

背景
目前随着公司业务的不断扩展,各个业务线的数据也越来越多,如果所有数据都集中管理比较错综复杂。MaxCompute的跨项目访问资源比较适合这样的场景。每个业务线创建对应的project,自行管理数据。如果有需要访问其他业务线数据的诉求,可以基于Package实现数据共享的诉求,下面我们来介绍下基于Package实现跨项目访问资源的具体操作,本文以共享自建udf函数为例。
前期准备
- MaxCompute项目projectA 和 projectB,详情参考 新建MaxCompute项目;
- 子账号 A(projectA开发环境任务发布人),详情参考 子账号创建;
- 子账号 B(projectA生产环境任务执行人,可为主账号或权限较高的子账号) ;
- 子账号 C(projectB跨项目访问人);
- projectA准备udf所有的jar包、表和函数,详情参考 MaxCompute udf。
步骤
账号权限明细
- 子账号 A(projectA开发环境任务发布人):普通开发人员
- 子账号 B(projectA生产环境任务执行人):除主账号外权限最高的管理者
- 子账号 C(projectB跨项目访问人):普通开发人员,详情参考权限管理
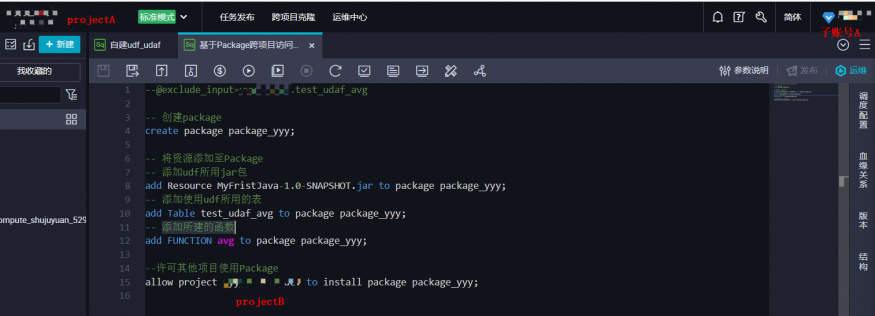
步骤一:子账号A 创建package任务并发布生产
- 登录DataWorks 数据开发,创建SQL节点,创建package任务,详情可参考 ODPS SQL节点。
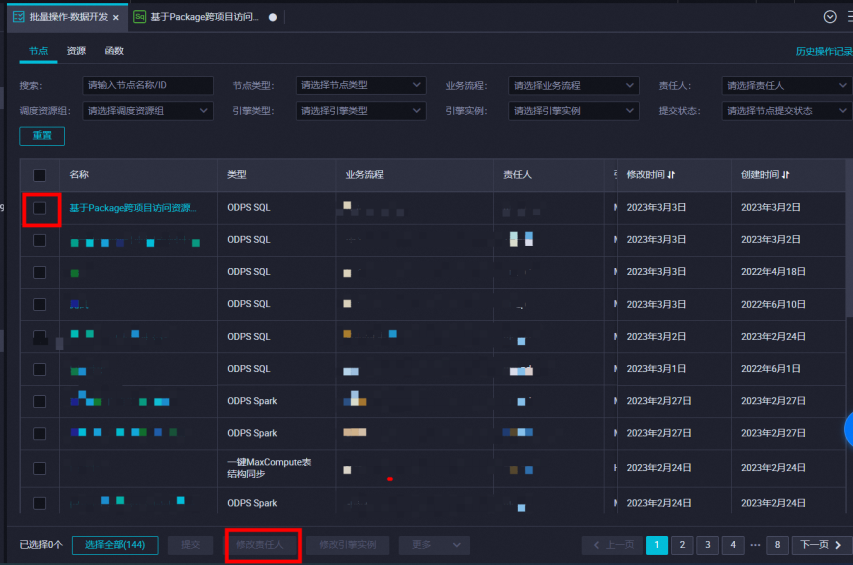
- 修改项目责任人(如果有专人执行生产任务可执行此步骤)
- 在数据开发页面,单击业务流程后的图标,进入任务列表页面。
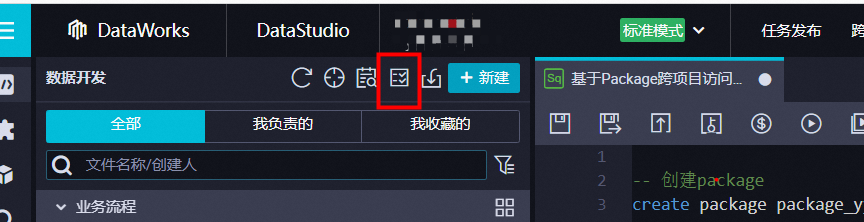
- 修改责任人
-
提交发布任务
-
提交
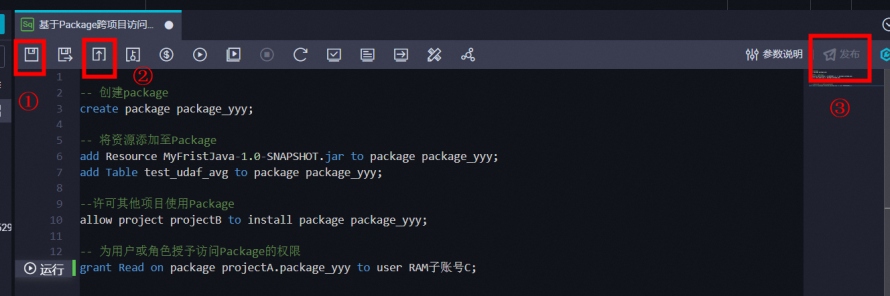
- 发布
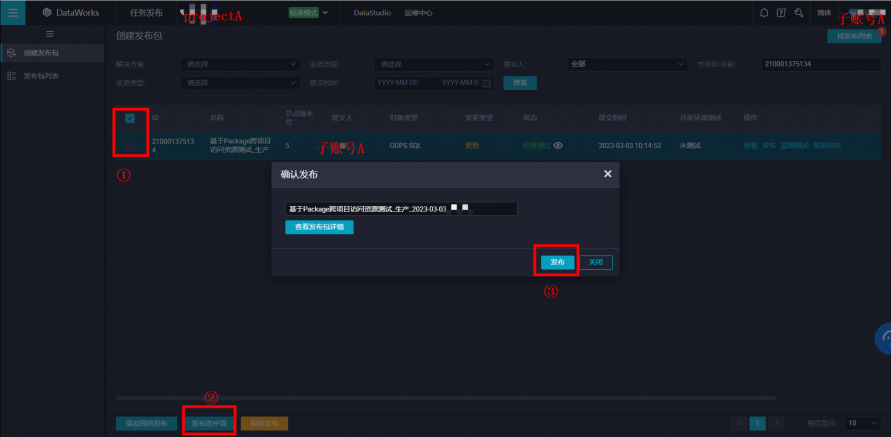
- 可在发布列表中查看

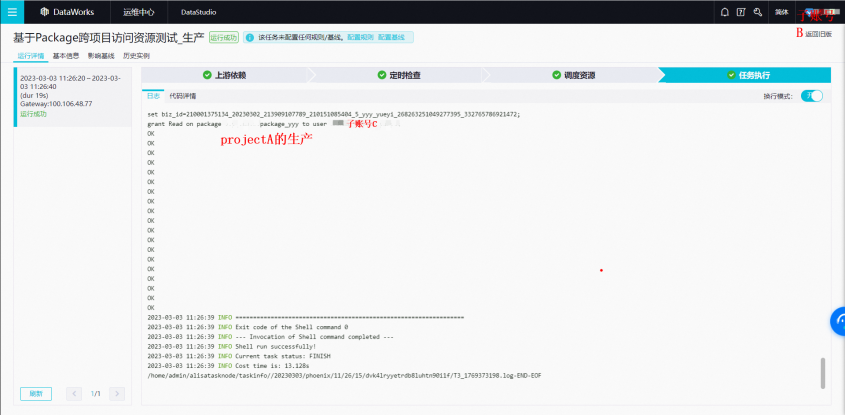
步骤二:子账号B 执行生产任务
1.子账号B登录DataWorks运维中心,周期任务运维 – 周期任务,详情可参考 DataWorks运维中心。
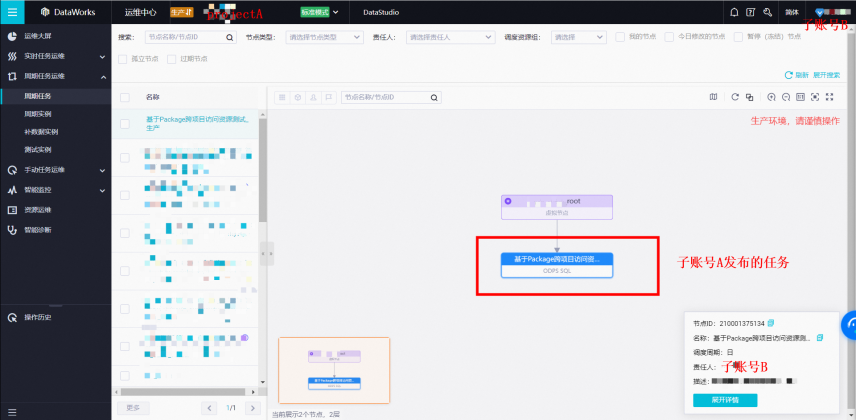
2.子账号B执行任务
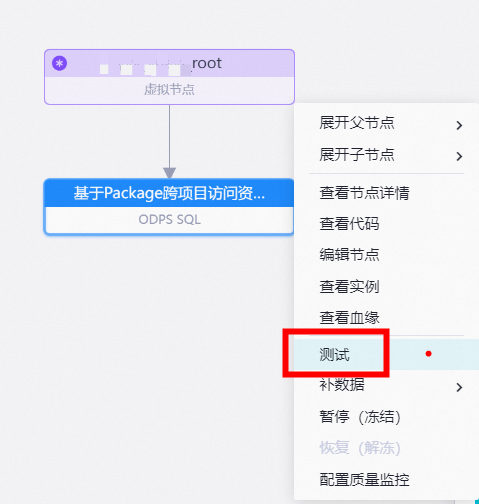
- 右键任务 – 测试,详情可参考周期任务运维
- 选择业务日期
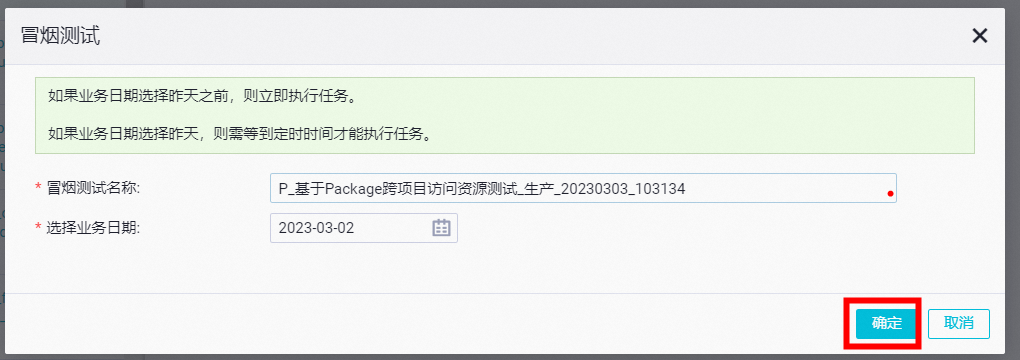
- 查看运行结果
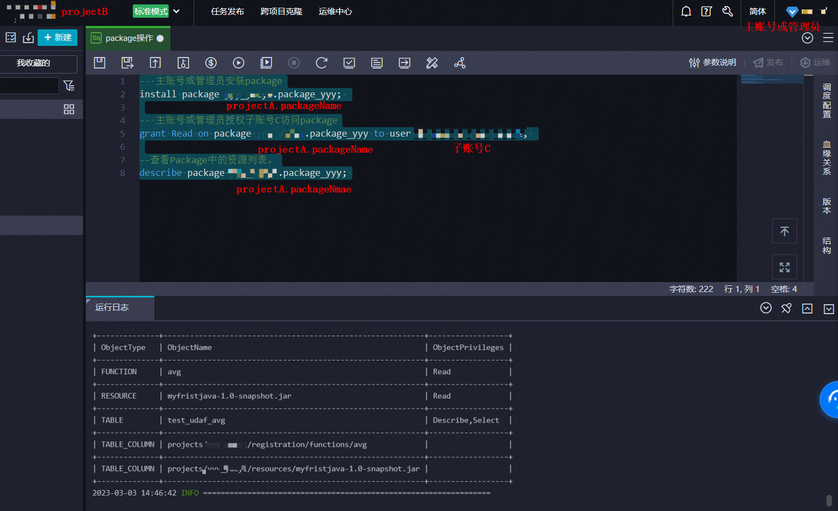
步骤三:子账号C 使用package
1.主账号或管理员(Super_Administrator 或者 Admin)登录 projectB,安装package 并允许子账号C 访问 package,详情可参考 基于package跨项目访问资源。
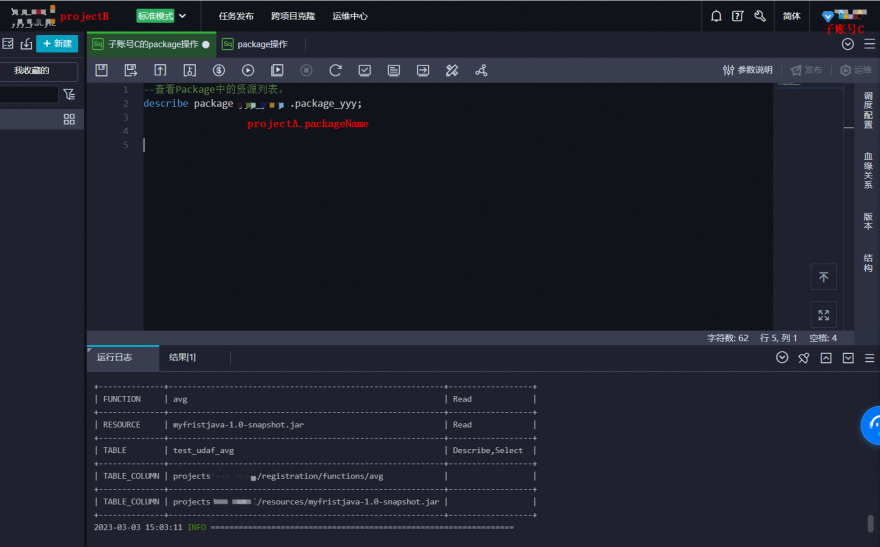
2.子账号C 登录 projectB,进行package访问
- 查看package的资源列表
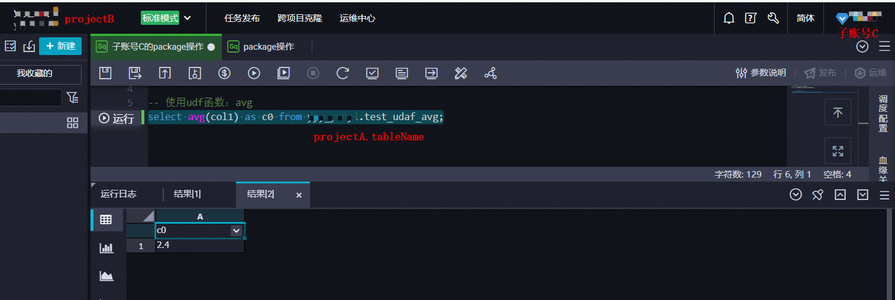
- 使用udf函数
【 MaxCompute发布免费试用计划,为数仓建设提速 】新用户可0元领取5000CU*小时计算资源与100GB存储,有效期3个月。 立即领取>>
