

前言
Goroutines 是 Go 语言主要的并发原语。它看起来非常像线程,但是相比于线程它的创建和管理成本很低。Go 在运行时将 goroutine 有效地调度到真实的线程上,以避免浪费资源,因此您可以轻松地创建大量的 goroutine(例如每个请求一个 goroutine),并且您可以编写简单的,命令式的阻塞代码。因此,Go 的网络代码往往比其它语言中的等效代码更直接,更容易理解(这点从下文中的示例代码可以看出)。
对我来说,goroutine 是将 Go 这门语言与其它语言区分开来的一个主要特征。这就是为什么大家更喜欢用 Go 来编写需要并发的代码。在下面讨论更多关于 goroutine 之前,我们先了解一些历史,这样你就能理解为什么你想要它们了。
基于 fork 和线程

高性能服务器需要同时处理来自多个客户端的请求。有很多方法可以设计一个服务端架构来处理这个问题。最容易想到的就是让一个主进程在循环中调用 accept,然后调用 fork 来创建一个处理请求的子进程。这篇 Beej’s Guide to Network Programming 指南中提到了这种方式。
在网络编程中,fork 是一个很好的模式,因为你可以专注于网络而不是服务器架构。但是它很难按照这种模式编写出一个高效的服务器,现在应该没有人在实践中使用这种方式了。
fork 同时也存在很多问题,首先第一个是成本: Linux 上的 fork 调用看起来很快,但它会将你所有的内存标记为 copy-on-write。每次写入 copy-on-write 页面都会导致一个小的页面错误,这是一个很难测量的小延迟,进程之间的上下文切换也很昂贵。
另一个问题是规模: 很难在大量子进程中协调共享资源(如 CPU、内存、数据库连接等)的使用。如果流量激增,并且创建了太多进程,那么它们将相互争夺 CPU。但是如果限制创建的进程数量,那么在 CPU 空闲时,大量缓慢的客户端可能会阻塞每个人的正常使用,这时使用超时机制会有所帮助(无论服务器架构如何,超时设置都是很必要的)。
通过使用线程而不是进程,上面这些问题在一定程度上能得到缓解。创建线程比创建进程更“便宜”,因为它共享内存和大多数其它资源。在共享地址空间中,线程之间的通信也相对容易,使用信号量和其它结构来管理共享资源,然而,线程仍然有很大的成本,如果你为每个连接创建一个新线程,你会遇到扩展问题。与进程一样,你此时需要限制正在运行的线程的数量,以避免严重的 CPU 争用,并且需要使慢速请求超时。创建一个新线程仍然需要时间,尽管可以通过使用线程池在请求之间回收线程来缓解这一问题。
无论你是使用进程还是线程,你仍然有一个难以回答的问题: 你应该创建多少个线程?如果您允许无限数量的线程,客户端可能会用完所有的内存和 CPU,而流量会出现小幅激增。如果你限制服务器的最大线程数,那么一堆缓慢的客户端就会阻塞你的服务器。虽然超时是有帮助的,但它仍然很难有效地使用你的硬件资源。
基于事件驱动
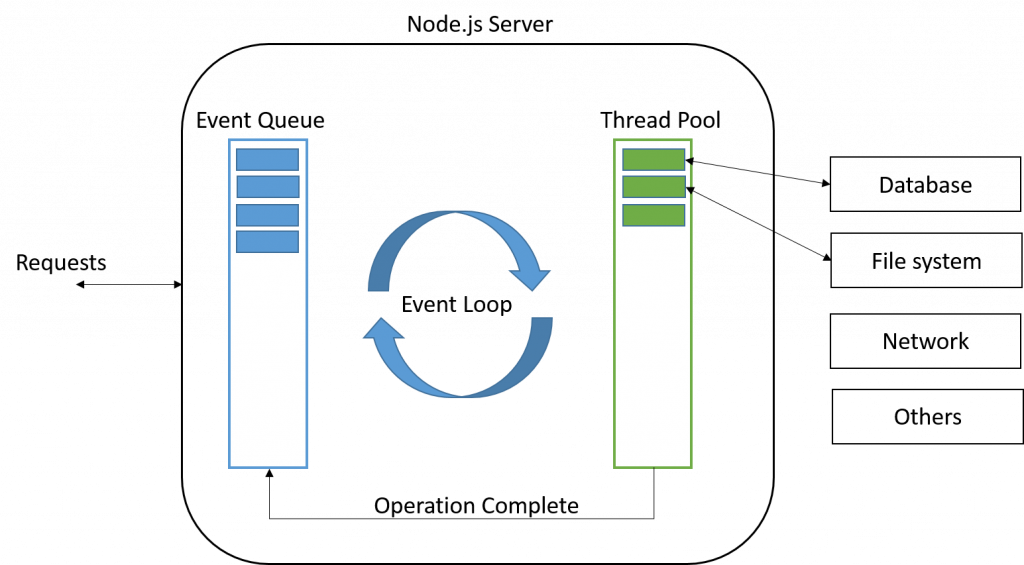
那么既然无法轻易预测出需要多少线程,当如果尝试将请求与线程解耦时会发生什么呢?如果我们只有一个线程专门用于应用程序逻辑(或者可能是一个小的、固定数量的线程),然后在后台使用异步系统调用处理所有的网络流量,会怎么样?这就是一种 事件驱动 的服务端架构。
事件驱动架构模式是围绕 select 系统调用设计的。后来像 poll 这样的机制已经取代了 select,但是 select 是广为人知的,它们在这里都服务于相同的概念和目的。select 接受一个文件描述符列表(通常是套接字),并返回哪些是准备好读写的。如果所有文件描述符都没有准备好,则选择阻塞,直到至少有一个准备好。
#include
#include
int select(int nfds,
fd_set *restrict readfds,
fd_set *restrict writefds,
fd_set *restrict exceptfds,
struct timeval *restrict timeout);
int poll(struct pollfd *fds,
nfds_t nfds,
int timeout);为了实现一个事件驱动的服务器,你需要跟踪一个 socket 和网络上被阻塞的每个请求的一些状态。在服务器上有一个单一的主事件循环,它调用 select 来处理所有被阻塞的套接字。当 select 返回时,服务器知道哪些请求可以进行了,因此对于每个请求,它调用应用程序逻辑中的存储状态。当应用程序需要再次使用网络时,它会将套接字连同新状态一起添加回“阻塞”池中。这里的状态可以是应用程序恢复它正在做的事情所需的任何东西: 一个要回调的 closure,或者一个 Promise。
从技术上讲,这些其实都可以用一个线程实现。这里不能谈论任何特定实现的细节,但是像 JavaScript
这样缺乏线程的语言也很好的遵循了这个模型。Node.js 更是将自己描述为“an event-driven JavaScript runtime, designed to build scalable network applications.”
事件驱动的服务器通常比纯粹基于 fork 或线程的服务器更好地利用 CPU 和内存。你可以为每个核心生成一个应用程序线程来并行处理请求。线程不会相互争夺 CPU,因为线程的数量等于内核的数量。当有请求可以进行时,线程永远不会空闲,非常高效。效率如此之高,以至于现在大家都使用这种方式来编写服务端代码。
从理论上讲,这听起来不错,但是如果你编写这样的应用程序代码,就会发现这是一场噩梦。。。具体是什么样的噩梦,取决于你所使用的语言和框架。在 JavaScript 中,异步函数通常返回一个 Promise,你给它附加回调。在 Java gRPC 中,你要处理的是 StreamObserver。如果你不小心,你最终会得到很多深度嵌套的“箭头代码”函数。如果你很小心,你就把函数和类分开了,混淆了你的控制流。不管怎样,你都是在 callback hell 里。
下面是一个 Java gRPC 官方教程 中的一个示例:
public void routeChat() throws Exception {
info("*** RoutChat");
final CountDownLatch finishLatch = new CountDownLatch(1);
StreamObserver requestObserver =
asyncStub.routeChat(new StreamObserver() {
@Override
public void onNext(RouteNote note) {
info("Got message "{0}" at {1}, {2}", note.getMessage(), note.getLocation()
.getLatitude(), note.getLocation().getLongitude());
}
@Override
public void onError(Throwable t) {
Status status = Status.fromThrowable(t);
logger.log(Level.WARNING, "RouteChat Failed: {0}", status);
finishLatch.countDown();
}
@Override
public void onCompleted() {
info("Finished RouteChat");
finishLatch.countDown();
}
});
try {
RouteNote[] requests =
{newNote("First message", 0, 0), newNote("Second message", 0, 1),
newNote("Third message", 1, 0), newNote("Fourth message", 1, 1)};
for (RouteNote request : requests) {
info("Sending message "{0}" at {1}, {2}", request.getMessage(), request.getLocation()
.getLatitude(), request.getLocation().getLongitude());
requestObserver.onNext(request);
}
} catch (RuntimeException e) {
// Cancel RPC
requestObserver.onError(e);
throw e;
}
// Mark the end of requests
requestObserver.onCompleted();
// Receiving happens asynchronously
finishLatch.await(1, TimeUnit.MINUTES);
}上面代码官方的初学者教程,它不是一个完整的例子,发送代码是同步的,而接收代码是异步的。在 Java 中,你可能会为你的 HTTP 服务器、gRPC、数据库和其它任何东西处理不同的异步类型,你需要在所有这些服务器之间使用适配器,这很快就会变得一团糟。
同时这里如果使用锁也很危险,你需要小心跨网络调用持有锁。锁和回调也很容易犯错误。例如,如果一个同步方法调用一个返回 ListenableFuture 的函数,然后附加一个内联回调,那么这个回调也需要一个同步块,即使它嵌套在父方法内部。
Goroutines
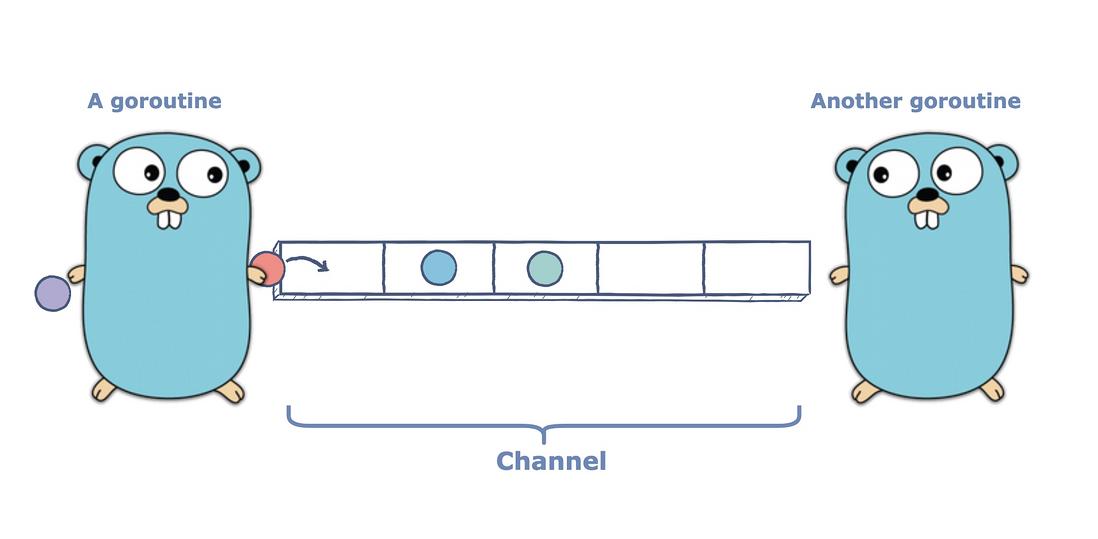
终于到了我们的主角——goroutines。它是 Go 语言版本的线程。像它语言(比如:Java)中的线程一样,每个 gooutine 都有自己的堆栈。goroutine 可以与其它 goroutine 并行执行。与线程不同,goroutine 的创建成本非常低:它不绑定到 OS 线程上,它的堆栈开始非常小(初始只有 2 K),但可以根据需要增长。当你创建一个 goroutine 时,你实际上是在分配一个 closure,并在运行时将其添加到队列中。
在内部实现中,Go 的运行时有一组执行程序的 OS 线程(通常每个内核一个线程)。当一个线程可用并且一个 goroutine 准备运行时,运行时将这个 goroutine 调度到线程上,执行应用程序逻辑。如果一个运行例程阻塞了像 mutex 或 channel 这样的东西时,运行时将它添加到阻塞的运行 goroutine 集合中,然后将下一个就绪的运行例程调度到同一个 OS 线程上。
这也适用于网络:当一个线程程序在未准备好的套接字上发送或接收数据时,它将其 OS 线程交给调度器。这听起来是不是很熟悉?Go 的调度器很像事件驱动服务器中的主循环。除了仅仅依赖于 select 和专注于文件描述符之外,调度器处理语言中可能阻塞的所有内容。
你不再需要避免阻塞调用,因为调度程序可以有效地利用 CPU。可以自由地生成许多 goroutine(可以每个请求一个!),因为创建它们的成本很低,而且不会争夺 CPU,你不需要担心线程池和执行器服务,因为运行时实际上有一个大的线程池。
简而言之,你可以用干净的命令式风格编写简单的阻塞应用程序代码,就像在编写一个基于线程的服务器一样,但你保留了事件驱动服务器的所有效率优势,两全其美。这类代码可以很好地跨框架组合。你不需要 streamobserver 和 ListenableFutures 之间的这类适配器。
下面让我们看一下来自 Go gRPC 官方教程 的相同示例。可以发现这里的控制流比 Java 示例中的更容易理
解,因为发送和接收代码都是同步的。在这两个 goroutines 中,我们都可以在一个 for 循环中调用 stream.Recv 和stream.Send。不再需要回调、子类或执行器这些东西了。
stream, err := client.RouteChat(context.Background())
waitc := make(chan struct{})
go func() {
for {
in, err := stream.Recv()
if err == io.EOF {
// read done.
close(waitc)
return
}
if err != nil {
log.Fatalf("Failed to receive a note : %v", err)
}
log.Printf("Got message %s at point(%d, %d)", in.Message, in.Location.Latitude, in.Location.Longitude)
}
}()
for _, note := range notes {
if err := stream.Send(note); err != nil {
log.Fatalf("Failed to send a note: %v", err)
}
}
stream.CloseSend()
虚拟线程
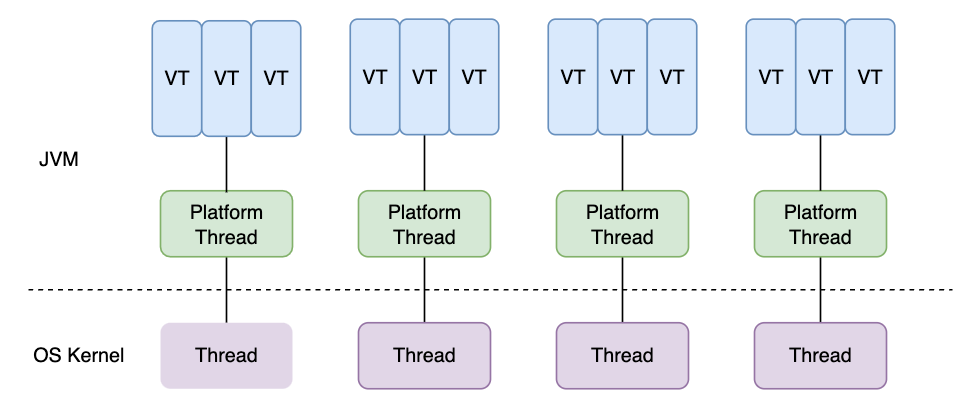
如何你使用 Java 这门语言,到目前为止,你要么必须生成数量不合理的线程,要么必须处理 Java 特有的回调地狱。令人高兴的是,JEP 444 中增加了 virtual threads,这看起来很像 Go 语言中的 goroutine。
创建虚拟线程的成本很低。JVM 将它们调度到平台线程(platform threads,内核中的真实线程)上。平台线程的数量是固定的,一般每个内核一个平台线程。当一个虚拟线程执行阻塞操作时,它会释放它的平台线程,JVM
可能会将另一个虚拟线程调度到它上面。与 gooutine 不同,虚拟线程调度是协作的: 虚拟线程在执行阻塞操作之前不会服从于调度程序。这意味着紧循环可以无限期地保持线程。目前不清楚这是实现限制还是有更深层次的问题。Go 以前也有这个问题,直到 1.14 才实现了完全抢占式调度(可见 GopherCon 2021)。
Java 的虚拟线程现在可以预览,预计在 JDK 21 中成为 stable(官方消息是预计 2023 年 9 月发布)状态。哈哈,很期待到时候能删除大量的 ListenableFutures。每当引入一种新的语言或运行时特性时,都会有一个漫长的迁移过渡期,个人认为 Java 生态系统在这方面还是过于保守了。
