

1 引言
在我们的日常编程任务中,对于集合的制造和处理是必不可少的。当我们需要对于集合进行分组或查找的操作时,需要用迭代器对于集合进行操作,而当我们需要处理的数据量很大的时候,为了提高性能,就需要使用到并行处理,这样的处理方式是很复杂的。流可以帮助开发者节约宝贵的时间,让以上的事情变得轻松。
2 流简介
流到底是什么呢?简要的定义为“从支持数据处理操作的源生成的元素序列”,接下来对于这个定义进行简要分析。
2.1 支持数据处理操作
流的数据处理操作和数据库的可以声明式的指定分组或查找等功能支持类似,和函数式编程的思想一致,如filter、map、reduce、find、match、sort等操作,这些流操作可以串行执行,也可以并行执行。
2.2 源
流会使用一个提供数据的源,可以通过三种方式来创建对象流,一种是由集合对象创建流:
List list = Arrays.asList(111,222,333);
Stream stream = list.stream();一种是由数组创建流:
IntStream stream = Arrays.stream(new int(){111,222,333});一种是由静态方法Stream.of()创建流,底层还是Arrays.stream():
Stream stream = Stream.of(111, 222, 333);Stream stream = Stream.of(111, 222, 333);
从有序集合生成流时会保留原有的顺序。由列表生成的流,其元素顺序与列表一致。
还有两种特殊的流:
- 空流:Stream.empty()
- 无限流:Stream.genarate()
2.3 元素序列
流也可以和集合一样访问包含特定的元素类型的一组有序值,但是它们的主要目的不一样,集合的主要目的是在于存储和访问元素,流的主要目的在于表达计算。
3 流的思想
流式思想和生产中的流水线具有异曲同工之妙,很多流模型都会返回一个流,这些模型都只负责它所需要做的事情,并不需要格外的内存空间来存储处理的结果。这些流模型可以被链接起来形成一个大的流水线,我们在这个过程中不关注中间步骤的数据被如何处理,只需要使用整个流水线处理后的结果。接下来的代码可以体现这种思想,代码中以商品为例,我们要筛选出商品中体积大于200的前两个商品的名字。
首先是商品类的定义:
public class Goods {
private final String Name;
private final Integer Volume;
public Goods(String name, Integer volume) {
Name = name;
Volume = volume;
}
public String getName() {
return Name;
}
public Integer getVolume() {
return Volume;
}
}接下来是商品集合的定义:
List goods = Arrays.asList(new Goods("土豆",10),
new Goods("冰箱",900),new Goods("办公椅",300));接下来获取我们想要的结果:
List twofoods = goods.stream()//获取流
.filter(goods1 -> goods1.getVolume()>200)//筛选商品体积大于200的
.map(Goods::getName)//获取商品名称
.limit(2)//筛选头两个商品
.collect(Collectors.toList());//将结果保存在list中这样看来,通过流来处理我们的特定需求,是不是比使用集合的迭代要方便很多呢?
4 流处理的特性
- 不存储数据
- 不会改变数据源
- 只可被使用一次
这里我们使用一个测试类StreamCharacteristic来验证流处理的以上特性:
import org.springframework.util.Assert;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class StreamCharacteristic {
public void test1(){
List list = Arrays.asList(1,2,2,5,6,9);
list.stream().distinct();
System.out.println(list.size());
}
public void test2(){
List list = Arrays.asList("wms", "KA", "5.0");
Stream stream = list.stream();
stream.forEach(System.out::println);
stream.forEach(System.out::println);
}
}test1()中的结果为6,尽管我们对于list对象所生成的Stream流做了去重操作distinct(),但是不影响数据源list。
test2()中调用了两次 stream.forEach方法来打印每一个单词,第二次调用时,抛出了一个“java.lang.IllegalStateException”异常:“stream has already been operated upon or closed”。这说明流不存储数据,遍历完后这个流已经被消费掉了,而且流不可以重复使用。
5 流操作与流的使用
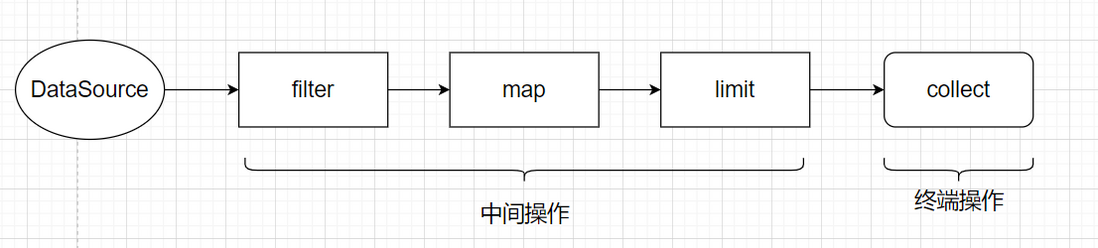
将所有的流操作连接起来可以组合成一个管道,管道有两类操作:中间操作和终端操作。
StreamAPI常用的中间操作有:filter,map,limit,sorted,distinct。
StreamAPI常用的终端操作有:forEach,count,collect。
在使用流的时候,主要需要三个要素:一个用来执行查询的数据源,用来形成一条流的流水线的中间操作链,一个能够执行流水线并能生成结果的终端操作。
下图展示了流的整个操作流程:
 []()
[]()
6 总结
- 流是从支持数据处理操作的源生成的元素序列
- 流的思想类似于生产中的流水线
- 流不存储数据,不改变数据源,只能被改变一次
- 流的操作主要分为中间操作和终端操作两大类
作者:京东物流 王辰玮
来源:京东云开发者社区 自猿其说Tech
