

摘要:本文由葡萄城技术团队于思否原创并首发。转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。
前言
本文主要通过值传递和指针、字符串、数组、切片、集合、面向对象(封装、继承、抽象)和设计哲学7个方面来介绍GO语言的特性。
文章目录:
1.Go的前世今生
1.1Go语言诞生的过程
1.2逐步成型
1.3正式发布
1.4 Go安装指导
2.GO语言特殊的语言特性
2.1值传递和指针
2.2字符串
2.3数组
2.4切片
2.5集合
2.6面向对象
2.6.1封装
2.6.2继承
2.6.3抽象
2.7设计哲学
2.7.1. Go 没有默认的类型转换
2.7.2. Go 没有默认参数,同样也没有方法重载
2.7.3. Go 不支持 Attribute
2.7.4. Go 没有 Exception
Rob Pike 和往常一样启动了一个 C++项目的构建,按照他之前的经验,这个构建应该需要持续 1 个小时左右。这时他就和 Google公司的另外两个同事 Ken Thompson 以及 Robert Griesemer 开始吐槽并且说出了自己想搞一个新语言的想法。当时 Google 内部主要使用 C++构建各种系统,但 C++复杂性巨大并且原生缺少对并发的支持,使得这三位大佬苦恼不已。

第一天的闲聊初有成效,他们迅速构想了一门新语言:能够给程序员带来快乐,能够匹配未来的硬件发展趋势以及满足 Google 内部的大规模网络服务。并且在第二天,他们又碰头开始认真构思这门新语言。第二天会后,Robert Griesemer 发出了如下的一封邮件:
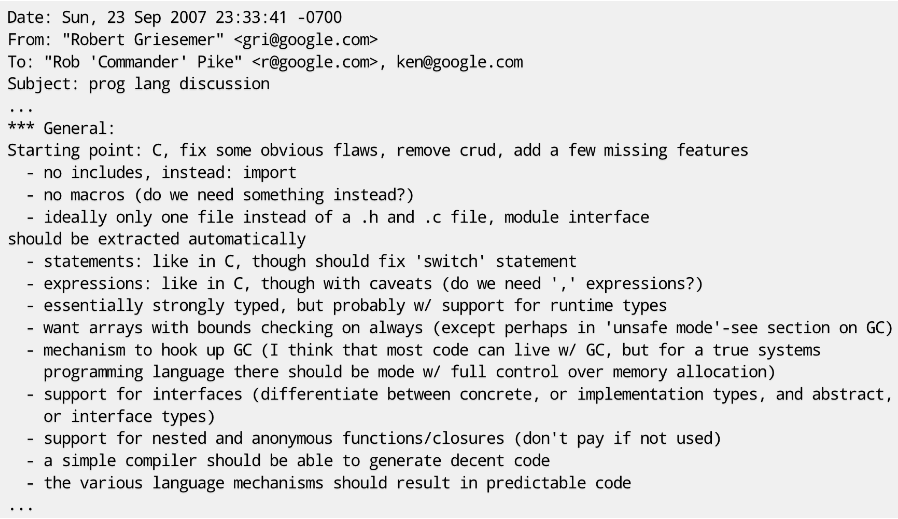
可以从邮件中看到,他们对这个新语言的期望是:在 C 语言的基础上,修改一些错误,删除一些诟病的特性,增加一些缺失的功能。比如修复 Switch 语句,加入 import 语句,增加垃圾回收,支持接口等。而这封邮件,也成了 Go 的第一版设计初稿。
在这之后的几天,Rob Pike 在一次开车回家的路上,为这门新语言想好了名字Go。在他心中,”Go”这个单词短小,容易输入并且可以很轻易地在其后组合其他字母,比如 Go 的工具链:goc 编译器、goa 汇编器、gol 连接器等,并且这个单词也正好符合他们对这门语言的设计初衷:简单。
https://golang.google.cn/
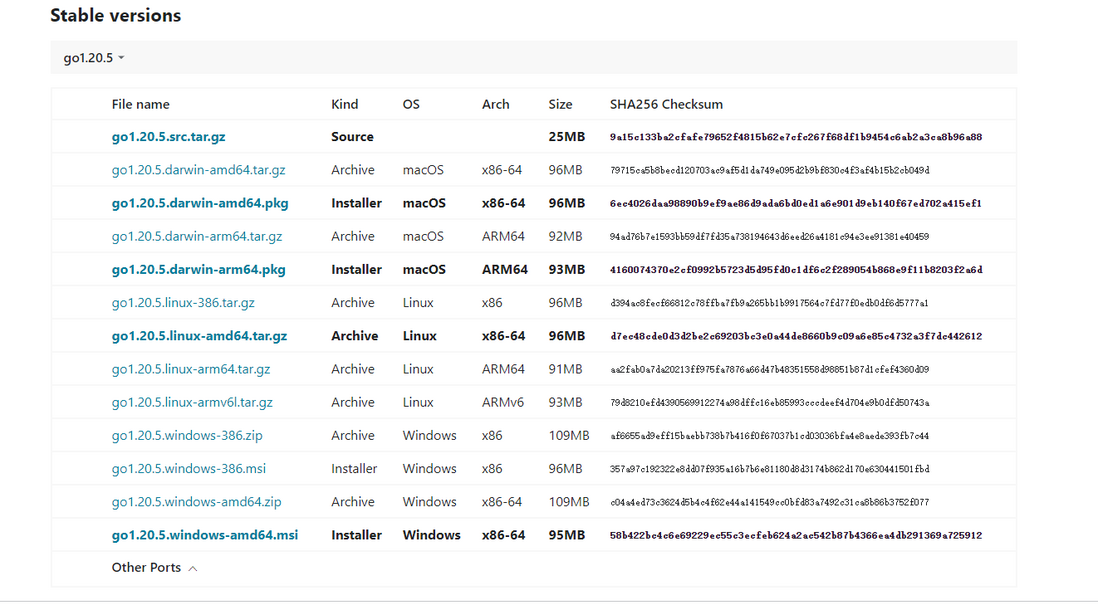
选择对应的安装版本即可(建议选择.msi文件)。
2.查看是否安装成功 + 环境是否配置成功
打开命令行:win + R 打开运行框,输入 cmd 命令,打开命令行窗口。
命令行输入 go version 查看安装版本,显示下方内容即为安装成功。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nhDTdQKK-1689067489257)(media/54576b6c7593e8c73a97975be0910b4b.png)]
2.Go语言特殊的语言特性
2.1值传递和指针
Go中的函数参数和返回值全都是按值传递的。什么意思呢?比如下述的代码:
type People struct {
name string
}
func ensureName(p People) {
p.name = "jeffery"
}
func main() {
p := People{
name: ""
}
ensurePeople(p)
fmt.Println(p.name) // 输出:""
}为啥上面这段代码没有把 p 的内容改成“jeffery”呢?因为 Go 语言的值传递特性,ensureName函数内收到的 p 已经是 main 函数中 p 的一个副本了。这就和 C#中把 p 改为一个 int 类型得到的结果一样。
那怎么解决呢?用指针。
不知道其他人怎么样,当我最开始学习 Go 的时候发现需要学指针的时候瞬间回想起了大学时期被 C 和 C++指针折磨的那段痛苦回忆,所以我本能的对指针就有一种排斥感,虽然 C#中也可以用指针,但是如果不写底层代码,可能写 10 年代码都用不到一次。
不过还好,Go 中对指针的使用进行了简化,没有复杂的指针计算逻辑,仅知道两个操作就可以很轻松的用好指针:
- “*“: 取地址中的内容
- “&”: 取变量的地址
var p *People = &People{
name: "jeffery",
}上述代码中,我创建了一个新的 People 实例,并且通过”&”操作获取了它的地址,把它的地址赋值给了一个*People的指针类型变量 p。此时,p 就是一个指针类型,如果按照 C 或者 C++,我是无法直接操作 People 中的字段 name 的,但是 Go 对指针操作进行了简化,我可以对一个指针类型变量直接操作其内的字段,比如:
func main() {
fmt.Println(p.name) // 输出:jeffery
fmt.Println(*(p).name) // 输出:jeffery
}上述的两个操作是等价的。
有了指针,我们就可以很轻松的模拟出 C#那种按引用传递参数的代码了:
type People struct {
name string
}
func ensureName(p *People) {
p.name = "jeffery"
}
func main() {
p := &People{
name: ""
}
ensurePeople(p)
fmt.Println(p.name) // 输出:jeffery
}2.2字符串
在 C#中字符串其实是 char 类型的数组,是一个特殊的分配在栈空间的引用类型。
而在 Go 语言中,字符串是值类型,并且字符串是一个整体。也就是说我们不能修改字符串的内容,从下面的例子可以很清楚的看出这一概念:
var str = "jeffery";
str[0] = 'J';
Console.WriteLine(str); // 输出:Jeffery上述的语法在 C#中是成立的,因为我们修改的其实是字符串中的一个 char 类型,而 Go 中这样的语法是会被编译器报错的:
str := "jeffery"
str[0] = 'J' // 编译错误:Cannot assign to str[0]但是我们可以用数组 index 读取对应字符串的值:
s := str[0]
fmt.Printf("%T", s) // uint8可以看到这个返回值是uint8,这是为啥呢?其实,在 Go 中,string 类型是由一个名为rune的类型组成的,进入 Go 源码看到rune的定义就是一个 int64 类型。这是因为 Go 中把 string 编译成了一个一个的 UTF8 编码,每一个 rune 其实就是对应 UTF8 编码的值。
此外,string 类型还有一个坑:
str := "李正龙"
fmt.Printf("%d", len(str))len()函数同样也是 go 的内置函数,是用来求集合的长度的。
上面这个例子会返回9,这是因为中文在 Go 中会编译为 UTF-8 编码,一个汉字的编码长度就 3,所以三个汉字就成了 9,但是也不一定,因为一些特殊的汉字可能占 4 个长度,所以不能简单用 len() / 3 来获取文字长度。
因此,汉字求长度的方法应该这样做:
fmt.Println(utf8.RuneCountInString("李正龙"))2.3数组
Go 中的数组也是一个我觉得设计的有点过于底层的概念了。基础的用法和 C#是相同的,但是细节区别还是很大的。
首先,Go 的数组也是一个值类型,除此之外,由于”严格地“遵循了数组是一段连续的内存的结合这个概念,数组的长度是数组的一部分。这个概念也很重要,因为这是直接区别于切片的一个特征。而且,Go 中的数组的长度只能是一个常量。
a := [5]int{1,2,3,4,5}
b := [...]{1,2,3,4,5}
lena := len(a)
lenb := len(b)上述是 Go 中数组的两个比较常规的初始化语法,数组的长度和字符串一样,都是通过len()内置函数获取的。其余的使用和 C#基本相同,比如可以通过索引取值赋值,可以遍历,不可以插入值等。
2.4切片
与数组对应的一个概念,就是 Go 中独有的切片Slice类型。在日常的开发中几乎很少能用得到数组,因为数组没有扩展能力,比如 C#中我们也几乎用不到数组,能用数组的地方基本都用List。Slice 就是 List 的一种 Go 语言实现,它是一个引用类型,主要的目的是为了解决数组无法插入数据的问题。其底层也是一个数组,只不过它对数组进行了一些封装,加入了两个指针分别指向数组的左右边界,就使得 Slice 有了可以增加数据的功能。
s1 := []int{1,2,3,4,5}
s2 := s1[1:3]
s3 := make([]int, 0, 5)上面是 Slice 的三种常用的初始化方式。
- 可以看到切片和数组的唯一区别就是没有了数组定义中的数量
- 可以基于一个去切片去创建另一个切片,其后面的数字的含义就是目前业界通用的左包含右封闭
- 可以通过**make()**函数创建一个切片
make()函数感觉可以伴随 Go 开发者的一生,Go 的三个引用类型都是通过 make 函数进行初始化创建的。对切片来说,第一个参数表示切片类型,比如上栗就是初始化一个 int 类型的切片,第二个参数表示切片的长度,第三个参数表示切片的容量。
想切片中插入数据需要使用到 append()函数,并且语法十分诡异,可以说是离谱到家了:
s := make([]int)
s = append(s, 12345) // 这种追加值还需要返回给原集合的语法真不知道是哪个小天才想到的这里出现了一个新的概念,切片的容量。我们知道数组是没有容量这个概念的(其实是有的,只不过容量就是长度),而切片的容量其实就类似于 C#中List的容量(我知道大部分 C#er 在使用 List 的时候根本不会去关心 Capacity 这个参数),容量表示的是底层数组的长度。
容量可以通过 cap()函数获取
在 C#中,如果 List 的数据写满了底层数组,那会发生扩容操作,需要新开辟一个数组将原来的数据复制到新的数组中,这是很耗费性能的一个操作,Go 中也是一样的。因此在日常开发使用 List 或者切片的时候,如果能提前确定容量,最好就是初始化的时候就定义好,避免扩展导致的性能损耗。
2.5集合
Go 中除了把 List 内置为切片,同样也把 Dictionary内置为了 map 类型。map 是 Go 中三个引用类型的第二个,其创建的方式和切片相同,也需要通过 make 函数:
m := make(map[int]string, 10)从字面意思我们就可以知道,这句话是创建了一个 key 为 int,value 为 string,初始容量是 10 的 map 类型。
对 map 的操作没有像 C#那么复杂,get,set 和 contains 操作都是通过[]来实现的:
m := make(map[string]string, 5)
// 判断是否存在
v, ok := m["aab"]
if !ok {
//说明map中没有对应的key
}
// set值,如果存在重复key则会直接替换
m["aab"] = "hello"
// 删除值
delete(m, "aab")这里要说个坑,虽然 Go 中的 map 也是可以遍历的,但是 Go 强制将结果乱序了,所以每次遍历不一定拿到的是相同顺序的结果。
2.6面向对象
2.6.1封装
终于说到面向对象了。细心的同学肯定已经看到了,Go里面竟然没有封装控制关键字public,protected和private!那我这面向对象第一准则的封装性怎么搞啊?
Go 语言的封装性是通过变量首字母大小写控制的(对重度代码洁癖患者的我来说,这简直是天大的福音,我再也不用看到那些首字母小写的属性了)。
// struct类型的首字母大写了,说明可以在包外访问
type People struct {
// Name字段首字母也大写了,同理包外可访问
Name string
// age首字母小写了,就是一个包内字段
age int
}
// New函数大写了,包外可以调到
func NewPeople() People {
return People{
Name: "jeffery",
age: 28
}
}2.6.2继承
封装搞定了,继承怎么搞呢?Go 里好像也没有继承的关键字extends啊?Go 完全以设计模式中的优先组合而非继承的设计思想设计了复用的逻辑,在 Go 中没有继承,只有组合。
type Animal struct {
Age int
Name string
}
type Human struct {
Animal // 如果默认不定义字段的字段名,那Go会默认把组合的类型名定义为字段名
// 这样写等同于: Animal Animal
Name string
}
func do() {
h := &Human{
Animal: Animal{Age: 19, Name: "dog"},
Name: "jeffery",
}
h.Age = 20
fmt.Println(h.Age) // 输出:20,可以看到如果自身没有组合结构体相同的字段,那可以省略子结构体的调用直接获取属性
fmt.Println(h.Name) // 输出:jeffery,对于有相同的属性,优先输出自身的,这也是多态的一种体现
fmt.Println(h.Animal.Name)// 输出:dog,同时,所组合的结构体的属性也不会被改变
}这种组合的设计模式极大的降低了继承带来的耦合,单就这一点来说,我认为是完美的银弹。
2.6.3抽象
在讲解关键字的部分我们就已经看到了,Go 是有接口的,但是同样没有实现接口的implemented关键字,那是因为 Go 中的接口全部都是隐式实现的。
type IHello interface {
sayHello()
}
type People struct {}
func (p *People) sayHello() {
fmt.Println("hello")
}
func doSayHello(h IHello) {
h.sayHello()
}
func main() {
p := &People{}
doSayHello(p) // 输出:hello
}可以看到,上例中的结构体 p 并没有和接口有任何关系,但是却可以正常被doSayHello这个函数引用,主要就是因为 Go 中的所有接口都是隐式实现的。(所以我觉得真的有可能出现你写着写着突然就实现了某个依赖包的某个接口的情况)
此外,这里看到了一个不一样的语法,函数关键字 func 之后没有直接定义函数名称,而是加入了一个结构体 p 的一个指针。这样的函数就是结构体的函数,或者更直白一点就是 C#中的方法。
在默认情况下,我们都是使用指针类型为结构体定义函数,当然也可以不用指针,但是在那种情况下,函数所更改的内容就和原结构体完全不相关了。所以一般也遵循一个无脑用指针的原则。
好了,封装、继承和抽象都有了,至于多态,在继承那里已经看到了,Go 也是优先匹配自身的相同函数,如果没有才回去调用父结构体的函数,因此默认情况下的函数都是被重写之后的函数。
2.7设计哲学
Go 语言的设计哲学是less is more。这句话的意思是 Go 需要简单的语法,其中简单的语法也包括显式大于隐式(接口类型真是满头问号)。这是什么意思呢?
2.7.1. Go 没有默认的类型转换
var i int8 = 1
var j int
j = i // 编译报错:Cannot use 'i' (type int8) as the type int还有一个例子就是 string 类型不能默认和 int 等其他类型拼接,比如输入”n你好” + 1在 Go 中同样会报编译错误。原因就是 Go 的设计者觉得这种都是隐式的转换,Go 需要简单,不应该有这些。
2.7.2. Go 没有默认参数,同样也没有方法重载
这也是一个很让人恼火语言特性。因为不支持重载,写代码时就不得不写大量可能重复但是名字不相同的函数。这个特性也是有开发者专门问过 Go 设计师的, 给出的回复就是 Go 的设计目标就是简单,在简单的大前提下,部分冗余的代码是可以接受的。
2.7.3.Go 不支持 Attribute
和目前没有泛型不同,Go 的泛型是一个正在开发的功能,是还没来得及做的。而特性 Attribute 也就是 Java 中的注解,在 Go 中是被明确说明不会支持的语言特性。
注解能在 Java 中带来怎样强大的功能呢?举一个例子:
在大型互联网都转向微服务架构的时代,分布式的多段提交,分布式事务就是一个比较大的技术壁垒。以分布式事务为例,多个微服务很可能都不是一个团队开发的,也可能部署在世界各地,而如果一个操作需要回滚,其他所有的微服务都需要实现回滚的机制。这里不光涉及复杂的业务模型,还有更复杂的数据库回滚策略(什么 2PC 啊,TCC 啊每一个策略都可以当一门单独的课来讲)。
这种东西如果要从头开发那几乎是很难考虑全面的。更别提这样的复杂代码再耦合到业务代码中,那代码会变得非常难看。都不说分布式事务了,简单的一个内存缓存,我们用的都很混乱,在代码中会经常看到先读取缓存在读取数据库的代码,和业务完全耦合在一起,完全无法维护。
而 Spring Cloud 中,代码的使用者可以通过一个简单的注解(也就是 C#的特性)@Transactional,那这个方法就是支持事务的,使这种复杂的技术级代码完全和业务代码解耦,开发者完全按照正常的业务逻辑写业务代码即可,完全不用管事务的一些问题。
然而, Go 的设计者同样认为注解会严重影响代码使用者对一个调用的使用心智,因为加了一个注解,就可以导致一个函数的功能完全不一样,这与 Go 显式大于隐式的设计理念相违背,会严重增加使用者的心智负担,不符合 Go 的设计哲学(哎,就离谱…)
2.7.4. Go 没有 Exception
在 Go 中没有异常的概念,相反地提供了一个 error 的机制。对 C#来说,如果一段代码运行存在问题,那我们可以手动抛出一个 Exception,在调用方可以捕获对应的异常进行之后的处理。而 Go 中没有异常,替代的方案是 error 机制。什么是 error 机制呢?还记得之前讲过的 Go 的几乎所有的函数都有多个返回值吗?为啥要那么多的返回值呢?对,就是为了接收 error 的。比如下述代码:
func sayHello(name string) error {
if name == "" {
return errors.New("name can not be empty")
}
fmt.Printf("hello, %s\n", name)
return nil
}
// invoker
func main() {
if err := sayHello("jeffery"); err != nil {
// handle error
}
}这样的 error 机制需要保证所有的代码运行过程中都不会异常崩溃,每个函数到底执行成功了没有,需要通过函数的返回错误信息来判断,如果一个函数调用的返回结果的 error == nil,说明这段代码没问题。否则,就要手动处理这个 error。
这样就有可能导致一个严重的后果:所有的函数调用都需要写成
if err := function(); err != nil这样的结构。这样的后果几乎是灾难性的(这也是为啥 VS2022 支持了代码 AI 补全功能后,网上的热评都是利好 Gopher)这种 error 的机制也是 Go 被黑的最惨的地方。
那这时候肯定有小伙伴说了,那我就是不处理搞一个类似于1/0这样的代码会怎么样呢?
如果写了类似于上述的代码,那最终会引发一个 Go 的panic。在我目前浅显的理解中,panic其实才是 C#中 Exception 的概念,因为程序运行遇到 panic 后就会彻底崩溃了,Go 的设计者在最开始的设计中估计是认为所有的错误都应该用 error 处理,如果引发了 panic 那说明这个程序无法使用了。因此 panic 其实是一个无法挽回的错误的概念。
然而,大型的项目中,并不是自己的代码写的万无一失就没有 panic 了,很可能我们引用的其他包干了个什么我们不知道的事就 panic 了,比如最典型的一个例子:Go 的 httpRequest 中的 Body 只能读取一次,读完就没有了。如果我们使用的 web 框架在处理请求时把 Body 读了,我们再去读取结果很有可能 panic。
因此,为了解决 panic,Go 还有一个 recover()的函数,一般的用法是:
func main() {
panic(1)
defer func() {
if err := recover(); err != nil {
fmt.Println("boom")
}
}
}其实 Go 有一个强大的竞争者——Rust,Rust 是 Mozilla 基金会在 2010 年研发的语言,和 Go 是以 C 语言为基础开发的类似,Rust 是以 C++为基准进行开发的。所以现在社区中就有 Go 和 Rust 两拨阵营在相互争论,吵得喋喋不休。当然,万物没有银弹,一切的事物都应该以辩证的思维去学习理解。
好了,看完了上面那些 Go 的语法之后,肯定也会手痒写一点 Go 的代码练习练习,加深记忆。正好,那就来实现一个 Go 官网中的一个小例子,自己动手实现一下这个计算 Fibonacci 数列第 N 个数的接口吧。
type Fib interface {
// CalculateFibN 计算斐波那契数列中第N个数的值
// 斐波那契数列为:前两项都是1,从第三项开始,每一项的值都是前两项的和
// 例如:1 1 2 3 5 8 13 ...
CalculateFibN(n int) int
}由于篇幅所限,这个小练习的答案我放在了自己的 gitee中,欢迎大家访问。
