


文|王特 (花名:亦夏)
Email:yixia.wt@antgroup.com
蚂蚁集团数据中间件核心开发
本文4927 字 阅读 13 分钟
Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。Seata 为用户提供了 AT、TCC、SAGA、XA 等多种事务模式,帮助解决不同业务场景下的事务一致性问题。
本文主要介绍 Seata Saga 模式的使用以及最佳实践,围绕三个部分展开,第一部分是 Seata Saga 的简介、第二部分旨在快速介绍 Seata Saga 模式的使用方法并帮助大家入门,最后一部分将会给大家分享一些 Seata Saga 实践中的经验,帮助用户更快、更好得使用 Seata Saga 模式。
1 Seata Saga 简介
1.1 Saga 模式
Saga 模式是分布式事务的解决方案之一,理念起源于 1987 年 Hector & Kenneth 发表的 Sagas 论文。它将整个分布式事务流程拆分成多个阶段,每个阶段对应我们的子事务,子事务是本地事务执行的,执行完成就会真实提交。

它是一种基于失败的设计,如上图可以看到,每个活动或者子事务流程,一般都会有对应的补偿服务。如果分布式事务发生异常的话,在 Saga 模式中,就要进行所谓的“恢复”,恢复有两种方式,逆向补偿和正向重试。比如上面的分布式事务执行到 T3 失败,逆向补偿将会依次执行对应的 C3、C2、C1 操作,取消事务活动的“影响”。那正向补偿,它是一往无前的,T3 失败了,会进行不断的重试,然后继续按照流程执行 T4、T5 等。
根据 Saga 模式的设计,我们可以得到 Saga 事务模式的优缺点。
优点:
- 子事务 (或流程) ,提交是本地事务级别的,没有所谓的全局锁,在长事务流程下,避免了长时间的资源锁定;另外这种流水线的处理模型天然符合阶段式信号处理模型,能发掘出更高的性能和吞吐。
- 正向服务和补偿服务都是交给业务开发实现的,所以 Saga 模式和底层数据库协议是无关的。XA/AT 模式可能依赖特定的数据库类型和版本,比如 MySQL 是 5.0 之后才支持的 XA,那么低版本的 MySQL 就不能适用到 XA 模式。
缺点:
- 也是因为正向服务和补偿服务都由业务开发者实现,所以业务上是有开发成本的,侵入性相对 XA/AT 打一个注解的方式会高很多。
- 因为一阶段子事务活动提交是本地事务级别的,所以 Saga 模式不保证隔离性。提交之后就可能“影响”其他分布式事务、或者被其他分布式事务所“影响”。例如:其他分布式事务读取到了当前未完成分布式事务中子事务的更新,导致脏读;其他分布式事务更新了当前未完成分布式事务子事务更新过的字段,导致当前事物更新丢失;还有不可重复读的场景等。
所以 Saga 模式的使用也需要考虑这些问题带来的“影响”。一般 Saga 模式的使用场景有如下几个:
- 长事务流程,业务上难以接受长时间的资源锁定,Saga 的特性使得它在长事务流程上处理非常容易;
- 业务性质上,业务可以接受或者解决缺乏隔离性导致的“影响”。例如部分业务只要求最终一致性,对于隔离性要求没有那么严格,其实是可以落地 Saga 模式的;
- 分布式事务参与者包含其他机构或者三方的服务,数据资源服务不是我们自身维护,无法提供 TCC 模式要求的几个接口。
1.2 Seata Saga
接下来我们来看看 Seata Saga 的实现。Saga 主流的实现分为两种:编排式和协调式。Seata Saga 的实现方式是编排式,是基于状态机引擎实现的。 状态机执行的最小单位是节点:节点可以表示一个服务调用,对应 Saga 事务就是子事务活动或流程,也可以配置其补偿节点,通过链路的串联,编排出一个状态机调用流程。在 Seata 里,调用流程目前使用 JSON 描述,由状态机引擎驱动执行,当异常的时候,我们也可以选择补偿策略,由 Seata 协调者端触发事务补偿。
有没有感觉像是服务编排,区别于服务编排,Seata Saga 状态机是 Saga+服务编排,支持补偿服务,保证最终一致性。
我们来看看一个简单的状态机流程定义:
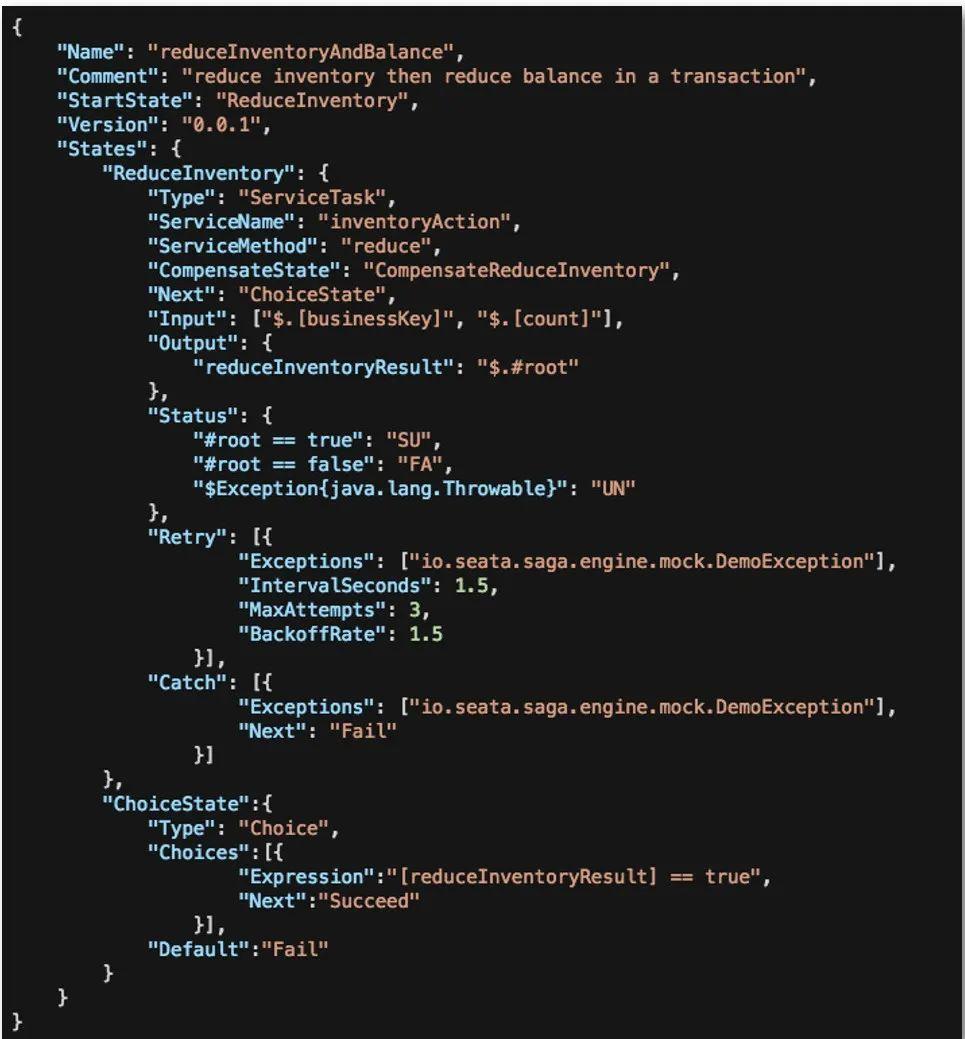
上方是一个 Name 为 reduceIncentoryAndBalance 的状态机描述,里面定了 ServiceTask 类型的服务调用节点以及对应的补偿节点 CompensateReduceInventory。
看看几个基本的属性:
- Type:节点类型,Seata Saga 支持多种类型的节点。例如 ServiceTask 是服务调用节点
- ServiceName/ServiceMethod:标识 ServiceTask 服务及对应方法
- Input/Output:定义输入输出参数,输入输出参数取值目前使用的是 SPEL 表达式
- Retry:控制重试流程
- Catch/Next:用于流程控制、衔接,串联整个状态机流程
更多类型和语法可以参考 Seata 官方文档[1],可以看到状态机 JSON 声明还是有些难度的,为了简化状态机 JSON 的编写,我们也提供了可视化的编排界面[2],如下所示,编排了一个较为复杂的流程。
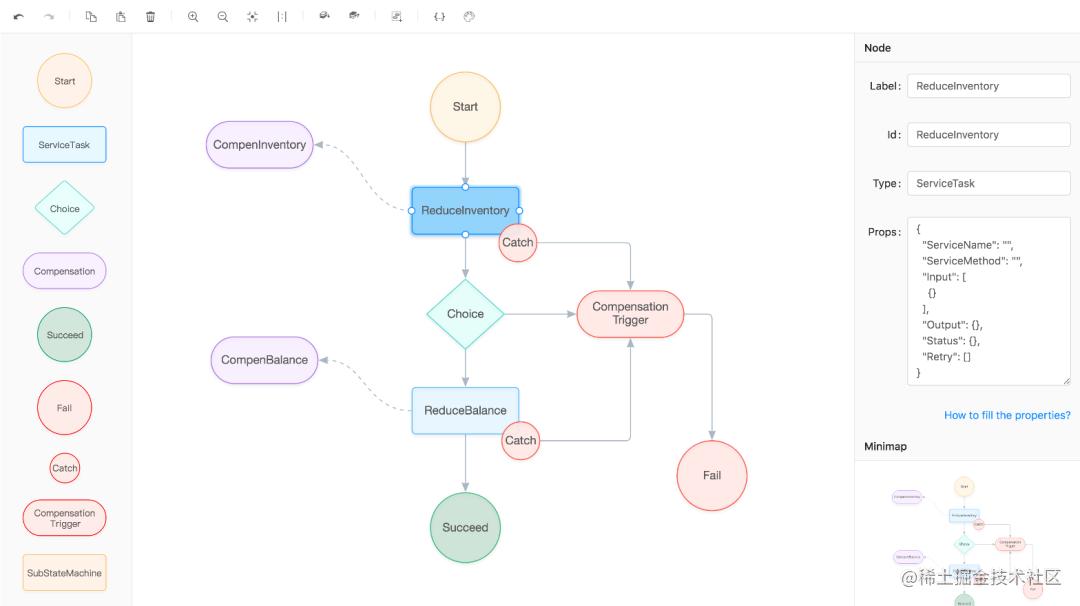
话不多说,我们进入下面的实践环节。
2 Seata Saga 使用入门
2.1 从 Seata 官网新人文档开始
Seata 分 TC、TM 和 RM 三个角色,TC (Server 端) 为单独服务端部署,TM 和 RM (Client 端) 由业务系统集成。
Server 端存储模式 (store.mode) 现有 file、db、redis 三种 (后续将引入 Raft、MongoDB) ,file 模式无需改动,直接启动即可。
部署 Seata Server
从新人文档,可以看出 Seata 还是传统的 CS 模型。首先我们需要部署 Seata Server 端。Server 端默认的存储模式时 file 模式,无需改动,直接执行 SpringBoot 启动类 main 方法即可启动 Seata Server。为了方便,本次演示就使用 file 模式启动,其他模式的启动方式可以参考新人文档的详细介绍。
创建 Client 端测试应用
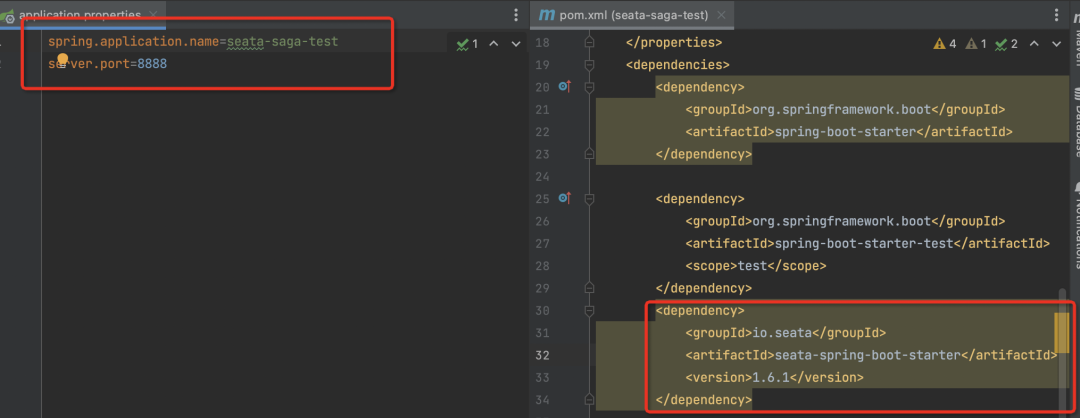
同时我们需要创建一个客户端的测试应用,这里命名 seata-saga-test,测试应用使用 SpringBoot 框架,配置好 spring 的 aplication.pname 和 port,并且引入 seata-spring-boot-starter 依赖,完成 Client 端应用的搭建。
2.2 从 Seata Saga 单元测试看起
一般了解一个框架的功能,建议是从入口的单元测试类开始看起。在 Seata 仓库中找到 Seata Saga 的 test 模块,从最外围的测试类 io.seata.saga.engine.StateMachineTests 看起 (一般开源项目最外围的测试类即是入口类) :
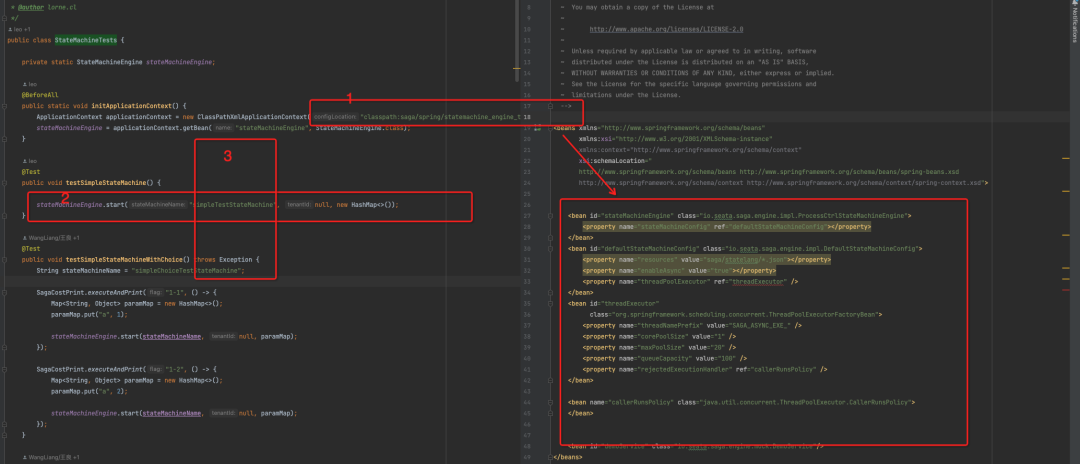
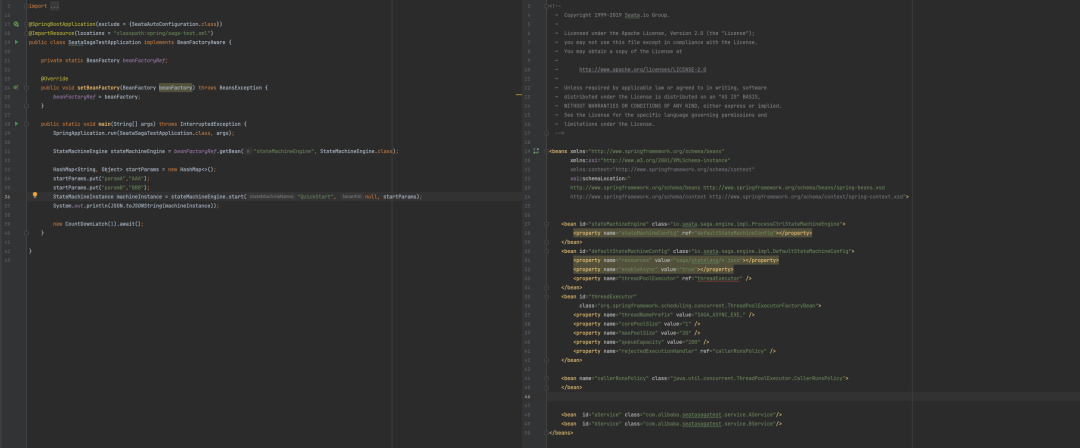
从上面的截图可以看出,入口测试方法主要分为三个部分:
【1】处的 spring 配置文件声明了 StateMachineEngine Bean 以及对应的属性,【2】处也引用了该类执行 start,判断该类为我们状态机的入口类,其实 StateMachineEngine 该类也就是 Seata Saga 状态机操作入口,控制状态机的开始、恢复等操作。StateMachineEngine 有一个重要的属性 resources,该属性声明了状态机 JSON 文件的存储路径,Seata Saga 状态机引擎启动的时候会加载对应路径下的状态机定义,以供后续使用,这里的路径根据我们需求更改。
【3】处调用了 StateMachineEngine 的 start 方法,传递状态机名称、启动参数,开启一个状态机流程调用。简单跟下实现,可以看到其中状态名称对应 resources 路径下状态机 JSON 定义中的 Name 属性。
测试 Seata Saga 状态机流程,我们得先有一个状态机 JSON 定义。使用 Seata Saga StateMachine Designer[3],定义一个简单 AService#doA 方法调用 BService#doB 方法的状态机流程,再加个入参,最终我们的类#方法和状态机 JSON 如下所示。
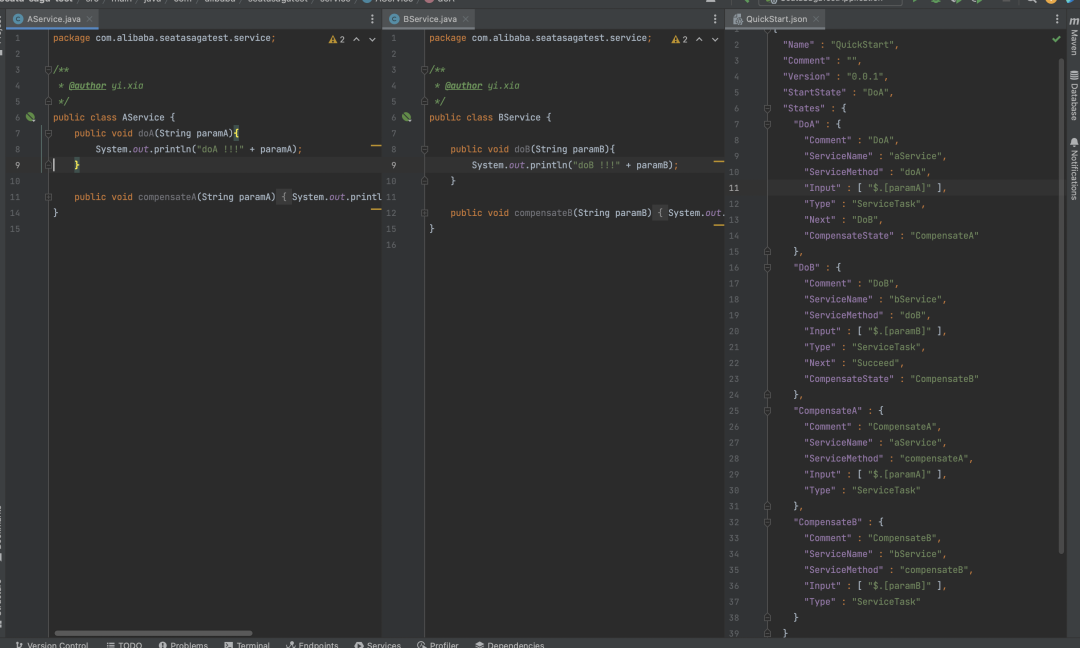
有了基础的调用模型和状态机 JSON 定义,按照测试用例,我们同样声明出状态机 Bean 及执行入口 (注意:start 方法里面的状态机名称需要和状态机 JSON 定义里面的 Name 名称保持一致) ,执行下 main 方法,我们可以发现 AService#doA 方法和 BService#doB 方法都被成功调用了。
至此,我们已经完成了 Seata Saga 状态机的入门使用。继续观察单测,我们发现 Seata Saga 单测还有两个模块,分别是 db 和 mock。

我们先来看看 db 模块的单测,可以看到 db 模块的单测类和上面基本类似,唯一的区别就在于 StateMachineEngine,指定了 db 存储,执行了 DDL SQL (初始化 Seata Saga 相关表) 。指定了 db 存储,那么我们的状态机执行过程将会持久化在 db 存储,方便事务执行过程查询和异常恢复,也是生产环境的实践方式。
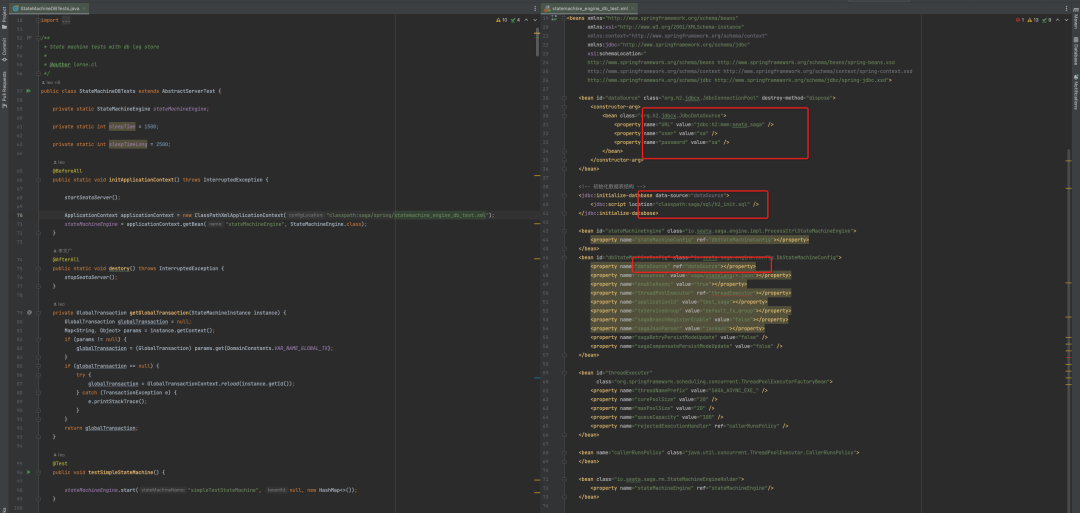
mock 模块通过 Mock Transcation,脱离 Seata Sever,仅使用了 Seata Saga 的服务编排能力。有兴趣的同学可以再去实践下 db 和 mock 模块的使用,这里就不展开了。
Seata Saga 最佳实践
3.1 基本使用
- 在应用层面,Seata Saga 状态机模式使用上不同于 AT、TCC 注解化方式,要使用状态机 API 执行;
- 在状态机模式里面,恢复策略分为向前重试和向后补偿,根据业务场景,要选择合适的补偿策略;
- Seata Saga 支持异步状态执行、状态机异步执行,适时使用异步,可以提升整个系统的吞吐量。
3.2 Saga 服务
- Saga 服务可能被多次调用,所以要保证幂等
- 补偿服务较原服务可能先执行、需要允许空补偿、同时需要拒绝后续的原服务请求,进行防悬挂控制
3.3 隔离性问题应对
- 业务驱动,如果业务上可以接受缺乏隔离性的影响,可以不用做任何操作
- 语义锁,对操作资源进行语义级别的锁定
- 使用悲观流程,例如 A->B 转账操作,先给 B 加钱,再给 B 减钱;换成悲观视图就是先给 A 减钱,再给 B 加钱,防止 B 加钱之后立刻消费导致的短款问题
- 其它方式
3.4 稳定性
基于 db 存储的 Saga 模式,需要注意:重试或者补偿默认会插入一条状态执行记录,频繁重试或者补偿,会导致状态执行记录爆炸,如果有大对象存储,可能会导致内存 crash。Seata Saga 提供了 update 模式,使用 update 记录代替新增执行记录,用来避免此类问题。
3.5 扩展
- Seata Saga 状态机存储、语法解析等都是面向 SPI 设计的,业务上可以平滑替换对应的存储或者状态机语言实现。例如将状态机的 JSON 解析替换到 YAML 解析。
- Seata Saga 支持 Mock Transaction 的方式,仅使用服务编排能力,也支持状态机定义 (JSON) 动态发布,也就是编排的动态发布,这一点在做 DSL 动态管控端的时候将会非常有用。
讲了这么多,Seata Saga 目前状态机的实现,上手成本相对还是比较高。一方面我们致力提升 Seata Saga 状态机模式的易用性,同时也在设计 Saga 的注解化模式、流式编排模式,期望提供给用户更具产品化能力的 Seata Saga。有兴趣的同学,也非常欢迎加入共建。
Seata Group 开源交流群:44816898
相关链接:
[1]Seata 官方文档:
http://seata.io/zh-cn/docs/user/saga.html
[2]可视化的编排界面
http://seata.io/saga_designer/index.html#/
[3]Seata Saga StateMachine Designer:
http://seata.io/saga_designer/index.html#/
Seata Star 一下✨:
https://github.com/seata/seata
