

随着业务的发展,实时场景在各个⾏业中变得越来越重要。⽆论是⾦融、电商还是物流,实时数据处理都成为了其中的关键环节。Flink 凭借其强⼤的流处理特性、窗⼝操作以及对各种数据源的⽀持,成为实时场景下的⾸选开发⼯具。
FlinkSQL 通过 SQL 语⾔⾯向数据开发提供了更友好的交互⽅式,但是其开发⽅式和离线开发 SparkSQL 仍然存在较⼤的差异。袋鼠云实时开发平台StreamWorks,⼀直致⼒于降低 FlinkSQL 的开发门槛,让更多的数据开发掌握实时开发能⼒,普及实时计算的应⽤。
本文将为大家简单介绍在袋鼠云实时开发平台开发 FlinkSQL 任务的四种⽅式。
脚本模式
该模式是最基础的开发⽅式,数据开发人员在平台 IDE 中通过 FlinkSQL 代码,完成 Flink 表定义和业务逻辑加⼯。代码如下:
-- 定义数据源表
CREATE TABLE server_logs (
client_ip STRING,
client_identity STRING,
userid STRING,
user_agent STRING,
log_time TIMESTAMP(3),
request_line STRING,
status_code STRING,
size INT
) WITH (
'connector ' = 'faker ',
'fields .client_ip .expression ' = '#{Internet .publicIpV4Address} ',
'fields .client_identity .expression ' = '- ',
'fields .userid .expression ' = '- ',
'fields .user_agent .expression ' = '#{Internet .userAgentAny} ',
'fields .log_time .expression ' = '#{date .past ' '15 ' ', ' '5 ' ', ' 'SECONDS ' '} ',
'fields .request_line .expression ' = '#{regexify ' '(GET |POST |PUT |PATCH){1} ' '} #{regexify ' '(/search .html|/login .html|/prod .html|c
'fields .status_code .expression ' = '#{regexify ' '(200 |201 |204 |400 |401 |403 |301){1} ' '} ',
'fields .size .expression ' = '#{number .numberBetween ' '100 ' ', ' '10000000 ' '} '
);
-- 定义结果表, 实际应用中会选择 Kafka、JDBC 等作为结果表
CREATE TABLE client_errors (
log_time TIMESTAMP(3),
request_line STRING,
status_code STRING,
size INT
) WITH (
'connector ' = 'stream-x '
);
-- 写入数据到结果表
INSERT INTO client_errors
SELECT
log_time,
request_line,
status_code,
size
FROM server_logs
WHERE status_code SIMILAR TO '4[0-9][0-9] ';
脚本模式的优缺点
优点:灵活性⾼。
缺点:Flink表定义逻辑复杂,如果不熟悉数据源插件,很难记住需要维护哪些参数;如果该任务涉及多张表,代码块中存在⼤段表定义代码,不⽅便排查业务逻辑。
向导模式
基于脚本模式存在的缺点,袋鼠云实时开发平台将 Flink 表定义逻辑抽象成了可视化配置的功能,引导数据开发⼈员通过⻚⾯配置化的⽅式完成 Flink 表定义,让数据开发更专注在业务逻辑的加⼯。
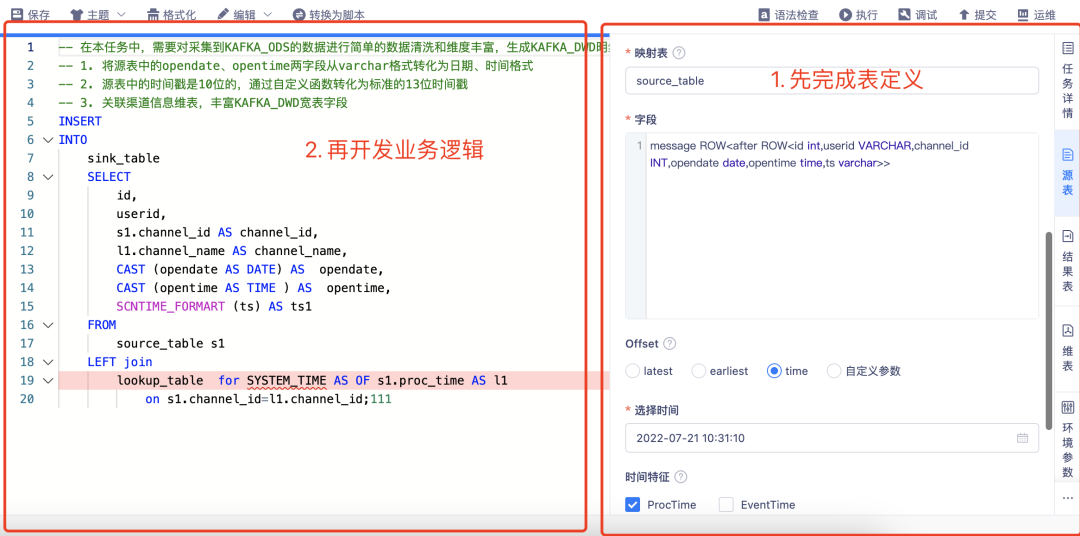
向导模式是在开发⻚⾯的配置项中根据⻚⾯引导,完成 Flink 表的源表、维表、结果表的映射,然后在 IDE 中直接引⽤,读写对应的 Flink 表,完成逻辑开发。
· 平台默认提供各类数据源的源表、维表、结果表常⽤配置项;
· 对于各种⾼级参数,平台也提供了维护⾃定义参数的 key/value ⽅式来满⾜灵活性要求。
Catalog 模式
在向导模式中,我们可以借助配置化的⽅式快速完成表映射,但同时也存在⼀个问题,这些映射表只能在当前任务中被引⽤,⽆法在不同的任务中复⽤。
但是在真实的实时数仓建设过程中,我们常会遇到下⾯这种场景:某⼀个 dws 层级的 kafka topic,会在多个 ads 任务中被作为源表使⽤。⽽在每个 ads 任务开发过程中,都需要为同⼀个 dws topic 做⼀次相同的 Flink 映射。
为了解决这种重复映射的开发⼯作,我们可以借助 Flink Catalog 功能,将映射表的元数据信息进⾏持久化存储,这样就可以在不同的任务中重复引⽤。具体使⽤⽅法如下(以平台的 DT Catalog 为例):
Catalog ⽬录维护
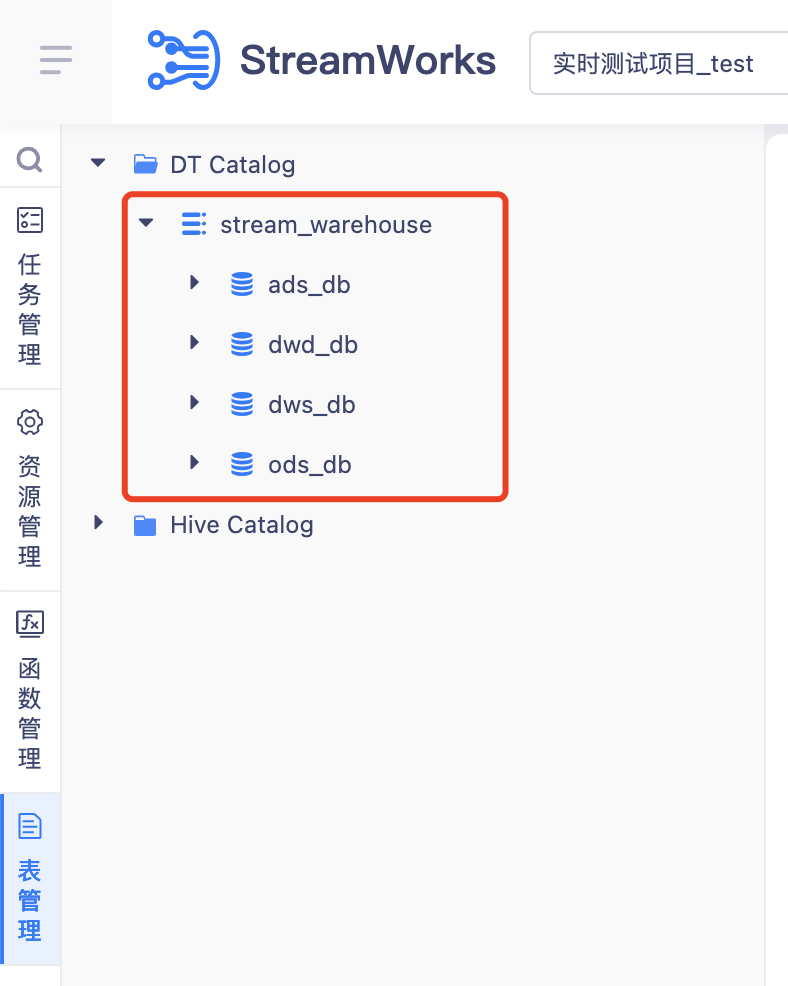
· 先在 DT Catalog 下创建⼀个名为 stream_warehouse 的 catalog
· 然后在该 catalog 下根据数仓层级或者业务域创建不同的 database
Flink 映射表创建
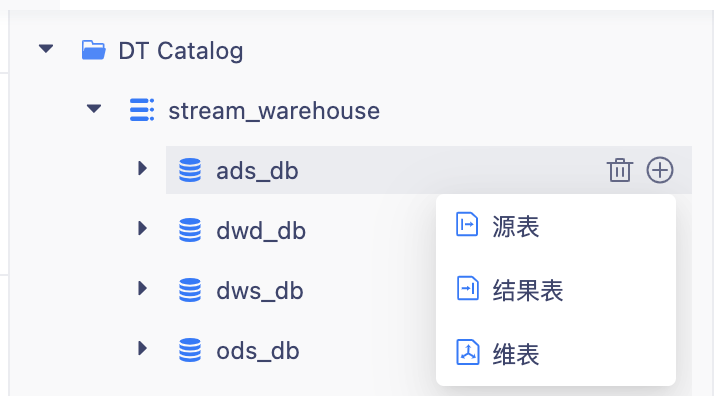
· ⽅式⼀:在⽬录中 hover database,根据引导通过配置化⽅式完成 Flink 表映射
· ⽅式⼆:在 IDE 中,通过 Create DDL 完成创建,注意要指定对应的 catalog.database 路径
CREATE TABLE stream_warehouse .dws .orders (
order_uid BIGINT,
product_id BIGINT,
price DECIMAL(32, 2),
order_time TIMESTAMP(3)
) WITH (
'connector ' = 'datagen '
);
FlinkSQL 任务开发
完成上面两个步骤,⼀张元数据持久化存储的 Flink 映射表就创建好了。我们在开发任务的时候,就可以直接通过 catalog.database.table 的⽅式,引⽤我们需要的表。
INSERT INTO stream_warehouse .ads_db .client_errors
SELECT
log_time,
request_line,
status_code,
size
FROM stream_warehouse .dws_db .server_logs
Demo 模式
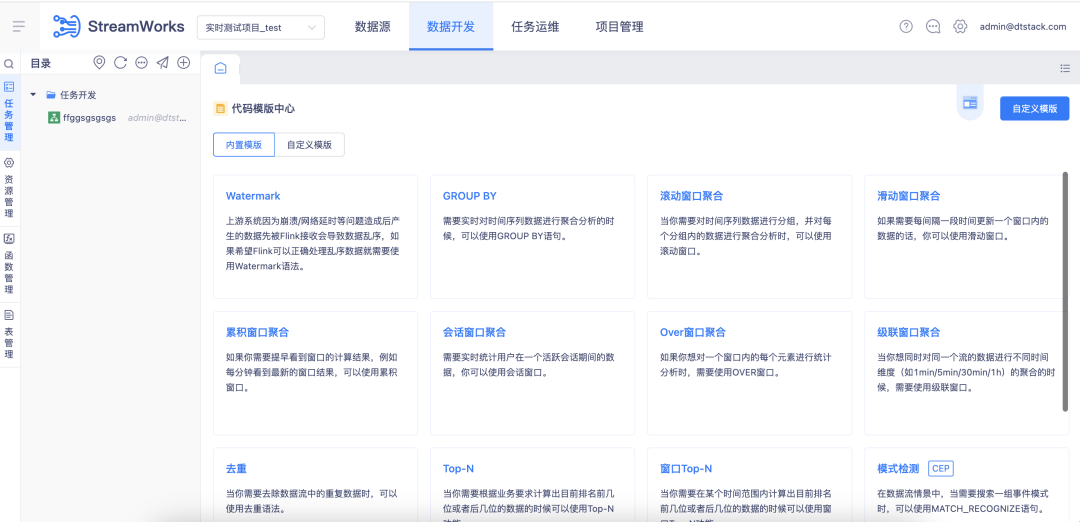
学会了上⾯三种开发⽅式后,如果你还对 FlinkSQL 的开发逻辑⽐较陌⽣,那么建议你可以通过袋鼠云实时开发平台的代码模版中⼼去完成⼀个完整的任务开发。
在模版中⼼,我们提供了⼆⼗余种常⻅的业务场景及其对应的 FlinkSQL 代码逻辑,如各类窗⼝的写法、各类 Join 的写法等等,你可以根据真实的业务场景去套⽤模版,快速地完成任务开发。
总结
每种开发模式没有绝对的好坏之分,需要根据不同企业的实时计算场景和阶段,采⽤不同的开发模式,才能真正达到降本增效的目的。
· 当企业刚接触实时计算,数据开发⼈员对 FlinkSQL 熟悉度较低时,DEMO 模式是最好的选择;
· 当企业已经上⼿实时计算,但是任务量还不⼤时,脚本模式或者向导模式是不错的选择;
· 当企业实时计算达到⼀定规模,需要进⾏类似离线数仓的管理⽅式时,Catalog 模式是最优的选择。
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm 想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szkyzg
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
