

作者:vivo 互联网服务器团队- Gong Bing
本文将学术界和工业界的纠删码技术的核心研究成果进行了相应的梳理,然后针对公司线上存储系统的纠删码进行分析,结合互联网企业通用的IDC资源、服务器资源、网络资源、业务特性进行分析对原有纠删码技术进行优化和微创新,提出了融合EC整体方案以及可落地的RS+LRC+中间结果优化+并行修复跨AZ带宽设计方案,为后续的工程实践提供重要原理和架构支撑。
引言
本文借友商轮值CEO 于2020年8月28日在长沙“数学促进企业创新发展论坛”上分享的《后香农时代,数学决定未来发展的边界》【85】进行开篇,发言提出了后香农时代,ICT信息产业面向数学的十大挑战性问题,其中就有一项“高效的纠删码问题”,虽然这个问题的提出背景是出于通信编码领域,但对于纠删码在存储领域的使用同样面临着具大的机遇与挑战。

图1:纠删码问题挑战
针对纠删码的研究分为两派:
-
一派则是纯理论界针对纠删码编码技术在编解码复杂度、修复带宽及磁盘IO、存储开销等维度进行研究提出新的理论完备性证明过的纠删码,这类研究可能考虑更多的是理论完备性的证明;不会考虑工程界的实现复杂度等情况;
-
一派是不改变编码理论,利用纠删码结合生产环境进行适当改造(多AZ、异构服务器、大条带、跨rack等)再结合实验数据在修复开销、存储开销、可靠性等指标来证明价值。这两派的研究相辅相成共同推动纠删码技术在分布式存储领域的发展。
本次分享的主题“纠删码技术在vivo存储系统的演进”,分为上下两篇:
-
上篇侧重介绍和分析纠删码技术的演进历程、核心纠删码技术的原理和以及工业界存储产品当中的纠删码技术的探索与实践,最后介绍vivo存储系统在纠删码技术上的一些探索;
-
下篇重点展开介绍存储团队在纠删码领域的研究成果及纠删码研究成果在vivo存储系统中的实践,与工业界存储产品中的纠删码相关指标进行全方位对比,以及未来的一些规划。
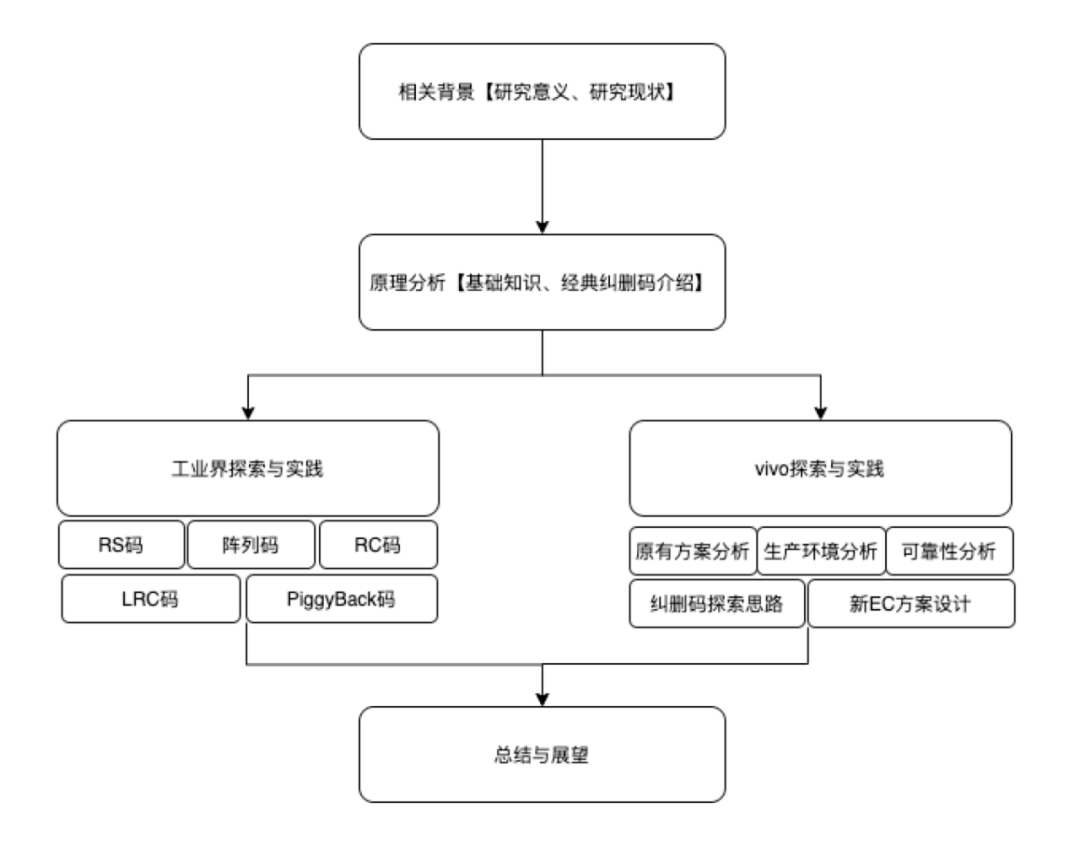
图2:本文的组织结构
注:本文当中有大量的专业术语,不可能所有术语都去作个解释,因此针对不懂的有些术语可以自行去搜索相关含义
一、相关背景
1.1 研究意义
分布式存储系统为了降低成本往往采用大量廉价通用的服务器提供服务,然而这些服务器的磁盘的可靠性是个很大的问题,其平均寿命在2-7年,还受外部环境因素的影响,受限于其机械构造,磁盘会发生磁盘故障、扇区故障和不可检测磁盘故障等。因此,分布式存储系统为了提高原始数据的可靠性,副本和纠删码是两种最常见的数据冗余方法。副本将原始数据复制到n份,并存储到不同的存储节点上,能够容忍任意n-1个节点失效,其缺点是存储开销大。纠删码则以计算资源换存储资源,采用了一种更高效的方式增加数据冗余,因此,纠删码成为了当前云存储的主流数据冗余方式,并且持续成为学术界和工业界在存储领域的一种研究热点。

图3:使用纠删码技术公司列表
1.2 研究现状
纠删码也被称为纠错码,它将原始数据编码为数据量更大的编码数据,并能够利用编码后的部分编码数据恢复出原始数据。当有节点发生故障时,要恢复这个节点的数据需要读取多个节点的数据,这个过程会消耗大量的网络带宽和磁盘IO,另外解码复杂度对业务可用性和数据可靠性也有影响,解码复杂度越高,则临时修复时延就高,从而增加业务读取时延;因此,影响纠删码好坏的指标很多,主要有如下一些指标:以下指标都是以可靠性统一基准的前提下进行参考:
-
【编码复杂度】编码复杂度决定了数据写入的时延
-
【解码复杂度】解码复杂度决定了读取的时延以及节点故障时数据临时修复及永久修复的时延
-
【修复网络带宽】节点故障时数据修复所需消耗的整体网络带宽,这个指标非常关键
-
【修复磁盘IO】磁盘IO消耗和网络带宽一般成正比,考虑大部分存储服务器是高密服务器,一般网络会是瓶颈
-
【修复节点数】修复节点数减少,往往也就降低了修复需要的网络带宽
-
【更新复杂度】更新复杂度是指一份数据有少量更新操作,比如更新一两个字节很频繁所涉及的相关操作复杂度
-
【存储开销】这个指标是指的编码效率,编码效率越高,存储开销越低
-
【参数限制】比如纠删码的码长受不受限制等等
以应用最为广泛的【n,k】RS码【2】为例,RS的码长为n,码的维度为k,当出现有节点故障时,需要k个节点进行恢复,同时可以容忍n-k个节点的故障,这种编码也被称为最大距离可分纠删码MDS【3】,对应上述指标也就意味着相同的容错能力下RS码的存储开销小,另外RS码的码长不受限制,这也是RS码如此受欢迎的原因;而在通信领域大杀四方的LDPC【4】纠错码在存储领域应用较少,原因就是因为LDPC不满足MDS特性,容错能力不限,意味着相同的容错能力LDPC需要更大的存储开销, LDPC更多是应用在磁盘内部的冗余;而得益于早期在RAID5和RAID6中的广泛使用,具有MDS特性的阵列纠删码也被尝试着应用在分布式存储系统当中,MDS阵列码相对于RS码全是异或操作,编解码相对RS码复杂度低,但是同时相关参数有所受限,这也抑制了它在分布式存储的广泛应用;常见的阵列码有EVENODD码【5】、RDP码【6】、STAR码【7】支持3容错、Liberation码相对EVENODD更新复杂度接近理论下界【8】,ZigZag码【9】磁盘IO开销达理论下界,Blaum-Roth码【10】基于多项式环上构造的MDS阵列码,相对于RS是编解码复杂度要低些。
另外针对RS码高昂的网络修复带宽,涌现出一类再生码【11】来降低修复中所要消耗的带宽。再生码是一类通过允许节点发送编码过的数据来使得修复中可最小化修复带宽的纠删码,其可在不增加存储开销的情况下显著降低修复带宽。Dimakis等人将再生码分为两大类:MSR码【23-47】和MBR码【12,13】。MBR码是最小化修复带宽主要分为Polygonal MBR Code【14】和Product-Matrix MBR Code【15】;MSR码是在最小化存储开销下降低修复带宽,又分为精确修复码和功能修复码,精确修复码是指通过修复可修复出原始丢失数据,功能修复码则不保证,数据读取每次都需要进行解码操作。比如Hu等人提出了一种功能性MSR码F-MSR【16】,精确性MSR研究主要基于Product-Matrix MSR【26】,还有比如Butterfly码【48】、Coupled Layer Code码【38-40】等当前已经在工业界有所应用的再生码。最近又有一些工作【18,19,20】是针对跨机架带宽和机架内带宽进行区分,为最小化跨机架带宽为目标减少修复带宽。降低修复带宽还有一些其它的研究工作,比如2013年Rashmi等人提出Piggybacking框架【22】,框架以MDS码为基本码通过将子条带数据嵌入其它条带来显著降低修复带宽,Piggybacking框架的编码设计也有很多研究成果。【79-81】
针对修复节点数降低这个指标,Huang等人提出了一种局部修复码LRC【17,21】通过对传统编码数据块进行分组,并针对每组生成校验块,从而使得单块修复只需要组内节点参与修复提高修复性能。但由于引入额外存储开销,LRC没达到存储最优。但由于LRC的简易性,工业界有很多的实践反馈,因此LRC逐渐成为近年来纠删码领域的研究热点【66-78】。LRC的一个分支MRC码的研究PMDS也吸引了不少关注【49-60】,除了单节点修复相关的LRC码的构造,针对修复多个节点的LRC码【62-65)】是一个研究方向,另外,结合LRC和RC的Local Regeration Code【61】也是个研究思路。
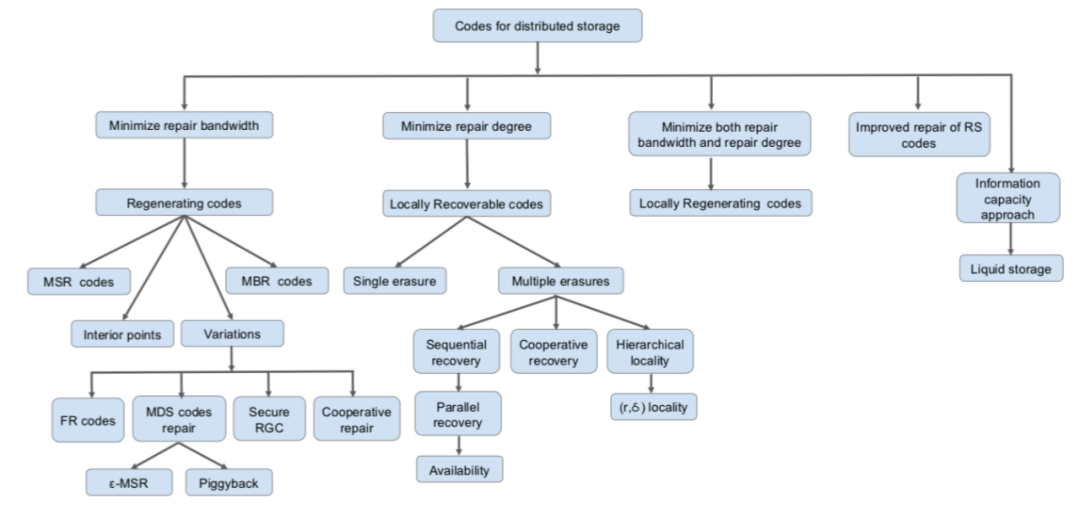
图4:纠删码研究方向概览
二、原理解析
2.1 基础知识介绍
概念1:纠删码原理
纠删码通用由两个参数n和k来进行配置,称为(n,k)编码。在分布式系统当中,通常将数据以固定大小的块进行组织,编码时,存储系统将k个数据块进行编码生成额外的n-k = m个大小相同的校验块,这样n个数据块和校验块中有任意的磁盘节点故障,都可以通过其它的磁盘节点进行解码恢复丢失的数据。以下为纠删码的一个示意图:

图5:纠删码原理示意图
概念2:Singleton顿界
假设C是一个参数为[n,k]的线性码,则C的极小距离d≤n-k+1。以上表明一个线性码的极小距离不会“太大”,无论怎样努力,都不能够构造出一个参数为[n,k]的线性码,使得它的极小距离大于n-k+1,这个n-k+1就称为Singleton界。
概念3:MDS特性
一个参数为[n,k]的线性码C,若满足dmin(C)=n-k+1,则称该码为极大距离可分码,简称为MDS(Maximum Distance Separable)码。
概念4:系统性
系统性就是系统中存储了k个数据块可用来直接存取,如果故障的节点没包括数据块,则不影响数据的读取,系统性可降低读取时延。非系统性则在每次读取时都需要进行解码操作,读取时延相对偏大。
2.2 经典纠删码介绍
2.2.1 Reed-Solomon Code
RS码最早是ECC领域的一种纠错算法,RS编码算法是一种典型的系统编码,也是一种典型的MDS性质的编码。
RS码基本思想其实就是拉格朗日插值多项式,我觉得用拉格朗日插值多项式来推导RS码相对于其它文献的讲解会更清晰,下面我们简单回顾一下拉格朗日插值多项式:对于任何k阶的多项式函数f(x)=a0+a1x+a2x^2+…+akx^k,我们很容易通过任意的n+1个点(x0, f(x0),(x1,f(x1)),… (xk,f(xk))对这个多项式进行恢复。

解码过程如下:
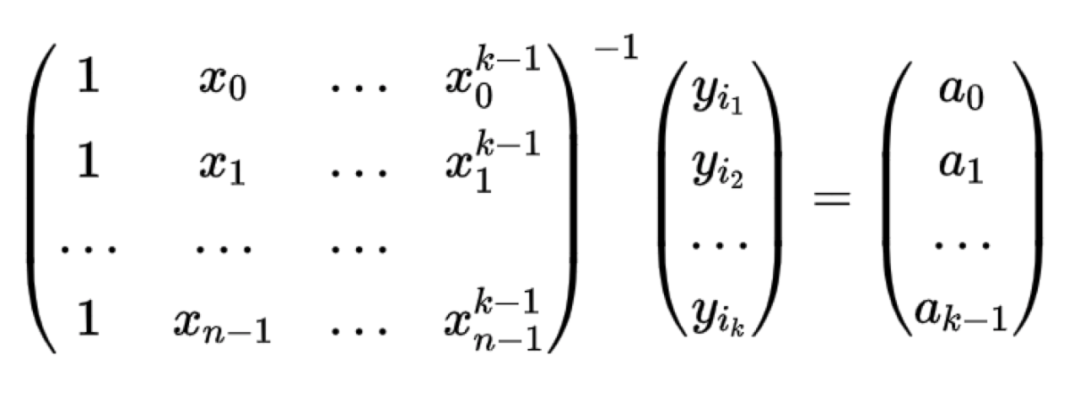
那么RS码是如何使用拉格朗日插值的呢?对于一个(n,k)的RS码,假设a0,a1,…ak-1在Fq域内的k个发送信号,我们在Fq中采样n个插值点x0,x1,…xn-1,则可以得到拉格朗日插值多项式为:
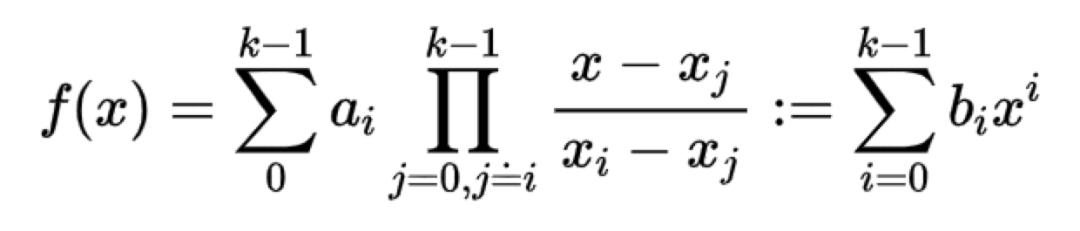
不难发现,前k个插值的多项式值有如下:

如果用矩阵来表示则为:
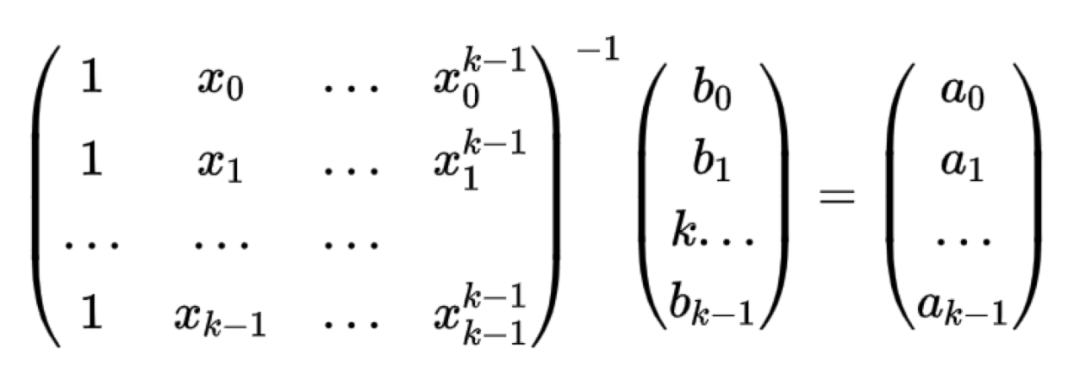
令上式的范德蒙德矩阵的逆*a向量 = b向量,则校验矩阵有如下:
【A|B】【A^-1】 a向量= 【E|BA^-1】* a向量 = 【a0,a1,…ak, c1,…cn-k】
这样就有了经典的(A Performance Evaluation and Examination of Open-Source Erasure Coding Libraries For Storage)描述Reed-Solomon码的编解码方式如下图所示:
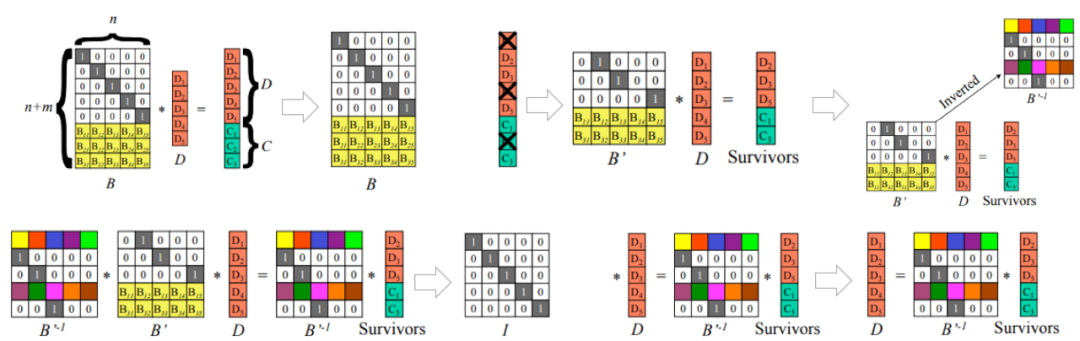
图6:RS编解码示意图
可以看出,RS(n,k)码一个满足MDS性质的编码,当有数据丢失需要k个节点同时进行恢复,另外,允许n-k+1个节点同时数据丢失。
2.2.2 MDS Array Code
MDS阵列码是一类比较特殊的线性分组码。阵列码相对于RS码避免了有限域计算,仅通过异或运算实现纠删码。在这类码中,符号均为m维的列向量,从而每个码字都是一个m*n的二维阵列。绝大部分的阵列码都是二元阵列码,阵列码的每一列可以全是数据位也可以既有数据位也有校验位。以下为一个m=2, n = 5, k = 3的阵列码的示意图:
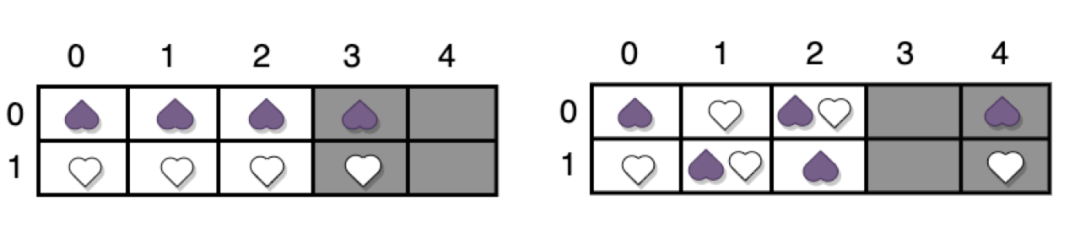
图7:陈列码示意图
不难看出该码的奇偶校验方程为:
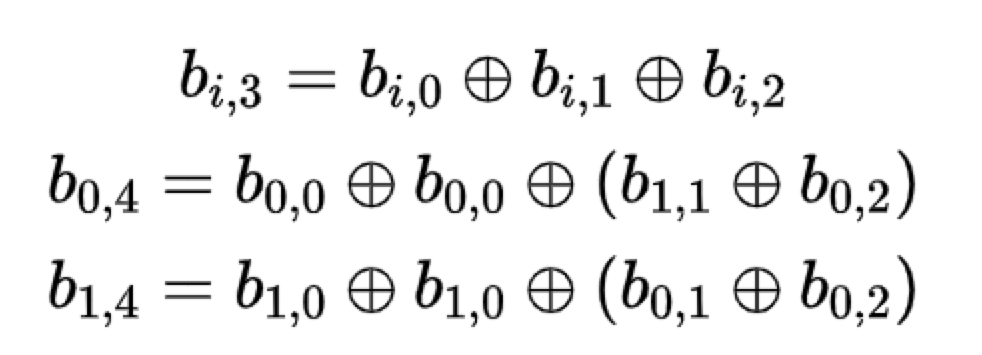
(1)EVENODD Code
EVENODD码是一种允许丢双列的容错码,有两列的校验列,是继RS码后最先运用在RAID当中的码,它是一个(m-1)*(m+2)的阵列码,其中m是一个素数。第m+1列和第m+2列的编码方式如下:
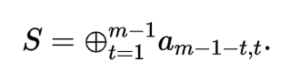
另外,对于每一个l,0

可以看到,第m+1列校验码的构造是前m列的数据位的异或;第m+2列的校验码的构造则是通过追加沿斜率为1的对角线异或和来达到容错目的。EVENODD码推出后,针对斜率不为1引入到纠删码的研究作为EVENODD码的推广为也就不足为奇。

图8:EVENODD码示意图
(2)RDP Code
RDP码的码字结构与EVENODD码非常类似,只是比EVENODD码少了一个数据列,是一个(m-1)*(m+1)阵列码,其中m是一个素数。RDP相对于EVENODD编解码复杂度都要低不少,因此在RAID应用广泛。
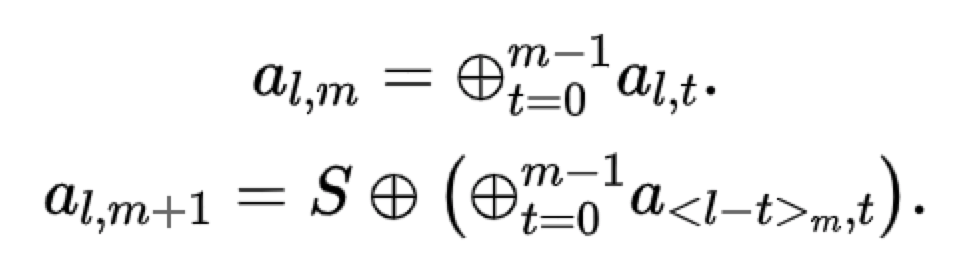
RDP码的编码结构示意框图如下所示:
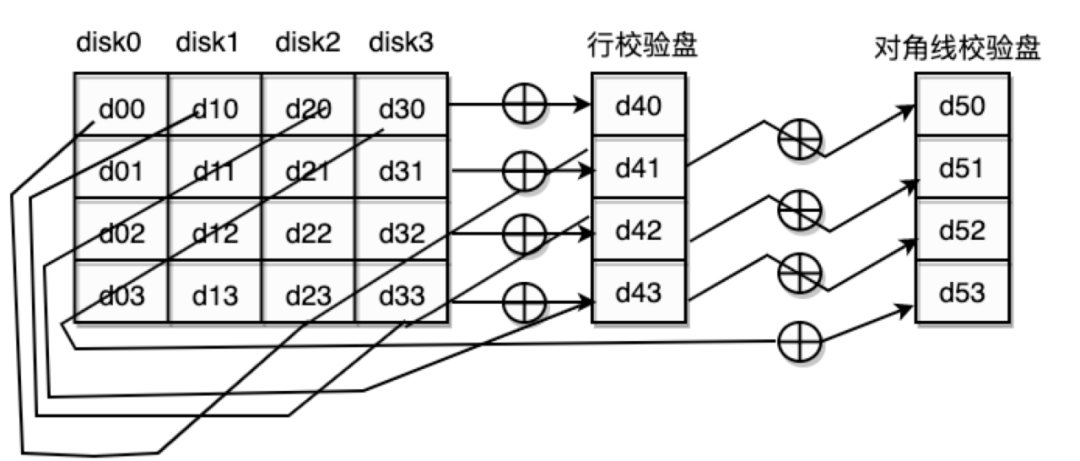
图9:RDP码示意图
2.2.3 Regeration Code
在讨论再生码这前我们来分析一下存储开销和修复开销的关系,从定性分析,我们很容易理解,当码率越大,存储空间效率越高,修复所需要的数据量就越大。A.G.Dimakis等人首次利用信息流图推导出存储开销与修复开销满足以下:

其中,alpha代表每个节点存储数据量,belta代表修复过程中每个参与节点传输的数据量,d代表辅助节点的个数。那么存储开销为所有节点存储量的总和。n* alpha。而修复开销是所有参与修复的存储节点所需要传输的数据量,d* belta。不难看出,alpha和belta不可能同时最小,alpha最小也就是M/k;belta最小也就是上式所有的(d-i)* belta都最小,可以求得d * belta = 2Md/(2kd-k^2+k)。
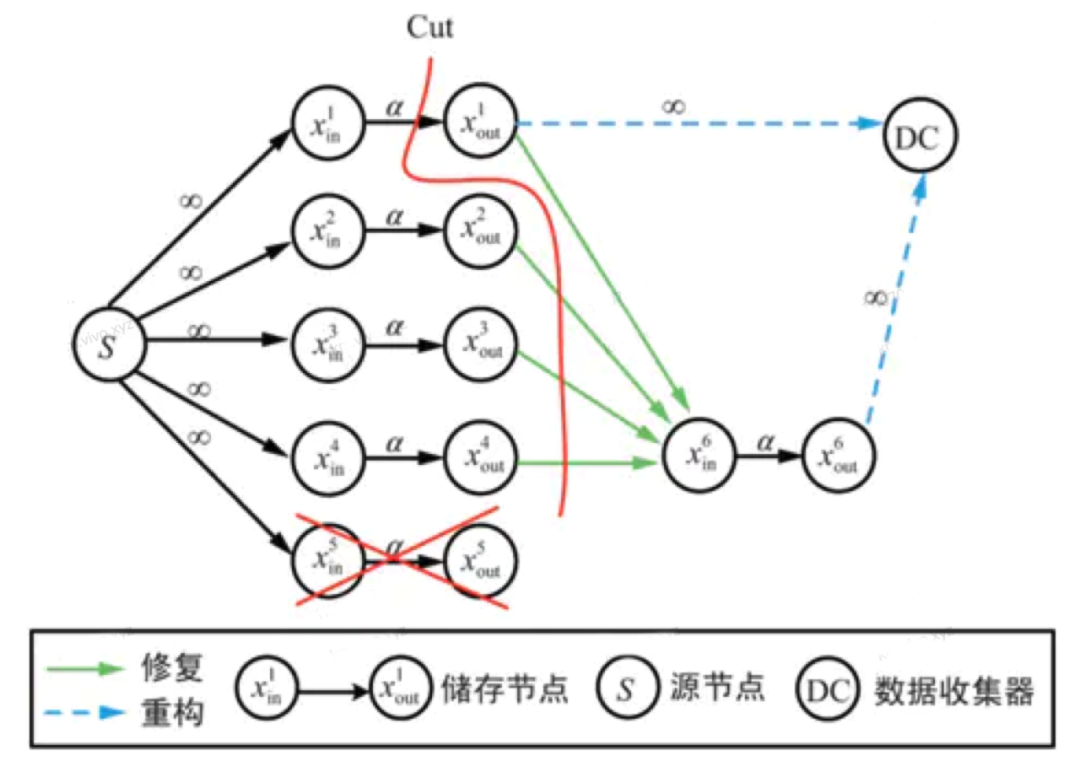
图10:再生码信息流图
(1)MSR
MSR全称为最小存储再生码Minimum Storage Regenerating码,不难理解,MSR是保证了存储消耗最小,所以MSR的存储数据块大小和失效修复带宽值计算公式如下:
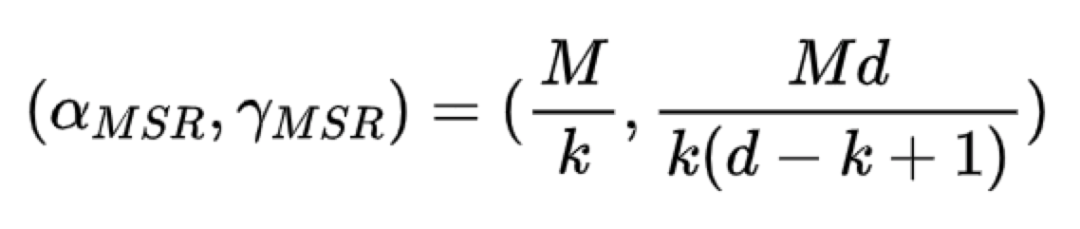
具体的编码方式就不介绍了,在下一章节介绍的Clay码就是MSR的一种工业上的应用MSR码。通过公式不难看出,d越大,修复开销越小。MSR的研究方向学术界和工程界侧重点有所有同,学术界是不考虑分包数大小,为了不断逼近最小的修复带宽去尽可能设计MSR码或者固定分包数然后在固定分包数下不断的去降低修复带宽;而工程界则更多考虑设计出分包数不高但是修复带宽低的MSR码,因为需要考虑工程实现。
(2)MBR
MBR全称为最小带宽再生码Minimum Bandwidth Regenerating,不难理解,MBR是保证了单节点失效修复带宽最小,所以MBR的存储数据块大小和失效修复带宽值计算公式如下:
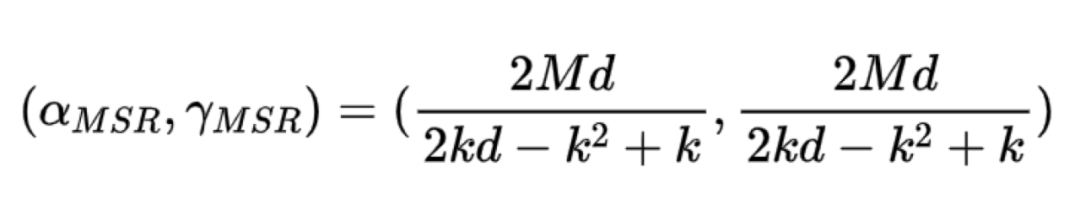
MBR相对于MSR实用性没有那么高,原因是因为分布式系统更多的是在存储开销最小化的情况去尽量降低修复带宽,因而MBR的研究热度没有MSR那么高。
2.2.4 Locally Repairable Code
局部修复码则是通过一类增加额外的存储来将数据修复尽可能在少量节点内完成,从而达到大大降低网络开销操作的纠删码。由于引入了额外的存储开销,局部修复码并没有达到存储最优。但是局部修复码实现简单,因此生产环境有了很多的实践,当前,LRC编码成为最近几年纠删码研究领域的一个热点研究方向。
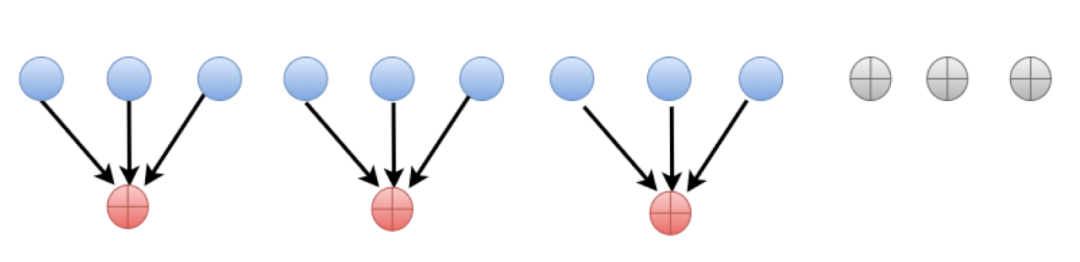
图11:LRC码示意图
Singleton-型上界:
针对于一个(n,k,r)的局部修复码,即码长为n的码中有k个信息位和具有局部修复性r,则有一个经过证明的该码的最小距离d(C)满足上界如下:
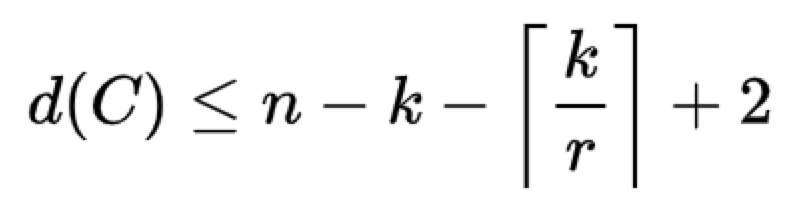
任何一个达到这个界的局部修复码称为最优局部修复码。因此,设计达到最优局部修复的码是LRC方向的一个研究热点。
上述局部修复码只能修复一个故障节点,多个故障节点没有考虑,学术界针对多个故障节点的LRC修复引入了(n,k,r,gama)-局部修复码,针对多个故障节点修复的局部修复码满足上界如下:
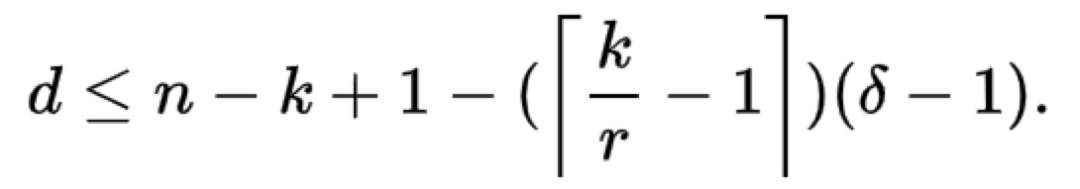
2.2.5 piggyback框架
piggyback框架严格意义上是MSR的一个子集,piggyback框架的核心思想是通过扩展后MDS码的子条带数据嵌入到其他子条带的操作,在不改变原有编码结构的情况下显著降低修复带宽。
例如,以一个(4,2)MDS码如图所示,它有两个子条带,每个子条带上分别有两个信息数据,每个子条带的后两位存储该条带的数据线性组合,图左1为MDS码,图左2为piggyback编码,我们来分析一下右图1和右图2两种节点故障的情况下修复带宽的消耗情况:
(1)右图1修复:传统MDS码:任意2个节点的2个符号来修复;piggyback码:b2, b1+b2, b1+2b2+a1这三个符号可以修复a1, b1两个符号;
(2)右图2修复:传统MDS码:任意2个节点的2个符号来修复;piggyback码:b1,b1+b2, 2a2-2b2-b1这三个符号可以修复a2,b2两个符号。

图12:PiggyBack框架示意图
三、纠删码行业探索与实践
在第二大章节以经对当前纠删码几个核心领域的编码原理进行了阐述,本章则介绍这几个核心领域的纠删码在工业界的应用。基本上每种类型的纠删码都或多或少在工业界有具体的编码算法及实践经验。为了保持和第二章的顺序保持一致,本章也从RS码、阵列码、RC、LRC、PiggyBack这几个方向应用于工业界的具体编码顺序进行详细介绍。
3.1 RS:CRS
首先是应用最为广泛,也是最成熟的RS码,当前工业界大多数的纠删码都是基于该编码实现的。虽然RS码的修复带宽一直是一个痛点,但是由于其基本上每家公司的最早的纠删码算法上线都是基于RS完成的。比如早期的Google、AWS、阿里、腾讯、华为、百度等公有云厂商。
3.2 阵列码:HashTag
An alternate construction of an access-optimal regenerating code with optimal sub-packetization level
3.3 MSR:Butterfly
butterfly是FAST 2016年的一篇论文提出的编码算法,最多可校正2个节点故障的数据丢失,算法只涉及XOR操作,性能较好。节点故障后只需要所有节点的1/2数据参数修复。由于编码操作用线相连对应符号位看起来像蝴蝶一样,如下图所示,所以取名butterfly code。
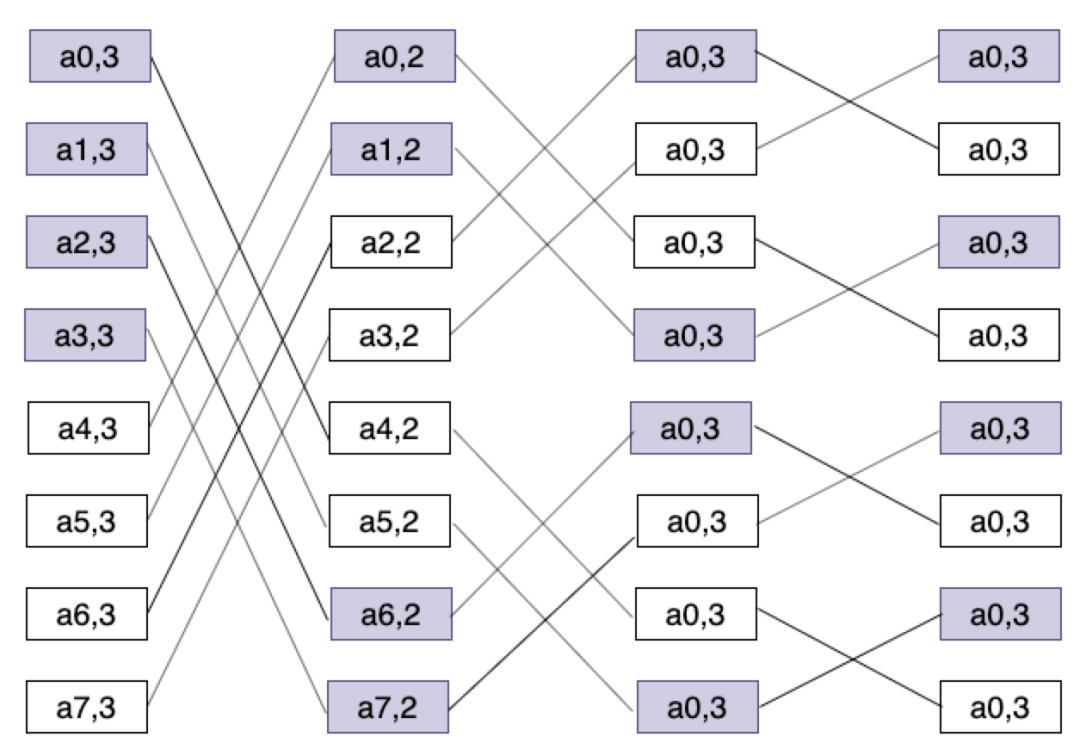
图13:Butterfly码示意图
编码方法:
首先数据符号需要转换成一个bit矩阵2^(k-1) * k记为Dk,用矩阵表示如下:

其中,A,B是2^(k-2) * (k-1)的bit矩阵,a,b则是一个包含2^(k-2)个元素的列向量。如果把 butterfly编码后的码字记为:Ck = (Dk−1 k ,…,D0 k ,H,B),则不难看出,H,B分别带为butterfly后的一个水平校验列和butterfly校验列。H,B的生成遵循如下递归准则:
如果 k = 2,那么有:
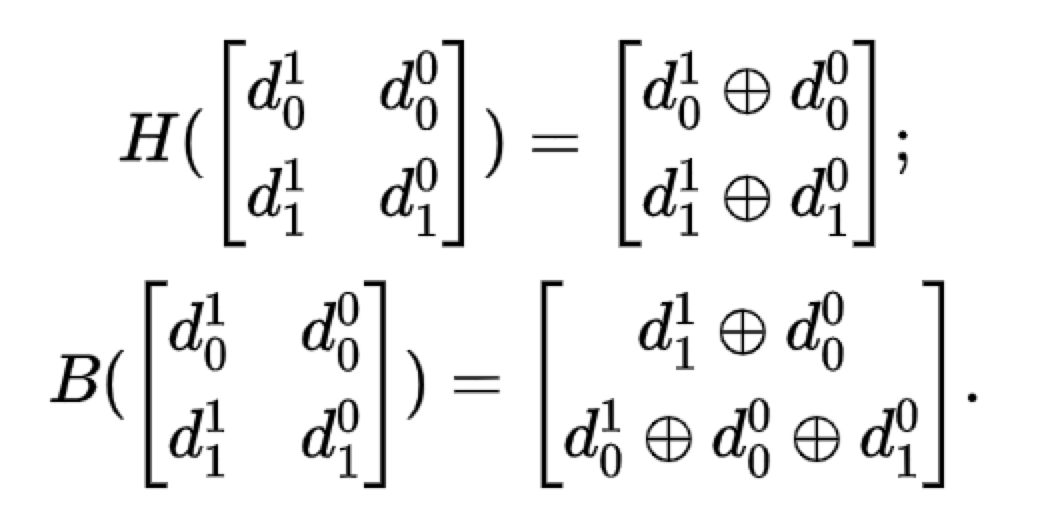
如果 k > 2,那么有:
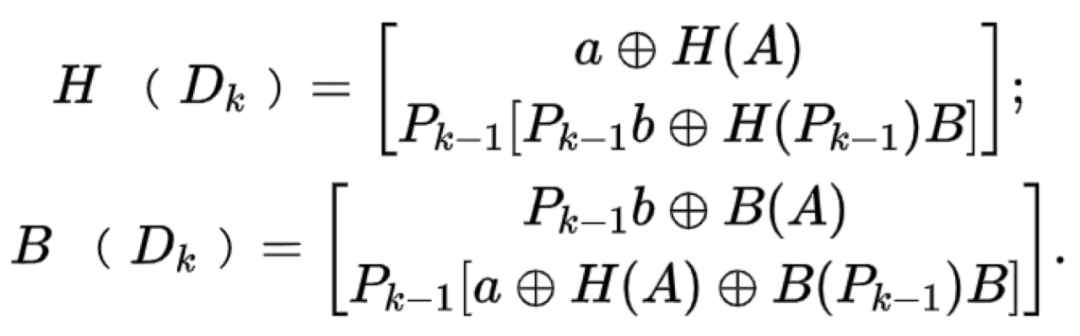
其中,Pk带表一个包含2^k * 2^k个元素的矩阵,矩阵的副对角线元素为1,其余元素为0。下图为一个k = 4的 butterfly编码:
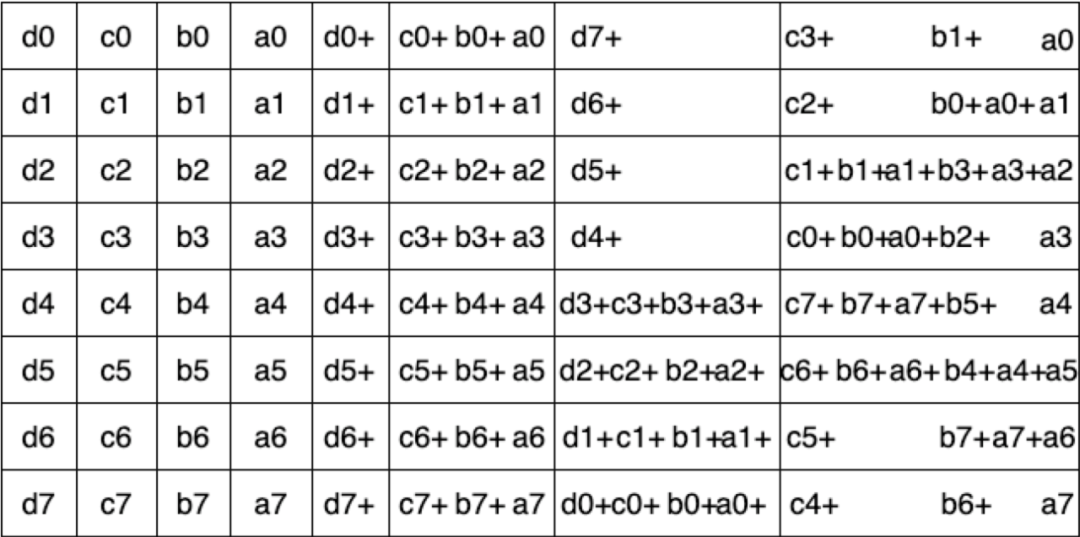
图14:k=4 Butterfly编码构造
3.4 MSR:Clay
Clay码是FAST 2018年的一篇论文提出的编码算法,Clay码能够将一般的MDS码转化为MSR码,Clay码包含两个特点:1 将MDS码分层处理;2 分层之间数据耦合,以(4,2)Clay码为例,为了更形象了解编码方式,将编码后的数据放在棱形柱上,其中alpha = 4,也就是有4层,原始数据如下:
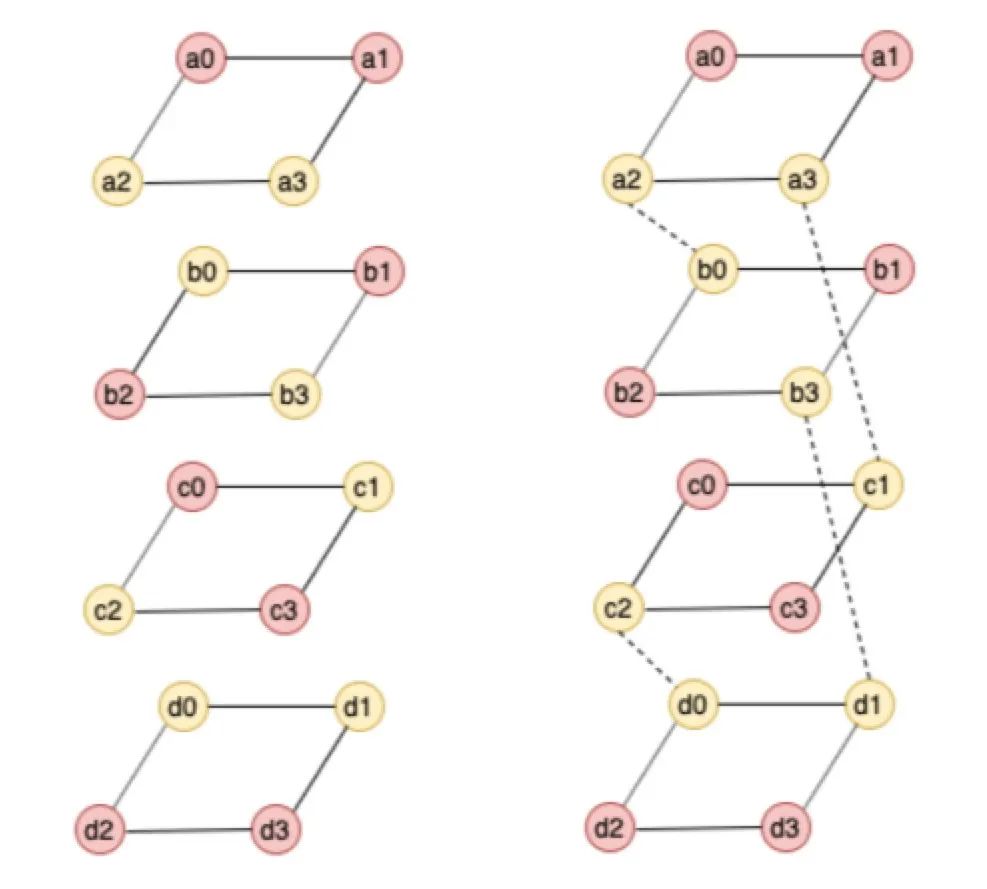
图15:原始数据结构
图中被耦合的数据用黄色表示,耦合关系如上图右虚线表示,黄色数据块存储的是耦合之后的数据,也就是不再是系统码,相当于解码需要进行解耦合才能得到原始数据。
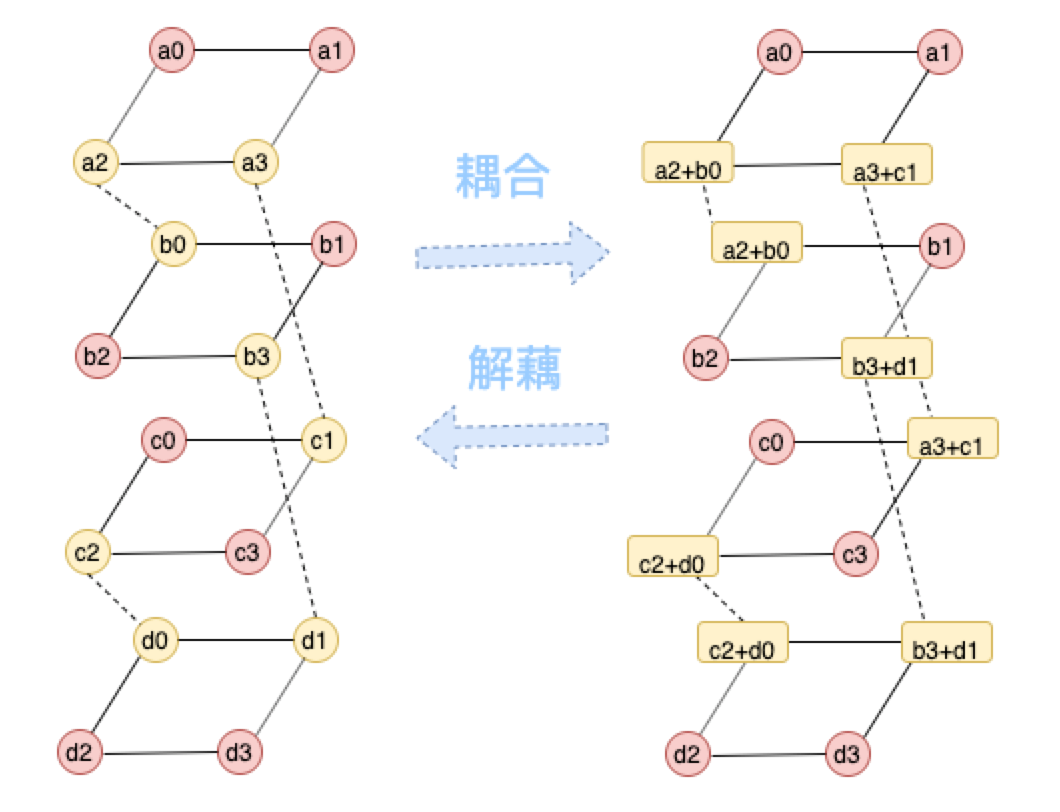
图16:CLAY编码结构
当有一个节点失效后,CLAY码的修复过程如下:
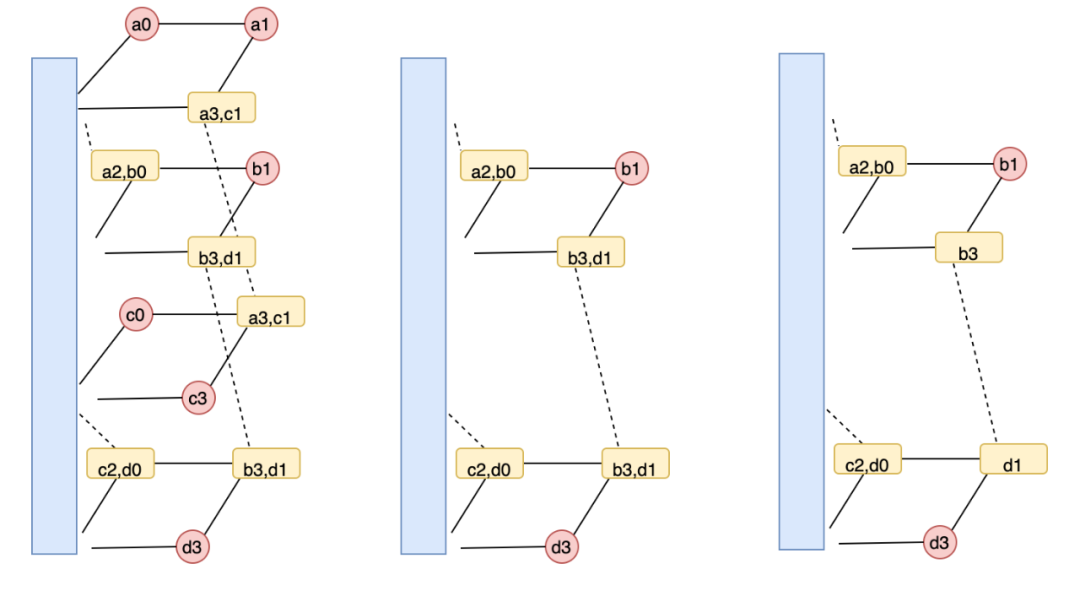
图17:CLAY修复结构
Clay 修复该节点失效只需要第二层和第三层的剩余数据块(如上图(中)所示),修复步骤如下:
-
两个耦合的数据块(b_3,d_1) 和[b_3, d_1] 解耦得到b3 和d1,如上图(右);
-
第二层通过b1,b3 的MDS 解码得到b_0, b_2,第四层MDS 解码得到d_0,d_2;
-
利用第二层中[a_2, b_0] 和步骤2 得到的b_0 得到a_2,同理得到c_2。
简单推导可以发现其他三个节点也可以以最小开销完成数据修复。
3.5 LRC:azure、yottachain LRC
局部可恢复码LRC是微软在2012年FAST发表的一篇论文,该论文同时也是当年FAST的best paper。核心思路就是通过引入局部校验位来辅助全局校验位进行节点故障后的修复,由于局部校验节点的存在,所以当有一个节点故障的时候可以只用局部少数节点进行恢复,而不需要全局节点进行恢复提升修复带宽。以下以(6,2,2)LRC为例进行介绍:
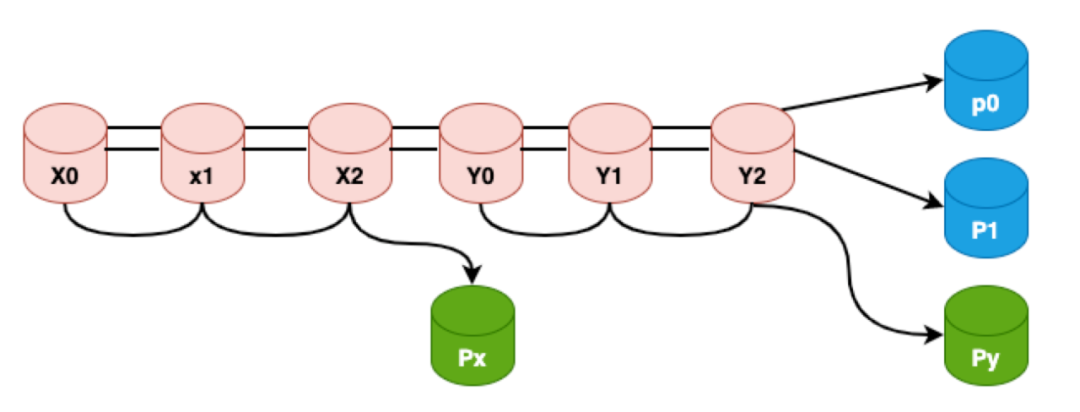
图18:全局&局部校验示意图
如上图所示px,py为局部校验节点,p0,p1为全局校验节点,不难看出,虽然LRC有4个校验节点,但是LRC不满足MDS性质,比如x0,x1,x2,px 4个节点全都故障,LRC无论如何校造都是无法恢复的,因为全局校验节点只有2个,而py和x0,x1,x2无关,所以无论如何都恢复不出来x0,x1,x2这三个数据节点,这种故障也称为信息论无法解码故障;虽然LRC不能容忍这种场景的4个节点故障,但是如果LRC构造得好,是可以达成其它场景的4个节点的故障,比如下图所示:
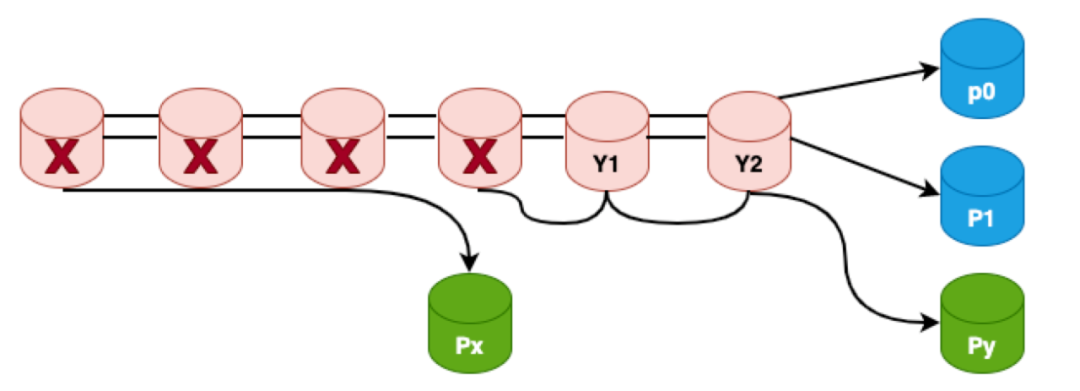
图19:4数据节点失效示意图
a图是x0,x1,p1三个节点故障,b图是x0,x1,y0,y1四个节点故障,这类故障是有可能重建的也称为信息论可解码故障。那么LRC的研究就是设计合理的编码方式来尽可能的覆盖所有信息论可解码故障场景,当LRC的构造方式覆盖了所有信息论可解码场景则称LRC码符合Maximally Recoverable(MR)性质。 (6,2,2)的校验位构造方程如下:
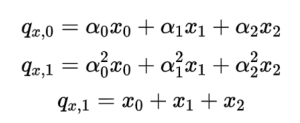
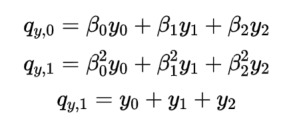
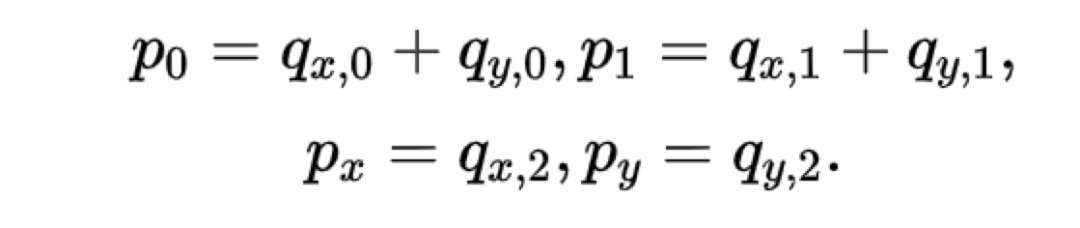
然后该编码构造方法需要覆盖所有理论可解码故障场景比如以下三种典型场景:
(1)4个节点全故障,平均分布在6个数据节点
这种场景则不难看出要想可求解就必需保证:
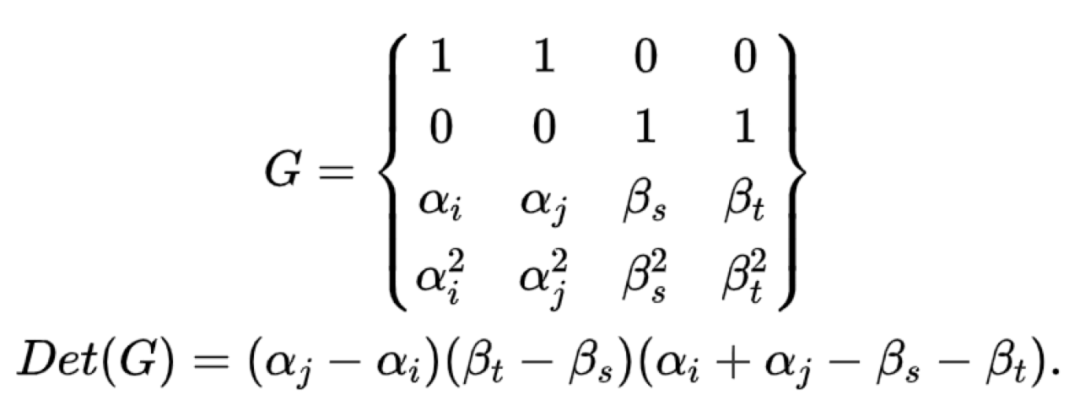
G的行列为不为0,G矩阵是奇异矩阵。
(2)px,py中有一个故障,假设是py故障,则必须有:
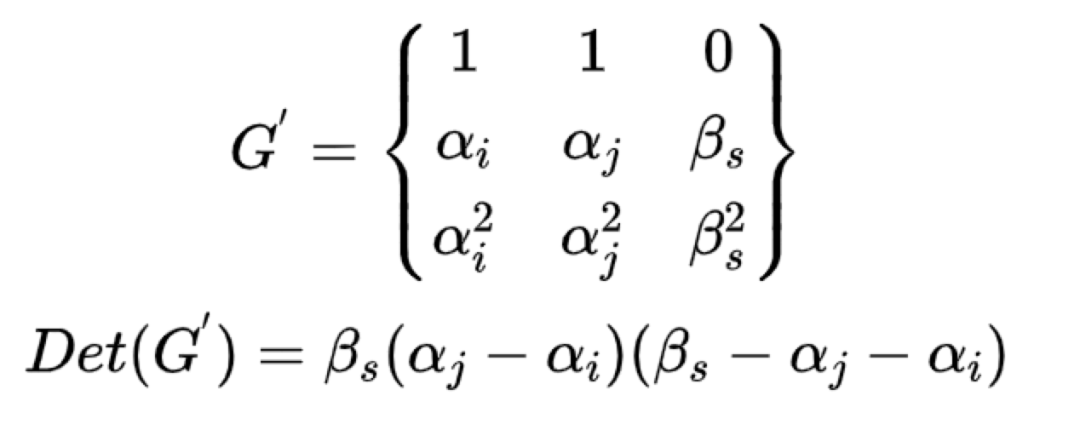
(3)同理如果px,py全故障,则必须有:
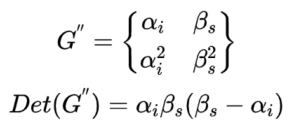
因此,alpha,belta的取值必须满足上述矩阵的行列式不为0。(6,2,2)LRC与(6,3)的RS对比不难发现:LRC可靠性略高,成本也略高,修复带宽几乎是原来的一半。
3.6 piggyback:Hitchhiker
piggyback框架的一个典型的工业界的应用实践场景是facebook在2014年提出的,当时facebook的f4系统原本也是用(10,4)RS纠删码来降低冗余度,但是RS码的修复带宽非常高,据当时统计数据,facebook一个PB级的集群中因为节点恢复所需要消耗的网络带宽达到了180TB。所以facebook针对冷存集群提出了一种基于piggyback框架的Hitchhiker编码来降低修复带宽。
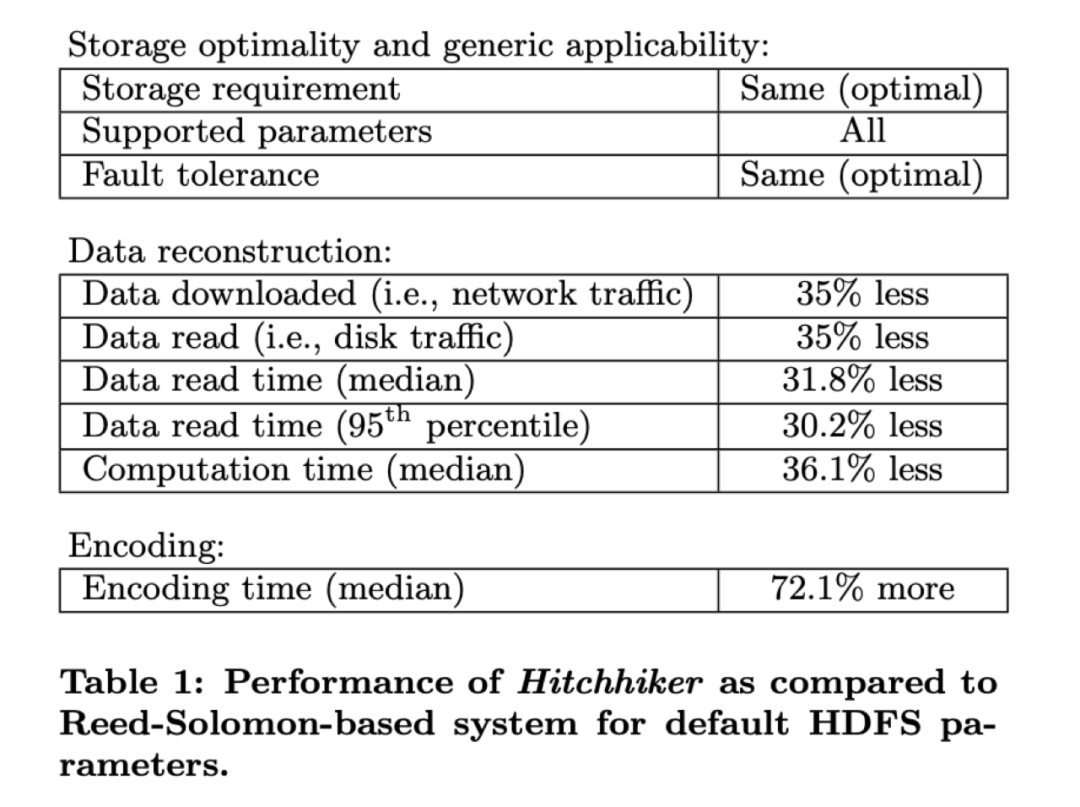
(1) Hitchhiker-XOR
传统的(10,4)的RS编码如下图左1所示,引入piggyback框架后则编码方式如下左2所示,Hitchhiker-XOR编码方式如下右1所示:
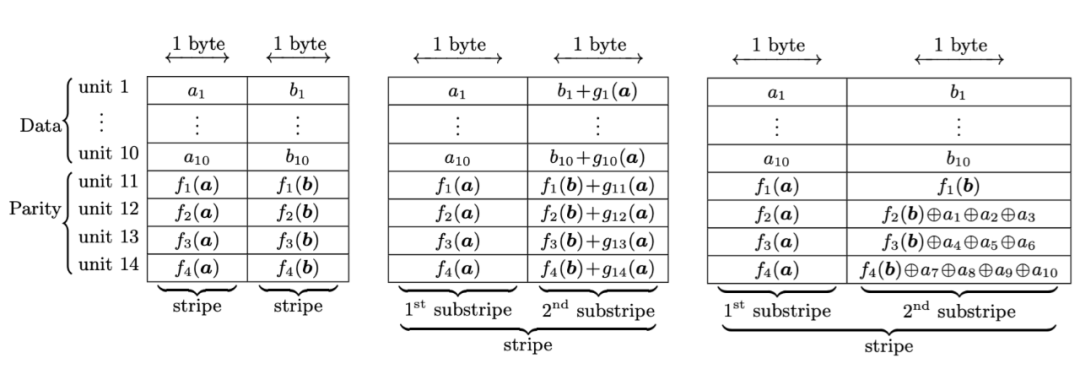
图20:Hitchhiker-XOR编码示意图
编码:
4个校验单元:f1保持不变,f2引入a1,a2,a3的奇偶校验位,f3引入a4,a5,a6的奇偶校验位,f4引入a7,a8,a9,a10的奇偶校验位。
修复:
当1-3有一个节点故障,则可以通过,b1-10,f1(b)中的任意10个但愿恢复出故障的bi,然后可以通过f2函数计算出f2(b),再结合第2个子条带的第2个校验单元以及a1-a3中的2个单元一起,可以计算出ai,这样就把ai,bi修复出来了。 同理,当4-6有一个节点故障时,也是一样的,可以通过13个byte将ai,bi进行恢复。
而当7-10有一个节点故障时,则需要通过14个byte进行恢复,原因是第2个子条带的第4个校验单元是由a7,a8,a9,10四个组合,其中有一个失效,需要引入第1个子条带的3个单元才能进行恢复。
(2)Hitchhiker-XOR+
针对Hitchhiker-XOR算法,可以看到在第7-10节点故障时需要14个Bytes进行修复,XOR+通过对RS码进行适当限制来降低这一部分的开销,限制条件如下:4个校验单元的函数f需要有一个满足:ALL-XOR性质,也就是子条带数据全部进行异或操作的同时满足MDS性质。通过该限制,则两个子条带的校验单元的编码方式如下图所示:

图21:Hitchhiker-XOR+编码示意图
修复:
不难看出,1-9节点故障时的修复是和Hitchhiker-XOR是完全一样的,只需要13个bytes进行修复,第10个节点故障时,则通过第2个子条带的1-10,13,14单元和第1条带的12单元可以恢复a10,b10,不难看出,恢复节点10也只需要13个bytes。
所以Hitchhiker-XOR+相对于Hitchhiker-XOR限制了RS码构造的条件,但进进一步降低了部分数据修复的开销。
(3)Hitchhier-NoXOR
这种编码是针对于Hitchhier-XOR+是引入了限制条件,为了消除这个限制条件,可以通过有限域运算的方式来达到Hitchhier-XOR+同样的效果,但是可以消除RS的校验生成限制,与此同时也是通过有限域运算开销来替换XOR操作。

图22:Hitchhier-NoXOR编码示意图
以上编码方式可以扩展到任意的(k,r),对于不同的k,r参数,HH码相对传统RS码可以降低25%-45%不等的开销。
3.7 纠删码对比
(n,k)纠删码,数据大小为M,划分为k份,生成m份校验数据 k + m = n,则相关纠删码算法的相关开销和性质总结如下:
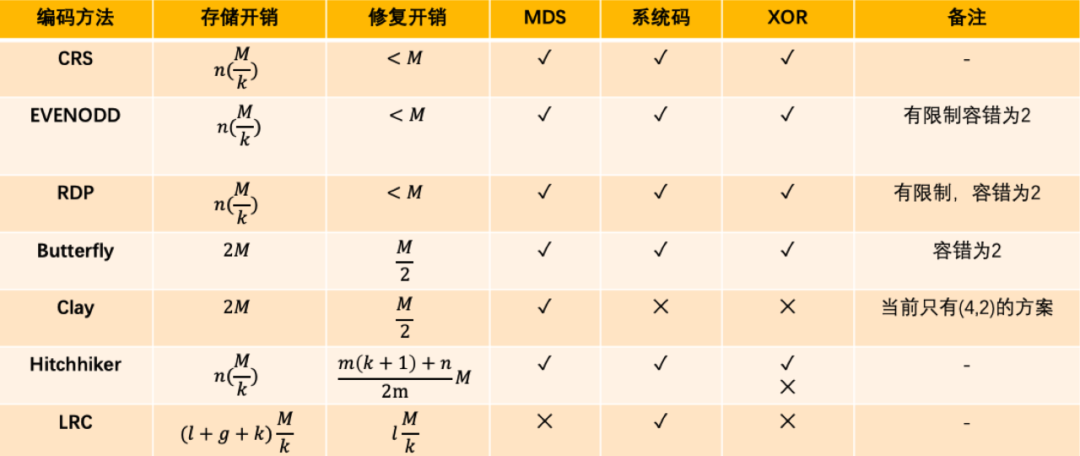
图23:纠删码算法相关维度对比
四、vivo 纠删码探索与实践
4.1 线上EC方案介绍
vivo对象存储的EC方案是采用RS纠删码,前面章节已经介绍过RS码是通过构造生成矩阵来编码数据块。生成矩阵可以采用范德蒙德矩阵,原因是因为范德蒙德矩阵是可逆的,另外,还有一种矩阵是也可逆矩阵那就是Cauchy矩阵,Cauchy矩阵是由两个交集为空的集合构成的矩阵,具体为:令C = [c(i,j)]m*n,有集合X = {x1,x2,…xm},Y = {y1,y2, …,yn},且X交集Y={空}。矩阵C中的元素cij满足:
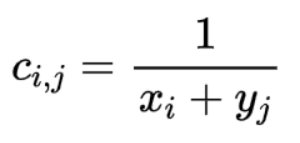
不难理解,如果不做优化,柯西编解码过程会充斥着大量的有限域的乘法和加法运算,为了降低复杂度,通过利用有限域任何一个GF(2^w)域上的元素都可以映射到GF(2)域上的一个二进制矩阵,例如,GF(2^3)域中的元素可以表示成GF(2)域中的二进制矩阵:
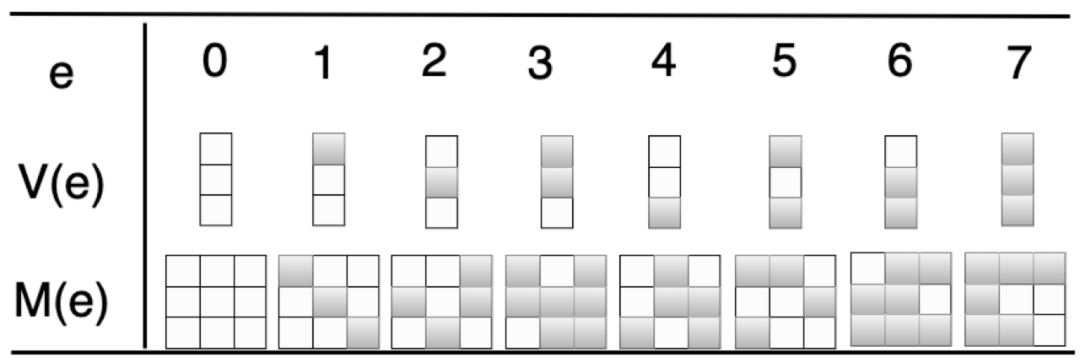
图24:GF(2^3)在GF(2)映射矩阵
其中,M ( e )的第i 列为V ( e ∗ 2^ (i − 1 )) 其中e ∗ 2^(i-1) 为G F ( 2 ^3 ) )上的乘法。
所以基于Cauchy矩阵的RS编码方案可以优化为bit-matrix为生成矩阵,原有的有限域上的乘法和加法也变成了有限域的“与运算”和“XOR”运算,从而提高编码效率。
在真正实现的时候, vivo纠删码的CRS编码和jeasure的CRS编码一样,针对bit-matrix在GF(2)有限域的与和OXR操作进行也进一步优化,就是通过将bit-matrix转化为一个schedule的方式,也就是一个五元组,其中,op操作是O,1对应是拷贝还是XOR,sd是源数据的id,sb为源数据中bit位的相对id,dd和db则为目的校验数据的id和校验数据bit位id。如下图针对一个k = 3, w = 5的bit-matrix对应的schedule操作为如下:
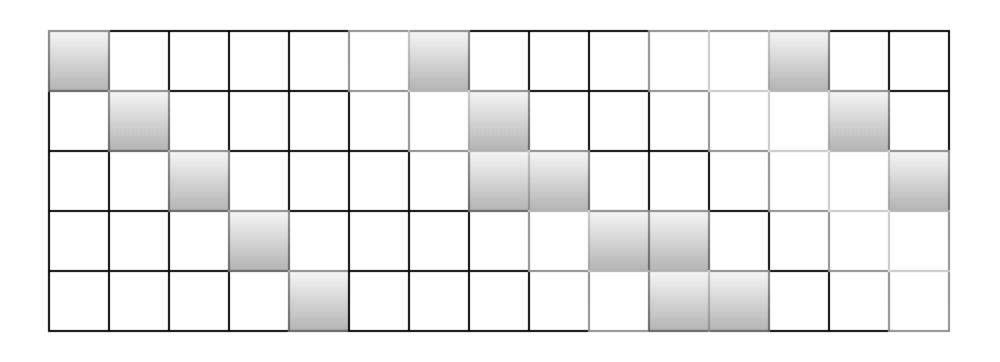

图25:bitmatrix的schedule操作
不难看出,通过schedule方式转化后编解码操作简化了好多,以下为一段C++代码:
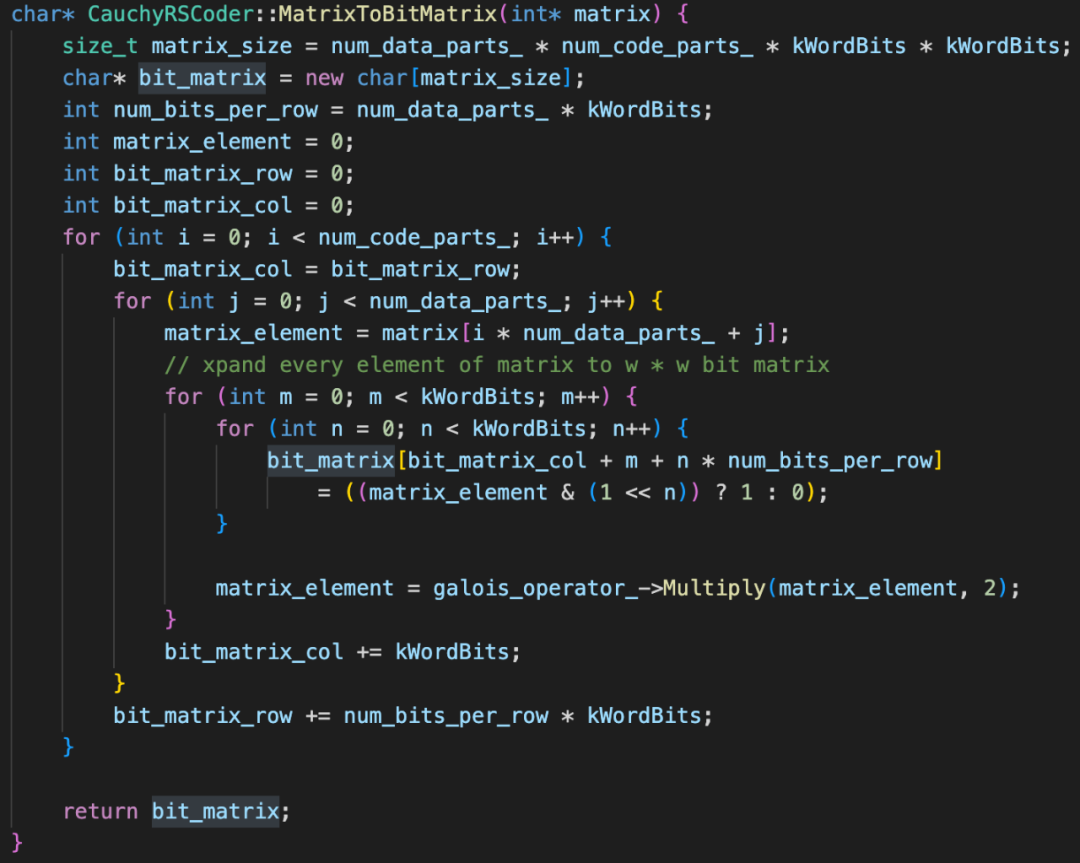
图26:存储纠删码schedule代码片断
4.2 生产环境分析
注:这里的生产环境分析章节是参照常规的业界生产环境部署规范进行假设和模拟,不代表本公司的真实生产环境。
4.2.1 IDC资源
现在很多公司为了能够防止数据中心因为某些不可抗力比如自然灾害、断电等极端情况导致整体故障而造成数据丢失和服务中断建设了多个数据中心,分布式存储服务可以通过将数据打散存储在多个不同的数据中心来保证当某个IDC故障后依然能提供稳定可靠的存储服务。纠删码技术通过将数据分块和校验码分块均匀打散到不同数据中心,实现同城容灾冗余。当某个数据中心不可用时,另外其他数据中心的数据依旧可以正常读取和写入,保障客户数据持久存储不丢失,维持客户业务数据连续性和高可用。
以下为一个同城冗余的示意图【引用自公有云多region多AZ机构】

图27:同城冗余机房示意图
4.2.2 存储资源
随着近年互联网业务的非速发展,互联网业务数据的规模及多样性也越来越复杂,各大公司的存储型服务器由于历史原因迭代过很多的版本,从4xTB到1x00TB容量不等的演进了有多种套餐类型,因此生产环境很难避免的有多种存储类型的服务器共存的情况出现,服务器的携带的HDD硬盘的块数和单盘的容量也不尽相同,单盘容量从4T到20多T不等,服务器携带的硬盘数目也从12到60多不等,还有各种其它类型的存储阵列比如JBOD产品(由多块60TB的硬盘组成的存储资源阵列)。
4.2.3 网络资源
如第1章所述,纠删码技术在海量分布式存储系统的引入为企业节省了大量的成本,但是在节约成本的同时,由于纠删码技术特点也带了带宽成本的上升,基于纠删码冗余的分布式系统在出现节点或硬盘故障时,需要多个节点进行同时恢复,这就需要大量的网盘带宽,而且以(n,k)RS码为例,1个RS码的节点故障,需要n个节点进行恢复,而副本技术的系统只需要1个节点参与,相当于纠删码技术的系统网络带宽放大了n倍速。因此,在IDC内部和IDC机房之间的带宽就成为了纠删码技术实施的关键因素。
以下为业界某司的IDC之间的网络拓扑架构如下:【引用自公有云多region多AZ机构】

图28:业界IDC带宽拓扑架构
而由于成本上的考虑,往往数据中心与数据中心之间的专线带宽都不会太高,但是传统的纠删码技术在提供低冗余度和高可靠的同时带来的是大理的修复带宽的成本,因此,跨IDC之间的纠删码技术不得不考虑IDC之间的带宽不大这个因素。
4.2.4 业务特性
-
对象存储业务特点1:通常接入对象存储的大规模业务的更新的操作比较少,因此原有的更新的操作消耗带宽成本高的痛点可以不考虑;
-
对象存储业务特点2:通常接入对象存储业务在线场景和离线场景区分比较明显;大存储业务呈现冷数据趋势;
-
对象存储业务特点3:互联网行业的数据类型丰富,一般对跨AZ和不跨AZ的需求有所不同,数据可靠性的要求各有不同;可用性指标各有不同。
4.3 vivo新纠删码方案
4.3.1 纠删码优化思路
-
基于纠删算法思考:通过对学术界和工业界的整体调研考虑实现复杂度和效果发现还是RS码还是当前工业界纠删码的主流,特别是对RS码引入并行修复后非常的适合降低跨IDC之间的带宽消耗;可以将大部分的带宽消耗收敛到IDC内部;
-
基于机房资源思考:基于多数据中心的数据分布考虑,纠删码可以考虑引入LRC,在数据中心内部引入局部校验块来进行数据中心内部的快速修复从而提高整体可靠性;
-
基于业务特性思考:根据互联网业务的通用特性分析可以将离线在线存储集群进行分离;以及数据可靠性要求进行规划EC集群,比如不考虑机房容灾的业务可以在同一个数据中心内部的不同Region进行部署EC集群;
-
基于服务资源思考: 互联网行业的存储服务器资源的存储和网卡配置迭代较快,线上这种异构环境导致的线上扩缩容操作都会引起集群可靠性的变化,因此引入可靠性评估模型对集群进行近实时的预估;
-
基于恢复带宽思考:优化目标是为了进一步降低EC冗余度但同时可靠性不降低,因此恢复带宽降低是一个重要优化思路,因此在全局引入并行修复和在局部引入MSR纠删修复的方式进一步降低恢复带宽。
4.3.2 可靠性模型设计
在优化思路我们提到引入可靠性评估模型来对集群进行近实时的预估,那么可靠性模型如何预估是合理的?当前并没有一个统一的可靠性评估方案,不过学术界基本都是基于马尔可夫链的MTTDL模型来进行EC的可靠性计算,工业界就没有特别统一的可靠性评估方案,在调研了行业内相关方案后我们的可靠性模型主要是基于MTTDL马尔可夫链模型再结合我之前分享的一篇【分布式存储系统的可靠性估算】形成特有的分布式存储可靠性模型估算方案。这套方案是结合了两种可靠性估算最合理的部分逻辑:MTTDL模型的理论严谨性 + 集群级磁盘故障的组合概率引入的必要性。
在介绍可靠性模型之前,我们先来看几个概念如下图所示:
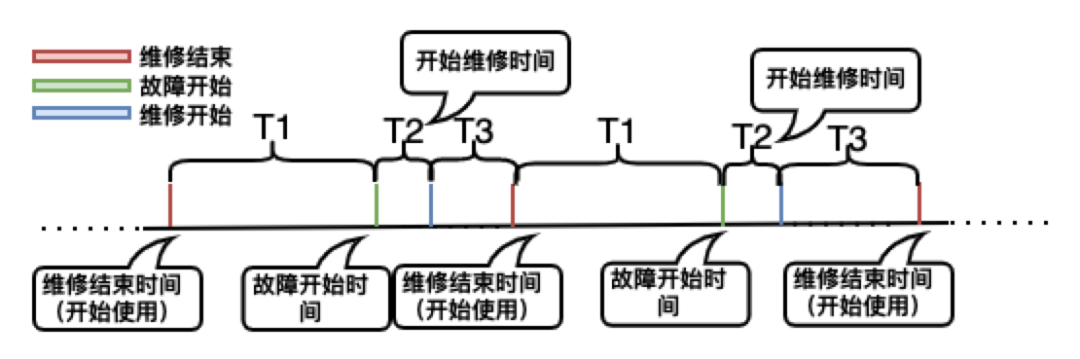
图29:系统故障处理流流程【时间线】
-
MTTF:Mean Time To Failure,平均无故障时间,指系统无故障运行的平均时间,取所有系统开始正常远行到发生故障之间的时间段的平均值,如上图的T1的平均值;
-
MTTR:Mean Time To Repair,平均修复时间,指系统从发生故障到维修结束之间的时间段的平均值。如上图的T2+T3的平均值;
-
MTTDL:Mean Time to Data Loss,平均数据丢失时间,换个说法也可以是系统两次故障发生时间的间隔平均值,如上图的T1+T2+T3的平均值。
(1)Markov可靠性模型
Markov可靠性模型是基于MTTDL进行预估的,Markov可靠性模型是基于下图来进行状态转移的:

图30:马尔科夫链的故障状态转移模型
初始状态为1状态,1状态为n块磁盘都没有故障的概率为1-n* ramda,从状态1转移到状态2则是有n*ramda概率,状态2恢复到1状态则由u决定,状态2转移到状态3的概率为1-(n-1)* ramda,则不难计算出维持2状态的概率如上图所示:
本文不对马尔科夫链状态转移进行详细推导,仅给出最终的MTTDL的简化版计算公式如下:
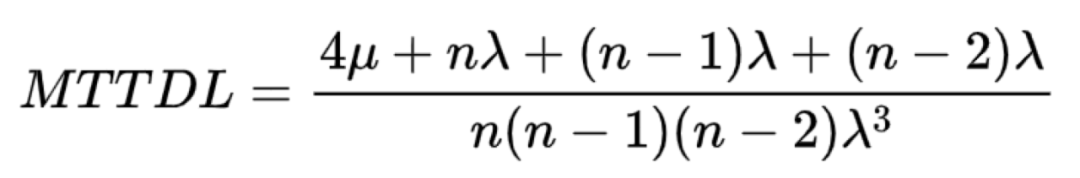
(2)其它可靠性模型
Markov可靠性模型是把所有磁盘都用在了数据的条带化处理,但是真实的线上环境集群可能非常庞大,整个集群的节点数会远大于进行纠删码的n的大小,那么从集群角度看可靠性如何估算呢?我曾经在21年有发表过一篇外发期刊【分布式存储系统可靠性:系统量化估算】,这篇文章就是以生产环境以集群部署的角度进行分析分布式存储系统的可靠性如何估算,这篇文章相对于Markov可靠性模型一个最大的借鉴意义是它把集群内的一个数据的条带化组合引入到了可靠性估算,因此,新的可靠性估算模型可以结合Markov可靠性模型和集群条带化组合比例进行设计,更加具体的设计方案会在【纠删码技术在vivo存储系统的演进-下篇】中介绍。
4.3.3 多融合EC方案设计
根据对IDC资源、服务器资源、业务特性、网络资源的分析,结合可靠性评估近实时系统的支撑,我们在原有的8+4 CRS纠删码算法的基础上进行优化,将整体的EC策略分为两种如下图所示:

图31:多融合EC方案架构图
跨AZ-EC策略
核心业务数据有跨AZ存储需求进行机房数据容灾,但是同时也带来在节点故障情况下有跨机房网络带宽的影响,因此EC策略是LRC+RS+并行修复+MSR结合的EC方式,针对不同的场景有不同的优化措施:
-
当只有一个数据节点故障情况下,通过在各机房的局部校验块,只需要在机房内用MSR最小带宽进行快速修复;
-
当只有一个局部校验节点故障下,也是通过在各机房的数据块在机房内进行快速修复;
-
当只有一个全局校验节节点故障下,则可以通过一个机房的局部校验块再结合其它机房的中间结果数据进行并行恢复;条带越宽,带宽节省越多,比如单机房12数据块,3机房可节省跨机房带宽80%+;
-
当有两个或两个以上节点同时故障的情况下,才需要进行跨机房传输数据修复,我们可以通过局部校验块+其它机房中间结果结合+并行修复的形式来降低网络带宽消耗。
为了能描述清楚我们的策略,我们以(16,4,4)4机房,4个局部校验块,4个全局校验块,16个数据块【如下图所示】为例来说明:
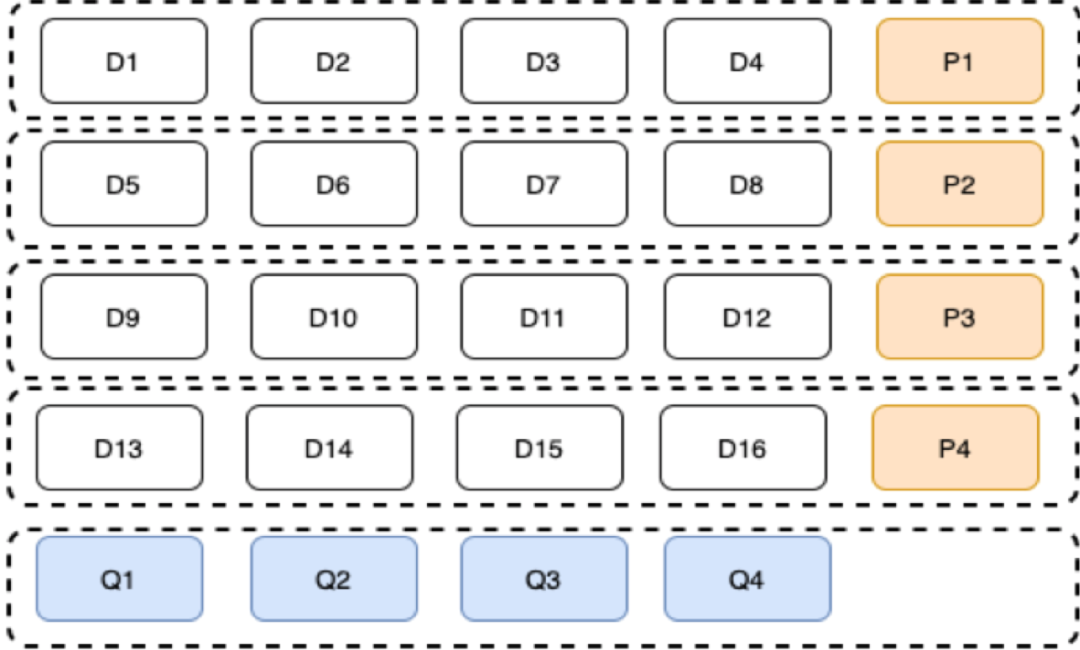
图32:(16,4,4)LRC编码拓扑
我们假设局部校验块P1、P2、P3、P4的构造按如下所示:

同样按RS码构造方式,我们假设Q1、Q2、Q3、Q4的构造按如下所示:

接下来我们来分析一下不同场景下的恢复情况:
-
只有一个数据节点或P节点故障:只需要在每个局部进行即可,利用生成矩阵的逆矩阵:

-
只有一个Q节点故障:按原来的算法是需要D1-16全部参与进行计算,但是我们分析可以发现生成矩阵是固定的,因此,完全可以在机房内部进行中间运算后再发送到故障机房进行最终运算得到,以Q2为例,只需要以下四个生成矩阵在各自机房与机房数据Di进行中间结果运算即可:
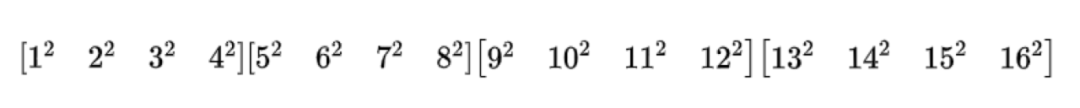
-
有两个或两个以上节点故障:可以通过在集群运行前先把所有可能的校验矩阵【如下图所示】准备好,然后再通过在各自机房与机房数据Di或Qj进行中间结果的计算,最后在需要恢复机房进行最终结果的合并计算得到恢复数据:

具体算法的详细细节会在后续的【纠删码技术在vivo存储系统的演进-下篇】介绍,整体思路就是全局RS+并行修复结合局部MSR最小带宽修复的策略来达到多AZ数据可靠性保障的目标。
五、总结
云存储领域针对纠删码技术的研究截止到现在仍然是学术界和工业界研究的热点,如何能降低网络的修复带宽,降低存储开销同时保证数据的可靠性的同时编解码算法又能工程落地,编解码复杂度又偏低,这些维度的考量衍生了各式各样的纠删码编码技术,vivo也在纠删码技术根据生产环境可落地的前提下在传统RS码的基础上引入并行修复以利用LRC+MSR局部校验块的组合来降低传统LRC在生产环境上运用导致的跨机房带宽开销,从而较低的跨机房带宽开销为高条带低冗余度的EC策略提供了保障。随着业务的发展,数据的存储开销成本会越来越明显,因此,针对纠删码技术的研究会是一个长期的过程,本人也会时刻关注学术界和工业界的动态,结合IDC、服务器、网络及业务的特性进行创新和优化为业务持续助力。
参考文献:
END
猜你喜欢
-
一种KV存储的GC优化实践
-
Kafka实时数据即席查询应用与实践
本文分享自微信公众号 – vivo互联网技术(vivoVMIC)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
