

导读
大报文问题,在京东物流内较少出现,但每次出现往往是大事故,甚至导致上下游多个系统故障。大报文的背后,是不同商家业务体量不同,特别是B端业务的采购及销售出库单,一些头部商家对京东系统支持业务复杂度及容量能力的要求越来越高。因此我们有必要把这个问题重视起来,从组织上根本上解决。
1 认识大报文问题
大报文问题,是指不同的系统通过网络进行数据交互时payload size过大导致的系统可用性下降问题。
 []()
[]()
对于大报文的产生方,过大的报文在序列化时消耗更多内存和CPU,在传输时(JSF/MQ)可能超过中间件的大小限制导致传输失败;对于大报文的消费方,过大的报文在反序列化时会产生大对象,消耗更多的内存和CPU,容易触发FullGC甚至OOM,而在处理过程中要遍历的内容更多,造成响应变慢,如果涉及数据库操作容易产生大事务、慢SQL,这些容易触发超时,如果客户端有重试机制,会进一步加重大报文消费方负载,严重时导致服务集群整体不可用。
此外,由于大报文与小报文是在一个接口上完成的,使用相同的UMP key,它会导致监控失真,报警阈值无效。如果日志记录了原始报文,也可能磁盘打满和响应变慢。
在京东物流技术体系内,具体表现为:
| 大报文场景 | 后果 |
|---|---|
| MQ的producer发送了大的Message | 由于JMQ对消息大小的限制,导致producer发送失败:消息未送达 |
| MQ consumer反序列化Message并处理计算时产生大对象,频繁FullGC,CPU使用率飙升 | |
| JSF Consumer调用API时传入大入参值 | 由于JSF Server对payload大小限制,导致服务端将报文抛弃:无法送达 |
| JSF Provider响应变慢,产生大对象,频繁FullGC,CPU使用率飙升,甚至OOM;请求处理超时 | |
| JSF Provider返回值包含大对象 | 由于JSF Consumer对payload大小限制,导致consumer无法获取响应 |
| JSF Consumer产生大对象,频繁FullGC,CPU使用率飙升,甚至OOM |
📌 JMQ/JSF对payload大小的限制都属于防御性保护措施,目前的值是科学的,它们都已经足够大了。在紧急止血情况下可以调整配置参数来暂时提高payload大小限制,但长期看它会加重系统的风险,应该从设计入手避免超过payload大小限制。
1.1 背景知识
1.1.1 JMQ限制
根据JMQ的官方文档,单条消息大小:JMQ4不要超过4M,JMQ2不要超过2M。
具体原理是发送消息时在生产端做主动校验,如果消息大小超过阈值则抛出异常(代码实现与官方文档不一致):
class ClusterManager {
protected volatile int maxSize = 4194304; // 4MB
}
class MessageProducer implement Producer { // Producer接口的具体实现类
ClusterManager clusterManager;
// producer.send时做校验
int checkMessages(List messages) {
int size = 0;
for (Message message : messages) {
size += message.getSize() // 压缩后的大小
}
if (size > this.clusterManager.getMaxSize()) {
throw new IllegalArgumentException("the total bytes of message body must be less than " + this.clusterManager.getMaxSize());
}
}
}📌 经与JMQ团队确认,JMQ消息大小的限制,以代码实现为准(官方文档不准确):
 []()
[]()
1.1.2 JSF限制
根据JSF官方文档,JSF可以在server和consumer端分别设置payload size,默认都是8MB。
 []()
[]()
📌 需要注意,触发provider报文长度限制时,JSF consumer(老版本)并不会立即失败,而是依靠客户端超时后才返回(感觉是JSF的缺陷)。具体原因:JSF依靠底层netty来实现报文长度限制,当provider从请求报文头里取得本次请求payload size发现超过限定值时,不会继续读取报文体,而是抛出netty定义的TooLongFrameException,而该异常的处理依赖netty的ChannelHandler.exceptionCaught方法,JSF里没有对TooLongFrameException做处理(吃掉异常),provider端不给consumer任何响应(请求被扔进黑洞),因此造成consumer一直等待响应直到超时,而这可能把consumer端的业务线程池拖死。
class LengthFieldBasedFrameDecoder { // 基于netty io.netty.handler.codec.LengthFieldBasedFrameDecoder的改动
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
// 从JSF协议的报文头里获取本次请求的payload size,此时还没有读取8MB的body
long frameLength = getUnadjustedFrameLength(in, actualLengthFieldOffset, lengthFieldLength, byteOrder);
if (frameLength > maxFrameLength) { // maxFrameLength即8MB限制
throw new TooLongFrameException();
}
}
}
class ServerChannelHandler implements ChannelHandler {
public void exceptionCaught(ChannelHandlerContext ctx, final Throwable cause) {
if (cause instanceof IOException) {
// ...
} else if (cause instanceof RpcException) {
// 这里可以看到遇到这种异常,JSF是如何给consumer端响应的
ResponseMessage responseMessage = new ResponseMessage(); // 给consumer的响应
responseMessage.getMsgHeader().setMsgType(Constants.RESPONSE_MSG);
String causeMsg = cause.getMessage();
String channelInfo = BaseServerHandler.getKey(ctx.channel());
String causeMsg2 = "Remote Error Channel:" + channelInfo + " cause: " + causeMsg;
((RpcException) cause).setErrorMsg(causeMsg2);
responseMessage.setException(cause); // 异常传递给consumer
// socket.write回consumer
ChannelFuture channelFuture = ctx.writeAndFlush(responseMessage);
} else {
// TooLongFrameException会走到这里,它的继承关系如下:
// TooLongFrameException -> DecoderException -> CodecException -> RuntimeException
// 异常被吃掉了,不给consumer响应
logger.warn("catch " + cause.getClass().getName() + " at {} : {}",
NetUtils.channelToString(channel.remoteAddress(), channel.localAddress()),
cause.getMessage());
}
}
}📌 经与JSF团队确认,consumer端或provider端发出的消息过大(超过playload)时consumer端得不到正确的异常响应只提示请求超时的问题,已经在1.7.5版本修复:需要provider端升级。升级后,如果consumer端发送的消息过大,provider会立即响应RpcException。
 []()
[]()
此外,在JSF旧版本下,consumer使用了默认的5秒超时,但consumer抛出超时异常总用时是48秒,这是为什么?
 []()
[]()
这是因为consumer配置的timeout不包括序列化时间,这48秒是把8MB的报文序列化的耗时:
class JSFClientTransport {
// consumer同步调用provider
ResponseMessage send(BaseMessage msg, int timeout) {
MsgFuture future = doSendAsyn(msg, timeout);
return future.get(timeout, TimeUnit.MILLISECONDS);
}
MsgFuture doSendAsyn(final BaseMessage msg, int timeout) {
final MsgFuture resultFuture = new MsgFuture(getChannel(), msg.getMsgHeader(), timeout);
Protocol protocol = ProtocolFactory.getProtocol(msg.getProtocolType(), msg.getMsgHeader().getCodecType());
byteBuf = protocol.encode(request, byteBuf); // 发送报文前的序列化
RequestMessage request = (RequestMessage) msg;
request.setMsg(byteBuf);
channel.writeAndFlush(request, channel.voidPromise()); // socket.write,异步IO
resultFuture.setSentTime(JSFContext.systemClock.now());
}
}
class MsgFuture implements java.util.concurrent.Future {
final long genTime = JSFContext.systemClock.now(); // new的时候就赋值了
volatile long sentTime;
// 抛出超时异常逻辑
ClientTimeoutException clientTimeoutException() {
Date now = new Date();
String errorMsg = "[JSF-22110]Waiting provider return response timeout . Start time: " + DateUtils.dateToMillisStr(new Date(genTime))
+ ", End time: " + DateUtils.dateToMillisStr(now)
+ ", Client elapsed: " + (sentTime - genTime) // 它包括:序列化时间,由于异步IO因此不包括socket.write时间
+ "ms, Server elapsed: " + (now.getTime() - sentTime);
return new ClientTimeoutException(errorMsg);
}
}1.1.3 物流网关限制
物流网关在nginx层通过client_max_body_size做了5MB限制。这意味着,JSF限制了8MB,但通过物流网关对外开放成HTTP JSON API时,调用者实际的限制是5MB。
1.1.4 MySQL限制
max_allowed_packet,net_buffer_length等参数在底层控制TCP层的报文长度,京东物流体系内该值足够大,研发不必关注。
研发需要关注的是字段长度的定义,主要是varchar的长度。MySQL通过sql_mode参数控制字段超过长度后的行为是字段截断还是中断事务。对于京东物流业务执行链路比较长的场景来讲,同一个字段可能多处保存,例如订单行里的skuName,就会在OFC/WMS等系统保存,sku_name varchar长度的不一致,特殊场景下可能造成上下游交互出现问题。
1.1.5 其他限制
DUCC value 的长度默认限制为 4W 字符。
UMP Key的限制128。
JMQ的businessId长度限制100,Producer在发送是默认超时2秒,Producer发送失败默认重试2次。
JMQ消费者抛出异常会导致重试(进入retry-db),首次重试10分钟,如果重试还不成功会越来越慢推送直至过期。过期时间:JMQ2为3天,JMQ4为30天。
JSF如果不配置consumer timeout,则使用默认值:5秒。
Zookeeper ZNode限制长度 1MB。虽然可以通过jute.maxbuffer这个Java系统属性修改,但强烈不建议。
原则上,所有依赖的中间件都要确认其限制约束,提升健壮性,避免边界条件被触发而产生出乎意料的错误。
1.2 产生原因
1.2.1 集合类字段无约束
导致京东物流线上事故的大报文问题中,绝大部分都属于该类问题。而这又可以细分为两种场景:
interface JsfAPI {
// 场景1:批量接口,对批量的大小无限制
void foo(List requests);
}
class Request {
// 场景2:对一个类内部的集合类字段大小无限制
// JMQ产生大报文,绝大部分属于该场景
List items;
}当数据量增大时,报文也会增大,造成几MB到几十MB的报文传输,系统为了处理这样大数据量的报文,必然会产生大对象,并且这种对象会一直处于内存中,在数据保存处理时,会造成内存不能释放,可能触发频繁FullGC,CPU使用率飙升。同时,处理集合数据,往往会有数据遍历过程,如果无并发则时间复杂度是O(N),大的数据集必然带来更慢的响应速度,而consumer端不会根据payload大小动态设置超时时间,它可能导致consumer端超时,超时可能带来多次重试,进而加重服务端压力。
例如:无印良品订单sku品类过多,比如一个出库单包含2万个sku的极端情况。
例如:WMS出库发货后向ECLP回传信息,之前都是通过一个JMQ Topic: eclp_delivery进行回传,一份消息包含了(订单主档,箱明细,包裹明细)3部分信息。后来中石化场景下,一个订单的包裹明细数量非常多,导致ECLP处理报文时CPU飙升,同时MQ Listener与对外服务共享CPU,导致接单功能可用率降低。后来,从源头入手把一个订单按照明细进行分页式拆分(之前是整单回传,之后是按明细分页回传),同时把eclp_delivery这一个topic拆分成3个topic:(订单,箱明细,包裹明细),解决了大报文问题。
1.2.2 大字段无约束
它指的是某一个字段(不是集合大小),由于没加长度限制,在特定场景下传入了远超预期大小的数据而造成的故障。
ECLP的商品主数据有个下发商品的接口,有个字段skuName,接口没有对该字段长度进行约束。系统一直平稳运行,直到有个商家下发了某一个商品,它的skuName达到了10KB(事后发现,商家是把该商品详情页的整个HTML通过skuName传过来了),插入数据库时超过了字段长度限制varchar(200),导致插入失败,但由于没有考虑到这种场景,返回了误导的错误提示。展开来看,如果ECLP为skuName定义了MySQL Text类型字段,还会有更严重问题:ECLP接收下商品,下发给WMS,但WMS里的skuName是varchar(200),这个问题就只能人工处理了,甚至与商家沟通。
WMS6.0为了考虑多场景全满足,在出库单预留了扩展字段,在接单时技术BP自行决定写入哪个扩展字段。京喜BP下发出库单时在订单明细维度传入了handOverSlip(交接单,其实是团单信息,里面有多层明细嵌套),该字段其实是一个大JSON,单个长度10KB上下,接单环节没问题。但组建集合单会把多个出库单组建成一个集合单,共产生3000多个明细,仅handOverSlip就占30MB,造成组建集合单后下发(JSF调用)拣货时遇到了JSF 8MB限制问题,下发失败,单据卡在那里,现场生产无法继续。
WMS6.0的用户中心系统,为其他系统提供了发送咚咚通知的服务,具体实现是调用集团的咚咚发送接口:xxx生产系统 -> 用户中心 -> 咚咚系统。链路上每一个环节都未对通知内容content字段长度做限制。一次xxx生产系统调用用户中心传入了超8MB的content字段,触发了咚咚系统的JSF底层的报文限制,最终在用户中心产生了ClientTimeoutException,它导致用户中心的JSF业务线程池打满;而由于用户中心为所有业务生产系统服务,现场操作会依赖它,进而导致生产卡顿,现场多环节无法正常生产。
Amazon FBA的SP-API(Sell Partner API),对可能出现风险的字段都做了长度限制,例如:
String displayableOrderComment; // maxLength: 1000
String sellerSku; // maxLength: 50
String giftMessage; // maxLength: 512
String displayableComment; // maxLength: 2501.2.3 查询接口返回大量数据
ECLP主数据有个接口:导出所有warehouse list,调用方很多,访问频率不高,每次响应长度3MB。该接口在线上出现过多次事故(2019年)。这个接口显然是不该存在的,但把它下线需要推动所有的调用方改动,这个周期很长阻力也很大。
最开始,直接查数据库,出现事故后加入JimDB,再次出现事故后配置了JimDB的local cache,后又加入JSF限流等措施。
出现故障时,ECLP CPU飙升,导致服务超时,京东零售调用方配置的超时设置很短,这导致越来越多的请求打过来,加重了ECLP负担。
1.2.4 导出问题
这个问题与【1.2.3 查询接口返回大量数据】看上去类似,但有很大不同:一个同步调用,返回的数据量相对少,另一个异步执行,返回数据量巨大。
WMS6.0的报表都有导出的需求,例如导出最近3个月的明细数据。贴近商家的OFC(如ECLP),也有类似需求,商家要求导出明细数据。系统执行过程大致是:根据用户指定的条件异步执行SQL,把数据库返回的数据集写入Excel,并存放到blob storage(指定TTL),用户在规定时间(TTL)内根据storage key去blob storage下载,完成整个导出过程。
这里的关键问题是如何查询数据库,而数据库作为共享资源往往是整个系统的瓶颈(增加复本数量意味着成本上升),它变慢会拖垮整个系统。如何查询数据库,有8个可选项:
 []()
[]()
导出问题的本质,是大范围table scan,很难设计精细的复合索引。WMS6.0最初使用的是方案1,它会产生深分页limit offset问题:越往后的页面越慢,对数据库的压力越大。举例:要导出100万行记录,每页1万,那么到50万记录时,每次分页查询相当于数据库要扫描50万+行记录后抛弃绝大部分并返回1万行,这还要继续执行50次,此外分页组件还要额外执行count语句以计算总行数。
如果每页是1千呢?因此,数据库的压力被放大了,可以简单理解为“全表扫描”了【50 + 100(count计算)=150】次,远不如不分页(不分页还要解决OOM问题)。目前,WMS6.0改用了方案8,根本上解决了数据库慢查询问题。思路是不再盲目静态分页,而是根据时间条件切分成多个SQL,分别查询,保证每个SQL返回数据量不大从而避免慢SQL。例如,某个仓要导出最近3个月的出库单数据,那么把这1个date range拆分(explode)成N个date range,分别执行:
condition = DateRange(from = "2022-01-01 00:00:00", to = "2022-04-01 00:00:00") // 用户指定的时间范围:3个月
// sql = select * from ob_shipment_order where xxx and update_time between condition.from and condition.to
List chunks = explode(condition)
for (DateRange chunk : chunks) {
// 该chunk的时间范围已经变成了1天,甚至是1小时,具体值是根据SQL执行计划估算得来的:数据量越大则拆分越细
sql = select * from ob_shipment_order where xxx and update_time between chunk.from and chunk.to
mysql.query(sql)
}1.2.5 payload约束不一致产生的问题
链路上经过不同的系统,不同系统对payload size的约束不同,也可能产生问题,因为决定是否可以正常处理的是最小的那个,但链路长时相关方可能不知道,在异步场景下这个问题尤为明显。
例如,aws的API Gateway与Lambda对payload size有不同的约束,最终用户必须知道限制最严格的那一个环节。
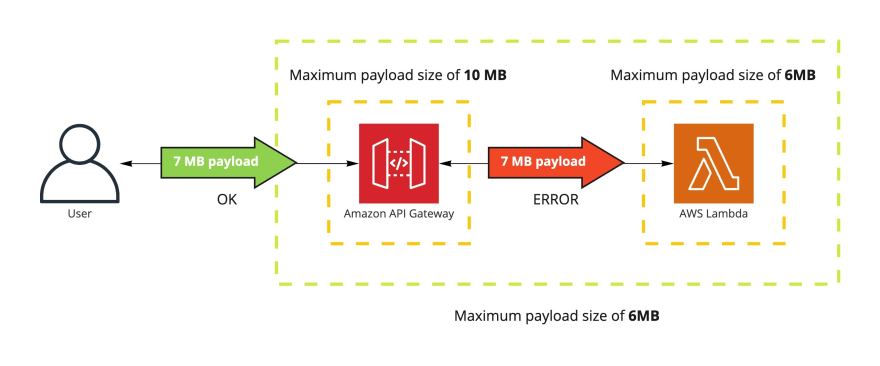 []()
[]()
对于京东物流,JSF与JMQ的限制不同,理论上可能产生这样的问题:JSF调用者发送8MB的请求,JSF提供者处理时采用同步转异步机制,异步把该请求8MB发送MQ,它会导致MQ发送永远无法成功,而JSF的调用方却浑然不觉。
如果通过物流网关对外开放,网关nginx限制是5MB,而JSF是8MB,设计上没问题(fail fast),但可能造成服务方承诺与调用者感知端到端的不一致。
JSF对provider(jsf:server)和consumer可以分别设置不同的报文大小限制,理论上也可能出现问题,但在京东物流尚未出现,可不必关注。
1.2.6 其他非入口场景
它发生在系统执行过程内部。典型场景是DAO层查询数据库返回大结果集,Redis大key问题等。这要根据具体中间件机制来识别,例如,MyBatis支持插件来识别DAO查询出大结果集:
public class ListResultInterceptor implements org.apache.ibatis.plugin.Interceptor {
private static final int RESULTSET_SIZE_THRESHOLD = 10000;
@Override
public Object intercept(Invocation invocation) throws Throwable {
Object result = invocation.proceed();
if (result != null && result instanceof List) {
int resultSetSize = ((List) result).size();
if (resultSetSize > RESULTSET_SIZE_THRESHOLD) {
// 报警
}
}
return result;
}
}2 设计原则
2.1 主动显式强约束
即,主动防御式自我保护,而不是依靠使用者的“自觉”:外部用户不可信赖。
对于JSF,可以通过JSR303向API Consumer显式传递约束,并且该约束可以通过框架对业务代码无侵入地自动执行。对于MQ,由于生产者与消费者解耦,无法直接传递约束,只能靠主动监控、人工协调。
它的前提条件,是研发有能力去主动识别出大报文风险。
2.2 Fail Fast
如果有前端,那么前端加约束,避免大报文传递给后端。
对于后端,链式的上下游关系中,上游要把好关。
这个原则并不是说下游不用关心大报文问题,恰恰相反,链路的每个环节都要关心,但Fail Fast可以降低整体的不必要的损耗成本,也可以缓解某个环节保护机制缺失带来的人工介入和修数成本。
2.3 上下游对齐隐式约束
同一个业务字段在上下游传递时,字段长度约束要一致,否则可能会出现上游成功落库下游无法落库的情况。
2.4 大报文产生方负责拆分
解决大报文的根本思路是拆分报文:大 -> 小。
对应MQ来讲,应该是Producer负责拆分大报文为小报文。
对于JSF来讲,有两种情况:
- consumer产生的大报文:应该provider加约束,强迫consumer端分页拆分请求。参考AJAX机制
典型场景:拣货下架调用库存预占接口,一次性传入1万个sku
- provider产生的大报文:应该变成分页返回结果
典型场景:一次性返回所有warehouse列表
 []()
[]()
 []()
[]()
📌 需要注意的是,拆分报文,会增加生产方和消费方的复杂度,尤其是消费方:幂等,集齐,(并发和异步调用时产生的)乱序,业务的原子性保证等。例如,一个出库单明细行过多时,整单预占库存(大报文) -> 按订单明细分页预占(小报文)。
拣货下架按明细维度分页调用库存预占接口场景下,如果订单不允许缺量:整单预占时,该订单预占库存的原子性(要么全成功预占,要么一个sku都不预占)是由库存系统(provider)保证的;而在按订单明细维度分页预占时,原子性需要在拣货系统(consumer)保证,即如果后面页码的预占失败则需要把前面页码的预占释放。这增加consumer端复杂度,但为了系统的性能和可用性,这是值得的。当然,也有另外一个可选方案,仍旧让库存保证原子性,但库存接口需要增加类似(currentPage, totalPages)的参数,那样就是库存更复杂了。无论如何,都增加了整体复杂度。
3 具体办法
3.1 报文分页
适用场景:MQ,以及JSF返回大报文响应。
为了保持报文的完整性,也便于消费方实现幂等、集齐等逻辑,需要在报文里额外增加分页信息:currentPage/totalPages。
class Payload {
List items;
int currentPage, totalPages;
}
void sendPayload(Payload payload) {
int currentPage = 1;
int totalPages = payload.getItems().size() / batchSize;
Lists.partition(payload.getItems, batchSize).forEach(subItems -> {
Payload subPayload = new Payload(subItems)
subPayload.setPageInfo(currentPage, totalPages)
producer.send(subPayload)
currentPage++;
});
}📌 在极端复杂场景下,也可以考虑分拆topic,但不推荐,因为它可能额外引入乱序问题。
📌 MQ报文编解码除了目前的JSON外,也可以考虑Protobuf等更高效格式。例如京东零售订单快照orderver就由xml升级到了PB。
3.2 报文转存
适用场景:MQ/JSF。
这种方案,也被称为Claim Check Pattern。
把大的明细List,按照固定batch size转存到JFS/OSS/JimKV/S3等外部blob storage,在报文里存放指针(blob地址)列表。
class BigPayload {
List items;
}
class SmallPayload {
List itemBlobKeys;
}
void sendPayload(BigPayload bigPayload) {
SmallPayload smallPayload = new SmallPayload();
Lists.partition(bigPayload.getItems(), batchSize).forEach(subItems -> {
List itemBlobKeys = blogStore.putObjects(subItems)
smallPayload.addItemBlobKeys(itemBlobKeys);
});
producer.send(JSON.encode(smallPayload);
}目前上游系统(eclp、序列号、OMC等)、DTC、下游系统(各版本WMS)的信息传递使用了该办法,共用一个JFS集群。
📌 Side effects:1)引入额外依赖,而且消费方被迫引入依赖 2)需要Blob存储的TTL机制或定期清理,否则加大存储成本 3)为消费方带来了不确定性,从blob拿回的数据可能超大,在反序列化和处理过程中有OOM/FullGC等风险(虽然一些json库提供了底层的基于词法token的Streaming Parsing API,但如果要读取全部内容仍然耗费大量内存)
3.3 报文截断
适用场景:大字段。
在确定用户体验可以接受的情况下,上层进行字段内容截断(truncate)。及早截断,不要依赖下层数据库的截断机制。
3.4 分页调用
适用场景:JSF。
两种场景:一种是批量接口,即入参是集合,另一种是入参对象里有集合字段。
class FooRequest {
@javax.validation.constraints.Size(min = 1, max = 200)
private List barItems;
}
interface JsfAPI {
// 场景1:批量接口
void foo(@javax.validation.constraints.Size(min = 1, max = 200) List requests)
// 场景2:请求对象里有集合字段
void bar(FooRequest request);
}对于JSF Consumer,可以通过JSF异步调用,它相当于redis pipeline模式,也可以通过客户端线程池并发调用方式实现分页调用,二者耗时相同,推荐使用前者:1)代码实现简单 2)节省了额外线程池成本。
 []()
[]()
 []()
[]()
int maxJsfRetries = 3; // JSF async下的自动重试只能应用层自己做了
int retried = 0;
do {
List>> futures = new LinkedList();
Lists.partition(voList, batchSize).forEach(subVoList -> {
ObLocatingOrderDto dto = mapper.INSTANCE.toDTO(subVoList);
locatingAppService.outboundOrderLocate(dto); // async JSF call
ResponseFuture> future = RpcContext.getContext().getFuture();
futures.add(future);
});
for (ResponseFuture> future : futures) {
try {
Result result = future.get();
} catch (RpcException jsfException) {
retried++;
} catch (Throwable e) {
// 额外的业务逻辑:与JSF并发同步调用相同的处理逻辑
}
}
} while (retried 📌 JSF异步调用时,jsf:consumer配置的retries无效,这是因为异步发送后如果出现网络超时,只能由业务代码通过future.get()才能拿到结果,JSF底层没有机会进行自动重试。而同步调用时,JSF底层可以判断出超时,它有机会根据配置进行自动重试。更多细节可以查看JSF的FailoverClient.doSendMsg方法。
3.5 MQ替代JSF
适用场景:单向通知类请求,相当于AsyncAPI。
大的报文往往意味着更长的处理时长,JSF同步调用下consumer必须同步等待provider端的返回,这会同时占用consumer和provider双方的线程池资源,极端情况下可能导致双方线程池用尽。JSF下可能耗尽线程池,进而拖死被强依赖的上游,产生雪崩效应;而MQ下,只会消费积压。
异步交互,使得上游对下游响应时间的依赖转换为吞吐率的依赖。JMQ实现了消费者和生产者在时间和空间上的解耦,消息的消费者可以承受更大范围的处理速度范围。
3.6 总结
 []()
[]()
4 最佳实践
4.1 单个接口与批量接口分离
根据sku编号查询商品资料,往往伴随着多个sku一起查询的需求,如何设计接口?
有的这样:
interface JsfAPI {
Result getSkuInfo(String sku);
Result> listSkuInfo(List skus);
}由于批量接口在技术上已经满足了单个查询的功能,有的团队干脆去掉了单个查询接口,造成使用者查询单个sku时:
Result result = jsfAPI.listSkuInfo(Lists.newArrayList("EMG1800752592"));应该这样:
interface JsfAPI {
Result getSkuInfo(String sku);
}
interface JsfBulkAPI {
Result> listSkuInfo(List skus);
}4.2 线程池隔离
JsfAPI与JsfBulkAPI把批量与单一接口进行分离后,可以分配到不同的线程池,尽可能互不干扰,这同理于Bulkhead Pattern。
| 单一接口 | 批量接口 |
|---|---|
| 处理关键业务,SLA要求更高 | 风险高,性能差 |
JSF可以通过jsf:server定义线程池,并为jsf:provider分配不同的server。
4.3 大报文与小报文分离
如果大报文实在无法拆分(例如,上游团队不配合),为了降低极端请求对绝大部分正常请求的影响,可以采用大小报文分离的办法。
对于JMQ,为了防止某一个大报文的消费长耗时或异常导致小报文的消费积压,可以把大报文转发到“慢队列”进行消费。
此外,也要考虑如何缓解UMP监控失真问题。
4.4 JMQ设置合理的批量大小
 []()
[]()
该值决定了MessageListener.onMessage入参messages的size。
interface MessageListener {
void onMessage(List messages) throws Exception;
}JMQ Consumer的ACK是以批为单位的,例如设置为10,则10条消息里任意一条产生异常都会导致10条全部重新消费。大报文场景下,如果发现问题,可以把该值调整为1,避免大小报文相互影响。
大批量消费主要有两个好处:1)压缩效果好(JMQ在发现报文超过100B时就进行压缩),TCP I/O性能高 2)降低获取消息的等待耗时,因为它相当于prefetch(具体原理是LinkedBlockingDeque的capacity,如果拉取的消息数超过它,则IO阻塞以防止拉取新消息)。同时它也有两大负面效应:1)ACK以批为单位,一个错误导致整批错误,整批重试 2)消息大小限制取决于整批所有消息大小,可能触发大报文问题。
 []()
[]()
对于京东物流绝大部分业务系统来讲,这点提升与繁重的业务处理来比不值一提,例如:I/O节省了5ms,但单个消息处理需要200ms(因为要通过接口查询,处理,然后写库),反倒是side effect成为主要矛盾。因此,绝大部分场景下该值应该设置为1。如果业务逻辑类似于集齐:把N个消息拿下来,本地缓冲暂不处理,等满足条件了再merge并一次性处理,那么可以调整批量大小为非1。
JMQ Producer提供了批量发送方法:
interface Producer {
void send(List messages) throws JMQException;
}我们的业务代码也在使用,例如:
/**
* 发送分播结果消息
*/
public void send(List checkResultDtos) {
List messageList = Lists.newArrayList();
for (CheckResultDto checkResultDto : checkResultDtos) {
String messageText = JmqMessage.createReportBody(checkResultDto.getUuid(), Lists.newArrayList(checkResultDto));
messageList.add(JmqMessage.create(topic, messageText, checkResultDto.getUuid(), checkResultDto.getWarehouseNo()));
}
producer.send(messageList);
}这里要注意,分批发送时,1)发送的超时(默认2s)作用于整批消息,而不是单个消息 2)消息大小限制(4MB)作用于整批消息之和,因此批包含的消息越多越可能失败。
4.5 避免大日志
尤其是AOP/Interceptor/Filter等统一处理的代码,因为对报文的打印往往需要先json序列化。
if (logger.isInfoEnabled()) {
log.info(JsonUtil.toJson(request); // CPU intensive and disk I/O intensive(虽然日志是顺序写)
}如果确实要记录,也可以考虑采样率方式记录大报文日志。
4.6 显式约束由严开始
开放API由于消费方多而且不确定性高,客观上造成了“只有一次做对的机会”。
List size limit, property max length limit等,要在开放API的第一时间公布出去。如果开始不约束,后期加约束可能遭遇大的阻力和沟通成本。此外,遵循从严开始的规律,为自己争取主动:你把限制放开,没人找你岔,反之则阻力大。例如:order.items max size limit由100变成200,你可以放心地做;但由200变成100,你要征得现有使用者的全部确认。
例如,Amazon FBA的SP-API对集合的条数限制绝大部分是50。
5 治理机制
5.1 识别大报文场景
无论采用哪种大报文问题解决办法,识别出大报文场景是前提。
技术上,可以通过JSF Filter分析报文长度,把尚未触发8MB但有潜在风险的自动识别出来。但JMQ无相关机制,业务系统要自行实现相关拦截机制。
5.1.1 JSF自动识别
provider端自动识别即可。
@Slf4j
public final class PayloadSizeFilter extends AbstractFilter {
private static final int PAYLOAD_SIZE_THRESHOLD = 4 PAYLOAD_SIZE_THRESHOLD) {
// 这里使用最简单的日志把潜在大报文暴露出来,各团队可以做更细化的机制
// 由于logbook限制只有error level日志才能配置"关键字报警",这里使用log.error
// 如果不想自动报警,只是人工巡检,可以log.warn
String methodName = requestMessage.getMethodName();
String className = requestMessage.getClassName();
log.error("Suspected BIG payload: {}.{}, {}>{}", className, methodName, payloadSize, PAYLOAD_SIZE_THRESHOLD);
}
// 自动识别潜在的大报文场景:报文字节小,但仍会导致处理慢,例如 List orderNos,如果发来1万个单号?
// 这里只能识别出入参是List的场景,对于字段类型是List的场景无效
Invocation invocation = requestMessage.getInvocationBody();
Class[] argClasses = invocation.getArgClasses();
Object[] args = invocation.getArgs();
for (int i = 0; i BATCH_SIZE_THRESHOLD) {
log.error("Too BIG Collection argument: {}>{}", collection.size(), BATCH_SIZE_THRESHOLD);
}
}
}
return getNext().invoke(requestMessage);
}
}5.1.2 JMQ自动识别
在consumer端加自动识别,如果发现,协同producer方确认风险判断是否需要改造。
public interface BigPayloadTrait extends MessageListener {
int THRESHOLD_BIG_PAYLOAD = 2 messages) {
for (Message message : messages) {
if (message.getSize() > THRESHOLD_BIG_PAYLOAD) {
return true;
}
}
return false;
}
}5.2 有效的监控
人工识别会有遗漏场景,关注监控全局指标,尤其是分析一些跳点,可能补充发现大报文场景。
5.3 设计应急预案
有些大报文问题,可能暂时无法通过技术手段解决,例如,已经有商家接入的对外接口,开放时没有对List size限制,加限制后需要商家配合修改做客户端分页,而商家不配合。这时候,可以采用大促期降级,限流,加开关,加强监控,设计应急预案,为此接口提供独立的线程池来隔离正常请求等手段解决。
5.4 常态化的大报文捣乱演练
以第三方视角帮助识别出尚未识别的大报文场景,不要自己给自己捣乱。
5.5 团队执行
推进大报文治理工作时,为了便于项目追踪管理,可以采用如下流程。
 []()
[]()
5.5.1 新的API和MQ
这里也包括现有API/MQ上加字段场景。
设计和评审时,检查:
- 字段长度,在上下游上长度对齐
- JSF接口对List等集合类型加@Size显式约束和校验,对List性批量接口入参也加@Size
- MQ Producer确保不发出大报文
5.5.2 现有系统治理
为所有JSF和MQ加入大报文预先监控机制(具体可参考【5.1 识别大报文场景】,根据是否改得动做相应的治理动作。
作者:京东物流 高鹏
来源:京东云开发者社区 自猿其说Tech
