

大规模的技术进步创造了新的工作方式,更容易获得信息,以及更容易使用设备和应用程序,今天的劳动力正在从这些改进中受益。然而,所需的日益复杂的支持架构会给IT团队带来挑战。解决越来越多的IT问题会导致摩擦,并导致企业依赖支持团队来处理更多种类的工单。决策者正在寻找解决方案,使他们能够让IT团队更快、更顺利地补救问题。
为了解决简单和复杂的IT问题,企业必须建立一个流程,使IT支持部门能够利用其有限的资源提高生产力。通过Workspace ONE Intelligence,企业可以从主动识别问题以及L1 IT支持和员工之间的无缝沟通中受益。被动的问题解决肯定仍然是一个核心功能,但在用户报告问题之前发现问题可以帮助组织 “左移”并分配更多的资源来关闭更复杂的工单。目标是减少平均解决问题时间(MTTR),同时增加关闭的工单数量。
为了说明这个过程,让我们体会这样一个场景:IT管理员使用Workspace ONE监控KPI,发现潜在的用户问题,并与终端用户合作,迅速补救问题。
构建Workspace ONE Intelligence工作流以监测设备健康状况
有许多统计数据是IT部门评估环境中不同组件健康状况的必要条件。Workspace ONE可以监测关于设备性能、应用程序性能和其他指标的关键数据,这些数据表明有没有IT问题影响员工体验。这些数据使IT管理员能够更快地发现问题,有时甚至在用户自己发现问题之前。
在Workspace ONE Intelligence中IT管理员可以创建工作流程,当设备上的特定使用阈值(或其他体验指标)被达到时,就会触发警报,这源于应用程序、设备或其他来源。在这个例子中,CPU使用率被确定为一个可以显著预测员工体验质量的指标。IT部门创建了一个警报,主动让他们知道一个员工的设备有很高的CPU使用率,使他们能够采取措施开始补救过程。
在这个例子中,IT管理员Nick希望监测用户的CPU健康状况,并创建一个工作流程,如果用户的设备达到75%以上的使用率,就会触发通知。在Workspace ONE Intelligence中,Nick选择了一个要提取数据的数据源,确定了目标指标,并为通知系统设置了一个相关的阈值。
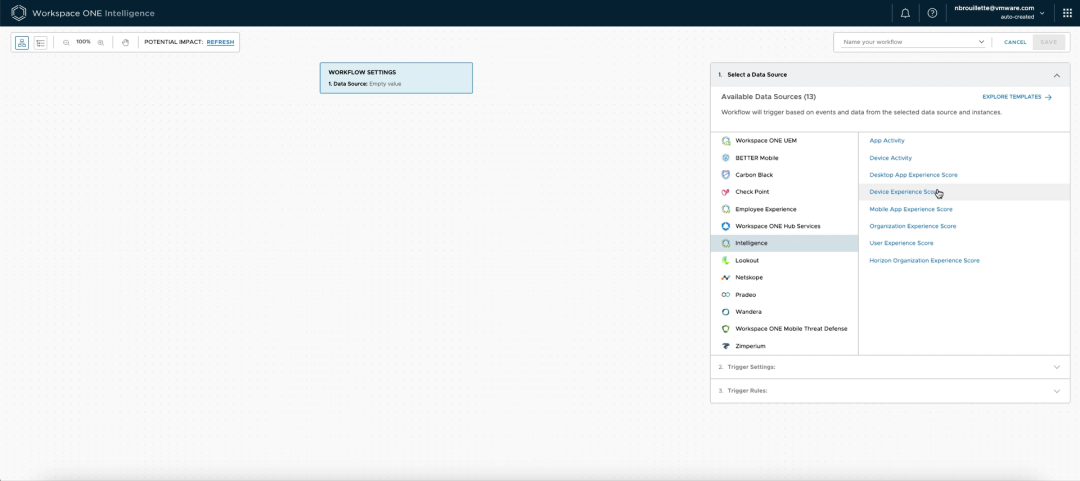
(确定所需的数据源)
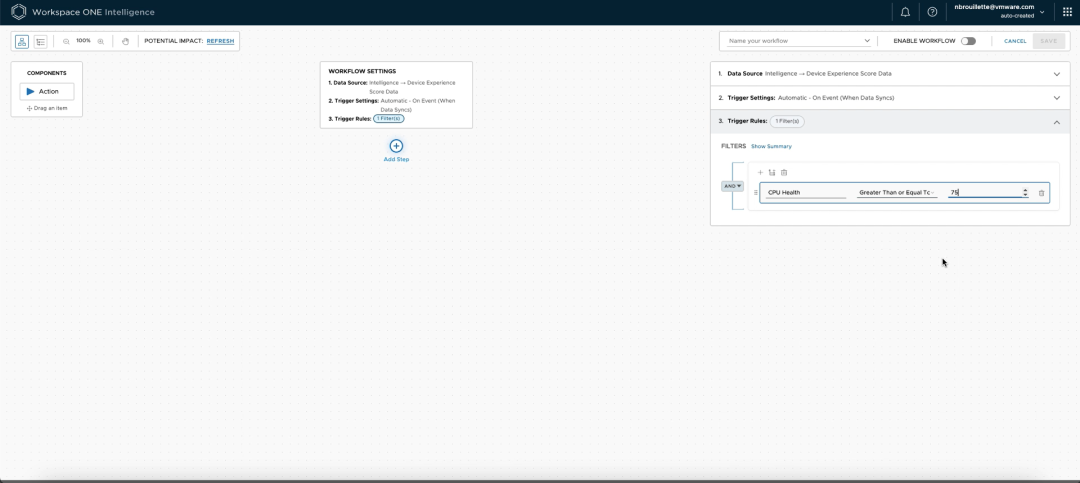
(选择一个要监测的KPI,并设置阈值)
但是通知会发到哪里呢?它真的可以去任何你想要的地方。在这个例子中,Nick希望Workspace ONE向一个IT Slack频道发出通知。他从可用的连接列表中选择了Slack Web API,指定了频道名称,并编写了通知消息模板,包括自动填充相关信息的宏。他还创建了第二个动作,为从Slack中获取问题的管理员创建一个ServiceNow工单。这两个动作通常都是增加MTTR的瓶颈。自动收集和传播设备数据使IT部门能更快地开始修复工作。

(选择一个应用程序来发送通知)
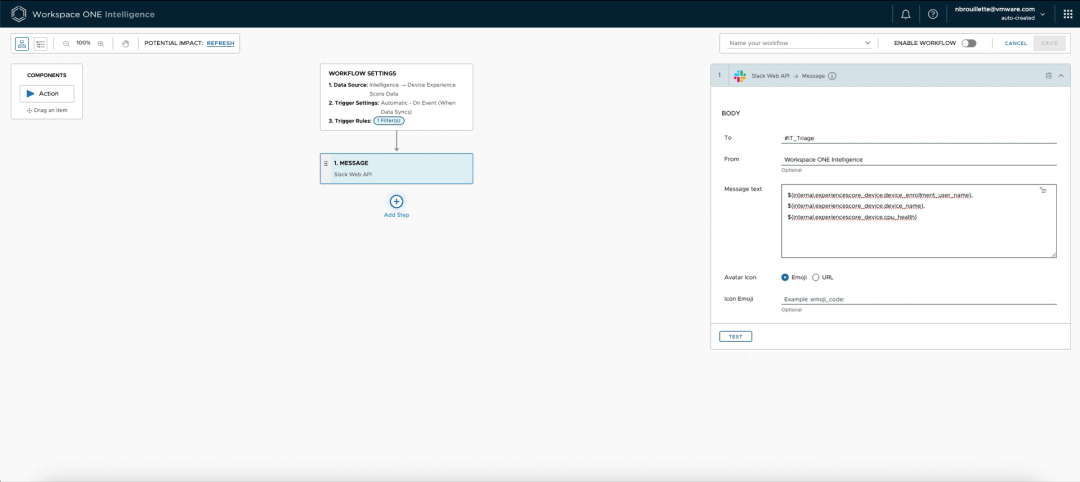
(生成通知信息的格式)

(添加一个ServiceNow工作流来生成一个工单)
根据Intelligence的通知采取行动
一旦在Slack中发送了消息并在ServiceNow中创建了工单,L1管理员将接过工单并开始工作以解决该工单。在Workspace ONE Intelligence仪表盘中,管理员可以搜索被自动拉入Slack消息的设备名称。Intelligence仪表盘提供了许多性能指标的数据;在这个用例中,管理员导航到 Experience 标签中的CPU健康。
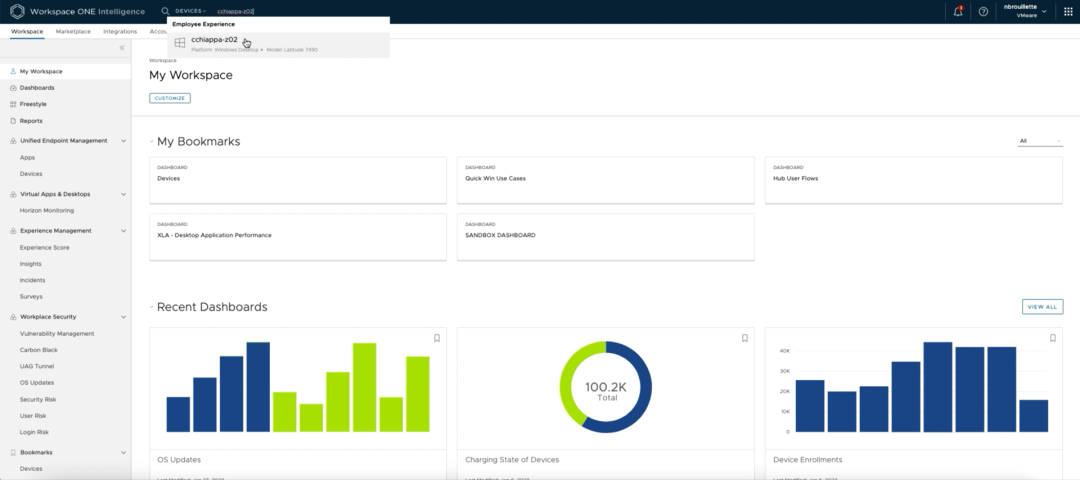
(Workspace ONE Intelligence 仪表盘)
他首先通过检查当前的性能得分来验证这个问题,发现其使用率为95%。为了深入研究,管理员查看了设备的CPU健康状况的时间线视图,并确定了设备开始出现性能问题的日期,在这个例子中是2月24日。该信息与启动日志相互参照,其中有一个在同一日期的操作系统更新记录。这两条信息可能有关联,给管理员提供了一个开始排除故障的地方。
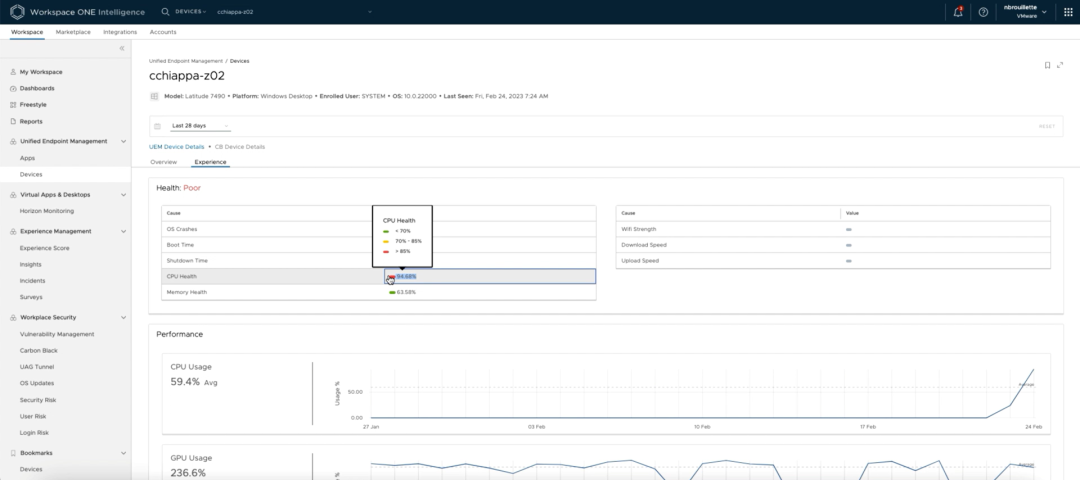
(确认触发指标)
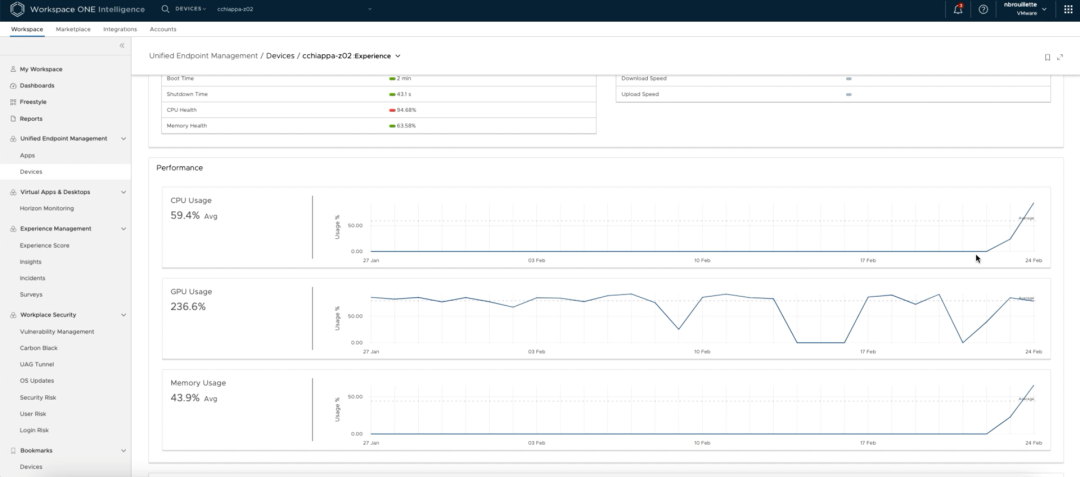
(审查历史上的CPU使用数据)
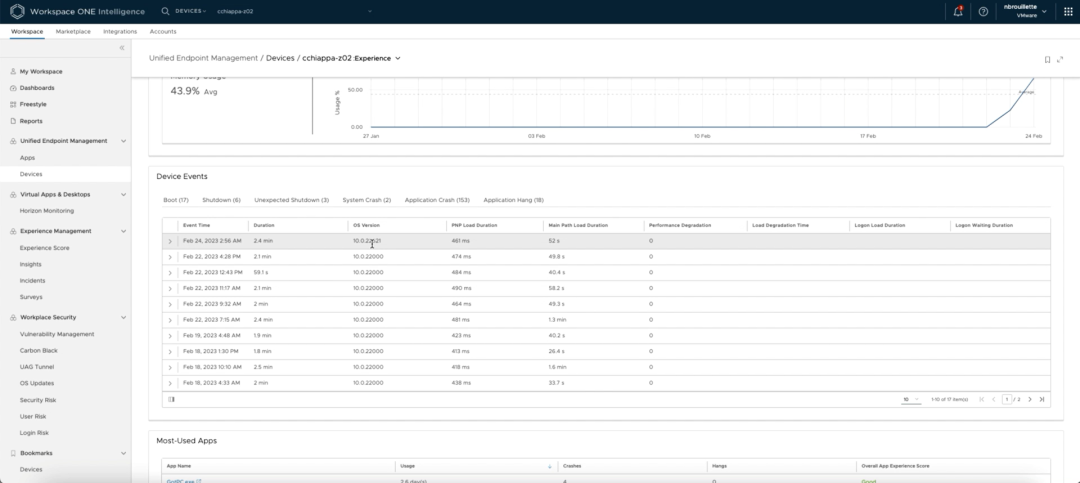
(打开设备启动日志,对照一下)
关于Workspace ONE Intelligence
所有这些数据都可以在Workspace ONE Intelligence中获得并显示出来。Intelligence不仅可以帮助组织访问和分析设备和应用程序数据,而且还允许组织决定如何管理这些数据并对其采取行动。这些用例跨设备、操作系统、应用程序和地点进行跟踪,使IT团队能够更快、更有效地解决更多工单。这些自动化给你的远程或混合劳动力提供了他们需要的IT支持,以继续支持他们在任何地方的工作。
上述例子只是Workspace ONE通过数据监控提供主动修复,在你的组织中实现任意工作空间的众多方式之一,从而带来强大和可靠的员工体验。
本文作者:Andrew Scott,VMware数字化员工体验团队的产品营销经理。
内容来源|公众号:VMware 中国研发中心
有任何疑问,欢迎扫描下方公众号联系我们哦~

