

下面的系列文章记录了如何使用一块linux开发扳和一块OLED屏幕实现视频的播放:
- 项目介绍
- 为OLED屏幕开发I2C驱动
- 使用cuda编程加速视频处理
这是此系列文章的第3篇, 主要总结和记录了如何使用cuda编程释放GPU的算力. 在此之前尝试过使用python调用opencv直接处理视频数据, 但使用之后发现处理过程效率不高, 处理时间偏长. 后来想到还有一块显卡没利用起来, 毕竟在前司见证了某国产GPGPU芯片从立项, 到流片再到回片验证的整个过程, cuda编程也算是传统艺能了. 最终效果看下面的视频:
跳转到6:48, 直接观看演示
1). 要用GPU做什么
这里不会介绍cuda的编程模型, cuda开发工具的使用等, 这部分内容可以参考cuda的官方文档, 学习cuda编程的话, 看这个文档就足够了.
原始的视频文件, 每帧画面的分辨率一般不会和我们的屏幕尺寸128×64匹配, 并且视频是彩色的, 使用的OLED屏幕只能显示黑白图像. 所以视频的数据必须经过resize和灰度处理之后才能发送给beaglebone black板子连接的OLED屏幕, 这部分视频处理工作就是在GPU上进行的.
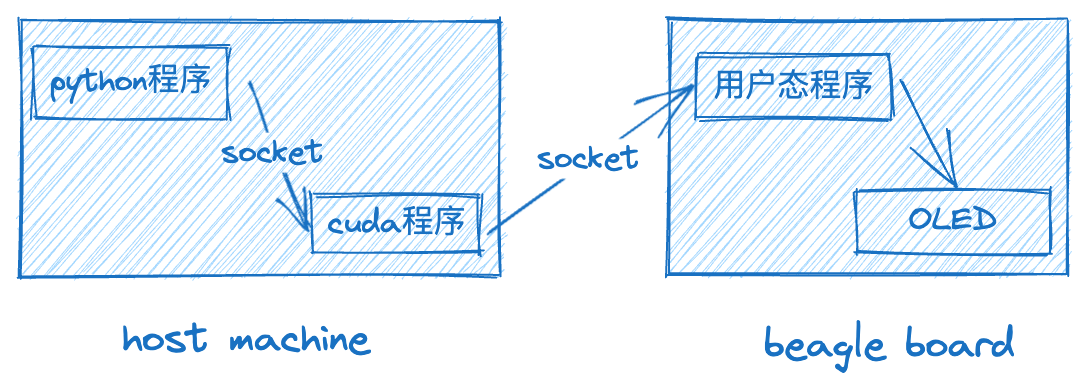
在host machine上的python程序使用opencv读取视频文件中的每一帧, 通过socket发送给cuda程序; cuda程序处理完数据之后, 再通过socket把数据发送给beagle board上的用户态程序; beagle board上的用户态程序, 把一帧数据写入屏幕, 完成绘制.
2). kernel函数的算法实现
下面是kernel函数的部分代码, oframe, ow, oh, 分别表示原始画面数据, 原始的宽度和高度, nframe, nw, nh分别表示处理之后的画面数据, 新的宽度和高度.
kernel中的resize操作, 使用最近临方式, (i, j)是新画面中的像素位置, 计算得到对应的原始画面像素位置(oi, oj), 取出原始的rgb值, 使用公式计算出亮度, 最后根据阈值确定(i, j)这个像素的亮灭.
__global__ void resize_frame_kernel(unsigned char *oframe, int ow, int oh,
unsigned char *nframe, int nw, int nh,
int threshold, unsigned int *locks)
{
for (int i = blockDim.x * blockIdx.x + threadIdx.x; i = threshold ? 1 : 0;
brightness = brightness 3). kernel函数中的并发问题
在上面的代码清单中使用原子交换指令atomicExch实现了一个自旋锁. 在kernel函数中使用锁是因为, nframe的大小是128×8字节, 屏幕分辨率是128×64, nframe的每个bit控制一个像素, 当kernel中更新nframe时, 可能同时有多个线程想更新nframe中的同一个字节. 关于这个自选锁中while循环的写法, 可以参考stack overflow.
4). 文末推广
欢迎关注我的B站账号, 或者加入QQ群838923389, 一起研究计算机底层技术, 一起搞事情:P
