 LoongISA 才是增强版,LoongArch 不是。我都指出来了,还不快查查资料再辩论。我第一条回复可没叫你多“读书”,“多读书”跟“查资料”是两码事。至于说你“无知”,也是你的二段回复好吧?我第一段回复我不觉得有什么问题。但你看你的二段回复讲的什么?“你在胡说八道些什么?要不要好好自己看看?”。是你讲我“胡说八道”,我才讲你“无知”的好吧?你觉得你很有素质吗?还“建议理性交流”,是你先“不理性的”好吧。.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 因果倒置论...你能做但你不能想,既然没想又怎么会去做.
因果倒置论...你能做但你不能想,既然没想又怎么会去做..comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 cuda有吗,TensorFlow/pytorch有吗,chatgpt有吗? 好像都没,那么硬件软件产品都没有,是靠什么进入第一梯队的呢
cuda有吗,TensorFlow/pytorch有吗,chatgpt有吗? 好像都没,那么硬件软件产品都没有,是靠什么进入第一梯队的呢.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 我都买mac mini了 我为什么还要安装deepin
我都买mac mini了 我为什么还要安装deepin.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 牛 x
牛 x.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 爬虫写得好,牢饭吃得早。
爬虫写得好,牢饭吃得早。.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
F现在有class来定义类了,有点亡羊补牢了,很多人都转其他语言了,但是似乎国外还有不少人在用perl.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 通篇过了一遍,核心思想大概可以概括为:re-package is cheap, show community your code. 从这个角度我完全赞同——但是这个问题的根本障碍在于社区对所谓的OSS许可证的原教旨主义坚持,对于伤害社区的行为过于包容。也就是说,由于社区并没有足够强力的组织,对社区做贡献的人一直在被放血。
通篇过了一遍,核心思想大概可以概括为:re-package is cheap, show community your code. 从这个角度我完全赞同——但是这个问题的根本障碍在于社区对所谓的OSS许可证的原教旨主义坚持,对于伤害社区的行为过于包容。也就是说,由于社区并没有足够强力的组织,对社区做贡献的人一直在被放血。.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 1500w的负主要责任,1亿多的负次要责任,这是多么和谐的合作协议啊
1500w的负主要责任,1亿多的负次要责任,这是多么和谐的合作协议啊.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 这就好比在火车上问人家买到票没有一样,你去谷歌问牛人这个语言好学吗?这不是搞笑吗?去大街上问估计百分之百说难学。
这就好比在火车上问人家买到票没有一样,你去谷歌问牛人这个语言好学吗?这不是搞笑吗?去大街上问估计百分之百说难学。.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 只是备案AI算法,有必要这么大惊小怪吗?你难道不知道现在境外就有AI换脸诈骗的行当了吗?
只是备案AI算法,有必要这么大惊小怪吗?你难道不知道现在境外就有AI换脸诈骗的行当了吗?.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
啊呀,西边的墙塌了,赶紧把东边的墙拆了,弄过来补一补~.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
疯牛啊 啥时候能支持注册中心啊.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
d漂亮国是唯恐天下不乱。狼子野心。.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 我宁愿相信中国男足已经进入全球第一梯队
我宁愿相信中国男足已经进入全球第一梯队.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 我一直以为开源中国最大的股东是红薯,没想到竟然是百度😀,恭喜红薯实现财务自由,我实现红薯自由
我一直以为开源中国最大的股东是红薯,没想到竟然是百度😀,恭喜红薯实现财务自由,我实现红薯自由.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 只是限制自由而已,和质量没关系
只是限制自由而已,和质量没关系.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 建議團隊放棄純C開發的執着,不喜歡用C++就用Rust啊,純C開發已經嚴重拖慢開發進度了。
建議團隊放棄純C開發的執着,不喜歡用C++就用Rust啊,純C開發已經嚴重拖慢開發進度了。.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 真是作死啊。
真是作死啊。.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 去意已决
去意已决.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
做游戏这么赚钱.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 孩子,你早晚会发现,男女长的一样。
孩子,你早晚会发现,男女长的一样。.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
F8个项目经理,一个程序员是吧,笑死了.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
F我的建议是 可以理性交流,别这么激动,显得你很没素质,别搞得像个G一样,急了跳墙,慢慢说话会死吗?.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 大利好
大利好.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 同样理解进来的。。。
同样理解进来的。。。.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 楼说说被增长的,这里的软件业务收入,指的是老板的收入增长了~当然,把开发裁了,可不收入就增长了~
楼说说被增长的,这里的软件业务收入,指的是老板的收入增长了~当然,把开发裁了,可不收入就增长了~.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 社区最大的贡献者本来就是红帽,到底是社区在被放血还是红帽在被放血?红帽这套操作无非是让那些半点不贡献只想搞白嫖的人没那么舒服罢了,开源如果真的想继续活下去,就得明白谁才是最大的贡献者。
社区最大的贡献者本来就是红帽,到底是社区在被放血还是红帽在被放血?红帽这套操作无非是让那些半点不贡献只想搞白嫖的人没那么舒服罢了,开源如果真的想继续活下去,就得明白谁才是最大的贡献者。.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 领导多,干活的少,看来这门语言又要玩完了
领导多,干活的少,看来这门语言又要玩完了.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 厉害:+1|type_1_2:
厉害:+1|type_1_2:.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 1、《中华人民共和国个人信息保护法》于2021年11月1日起施行。2、据悉,该毕业生还曾在自己的社交账号上公开炫耀自己的所作所为,但后来删除了相关内容。网传截图显示,该动态发布于 2020 年 10 月。 好像不能按这个处理,最多算侵犯肖像权吧。
1、《中华人民共和国个人信息保护法》于2021年11月1日起施行。2、据悉,该毕业生还曾在自己的社交账号上公开炫耀自己的所作所为,但后来删除了相关内容。网传截图显示,该动态发布于 2020 年 10 月。 好像不能按这个处理,最多算侵犯肖像权吧。.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 uniapp还是帮助了很多中小厂吧
uniapp还是帮助了很多中小厂吧.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 用了人家框架挣钱,又无比嫌弃别人逼他用似的
用了人家框架挣钱,又无比嫌弃别人逼他用似的.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 百度居然是原股东,真是想不到
百度居然是原股东,真是想不到.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
为什么实际用起来感觉3A4000没有他们说的可以接近zen1的水平呢.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 666
666.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
F你说进就进了?国足是否是世界第一梯队的?按投入的资金来看确实是第一梯队的,花了那么多钱,踢得怎么样呢?.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
这种做法,目前已经应用到各行各业了吧,说实在法律就是完善太慢,很多政策跟不上时代,或者是不想跟.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 前排支持
前排支持.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 发布了一个MIT协议的框架 。PHP 版本的niucloud-admin。大家可测试下载。
发布了一个MIT协议的框架 。PHP 版本的niucloud-admin。大家可测试下载。.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
 这人姓马,是叫马克扎克伯格是吧?
这人姓马,是叫马克扎克伯格是吧?.comments-box__list-news .osc-avatar{border-radius: 5px}.comments-box__list-news .comment-item:hover{background: rgba(201,201,201,0.1)}
F以前intel时代还能装个windows,现在用arm-mac的谁会装其他系统啊,最多搞个虚拟机关于作者


推荐关注
换一批 twelvet开源软件作者
twelvet开源软件作者 最后_开源软件作者
最后_开源软件作者 恋恋美食文章 193访问 137.2W
恋恋美食文章 193访问 137.2W 程序猿DD文章 2.5K访问 122.9W
程序猿DD文章 2.5K访问 122.9W wotrd文章 26访问 19.9W选择专区和圈子:{{title}}{{o.name}}{{m.name}}
wotrd文章 26访问 19.9W选择专区和圈子:{{title}}{{o.name}}{{m.name}}OSCHINA 社区
关于我们
联系我们
加入我们
合作伙伴
Open API在线工具
Gitee.com
企业研发管理
CopyCat-代码克隆检测
实用在线工具
国家反诈中心APP下载攻略
项目运营
Awesome 软件(持续更新中)QQ群
530688128公众号

视频号

OSCHINA 小程序
聚合全网技术文章,根据你的阅读喜好进行个性推荐
OSC小程序©OSCHINA(OSChina.NET)工信部开源软件推进联盟
指定官方社区社区规范
深圳市奥思网络科技有限公司版权所有粤ICP备12009483号
.codeBlock:hover .oscCode{display: block !important;} .codeBlock{z-index: 2;position: fixed;right: 20px;bottom: 57px; overflow: hidden; margin-bottom: 4px;padding: 8px 0 6px;width: 40px;height: auto;box-sizing: content-box;cursor: pointer;border: 1px solid #ddd;background: #f5f5f5;text-align: center;transition: background 0.4s ease;}
@media only screen and (max-width: 767px){ .codeBlock{display: none;}}/*
html{
-webkit-filter: grayscale(100%);
-moz-filter: grayscale(100%);
-ms-filter: grayscale(100%);
-o-filter: grayscale(100%);
filter:progid:DXImageTransform.Microsoft.BasicImage(grayscale=1);
_filter:none;
}
*/
 顶部
顶部(function(){
var bp = document.createElement('script');
var curProtocol = window.location.protocol.split(':')[0];
if (curProtocol === 'https'){
bp.src = 'https://zz.bdstatic.com/linksubmit/push.js';
}
else{
bp.src = 'http://push.zhanzhang.baidu.com/push.js';
}
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();var _hmt = _hmt || [];
_hmt.push(['_requirePlugin', 'UrlChangeTracker', {
shouldTrackUrlChange: function (newPath, oldPath) {
return newPath && oldPath;
}}
]);
(function() {
var hm = document.createElement("script");
hm.src = "https://hm.baidu.com/hm.js?a411c4d1664dd70048ee98afe7b28f0b";
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();{
"@context": "https://ziyuan.baidu.com/contexts/cambrian.jsonld",
"@id": "https://my.oschina.net/u/5735652/blog/10086596",
"appid": "1653861004982757",
"title":"Apache Doris 在拈花云科的统一数据中台实践,One Size Fits All - SelectDB的个人空间",
"images": [""],
"description":"作者|NearFar X Lab 团队 洪守伟、陈超、周志银、左益、武超 整理|SelectDB 内容团队 导读: 无锡拈花云科技服务有限公司(以下简称拈花云科)是由中国创意文旅集成商拈花湾文旅和北京滴普科技有限公司共同孵化...",
"pubDate": "2023-07-05T18:15:54+08:00",
"upDate":"2023-07-05T18:15:54+08:00",
"lrDate":""
}<!--
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());gtag('config', 'G-TK89C9ZD80');
-->
window.goatcounter = {
path: function(p) { return location.host + p }
}(function(){
var el = document.createElement("script");
el.src = "https://lf1-cdn-tos.bytegoofy.com/goofy/ttzz/push.js?2f2c965c87382dadf25633a3738875e5ccd132720338e03bf7e464e2ec709b9dfd9a9dcb5ced4d7780eb6f3bbd089073c2a6d54440560d63862bbf4ec01bba3a";
el.id = "ttzz";
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(el, s);
})(window)// 动弹话题页面描述加链接
$(function () {
const el = $('.www-tweet .tweet-form-header .topic-desc');
if (el && el.length > 0) {
const desc = el.html();
el.html(desc.replace(/http(s?)://[wd-./?=]+/, url => `${url}`));
}
});{{o.name}}{{m.name}}







点击引领话题📣