

前段时间,袋鼠云离线开发产品接到改造数据同步表单的需求。
一方面,数据同步模块的代码可读性和可维护性较差,导致在数据同步模块开发新功能和定位问题的效率很低。另一方面,整体规划上,希望在对接新的数据源时,可以不再关心表单渲染相关问题,从数据源中心新建数据源一直到数据源在数据同步模块的应用,全链路的表单都可以通过配置化的方式解决。
本文就将以此为例,抛砖引玉,为大家详细介绍配置式表单渲染器实现的实践之路。
数据同步表单背景
数据同步模块整体上分为四个部分,数据来源表单、同步目标表单、字段映射组件和通道控制表单。
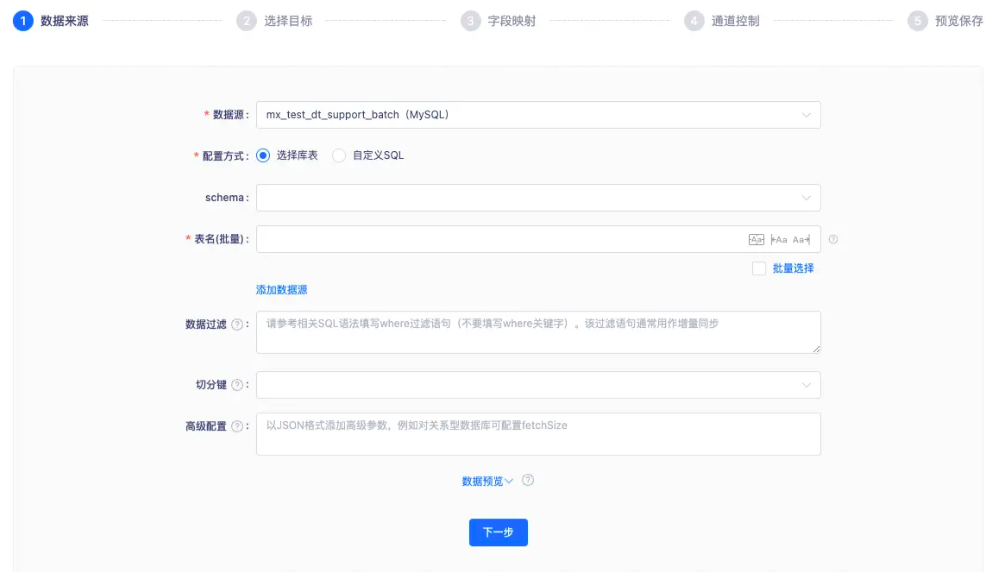
其中前三个部分对应的代码非常混乱,代码量也很大,单个组件代码 5000+ 行,这里着重说一下数据来源表单和同步目标表单。
数据来源和同步目标表单的主要功能是收集数据源对应的配置信息,并且根据数据源类型的不同,对应需要渲染的表单项也不同。
目前袋鼠云离线开发产品 BatchWorks 数据同步功能的数据源多达50+种。在长时间的迭代过程中,日积月累出现了很多强行复用的代码,这些强行复用的代码内部又包含着大量的 if else 逻辑。另外,数据同步模块的表单内部有很多联动关系,比如:
· 某个表单项的值变化时,需要发起接口请求,请求的返回值被用作另一个表单项下拉框的数据
· 某个表单项的值变化时,需要去清空/重置其他一些表单项的值
· 某个表单项的值变化时,需要显示/隐藏某个表单项
· 某个表单项的值变化时,某个表单项的 label 文案、表单项组件(比如从 select 变成 input ) 等随之发生变化
这些表单项的联动处理逻辑在代码中混杂交叉,另外还要加上表单回显的特殊逻辑处理,表单的值收集到 redux 的特殊逻辑处理等。
需求分析
基于上述需求背景,表单渲染器的核心功能是输入一份配置,输出表单 UI 组件。
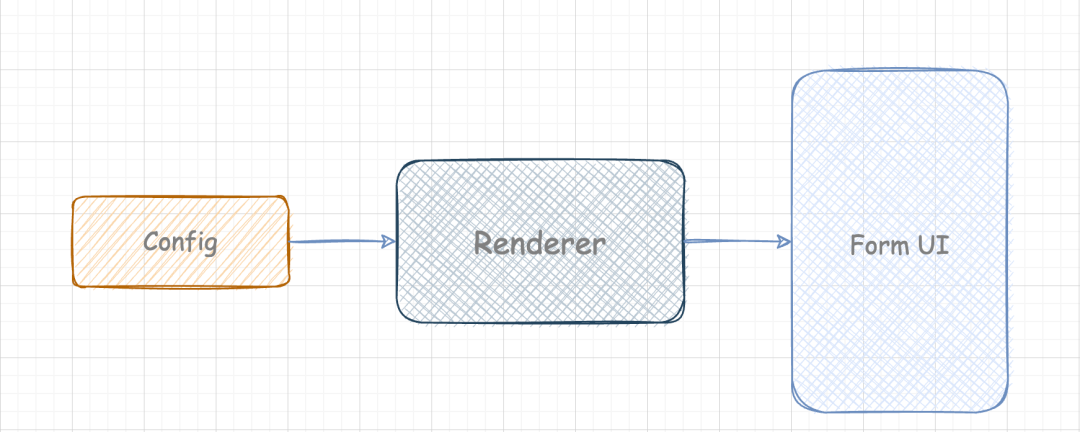
基于上述数据同步表单背景,我们希望渲染器可以尽可能吸收掉表单内部的复杂度,也就是说在表单的配置中要能够描述上述的联动关系,那么可以大概得出表单的配置需要描述:
· 表单项的基础信息,比如字段名、label、表单组件、校验信息等
· 表单项数据之间的联动
· 表单项 UI 的联动(控制显示/隐藏)
· 表单项的值变化时需要触发的副作用(比如调用接口)
表单基础信息描述
这里配置格式使用 JSON 格式,用一个数组描述所有的表单项信息,UI 上表单项的渲染顺序即配置数组中表单项配置的顺序,表单组件使用 Ant Design Form。
对于表单项基础信息的描述配置,大多可以直接搬用 Ant Design Form Item 的 props,比如 label、rules、Tooltip 等属性,这里不多赘述。
比较特殊的是,需要在配置里描述表单项描述的 UI 组件,比如 Select、Input,那么这里使用 widget 字段去描述。另外,组件的描述除了组件名称,还需要描述组件的 props, 所以还需要一个 widgetProps 字段去描述组件的属性,比如 placeholder、disabled 等。
那么一个用于选择数据源的表单项应该这样描述:
{
"fieldName": "sourceId",
"label": "数据源",
"rules": [
{
"required": true,
"message": "请选择数据源!",
},
],
"widget": "Select",
"widgetProps": {
"placeholder": "请选择数据源",
"options": [
{
"lable": "数据源1",
"value": 1
}
]
},
}
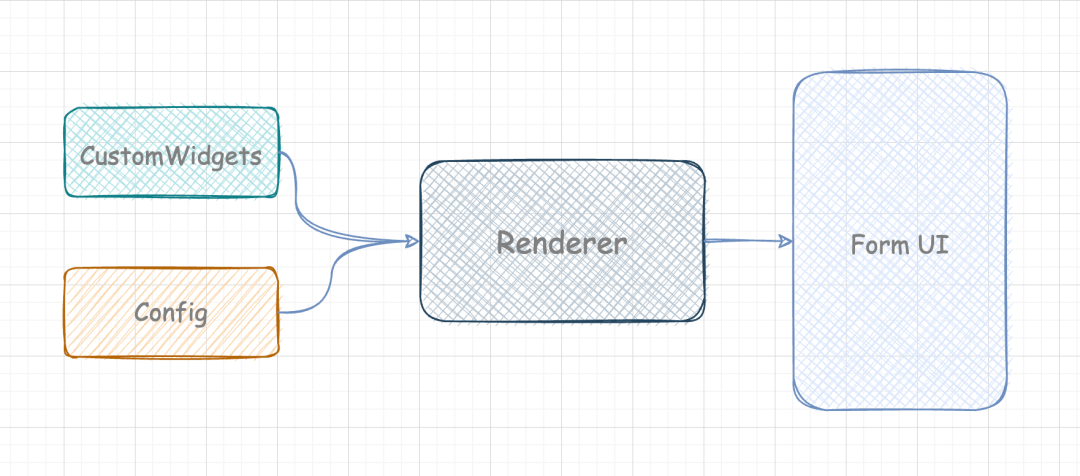
当然可能会存在某些表单项的 UI 组件有自定义的情况,比如可编辑表格,代码编辑器等。这个时候就需要开发自定义表单组件了,然后把这些组件注入到 FormRenderer 中,伪代码如下所示:
import { Editor, EditableTable } from './customWigets'
export const getWidets = (widgetsName) => {
switch(widgetsName) {
case 'Editor': {
return Editor
}
case 'EditableTable': {
return EditableTable
}
}
}
那么目前的结构如图所示:
这份配置写到这里的时候,问题出现了:
· 无法在配置中描述 onChange、onSelect 等事件回调函数
· 相比于 jsx 强大的表达能力,JSON 中只能表达基本的数据结构,而没办法直接表达逻辑
· Select 下拉框的数据可能来源于接口,这种情况在业务中相当常见,这里也没办法表达
· 不能自定义表单校验器,无法支持复杂的 Tootip 提示,比如带有 a 标签的 Tootip
上述问题产生的根本原因,实际上是 JSON 与 jsx 之间表达能力的差距。但是从另一个角度来讲,正因为 JSON 的表达能力和灵活性不如 jsx,所以在用来描述 UI 时,JSON 更不容易导致混乱。
我们先思考如何表达 Select 下拉框的数据来源于接口,这里可以拆解为两个部分,数据获取和取得接口的返回值并在配置项中表达。
数据获取
实际上,Select 下拉框中的数据也并不一定来源于接口,也可能是来源于其他业务数据,所以在配置项描述数据获取时,不应该关心数据的来源。
很显然,数据获取逻辑需要用 js 描述 ,这里我们抽象出一个 Service 的概念,用于描述/声明数据获取逻辑,Service 的声明使用 js,在 JSON 配置中,只需要去描述 Service 的调用逻辑即可。对于 JSON 配置来说, Service 调用需要三个要素:
· Service 的标识/名称,表示哪一个 Service 被触发
· Service 的触发时机
· Service 返回的数据如何存储
● Service 的触发时机
Service 的触发一般来说是由于用户的交互引起的,当然也存在在表单项组件挂载时就需要触发的情况,那么调用时机大概就是以下几种:
· onMount
· onChange
· onSearch
· onFocus
· onBlur
● Service 返回的数据如何存储
这里 Service 返回的数据存储需要能被 UI 获取到,那么需要将返回的数据都维护在 FormRender 内部,这里将存储数据的地方命名为 extraData。那么我们描述 Service 返回的数据的存储,可以使用一个 fieldInExtraData 的字段,描述当前 Service 返回的数据被存储在 extraData 的那个字段中,取值时:extraData[fieldInExtraData]。
那么在表单项配置中描述 Service,如下所示:
{
"serviceName": "getSourceList",
"triggers": ["onMount", "onSearch"],
"fieldInExtraData": "schemaList"
}
● Service 的声明
对于 Service 本身来说,要做的事情就是获取并处理数据然后返回,当然 Service 本身可能需要接受一些参数,比如当前 Form 收集到的数据、Service 是被哪个字段触发的、触发时机是什么等等,那么 Service 的格式如下所示:
const getSourceList = ({ formData, extraData, trigger, triggerFieldName }) => {
return Promise((resolve) => {
resolve(...)
})
}
由于 Service 可能是异步的,所以这里 Service 都返回一个 Promise,然后将所有的 Service 都注入到 FormRenderer 中,FormRenderer 根据表单项配置中声明的调用时机去调用 Service,整个数据获取的链路就完成了。
获取 Service 返回值并在配置项中表达
上文中提到,Service 的返回的数据都被存储在 FormRenderer 内部的 extraData 中,一般情况下如果使用 jsx 当然能很容易地取到对应的值,但是在 JSON 中,是没办法表达的。但是我们可以借鉴 jsx 的插值表达式和 vue 的插值表达式。
{user.name}
在 jsx 中,如果在一对标签内部写了一串字符串,对应的会有两种解析策略,第一种是直接识别为字符串,第二种如果识别到花括号,则将其视为 js 表达式。 同理,在 JSON 配置中也可以使用这种方式去取值。
{
"fieldName": "sourceId",
"label": "数据源",
"widget": "Select",
"widgetProps": {
"placeholder": "请选择数据源",
"options": "{{ extraData.sourceList }}"
},
"triggerServices": [
{
"serviceName": "getSourceList",
"triggers": ["onMount", "onSearch"],
"fieldInExtraData": "sourceList"
}
]
}
● 函数表达式
上例中,使用一对花括号声明函数表达式,表面上是借鉴了 jsx 的插值表达式,但是其实两者有很大的区别。jsx 的插值表达式是在编译阶段就转化成了 js 表达式。而在 JSON 中的这种自定义的函数表达式要在运行时转换,上述的函数表达式只能被转换为函数执行。即:
"{{ extraData.schemaList }}"
// 转化为
const valueGetter = new Function('extraData', 'return extraData.schemaList')
出于安全问题考虑,表达式还需要被放在一个类似沙箱的环境中执行,避免表达式内部修改全局环境变量。创建简易沙箱使用 proxy + with + symbol.unscopables 的方式,这里不展开讲解了。最终函数表达式的应用大概是如下形式:
function Comp () {
return
}
到目前为止,已经有了两个新概念:Service 和 函数表达式,回到上文中提到的问题,我们已经解决了 Select 下拉框来源于接口的问题,那么还剩下如下问题:
· JSON 中只能表达基本的数据结构,而没办法直接表达逻辑
· 无法在配置中描述 onChange、onSelect 等事件回调函数,也不能自定义表单校验器
· 不能自定义表单校验器,无法支持复杂的 Tootip 提示,比如带有 a 标签的 Tootip
json 中没办法表达逻辑的问题,其实已经可以通过函数表达式来解决了。函数表达式内部支持写任意的 js 表达式,另外,在函数表达式中也可以支持访问 form 表单数据,有了数据支持和逻辑表达能力支持,绝大多数情况下的已经能够满足 UI 渲染中的逻辑表达了。
而描述 onChange、onSelect 等事件回调函数可以通过配置 Service 来解决。
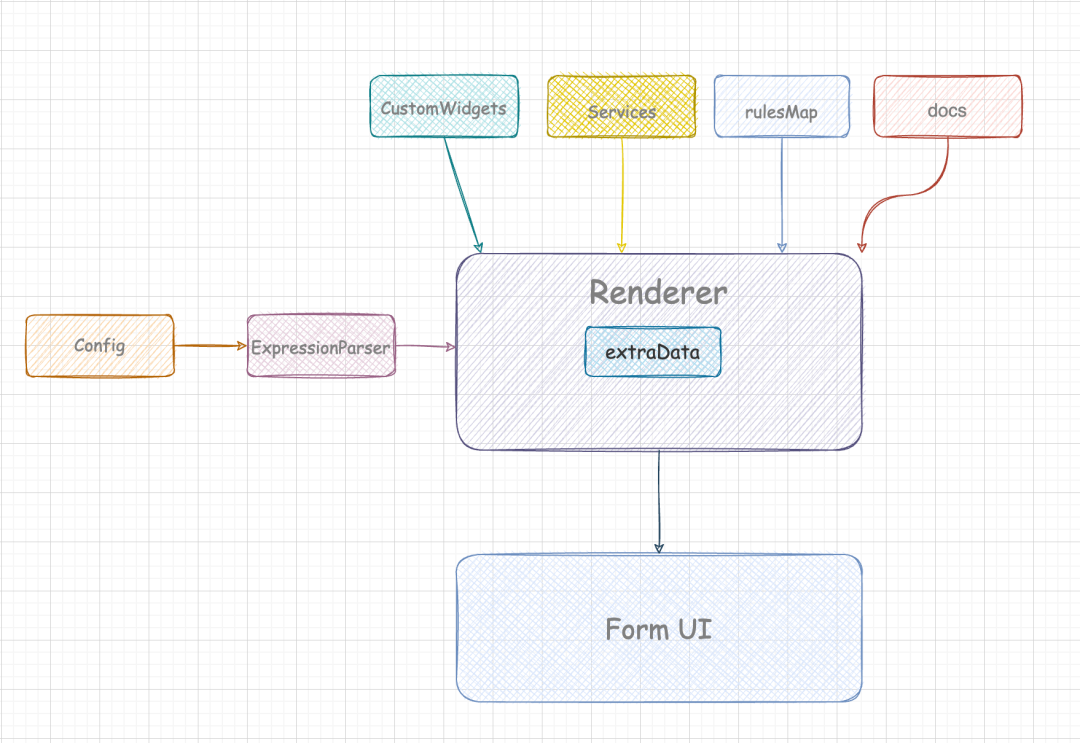
自定义表达校验器可以通过函数表达式的变种来解决,可以向 FormRenderer 中注入 form 校验器的集合,然后通过 {{ ruleMap.xxx }} 来指定表单项的某一条校验规则的校验器。
{
"fieldName": "sourceId",
"label": "数据源",
"rules": [
{
validator: "{{ ruleMap.checkSourceId }}"
},
],
}
Tooltip 提示也是如此。目前结构如下图所示:
表单数据联动
表单数据联动实际上就是当表单中某个表单项值变化时,去重置其他表单项的值,那么要在配置中描述这种联动关系有两种方式:
· 当前字段受哪些字段的影响
· 当前字段的值变化会影响到哪些字段
一般情况下,在代码中描述这种逻辑时都是采用第二种方式,也就是监听某个字段的值的变化,然后在回调函数中去做对应的数据联动操作。
但是在配置 JSON 时,第二种方式就变得不那么友好了,那会让字段配置之间产生更多的耦合。更加友好的方式是在某个字段内表达本字段受到哪些字段的影响,这样做的另一个好处是,当开发者填写或者修改某一个字段的配置时,可以更加聚焦,不用关心其他字段的配置。
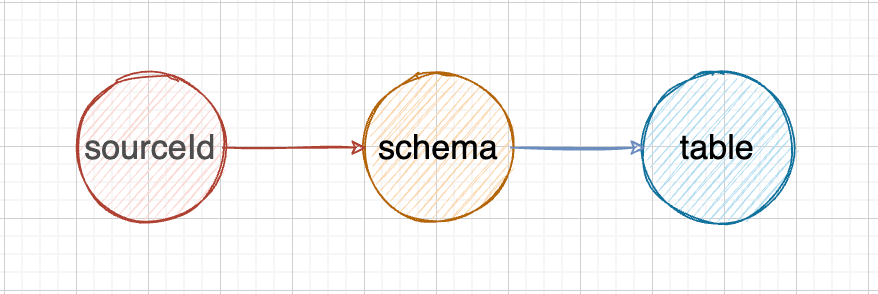
这里用 dependecies 字段来表达当前字段的值受哪些字段的影响。举个例子,表单中有数据源、schema、table 三个字段,数据源变化时,schema 的值应该被重置;schema 变化时,table 的值会被重置。那么在 json 中应该这样描述:
[
{fieldName: 'sourceId', dependencies: []},
{fieldName: 'schema', dependencies: ['sourceId']},
{fieldName: 'table', dependencies: ['schema']},
]
对应的依赖关系图如下:
这里新的问题产生了,当数据源变化时,table 的值是否要被重置?一般情况下是肯定的。那么实际上它们的依赖关系是这样的:
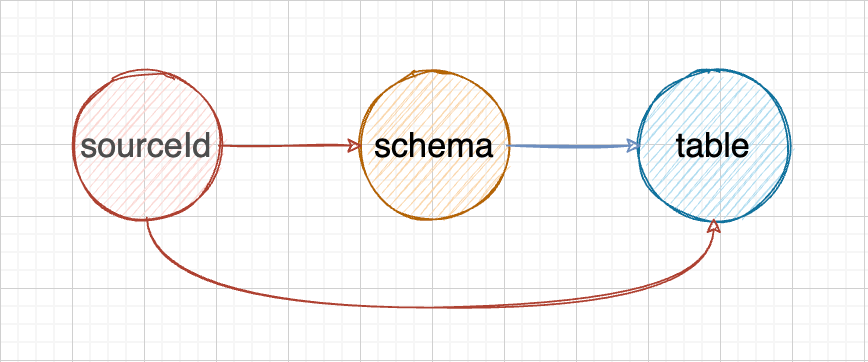
这里有两种方式来解决这种隐式的依赖关系:
· 开发者在配置时显式得声明所有的依赖关系
· 渲染器内部解析依赖关系时,将这种隐式的依赖关系也解析出来
那么如何选择使用哪一种方式呢?
如果采用第一种方式,优点是渲染器不再需要关心这种隐式的依赖关系了,但是在配置时的心智负担可能比较大,很容易出现漏配依赖关系的情况。
如果采用第二种方式,优点是配置起来心智负担低,但是也有可能出现 table 确实不依赖 sourceId 的情况,也就是间接依赖不生效的情况。
结合实际业务看,目前的业务中,所有的字段之间间接依赖其实都是隐式依赖,也就是需要生效的,这里采用第二种方式。前文中也提到了,期望是 FormRenderer 可以尽可能的吸收掉表单内部的复杂度。
特殊的表单数据联动
在实际业务中还存在着一些比较特殊的表单数据联动,比如:
· 选择数据源时,除了需要收集数据源的 id,还需要收集数据源类型
· 选择数据源后,需要将数据源的其他信息展示为表单项,比如下图中的表单
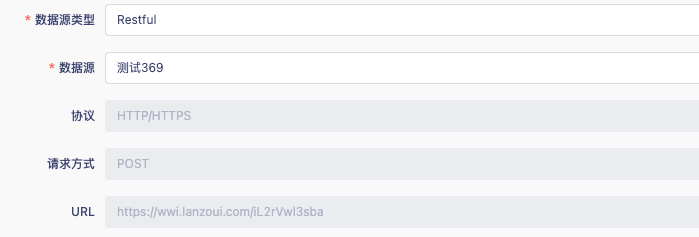
对于这种业务场景,我们可以理解为某个表单项的值是由其他表单项的值派生出来的,那么就需要去描述这种派生逻辑。当然,这种派生逻辑可以在业务代码中描述,只需要在数据源变化时,手动的 setFieldValue 就可以了。但是还是上文中提到的期望,FormRenderer 可以尽可能吸收掉复杂度。
处理这种情况,需要新增一个配置项去描述派生逻辑,这里配置项定为 valueDerived,这个配置项的值应该为一个取值表达式,那么以第一个例子为例,配置应该如下所示:
[
{
"fieldName": "sourceId",
"label": "数据源",
"widget": "Select",
"widgetProps": {
"placeholder": "请选择数据源",
"options": "{{ extraData.sourceList }}"
},
},
{
"fieldName": "sourceType",
"label": "数据源类型",
"hidden": true,
"valueDerived": "{{ extraData.sourceList.find(s => s.value === formData.sourceId).type }}",
},
]
FormRenderer 内部根据配置的 valueDerived 去自动更新表单中对应字段的值。
表单 UI 联动
表单 UI 联动可以分为以下两个部分。
表单项 UI 文案、样式等根据数据联动
表单项的 UI 联动在 React 和 JSX 中,都能很轻易、很自然的发生。但是想要在 JSON 中描述,由于JSON本身不具备表达逻辑的能力,还是要借助函数表达式。只需要支持对应的配置项可以使用函数表达式就能完成表单项的联动。举个例子:
[
{
"fieldName": "time",
"label": "{{ extraData.type === 1 ? '开始时间' : '结束时间' }}",
"widget": "Input",
"widgetProps": {
"placeholder":"{{ extraData.type === 1 ? '请输入开始时间' : '请输入结束时间' }}",
},
}
]
那么它们实际渲染时等同于以下伪代码:
function Comp (props) {
const {fieldName, label, widget, widgetProps, extraData} = props
const form = useFormInstance()
const formData = form.getFieldsValue()
const tarnsformer = (configItem) => {
const fn = new Function('formData', 'extraData', `return $[configItem}`)
return fn.call(null, formData, extraData)
}
return
}
这样就能做到表单项的文案样式等根据数据变化自然的联动。
表单项的显示与隐藏
表单项的隐藏也能拆分为以下两种情况:
· 隐藏但不销毁,表单项的值仍然会被收集和保留
· 销毁,不再保留/收集表单项的值
隐藏但不销毁的情况,antd form 本身就有 hidden 配置支持,那么这里只需要支持 hidden 配置使用函数表达式就可以了。
对于表单项的销毁,就需要新增一个字段了,这里命名为 destory,同样通过支持使用函数表达式完成联动,但是这里需要考虑一些其他情况。比如从销毁状态变成显示状态时,需要去触发 mount service 等。
思路小结
回顾上文需求分析中所说的需要实现的功能:
· 表单项的基础信息,比如字段名、label、表单组件、校验信息等
· 表单项数据之间的联动
· 表单项 UI 的联动(控制显示/隐藏)
· 表单项的值变化时需要触发的副作用(比如调用接口)
目前在思路上,上述功能都是可以实现的。除了基础的渲染功能以外,FormRender 需要额外实现的功能有:
· 内置一个 extraData 存储 Service 返回的数据
· 支持根据配置在正确的时机触发 Service
· 支持函数表达式
· 支持根据配置在内部处理数据联动逻辑
大体实现
整体上,导出一个 FormRenderer 组件,上文中提到的 json config、Service 声明、自定义的表单校验器,自定义表单项组件等,都通过 FormRenderer 的 props 传入。
内置 extraData
由于 extraData 内部存储的数据变化可能导致视图更新,那么只能使用 React.Context 或者 state,事实上即使使用 Context 也还是需要声明 state 来触发视图更新,但是 Conetxt 在传递数据时有着独特的优势,这里直接使用 Context 存储数据。
// 避免闭包问题
export function useExtraData(init: IExtraDataType) {
const stateRef = useRef(init);
const [_, updateState] = useReducer((preState, action) => {
stateRef.current =
typeof action === 'function'
? { ...action(preState) }
: { ...action };
return stateRef.current;
}, init);
return [stateRef, updateState] as const;
}
// 创建context
const ExtraContext = React.createContext({
extraDataRef: { current: { } },
update: () => void 0,
});
import { useExtraData, ExtraContext } from 'extraDataContext.ts'
const FormRenderer: React.FC = () => {
const [extraDataRef, updateExtraData] = useExtraData({});
// ....
return(
{....}
)
}
在正确的时机触发 Service
在 JSON 配置中 Service 相关描述如下所示:
[
{
"fieldName": "sourceId",
"label": "数据源",
"triggerServices": [
{
"serviceName": "getSourceList",
"triggers": ["onMount", "onSearch"],
"fieldInExtraData": "sourceList"
},
{
"serviceName": "getSchemaList",
"triggers": ["onChange"],
"fieldInExtraData": "schemaList"
},
]
}
]
triggerServices 已经很清楚直观的描述了,该字段在什么时机应该调用哪个 service,在代码实现上,为了这部分触发逻辑与视图渲染分离,采用发布订阅模式。大体流程如下图所示:
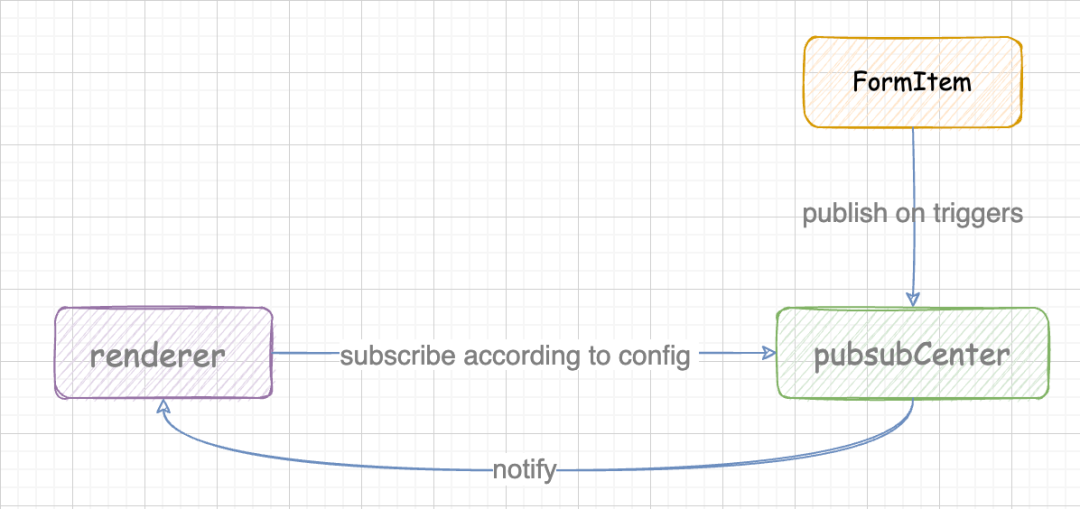
这里流程已经走通了,但是可以发现,renderer 中仍然需要去处理订阅的逻辑,Service 触发逻辑与视图渲染逻辑分离的不够彻底,那么可以继续优化一下,加入一个订阅器去处理这部分逻辑,优化后的逻辑如下图所示:

支持函数表达式
上文中提到了,函数表达式的实现是用 new Function,以及处于安全问题考虑需要将函数表达式放到模拟沙箱环境中执行,执行流程如下所示:

实现代码如下所示(不包含正则处理):
class FnExpressionTransformer {
private sandboxProxiesMap: WeakMap> =
new WeakMap();
private createProxy(scopeObj: ScopeType) {
/** 存储创建的 proxy 避免重复创建 */
if (this.sandboxProxiesMap.has(scopeObj)) {
return this.sandboxProxiesMap.get(scopeObj);
}
const scope = {
extraData: scopeObj.extraDataRef,
formData: scopeObj.formData,
Math: Math,
Date: Date,
};
const proxy = new Proxy(scope, {
has() {
return true;
},
get(target, prop) {
if (prop === Symbol.unscopables) return undefined;
if (prop === 'extraData') {
return target[prop]['current'];
}
return target[prop];
},
});
this.sandboxProxiesMap.set(scopeObj, proxy);
return proxy;
}
transform = (code: string): TransformedFnType => {
return (scope: ScopeType) => {
const proxy = this.createProxy(scope);
const fnBody = `with(scope) { return ${code} }`;
const fn = new Function('scope', fnBody);
return fn(proxy);
};
};
}
比如在 label 配置中使用了函数表达式:
[
{
"fieldName": "name",
"label": "{{ extraData.xxx ? '用户名' : '昵称' }}"
}
]
那么经过转换后,就是等同于以下函数:
function lableValue (scope) {
return scope.extraData.xxx;
}
具体应用如下:
{/* xxxx */}
支持根据配置在内部处理数据联动逻辑
与上文中 Service 触发逻辑一样,将这部分联动的逻辑通过发布订阅与视图渲染逻辑分离。但是相比于 Service 触发逻辑,这里多了分析依赖的步骤。比如,有如下 json 配置:
[
{fieldName: 'schema', dependencies: []},
{fieldName: 'table', dependencies: ['schema']},
{fieldName: 'partition', dependencies: ['schema', 'table']},
{fieldName: 'coprate', dependencies: ['table', 'partition']}
]
那么生成的依赖关系图就应该是:
[
{fieldName: 'schema', isField: true]},
{fieldName: 'table', isField: true},
{fieldName: 'partition', isField: true},
{fieldName: 'coprate', isField: true},
{fieldName: 'schema', dependBy: 'table', isRelation: true},
{fieldName: 'schema', dependBy: 'partition', isRelation: true},
{fieldName: 'table', dependBy: 'partition', isRelation: true},
{fieldName: 'table', dependBy: 'coprate', isRelation: true},
{fieldName: 'partition', dependBy: 'coprate', isRelation: true},
]
生成上述依赖关系后,剩下的流程与触发Service 的流程类似,在这里不多做赘述了。
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm 想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szkyzg
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
