老夫桌上有酒,不喜独酌,闻数家国产CPU有擅桌面者,故许利淘宝陆续擒得之,长随老夫左右伴饮。已得龙芯、海光、飞腾、兆芯四姓围坐,皆为桌面CPU才俊,老夫甚慰。
此日海光新至,为其接风饮宴。席间其乐融融,众CPU互报姓名,曰:海光C86-3250、龙芯3A5000、飞腾D2000、兆芯KX-U6780A。其间海光3250言其太上蛮横,只许子弟行走于服务器和工作站之间,围坐桌面乃是越矩,此番被拘于此方知桌面之妙,愿以文会友,以人鉴己。老夫虽知其本意,却亦有意相试各CPU才情,便允其以文会友之请。
然唯有龙芯3A5000跃跃欲试,飞腾D2000及兆芯KX-U6780A皆面色有异。老夫颇为不解,此二子平日豪言已至国际先进水平,此时缘何畏惧?为探知真相,余唤来四位海外桌面CPU王侯,与国产四俊以同题相校,印证各CPU水平究竟。
再观各CPU颜色,龙芯3A5000对海外王侯竟显“彼可取而代也”之豪情。海光3250面色淡然,似无争强之意。飞腾D2000和兆芯KX-U6780A两股战战,几欲先走。老夫见此情景更生疑惑,先令家仆闭门,再令所有CPU报上各自参数。往酒缸中投入几枚青梅后,便拟定以SPEC CPU2006&2017、Stream、UnixBench试之,数日后定要见个分晓。
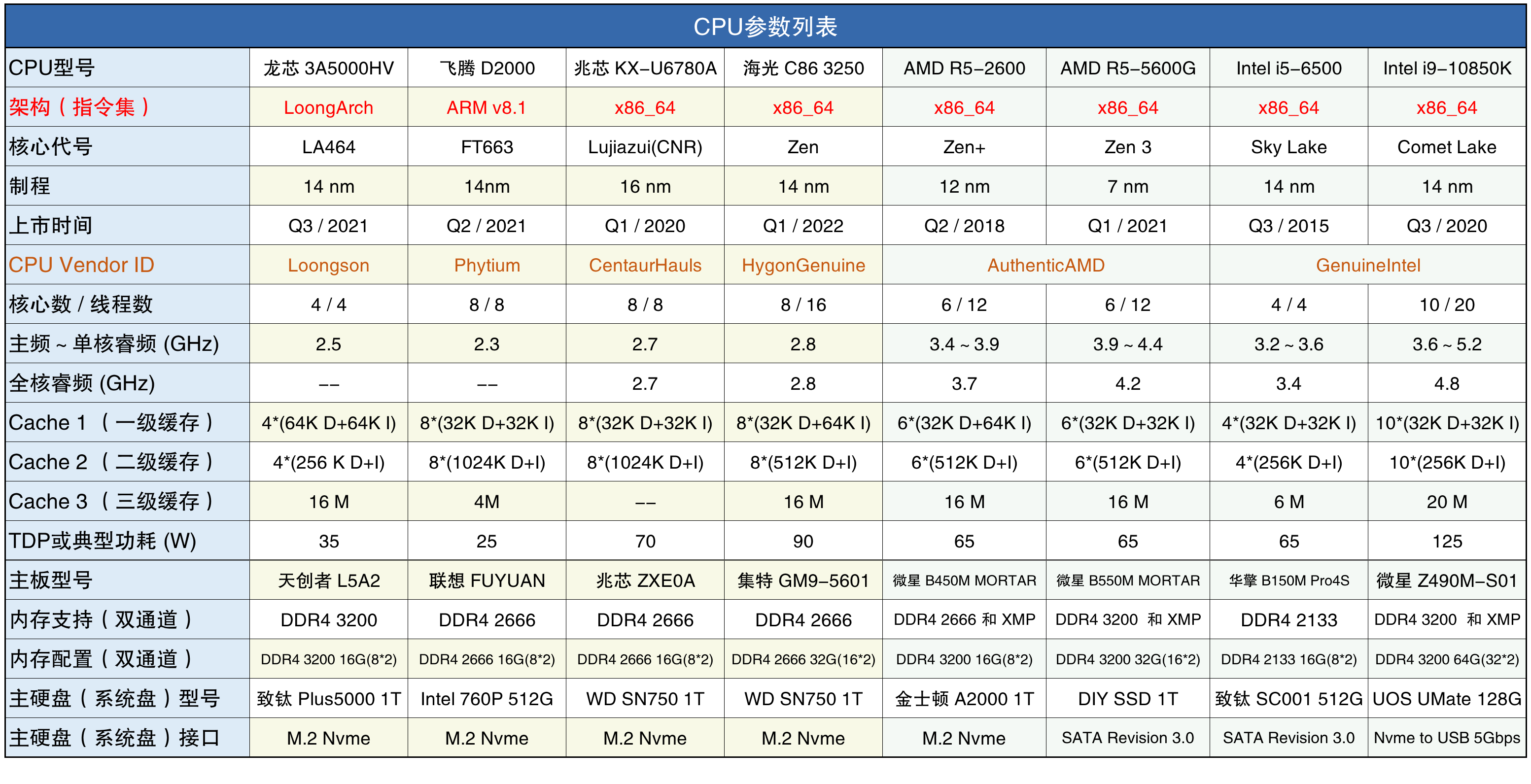
上表8款CPU中,纸面参数最弱者是龙芯3A5000,仅为4核2.5GHz。次弱者是Intel i5-6500,亦为4核,但最高频率较龙芯3A5000多出44%,余者6核、8核、10核皆有。海光、兆芯、飞腾皆为8核,主频也相近,余更不解兆芯和飞腾何以畏缩。
在四款国产CPU中,只有海光支持超线程,它的核心是购自AMD的初代Zen,但3250的主频仅有2.8GHz,比AMD相同核心的产品低了很多。所有的国产CPU主频都不高,大约都只有Intel和AMD同类产品的一半左右,也就是说即使国产CPU每GHz的性能与Intel和AMD相差无几,单核性能也只有它们的一半左右。
严格地说,四款国产CPU都不支持睿频,海光虽言说有睿频,但无法开启。龙芯和飞腾都是固定频率,海光和兆芯支持在低负载时自动降频。但海光和兆芯的TDP决定了,就算降了频功耗也低不到哪儿去,可以用于桌面和工作站,做笔记本CPU就有些不合时宜。
兆芯和飞腾也与海光一样也走的是先引进再自主的路线,不过这么多年过去,它们的CPU核心有多少自主设计的成分尚不可知。特别是兆芯CPU VendorID仍是初始设计者CentaurHauls,就更显疑窦丛生。
四款国产CPU中唯一从零开始自主设计CPU核心的只有龙芯3A5000,可它非但主频比海光3250和兆芯KX-U6780A低,且核心数量也只有另外几款国产CPU的一半,令它同台竞技似乎有些不近人情,但它已然摩拳擦掌,那还是不要按捺的好。若把各款CPU的单核测试成绩都折算成1.0GHz的得分,倒是可以称量称量龙芯3A5000的核心设计水平与其它CPU相差几许。
SPEC CPU 2006&2017 测试说明
SPEC CPU 2006和2017都是业界公认的专业的CPU通用性能评估工具,两者是在不同年代发布的不同版本。它们测试的是CPU整数和浮点通用处理性能,重点在“通用”这两个字。整数通用性能代表了常规桌面和服务器软件在CPU上运行时的性能表现,浮点通用性能则侧重于科学计算、人工智能等专业任务的性能表现。各家CPU厂商在发布新产品时,通常都会发布SPEC CPU的整数通用性能评估结果,一般都包含了单任务和多任务两种模式的测试成绩。
int_speed:单任务整数通用性能,编译器不开启自动并行化时表示单核性能。
fp_speed:单任务浮点通用性能,编译器不开启自动并行化时表示单核性能。
int_rate:多任务整数通用性能,任务数≥核心数量时代表全CPU性能。
fp_rate:多任务浮点通用性能,任务数≥核心数量时代表全CPU性能。
SPEC CPU是包含了数十个性能评估项目的测试套件,涵盖了众多领域和场景的应用算法,测试内容以C、C++、Fortran源代码的形式提供。程序中没有嵌入针对特定架构优化的汇编代码,以保证它在跨架构测试时的公平性。测试者需要自行配置编译器和编译参数,由SPEC CPU的测试程序根据配置自动编译并运行测试项目。编译优化参数可以配置为base和peak两种模式,区别是peak模式允许对每一个测试项目单独配置优化参数,并且支持二次编译优化。因此操作系统、编译器类型、编译优化参数对测试成绩有很大影响。有的测试者还会使用第三方优化组件、开启单任务自动并行化、32位和64位混合编译等手段来提高测试成绩。内存性能也对测试成绩有影响,但主要影响多任务并行时的成绩,对单任务的测试成绩影响较为有限,硬盘、显卡等其它设备对测试结果的影响可以忽略不计。
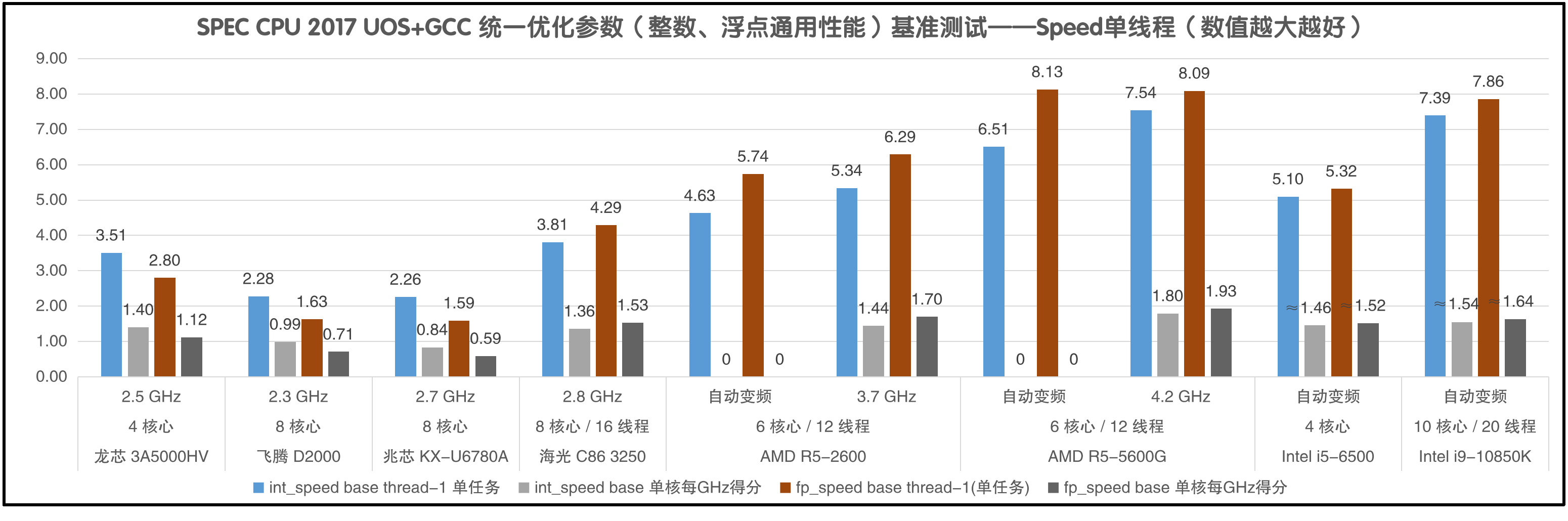
“单任务并行化”是把单线程程序中的部分循环代码拆分到多个核心上并行运行的技术。在一段循环代码中,如果改变每次循环的顺序不会影响运行结果,那么这个循环就可以并行化。 如果在编译时允许了“自动并行化”,那么单任务的测试成绩就不能代表单核性能。SPEC CPU2006版的“自动并行化”依赖编译器分析代码的能力,2017版在是测试集源码中添加了对OpenMP的支持,也就是由源码的编写者手工指定哪些循环代码可以并行执行。在引入OpenMP之后,就弱化了编译器自动并行化的作用,使性能评估更加规范。因此在SPEC CPU2017的测试中,对单任务必须明确标注使用了多少个线程。
SPEC CPU的测试集中可以并行化的代码不多,CPU核心越多开启并行化后的收益就越高。但大多数普通软件的源码中可以被并行化的代码比SPEC CPU更少,编译器的自动并行化又可能对软件的其余部分造成负面影响,因此几乎只被用来跑分。除了自动并行化之外,把GCC换成ICC也能把总成绩提升10%左右,再开启ICC增强的“自动向量化”还能再提升10%左右,然后再加上第三方优化组件也能把总成绩提升10%左右,最后再换成peak模式对每个测试项目单独调优,并且开启二次编译优化,还能把成绩再提高10%左右……然而上述所有的提分手段对普通应用软件的增益都远不如SPEC CPU跑分明显,反而会引起兼容性和稳定性降低的问题,因此凡是有大量用户的知名软件都会避免使用这些跑分专用的、近似于“作弊”的优化技术。
此次测试都使用UOS系统,国产CPU使用UOS专业版,进口CPU使用UOS家庭版。编译器都使用系统中内置的GCC、G++、GFortran 8.3版本,不使用任何的第三方优化库,也不开启单任务自动并行化,测试项目都统一编译为64位,只测试base模式的成绩。之所以不使用那些有助于提升测试成绩的额外的优化方法,是因为需要满足所有前置条件才能获得的高分对软件开发者没有意义、对软件用户更没有意义。有些CPU厂商用专门优化得到的peak成绩去对标同行正常测试的base成绩,是极端不自信的自欺欺人的表现,只有不使用那些跑分专用技巧时得到的测试成绩,才能代表用户能体验到的CPU性能。
SPEC CPU 2006&2017 测试成绩
为了使对比更加公平,老夫对编译优化参数也作出了限制,除了因为CPU指令集(架构)不同而不得不修改的参数之外,其它的编译优化参数都完全一致。免得它们到时候说别人成绩好是因为编译参数优化得好,自己成绩差是老夫故意劣化,凡是以此种借口掩耳盗铃者,一律打出门去。
为了得到AMD的两款CPU较为准确的每GHz的成绩,就给它们加测了一次固定CPU频率时的成绩。一来为了验证海光购买的AMD Zen核心和比它更新一些的Zen+核心有多大差距,二来因为龙芯说下一代3A6000每GHz的成绩和Zen3相当,老夫提前收集一点儿数据,等3A6000发布后方便验证是否与宣传相符,到时候该夸就夸该骂就骂。
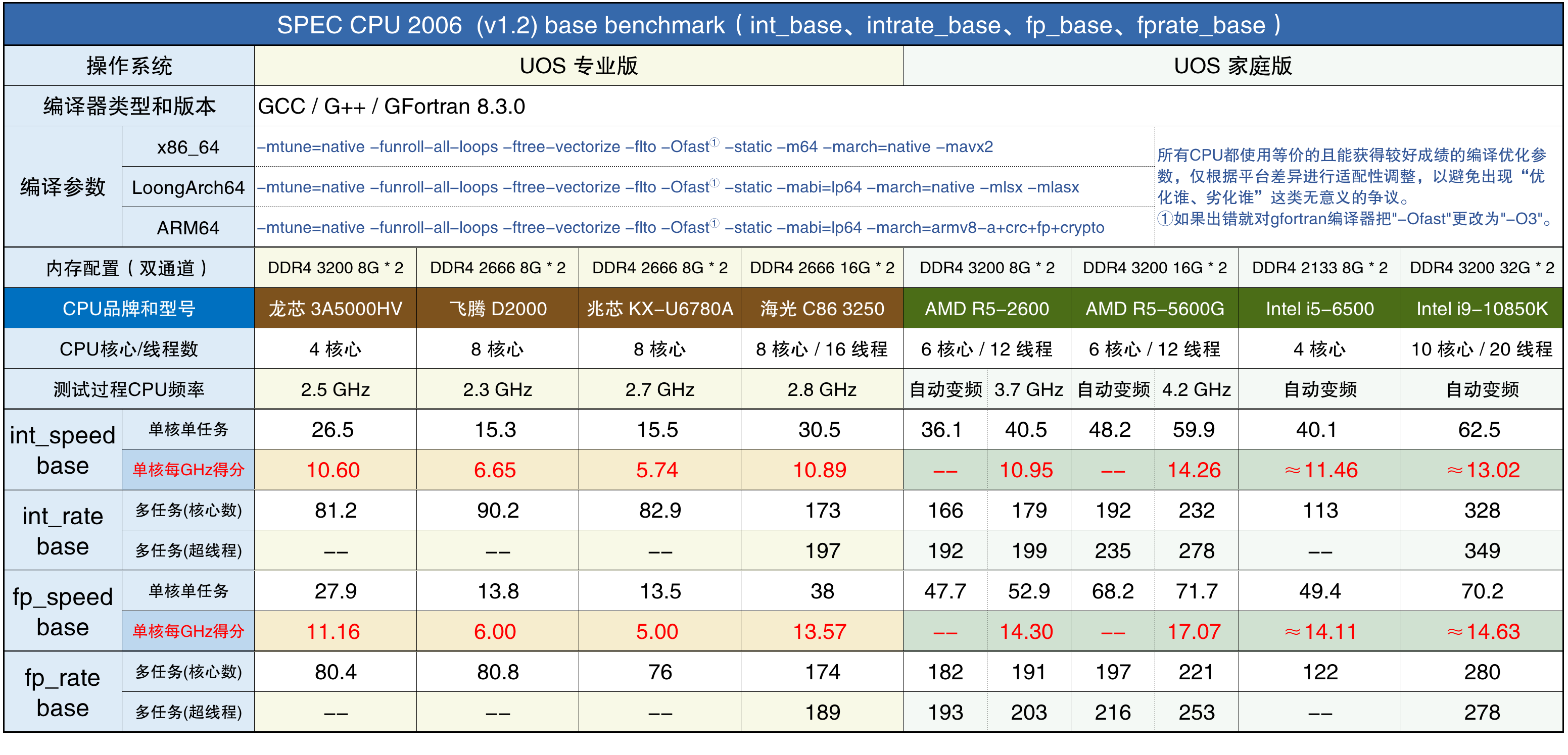
SPEC CPU 2006的speed和rate分别是单任务和多任务测试,测试项目相同,只是并行的任务数量不同。
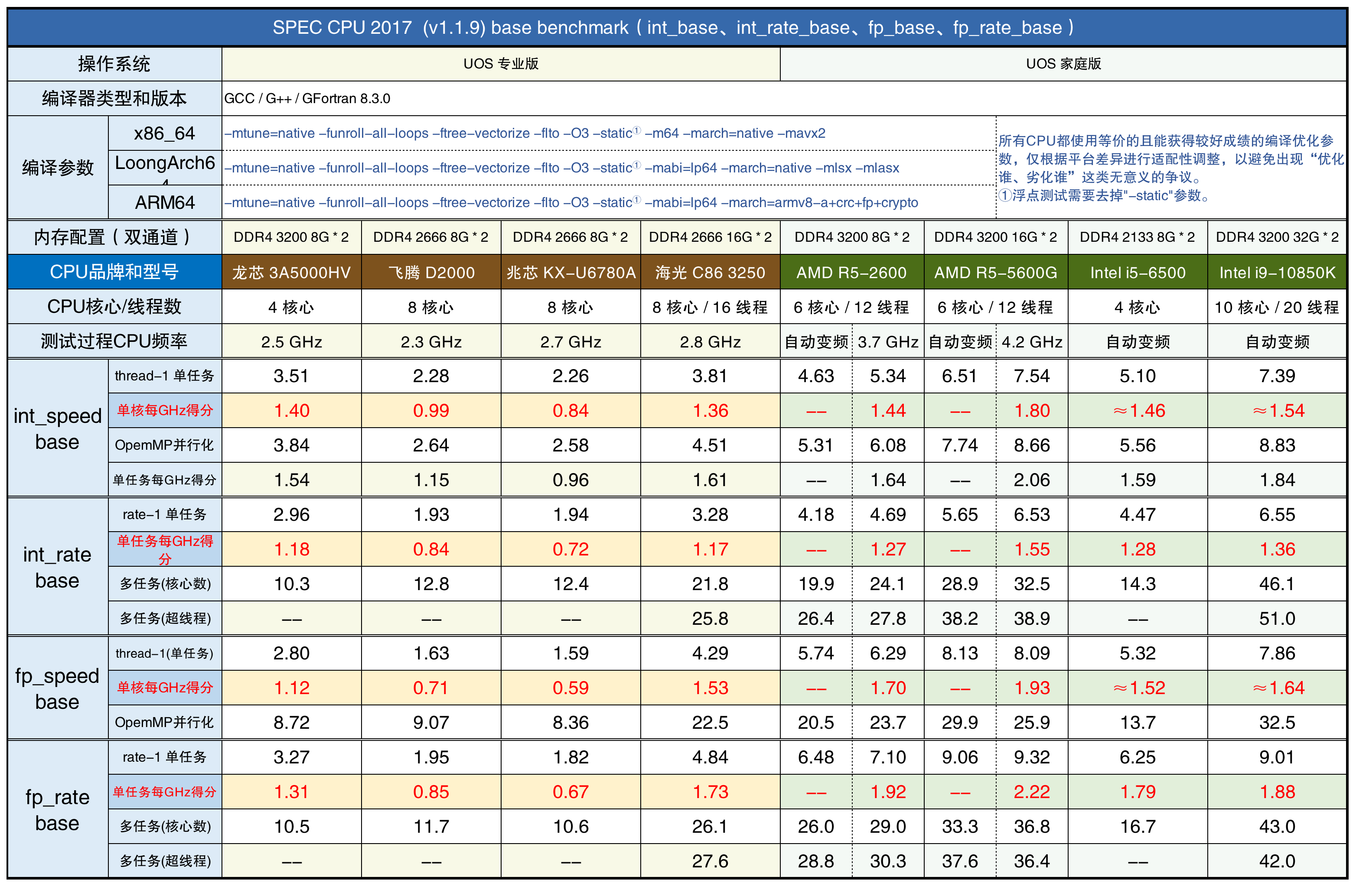
SPEC CPU 2017的speed和rate分别是单任务和多任务测试,不只是并行的任务数量不同,测试项目也有区别。因此除了测试了speed 的单线程成绩(thread-1 单任务),还测试了rate模式时只运行一个任务的成绩(rate-1 单任务),这两种模式的成绩是不同的。
通过对表中成绩的解读,可以得出以下结论:
- CPU的频率控制很影响性能发挥。
当由主板和系统自动控制CPU频率时,CPU的频率会根据负载和温度不断变化,不同的CPU、主板、操作系统和设置,都会影响控制频率的策略。AMD的两款CPU在单核高负载时,频率被控制在默认频率附近,在多核高负载时才更接近最高睿频。而Intel的CPU就正好相反,单核高负载时倾向于保持睿频,多核高负载时反而降到了默认频率附近。导致10核20线程的i9-10850k在多任务测试中表现得不好,相对于R5-5600G来说成绩没有核心数量的差距那样大。
在不锁定CPU频率时测试单任务,R5-2600平均频率约为3.3GHz,R5-5600G平均频率约为3.4GHz,i5-6500平均频率约为3.5Ghz,i9-10850K平均频率约为4.8GHz。
4款国产CPU在测试过程中都能保持在最高频率,性能表现稳定。
- CPU频率相近不等于单核性能相近。
例如兆芯KX-U6780A在SPEC CPU 2006和2017的测试中,单核整数成绩分别是15.5和2.26,仅为海光3250的50%~60%,也只有龙芯3A5000的60%左右,而它们的主频差距很小。这说明频率不能单独决定CPU单核性能,CPU的单核性能等于“频率×IPC”。IPC是“每周期执行的指令数”,在相同频率下IPC越高的CPU,通过测试软件得到的成绩越高。
当内存频率不变时,IPC随CPU频率升高而降低,因此把单核成绩折算到每GHz成绩会有误差。但是当内存带宽不是瓶颈时,它对测试成绩的影响就较低,所以把5GHz时的单核测试成绩折算到1GHz时产生的误差可以忽略不计。
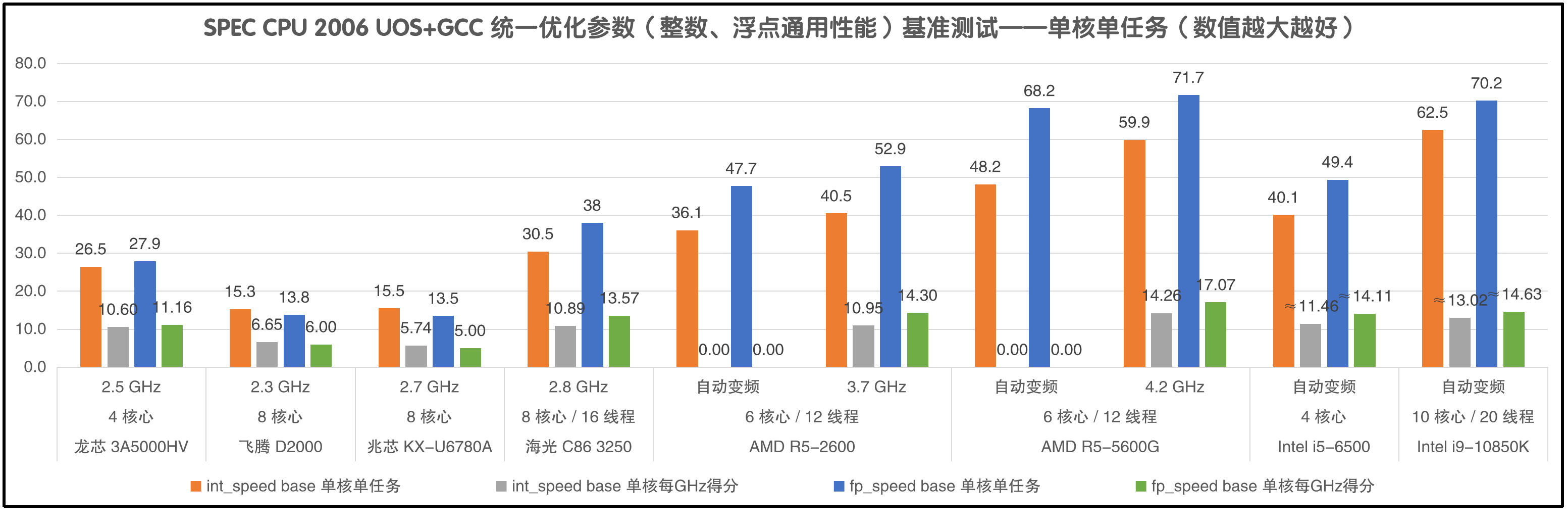
IPC或每GHz成绩主要代表了CPU核心的逻辑设计水平,CPU的主频主要体现出物理设计和制程工艺的水平。例如Pentium4(641)用SPEC CPU 2006测得的每GHz单核整数成绩仅2.37,IPC太低,它如果想达到i9-10850K(5.2Ghz)时的单核性能,就必须把主频提到近30GHz。
CPU核心的逻辑设计、物理设计、以及制程工艺的水平提升必须并重,特别是在国产CPU的物理设计和制程工艺短时间难以突破的情况下,更有必要通过提高逻辑设计能力来提高IPC。
AMD说Zen+比Zen的IPC提升了3%,这里对海光3250和AMD R5-2600的测试没有体现出来,主要原因是UOS专业版对x86多了一些额外的优化,老夫也用家庭版在相同条件下测试过海光3250,SPEC CPU 2006单核整数成绩没过30分,符合Zen+比Zen的IPC提升了3%的说法。
在整数通用性能方面,龙芯3A5000核心逻辑设计水平和海光3250(AMD Zen)相当。在Zen的IPC水平上,龙芯3A5000的主频要比海光3250低0.3GHz,导致单核性能也要低一些。龙芯下一代3A6000的核心逻辑设计水平可能和AMD Zen3相当,且整数和浮点IPC都与Zen3差不多。
- 对于不同的CPU,浮点性能与整数性能不一定是相同比例。
例如几款x86指令集的CPU,只有兆芯KX-U6780A的浮点成绩比整数成绩低,与VIA历史上的所有CPU都如出一辙。飞腾D2000的浮点成绩比整数成绩低,也体现了ARM的传统风格。
龙芯3A5000在SPEC CPU 2006测试中浮点成绩与整数成绩差不多,但SPEC CPU 2017的浮点测试成绩低于本人预期,怀疑是由于GFortran编译器对LoongArch架构优化不足的缘故。不过3A5000的浮点成绩也不算差,单核成绩比使用7nm工艺的鲲鹏920还高一些。
- SPEC CPU 2006 和2017的测试成绩没有固定的换算比例
虽然SPEC CPU 2006和2017是同一款性能评估套件的两个版本,有部分测试项目相似,但是它们仍然是两种不同的性能评估工具,所得到的成绩不能相互换算。
比如飞腾D2000和KX-U6780A在使用SPEC CPU20017进行测试时,表现得就比使用SPEC CPU2006的时候更好,每款CPU的两种测试成绩的比例都不相同。
本次测试没有鲲鹏920,但这里有一份来自鹏城实验室的SPEC CPU 2017测试成绩供参考,我们暂时只关注单任务的测试成绩:

表中是用48核的鲲鹏920与64核的飞腾FT-2000+进行对比,FT-2000+的核心和本次测试的D2000一样,但主频要低一些,因此单任务单线程的int_speed成绩只有2.11,比D2000的2.28要低一些。不过FT-2000+有64个核心,所以单任务64线程的测试成绩就要比D2000高一些。按公开资料中的说法,鲲鹏920的48核版本主频是2.6GHz,但它单任务单线程的int_speed成绩只有3.01,而2.5GHz的龙芯3A5000得分是3.51。但已知鲲鹏920在2.6GHz时用SPEC CPU 2006测试的int_speed成绩和龙芯3A5000相近,这又是一个2006和2017的成绩不存在固定比例的例子。
虽然两个版本的SPEC CPU的测试成绩不存在固定比例,但测试成绩都与CPU性能有强相关性。使用同种没有针对特定环境优化的测试工具进行横向对比时,性能越高的CPU成绩就一定会越好。
- CPU多核性能不是对所有核心简单叠加。
无论是整数还是浮点测试,每个核心的平均效率总是会随着并行任务数量的增加而降低。在CPU频率不变的情况下,影响多任务效率的主要因素是内存带宽和多核心的互联效率。CPU性能越高,内存带宽不足造成的负面影响就越大;CPU核心数量越多,核间互联效率就越低。
比如海光3250的SPEC CPU 2006整数单任务成绩是30.5,如果直接乘上8个核心,那么8任务整数成绩应该是244,但实际上只有173。用173÷244,得到多任务时平均每个核心的效率只有70.9%。SPEC CPU 2017因为speed和rate的测试项目不同,所以应该用rate-1的成绩计算每个核心的平均效率。计算平均效率时也不能把超线程计算在内,否则会有很大的误差。在测试过程中发现只有4款国产CPU在多任务时仍然能保持频率,其它CPU即使在BIOS中设置了固定的倍频,多任务时也仍然会有降频的现象,也会导致计算每个核心的平均效率时出现误差。下方的图表中就只统计4款国产CPU在运行SPEC CPU时每个核心的平均效率:
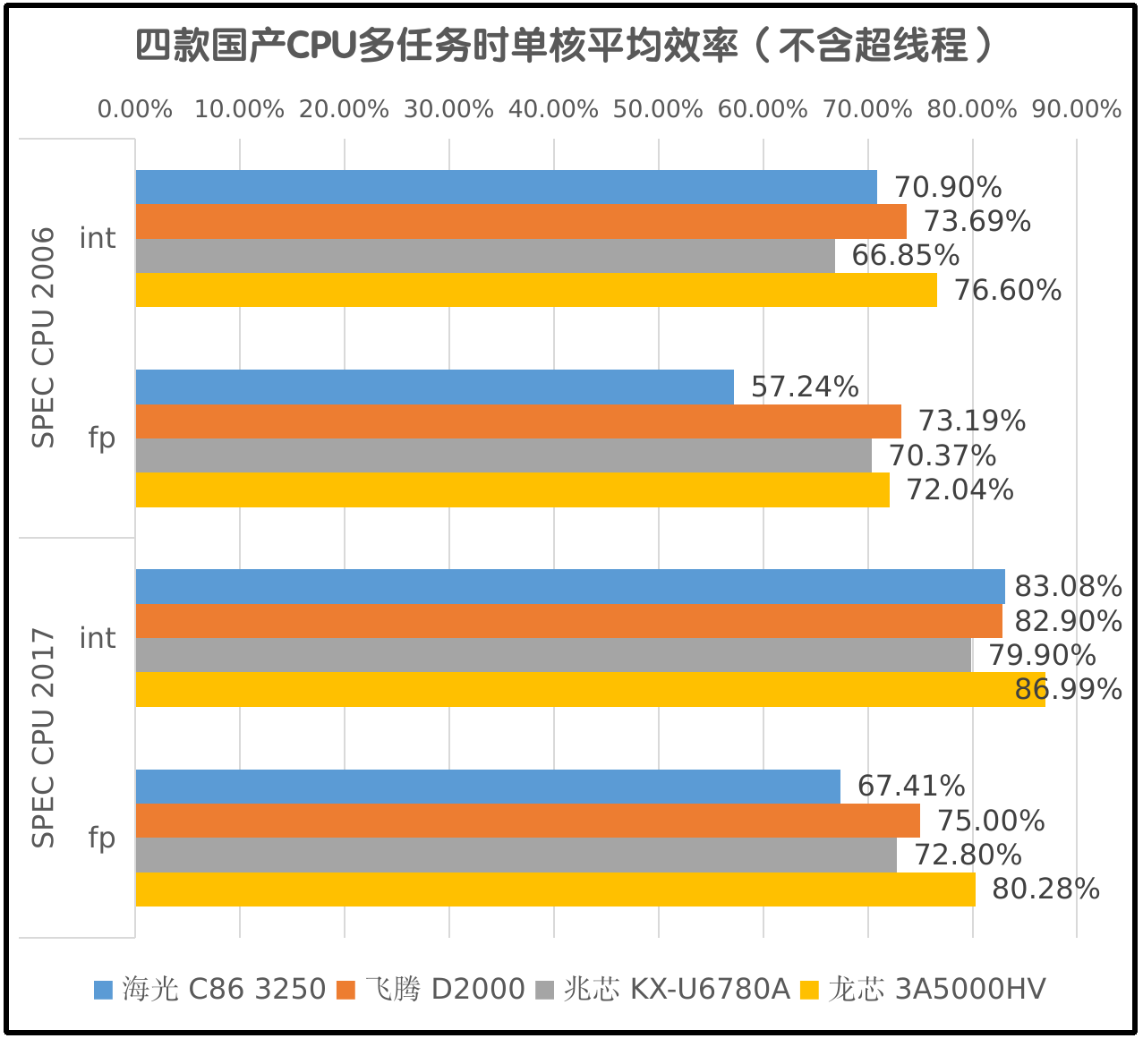
可以清楚地看到,不同版本的SPEC CPU、不同的测试类型、不同的CPU,在运行多任务时每个核心的平均效率是不同的。龙芯3A5000的多核效率高很有可能是它核心数量最少的原因,飞腾的多核效率也不错,海光和兆芯就要差上一些了。不过海光因为单核性能最高,还支持超线程,它的多核性能在四款国产CPU中仍然是最高的。
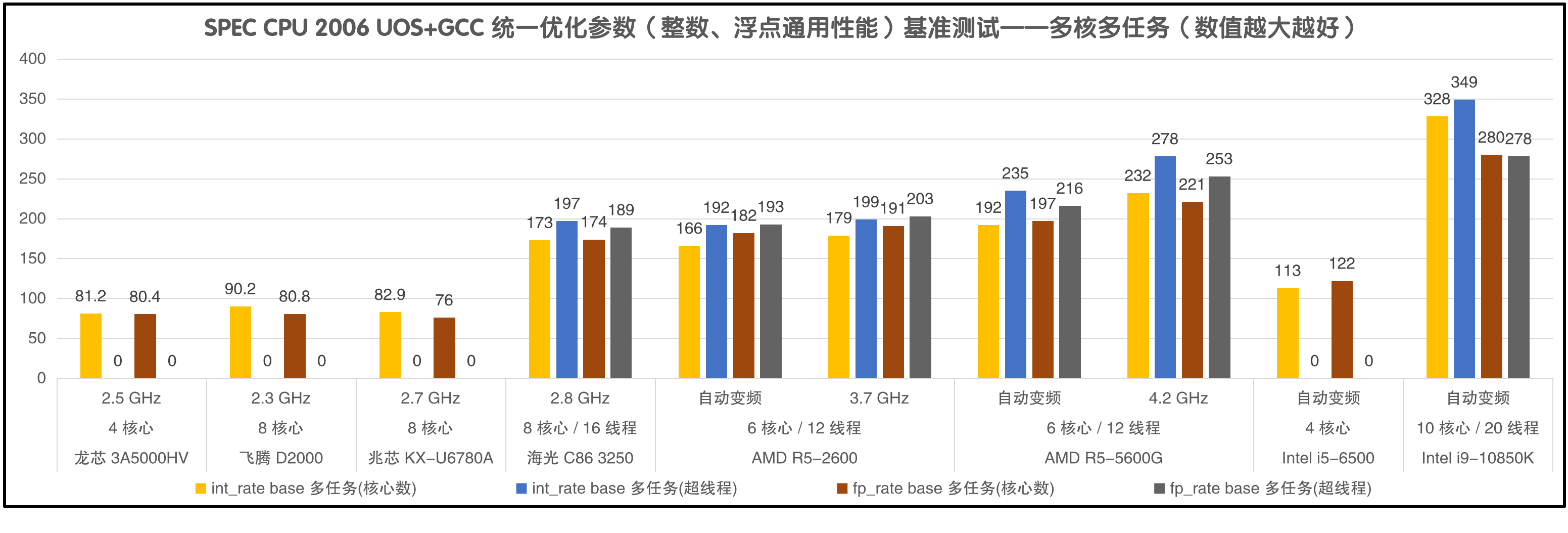
尽管海光3250无论整数还是浮点性能都比R5-2600低,但它毕竟是8核16线程,全CPU的多核性能与6核12线程的R5-2600是差不多的。可能把海光3250看作降频版本的AMD R7-1700更加恰当,因为都是8核16线程,都是Zen核心。

飞腾D2000和兆芯KX-U6780A有滥竽充数的嫌疑,它们也都是8个核心,测试成绩所代表的多核性能却还不到海光3250的一半,和4核的3A5000的多核成绩非常接近。
特别是兆芯,KX-U6780A单核每GHz的成绩和10年前引进的VIA C4350AL相比大约只提升了10%。但是VIA C4350AL的内存是DDR3 1333单通道,而KX-U6780A是DDR4 2666双通道,老夫毫不怀疑4倍的内存带宽可以把IPC提高10%。
从ZX-A到ZX-E,历经了5代产品,兆芯都还没有给CPU加上三级缓存。还有那个可笑的VendorID——CentaurHauls,在兆芯的桌面CPU上已经挂了10年。连海光CPU的VendorID都改成了HygonGenuine,兆芯却不忘本。不过有些令人担心的是,海光也无法再向AMD购买更新更好的核心,兆芯的今日是否是海光的明日犹未可知。
飞腾D2000最优秀的地方是功耗,它用25W的TDP达到了比兆芯70W的TDP略好的性能。飞腾D2000的功耗也要比龙芯3A5000的35W典型功耗更低,且多核性能比龙芯3A5000略高,毕竟是8核跟4核作比较,总不能一点优势都没有。
尽管4核的龙芯3A5000多核性能只是与8核的兆芯和飞腾桌面CPU相当,但在桌面应用中,单核性能高就是优点。桌面应用中的流畅度,海光3250与龙芯3A5000大约和2代酷睿i5、i7台式机差不多,兆芯KX-U6780A和飞腾D2000就只能和凌动平板电脑相提并论了。龙芯在6000系列才终于放下了4核打8核的执拗,3A6000是4核8线程,3B6000就是8核了(大小核设计)。3A6000预计单核及多核性能都超过i5-6500,与6、7代酷睿i7桌面CPU的性能相当,3B6000的单核及多核性能大约都能超过AMD R5-2600吧。
- 超线程在高负载时实际提升约为0%~20%,部分情况下造成负增长。
在某些测试中,超线程可提高50%以上的效率,因此造成了超线程可以把1个物理核心当成1.5个来用的印象。然而提高50%算是特例,实际上平均来看是不可能达到那么高的。
超线程的加速能力和程序的计算类型有关、和程序对内存带宽的需求有关、也和超线程的技术方案有关。使用涵盖面较广的SPEC CPU 2006&2017来测试,可以得出超线程对效率的平均提升幅度是0%~20%的结论。
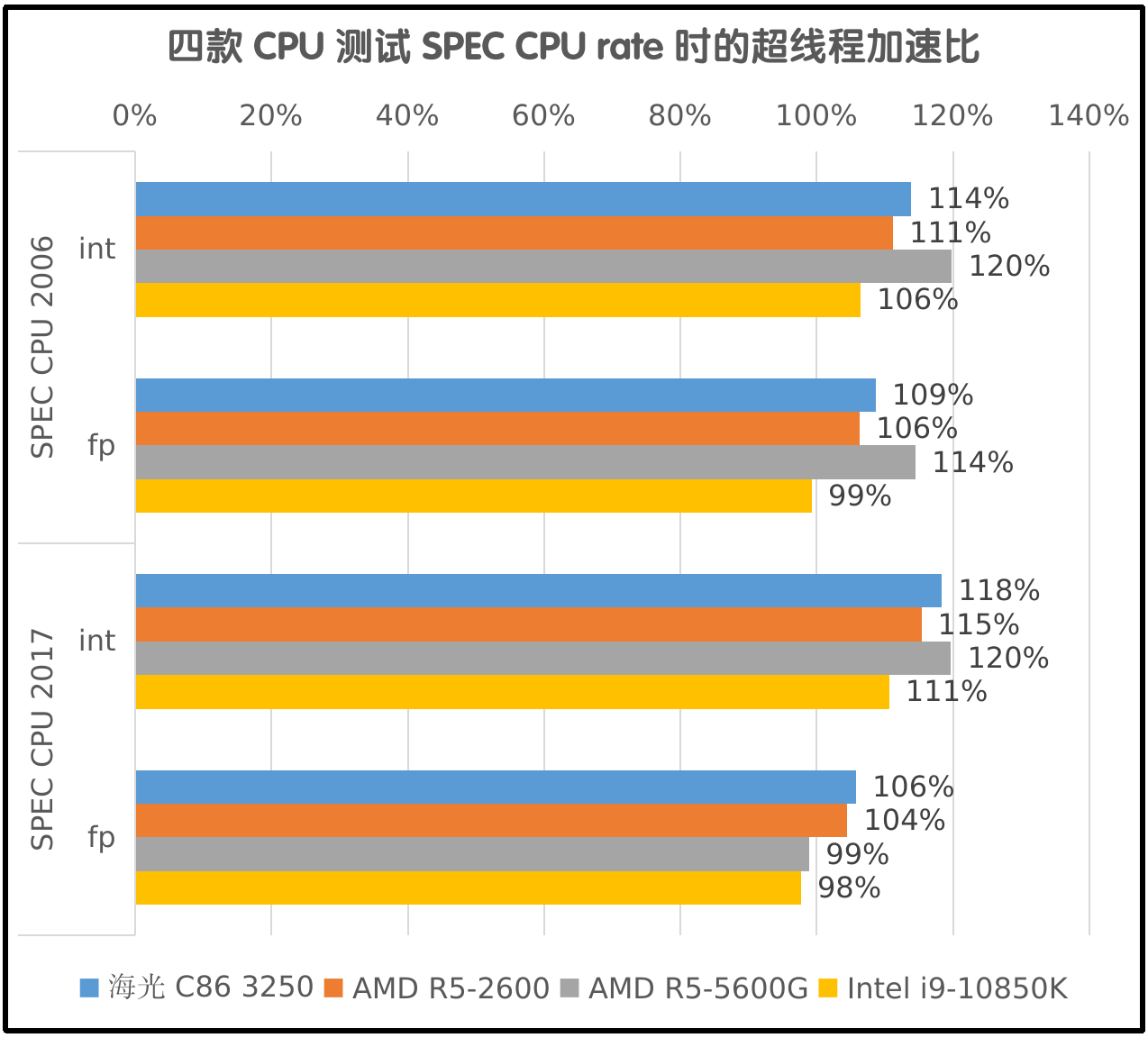
从上面的图表中可以看到在各项多任务测试中,海光3250的超线程加速比AMD R5-2600还高一些,老夫猜测是海光3250主频更低的原因。虽然它们的内存频率也有差距,但实际的内存访问速度差距不大。
Intel i9-10850k的超线程加速比最低,并且在SPEC CPU 2006和2017的浮点多任务测试中都出现了负增长,这能说明Intel的超线程技术最差吗?这种笑话不能信,真正的原因应该是Intel i9-10850k有20个线程,同时运行20个任务,内存带宽成为了瓶颈。R5-5600G在SPEC CPU 2017的浮点多任务测试中也同样出现了负增长,也能证明双通道DDR4-3200这时已经达到了极限。
桌面CPU不管有多少个核心,一般都只共享两个内存通道,这也是桌面CPU不能替代服务器CPU的主要原因之一。
stream内存访问速度测试
前面提到多任务并行时,内存性能会成为瓶颈,服务器CPU必须有更多的内存通道。但内存频率和通道数并不等价于内存访问速度, CPU中还有一个重要的组成部分是内存控制器,内存控制器和内存是“谁慢谁有理”的关系。比如DDR4-2666双通道理论带宽上限超过40GB每秒,但国产CPU中的内存控制器目前都达不到理论带宽的的内存访问速率。
Linux下测试内存访问速率通常是使用Stream测试软件,它也是以源码方式提供,根据编译参数不同而得到支持单线程和多线程测试的两种版本。通常使用GCC编译器的“-O”和“-O2”作为基础编译参数,如果使用GCC的“-O3”参数,对x86架构CPU的内存复制性能会有加成。
内存访问速率除了受限于内存控制器的实现以及CPU与内存的时序匹配之外,还与应用程序有密切关系。没有任何正常的软件会只读写内存而不干点别的事情,像Stream这种内存的带宽测试软件也是如此。Stream是在模拟普通应用软件访问内存的方式——在循环中读写数组,不像AIDA64那种执着于带宽极限,因此Stream测试得到的内存访问速率总是低于理论峰值。不过只要内存控制器效率越高,Stream访问内存的速率也一定越高。
下面是用Stream对8款CPU访问内存速率的测试结果,分别测试了单通道-单线程、单通道-多线程、双通道-单线程、双通道-多线程。编译参数使用了能代表大多数软件的“-O”,对双通道的情况又增加了对x86架构有加成的“-O3”参数。这8款CPU都是桌面CPU,但因为同系列的服务器CPU使用的内存控制器一般也相同,只是增加了通道数量,所以通过下表中的测试结果也能估计它们对应的服务器CPU访问内存的效率。
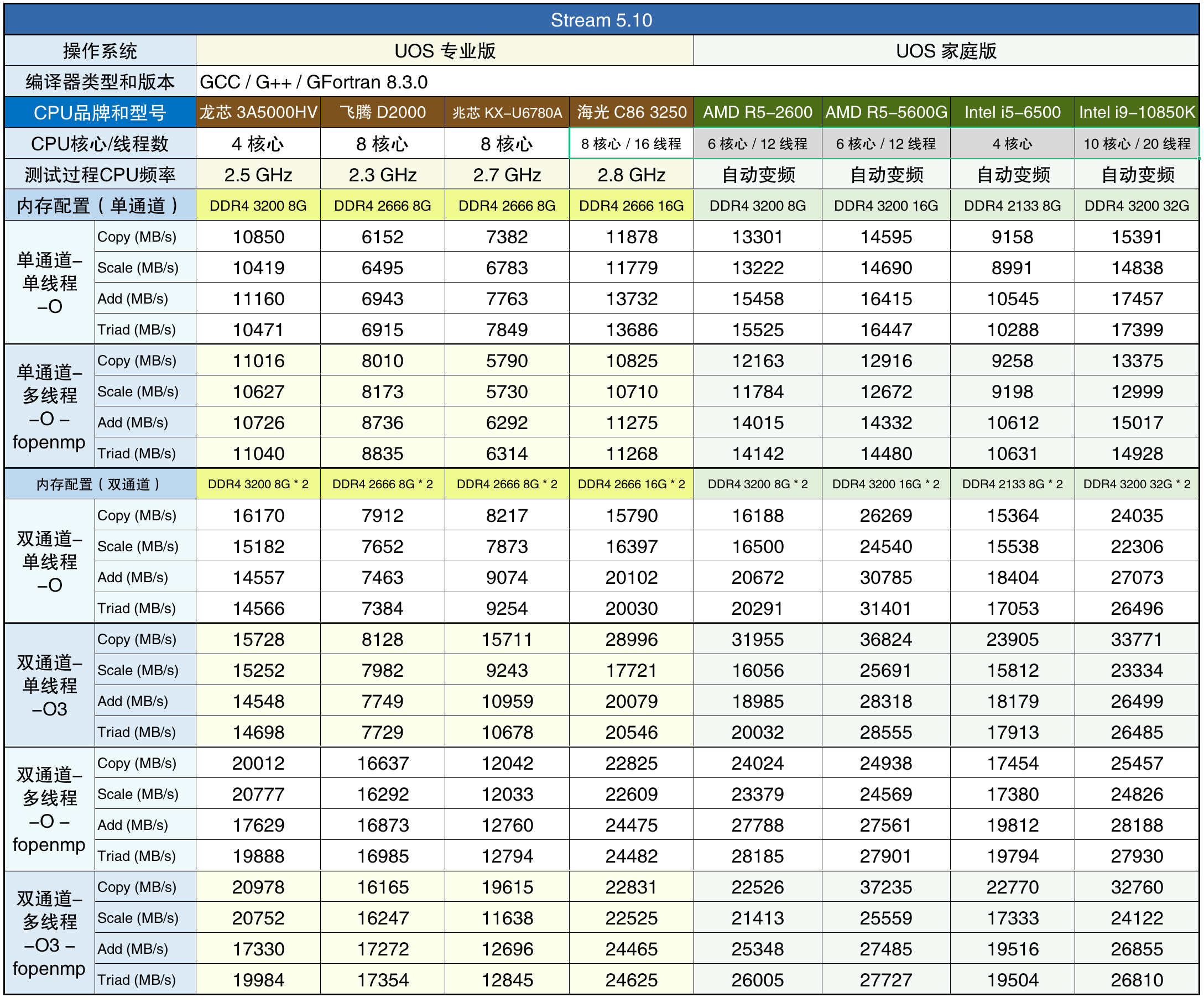
从实测数据来看,海光3250的内存控制器效率和AMD R5-2600相似,是DDR4-3200和2666内存的差距造成了它们测试成绩的差距。内存控制器效率与海光和AMD最接近的是龙芯,龙芯的内存控制器和CPU核心一样都是自主设计。因为高水平的内存控制器和高性能的CPU核心一样难以买到,所以兆芯和飞腾的内存控制器的效率都比较低,同样是DDR4-2666内存,它们的访问速率和海光的差距很大。
所有的stream测试项目,兆芯KX-U6780A和飞腾D2000的速率都比海光3250和龙芯3A5000要低。如果只看在使用“-O”作为基础编译参数时的内存复制效率,兆芯KX-U6780A和飞腾D2000在单通道和单线程时的内存访问性能甚至只有海光3250和龙芯3A5000的一半左右。兆芯KX-U6780A甚至在“双通道-多线程”时的内存访问速度也只有海光3250和龙芯3A5000的一半左右。

下图是在使用“-O3”参数之后,各CPU“双通道-多线程”时4种测试项目的内存访问速度。当使用“-O3”作为基础编译参数时,所有x86 CPU的内存复制的性能都有大幅度提升,但另外三项测试的速度没有明显变化。
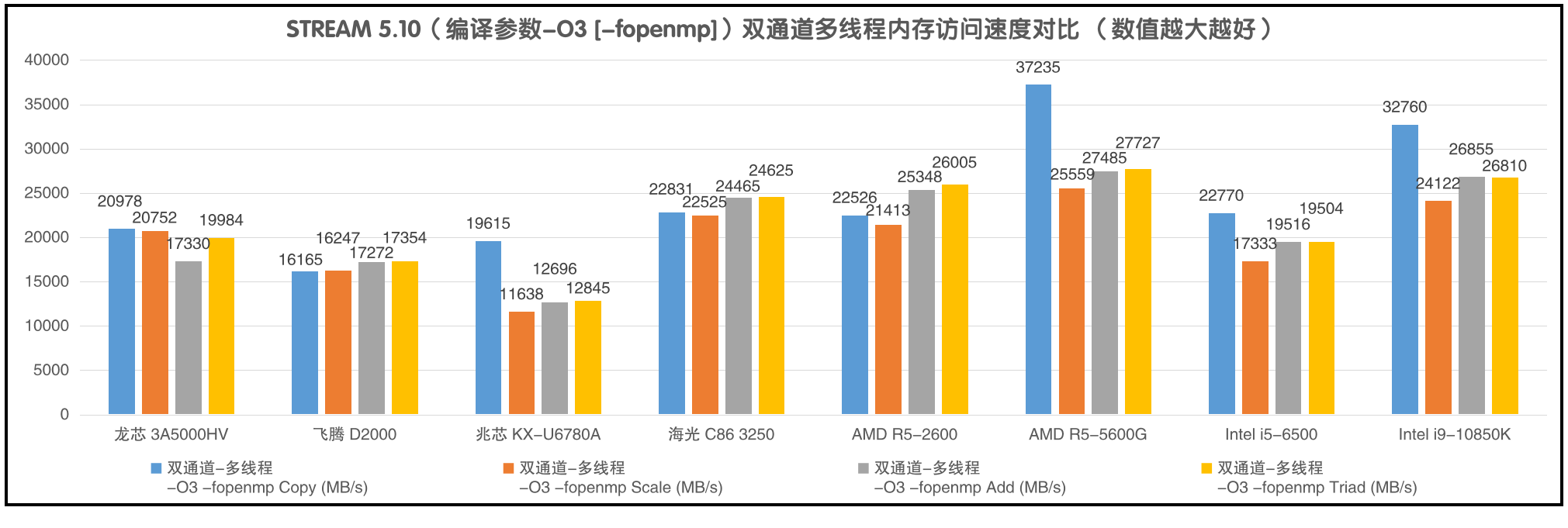
从海光3250、AMD R5-2600、AMD R5-5600G的测试情况来看,AMD Zen和Zen3核心各自配套的内存控制器差距还是比较明显的。龙芯自主设计的内存控制器也只是比兆芯和飞腾的更好,但与AMD及Intel还有相当大的差距。据介绍下一代龙芯6000系列已经补上了DDR4内存控制器的短板,达到了DDR4-3200内存的理论带宽,也就是说stream测试的内存访问速度应该和上表中AMD R5-5600G及Intel i9-10850k的测试结果近似。
UnixBench测试成绩
UnixBench不是CPU测试工具,它测试的是最小整机系统的综合性能。最小整机系统就是由CPU、主板、硬盘、内存、操作系统构成的可以启动的完整系统,如果要测试UnixBench Graphics,那么还可以算上显卡。我们此次不测试Graphics,因为GPU是一个很大的变量。
UnixBench主要是测试一台电脑处理日常事务的效率,包括文本处理、浮点函数、文件读写、进程创建、管道通信、脚本执行,这些都是应用软件和操作系统常用的功能。因为所有功能的执行都与CPU有关,所以它的测试成绩也与CPU性能有直接关系。但是操作系统如果对创建进程、管道通信等等功能进行优化,也能提高测试成绩,因此UnixBench是既测试CPU也测试操作系统,内存和硬盘性能也占了一定的比重。总体上看,UnixBench的测试成绩代表的是电脑执行日常任务的流畅程度。
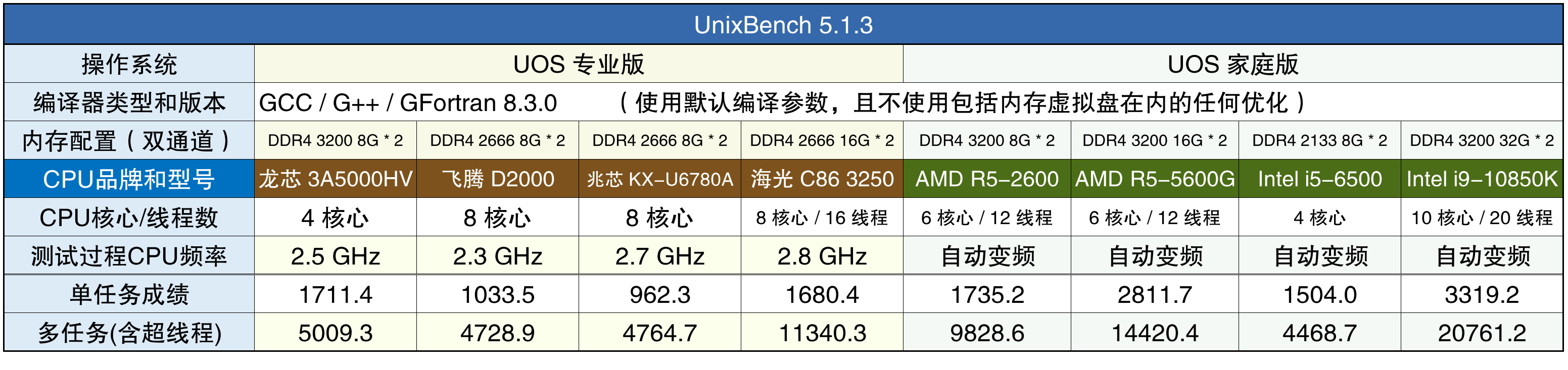
UnixBench的测试也分为单任务和多任务,不过单任务中有一项是多脚本并行测试,会分派到多个核心上同时运行,因此UnixBench的单任务不是纯粹的单核任务。UnixBench和SPEC CPU一样也有“作弊”优化的手段,但老夫偏不许它们使用。
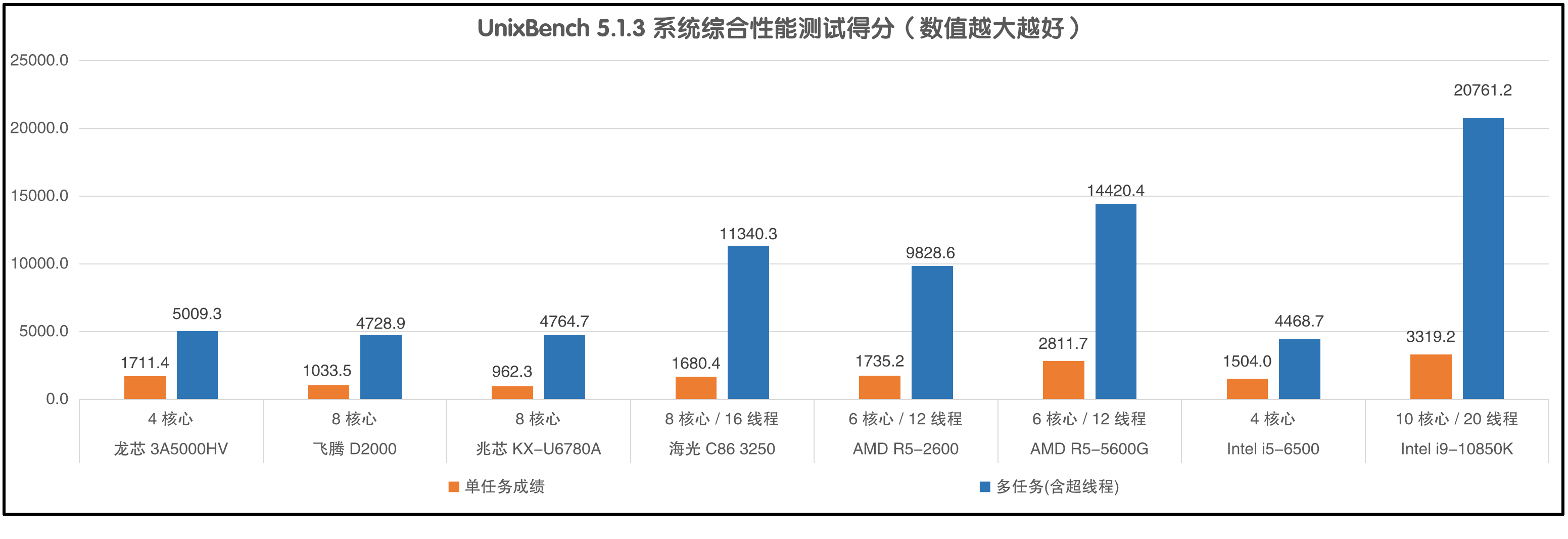
Intel i9-10850K无论是单任务还是多任务的成绩都一骑绝尘,紧随其后的是AMD 5600G,再之后就是海光3250和AMD R5-2600了。龙芯3A5000的单任务成绩和AMD R5-2600是同一档次,比海光3250和Intel i5-6500还高一些,但多任务成绩就只能和兆芯KX-U6780A、飞腾D2000、Intel i5-6500归为同一档了。不过龙芯3A5000和Intel i5-6500只有4个核心,兆芯KX-U6780A和飞腾D2000有8个核心,也不知道谁会更加尴尬。
其实兆芯KX-U6780A和飞腾D2000在UOS系统中的的测试成绩相对一年前已经提高了很多,因为最近一年UOS系统做了大量优化,带来的附加效果就是它们的UnixBench多任务测试成绩都提高了1000分左右,龙芯3A5000的UnixBench多任务测试成绩也提高了近500分。
为了验证成绩提升确实来自于UOS系统优化,我用Ubuntu 22测试了KX-U6780A的UnixBench成绩,单任务仅有678.1分,多任务也仅有3156.1分,而在UOS系统中的测试成绩分别是962.3和4764.7分,说明UOS系统的日常应用流畅程度远高于Ubuntu。只不过这些优化对SPEC CPU用处不大,各种纯计算的任务主要还是依赖CPU本身的性能。
总结
目前国产CPU的性能与主流产品还有明显的差距,因为CPU频率的差距,即使海光和龙芯CPU的单核性能也只有主流中高端CPU的一半左右,兆芯和飞腾则几乎没有对比的价值。
在当前,国产CPU中海光的性能最高,龙芯在与海光的核心数量相同时性能差距甚小,飞腾和兆芯的桌面产品只能用8核逼平龙芯4核,颇为无力。国产CPU中龙芯的成长能力最强,单核性能达到或超过R5-2600和i5-6500 的产品今年底或明年初就能供货,而IPC则能达到AMD Zen3和Intel酷睿12代的水准。
X86架构的软件生态最完备,ARM和LoongArch在Linux上的软件生态是半斤八两,龙芯的二进制翻译暂时还不能完全弥补与x86的生态差距。
国产CPU的性价比很低,但既然已经在讨论性价比了,那就说明国产CPU的性能已经可以用了,至少海光和龙芯是可以用了。
海光CPU是引进技术的代表,既有性能又有生态,只是海光未来提升性能可能和兆芯飞腾一样艰难;龙芯CPU是自主设计的代表,海光是龙芯即将跨过的最后一道门槛,今年过后龙芯CPU的性能在国产中必定一骑绝尘,软件生态也更趋完善。龙芯将能全力追赶Intel和AMD——超越它们是龙芯的执念。
本文图表中8款CPU的所有测试数据,均为老夫实测,若需查看SPEC CPU、UnixBench的原始测试报告,请移步下方截图中所示地址。