

0 前文回顾
在《MySQL自治平台建设的内核原理及实践(上)》一文中,我们主要介绍了数据库的异常发现与诊断方面的内容,在诊断方面经常会碰到一些难以找出根因的Case。针对这些疑难杂症Case,通过本篇可以了解到,如何通过内核可观测性以及全量SQL来解决这些问题。除此之外,在得出根因后,如何处理异常,如何对SQL进行优化,以及如何进行SQL治理等相关方面问题,也将在本篇中给予解答。
1 内核可观测性建设
1.1 内核可观测性建设
1.1.1 性能诊断挑战
在自治性能诊断平台的建设过程中,我们发现如下两大挑战:
- 很多SQL性能抖动的问题找不出根因,比如SQL的执行时长莫名其妙的突然变大,其执行计划良好、扫描跟返回的行数都很少,也没有行锁、MDL锁相关锁阻塞;查看慢查询日志,也没有哪个字段的耗时比较高,但是SQL的执行时长就是突然变长,有时候达到几十秒长,而平时往往是几毫秒,各种分析后找不出原因。
- 有时候在诊断一些指标异常的根因时,凭借的是不太严格的经验,而不是量化分析,比如thread_running或者slow_queries值突然升高的时候,可能会通过表information_schema.processlist查看当前的活跃会话中线程的状态,看一下状态是不是有行锁或者MDL锁之类的阻塞,或者通过慢查询日志里的相关数据来诊断根因。这里的挑战是:我们看到的是整个SQL某个时间点的瞬时状态,或者只是整个SQL执行过程中的部分数据,而不是整体的数据,所以得出的根因诊断可能是片面的,也许一瞬间看到的是行锁,但是大部分时间被MDL锁阻塞。
1.1.2 解决思路
如果使用的是社区版本的MySQL,基本上都会面临上面两大问题。我们先从内核的角度分析一下这两个挑战,对于第一个挑战,主要是对MySQL在内核层面执行细节不够了解,比如一条SQL执行了10s,而从内核层面来看的话,这十秒的时间可能会有几百个步骤组成,检查后可能发现row或者MDL锁等待时间加起来只有1秒,那么其他的9秒的耗时在哪里呢?可能发生在这几百个步骤中的任何一个或者多个,所以如果没有这几百个步骤的明细数据,就无法诊断出突然出现的性能问题的根因。
第二个问题跟第一个问题从本质上来说是一样的。由于采集的数据是某个时间点的快照数据(通过活跃会话),或者只是部分指标的数据(通过慢查询日志),所以我们看到的只是片面的信息,而没有办法获取到整个SQL的完整的耗时分布信息。
1.1.3 Wait耗时量化分析法
在分析完原因之后,我们参考了TSA的思想,同时结合MySQL自身的特点来做基于Wait的内核可观测性的建设。从TSA可以看出,SQL执行的总耗时无非就是由Off-CPU跟ON-CPU两大部分组成,如果SQL有耗时长的问题,首先要确认是在OnCPU还是在OffCPU上耗时多。如果是前者,那么说明SQL本身有问题,比如消耗资源太多(比如无效索引造成扫描行数过多);如果是后者,那么说明SQL本身没有问题,而是受到干扰或者系统资源不足,进而造成OffCPU层面耗时过多。
无论是何种情况,我们都需要把OnCPU跟OffCPU的耗时做进一步的拆分,从而来查看耗时瓶颈点到底在哪里,并且对耗时比较多的关键代码路径交由内核团队来进行埋点;相对MySQL performance_schema库中统计的Wait信息,实现非常轻量,所以对总体的性能的影响很小,并且耗时指标都是SQL明细粒度的,而不是类似performance_schema中的SQL模版级别的聚合数据。
耗时在OnCPU
在分析一条SQL执行耗时,如果发现像下图一样,耗时分布大部分都在OnCPU,这说明SQL本身有严重的性能问题(全表扫描、过滤效果不佳或者查询优化器的bug等原因),我们可以把诊断的方向集中在如何优化SQL本身就可以了,而不需要去关注其他的方面,如锁阻塞、磁盘或者网络延迟等OffCPU方面的问题。通过使用getrusage方法来获取某条SQL的OnCPU耗时时长,比如在SQL执行前,获取当前线程的ru_utime、ru_stime时间,然后在SQL执行完毕时再次获取ru_utime、ru_stime值,就可以得到SQL执行的CPU Time。

耗时在OffCPU
如果发现OnCPU的耗时占总耗时的比率比较低,通过OffCPU的相关指标发现其占总耗时的比率比较高,说明SQL本身没有问题,可能是被锁住了、硬件资源不足或者是被内核层面某个内核锁给卡住了。我们就需要查看到底是OffCPU相关的哪个,或者哪些指标耗时比较高,需要在内核层面对执行过程中的可能的、耗时比较长的执行代码路径进行埋点,只有获取到了跟性能相关的关键的数据,才能做出准确的判断。

如何选择合适而全面的OffCPU相关的代码路径进行埋点?经过探索,这里提供了如下几个方式:
- 分析setup_instruments表中包含的关键埋点信息,大致知道有哪些关键的指标可以埋点,比如wait/IO、Mutex类等,再结合自身的经验来判断哪些指标可能有性能瓶颈的问题。
- 根据实际疑难case来判断选择哪些Wait指标,比如看到”Thread xxx has waited at trx0trx.cc line 1193 for 241.00 seconds the semaphore: xxxxx mutex REDO_RSEG created trx0rseg.cc:211, lock var 1″,则对mutex REDO_RSEG进行埋点,看到”Thread xxx has waited at dict0dict.cc line 1239 for 245.00 seconds the semaphore: xxxxxx Mutex DICT_SYS created dict0dict.cc:1173, lock var 1″则对 Mutex DICT_SYS进行埋点。
- 源码分析,在内核层面对SQL的执行过程进行逐步的Debug,根据经验分析可能的瓶颈点来埋点;下面举两个例子分别就纯源码的角度来分析,SQL在读、写过程中哪些地方可能会造成性能抖动并做埋点。
例子1,在SQL读操作的执行过程中,需要从buffer pool中请求内存资源,如果一直满足不了内存资源的请求则一直会循环尝试获取,如果在2000ms内还是没有从Buffer pool中请求到需要的内存,会打印日志“Difficult to find free blocks in the buffer pool……”,来表明内存很紧张;这种长时间等待内存资源的获取会生产了性能抖动,这个时候就需要在对应的内核代码处进行埋点获取BP内存资源等待时间。
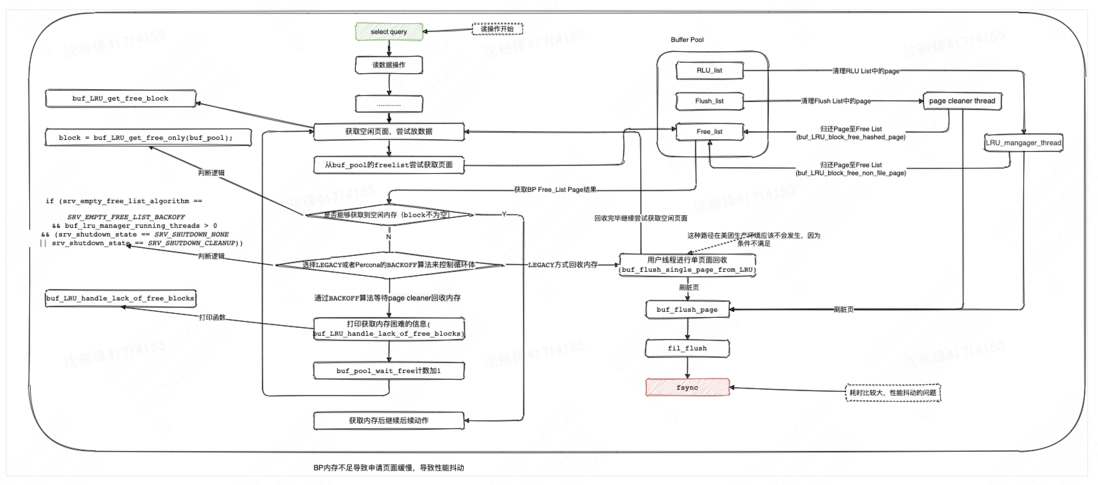
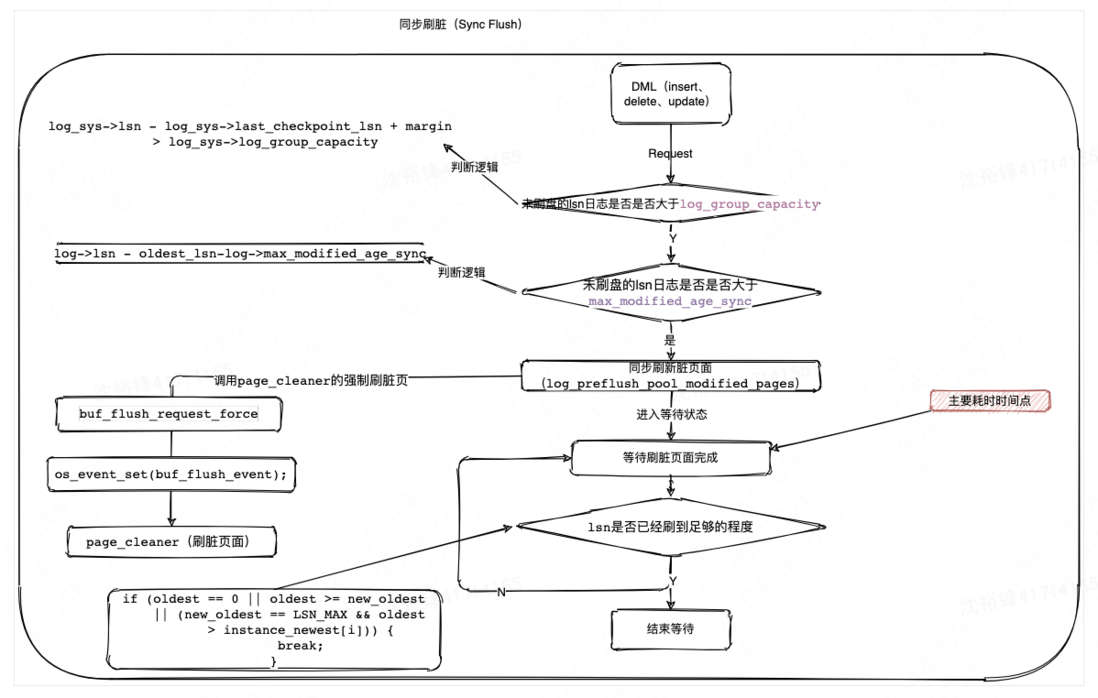
例子2,在SQL写操作的执行过程中是需要写redo log的,如果redo log空间不够,则需要刷盘redo log跟BP中的脏页,而刷脏页可能是个很耗时的操作,并会引起包括活跃会话突增、慢查询等性能抖动问题。这个场景跟上面的类似,也需要对源码进行分析,并且在关键的位置进行埋点来统计刷脏的耗时。
1.1.4 Wait指标层次图
通过上面的三种方式我们不断地迭代累计的关键耗时指标,整理成如下的OffCPU跟OnCPU两大类的分层架构图。截止目前为止,我们内核团队在内核层面埋点了100多个关键指标来辅助诊断,指标分为Statement跟Wait两大层级。
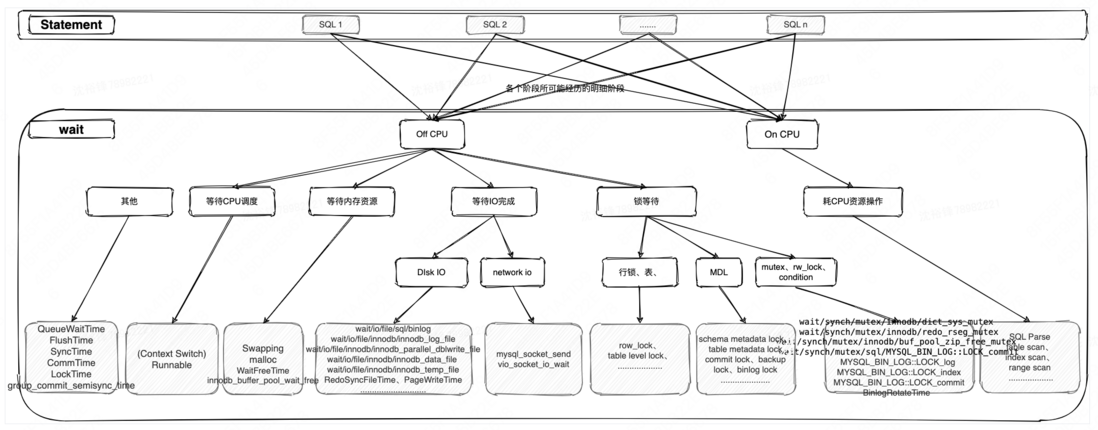
Statement
SQL语句级别的指标,如QUERY_TIME、 Row_time行锁时间、ROWS_EXAMINED、ROWS_SENT、Bytes_sent、NO_INDEX_USED、Full_SCAN等,但是这个层面的数据不足于判断出SQL性能问题的根因,比如QUERY_TIME很长,但是ROWS_EXAMINED、ROWS_SENT都很小,就需要进入下一个Wait级别的指标进行进一步的分析。
Wait
Wait层面主要是MySQL内核层面的指标,比如Latch(Mutex、rw_lock、sx_lock、cond)的指标,这里需要说明的是上面的分层图跟MySQL自带的performance_schema中的wait type分层图看上去很像,那为什么不直接使用而需要自研呢?这里主要从如下几个原因且内核团队都很好的解决了:
- performance_schema相关的统计信息是自实例启动后总体的wait时间的聚合数据,而更需要的是任何时间段、单SQL例子的明细数据,因为诊断的往往是某个时间点或者时间段的异常SQL问题。
- performance_schema中其有不少Bug,除此之外,它只支持OffCPU类型的指标,OnCPU耗时的统计不支持,甚至有些非常重要OffCPU的指标,比如row lock的wait统计信息都不支持。
- 开启performance_schema相关的wait后,对总体的性能影响比较大,而基于内核埋点的实现方式很轻量级,对数据库整体性能影响很小。
2 全量SQL
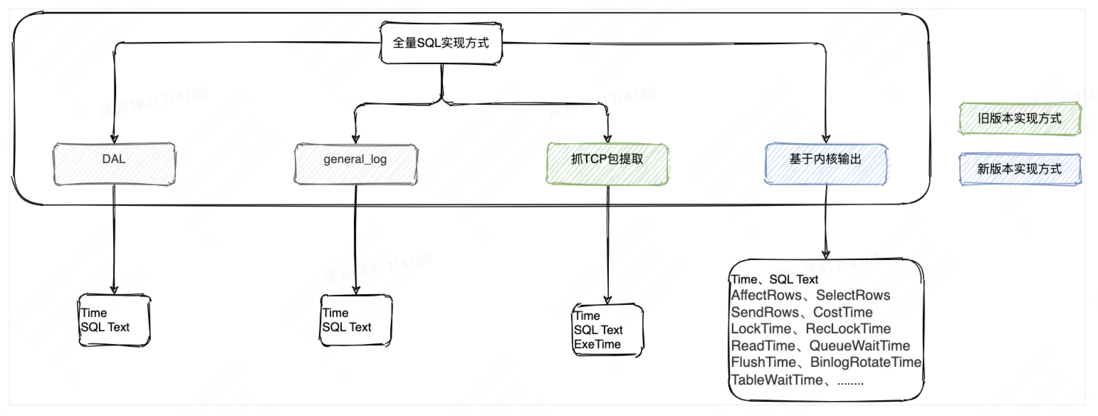
全量SQL,指的是把应用程序或者用户访问DB的所有SQL集合,需要捕获到这些SQL并且发至后端进行分析。在内核可观测性建设之前,原来采用的方式是根据MySQL的协议,来解析TCP报文来提取出SQL。此种实现方式的缺陷也很明显,就是除了SQL文本外,其他的能获取到的关键SQL指标信息非常少,这样做数据库的故障诊断跟SQL性能分析,会因为缺少关键指标而带来挑战。
针对此挑战,我们的解决方案是:改造为直接从MySQL内核吐数据,来作为全量SQL的数据来源(前面的内核可观测性分析介绍可知,单条SQL维度上能从内核层面输出100多个关键指标,包含故障诊断跟SQL性能分析需要的重要指标)。
2.1 实现方式
全量SQL其实有好几个实现方式,初版使用了抓TCP包的方式,现在逐步从TCP抓包过渡到了基于内核输出SQL文本跟关键指标的方案。
2.2 内核实现方式
从内核层面来说,MySQL对于用户的链接将创建独立的thd结构体,所以采集的全量SQL对应的SQL文本跟关键指标数据,可以存于thd结构体中。然后用户线程将thd保存的指标数据,复制到一个自定义内存池中(无锁队列);输出模块有一个线程从内存池中依次获取保存的信息后,写入全量SQL文件。具体流程如下图所示:
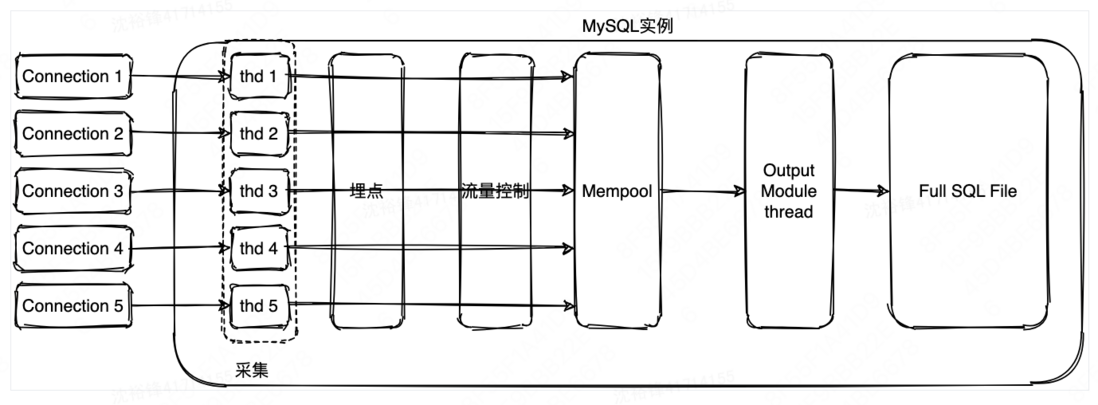
2.3 全量SQL总体架构
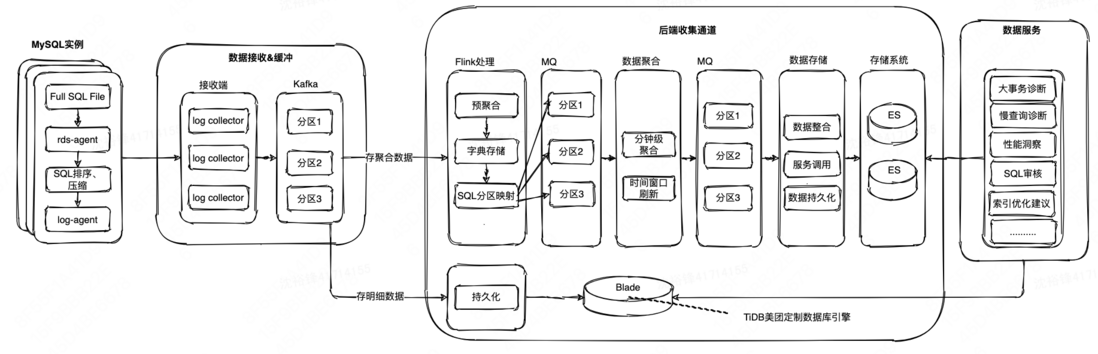
如何把海量信息(日均PB级别)上报到后端系统,来赋能故障诊断、SQL审核、索引优化建议等场景是一个较大的挑战。我们首先通过数据采集器(rds-agent)读取Full SQL File文件内的内容,再往后端传输。
但是由于数据量特别大,为了节省存储资源,分析后选用Snappy压缩算法进行压缩,默认情况下压缩效果只有1~2倍,为此分析了Snappy的源码,发现如果让相似的SQL文本聚合在一起,那么压缩效果会有很大的提高,所以按照SQL文本的前N个字符(N取50,可以根据SQL文本的实际情况做调整)进行了排序后再压缩,发现压缩比提高到了7~8倍。后端的SQL存储分成了两种形式,一种是存明细SQL,另一种是存聚合后的SQL模版信息。
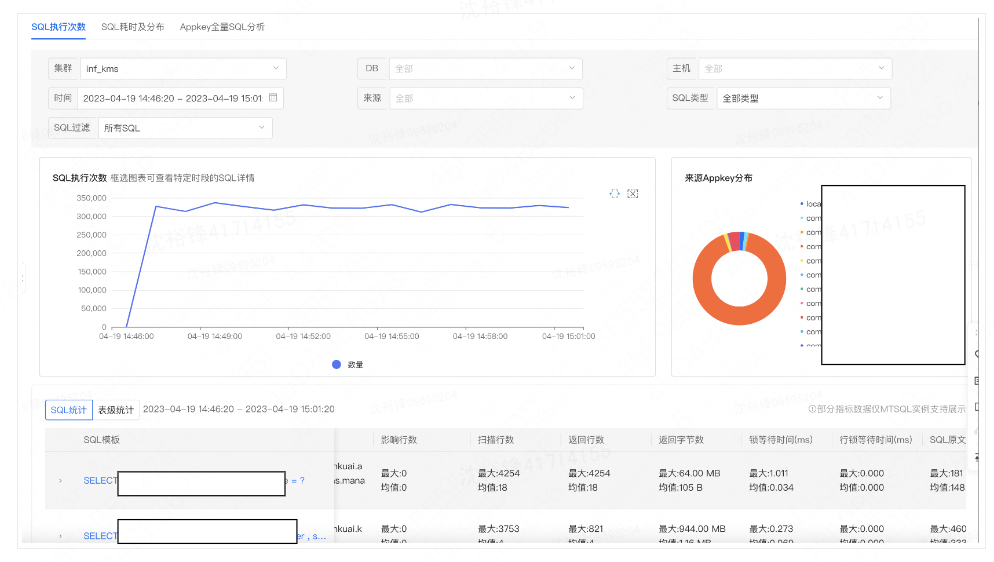
产品展示
采集到的全量SQL既可以模版化展示,点击模版后也可以看到明细的SQL。
3 异常处理
根因分析后,就需要根据具体根因来进行相应的处理,但是如何安全、可靠的进行处理其实是一个很大的挑战。具体的策略是根据其操作是“无损”还是“有损”来采取不同的处理策略。
如果是对业务“无损”的操作,比如磁盘空间清理、参数值调整、缺失索引添加等,目标是让操作尽量的自动化。如果是对业务是“有损”的操作,比如需要Kill或者限流,把相关操作进行包装,发送相关的聊天群让DBA或者用户确认后再进行相关的操作。
对于MySQL Hang的情况,高可用团队会进行周期性探测,如果发现主库MySQL Hang了,则会自动进行主从切换,如果发现从库MySQL Hang了则会进行相应的MySQL实例下线替换动作。
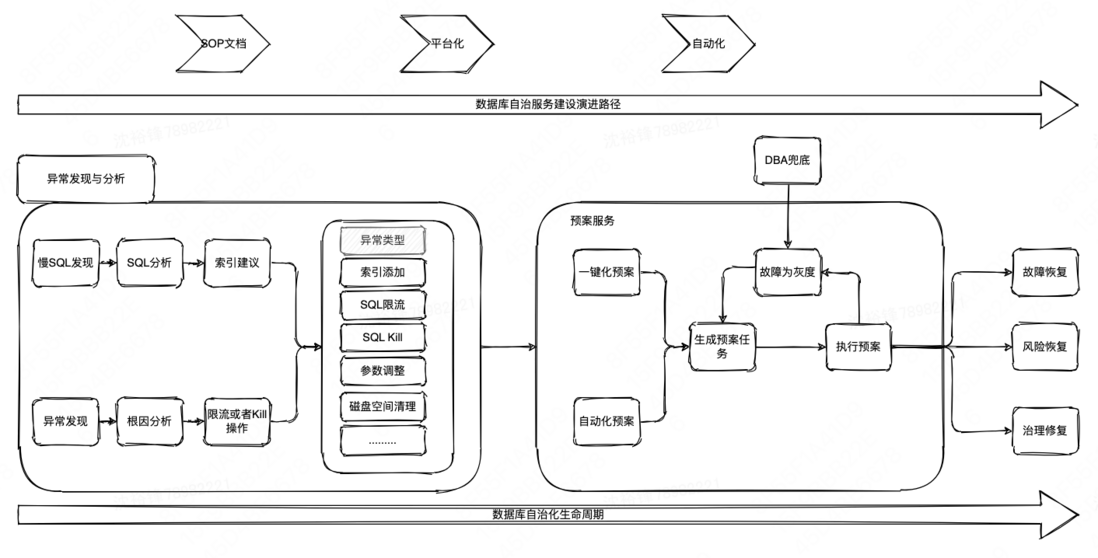
3.1系统架构
整个异常处理的系统架构图如下,由“异常发现与分析”系统以及DBA团队开发的“预案服务”系统组成,前者提供精确的故障根因,后者根据具体的根因来安全、可靠的执行对应的预案,使故障快速恢复。
3.2 产品展示
下图是两个异常发现、分析、给出建议以及处理的例子:1)异常发现、确认根因后,发现缺索引,系统会自动调用索引优化建议系统给出建议,用户可一键添加索引;2)对于慢查询或者主从延迟问题,分析根因后提供用户进行限流、Kill、参数调优等操作的建议,避免异常被进一步放大。

4 索引优化建议与治理
众所周知,很大一部分的数据库的异常都是跟SQL性能有关。很显然,日常的SQL性能问题的治理就很有必要,一个低成本但效果显著的SQL性能优化方案是提供索引优化建议,并且可以将这种索引优化建议的能力应用于SQL生命周期的三个阶段,这三个阶段下文会进一步阐述。
- 应用程序“发布前”的性能问题SQL审核(事前);
- SQL执行过程中的实时性能问题SQL发现(事中);
- SQL“执行完毕”后批量的SQL治理(事后)。
4.1 索引优化建议
建立适合的索引对SQL的性能提升效果很明显,如何添加适合的索引是一个有挑战性的任务。索引的添加不能光凭经验,因为索引是否被用到不但跟表的数据的分布有关,还跟MySQL查询优化器的Cost逻辑有关系,所以“人肉”进行索引建议的评估并不是一个好的方案。
解决方式是尽量要基于MySQL的Cost模型,利用MySQL自身提供的查询优化器的能力,来给出最佳的索引;索引优化建议的建设一般分为三个阶段:1)单SQL维度的优化建议;2)基于workload的整体优化建议;3)索引自维护。这几个阶段的建设需要按顺序来进行,并且不可跳跃。下面我们将分别进行阐述。
4.2 单SQL索引优化建议
4.2.1 实现思路
单SQL索引优化建议,就是指输入一条SQL语句后,优化建议系统给出一个索引优化建议的过程。想要利用查询优化器本身的能力来实现索引建议的目标,就必须先要了解MySQL的查询优化器是如何工作的。
这里举个简单的单表SQL查询的例子,帮助我们来初步了解其工作原理。我们先了解查询优化器是如何从众多的候选执行计划中选择最终的执行计划的;在有了这个基础之后,再来讲是如何利用查询优化器自身的能力来做索引优化建议。
比如有SQL语句“select * from test_db.table1 where c2=3 and c3=4 and c4
具体来说,针对SQL的两类表访问方式:1)基于全表扫描的访问方式;2)非全表扫描的方式(比如Index_scan、ref类型或者range_access等),下图是这些访问方式Cost计算过程中涉及到的查询优化器跟存储引擎的关键函数,目标是假设某个索引存在的情况下,修改这些函数来模拟Cost的计算过程,来发现哪个索引存在的情况下对应的Cost值最小。

流程中的各种数据访问方式,对其Cost计算方式逐个分析。
1)Table scan访问方式
从全表扫描cost计算公式可以知道Table scan的Cost分为IO的Cost跟CPU Cost两个部分之和,大致的公式为:IO-cost:#pages in table IO_BLOCK_READ_COST + CPU cost:#records ROW_EVALUATE_COST,其中IO-cost是通过table_scan_cost来计算的。
这里有两个关键的变量records跟pages in table,分别表示这个表有多少行跟多少page,这两个变量的值是怎么来的呢?如果使用的是innodb,那么前者来自于ha_innobase::info_low(ha_innobase::info),后者来自于ha_innobase::scan_time()(而这两个函数都是SQL层handler.h定义的虚函数,不同的存储引擎分别实现之),知道了这两个变量的值,就知道具体的Cost值了。
2)Index scan访问方式
覆盖索引的扫描,从index_scan_cost得知Index scan的Cost为:O-cost:#(records/keys_per_block) IO_BLOCK_READ_COST+ CPU cost:#records ROW_EVALUATE_COST,由于IO_BLOCK_READ_COST跟ROW_EVALUATE_COST都是常量,所以需要关注是keys_per_block(keys_per_block的计算跟block_size等有关)跟records这两个变量,也就是说如果知道了这两个变量的值,就知道了具体的Cost值了。
3)range access访问方式
从multi_range_read_info_const得知range access的Cost为:IO-cost:#records_in_range IO_BLOCK_READ_COST + CPU cost:2#records_in_range* ROW_EVALUATE_COST,由于IO_BLOCK_READ_COST跟ROW_EVALUATE_COST都是常量,所以只需要知道records_in_range这个变量的值,就能计算其Cost了。
4)ref访问方式
从find_best_ref得知ref访问方式的Cost大致为:IO-cost:#prefix_rowcount IO_BLOCK_READ_COST + CPU cost:#prefix_rowcount cur_fanout ROW_EVALUATE_COST,需要实现cur_fanout这个变量,而这个变量跟info中的 rec_per_key(rec_per_key的意思是,比如对于select from test_db.table1 where c2=3,table1中有多少行数据满足c2=3)有关系,所以实现rec_per_key算法后就可以知道其Cost值了。
4.2.2 What_If索引建议策略
如何把上面的Cost计算方式的理论分析应用到索引优化建议中?假设表table1除了主键外没有任何索引,索引优化建议工具最后怎么能给用户推荐出索引idx_2呢?关于这个问题可以用到一种称之为What_If的策略(在微软的AutoAdmin “what-if” index analysis utility中提出),思路就是假设索引idx_2存在并且能计算出在索引idx_2存在的情况下,此执行计划的Cost值,如果发现其Cost只要比当前存在的其他执行计划的Cost值更小,就推荐这个索引。
但是MySQL计算Cost的时候,要求索引是真实存在的,为了给出索引优化建议在生产环境实际去创建各种索引是不可能的。解决的策略就是在非生产环境的数据库实例上创建一个空表,并且添加所有可能被用到的索引(只是一个元数据的create index操作而不去真正的向表内添加数据),最后让优化器去自己选择最佳的索引来生成执行计划,这就是索引优化建议总体思路。
那么问题来了,在非生产环境下创建的索引只是一个元数据,不包含任何数据,如果就这样让查询优化器去计算Cost肯定是行不通。主要原因是缺乏上面的分析的各个访问方式的关键变量值,所以最关键的如何获取到那些影响cost计算的关键的变量信息。
从上面的“实现思路”分析可知,在计算Table scan、Index scan、range access或者ref的cost的时候,主要是从scan_time()、records_in_range()、info()这些在innodb存储引擎里实现的方法获取相关统计信息,来计算Cost大小。而索引没有真实的数据,所以必须要修改存储引擎里scan_time()、records_in_range()、info()这些跟计算Cost相关的方法的实现代码,让其在索引数据不存在的情况下,也能比较真实地获取到跟计算Cost值相关的统计数据。
比如,上面提到的records、keys_per_block、pages in table、records_in_range、cur_fanout等这些变量,就需要自己去计算;比如records这个变量,发现其是在Innodb中info()的实现,通过n_rows(records)赋值给records,所以只需要在info()中从生产环境的表里获取到真实的行数,赋值给records就可以了,其实就是一个元数据的查询而已。
再看一下ref类型访问方式的Cost计算过程中用到的cur_fanout变量,而这个值是来自info()中innodb_rec_per_key的值,它表示有多少个值满足等值条件,只需要在info()中实现innodb_rec_per_key的计算就可以了。
那么innodb_rec_per_key又怎么计算呢?我们可以对表进行了采样(采样的方案可以参考这篇《Random Sampling for Histogram Construction: How Much is Enough?》论文),采样后的数据对某列统计有多少个不同的值,之后使用采集到的总行数/不同值的个数来获取到innodb_rec_per_key值。
这里还有一个非常重要的问题,上面的方案是需要修改对应存储引擎的scan_time()、records_in_range()、info()这些关键的方法,但是innodb存储引擎的代码太复杂了,修改的难度比较大,一个比较好的方案是去修改federated存储引擎里的scan_time()、records_in_range()、info()这些方法,去获取上面不同访问方式中需要用到的关键变量,因为其实现代码比较简单。
4.2.3 索引建议整体流程图
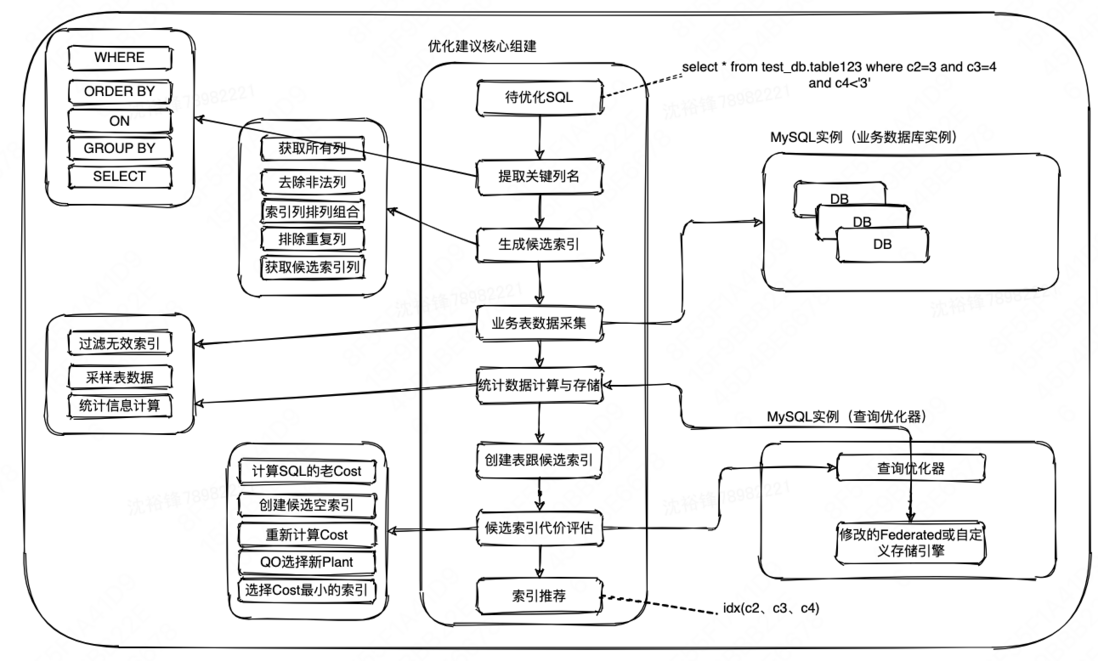
把之前的步骤整理后的索引优化建议的流程图如下:
- 从待优化的SQL的关键位置,比如Where、On、Ordr By等位置提取关键字段信息,利用提取到的字段信息生成候选索引;
- 通过对涉及到的表的数据进行采样来获取查询优化器计算Cost时需要用到的统计信息,之后创建不包含任何数据的索引;
- 修改存储引擎的代码重新实现的scan_time()、records_in_range()、info()这些函数,使得查询优化器能利用数据采样后计算出来的统计信息来比较真实的获取Cost值;
- 选择一个Cost代价最小的执行计划,而此执行计划背后的索引就是优化建议工具推荐的索引,整体思路就是这样。
4.2.4 验证与跟踪
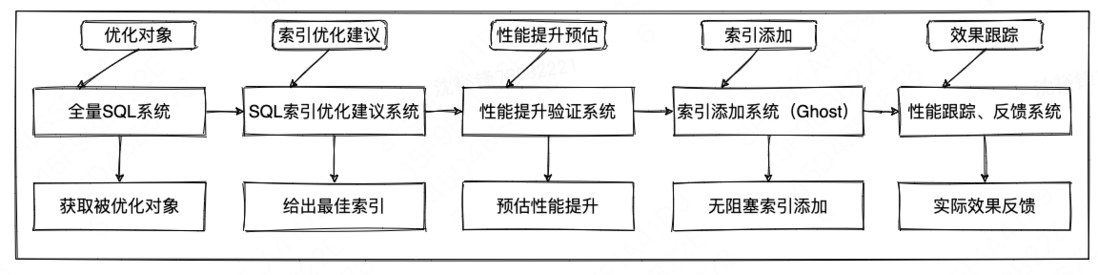
通过全量SQL等系统获取待优化的SQL语句后,输入索引优化建议系统,在给真实的生产环境添加这些索引之前,需要在非生产环境进行验证,看一下添加了相关的索引后性能是否真的有提升。如果有提升,那么把索引在生产环境添加后(比如通过开源的改表工具Ghost等),需要通过跟踪被影响SQL的性能,来查看其执行时间性能是否真的有所提高。如果有性能有回退,需要及时进行告警。
4.2.5 产品展示
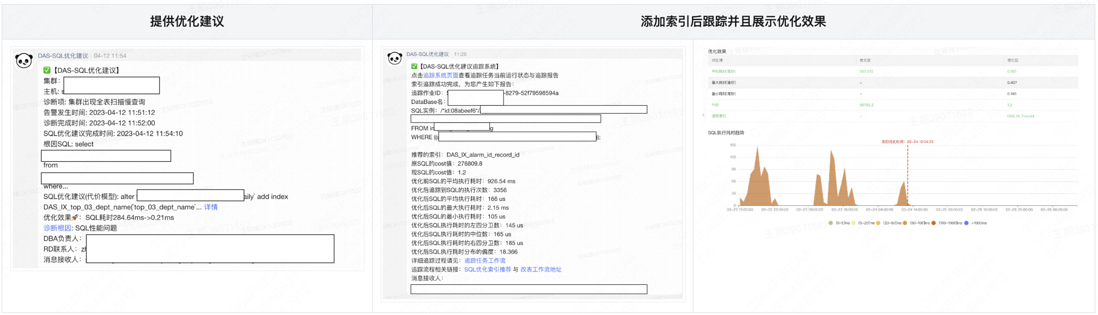
下面的三个图分别展示了提供给用户的索引建议,以及索引添加前后的执行时间效果数据对比图。
4.3 基于Workload的索引优化建议
具备了单SQL的索引优化建议能力后,那么在有限的存储空间的限制下(比如某个实例最多只能添加100G空间的索引),如果想给某个DB或者实例添加索引,添加哪些索引才能使整个数据库的性能提升达到最大化呢?思路主要是参考了微软在基于Workload索引优化建议方面的一序列相关工作。
4.3.1 总体架构
基于Workload的索引优化总体架构如下,总共有6大步骤组成,每个步骤对应着一个核心组件。

1)COLUMN GROUP RESTRICTION组件
如果一个workload(典型业务周期内包含的所有SQL总和称之为workload)包含大量的SQL模版,那么潜在的索引组合的数量是极其庞大的,从中挑选出让系统性能提升最大的索引组合是一个非常困难并且耗时的过程。所以,我们需要一种称为列组合限制(COLUMN GROUP RESTRICTION)的技术,它的目的是消除大量可能组成索引的列组,因为这些列组最多只能对最终推荐的质量产生很小的边际影响(就是说就算推荐了索引,最后对数据库整体的性能的提升很有限,比如某个SQL只执行了一次,那么给之对应的表加索引就没意义了),所以本步骤的输出是workload的一组“有趣”的、对整体性能提升可能有最大提升的列组。
那么,怎么样选出这个“有趣”列组呢?我们需要定义一个叫CG-Cost (g) 的函数,其值为引用列组合g的workload中所有查询SQL的Cost的某个分数值,查询SQL的Cost可以通过优化器估计的成本(MySQL中explain给出的Cost)来获取。如果CG-Cost(g) ≥ f ,列组g需要保留下来(其中的0 ≤ f ≤ 1是预先确定的阈值),否则可以丢失这个列组g。看一个具体的例子:考虑下面的表T (A,B,C,D) 的workload由“Q1,… Q10”等10个SQL组成。如果查询引用该列,则上述矩阵中的单元格包含1,否则包含0。为了简单起见,假设所有查询的成本均为1个单位。
假设指定的阈值f = 0.2,那么工作负载的有趣列组是{A}、{B}、{C}、{A,B}、{A,C}、{B,C} 和 {A,B,C} ,以及各组的 CG-Cost(g)为1.0、0.3、0.9、0.3、0.9、0.2、0.2,而D相关的列因为CG-Cost (g) 值小于0.2而不被考虑,这样就可以在庞大的列组合的情况下排除掉大部分列组合,加快整个索引选择的迭代优化的过程。

2)Candidate index selection组件
单列索引(假设索引)的建立,如果考虑workload的每一个可能的索引集,那么就会有太多的what_if索引需要考虑,这样整体的优化过程会非常缓慢。
一个比较好的思路是为每个Query独立确定最佳的索引集,并将属于这些最佳的索引集中的一个或多个索引视为候选索引集。该算法背后的直觉是,如果对于workload中的单个查询,该索引不是最佳的索引集的一部分,也不可能是整个workload的最佳的索引集的一部分。
这个算法的挑战在于如何为workload中的每个查询Q确定最佳的索引集呢?其实针对单个查询来确定最佳的索引集这个问题与根据整体的基于workload来选择最佳的索引集这个问题,两者没有本质的不同。所以可以设计一个特殊的workload,而这个workload只包含一个查询,之后可以通过上面已经实现的索引优化建议工具本身,来为单个Query获取最佳的索引集。
单查询获取最佳的索引集,如何为单个SQL(SQL模版)获取最佳的索引集呢?一个方法是单个SQL模版进行解析,在SQL关键的位置比如where、on、order by、group by、select等的取出关键的列先创建单个列作为候选索引列,再结合下面的从“Multi-column Index Generation组件”那节创建出来的多列候选索引,让查询优化器自己去选择最好的索引。同时这个步骤依靠优化器选出来的索引,作为下一轮算法(索引合并)的输入。
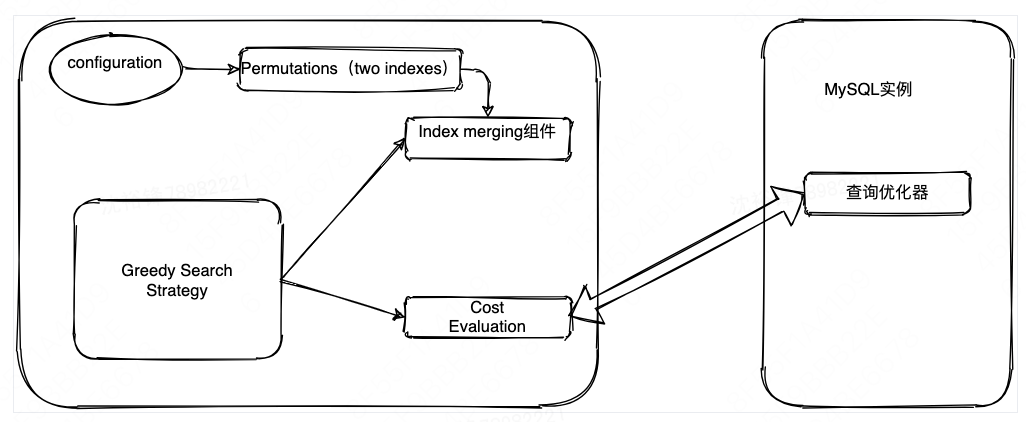
3)Index merging组件
上面的“CANDIDATE SELECTION”组建选出来的索引是专门针对单SQL优化的索引集,但是对于整体workload来说,这个方法会导致较大的存储和索引维护成本。比如,针对单SQL选出的索引都是最佳的,但是这些索引加起来后的存储大小已经超出了允许的范围,需要进行一些索引的合并。
如果两个索引的列存在部分重叠,则可能可以合并,比如包括关系的索引[a,b,c] 跟[a,b] 以及有部分重叠的索引[a,b,c] 跟[c,d}] 的合并,当然[a,b] 跟[c,d}]是不能合并的。索引合并的主要思想就是采用现有的一组索引生成一组具有更低存储和维护开销的新索引,同时索引被合并的情况下,SQL查询的性能能保持不变或者影响比较小,索引合并的架构如下:
4)Configuration Enumeration组件
如果基于workload的索引集有n个候选索引,但是因为存储大小限制,要求workload工具最多只能选择k个索引(一般是受到了存储大小跟Cost大小的限制),那么应该如何选择这个k个索引呢?一般来说,原始的暴力枚举算法将枚举大小为k或更小的候选索引的所有子集,并选择总成本最低的一个索引集,这个枚举算法确实保证了最优解。
然而,这在工程上不切实际的。因为对于n=40和k=10的情况,枚举的索引集的数量实在太庞大,无法进行详尽的枚举,所以需要一个性能更好的算法的“贪心算法”,其思想是假设有n个SQL(一般是实施的时候,是n个SQL模版来替代n个SQL实例),整个workload W表示为 {Q1, .., Qn}。
方案是利用暴力跟贪心算法的组合,运行Greedy(m, k)算法枚举索引集合(m为通过暴力算法选择的m个最佳索引,k为选择的索引的总大小),选择一组索引,直到选出所需数量的索引或总Cost无法进一步降低,该算法选择大小为m(其中m
5)Multi-column Index Generation组件
多列索引的选择有一个比较大的挑战,就是候选索引实在太多,比如对于表中给定的一组k列,最多可能有k!多列索引,考虑所有排列组合将会显著增加Configuration(索引)空间,所以需要减少列组合的搜索空间。采用迭代方法来考虑多列索引的宽度(列的个数)。在第一次迭代中,只考虑单列索引,基于在第一次迭代中选择的单列索引,在往后的迭代中选择一组可接受的双列索引。这组“两列索引”与单列索引一起成为第二次迭代的输入。
那么,具体是如何在单列的基础上选择其他的列组成多列索引呢?这里有多种算法,先使用符号M (a, b) 来表示列a和b上的双列索引,其中a是双列索引的前导列。多列索引选择一般有MC_LEAD、MC_ALL、MC_BASIC三种算法,这几种算法在实现的时候一般会采用MC_LEAD算法 ,因为被证明效果最好。
- MC_LEAD:从CANDIDATE SELECTION被优化器选择的索引,再加上某个“indexable column” 列,这个“indexable column” 列对应的索引不一定在第一轮迭代中被选择;
- MC_ALL:从CANDIDATE SELECTION被优化器选择的索引,再加上某个“indexable column” 列,这个“indexable column” 列对应的索引一定在第一轮迭代中被选择,这种条件比较苛刻,业界相关的测试表明效果明确不如MC_LEAD跟MC_BASIC,虽然多列索引的搜索空间明显减少,提升了总体性能;
- MC_BASIC:则是把单列跟多列索引混在一个迭代周期里建立,而不是先根据单列建议一个索引,然后再通过迭代的方式在单列的基础上逐渐增加索引的宽度。
6)Final Indexes组件
经过几轮迭代,当同时满足Cost跟Storage Size的要求后退出迭代优化过程,输出一组最优的索引优化建议集合。
4.4 SQL治理
具备了SQL索引优化建议的能力后,就可以对有性能问题的SQL进行三个阶段的治理,1)SQL发布生产环境前,起到防患于未然、把问题扼杀在摇篮中的作用;2)SQL生产环境执行过程中,起到实时监控发现正在执行的问题SQL,快速止损,比如误删索引的作用;3)SQL生产环境执行过后,对于执行过的SQL,基于整体的Workload优化策略,通过离线的方式进行批量的风险SQL治理。如下图所示:
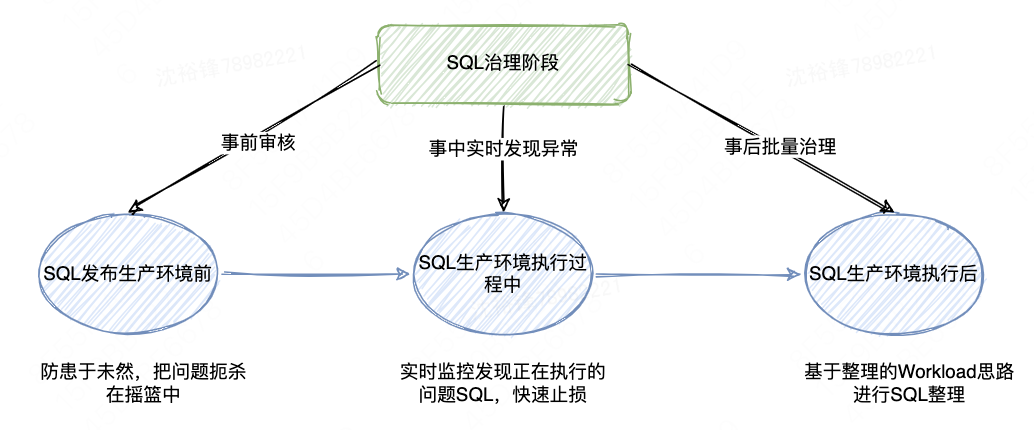
4.4.1 风险SQL审核(事前)
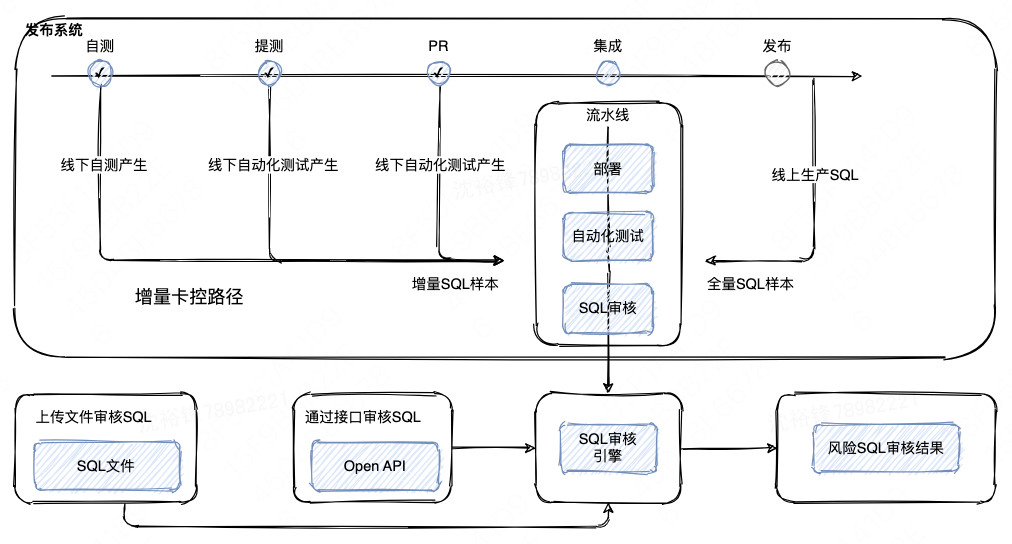
此阶段是程序发布前对潜在的风险SQL进行卡点,在公司的CI/CD平台集成流水线里增设SQL审核卡控点,尽量防止风险SQL被带到生产环境引发故障,起防患于未然的作用。
具体来说,指定了一序列的规则,发现风险SQL后可以暂停发布,并且给出相应的索引优化建议来优化SQL。
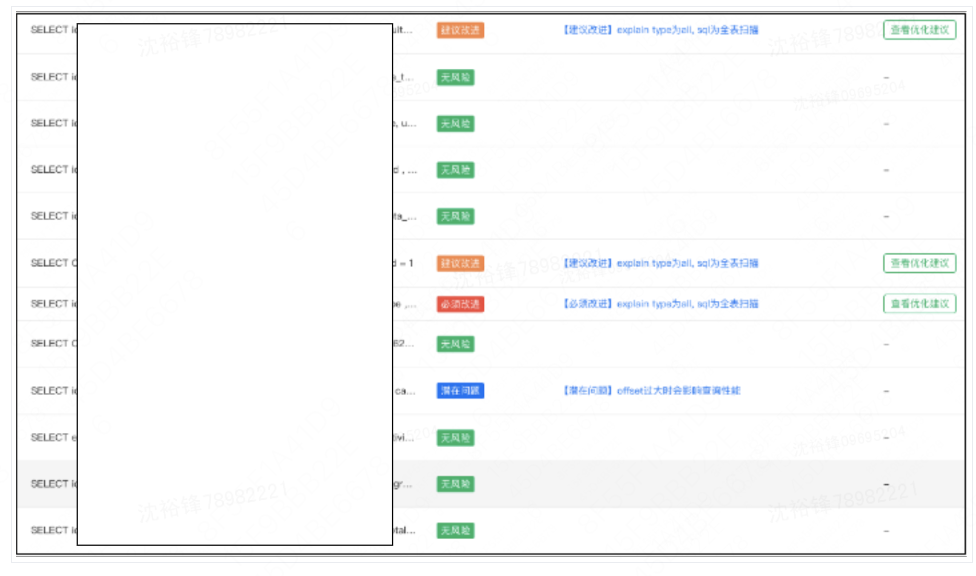
4.4.2 产品展示
根据审核规则,展示审核结果与建议,包括风险提示跟SQL索引优化建议等内容,审核的规则包括是否全表扫描、扫描行数过多等内容。
4.4.3 性能问题SQL实时发现(事中)
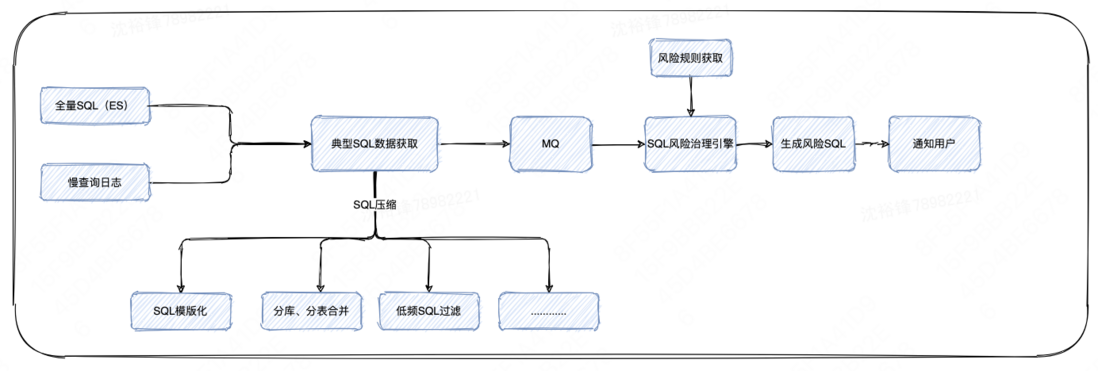
此阶段是风险SQL的实时发现功能,主要针对在SQL运行过程中因为表结构的更改(如索引误删除)、事前审计阶段遗漏掉的性能问题SQL等场景,实时地发现有性能问题的SQL,并且给出优化建议。对于实时的性能问题SQL发现使用了两种发现策略,一种是基于规则的发现策略,另一种通过数据建模的方式来发现策略。
基于规则的风险发现策略,其中的规则包括单位时间内的慢查询数量、SQL执行时间、扫描行数等内容。

基于数据建模的风险发现策略,是通过全量SQL获取SQL的历史执行时长来建模,再通过Process List等数据源,把当前正在执行SQL的执行时间输入模型,从执行时间的角度来判断是否有异常。

4.4.4 批量SQL治理(事后)
此阶段是通过对SQL执行的历史记录进行批量分析,从全局的角度、利用workload索引优化建议的思想提供最佳SQL索引优化建议,批量推送优化建议给用户进行风险SQL的治理。
4.4.5 产品展示
对于批量的SQL优化建议,这里提供了一键审批索引添加的功能,可以更快的让被建议的索引添加到生产环境上。

5 本文作者
裕锋,来自美团基础研发平台-基础技术部,负责美团数据库自治平台的相关工作。
6 参考
- https://github.com/shenyufengdb/sql
- https://github.com/percona/percona-server/blob/release-5.7.41-44
- An Efficient, Cost-Driven Index Selection Tool for Microsoft SQL Server
- plan-stitch-harnessing-the-best-of-many-plans-2
- Random Sampling for Histogram Construction: How Much is Enough?
- AutoAdmin “what-if” index analysis utility
- What is a Self-Driving Database Management System?
- https://www.microsoft.com/en-us/research/publication/self-tuning-database-systems-a-decade-of-progress/
- Automatic Database Management System Tuning Through Large-scale Machine Learning
- Query-based Workload Forecasting for Self-Driving Database Management Systems
- The TSA Method
- https://blog.langchain.dev/langchain-chat/
- https://github.com/hwchase17/langchain
- REAC T: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
- Evaluating the Text-to-SQL Capabilities of Large Language Models
- SQL-PALM: IMPROVED LARGE LANGUAGE MODEL ADAPTATION FOR TEXT-TO-SQL
阅读更多
| 在美团公众号菜单栏对话框回复【2022年货】、【2021年货】、【2020年货】、【2019年货】、【2018年货】、【2017年货】等关键词,可查看美团技术团队历年技术文章合集。

| 本文系美团技术团队出品,著作权归属美团。欢迎出于分享和交流等非商业目的转载或使用本文内容,敬请注明“内容转载自美团技术团队”。本文未经许可,不得进行商业性转载或者使用。任何商用行为,请发送邮件至tech@meituan.com申请授权。
