

一、现象回顾
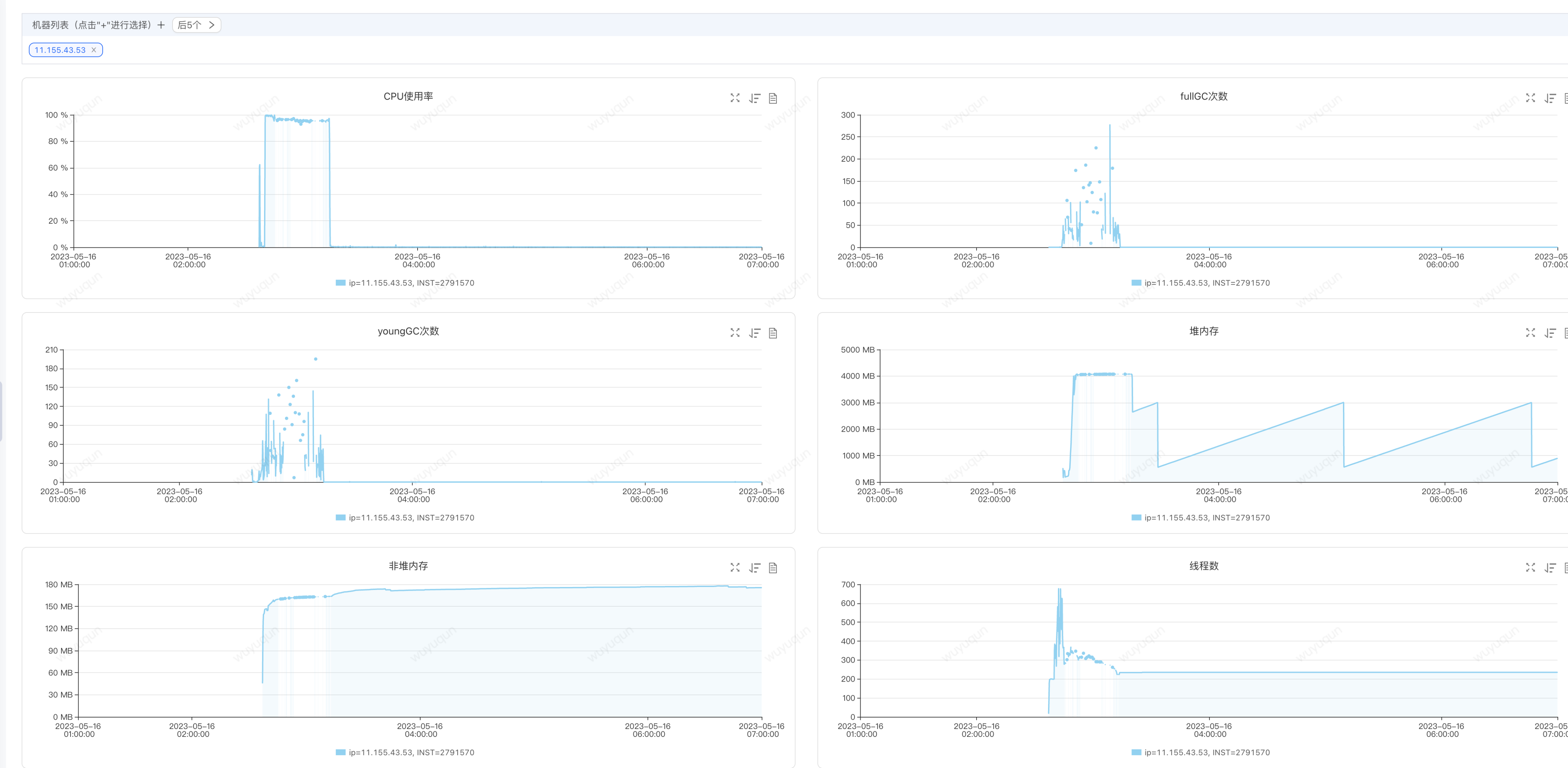
在今天ForceBot全链路压测中,有位同事负责的服务做Serverless扩容(负载达到50%之后自动扩容并上线接入流量)中,发现新扩容的机器被击穿,监控如下(关注2:40-3:15时间段的数据),我们可以看到,超高CPU,频繁FullGC,并且每次FullGC之后对内存并不回收(见FullGC时间段对应的堆内存的曲线,是一条横线)
分析结论: 内存已经被处理线程全部占完,FullGC之后基本收不回多少内存,那么意味着很快又会继续FullGC,频繁FullGC占用大量CPU时间片段和暂停会导致系统处理能力剧烈下降,最终导致整个JVM进入崩溃状态
二、问题重现
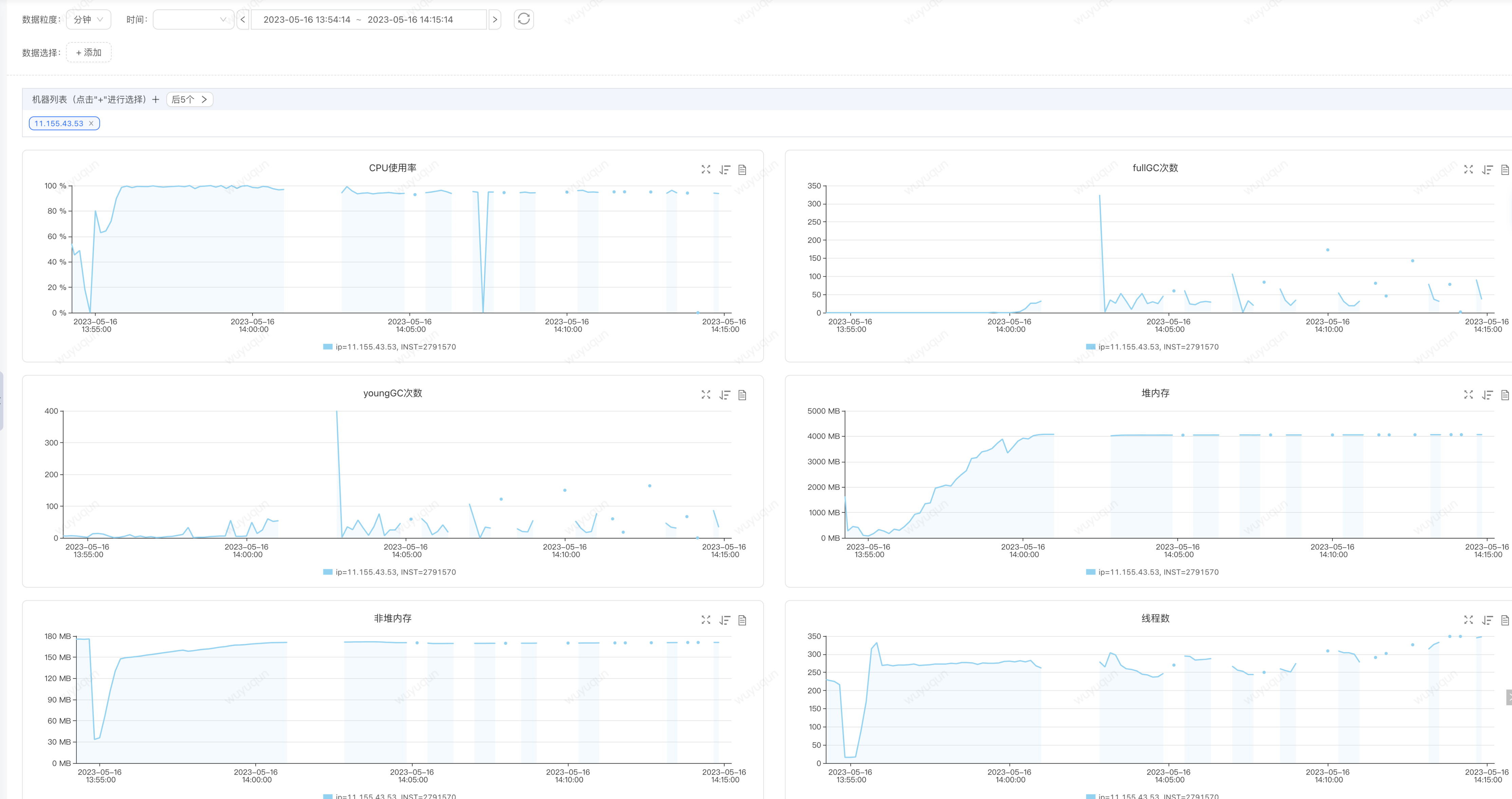
如上只是我们的理论分析,我们重新进行现象回放,模拟问题重现,目前订单单机400QPS下,CPU大概是达到30-40%,我们模拟一下在没有提前预热(重启Java服务)的情况下,使用压测脚本对服务进行请求回放,如下是我们一次重现的结果 (非必定,会有一定的概率重现),同样的高CPU、频繁FullGC,对内存无法被回收,JVM直接进入崩溃状态
分析结论: 我们需要避免瞬间流量让服务进入超高负载,进而被击穿
三、解决方案
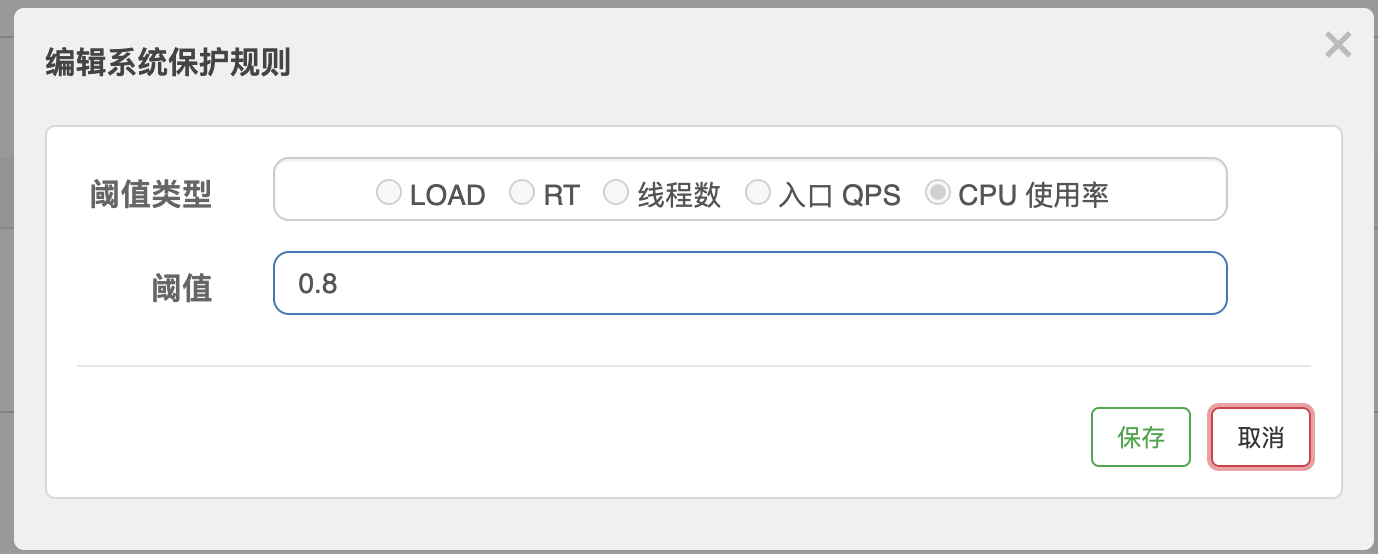
针对如上情况,我们尝试使用Sentinel的系统规则,在系统负载过高的时候自动进行熔断,避免系统过载导致被击穿,我们设置一条CPU不超过80%的系统保护规则,如下,通过后面几个过程,我们对比一下这条规则对我们系统的影响
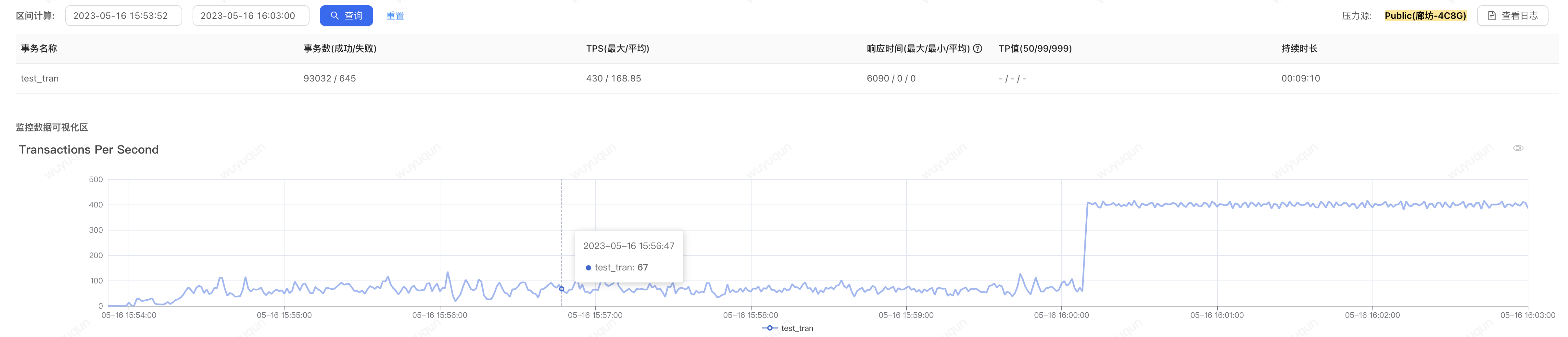
1.冷启动状态下,没有设置系统保护规则的场景
在没有配置如上规则的情况下,即便没有被击穿,我们看到,在冷启动的状态下,系统大概需要5-7分钟的时间来让系统从“准崩溃状态”中恢复回来,如下是CPU监控视图(大概6分钟左右处于高负载的CPU状态下,一旦恢复回来,CPU仅在30-40%左右)
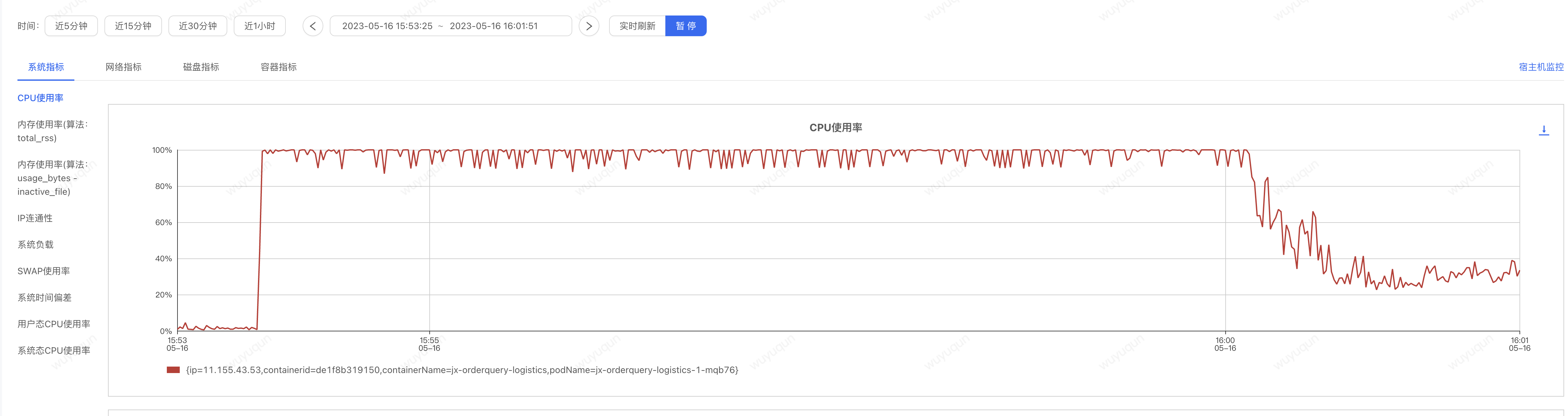
压测端在高CPU阶段QPS上不去,仅在50-100之间波动,CPU恢复之后,QPS迅速上涨到400,整个过程Sentinel无熔断发生
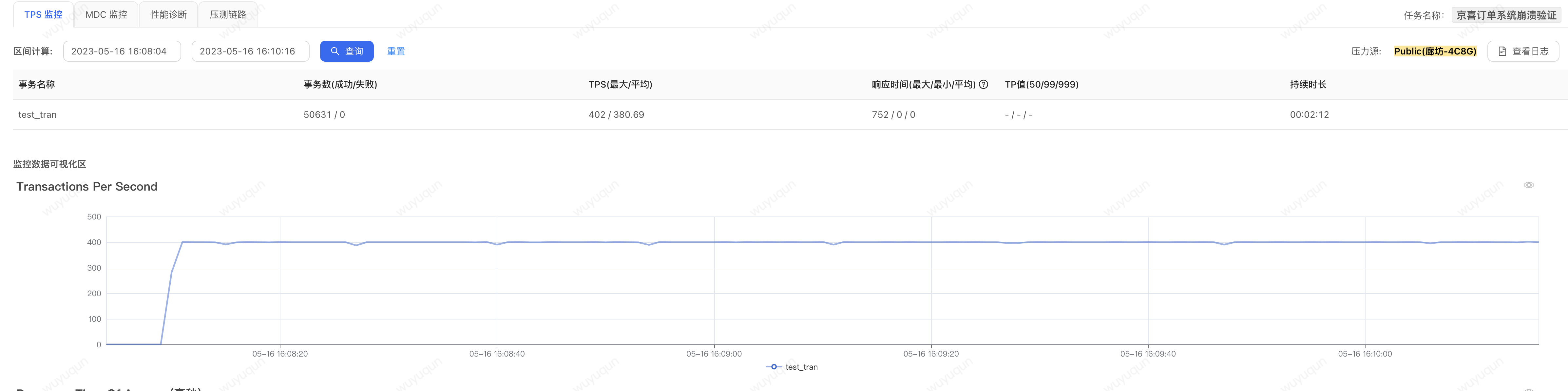
2.热启动状态下,没有设置系统保护规则:
在热启动状态下,我们在上面压测完一轮之后再压测一轮,我们可以看到这个时候系统就没有一个“预热过程”的“准崩溃状态”了
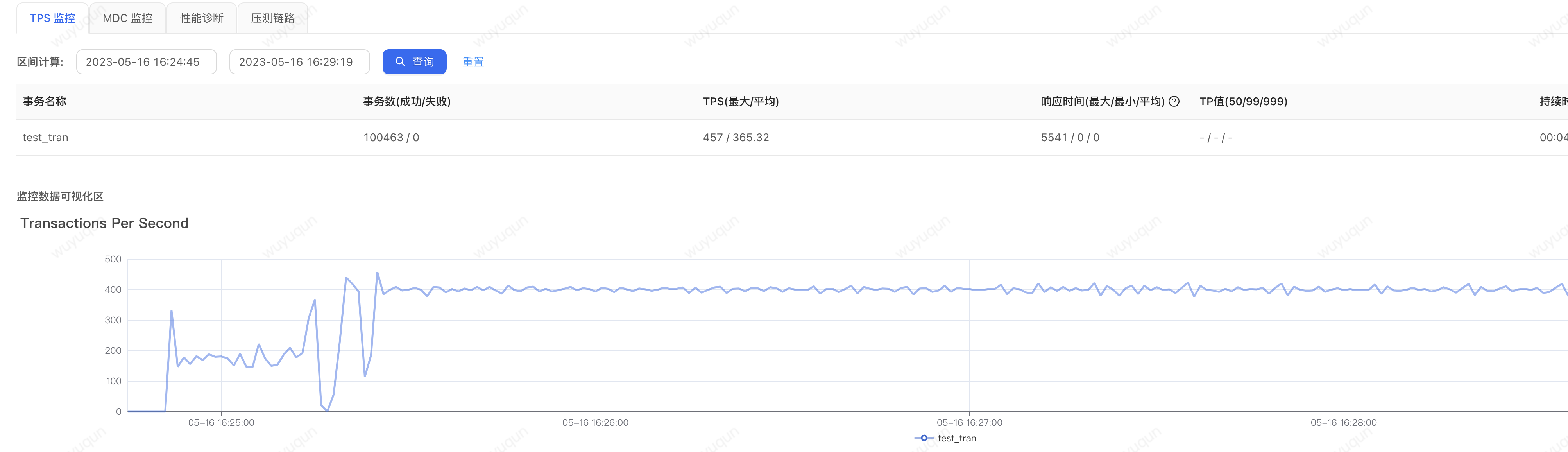
3.冷启动状态下,设置系统保护规则
我们再压测一下冷启动状态下设置系统保护规则的情况(压测前重新启动一下Java进程,让应用处于“冷启动”的状态),看如下监控图,只要系统不进入“准崩溃状态”,那么系统会很快就恢复到正常状态,从下面图上看冷启动下对系统的影响只有前一分钟
如下是压测端视图
如下是CPU的情况
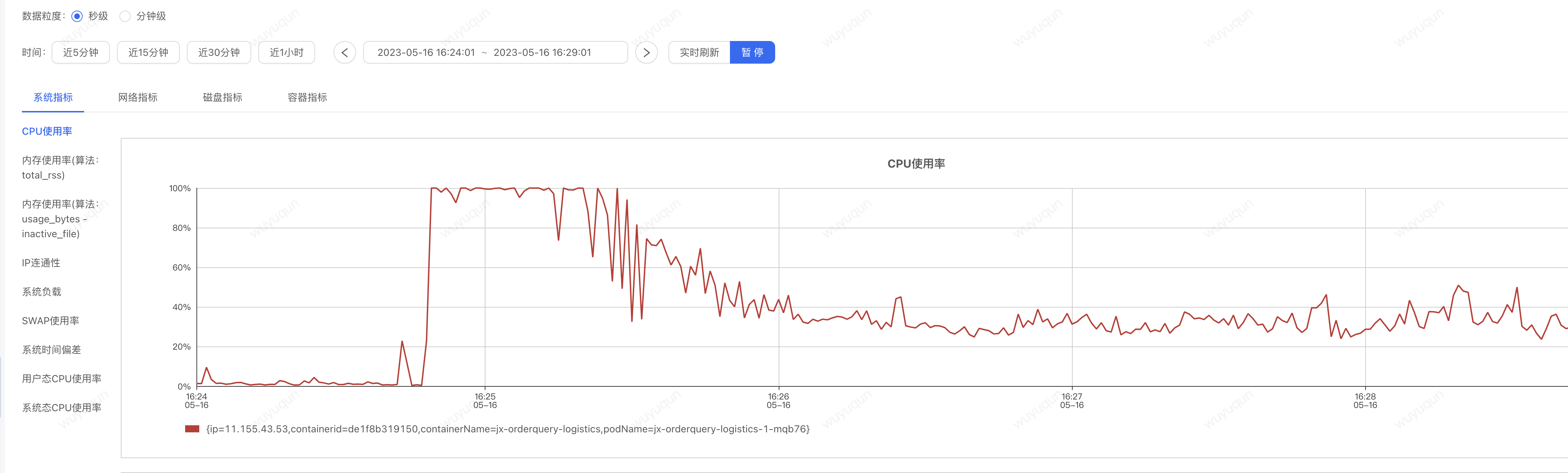
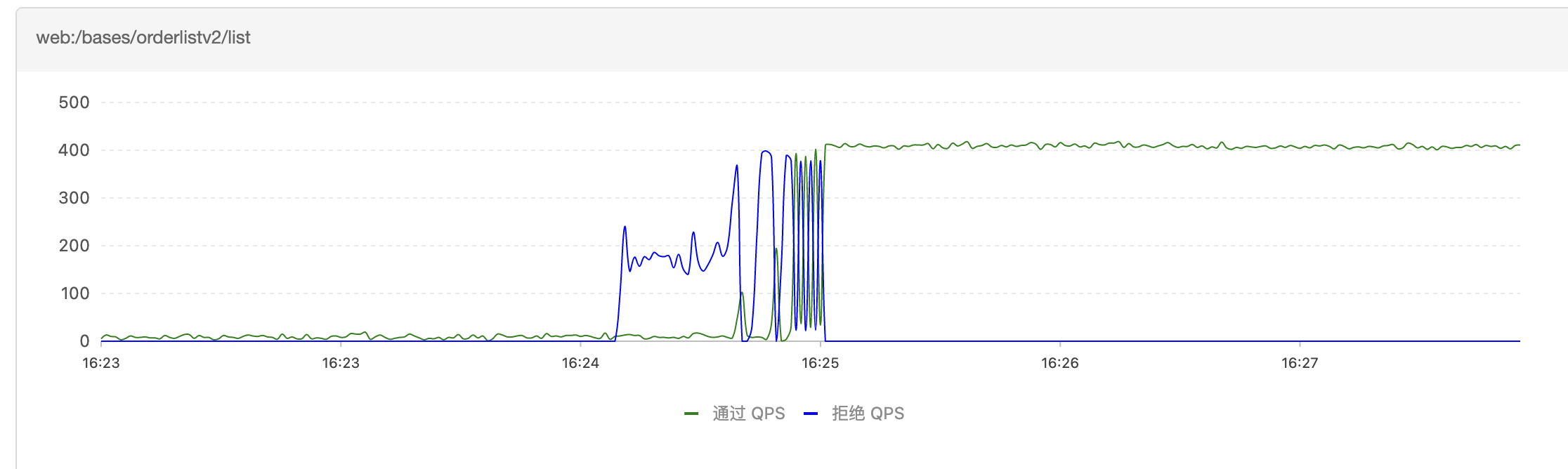
如下是Sentinel熔断情况,有1分钟左右有熔断发生
4.冷启动性能差之谜
冷启动过程性能比较慢,主要是有几方面因素导致:
1)HotSpot JVM优化:热点监测JVM会在程序运行期间不断对代码进行不同级别的优化,高频执行代码会被JIT Compiler优化到最佳的状态,而在冷启动开始运行的时候,代码还处于原始状态,性能相对会差
2)资源就绪情况:譬如一些线程池在开始运行之后才会被创建,或者程序中有一些连接是在启动之后才会开始建立
3)崩溃循环:当CPU升高之后,线程切换等操作本身可能会导致CPU更高,从而让系统螺旋式进入一种越来越糟糕的状态,直到达到一个平衡点,而上面的1)和2)随着运行的优化会在达到平衡点之后打破平衡点,螺旋式下降让系统恢复到比较好的状态,但最糟糕的情况是达不到平衡点系统直接崩溃无法恢复
四、题外话
这个问题不仅仅出现在Serverless冷扩,如果有一天,你发现请求量暴涨负载过高,于是你扩容了机器,然后你接入了流量,哐当,被打崩了……这个场景是不是太过惨淡了
作者:京东零售 吴毓群
内容来源:京东云开发者社区
