

1.数据爬取
数据爬取的内容主要包括30个岗位种类(数据分析,产品经理,产品助理,交互设计,前端开发,软件设计,IOS开发,业务分析,安卓开发,PHP开发,业务咨询,需求分析,流程设计,售后经理,售前经理,技术支持,ERP实施,实施工程师,IT项目经理,IT项目助理,信息咨询,数据挖掘,数据运营,网络营销,物流与供应链,渠道管理,电商运营,客户关系管理,新媒体运营,产品运营),每一个岗位爬取的信息包括:岗位名称、公司名称、公司规模、工作地点、薪资、工作要求、工作待遇等。
数据爬取代码展示:
1. import requests
2. from bs4 import BeautifulSoup
3. import pymysql
4. import random
5. from selenium import webdriver
6. from lxml import etree
7. import lxml
8. from selenium.webdriver import ChromeOptions
9. import re
10. import time
11. import requests
12. #定义函数,用于获取每个 url 的 html
13. def spider(url):
14. headers = {
15. "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36 Edg/94.0.992.31"}
16. try:
17. rep = requests.get(url, headers=headers)
18. rep.raise_for_status()
19. rep.encoding = rep.apparent_encoding
20. txt = rep.text
21. return txt
22. except:
23. print("解析失败")
24.
25. #定义 jiexi()函数,用于解析得到的 html
26. def jiexi(html, info,name):
27. soup = BeautifulSoup(html, "lxml")
28. text = soup.find_all("script", type="text/javascript")[3].string
29. #观察原始代码发现我们需要的数据在 engine_jds 后
30. data = eval(str(text).split("=", 1)[1])["engine_jds"]
31. for d in data:
32. try:
33. job_name = d["job_name"].replace("\", "") # 岗位名称
34. except:
35. job_name = " "
36. try:
37. company_name = d["company_name"].replace("\", "") # 公司名称
38. except:
39. company_name = " "
40. try:
41. providesalary_text = d["providesalary_text"].replace("\", "") # 薪资
42. except:
43. providesalary_text = " "
44. try:
45. workarea_text = d["workarea_text"].replace("\", "") #工作地点
46. except:
47. workarea_text = " "
48. try:
49. updatedate = d["updatedate"].replace("\", "") #更新时间
50. except:
51. updatedate = " "
52. try:
53. jobwelf = d["jobwelf"].replace("\", "") # 工作待遇
54. except:
55. jobwelf = " "
56. try:
57. companyind_text = d["companyind_text"].replace("\", "") # 公司类型
58. except:
59. companyind_text = " "
60. try:
61. companysize_text = d["companysize_text"].replace("\", "") # 公司规模
62. except:
63. companysize_text = " "
64. try:
65. at = d["attribute_text"] # 工作要求
66. s = ''
67. for i in range(0, len(at)):
68. s = s + at[i] + ','
69. attribute_text = s[:-1]
70. except:
71. attribute_text = " "
72. #将每一条岗位数据爬取下的内容以及传入参数 name 作为一个列表,依此加入到 info 列表中
73. info.append( [ name,job_name, updatedate, company_name, companyind_text, companysize_text, workarea_text, providesalary_text, attribute_text, jobwelf])
74. #将数据存到 MySQL 中名为“51job”的数据库中
75. def save(info):
76. #将数据保存到数据库表中对应的列
77. for data in info :
78. present_job = data[0] # 当前爬取岗位
79. job_name = data[1] #岗位
80. updatedate = data[2] #更新时间
81. company_name = data[3] # 公司名称
82. companyind_text = data[4] #公司类型
83. companysize_text = data[5] #公司规模
84. workarea_text = data[6] #工作地点
85. providesalary_text = data[7] #薪资
86. attribute_text = data[8] #工作要求
87. jobwelf = data[9] #工作待遇
88. # 创建 sql 语句
89. sql = "insert into jobs(当前爬取岗位,岗位,更新时间,公司名称,公司类型,公司规模,工作地点,薪资,工作要求,工作待遇) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
90. # 执行 sql 语句
91. cursor.execute(sql, [present_job, job_name, updatedate, company_name, companyind_text, companysize_text,
92. workarea_text, providesalary_text, attribute_text, jobwelf])
93. db.commit() # 提交数据
94. if __name__ == '__main__': #主函数
95. job=["产品经理","产品助理","交互设计","前端开发","软件设计","IOS开发","业务分析","安卓开发","PHP开发","业务咨询","需求分析","流程设计"
96. ,"售后经理","售前经理","技术支持","ERP实施","实施工程师","IT项目经理","IT项目助理","信息咨询","数据挖掘","数据运营","数据分析","网络营销",
97. "物流与供应链","渠道管理","电商运营","客户关系管理","新媒体运营","产品运营"]
98. page_list=['1141', '62', '169', '619', '356', '61', '229', '64', '56', '356', '1379', '147', '62', '29', '2000', '173', '184', '10', '2', '396', '221', '115', '2000', '381', '5', '295', '1233', '280', '699', '352']
99. #https://www.pexels.com/
100. option = ChromeOptions()
101. UA="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36 Edg/94.0.992.31"
102. option.add_argument(f'user-agent={UA}')
103. option.add_experimental_option('useAutomationExtension', False)
104. option.add_experimental_option('excludeSwitches', ['enable-automation'])
105. web = webdriver.Chrome(chrome_options=option) # chrome_options=chrome_opt,,options=option
106. web.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
107. "source": """
108. Object.defineProperty(navigator, 'webdriver', {
109. get: () => undefined
110. })
111. """
112. })
113. web.implicitly_wait(3)
114. url='https://search.51job.com/list/000000,000000,0000,00,9,99,%E4%BA%A7%E5%93%81%E7%BB%8F%E7%90%86,2,2.html?'
115. web.get(url)
116. time.sleep(6)
117. le=len(job)
118. db = pymysql.connect( # 连接数据库host="127.0.0.1", #MySQL 服务器名
119. user="root", # 用户名
120. password="root", # 密码
121. database="python上机", # 操作的数据库名称charset="utf8"
122. )
123. cursor = db.cursor()
124. for j in range(23,le):
125. for i in range(1,int(page_list[j])):#页面
126. info = []
127. # url = "https://search.51job.com/list/000000,000000,0000,00,9,99," + j + ",2," + str(i) + ".html?"
128. url = "https://search.51job.com/list/000000,000000,0000,00,9,99,{},2,{}.html?".format(job[j], i)
129. web.get(url)
130. ht = web.page_source
131. soup = BeautifulSoup(ht, "lxml")
132. jiexi(ht, info,job[j])
133. print('岗位{}:{}/{}'.format(j,i,page_list[j]))
134. time.sleep(1)
135. save(info)
136. time.sleep(1)
137. cursor.close()
138. # 关闭连接
139. db.close()
数据爬取结果:
2.数据清洗
2.1匹配工作岗位
由于岗位爬取过程是以整页为单位进行的数据爬取,在爬取的最后一页岗位信息内容中会包含非关键词岗位搜索内容,为了确保爬取岗位信息的准确性,进行岗位匹配的数据清洗过程。
代码展示:
1. def pipei():
2. cursor = db.cursor() #获取操作游标
3. cursor.execute("select * from jobs") #从 jobs 表中查询所有内容并保存
4. results = cursor.fetchall() #接受全部的返回结果
5. after_pipei = [] #建立一个空列表, 用来存储匹配后数据
6. for each_result in results:
7. if each_result[-1] == '物流与供应链':
8. if '物流' in each_result[0] or '供应链' in each_result[0]:
9. after_pipei.append(each_result)
10. elif each_result[-1] == '新媒体运营' or each_result[-1] == '电商运营':
11. if '运营' in each_result[0]:
12. after_pipei.append(each_result) # 由于在以关键词“电商运营” 或“新媒体运营” 搜索的岗位信息中包含大量具体电商或
13. #新媒体平台名称的岗位名称, 如“拼多多运营”“抖音运营” 等, 因此在这两类
14. #岗位名称匹配时我们认为只要岗位名称中包含“运营” 就算匹配成功。
15. elif each_result[-1] == '客户关系管理':
16. if '客户关系' in each_result[0]:
17. after_pipei.append(each_result)
18. elif each_result[-1] == '安卓开发':
19. if '安卓' in each_result[0] or 'Android' in each_result[0]:
20. after_pipei.append(each_result) # 由于在很多公司的招聘岗位中“安卓” 会以“Android” 英文形式出现, 因此, 在以“安卓开发” 为关键词进行搜索时, 我们认为只要包含“安卓” 或“Android” 开发就算匹配成功。
21. elif each_result[-1][:-2] in each_result[0] and each_result[-1][-2:] in each_result[0]:
22. after_pipei.append(each_result) #剩余岗位需两个关键词都存在岗位名称中, 例如包含“数据” 或“分析” 在以“数据分析”
23. else:
24. after_pipei.append(each_result) #为关键词搜索的岗位名称中, 我们就认为匹配成功。
25. cursor.close() #关闭游标
26. return after_pipei #返回匹配后的列表
2.2工作地点筛选
由于爬取到的工作地点信息格式不统一,有的地点只给出一级地名,有的给出了两级,我们将岗位对应的工作地点统一保留到给出的最高级别地名,例如“上海—普陀区”只保留“上海”。
代码展示:
1. def split_city(data):
2. after_split_city = [] #建立一个空列表, 用来存储匹配后数据
3. for each_date in data:
4. each_date_list = list(each_date)
5. each_date_list[5] = each_date_list[5].split('-')[0] #将数据表中工作地点列以'-'进行切割, 选取第一个元素替换
6. after_split_city.append(each_date_list)
7. return after_split_city #返回筛除后的数据 2.3清洗薪资
由于爬取到的薪资信息大都是以区间数据形式出现, 例如“5000-6000/月”,并且薪资单位不一致,有“千/月”、“万/年”等形式,因此对薪资数据的清洗主要包括两个方面:
1)对区间数值取组中值。如“5000-6000/月”处理为“5500/月”;
2)统一量纲。将薪资的单位统一为“千/月”,如“5500/月”处理为“5.5 千/月”,“24万/年”处理为“20千/月”。
代码展示:
1. def split_city(data):
2. after_split_city = [] #建立一个空列表, 用来存储匹配后数据
3. for each_date in data:
4. each_date_list = list(each_date)
5. each_date_list[5] = each_date_list[5].split('-')[0] #将数据表中工作地点列以'-'进行切割, 选取第一个元素替换
6. after_split_city.append(each_date_list)
7. return after_split_city #返回筛除后的数据def salary(data):
8. after_salary=[] #建立一个空列表, 用来存储匹配后数据
9. for each_data in data:
10. if each_data[6] != '' and each_data[6][-3] != '下' and each_data[6][-3] != '上':
11. #筛除缺失值, 以小时计费, 给出的薪资表达为在“……以下” 及“……以上” 等难以计算数据的工作岗位
12. #统一量纲(单位:千/月)
13. if each_data[6][-1] == '年':
14. if "-" in each_data[6]:
15. each_data[6] = str((float(each_data[6].split('万')[0].split('-')[0]) + float(each_data[6].split('万')[0].split('-')[1])) * 5/12) + '千/月'
16. else:
17. each_data[6] = str((float(each_data[6].split('万')[0].split('-')[0])) * 10/12) + '千/月'
18. elif each_data[6][-1] == '天':
19. if "-" in each_data[6]:
20. each_data[6] = str((float(each_data[6].split('元')[0].split('-')[0])+float(each_data[6].split('元')[0].split('-')[1]) )* 15/1000) +'千/月'
21. else:
22. each_data[6] = str(float(each_data[6].split('元')[0]) * 30 / 1000) + '千/月'
23. elif each_data[6][-3] == '万':
24. if "-" in each_data[6]:
25. each_data[6] = str((float(each_data[6].split('万')[0].split('-')[0]) + float(each_data[6].split('万')[0].split('-')[1])) * 5) + '千/月'
26. else:
27. each_data[6] = str((float(each_data[6].split('万')[0].split('-')[0])) * 10) + '千/月'
28. elif each_data[6][-1] == '时':
29. if "-" in each_data[6]:
30. each_data[6] = str((float(each_data[6].split('元')[0].split('-')[0])+float(each_data[6].split('元')[0].split('-')[1]))*160/1000)+'千/月'
31. else:
32. each_data[6] = str((float(each_data[6].split('元')[0].split('-')[0]))*160/1000)+'千/月'
33. else:
34. if "-" in each_data[6]:
35. each_data[6] = str((float(each_data[6].split('千')[0].split('-')[0]) + float(each_data[6].split('千')[0].split('-')[1])) /2 ) + '千/月'
36. else:
37. each_data[6] = str((float(each_data[6].split('千')[0].split('-')[0]))) + '千/月'
38. after_salary.append(each_data)
39. return after_salary #返回平均工资后的数据 2.4清洗工作要求
由于爬取到的“工作要求”内容中一般包含“地点,经验,学历,招收人数”四项内容,在本次实验中只用到“经验” 和“学历” 两项内容,因此此步骤需要清洗掉其他两项内容。
代码展示:
1. def job_attribute_text(data):
2. for each_data in data:
3. if len(each_data[7].split(',')) == 3:
4. if '经验' in each_data[7].split(',')[1] or '在校生' in each_data[7].split(',')[1]:each_data[7] = each_data[7].split(',')[1] + ','
5. #以“,” 切割后的列表长度为 3,若不包含“经验” 元素,则保留“,学历” 形
6. #式内容
7. else:
8. each_data[7] = ',' + each_data[7].split(',')[1]
9. #以“,”切割后的列表长度为 4,选取中间两个元素,保留“经验,学历”形式
10. #内容
11. elif len(each_data[7].split(',')) == 4:
12. each_data[7]= each_data[7].split(',')[1]+','+each_data[7].split(',')[2]
13. else:
14. each_data[7] = ''
15. return data #返回筛除后的数据
16. #将清洗后的数据保存到数据库中 after_clean 表中,代码和保存爬取数据时类似
17. def save(data):
18. cursor = db.cursor()
19. for each_data in data:
20. job_name = each_data[0]
21. updatedate = each_data[1]
22. company_name = each_data[2]
23. companyind_text = each_data[3]
24. companysize_text = each_data[4]
25. workarea_text = each_data[5]
26. providesalary_text = each_data[6]
27. attribute_text = each_data[7]
28. jobwelf = each_data[8]
29. present_job = each_data[9]
30. sql = "insert into after_clean(当前爬取岗位,岗位,更新时间,公司名称,公司类型,公司规模,工作地点,薪资,工作要求,工作待遇)values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
31. cursor.execute(sql,[present_job, job_name, updatedate,company_name, companyind_text,companysize_text, workarea_text,providesalary_text, attribute_text, jobwelf])
32. db.commit()
33. cursor.close()
34. db.close()
35. #定义主函数, 用以执行以上四步数据清洗过程
36. if __name__ == '__main__':
37. data = pipei()
38. data1 = split_city(data)
39. data2 = salary(data1)
40. data3 = job_attribute_text(data2)
41. save(data3)
数据清洗前:
数据清洗后:
3.数据可视化
3.1柱状图
用柱状图描绘九小类岗位(技术管理类,IT运维类,技术开发类,业务咨询类,技术支持类,数据运营类,市场职能类,产品运营类,数据管理类)的市场需求的数量特征。
代码展示:
1. #柱状图
2. #描绘九小类岗位的市场需求的数量特征
3. def gangweishuliang_hist (): #主函数调用的 gangweishuliang_hist ()函数
4. cursor = db.cursor()
5. cursor.execute("select `当前爬取岗位` from after_clean")
6. #选出 30 个岗位关键词所在的列数据
7. results = cursor.fetchall()
8. jobs = ['产品经理','产品助理','交互设计','前端开发','软件设计',
9. 'IOS 开发','业务分析','安卓开发','PHP 开发','业务咨询',
10. '需求分析','流程设计','售后经理','售前经理','技术支持',
11. 'ERP 实施','实施工程师','IT项目经理','IT项目助理',
12. '信息咨询','数据挖掘','数据运营','数据分析','网络营销',
13. '物流与供应链','渠道管理','电商运营','客户关系管理',
14. '新媒体运营','产品运营']
15. count = [] #创建一个空列表, 用于存储每种岗位的数量值
16. for i in range(len(jobs)):
17. count.append(0) #先在空列表中创建 30 个 0 元素
18. for each_result in results:
19. for i in range(0, 30):
20. if each_result[0] == jobs[i]:
21. count[i] += 1
22. continue #计算每种岗位的数量
23. jobs_classification = ['技术管理类','IT运维类','技术开发类','业务咨询类',
24. '技术支持类','数据运营类','市场职能类','产品运营类',
25. '数据管理类'] #将 30种岗位划分为九小类
26. counts = [] #创建一个空列表, 用于存储每小类岗位的数量值
27. for i in range(len(jobs_classification)):
28. counts.append(0) #先在空列表中创建 9 个 0 元素
29. #根据大纲中给出的分类表, 依据 30 种岗位数量值, 分别计算出九小类岗位的数量值
30. counts[0] = count[0] + count[1] + count[2]
31. counts[1] = count[17] + count[18]
32. counts[2] = count[3] + count[4] + count[5] + count[6] + count[7] + count[8]
33. counts[3] = count[9] + count[10] + count[11]
34. counts[4] = count[12] + count[13] + count[14] + count[15] + count[16]
35. counts[5] = count[21] + count[22]
36. counts[6] = count[23] + count[24] + count[25]
37. counts[7] = count[26] + count[27] + count[28] + count[29]
38. counts[8] = count[19] + count[20]
39. plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
40. plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
41. #画柱状图
42. fig, ax = plt.subplots(figsize=(10, 7)) #定义图片的大小
43. ax.bar(x=jobs_classification, height=counts, color=Colors) # x 是所有柱子的下标的列表 jobs_classification, height 包含所有柱子的高度值的列表 counts, width每个柱子的宽度, 本代码使用默认值。 align 柱子对齐方式, 有两个可选值: center和 edge, 本代码使用默认值“center”。 color 为每根柱子呈现的颜色。
44. ax.set_title("岗位数量柱状图", fontsize=15) #为柱状图命名并设置字体大小
45. for x, y in enumerate(counts):
46. plt.text(x, y + 5, '%s' % y, ha='center') #为每根柱子加上数值
47. plt.show() #展示图片
48. cursor.close() #关闭操作游标 可视化结果:
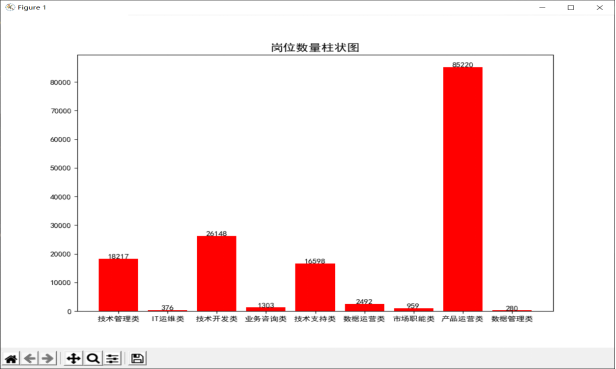
从图中可以看出,在我们清洗过后的26400条岗位数据中,九小类岗位的市场需求数量存在很大的差异。
1.从图中可以明显看出产品运营类的岗位数量最多,高达85220条。这可能是因为这一类包括电商运营与新媒体运营这两大近年来发展迅猛的市场需求,这体现了信管专业就业的市场导向,符合互联网行业变化快的特征。
2.可以看出信管专业市场需求的第二梯队主要集中在技术开发、技术管理和技术支持类,岗位数量分别达18217、26148、16598条。
3.市场对于信管专业在数据管理、IT运维、市场职能等方面的需求较少。岗位数量最少的是数据管理类,在15989条岗位中仅有280条,这可能是因为企业对数据挖掘和信息咨询岗位的定位在于少而精,导致需求量不多,但是要求高。
综上,可以发现信管专业就业主要有两个方向,一个是以近期较热门的电商运营与新媒体运营为代表的产品运营类岗位,另一个是以技术为主的技术开发、技术管理和技术支持类。因此,我们除了需要及时关注行业发展动态,捕捉市场需求的变化外,还需要不断提升自身的技术水平,以期在未来就业市场的激烈竞争中获取更大的竞争优势。
3.2饼状图
代码展示:
1. #描绘所有岗位学历要求饼图
2. def xueli_pie(): #主函数调用的 xueli_pie()函数
3. cursor = db.cursor()
4. cursor.execute("select `工作要求` from after_clean") #选出工作要求的列数据
5. results = cursor.fetchall()
6. xueli = [] #创建一个空列表, 用来装工作要求种的“学历“数据
7. for each_result in results:
8. if each_result[0] !='' and each_result[0].split(',')[1]!='':
9. xueli.append(each_result[0].split(',')[1])
10. after_quchong_xueli = list(set(xueli)) #对学历去重复值, 由于元组不能更改, 转换为列表类型, 便于后续操作
11. after_quchong_xueli = ['在校生/应届生' if each == '在校生\/应届生' else each for each in after_quchong_xueli]
12. counts = [] #创建一个空列表, 用于装所有岗位信息中每一种学历的数量值
13. for i in range(len(after_quchong_xueli)):
14. counts.append(0)
15. for each in xueli:
16. for i in range(len(after_quchong_xueli)):
17. if each == after_quchong_xueli[i]:
18. counts[i]+=1 #计算每种学历的数量值
19. #在画图前, 先设置参数 explode, 计算每个城市数据分析岗位占比, 让占比小于 5%的城市在饼图中突出一部分
20. A = []
21. for i in range(0, len(after_quchong_xueli)):
22. A.append(0)
23. for i in range(0,len(after_quchong_xueli)):
24. total = sum(counts[:len(after_quchong_xueli)])
25. if (counts[i]/total) 可视化结果:
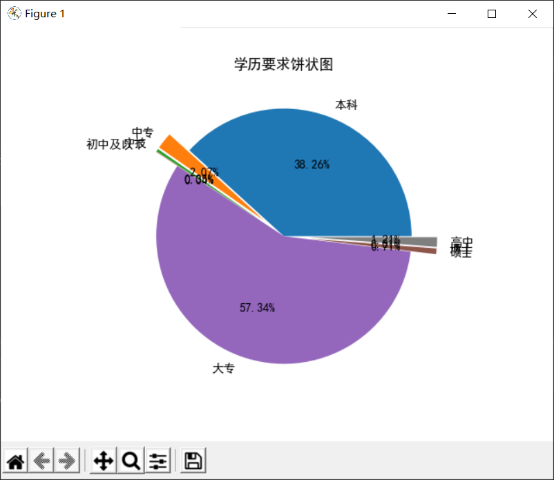
从图中可以看出,市场对信管专业同学的学历还是有一定要求的。
1.学历要求主要是大专生和本科生,这两类学历占比超过了95%。即对于找工作来说,本科学历是一个明显的门槛,拥有本科学历后可以选择就业市场上接近99%的工作,就业前景十分良好。
2.大专以下学历的岗位数量只占3%左右,这体现了市场对我们的要求是起码需要经过专业的训练,是一个有门槛的行业。这也符合信管专业既包括专业技术学习,也包括管理理论学习的专业特色。
3.硕士与博士的行业需求只占1%左右。这首先与硕博士的市场供给有关,即就业市场上求职的硕博士并不多,导致需求也不多。其次,这也说明就业市场上只需要硕博士的高要求岗位并不多,绝大部分岗位对学历要求没这么高。
综上我们就业来说,只要达到木科学历就可以胜任绝大部分工作,继续深造对就业选择数量的增加不多。
3.3条形图
代码展示:
1. #描绘所有岗位公司规模的数量特征
2. def company_size(): #主函数调用的 company_size()函数
3. cursor = db.cursor()
4. cursor.execute("SELECT `公司规模` FROM `after_clean`") #选出公司规模列
5. results = cursor.fetchall()
6. #筛出非空数据,装进 size 列表中
7. size = []
8. for each_result in results:
9. if each_result[0] != '' and each_result[0].split(',')[0] != '':
10. size.append(each_result[0].split(',')[0])
11. # 将公司规模类型去重复值,得到例如['少于50 人', '1000-5000 人', '5000-10000人', '50-150 人', '150-500 人', '10000 人以上', '500-1000 人']的 after_quchong 列表
12. after_quchong = list(set(size))
13. # 计算公司规模的类型数量 type_size
14. type_size = len(after_quchong)
15. #计算每种公司规模的岗位数
16. #创建一个起始值为 0,有 type_size 各元素的 count_each_size 列表
17. count_each_size = []
18. for i in range(type_size):
19. count_each_size.append(0)
20. # 计算不同规模公司的岗位数量
21. for each_size in size:
22. for each in range(0, type_size):
23. if each_size == after_quchong[each]:
24. count_each_size[each] = count_each_size[each] + 1
25. # 创建一个公司规模类型和数量一一对应的字典
26. dic = {}
27. for i in range(0, type_size):
28. dic[count_each_size[i]] = after_quchong[i]
29. #本例希望画出经过排序后的图形,由于 sort 排序会直接改变列表原来的元素, 因此本例先新建一个与 count_each_size 相同的 order 列表,再进行排序
30. scale = []
31. for i in range(0, type_size):
32. scale.append(dic.get(count_each_size[i]))
33. #画图
34. plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
35. plt.barh(scale, count_each_size)
36. plt.xlabel('数量') # x 轴名称
37. plt.ylabel('规模') # y 轴名称
38. plt.title('公司规模') # 图形名称
39. for y, x in enumerate(count_each_size):
40. plt.text(x + 0.1, y, "%s" % round(x, 1), va='center') # 为每个柱子加上对应的数值,其中 round(x,1)是将 x 值四舍五入到一个小数位
41. plt.show() # 展示图形
42. cursor.close() # 关闭操作游标 可视化结果:
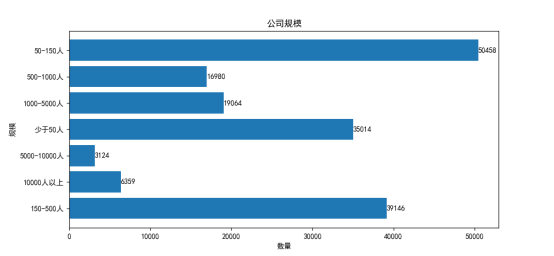
信管专业的就业需求主要集中在公司规模在500人以下的中小企业,这与现在市场上的公司分布离不开,因为现在市场上的互联网巨头就那么几家,而这一类企业对于信管学生的需求很少,也就意味着信管专业学生要想进入互联网大厂的竞争是很激烈的,能力要求相当高,所以信管学生就业需要考虑自身能力水平考虑去中小企业还是大型企业。
3.4热力图
代码展示:
1. #所有岗位在各个城市的数量分布热力图
2. def gangweishuliang_heatmap(): #主函数调用的 gangweishuliang_heatmap ()函数
3. cursor = db.cursor()
4. cursor.execute("SELECT `工作地点` FROM `after_clean` ")
5. all = cursor.fetchall()
6. cities = [] #创建一个空列表,用来装各个城市名称
7. for each in all:
8. if len(each[0]) == 2:
9. cities.append(each[0])
10. names = list(set(cities)) # 将城市名称去重复值,便于计算
11. # 获取各个城市的岗位数量值,装在 final 列表中
12. final = []
13. for i in range(0, len(names)):
14. final.append(0)
15. for each in all:
16. for each_name in range(0, len(names)):
17. if each[0] == names[each_name]:
18. final[each_name] += 1
19. break
20. aa = [list(z) for z in zip(names, final)]
21. geo = (Geo().add_schema(maptype="china")
22. .add("岗位-城市数量分布热力图", # 图题
23. aa,type_=ChartType.HEATMAP, # 地图类型
24. ).set_series_opts(label_opts=opts.LabelOpts(is_show=False)) # 设置是否显示标签
25. .set_global_opts(visualmap_opts=opts.VisualMapOpts(max_=260), # 设置 legend 显示的最大值
26. )
27. )
28. geo.render("cities_heatmap.html") # 以 html 类型保存,名称为 cities_heatmap
29. cursor.close() 可视化结果:
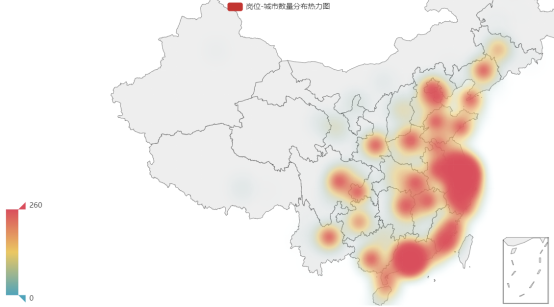
从图中可以看出,信管专业的市场需求主要分布在东南沿海以及除西北地区外的各个省会城市。
首先,以上海为中心的长三角地区以及广州、深圳等沿海城市的岗位数量明显多于其他各城市,这说明信管专业的岗位需求与经济发展水平有着明显的正向关系,同学们想要获得更好的职业发展机会应该优先考虑–线沿海城市。
其次,北京、武汉、长沙等内陆省会城市的岗位数量虽不及一线沿海城市,但对信管专业的同学也有一定的需求,若来自这些地方的同学想回家乡工作,各自的省会城市也能提供不错的发展机会。
最后,从图中可以看到西北城市提供的信管专业岗位数量很少,几乎没有,这说明信管专业的就业还是有一定的地区聚集效应,来自这些地方的同学若想要继续从事信管相关工作,还是需要考虑中东部发达城市。
3.5箱线图
代码展示:
1. def salary_xueli_boxplot(): #主函数调用的 salary_xueli_boxplot()函数
2. cursor = db.cursor()
3. cursor.execute("SELECT `薪资`,`工作要求` FROM `after_clean`")
4.
5. all = cursor.fetchall()
6. #创建两个空列表,用来存储筛选后的学历和薪资
7. xueli = []
8. salary = []
9. for each in all:
10. if each[1] != '' and each[1].split(',')[1] != '' and float(each[0].split('千/月')[0])可视化结果:
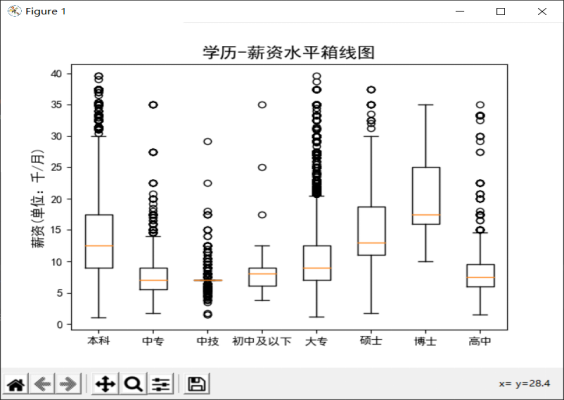
从图中可以看出,市场对于不同学历的求职者给与的薪资水平是存在差异的。
首先,随着学历水平的提高,薪资水平也有着相应的提高,从中位数来看,博士生的薪资是要明显高于其他学历求职者的。
其次,对于学历要求为本科和硕士的岗位,其薪资水平十分接近,这说明可能对于我们来说,本科学历已经足以胜任大部分工作。
再者,可以发现学历要求为大专的岗位异常值最多,这说明该学历的薪资分歧严重,这可能是以为某些小企业对于数据分析人才的急缺,导致它们在降低学历要求的同时给出了更高的薪资待遇。
最后,由于学历要求为高中、中技、中专的岗位数较少,因此其各数据几乎重叠且数值较低,不具代表性。
总的来说,除去一些极端情况,学历和薪资还是存在一定正相关关系的,同学们可以根据自己的期望薪资水平来考虑是否要继续深造。
3.6Sankey 图
代码展示:
1. def post_salary(): #主函数调用的 post_salary()函数
2. cursor = db.cursor()
3. # 从数据库表中选择这 7 种职务的薪资和名称
4. cursor.execute("SELECT `当前爬取岗位`,`薪资` FROM `after_clean` ")
5. results = cursor.fetchall()
6. # 根据实验课程大纲中的表格分类信息,将 30 种岗位分为九小类
7. post = ['技术管理类', '技术开发类', '业务咨询类', '技术支持类', 'IT 运维类', '数据管理类', '数据运营类', '市场职能类', '产品运营类']
8. T1 = ['产品经理', '产品助理', '交互设计']
9. T2 = ['前端开发', '软件设计', 'IOS 开发', '业务分析', '安卓开发', 'PHP 开发']
10. C1 = ['业务咨询', '需求分析', '流程设计']
11. C2 = ['售后经理', '售前经理', '技术支持', 'ERP 实施', '实施工程师']
12. C3 = ['IT 项目经理', 'IT 项目助理']
13. D1 = ['信息咨询', '数据挖掘']
14. D2 = ['数据运营', '数据分析']
15. P1 = ['网络营销', '物流与供应链', '渠道管理']
16. P2 = ['电商运营', '客户关系管理', '新媒体运营', '产品运营']
17. clasify = [T1, T2, C1, C2, C3, D1, D2, P1, P2]
18. post1 = []
19. for each_post in post:
20. for i in range(7):
21. post1.append(each_post)
22. #将九小类岗位重复 7 次,放进 post1列表中,用于后续计算数值和画图
23. # 薪资水平划分
24. salary = ['5 千/ 月以下', '5-10 千/ 月', '10-15 千/ 月', '15-20 千/ 月', '20-25 千/ 月','25 - 30 千 / 月','30 千 / 月以上']
25. # 为了能对应九小类职务,将每种水平薪资取 7 次
26. salary1 = salary * 9
27. # 构建一个包含 7*9 个元素的列表,初始值为 0,用于存储职务与薪资水平的一对一岗位数量
28. count = []
29. for i in range(7 * 9):
30. count.append(0)
31. # 计算 count 列表种每个元素的值,即职务与薪资水平的一对一岗位数量
32. for each_result in results:
33. for i in range(9):
34. if each_result[0] in clasify[i] and each_result[1] != '':
35. if float(each_result[1].split('千/月')[0]) 可视化结果:

可以清晰地看出信管专业的总体薪资水平主要集中在5-10k/月、10-15k/月和15-20k/月这三个区间,每月30k以上的岗位数量非常少。
市场需求较大的产品运营类、技术支持类、技术开发类和技术管理类岗位的薪资主要集中在5-10k/月和10-15k/月两个区间水平,并且这几类岗位中还有不少岗位的薪资能达到每月15-20k/月的薪资水平,总体薪资还是很不错的。这些薪资水平会根据具体的能力有一定的波动,但总体不会相差很大,信管学生可以根据自己的期望和能力选择合适的岗位就业。
3.7词云图
代码展示:
1. def wordcloud_welfare(): #主函数调用的 wordcloud_welfare()函数
2. cursor = db.cursor()
3. cursor.execute("SELECT `工作待遇` FROM `after_clean`")
4. results = cursor.fetchall()
5. txt = ''
6. for each_result in results:
7. txt = txt + each_result[0]
8. # 统计词频的字典
9. word_freq = dict()
10. # 装载停用词,此处需将资料中给出的hit_stopwords.txt 文件放到本代码所在路径下
11. with open("stopwords.txt", "r", encoding='utf-8') as f1:
12. # 读取我们的待处理本文
13. txt1 = f1.readlines()
14. stoplist = []
15. for line in txt1:
16. stoplist.append(line.strip('n'))
17. # 切分、停用词过滤、统计词频
18. for w in list(jieba.cut(txt)):
19. if len(w) > 1 and w not in stoplist:
20. if w not in word_freq:
21. word_freq[w] = 1
22. else:
23. word_freq[w] = word_freq[w] + 1
24. # 指定背景模式图片
25. back_color = imread("地大.png")
26. # 构造 WordCloud 对象
27. wc = WordCloud(background_color='white', max_words=100, collocations=False, width=1000, height=1000,
28. font_path='simhei.ttf', mask=back_color)
29. # 调用方法生成词云图
30. wc = wc.generate_from_frequencies(word_freq)
31. # 保存图片
32. wc.to_file('WordCloud.png')
33. plt.imshow(wc)
34. plt.axis("off")
35. plt.show() 可视化结果:

从图中可以非常清晰直观地看出岗位提供的各种福利待遇和–些基本的待遇类型。
首先,字体最大的是年终奖金和绩效奖金、专业培训,说明这些待遇是公司提供的基本福利待遇,一般公司都会提供。因此同学们在今后找工作时可以先考虑对方公司是否会提供这些基本福利待遇。
其次,还包括通讯、交通、医疗保险、旅游、餐饮、体检、周末和全勒奖等的字体也较大,大多数的公司也会给予员工这些福利待遇,可以较基本待遇更吸引求职者。还有一些待遇较好的公司还会提供住宿、包吃、山国机会、班车、带薪休假.等等福利,但这种待遇在图中的字体较小,说明这并不是普遍存在于各个公司,要视公司而定。这些福利待遇将更多地吸引要求较高福利待遇的求职者并起到积极的激励作用。
总体而言,公司一般都会提供绩效奖、年终奖和专业培训这些基本福利待遇,较好的公司还会提供更多更吸引人的福利,我们可以根据自己的实际情况,在求职时对公司有更多的了解和要求。
