


Apache Hudi 是一款开源的数据湖解决方案,它能够帮助企业更好地管理和分析海量数据,支持高效的数据更新和查询。并提供多种数据压缩和存储格式以及索引功能,从而为企业数据仓库实践提供更加灵活和高效的数据处理方式。
在金融领域,企业可以使用 Hudi 来处理大量需要实时查询和更新的金融交易数据。在电商业务中,企业可以使用 Hudi 来跟踪订单数据,以及对订单进行实时更新和查询。在物流和供应链管理中,Hudi 可以帮助企业实时处理和更新大量的物流数据,保证数据的一致性和可靠性。
作为一站式大数据基础软件的袋鼠云数栈,基于 Apache Hudi 为客户提供了存量数据迁移、数据入湖、文件治理等完整支持能力。在这个过程中,积累了一些 Hudi 性能优化的经验,希望通过本文与大家分享交流。
Hudi 原理简析
Apache Hudi 是一个开源的数据湖解决方案,它是基于 Hadoop 和 Spark 的技术栈构建而成,并且拓展到了 Flink、 Trino 等多种计算引擎。Apache Hudi 的主要目的是提供一个高效、可扩展且可靠的数据湖解决方案,用于管理和处理大规模的数据集。
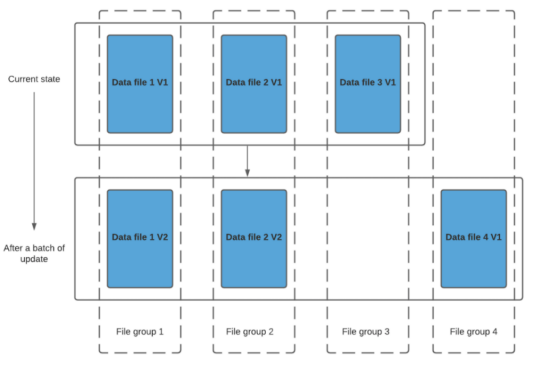
Hudi 的核心实现是通过将数据集合划分为多个数据文件,并为每个数据文件维护一个数据版本和索引信息,来支持增量数据更新和查询操作。如下图所示,当用户需要对数据进行更新时,Hudi 会将更新的数据写入一个新的数据文件中,并通过写时复制(copy-on-write)操作,将原始数据文件中的数据记录复制到新的数据文件中,并在新的数据文件中更新对应的数据记录。
同时,Hudi 会更新数据版本和索引信息,以便用户可以根据数据版本和唯一标识符来访问最新的数据记录。当用户需要查询数据时,Hudi 会使用索引信息来定位数据记录,并返回最新的数据记录。
在 Hudi 的 merge on read 模式中,更新操作是通过在查询时将原始数据和更新数据进行合并来实现的。具体来说,当有新的数据要被写入时,Hudi 会将新数据追加写入到一个新的日志文件中,并在元数据文件中记录新文件的信息。当查询数据时,Hudi 会将所有数据文件进行合并,生成一个视图,然后对视图进行查询。
由于 Hudi 只需要在查询时将需要更新的数据进行合并,而不需要在写入时进行合并,因此可以避免写入时的性能开销,从而实现快速的更新操作。
Apache Hudi 在写入数据时创建一个新版本,而读取数据时通过将所有版本的数据进行合并来生成一个视图。在视图中,每个数据记录只出现一次,并且是最新的版本,这样可以保证读操作只会涉及到视图中的数据,而不会对原始数据进行修改,从而实现了读写分离。
通过多版本实现并发控制,Hudi 可以在保证数据一致性的前提下,提高读操作的性能,同时也保证了数据的可靠性和可扩展性。
Hudi 优化实践
下面介绍基于袋鼠云数栈的实践经验,所做的 Hudi 性能优化。
支持多索引
Hudi 将数据集合划分为多个数据文件,并为每个数据文件维护一个数据版本和索引信息,来支持增量数据更新和查询操作。通过构建索引就可以利用生成的元数据快速定位查询所需数据的位置,如下图所示。这样可以减少甚至避免从文件系统中扫描或者读取不必要的数据,减少 IO 的开销,大大提升查询效率。Hudi 已经支持几种不同的索引技术,并且还在不断地改进和添加更多的索引实现。
袋鼠云数栈支持用户在创建 Hudi 表时就设置想要使用的索引类型,包括 SIMPLE、BLOOM FILTER、BUCKET 等类型。在写入过程中,Hudi 会将索引信息写入到 parquet 文件或者外部存储中,在读取时应用程序根据这些信息进行比较判断,跳过不必要的数据文件。
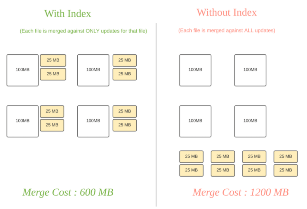
Hudi 在0.11.0版本引入了 MetadataTable 这种多模式索引,利用 MetadataTable 汇总元数据信息,应用程序可以避免文件系统调用文件 Listing 操作(这在对象存储中是非常耗时的),还可以避免直接读取 parquet 文件中的 footer 信息,能够大幅提升查询性能。
袋鼠云数栈支持用户在建表时就开启多模式索引,在写入数据的同时将文件的索引信息也写入 MetadataTable。数栈还支持以异步的方式构建 MetadataTable,保证写入仍然处于低延迟的状态,再由后台的应用程序离线生成 MetadataTable 以提升读取性能。
由于 MetadataTable 依赖 base 文件记录的 column stats/bloomfilter 等信息,因此 merge on read 模式下没有办法将 log 文件的信息保存到 MetadataTable 中,开源框架上没有利用它实现进行文件过滤。
但考虑到 base 文件和 log 文件共用相同的 fileId,袋鼠云技术团队在数栈内部进行了改造:通过 MetadataTable 获取到 base 文件之后,再根据 fileId 进行 log 文件过滤,避免不必要读取。经过验证,这种改动能够使得 merge on read 模式具备和 copy on write 模式相同的过滤效果。
优化文件布局
在大数据存储中,文件布局优化是一种重要的性能优化技术。其主要目的是在数据写入时将数据按照一定的规则布局到存储介质中,以提高数据读取和处理的效率。文件布局优化可以采用多种方式,如时间戳排序、分区排序和合并文件等方式。
Hudi 提供了一种名为 Clustering 的文件布局优化方法,可以借此将小文件合并成较大的文件以减少查询引擎需要扫描的文件总数,或者利用空间填充曲线之类的概念来适应数据湖布局并减少查询读取的数据量。利用 Clustering,可以将具有相同查询特征的数据放到相邻的几个文件内,在查询时再根据索引信息进行过滤,能够有效减少需要读取的文件数量,降低计算成本。
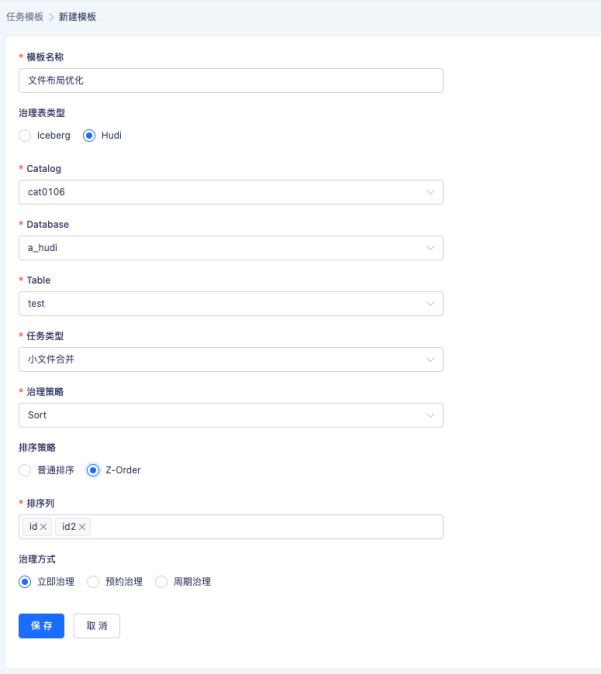
袋鼠云数栈提供了可视化页面以方便用户对文件布局进行调整,用户可以根据需要自由设置排序策略、排序字段、过滤条件等,如下图所示,应用程序会周期性地在后台根据配置对文件进行优化。因为 Hudi 采用多版本组织文件,用户不需要担心优化任务会影响正在运行的读取任务,在优化完成后新的读取任务即可享受到新的布局带来的效率提升。
探索新特性
在落地 Hudi 的过程中,袋鼠云数栈也在积极跟踪实践社区的新功能新特性。
在 Hudi 0.13.0 中,Hudi 实现了“优化记录负载处理”的特性。通过设置 hoodie.datasource.write.record.merger.impls=org.apache.hudi.HoodieSparkRecordMerger 和 hoodie.logfile.data.block.format=parquet 两个参数避免了额外的复制和反序列化,在写入操作的整个生命周期内以统一的方式处理记录。
袋鼠云数栈测试和引入了这项特性,经过验证,更新性能相比上一版本有了约20%的提升,符合社区的描述。另外,数栈还参考了 Hudi 0.13.0 引入的 disruptor 无锁消息队列写入数据的新特性,通过设置 hoodie.write.executor.type = DISRUPTOR 和 hoodie.write.executor.disruptor.wait.strategy = BUSY_SPIN_WAIT 参数,结合前述的优化配置,更新性能整体提升了30%以上。
总结
Apache Hudi 的优势在于支持增量数据处理,具有良好的数据一致性和可靠性,同时提供多种性能优化技术,能够提高数据处理和查询的效率,具有良好的性能和可扩展性。
袋鼠云数栈团队在落地 Hudi 的过程中,验证了 Hudi 的多种索引,应用了文件组织优化功能,总结了常用的调优参数,为推动企业数据湖建设,提供可靠、高效、可扩展的数据湖解决方案积累了不少经验,能够帮助企业更好地管理和分析数据,提高业务决策的精度和效率。
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm 想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szkyzg
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
