

问题来源于某客,如下图所示:
问题链接:https://www.nowcoder.com/feed/main/detail/b12f8ece42f6485d8e462ab872c4f8d8
答案解析
1.线程池有几种实现方式?
线程池的创建方法总共有 7 种,但总体来说可分为 2 类:
- 通过 ThreadPoolExecutor 创建的线程池;
- 通过 Executors 创建的线程池。
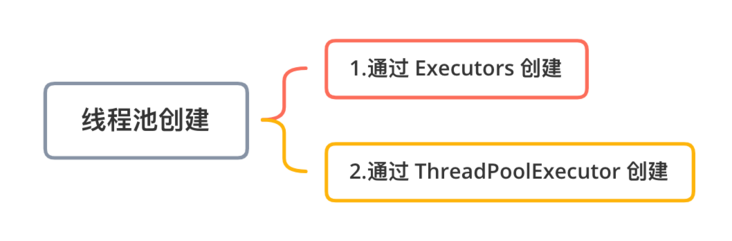
线程池的创建方式总共包含以下 7 种(其中 6 种是通过 Executors 创建的,1 种是通过 ThreadPoolExecutor 创建的):
- Executors.newFixedThreadPool:创建一个固定大小的线程池,可控制并发的线程数,超出的线程会在队列中等待;
- Executors.newCachedThreadPool:创建一个可缓存的线程池,若线程数超过处理所需,缓存一段时间后会回收,若线程数不够,则新建线程;
- Executors.newSingleThreadExecutor:创建单个线程数的线程池,它可以保证先进先出的执行顺序;
- Executors.newScheduledThreadPool:创建一个可以执行延迟任务的线程池;
- Executors.newSingleThreadScheduledExecutor:创建一个单线程的可以执行延迟任务的线程池;
- Executors.newWorkStealingPool:创建一个抢占式执行的线程池(任务执行顺序不确定)【JDK 1.8 添加】。
-
ThreadPoolExecutor:最原始的创建线程池的方式,它包含了 7 个参数可供设置,会更加可控。
2.线程池的参数含义?
问到线程池参数的含义,一定是问 ThreadPoolExecutor 参数的含义,这七个参数的含义分别是:
-
个参数代表的含义如下:
参数 1:corePoolSize
核心线程数,线程池中始终存活的线程数。
参数 2:maximumPoolSize
最大线程数,线程池中允许的最大线程数,当线程池的任务队列满了之后可以创建的最大线程数。
参数 3:keepAliveTime
最大线程数可以存活的时间,当线程中没有任务执行时,最大线程就会销毁一部分,最终保持核心线程数量的线程。
参数 4:unit:
单位是和参数 3 存活时间配合使用的,合在一起用于设定线程的存活时间 ,参数 keepAliveTime 的时间单位有以下 7 种可选:
- TimeUnit.DAYS:天
- TimeUnit.HOURS:小时
- TimeUnit.MINUTES:分
- TimeUnit.SECONDS:秒
- TimeUnit.MILLISECONDS:毫秒
- TimeUnit.MICROSECONDS:微妙
-
TimeUnit.NANOSECONDS:纳秒
参数 5:workQueue
一个阻塞队列,用来存储线程池等待执行的任务,均为线程安全,它包含以下 7 种类型:
- ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列;
- LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列;
- SynchronousQueue:一个不存储元素的阻塞队列,即直接提交给线程不保持它们;
- PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列;
- DelayQueue:一个使用优先级队列实现的无界阻塞队列,只有在延迟期满时才能从中提取元素;
- LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。与SynchronousQueue类似,还含有非阻塞方法;
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
较常用的是 LinkedBlockingQueue 和 Synchronous,线程池的排队策略与 BlockingQueue 有关。
参数 6:threadFactory
线程工厂,主要用来创建线程,默认为正常优先级、非守护线程。
参数 7:handler
拒绝策略,拒绝处理任务时的策略,系统提供了 4 种可选:
- AbortPolicy:拒绝并抛出异常。
- CallerRunsPolicy:使用当前调用的线程来执行此任务。
- DiscardOldestPolicy:抛弃队列头部(最旧)的一个任务,并执行当前任务。
- DiscardPolicy:忽略并抛弃当前任务。
默认策略为 AbortPolicy。
3.锁升级的过程?
锁升级的过程指的是 synchronized 锁升级的过程,synchronized 锁升级机制也叫做锁膨胀机制,此机制诞生于 JDK 6 中。
在 Java 6 及之前的版本中,synchronized 的实现主要依赖于操作系统的 mutex 锁(重量级锁),而在 Java 6 及之后的版本中,Java 对 synchronized 进行了升级,引入了锁升级的机制,可以更加高效地利用 CPU 的多级缓存,提升了多线程并发性能。
synchronized 锁升级的过程可以分为以下四个阶段:无锁状态、偏向锁、轻量级锁和重量级锁。其中,无锁状态和偏向锁状态都属于乐观锁,不需要进行锁升级,锁竞争较少,能够提高程序的性能。只有在锁竞争激烈的情况下,才会进行锁升级,将锁升级为轻量级锁状态。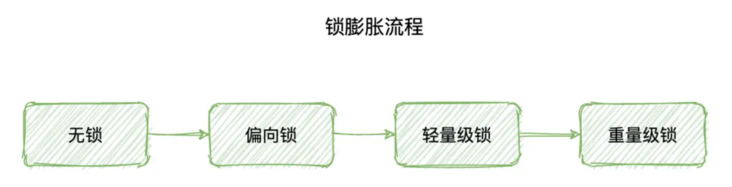
下面是 synchronized 锁升级的具体流程:
1.无锁状态
当一个线程访问一个同步块时,如果该同步块没有被其他线程占用,那么该线程就可以直接进入同步块,并且将同步块标记为偏向锁状态。这个过程不需要进行任何加锁操作,属于乐观锁状态。
2.偏向锁状态
在偏向锁状态下,同步块已经被一个线程占用,其他线程访问该同步块时,只需要判断该同步块是否被当前线程占用,如果是,则直接进入同步块。这个过程不需要进行任何加锁操作,仍然属于乐观锁状态。
3.轻量级锁状态
如果在偏向锁状态下,有多个线程竞争同一个同步块,那么该同步块就会升级为轻量级锁状态。此时,每个线程都会在自己的 CPU 缓存中保存该同步块的副本,并通过 CAS(Compare and Swap)操作来对同步块进行加锁和解锁。这个过程需要进行加锁操作,但相对于传统的 mutex 锁,轻量级锁的效率要高很多。
4.重量级锁状态
轻量级锁之后会通过自旋来获取锁,自旋执行一定次数之后还未成功获取到锁,此时就会升级为重量级锁,并且进入阻塞状态。
synchronized 锁升级的过程可以有效地减少锁竞争,提高多线程并发性。
4.i++ 如何保证线程安全?
保证 i++ 线程安全的手段是加锁,可以通过 synchronized 或 Lock 加锁来保证 i++ 的线程安全。
5.HashMap和ConcurrentHashMap有什么区别?
HashMap 和 ConcurrentHashMap 是 Map 接口的具体实现,ConcurrentHashMap 可以看作是 HashMap 的线程安全版本,它们的具体区别如下:
-
线程安全性:
- HashMap:HashMap 是非线程安全的。如果多个线程同时访问和修改 HashMap,没有适当的同步机制的话,可能会导致不一致的结果或者抛出 ConcurrentModificationException 异常。
- ConcurrentHashMap:ConcurrentHashMap 是线程安全的。多个线程可以同时读取和修改 ConcurrentHashMap,而不会导致数据不一致或者抛出异常。它使用了一种称为”分段锁”(Segmented Locking)的技术,将整个数据结构分成多个部分,每个部分都有一个独立的锁。这样,在多线程环境下,不同的线程可以同时操作不同的部分,从而提高并发性能。
-
性能:
- HashMap:HashMap 在单线程环境下通常具有更好的性能,因为它不需要额外的同步开销。
- ConcurrentHashMap:ConcurrentHashMap 在高并发环境下具有更好的性能,因为它使用了分段锁技术,多个线程可以同时操作不同的部分,从而减少了竞争和阻塞。
-
Null 值和 Null 键:
- HashMap:HashMap 允许使用 null 作为值和键。
-
ConcurrentHashMap:ConcurrentHashMap 不允许使用 null 作为键,但允许使用 null 作为值。
6.@Autowired和@Resource区别?
@Autowired 和 @Resource 都是 Spring/Spring Boot 项目中,用来进行依赖注入的注解。它们都提供了将依赖对象注入到当前对象的功能,但二者却有以下不同:
- 来源不同:@Autowired 和 @Resource 来自不同的“父类”,其中 @Autowired 是 Spring 定义的注解,而 @Resource 是 Java 定义的注解,它来自于 JSR-250(Java 250 规范提案);
- 依赖查找的顺序不同:@Autowired 是先根据类型(byType)查找,如果存在多个 Bean 再根据名称(byName)进行查找;而 @Resource 是先根据名称查找,如果(根据名称)查找不到,再根据类型进行查找;
- 支持的参数不同:@Autowired 只支持设置一个 required 的参数,而 @Resource 支持更多的参数设置,@Resource 支持 7 个参数的设置;
- 依赖注入的支持不同:@Autowired 支持属性注入、构造方法注入和 Setter 注入,而 @Resource 只支持属性注入和 Setter 注入;
-
编译器 IDEA 的提示不同:当使用 IDEA 专业版注入 Mapper 对象时,使用 @Autowired 编译器会提示报错信息(虽然报错但不印象程序的执行);而 @Resource 则不会报错。
7.说说常用的设计模式
说到设计模式可以举一些常见的设计模式,以及这些设计模式的具体应用,比如以下这些:
- 工厂模式(Factory Pattern): 工厂模式是一种创建型设计模式,它提供了一种创建对象的方式,使得应用程序可以更加灵活和可维护。比如在 Spring 中,FactoryBean 就是一个工厂模式的实现,使用它的工厂模式就可以创建出来其他的 Bean 对象;
- 单例模式(Singleton Pattern):单例模式是一种创建型设计模式,它保证一个类只有一个实例,并提供了一个全局访问点。比如在 Spring 中,所以的 Bean 默认是单例的,这意味着每个 Bean 只会被创建一次,并且可以在整个应用程序中共享;
- 代理模式模式(Proxy Pattern): 代理模式是一种结构型设计模式,它允许开发人员在不修改原有代码的情况下,向应用程序中添加新的功能。比如在 Spring AOP(面向切面编程)就是使用代理模式的实现,它允许开发人员在方法调用前后执行一些自定义的操作,比如日志记录、性能监控等;
- 模板方法模式(Template Pattern):模板方法模式是最常用的设计模式之一,它是指定义一个操作算法的骨架,而将一些步骤的实现延迟到子类中去实现,使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。此模式是基于继承的思想实现代码复用的。比如在 MyBatis 中的典型代表 BaseExecutor,在 MyBatis 中 BaseExecutor 实现了大部分SQL 执行的逻辑;
- 观察者模式(Observer Pattern):定义了一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知并自动更新。比如事件驱动、消息传递等功能时,可以使用观察者模式,例如 Spring Event 事件机制;
- 适配器模式(Adapter Pattern):适配器模式是一种结构型设计模式,它允许开发人员将一个类的接口转换成另一个类的接口,以满足客户端的需求。在 Spring 中,适配器模式常用于将不同类型的对象转换成统一的接口,比如将 Servlet API 转换成 Spring MVC 的控制器接口。
8.Redis为什么这么快?
Redis 运行比较快的原因有以下几个:
- 内存存储:Redis 主要是将数据存储在内存中,而不是磁盘上。相比于传统的磁盘存储数据库系统,内存访问速度更快,因此可以实现更低的延迟和更高的吞吐量;
- 单线程模型:Redis 采用单线程模型来处理客户端的请求。这意味着不会发生多线程之间的锁竞争和上下文切换,避免了由于线程切换而导致的性能损耗。此外,单线程模型使得 Redis 的代码更加简单和可预测;
- 非阻塞I/O:Redis 使用非阻塞 I/O 模型来处理网络请求。它通过使用事件驱动的方式处理并发连接,充分利用了操作系统提供的异步 I/O 功能。这使得 Redis 能够高效地处理大量并发请求,而不会被阻塞;
- 高效的数据结构:Redis 提供了多种高效的数据结构,如字符串、哈希表、列表、集合和有序集合等。这些数据结构在内存中直接存储和操作数据,使得Redis能够以常数时间复杂度 (O(1))来执行许多常见的操作,如插入、删除和查找;
- 异步操作:Redis 支持异步操作,可以将一些耗时的操作(如持久化)放到后台进行,不会阻塞其他的操作;
- 轻量级:Redis 本身是一个非常轻量级的软件,它使用 C 语言编写,代码简洁高效。它没有复杂的依赖和额外的抽象层,因此可以更快地启动和运行。
9.索引的种类?如何优化?
MySQL 索引根据不同的维度可以分为不同类型,比如以下这些:
- 根据数据结构分类可分为:B+ tree 索引、Hash 索引、Full-Text 索引;
- 根据物理存储分类可分为:聚簇索引、二级索引(辅助索引、非聚簇索引);
- 根据字段特性分类可分为:主键索引、普通索引、唯一索引、前缀索引;
-
根据字段个数分类可分为:单列索引、联合索引(复合索引、组合索引)。
索引优化
索引优化可以从以下几个方面入手:
- 选择适当的索引类型:MySQL 提供了不同类型的索引,包括 B-tree、哈希、全文等。根据查询的特点和数据的特性,选择合适的索引类型。B-tree 索引是最常用的索引类型,适用于范围查询和排序操作;
- 选择合适的索引列:选择对查询频率高且选择性好的列作为索引列。选择性是指索引列中不重复值的比例,选择性越高,索引的效果越好。避免在索引中包含过多重复值或过长的列;
- 尽量使用聚簇索引:聚簇索引的叶子节点存储了具体的数据,不用在像非聚簇索引一样进行回表查询,所以在查询时,尽量选择聚簇索引;
- 避免过多的索引:索引会占用存储空间,并且在数据更新时需要维护索引,过多的索引会增加维护的开销。只创建必要的索引,避免创建过多的索引;
- 使用索引提示:在某些情况下,MySQL 的查询优化器可能选择了不理想的查询计划。可以使用索引提示(Index Hint)来指导优化器选择正确的索引;
- 定期监控和优化:持续监控数据库的性能指标,如查询执行时间、索引使用情况等。根据监控结果,对索引进行调整和优化,以保持数据库的高性能。
10.算法题:合并重叠区间
解题思路和实现代码参考:https://leetcode.cn/problems/merge-intervals/solution/he-bing…
小结
从上面的题可以看出来,团子的整体面试题是不难的,可以说社招的面试难度,现在是小于校招的面试难度的,这也可能和校招庞大的竞争者群体有关。所以如果是社招的哥们,也可以定期骑驴找马试试水,一是检验自己能力是否已经落后与用人市场;二是,万一有惊喜,拿到更好的 offer,也就开启了职场的新篇章。
本文已收录到我的面试小站 www.javacn.site,其中包含的内容有:Redis、JVM、并发、并发、MySQL、Spring、Spring MVC、Spring Boot、Spring Cloud、MyBatis、设计模式、消息队列等模块。
