

提要:本系列文章主要参考MIT 6.828课程以及两本书籍《深入理解Linux内核》 《深入Linux内核架构》对Linux内核内容进行总结。
内存管理的实现覆盖了多个领域:
- 内存中的物理内存页的管理
- 分配大块内存的伙伴系统
- 分配较小内存的slab、slub、slob分配器
- 分配非连续内存块的vmalloc分配器
- 进程的地址空间
内核初始化后,内存管理的工作就交由伙伴系统来承担,作为众多内存分配器的基础,我们必须要对其进行一个详细的解释。但是由于伙伴系统的复杂性,因此,本节会首先给出一个简单的例子,然后由浅入深,逐步解析伙伴系统的细节。
伙伴系统简介
伙伴系统将所有的空闲页框分为了11个块链表,每个块链表分别包含大小为1,2,4,(2^3),(2^4),…,(2^{10})个连续的页框(每个页框大小为4K),(2^{n})中的n被称为order(分配阶),因此在代码中这11个块链表的表示就是一个长度为11的数组。考察表示Zone结构的代码,可以看到一个名为free_area的属性,该属性用于保存这11个块链表。
struct zone {
...
/*
* 不同长度的空闲区域
*/
struct free_area free_area[MAX_ORDER];
...
};
结合之前的知识,我们总结一下,Linux内存管理的结构形如下图:
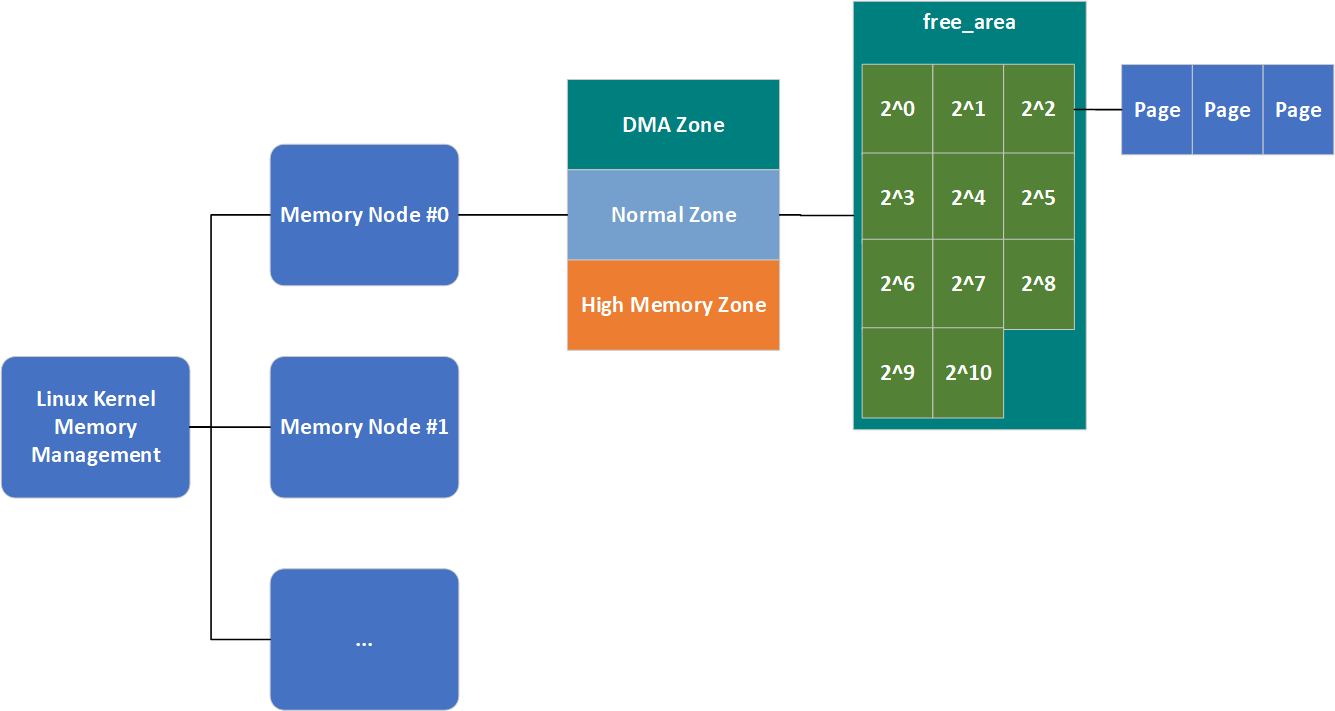
当然,这还不是完整的,我们本节就会将其填充完整。最后借用《深入理解Linux内核》中的一个例子简单介绍一下该算法的工作原理进而结束简介这一小节。
假设要请求一个256个页框(2^8)的块(即1MB)。
- 算法先在256个页的链表中检查是否有一个空闲块。
- 如果没有这样的块,算法会查找下一个更大的页块,也就是,在512个页框的链表中找一个空闲块。
- 如果存在这样的块,内核就把256的页框分成两等份,一半用作满足请求,另一半插人到256个页框的链表中。
- 如果在512个页框的块链表中也没找到空闲块,就继续找更大的块 一一1024个页框的块。
- 如果这样的块存在,内核把1024个页框块的256个页框用作请求,然后从剩余的768个页框中拿512个插入到512个页框的链表中
- 再把最后的256个插人到256个页框的链表中。
- 如果1024个页框的链表还是空的,算法就放弃并发出错信号
以上过程的逆过程就是页框块的释放过程,也是该算法名字的由来。内核试图把大小为b的一对空闲伙伴块合并为一个大小为2b的单独块。满足以下条件的两个块称为伙伴:
- 两个块具有相同的大小,记作 b。
- 它们的物理地址是连续的。
- 第一块的第一个页框的物理地址是2 x b x (2^{12})的倍数。
注意:该算法是迭代的,如果它成功合并所释放的块,它会试图合并2b的块,以再次试图形成更大的块。然而伙伴系统的实现并没有这么简单。
避免碎片
伙伴系统作为内存管理系统,也难以逃脱一个经典的难题,物理内存的碎片问题。尤其是在系统长期运行后,其内存可能会变成如下的样子:
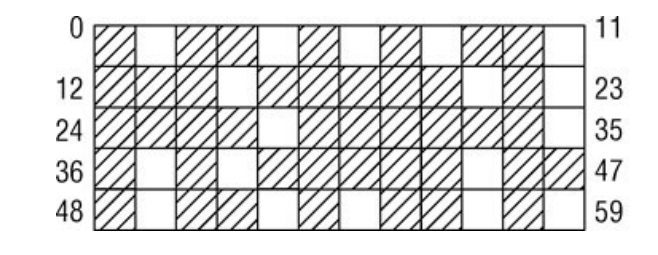
为了解决这个问题,Linux提供了两种避免碎片的方式:
- 可移动页
- 虚拟可移动内存区
可移动页
物理内存被零散的占据,无法寻找到一块连续的大块内存。内核2.6.24版本,防止碎片的方法最终加入内核。内核采用的方法是反碎片,即试图从最初开始尽可能防止碎片。因为许多物理内存页不能移动到任意位置,因此无法整理碎片。
可以看到,内核中内存碎片难以处理的主要原因是许多页无法移动到任意位置,那么如果我们将其单独管理,在分配大块内存时,尝试从可以任意移动的内存区域内分配,是不是更好呢?
为了达成这一点,Linux首先要了解哪些页是可移动的,因此,操作系统将内核已分配的页划分为如下3种类型:
| 类别名称 | 描述 |
|---|---|
| 不可移动页 | 在内存中有固定位置,不能移动到其他地方。核心内核分配的大多数内存属于该类别 |
| 可回收页 | 不能直接移动,但可以删除,其内容可以从某些源重新生成 |
| 可移动页 | 可以随意移动。属于用户空间应用程序的页属于该类别。它们是通过页表映射的。如果它们复制到新位置,页表项可以相应地更新,应用程序不会注意到任何事 |
内核中定义了一系列宏来表示不同的迁移类型:
#define MIGRATE_UNMOVABLE 0 // 不可移动页
#define MIGRATE_RECLAIMABLE 1 // 可回收页
#define MIGRATE_MOVABLE 2 // 可移动页
#define MIGRATE_RESERVE 3
#define MIGRATE_ISOLATE 4 /* 不能从这里分配 */
#define MIGRATE_TYPES 5
对于其他两种类型(了解就好):
- MIGRATE_RESERVE:如果向具有特定可移动性的列表请求分配内存失败,这种紧急情况下可从MIGRATE_RESERVE分配内存
- MIGRATE_ISOLATE:是一个特殊的虚拟区域,用于跨越NUMA结点移动物理内存页。在大型系统上,它有益于将物理内存页移动到接近于使用该页最频繁的CPU。
伙伴系统实现页的可移动性特性,依赖于数据结构free_area,其代码如下:
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
| 属性名 | 描述 |
|---|---|
| free_list | 每种迁移类型对应一个空闲页链表 |
| nr_free |
所有列表上空闲页的数目 |
与zone.free_area一样,free_area.free_list也是一个链表,但这个链表终于直接连接struct page了。因此,我们的内存管理结构图就变成了如下的样子:
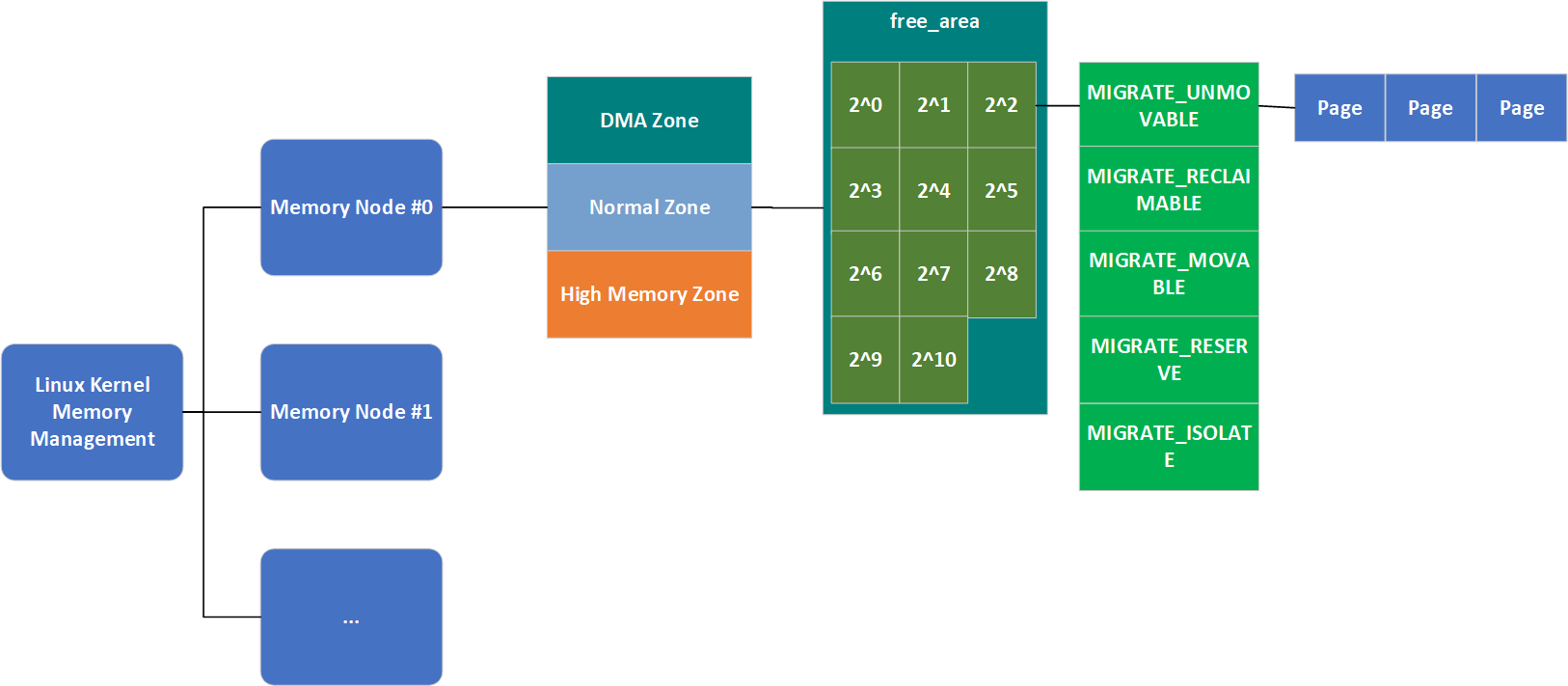
与NUMA内存域无法满足分配请求时会有一个备用列表一样,当一个迁移类型列表无法满足分配请求时,同样也会有一个备用列表,不过这个列表不用代码生成,而是写死的:
/*
* 该数组描述了指定迁移类型的空闲列表耗尽时,其他空闲列表在备用列表中的次序。
*/
static int fallbacks[MIGRATE_TYPES][MIGRATE_TYPES-1] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_RESERVE },
[MIGRATE_RESERVE] = { MIGRATE_RESERVE, MIGRATE_RESERVE, MIGRATE_RESERVE },/* 从来不用 */
};
该数据结构大体上是自明的:在内核想要分配不可移动页时,如果对应链表为空,则后退到可回收页链表,接下来到可移动页链表,最后到紧急分配链表。
在各个迁移链表之间,当前的页面分配状态可以从/proc/pagetypeinfo获得:
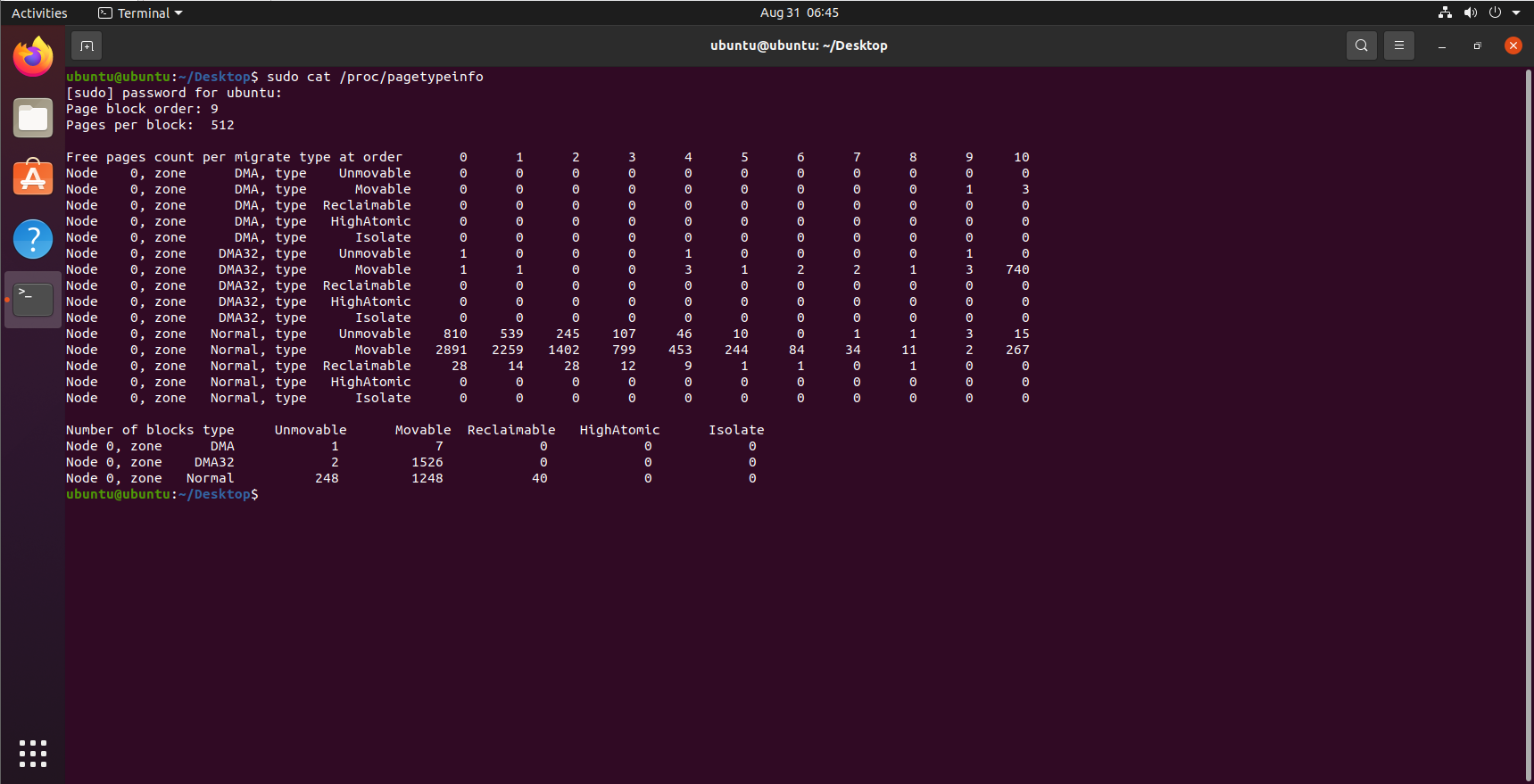
虚拟可移动内存域
可移动页给与内存分配一种层级分配的能力(按照备用列表顺序分配)。但是可能会导致不可移动页侵入可移动页区域。
内核在2.6.23版本将虚拟可移动内存域(ZONE_MOVABLE)这一功能加入内核。其基本思想为:可用的物理内存划分为两个内存域,一个用于可移动分配,一个用于不可移动分配。这会自动防止不可移动页向可移动内存域引入碎片。
取决于体系结构和内核配置,ZONE_MOVABLE内存域可能位于高端或普通内存域:
enum zone_type {
...
ZONE_NORMAL
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
MAX_NR_ZONES
};
与系统中所有其他的内存域相反,ZONE_MOVABLE并不关联到任何硬件上有意义的内存范围。实际上,该内存域中的内存取自高端内存域或普通内存域,因此我们在下文中称ZONE_MOVABLE是一个虚拟内存域。
那么用于可移动分配和不可移动分配的内存域大小如何分配呢?系统提供了两个参数用来分配这两个区域的大小:
- kernelcore参数用来指定用于不可移动分配的内存数量,即用于既不能回收也不能迁移的内存数量。剩余的内存用于可移动分配。
- 还可以使用参数movablecore控制用于可移动内存分配的内存数量
辅助函数find_zone_movable_pfns_for_nodes用于计算进入ZONE_MOVABLE的内存数量。如果kernelcore和movablecore参数都没有指定,find_zone_movable_pfns_for_nodes会使ZONE_MOVABLE保持为空,该机制处于无效状态。
但是ZONE_MOVABLE内存域的内存会按照如下情况分配:
- 用于不可移动分配的内存会平均地分布到所有内存结点上。
- 只使用来自最高内存域的内存。在内存较多的32位系统上,这通常会是ZONE_HIGHMEM,但是对于64位系统,将使用ZONE_NORMAL或ZONE_DMA32。
为ZONE_MOVABLE内存域分配内存后,会保存在如下位置:
- 用于为虚拟内存域ZONE_MOVABLE提取内存页的物理内存域,保存在全局变量movable_zone中;
- 对每个结点来说,zone_movable_pfn[node_id]表示ZONE_MOVABLE在movable_zone内存域中所取得内存的起始地址。
伙伴系统页面分配与回收
就伙伴系统的接口而言,NUMA或UMA体系结构是没有差别的,二者的调用语法都是相同的。所有函数的一个共同点是:只能分配2的整数幂个页。本节我们会按照如下顺序介绍伙伴系统页面的分配与回收:
- 介绍伙伴系统API接口
- 介绍API的核心逻辑
我们会按照分配页面与回收页面两节分别介绍。
分配页面
分配页面API
分配页面的API包含如下4个:
| API | 描述 |
|---|---|
| alloc_pages(mask, order) | 分配(2^{order})页并返回一个struct page的实例,表示分配的内存块的起始页 |
| alloc_page(mask) | alloc_pages(mask,0)的改写,只分配1页内存 |
| get_zeroed_page(mask) | 分配一页并返回一个page实例,页对应的内存填充0 |
| __get_free_pages(mask, order) | 分配页面,但返回分配内存块的虚拟地址 |
| get_dma_pages(gfp_mask, order) | 用来获得适用于DMA的页 |
在空闲内存无法满足请求以至于分配失败的情况下,所有上述函数都返回空指针(alloc_pages和alloc_page)或者0(get_zeroed_page、__get_free_pages和__get_free_page)。
可以看到,每个分配页面的接口都包含一个mask参数,该参数是内存修饰符,用来控制内存分配的逻辑,例如内存在哪个内存区分配等,为了控制这一点,内核提供了如下宏:
/* GFP_ZONEMASK中的内存域修饰符(参见linux/mmzone.h,低3位) */
#define __GFP_DMA ((__force gfp_t)0x01u)
#define __GFP_HIGHMEM ((__force gfp_t)0x02u)
#define __GFP_DMA32 ((__force gfp_t)0x04u)
...
#define __GFP_MOVABLE ((__force gfp_t)0x100000u) /* 页是可移动的 */
注意:设置__GFP_MOVABLE不会影响内核的决策,除非它与__GFP_HIGHMEM同时指定。在这种情况下,会使用特殊的虚拟内存域ZONE_MOVABLE满足内存分配请求。
这里给出其他一些掩码的含义(需要用时现查):

实际上,上面所有用于分配页面的API,最终都是通过alloc_pages_node方法进行内存分配的,其调用关系如下:
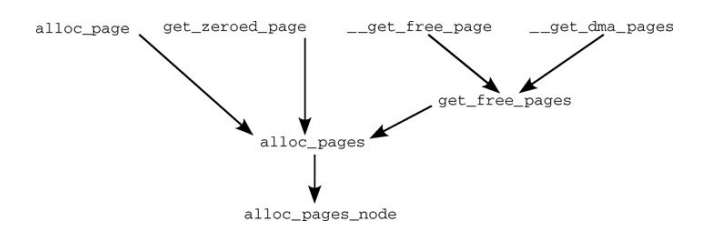
后面我们将主要讨论alloc_pages_node方法的具体逻辑。
alloc_pages_node:分配页面的具体逻辑
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask,
unsigned int order)
{
if (unlikely(order >= MAX_ORDER))
return NULL;
/* 未知结点即当前结点 */
if(nidnode_zonelists + gfp_zone(gfp_mask));
}
alloc_pages_node方法很简单,进行了一些简单的检查,并将页面的分配逻辑交由__alloc_pages方法处理。这里我们又见到了老朋友zonelist,如果不熟悉请参见该链接。gfp_zone方法,负责根据gfp_mask选择分配内存的内存域,因此可以通过指针运算,选择合适的zonelist(内存区选择备用列表)。
分配页面需要大量的检查以及选择合适的内存域进行分配,在完成这些工作之后,就可以进行真正的分配物理内存。__alloc_pages方法就是按照这个逻辑编写的。
__alloc_pages会根据现实情况调用get_page_from_freelist方法选择合适的内存域,进行内存分配,然而内存域是否有空闲空间,也有一定的条件,这个条件由zone_watermark_ok函数判断。这里的判断条件主要和zone的几个watermark有关,即pages_min、pages_low、pages_high,这三个参数的具体含义可以参考第二章的讲解
内核提供了如下几个宏,用于控制到达各个水印指定的临界状态时的行为:
#define ALLOC_NO_WATERMARKS 0x01 /* 完全不检查水印 */
#define ALLOC_WMARK_MIN 0x02 /* 使用pages_min水印 */
#define ALLOC_WMARK_LOW 0x04 /* 使用pages_low水印 */
#define ALLOC_WMARK_HIGH 0x08 /* 使用pages_high水印 */
#define ALLOC_HARDER 0x10 /* 试图更努力地分配,即放宽限制 */
#define ALLOC_HIGH 0x20 /* 设置了__GFP_HIGH */
#define ALLOC_CPUSET 0x40 /* 检查内存结点是否对应着指定的CPU集合 */
前几个标志表示在判断页是否可分配时,需要考虑哪些水印。
- 默认情况下(即没有因其他因素带来的压力而需要更多的内存),只有内存域包含页的数目至少为zone->pages_high时,才能分配页。这对应于ALLOC_WMARK_HIGH标志。
- 如果要使用较低(zone->pages_low)或最低(zone->pages_min)设置,则必须相应地设置ALLOC_WMARK_MIN或ALLOC_WMARK_LOW
- ALLOC_HARDER通知伙伴系统在急需内存时放宽分配规则
- 在分配高端内存域的内存时,ALLOC_HIGH进一步放宽限制
- ALLOC_CPUSET告知内核,内存只能从当前进程允许运行的CPU相关联的内存结点分配,当然该选项只对NUMA系统有意义
zone_watermark_ok方法,使用了ALLOC_HIGH和ALLOC_HARDER标志,其代码如下:
int zone_watermark_ok(struct zone *z, int order, unsigned long mark,
int classzone_idx, int alloc_flags)
{
/* free_pages可能变为负值,没有关系 */
long min = mark;
long free_pages = zone_page_state(z, NR_FREE_PAGES) -(1 lowmem_reserve[classzone_idx])
return 0;
for(o= 0;o free_area[o].nr_free >= 1;
if (free_pages 注意,zone_watermark_ok方法中的mark参数就是zone中的水印,根据设置的ALLOC_WMARK_*标志的不同,mark选择对应的pages_*水印,zone_page_state方法用于访问内存域中的统计量,由于提供了标志NR_FREE_PAGES,这里获取的是内存域中空闲页的数目。
可以看到当flag设置了ALLOC_HIGH和ALLOC_HARDER后,min的阈值变小了,这也就是所谓的放宽了限制。当前内存域需要满足如下两个条件才能进行内存分配:
- min+lowmem_reserve中指定的紧急分配值
- 对于指定order前的每一个分配阶,都要高于当前阶的min值(每升高一阶,所需空闲页的最小值折半)
了解了内存域的可用性条件后,我们将讨论,哪个方法负责从备用列表中选择合适的内存域。该方法为get_page_from_freelist,如果查找到对应的内存域,将发起实际的分配操作。
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist, int alloc_flags)
{
struct zone **z;
struct page *page = NULL;
int classzone_idx = zone_idx(zonelist->zones[0]);
struct zone *zone;
...
/*
* 扫描zonelist,寻找具有足够空闲空间的内存域。
* 请参阅kernel/cpuset.c中cpuset_zone_allowed()的注释。
*/
z = zonelist->zones;
do {
...
zone = *z;
//cpuset_zone_allowed_softwall是另一个辅助函数,用于检查给定内存域是否属于该进程允许运行的CPU
if ((alloc_flags & ALLOC_CPUSET) &&!cpuset_zone_allowed_softwall(zone, gfp_mask))
continue;
if (!(alloc_flags & ALLOC_NO_WATERMARKS)) {
unsigned long mark;
if (alloc_flags & ALLOC_WMARK_MIN)
mark = zone->pages_min;
else if (alloc_flags & ALLOC_WMARK_LOW)
mark = zone->pages_low;
else
mark = zone->pages_high;
if (!zone_watermark_ok(zone, order, mark,classzone_idx, alloc_flags))
continue;
}
page = buffered_rmqueue(*z, order, gfp_mask);
if (page) {
zone_statistics(zonelist, *z);
break;
}
} while (*(++z) != NULL);
return page;
}
可以看到do..while循环遍历了整个备用列表,通过zone_watermark_ok方法查找第一个可用的内存域,查找到后进行内存分配(buffered_rmqueue方法负责处理分配逻辑)。
__alloc_pages通过调用get_page_from_freelist方法进行实际的分配,但是,分配内存的时机是一个很复杂的问题,在现实生活中,内存并不总是充足的,为了充分解决这些情况,__alloc_pages方法考虑了诸多情况:
-
内存充足时,调用
get_page_from_freelist方法直接分配:struct page * fastcall __alloc_pages(gfp_t gfp_mask, unsigned int order, struct zonelist *zonelist) { const gfp_t wait = gfp_mask & __GFP_WAIT; struct zone **z; struct page *page; struct reclaim_state reclaim_state; struct task_struct *p = current; int do_retry; int alloc_flags; int did_some_progress; might_sleep_if(wait); restart: z = zonelist->zones; /* 适合于gfp_mask的内存域列表 */ if (unlikely(*z == NULL)) { /* *如果在没有内存的结点上使用GFP_THISNODE,导致zonelist为空,就会发生这种情况 */ return NULL; } page = get_page_from_freelist(gfp_mask|__GFP_HARDWALL, order,zonelist, ALLOC_WMARK_LOW|ALLOC_CPUSET); if (page) goto got_pg; ...可以看到,第一次尝试分配内存时,系统对分配的要求会比较严格:
- gft_mask设置了__GFP_HARDWALL:它限制只在分配到当前进程的各个CPU所关联的结点分配内存。
- flag设置了ALLOC_WMARK_LOW和ALLOC_CPUSET(这两个含义代码注释里有,这里就不解释了)
-
首次分配失败后,内核会唤醒负责换出页的kswapd守护进程,写回或换出很少使用的页。在交换守护进程唤醒后,再次尝试
get_page_from_freelist:... for (z = zonelist->zones; *z; z++) wakeup_kswapd(*z, order); alloc_flags = ALLOC_WMARK_MIN; if ((unlikely(rt_task(p)) && !in_interrupt()) || !wait) alloc_flags |= ALLOC_HARDER; if (gfp_mask & __GFP_HIGH) alloc_flags |= ALLOC_HIGH; if (wait) alloc_flags |= ALLOC_CPUSET; page = get_page_from_freelist(gfp_mask, order, zonelist, alloc_flags); if (page) goto got_pg; ... }此处的策略不仅换出了非常用页,而且放宽了水印的判断条件:
- alloc_flags成为了ALLOC_WMARK_MIN
- 对实时进程和指定了__GFP_WAIT标志因而不能睡眠的调用,会设置ALLOC_HARDER。
-
如果设置了PF_MEMALLOC或进程设置了TIF_MEMDIE标志(在这两种情况下,内核不能处于中断上下文中),内核会忽略所有水印,调用
get_page_from_freelist方法:rebalance: if (((p->flags & PF_MEMALLOC) || unlikely(test_thread_flag(TIF_MEMDIE)))&& !in_interrupt()) { if (!(gfp_mask & __GFP_NOMEMALLOC)) { nofail_alloc: /* 再一次遍历zonelist,忽略水印 */ page = get_page_from_freelist(gfp_mask, order,zonelist, ALLOC_NO_WATERMARKS); if (page) goto got_pg; if (gfp_mask & __GFP_NOFAIL) { congestion_wait(WRITE, HZ/50); goto nofail_alloc; } } goto nopage; } ...通常只有在分配器自身需要更多内存时,才会设置PF_MEMALLOC,而只有在线程刚好被OOM killer机制选中时,才会设置TIF_MEMDIE
这里的两个goto语句负责处理此种情况下,内存分配失败的情况:
- 设置了__GFP_NOMEMALLOC。该标志禁止使用紧急分配链表(如果忽略水印,这可能是最佳途径),因此无法在禁用水印的情况下调用get_page_from_freelist。跳转到nopage处,通过内核消息将失败报告给用户,并将NULL指针返回调用者
- 在忽略水印的情况下,get_page_from_freelist仍然失败了,这种情况下会放弃搜索,报告错误消息。如果设置了__GFP_NOFAIL,内核会进入无限循环(跳转到第4行的标号nofail_alloc),重复本段内容。
-
如果上述3种情况都没有成功分配内存,内核会进行一些耗时的操作。。前提是分配掩码中设置了__GFP_WAIT标志,因为随后的操作可能使进程睡眠(为了使得kswapd取得一些进展)。
if (!wait) goto nopage; cond_schedule(); ...如果wait标志没有被设置,这里会放弃分配。如果设置了,内核通过cond_reschedᨀ供了重调度的时机。这防止了花费过多时间搜索内存,以致于使其他进程处于饥饿状态。
分页机制提供了一个目前尚未使用的选项,将很少使用的页换出到块介质,以便在物理内存中产生更多空间。但该选项非常耗时,还可能导致进程睡眠状态。try_to_free_pages是相应的辅助函数,用于查找当前不急需的页,以便换出。
/* 我们现在进入同步回收状态 */ p->flags |= PF_MEMALLOC; ... did_some_progress = try_to_free_pages(zonelist->zones, order, gfp_mask); ... p->flags &= ~PF_MEMALLOC; cond_resched(); ...该调用被设置/清除PF_MEMALLOC标志的代码间隔起来。try_to_free_pages自身可能也需要分配新的内存。由于为获得新内存还需要额外分配一点内存(相当矛盾的情形),该进程当然应该在内存管理方面享有最高优先级,上述标志的设置即达到了这一目的。try_to_free_pages会返回增加的空闲页数目。
接下来,如果try_to_free_pages释放了一些页,那么内核再次调用get_page_from_freelist尝试分配内存:
if (likely(did_some_progress)) { page = get_page_from_freelist(gfp_mask, order,zonelist, alloc_flags); if (page) goto got_pg; } else if ((gfp_mask & __GFP_FS) && !(gfp_mask & __GFP_NORETRY)) { ...如果内核可能执行影响VFS层的调用而又没有设置GFP_NORETRY,那么调用OOM killer:
/* OOM killer无助于高阶分配,因此失败 */ if (order > PAGE_ALLOC_COSTLY_ORDER) { clear_zonelist_oom(zonelist); goto nopage; } out_of_memory(zonelist, gfp_mask, order); goto restart; }out_of_memory函数函数选择一个内核认为犯有分配过多内存“罪行”的进程,并杀死该进程。这有很大几率腾出较多的空闲页,然后跳转到标号restart,重试分配内存的操作。但杀死一个进程未必立即出现多于(2^{PAGE_COSTLY_ORDER})页的连续内存区(其中PAGE_COSTLY_ORDER_PAGES通常设置为3),因此如果当前要分配如此大的内存区,那么内核会饶恕所选择的进程,不执行杀死进程的任务,而是承认失败并跳转到nopage。
如果设置了__GFP_NORETRY,或内核不允许使用可能影响VFS层的操作,会判断所需分配的长度,作出不同的决定:
... do_retry = 0; if (!(gfp_mask & __GFP_NORETRY)) { if ((order comm, order, gfp_mask); dump_stack(); show_mem(); } got_pg: return page; }- 如果分配长度小于(2^{PAGE_ALLOC_COSTLY_ORDER})=8页,或设置了__GFP_REPEAT标志,则内核进入无限循环。在这两种情况下,是不能设置GFP_NORETRY的。因为如果调用者不打算重试,那么进入无限循环重试并没有意义。内核会跳转回rebalance标号,即 的入口,并一直等待,直至找到适当大小的内存块——根据所要分配的内存大小,内核可以假定该无限循环不会持续太长时间。内核在跳转之前会调用congestion_wait,等待块设备层队列释放,这样内核就有机会换出页。
- 在所要求的分配阶大于3但设置了__GFP_NOFAIL标志的情况下,内核也会进入上述无限循环,因为该标志无论如何都不允许失败。
- 如果情况不是这样,内核只能放弃,并向用户返回NULL指针,并输出一条内存请求无法满足的警告消息。
总结
本节主要总结了伙伴系统中__alloc_pages方法的主要流程,由于后续内容过多,这里会分为多个小结总结。
