

前言
MySQL性能优化是一个很大的话题,小到一句SQL,大到一个系统,都是我们优化的目标,博主之前曾写过一篇关于SQL优化的博客,感兴趣的小伙伴直接点击即可。本篇,我们将从多个维度来讲解MYSQL性能优化相关的内容,读完此篇,你将初步了解有哪些MySQL的优化策略,以及怎么去进行MySQL的性能优化。下面,我们直奔主题吧!
优化介绍
关于优化,我们不能够断章取义,有时候我们会直接去网上搜一些优化相关的博客,然后照着做。这是不对的,起码不是百分百正确,套路是这个套路,但优化就像不同的人去买衣服,每个人都有自己的特殊情况,我们要具体情况具体分析,毕竟不是每个人的应用和服务器都是一样的,千人千面用在这里再好不过了。
MySQL几乎是目前绝大多数互联网公司的选择,出色的性能,低廉的成本,丰富的资源深受大众的喜爱。所以本文我们将MySQL作为我们的目标数据库。
但优化有风险,优化需谨慎。风险来源在于以下几点:
- 优化一般针对的是一个复杂的且已经上线的系统;
- 优化是把双刃剑,可能提高性能,也可能降低性能;
- 优化之前,要提前预测好可能出现的问题,将有可能出现的后果控制在可接受范围内,做好灾情预警方案;
- 一般优化肯定是遇到了问题,保持现状就是风险;
所以,优化可能有这么多的问题存在,那我们为什么还要做优化呢?这是因为大多数已知的优化会给我们带来优质的体验。就好比吃多了真的会撑死,我们为什么还要吃饭呢?
在优化时,我们一般会考虑业务的稳定性和可持续性,优化不是单纯的进行SQL的优化,还涉及到整体的业务,任何脱离开业务的优化都是扯淡。
优化也不是一个两个人就可以做的,必定是以团队为基础进行实施,当然,前提是公司部门分工明确的情况下,因为一般公司权限控制都很严格,不是说动就随时能动的,大家都明白的。
优化的方向上,我们一般分为两个方向:
- 安全,保证数据安全
- 性能,高性能数据访问
如果你能想到第三个方向,欢迎留言一起讨论。关于安全方面,博主后期会针对分布式锁给大家进行讲解,分布式事务在上一篇已经给大家讲解过,所以在本篇,我们仅针对性能跟大家进行分析讨论。
这里有一张优化方向和效果的展示图,大家看看:
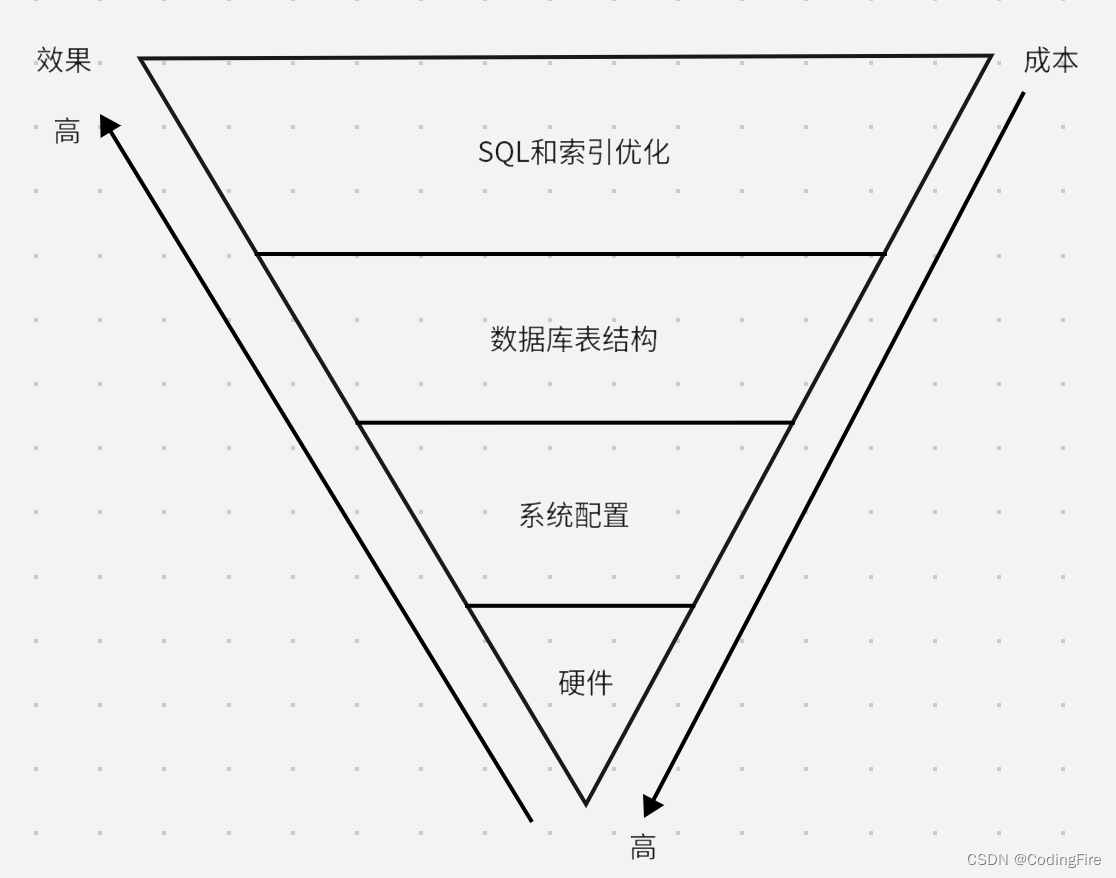
这张图很经典,希望大家记住这个变化的方向。
到这里,就是性能相关的介绍,想必你对MySQL优化的前提条件已经基本了解,下面,我们就开始对优化的具体内容展开说明。
常规SQL优化
查询优化
先奉上一张数据库的查询流程图:
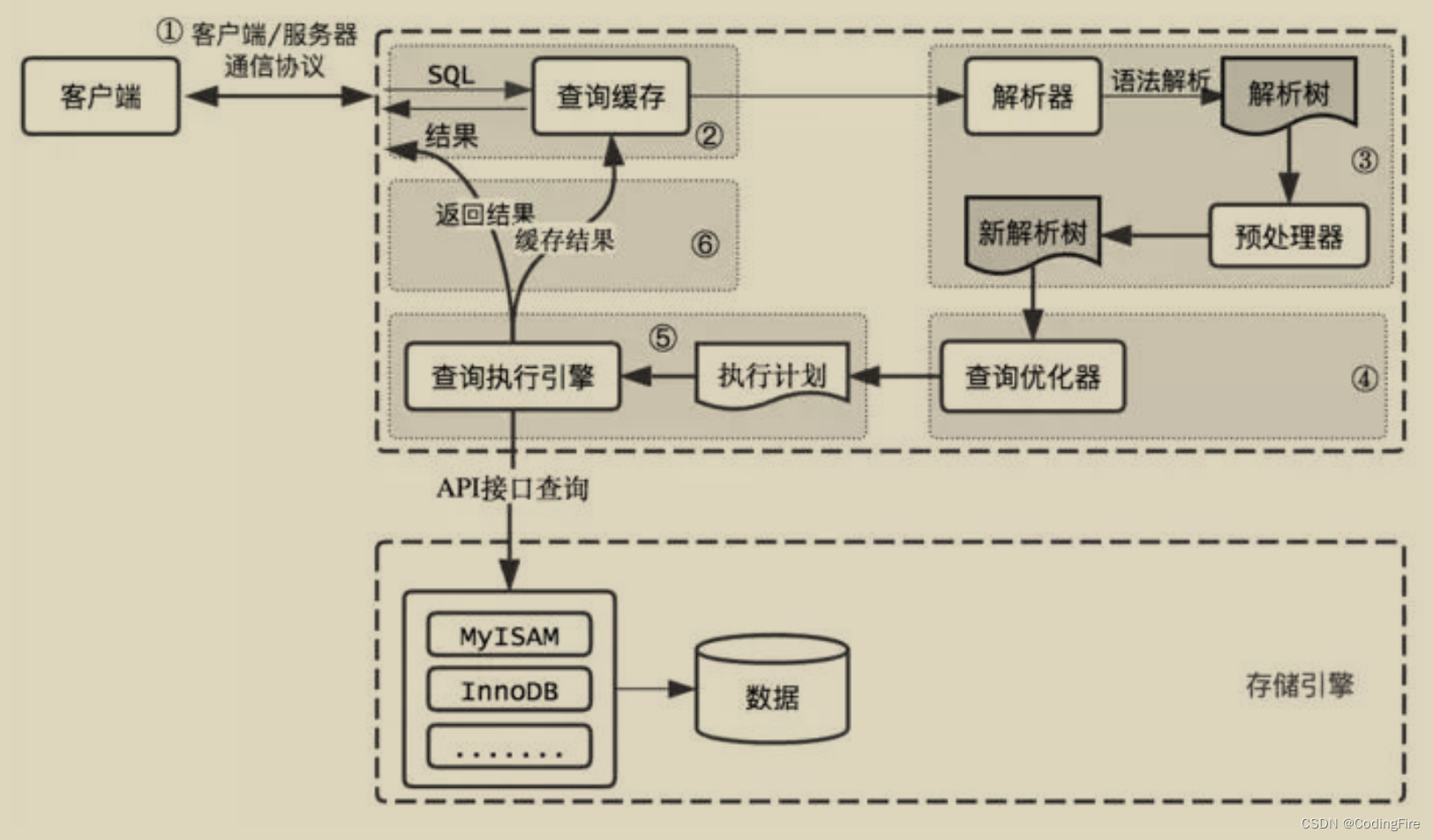
我想,关于查询的具体步骤就不必向大家讲解太多了,否则就有点啰嗦。但关于里面的步骤的作用还是有必要一探究竟的。
查询缓存:数据库解析一个SQL语句前,如果查询缓存是开启的,MySQL就会判断当前查询是否能够命中缓存中的数据,如果命中,则直接从缓存中拿出相应的数据返回给客户端,此时不会解析SQL,不生成执行接话,不执行查询操作。
语法解析和预处理器:MySQL通过关键字对SQL进行解析,生成对应的解析树,接着MySQL就会根据自己的语法规则进行验证和解析查询。
查询优化树:语法树被效验合法后,由优化器转成查询计划。一条SQL会有多种执行方式,优化器的作用就是找到最合适的那个方式来执行本条SQL。
查询执行引擎:根据图,在解析和优化后,将生成对应的执行计划,查询引擎就根据这个执行计划来执行SQL,最常用的执行引擎是默认的innoDB,还有一种引擎也比较常见,叫MyISAM。
SQL是我们查询的主要手段,也是表面上我们打交道最多的东西,所以很大成分的优化都是在这个维度上展开的,而SQL的优化手段分为两种,慢日志查询和EXPLAIN分析查询。
慢日志查询
默认的慢日志查询是关闭的,查看状态可根据如下命令:
show variables like '%slow_query_log%';

接下来我们开启慢SQL日志 :
set global slow_query_log=1;
并重新查看状态:

设置慢查询时间临界点:
set long_query_time = 1;
设置慢查询存储的方式,默认是FILE,可修改为TABLE:
set global log_output='TABLE';
查询慢查询日志的开启状态和慢查询日志储存的位置:
show variables like '%quer%';

参数注意:
slow_query_log : 是否已经开启慢查询
slow_query_log_file : 慢查询日志文件路径
long_query_time : 超过多少秒的查询就写入日志
log_queries_not_using_indexes 如果值设置为ON,则会记录所有没有利用索引的查询(性能优化时开启此项,平时不要开启)
发现,慢日志查询已开启时,如果重启MySQL,会自动关闭,需要在 /etc/my.cnf 或 /etc/mysql/my.cnf 文件中添加如下:
slow_query_log=ON slow-query-log-file=/var/lib/mysql/slow-query.log long_query_time=0
修改完重启mysql:
service mysqld restart
永久开启博主觉得没人会这么做吧?
关于慢查询日志的分析,应该没人还不会用mysqldumpslow吧?由于它是mysql自带工具,使用简单,所以很是比较受欢迎的,也有一些需要单独安装的工具,比如pt-query-digest,看个人习惯吧。
mysqldumpslow的使用很简单:
mysqldumpslow -s c -t 10 /var/lib/mysql/8e46c78ba828-slow.log
后面的路径要填上面我们查询出来的路径,这里解释下里面字母的含义:
-s代表排序方式,c为排序的选项之一,总共有c,t,l,r四种排序方式,分别是:记录次数,时间,查询时间,返回的记录数,如果想要倒叙,就在字母前加一个a,ac,at,al,ar。
-t代表top n的意思,这里是10,也就是top10的数据。
简单做个测试:

可以在途中的最后看到我们查询的语句,这也是mysqldumpslow 的一大优点之一,毕竟我们是要看具体哪条SQL查询的比较慢的。但要注意,慢日志查询还是比较耗性能的,一般不要随便开启,一旦使用,就是在生产环境,用到时开启,用完后关闭即可。
EXPLAIN分析查询
EXPLAIN关键字可以模拟优化器执行SQL查询语句,就可以知道MySQL是如何处理SQL语句的,EXPLAIN的作用如下:
- 查看表的读取顺序;
- 查看哪些索引被用到;
- 查看表之间的引用关系;
- 查看被优化器查询的数据有多少行;
EXPLAIN使用起来也比较简单:
explain sql语句
比如:

这里博主只是简单的一张表查询,下面我们来做个多表查询:
创建三张最简单的表:
create table t1(
id int primary key,
name varchar(20),
col1 varchar(20),
col2 varchar(20),
col3 varchar(20)
);
create table t2(
id int primary key,
name varchar(20),
col1 varchar(20),
col2 varchar(20),
col3 varchar(20)
);
create table t3(
id int primary key,
name varchar(20),
col1 varchar(20),
col2 varchar(20),
col3 varchar(20)
);
insert into t1 values(1,'zs1','col1','col2','col3');
insert into t2 values(1,'zs2','col2','col2','col3');
insert into t3 values(1,'zs3','col3','col2','col3');
create index ind_t1_c1 on t1(col1);
create index ind_t2_c1 on t2(col1);
create index ind_t3_c1 on t3(col1);
create index ind_t1_c12 on t1(col1,col2);
create index ind_t2_c12 on t2(col1,col2);
create index ind_t3_c12 on t3(col1,col2);
接着执行下面的explain语句:
explain select t2.* from t1,t2,t3 where t1.id = t2.id and t1.id = t3.id and t1.name = 'zs';
 下面我们来解释下各值的作用:
下面我们来解释下各值的作用:
- id:id值越大,优先级越高,如果想等,则从上到下开始;
- select_type
- SIMPLE : 简单的select查询,查询中不包含子查询或者UNION
- PRIMARY: 查询中若包含复杂的子查询,最外层的查询则标记为PRIMARY
- SUBQUERY : 在SELECT或者WHERE列表中包含子查询
- DERIVED : 在from列表中包含子查询被标记为DRIVED衍生,MYSQL会递归执行这些子查询,把结果放到临时表中
- UNION: 若第二个SELECT出现在union之后,则被标记为UNION,若union包含在from子句的子查询中,外层select被标记为derived
- UNION RESULT: 从union表获取结果的select
- table:这一行和哪张表有关,是哪张表的;
- type:type显示的是访问类型,是一个重要指标,结果值从最好到最坏依次是system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range(尽量保证) > index > ALL,一般需要保证查询是range,最好是ref
- system:表中只有一行记录(系统表),这是const类型的特例, 基本上不会出现
- const:通过索引一次查询就找到了,const用于比较primary key或者unique索引,该表最多有一个匹配行,在查询开始时读取。由于只有一行, 因此该行中的值可以被优化器的其余部分视为常量。const 表非常快, 因为它们只读一次
- eq_ref:读取本表中和关联表表中的每行组合成的一行。除 了 system 和 const 类型之外, 这是最好的联接类型。当连接使用索引的所有部分时, 索引是主键或唯一非 NULL 索引时, 将使用该值
- ref :非唯一性索引扫描,返回匹配某个单独值的所有行,本质上也是一种索引访问,它返回所有符合条件的行
- range : 只检索给定范围的行, 使用一个索引来选择行,key列显示的是真正使用了哪个索引,一般就是在where条件中使用between,>,
- index : 扫描整个索引表, index 和all的区别为index类型只遍历索引树,这通常比all快,因为索引文件通常比数据文件小,虽然index和all都是读全表,但是index是从索引中读取,而all是从硬盘中读取数据
- all: 全表扫描 :将遍历全表以找到匹配的行
- key:真正使用的索引,如果为null,表示没有使用索引,这个比较常用
- key_len:索引中使用的字节数,可通过该列计算查询中使用的索引的长度,长度越短越好
- ref:显示索引的哪一列被使用了,如果可能的话,是一个常数。表示哪些列或者常量被用于查找索引列上的值
- rows:根据表统计信息及索引选用的情况,估算并找出所需记录要读取的行数 (有多少行记录被优化器读取) ,越少越好
- extra:包含不适合在其他列中显示但十分重要的额外信息。
其实这里你能用到的信息很少,回看关键数据就行,主要看有没有使用我们预期的索引,判断索引是否生效,其他的一般不太用得到,但也要具体情况具体分析。
索引优化
关于索引的数据结构,可看这篇博客:索引的数据结构
这里仅说明索引失效的几种情况,方便大家对号入座:
- 全值匹配,这是查询大忌,尽量用到什么给什么;
- 最左前缀法则,如果索引有多列,要从左开始,并不跳过中间的索引,比如A,B,C三个索引,使用时,不能直接用BC,AC直接查,但可以AB,ABC使用,否则索引失效;
- 不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),如果做的话,会导致索引失效而转向全表扫描;
- 存储引擎不能使用索引中范围条件(bettween、、in等)右边的列(范围条件右边与范围条件使用的同一个组合索引,右边的才会失效,若是不同索引则不会失效);
- mysql5.7 在使用不等于(!= 或者)的时候无法使用索引会导致全表扫描,但8.0不会;
- mysql5.7 is not null无法使用索引,但是is null是可以使用索引的,但8.0不会
- like以%开头(‘%abc…’)mysql索引失效会变成全表扫描的操作
- 字符串不加单引号索引失效 ( 底层进行转换使索引失效,使用了函数造成索引失效)(隐式类型转换)
一般在开发中,当要进行调优时,需要有一定的依赖信息,可以通过show status like 'Handler_read%';查看索引的使用情况:
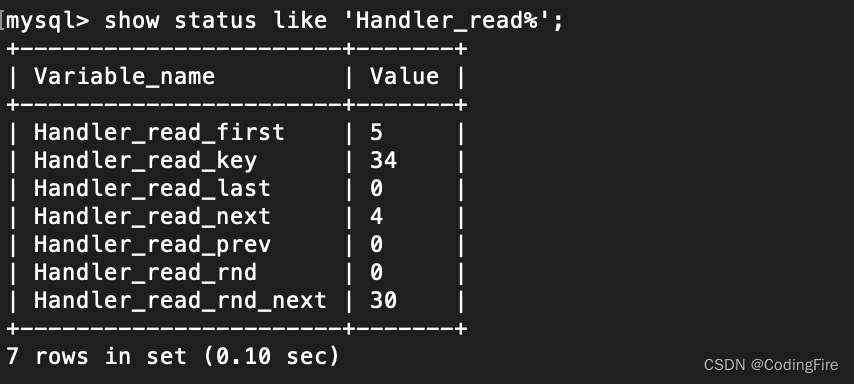
handler_read_key:这个值越大说明使用索引查询到的次数越多。
handler_read_rnd_next:这个值越高,说明查询越低效。
基于此,再去进行优化,如果这里数据很好,那就没这个必要。
数据库优化
表结构优化
表结构优化其实很简单,在创建表的时候对字段进行约束就可以,但最简单的往往是最容易让人忽略的地方,下面,博主大致列出需要注意的地方:
- 将表字段定义为NOT NULL约束,因为MySQL中空值的列不好进行查询优化,NULL值会使索引以及索引的统计信息变得很复杂;
- 对于一些特定类型的字段,比如性别,可用布尔;类型,可用枚举;
- 对于一些数值类型的字段,尽量准确使用其类型,比如年龄,简单的int就可以,甚至使用TINYINT(4)、SMALLINT(6)、MEDIUM_INT(8)作为整数类型而非INT,非负则加上UNSIGNED
- VARCHAR的长度控制为需要的长度,比如身份证号码,位数难道还有超过18位的?
- 使用TIMESTAMP而非DATETIME,但TIMESTAMP只能表示1970 – 2038年,比DATETIME表示的范围小得多,而且TIMESTAMP的值因时区不同而不同;
- 单表不要有太多字段,建议在20以内;
- 合理的加入冗余字段可以提高查询速度,比如用户表和角色表,你难道还要通过用户角色关系去查角色吗?干脆直接在用户表中增加一个角色的字段,这就是冗余。
分库分表
垂直拆分
其实分库分表本不应该出现在这里,这已经是微服务架构的内容,这里提供思路,详细的分库分表方式不在此处进行说明。
以表为例,垂直拆分是将一张表中的多个字段拆分成几张表,拆分后的表具有不同的结构,更少的列,但其缺点也比较明显,插入数据时需要使用事务,查询数据时需要关联查询。
以库为例,是将不同的模块单独分配一个数据库,比如购物车数据库,订单数据库,个人信息数据库这样。
当然,你也可以选择分库分表同时存在,只是会相对麻烦,还需要高可用的架构模式,Haproxy+keepalived+mycat,但目前的微服务我们一般使用在水平拆分上会多一些。主要还是看项目的体量,微服务真的很花服务器的钱。
水平拆分
水平拆分和垂直拆分不同。
以表为例,水平拆分就像是将一张表的结构复制了多份,水平拆分后的表,结构完全相同,存储的时候需要按照一定的规则或者权重存储到不同的表中,这里多会使用mycat进行拆分,读取的时候mycat也会帮助我们去不同的表中读取。
以库为例,水平拆分后的数据库结构完全一样,里面的表完全一样,表中的字段完全一样,除了表中存储的数据,其他都一样,也是按照一定的规则权重进行存储,一般到这里多半是上了微服务架构,高可用的Haproxy+keepalived+mycat负载均衡集群了解一下。
此处不再对具体的技术进行详细说明,后期有时间会给大家单独出一篇手把手教程。
读写分离
上了一定量级的服务器难免会遇到高并发的问题,如果还是只有一台服务器难免顾此失彼,无暇他顾,就会面临数据库崩溃,数据丢失的问题,要是碰到顾客下单,那真是亏大发了,为了解决这个问题,就有了读写分离的思想,甚至是主从复制,主主复制,级联复制等等一系列的数据库架构,关于此,博主推荐两篇前些时日写的博客:
Java开发 – MySQL主从复制初体验
Java开发 – 读写分离初体验
这里就不再过多的阐述了,相信大家对此也多有了解,这两篇博客基本上能说的七七八八,入个门不在话下。
集群
这里只是提一嘴,如果需要更大的布局,就需要使用集群,主要目的是异地容灾,虽然目前大多数的服务器可能连正儿八经的微服务都没有实现,但这并不妨碍我们对这个东西要有一定的了解,关于集群,其实也是高可用负载均衡Haproxy+keepalived+mycat可以实现的功能,也许还有别的方式,博主熟悉的就是这种,后期再出教程吧,不再这里参杂了,我怕写10w的字。
存储引擎优化
InnoDB简介
InnoDB存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全,相比较MyISAM存储引擎,InnoDB写的处理效率要差一点,并且会占用更多的磁盘空间保留数据和索引。InnoDB提供了对数据库事务ACID(原子性Atomicity、一致性Consistency、隔离性Isolation、持久性Durability)的支持,实现了SQL标准的四种隔离级别。这点是MyISAM不具备的,MyISAM毕竟是非事务型数据库。
InnoDB设计的初衷就是处理大容量的数据,MySQL运行时,InnoDB会在内存中建立缓冲池,用于缓冲数据和索引。
在执行函数操作“select count(*) from table”语句时需要扫描全表,因为使用innodb引擎的表不会保存表的具体行数,需要扫描整个表才能计算多少行,是幸,也是不幸。
InnoDB引擎是行锁,粒度更小,所以写操作不会锁定全表,在并发较高时,使用InnoDB会提升效率。
综上,如果要支持事务,必须用InnoDB,基于事务回滚+日志,可以实现数据的恢复,同时,UPDETE/INSERT的表,使用处理多并发的写请求时,行锁的效率也会比表锁高。它还具有外键约束、列属性AUTO_INCREMENT支持的功能。
关于数据库结构,可以查看这两篇博客:
Java开发 – 数据库索引的数据结构
Java开发 – 数据库中的基本数据结构
相信对学习数据库有一定的帮助。
MyISAM简介
MyISAM不支持事务,不支持外键,以SELECT/INSERT为主的应用可以使用该引擎。每个MyISAM可以存储成3个文件,扩展名分别是:
- frm:存储表定义(表结构等信息)
- MYD(MYData),存储数据
- MYI(MYIndex),存储索引
不同MyISAM表的索引文件和数据文件可以放置到不同的路径下,当然,其前提一定是可以放置在相同的目录下,这个看自己。MyISAM类型的表还提供修复的工具,可以用CHECK TABLE语句来检查MyISAM表健康,并用REPAIR TABLE语句修复一个损坏的MyISAM表。
MySQL5.6以前,只有MyISAM支持Full-text全文索引,所以5.6之后,InnoDB肯定也支持了。
MyISAM引擎适合需要经常SELECT的表,它虽然不支持事务,但却可以做很多的count函数计算。
两者的区别
综上我们所说的内容,他们的区别如下:
- MyISAM是非事务安全型的,InnoDB是事务安全型的
- MyISAM锁的粒度是表级,InnoDB支持行级锁定
- MyISAM不支持外键,InnoDB支持外键
- MyISAM相对简单,在效率上要优于InnoDB,所以小型应用可以考虑使用MyISAM
- InnoDB表比MyISAM表更安全,体现在ACID
扯淡的优化方案
禁用索引
对于使用索引的表,插入记录时,MySQL会对插入的记录建立索引,如果插入大量数据,建立索引会降低插入数据速度,所以,为了解决这个问题,可以在批量插入数据之前禁用索引,数据插入完成后再开启索引。
禁用索引:
ALTER TABLE '表名' DISABLE KEYS
开启索引:
ALTER TABLE '表名' ENABLE KEYS禁用唯一性检查
唯一性校验会降低插入记录的速度,可以在插入记录之前禁用唯一性检查,插入数据完成后再开启。
禁用唯一性检查:
SET UNIQUE_CHECKS = 0;
开启唯一性检查:
SET UNIQUE_CHECKS = 1;禁用外键检查
插入数据之前执行禁止外键的检查,数据插入完成后再恢复,可以提高插入的速度。
禁用外键检查:
SET foreign_key_checks = 0;开启外键检查:
SET foreign_key_checks = 1;禁止自动提交
插入数据之前执行禁止事务自动提交,数据插入完成后再恢复,可以提高插入速度。
禁用自动提交 :
SET autocommit = 0;开启自动提交 :
SET autocommit = 1;总结吐槽
博主觉得这个挺扯淡的,虽然能提高速度,但是也有风险,感觉弊大于利,效率可以通过其他方式提高,有兴趣的自己研究研究。这里要说明一点,不是所有的优化都是必要的,好比夏天天热,衣服穿的越少越凉快,但你可曾见过在大街上裸奔的人?
缓存优化
这里的缓存并不是指Redis,es这样的缓存,而是数据库本身的缓存,可能很多人都没有想到数据库还有这功能,基本也没用过,但是当面临某些查询数据量庞大却又不要求非实时的需求时,数据库缓存将起到很大的缓解压力的作用。
数据库缓存简单分类可大致分为四种:查询缓存,全局缓存,局部缓存,其他缓存。下面一起来认识一下吧。
查询缓存
查询缓存的设置参数为query_cache_size,它可以作用于整个数据库,用来缓存MySQL中的ResultSet,也就是SQL语句执行的结果集,所以只能用在select上面。但是,查询缓存从MySQL 5.7.20开始被弃用,并在MySQL 8.0中被删除。
鉴于此,我们就简单说明下。当打开了此功能,只要select语句符合Query Cache的要求,MySQL会根据预先设定好的HASH算法将此select语句以字符串方式进行hash,然后到Query Cache中直接查找是否已有缓存。如果有,select会直接将数据返回,而放弃正常的查询步骤(如SQL语句的解析,优化器优化以及向存储引擎请求数据等),可极大的提高性能。
但Query Cache也有一个严重缺陷,那就是当某个表的数据有任何任何变化,都会导致所有使用该select语句的查询在Query Cache中的缓存数据失效。这个使用时就要格外注意了。
缓存相关变量的查看方式:
show variables like '%query_cache%';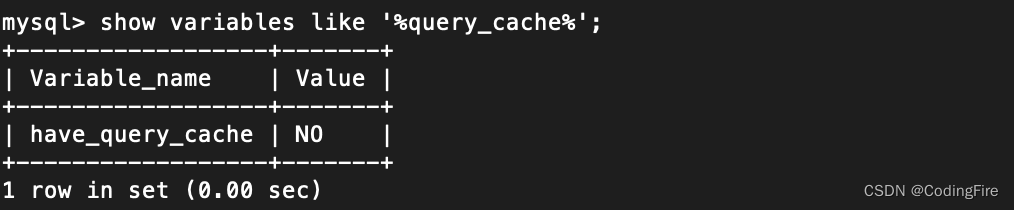
- have_query_cache:表示此版本mysql是否支持缓存
- query_cache_limit :缓存最大值
- query_cache_size:缓存大小
- query_cache_type:off 表示不缓存,on表示缓存所有结果。
可见,博主的mysql版本不支持缓存,大家可以自行查看,不过根据其特性,除非你是纯查询的表可以考虑开启,否则还是算了。
全局缓存
全局缓存在mysql启动时就会分配内存,可以在MySQL的my.conf或者my.ini文件的[mysqld]组中配置,查询缓存也是全局缓存的一种。
为什么要使用缓存呢?我们在开发中会使用Redis缓存,ES缓存,其目的都是提高查询的效率,但是我们很多人没想过的是,数据库也有缓存。数据库作为一个高IO的应用程序,如果没有IO的缓存,那真是说不过去,缓存优化,必须要优化IO,全局缓存的参数有:
- key_buffer_size(默认值:402653184,384M)、
- innodb_buffer_pool_size(默认值:134217728,128M)、
- innodb_additional_mem_pool_size(默认值:8388608,8M)、
- innodb_log_buffer_size(默认值:8388608,8M)、
- query_cache_size(默认值:33554432,32M)
以上参数看看就行,也不用记,没啥意义。下面我们来了解他们分别都是什么:
- key_buffer_size:索引块的缓冲区大小,它越大,则越能更好的处理索引,它决定了数据库索引处理的速度,尤其是索引读的速度,是对MyISAM表性能影响最大的一个参数。但如果它太大,那就适得其反了,系统运行将会变慢
- innodb_buffer_pool_size:功能和Key_buffer_size一样,是InnoDB表性能影响最大的一个参数,其在不承担任何工作时,自身的运行还需占用大约8%的开销,用于每个缓存页帧的描述、adaptive hash等数据结构,如果不是安全关闭,启动时还要恢复的话,还需另外大约12%的内存来恢复,总共多就有大约21%的开销
- innodb_additional_mem_pool_size:用来设置InnoDB存储引擎用来存放数据字典和内部数据结构的内存空间大小,当一个MySQL Instance中的数据库对象非常多的时候,需适当调整该参数的大小以确保所有数据都能存放在内存中,提高访问效率,而众所周知,内存的访问效率要高于硬盘
- innodb_log_buffer_size:设置InnoDB存储引擎的事务日志所使用的缓冲区大小,类似于Binlog Buffer,InnoDB在写事务日志的时候,为了提高性能,也是先将信息写入Innodb Log Buffer中,当满足innodb_flush_log_trx_commit参数所设置的相应条件(或者日志缓冲区写满)之后,才会将日志写到文件(或者同步到磁盘)中。可以通过innodb_log_buffer_size 参数设置其可以使用的最大内存空间。大的日志缓冲可以减少磁盘IO,理想值为1M-8M,最大不超过32M
局部缓存
局部缓存是MySQL为每一个单独的连接分配的缓存区,就像是程序中方法的栈区,大小为256K,在线程空闲时,他们还可使用线程堆栈,缓存等,而不必自己分配内存。较小的查询消耗的内存会很小,但当大的查询,发生时,如排序,临时表等,还需要分配read_buffer_size,sort_buffer_size,read_rnd_buffer_size,tmp_table_size,record_buffer的内存,这几个内存空间只在需要的时候才分配,并在使用完之后立即释放。
- read_buffer_size:MySQL读入缓冲区大小,对表进行顺序扫描的请求将分配一个读入缓冲区,MySQL会为它分配一段内存缓冲区。read_buffer_size变量控制的就是该缓冲区的大小。如果对表的顺序扫描请求非常频繁,且扫描进行的太慢,可以通过增加该变量值大小提高性能
- sort_buffer_size:MySQL执行排序使用的缓冲大小,如果想要增加ORDER BY的速度,首先让MySQL使用索引,如果不能使用索引,则尝试增加sort_buffer_size变量的大小来提高排序速度
- read_rnd_buffer_size:MySQL随机读缓冲区大小,当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读缓存区。之后在进行排序查询时,MySQL会首先查询该缓冲区内是否有排好序的数据,从而避免磁盘搜索,提高查询效率,如果对大量数据进行排序,可适当调高该值。由于MySQL会为每个连接分配该缓冲空间,所以该值的大小应适当,不宜过大
- tmp_table_size:MySQL的heap (堆积)表缓冲大小,简单说就是临时表大小。所有联合在一个DML指令内完成,并且大多数联合甚至可以不用临时表就可以完成。大多数临时表是基于内存的(HEAP)表,如果是大记录长度的临时表 (所有列的长度的和)或包含BLOB列的表存储在硬盘上。当某个内部heap(堆积)表大小超过tmp_table_size时,MySQL会自动将此heap表改为基于硬盘的MyISAM表,也可以通过设置tmp_table_size值增加临时表的大小。
- record_buffer:每个顺序扫描的线程为其扫描的表分配一个这样大小的缓冲区,顺序扫描很频繁时增加该值的大小
其他缓存
- table_cache:TABLE_CACHE(5.1.3及以后版本又名TABLE_OPEN_CACHE),table_cache是表缓存的大小,当MySQL访问一个表时,如果在表缓冲区中还有空间,该表就被打开并放入其中,这样可以更快地访问表内容,但这并不是随意设置table_cache的理由,如果设置过高,可能会造成文件描述符不足,造成性能不稳定或连接失败的问题
- thread_cache_size:服务器线程缓存数量,默认thread_cache_size=8,表示可以重新被利用的保存在缓存中线程的数量,当断开连接时,如果缓存中还有空间,那么客户端的线程会被放到缓存中,如果线程重新被请求,就从缓存中读取,如果缓存中是空的或没有当前请求线程的缓存,若线程缓存有空间,就创建这个请求线程的缓存。增加这个值可以改善系统性能,可通过比较Connections 和 Threads_created 状态的变量查看作用。
服务器优化
服务器层面的优化,我们单纯从本地来讲,硬盘,内存,CPU是制约硬件的三大要素,但是有自己机房的公司还是在少数,云服务器还是我们的首要选择,基于此,硬盘,内存,CPU,砸钱呗!没啥好讲的。
服务器就是主机,咱暂且不说,另外两个可优化的点是MySQL服务器和Linux服务器,咱们分别来说说这俩东西。
MySQL服务器优化
这个其实也没什么好讲的,主要是参数的设置,一些常用参数如下:
- back_log:当MySql的连接数据达到max_connections时,新的请求会被存在堆栈中等待,back_log就是可以存储的最大的请求数量。如果等待连接的数量超过back_log,就存不进去了
- wait_timeout:当MySQL闲置时,超过一定时间后将会被强制关闭,默认的wait_timeout值为8小时,可自定义,如果经常发现MYSQL中有大量的Sleep进程,就需要修改wait_timeout的值了
- max_connections:MySQL服务器允许的最大连接数,该值最大不超过16384,MySql会为每个连接提供连接缓冲区,占用的内存随连接数增加,所以要适当调整该值,不能盲目设置
- max_user_connections:每个数据库用户的最大连接数,它针对的是某一个账号的所有客户端并行连接到MYSQL服务的最大并行连接数,不是所有用户。设置为0表示不限制。
- thread_concurrency:并发线程数,合理设置它的值可以有效提高MySQL性能,一般我们建议设置它为CPU核数的2倍,这样才能充分利用CPU多核的特性
- skip-name-resolve: 禁止MySQL对外部连接进行DNS解析,它可以降低MySQL进行DNS解析的时间。注意!!!如果开启该选项,所有远程主机连接授权都要使用IP地址方式,否则MySQL将无法正常处理连接请求
- default-storage-engine:default-storage-engine=InnoDB(设置InnoDB类型,另外还可以设置MyISAM类型)设置数据库存储引擎
总结
写了很多陌生的参数啊,由此可见,这些值都是把双刃剑啊 ,太小不行,太大也不行,所幸,默认值能满足很大一部分需求,只有当极限优化时才会使用这些值,我相信很多人根本没动过这些值,希望你们用不到吧,但这并不妨碍你们知道有这些东西。
结语
说实话,博主最熟悉的是优化SQL,服务器层面砸钱,分库分表优化,像是缓存上的和一些参数上的优化也很少接触,真实的环境上这些参数的设置都是比较慎重的,即使在测试环境设置了没事,也不代表生产环境可以正常,测试环境的并发…测试环境有并发吗?哈哈~所以啊,基本上普通开发不太需要考虑这些问题,还是要靠大佬们啊,不过,谁不想成为大佬啊,今天讲解的内容大家可以了解下详细的操作步骤,其实就是设置参数了,大多数参数设置多少要根据实际业务来计算,并不是随意设置的,具体还是自己用到的时候私下进行查询,希望每个看到这篇博客的童鞋都可以成为大佬。加油哦!!!
