

倒排索引
全文搜索引擎目前主流的索引技术就是倒排索引的方式。传统的保存数据的方式都是:记录→单词。而倒排索引的保存数据的方式是:单词→记录, 基于分词技术构建倒排索引,每个记录保存数据时,都不会直接存入数据库。系统先会对数据进行分词,然后以倒排索引结构保存。
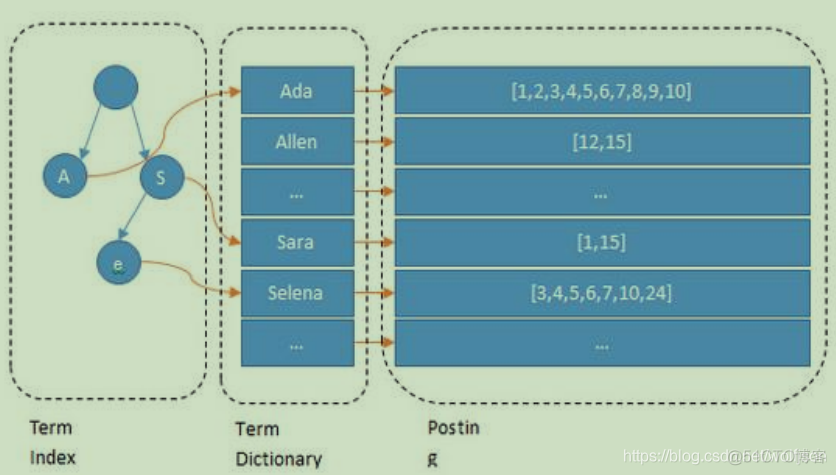
可以看到 Lucene 为倒排索引(Term Dictionary)部分又增加一层 Term Index 结构,用于快速定位,而这 Term Index 是缓存在内存中的,但 MySQL 的 B+tree 不在内存中,所以整体来看 ES 速度更快,但同时也更消耗资源(内存、磁盘)
集群操作
- 集群健康状态 – GET /_cat/health?v
绿 – 一切正常(集群功能齐全)
黄 – 所有数据可用,但有些副本尚未分配(集群功能完全)
红 – 有些数据不可用(集群部分功能) - 查看节点的情况 – GET /_cat/nodes?v
- 查询各个索引状态 – GET /_cat/indices?v
索引
- 创建索引 – PUT /film
- 查看某一个索引的分片情况 – GET /_cat/shards/film?v
- 删除索引 – DELETE /film
文档操作
- 创建文档 – PUT /film/_doc/1 幂等性
{ "id":100,
"name":"operation red sea",
"doubanScore":8.5,
"actorList":[
{"id":1,"name":"zhang yi"},
{"id":2,"name":"hai qing"},
{"id":3,"name":"zhang han yu"}
]}- POST /film/_doc/ 非幂等性
{
"id":300,
"name":"incident red sea",
"doubanScore":5.0,
"actorList":[ {"id":4,"name":"zhang cuishan111"}]
}根据主键保证幂等性
- 查询某一个索引中的全部文档 – GET /film/_search
- 根据id查询某一个文档 – GET /film/_doc/3
- 根据文档id,删除某一个文档 – DELETE /film/_doc/3
- 修改文档 – PUT /film/_doc/3 对已经存在的文档进行替换(幂等性)
{
"id":300,
"name":"incident red sea",
"doubanScore":5.0,
"actorList":[ {"id":4,"name":"zhang cuishan"}]
}- POST /film/_doc/3/_update 更新文档中的某一个字段内容
{ "doc": { "yy": "字符串" } }Elasticsearch实际上并没有在底层执行就地更新,而是先删除旧文档,再添加新文档
- 批量创建文档
POST /film/_doc/_bulk
{"index":{"_id":66}}
{"id":300,"name":"incident red sea","doubanScore":5.0,"actorList":[{"id":4,"name":"zhang cuishan"}]}
{"index":{"_id":88}}
{"id":300,"name":"incident red sea","doubanScore":5.0,"actorList":[{"id":4,"name":"zhang cuishan"}]}- 批量更新与删除文档
POST /film/_doc/_bulk
{"update":{"_id":"66"}}
{"doc": { "name": "wudangshanshang" } }
{"delete":{"_id":"88"}}查询
GET /索引名/_search?q= &pretty这种方式不太适合复杂查询场景*
- 查询指定字段 – GET /film/_search
{ "_source": ["name", "doubanScore"]}- 按分词查询(必须使用分词 text 类型)
GET /film/_search
{
"query": {
"match": {
"actorList.name": "zhang han yu"
}
}}- 按短语查询 相当于like
GET /film/_search
{
"query": {
"match_phrase": {
"actorList.name": "zhang han yu"
}
}}- 不分词 通过精准匹配进行查询
GET /film/_search
{
"query": {
"term": {
"actorList.name.keyword":"zhang han yu"
}
}}- 容错匹配
GET /film/_search
{
"query": {
"fuzzy": {
"name": "radd"
}
}}- 匹配和过滤同时
GET /film/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "red"
}
}],
"filter": {
"term": {
"actorList.id": "3"
}
}
}}}- 范围过滤 ,将豆瓣评分在6到9的文档查询出来
GET /film/_search
{
"query": {
"range": {
"doubanScore": {
"gte": 6,
"lte": 9
}}
}}- 按照豆瓣评分降序排序
GET /film/_search
{ "query": {
"match": {
"name": "red"
}},
"sort": [ {
"doubanScore": {
"order": "asc"
}
} ]}- 分页查询
GET /film/_search
{"from": 0, "size": 2}- 搜索结果高亮
GET /film/_search
{
"query": {
"match": {
"name": "red"
}
},
"highlight": {
"fields": {"name":{} },
"pre_tags": "",
"post_tags": ""
}
}- 聚合 – 聚合提供了对数据进行分组、统计的能力,类似于 SQL 中 Group By 和 SQL 聚合函数。在 ElasticSearch 中,可以同时返回搜索结果及其聚合计算结果,这是非常强大和高效的。
GET /film/_search
{
"aggs": {
"groupByName": {
"terms": {
"field": "actorList.name.keyword",
"size": 10,
"order": {
"avg_score": "desc"
}
},
"aggs": {
"avg_score": {
"avg": {
"field": "doubanScore"
} }
}}
}}.keyword 是某个字符串字段,专门储存不分词格式的副本,在某些场景中只允许只用不分词的格式,比如过滤 filter 比如聚合 aggs, 所以字段要加上.keyword 的后缀
中文分词
- 中文分词器对比
- GET _analyze
{"analyzer": "ik_smart", "text": "我是中国人" }
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}- 自定义分词词库
IK Analyzer 扩展配置
./myword.txt
Mapping
- 自定义mapping – 实际上每个 Type 中的字段是什么数据类型,由 mapping 定义,如果我们在创建 Index的时候,没有设定 mapping,系统会自动根据一条数据的格式来推断出该数据对应的字段类型,具体推断类型如下:true/false → boolean 1020 → long 20.1 → float “2018-02-01” → date “hello world” → text +keyword默认只有 text 会进行分词,keyword 是不会分词的字符串。mapping 除了自动定义还可以手动定义,但是只能对新加的、没有数据的字段进行定义,一旦有了数据就无法再做修改了。
PUT film01
{
"mappings": {
"movie":{
"properties": {
"id":{
"type": "long"
},
"name":{
"type": "keyword"
},
"doubanScore":{
"type": "double"
},
"actorList":{
"properties": {
"id":{
"type":"long"
},
"name":{
"type":"keyword"
}
} } }
} }}copy索引数据
- ElasticSearch 虽然强大,但是却不能动态修改 mapping 到时候我们有时候需要修改结构的时候不得不重新创建索引;ElasticSearch 为我们提供了一个 reindex 的命令,就是会将一个索引的快照数据 copy到另一个索引,默认情况下存在相同的_id 会进行覆盖(一般不会发生,除非是将两个索引的数据 copy 到一个索引中)
POST _reindex
{ "source": {
"index": "my_index_name"
},
"dest": {
"index": "my_index_name_new"
}}索引别名
- 应用场景 – 给多个索引分组,把多个索引归并到一组
- 给索引的一个子集创建视图相当于给 Index 加了一些过滤条件,缩小查询范围
- 创建索引 并指定别名
PUT flim01
{ "aliases": {
"film_chn_3_aliase": {}
},- 查看所有别名
GET /_cat/aliases- 索引增加、删除索引
POST /_aliases
{ "actions": [
{ "remove": { "index": "movie_chn_1", "alias": "movie_chn_query" }},
{ "remove": { "index": "movie_chn_2", "alias": "movie_chn_query" }},
{ "add": { "index": "movie_chn_3", "alias": "movie_chn_query" }}
]
}索引模板
- 应用场景
- 分割索引
- 分割索引就是根据时间间隔把一个业务索引切分成多个索引。比如 把 order_info 变成 order_info_20200101,order_info_20200102 这样做的好处有两个:
- 结构变化的灵活性
- 因为 ES 不允许对数据结构进行修改。但是实际使用中索引的结构和配置难免变化,那么只要对下一个间隔的索引进行修改,原来的索引维持原状。这样就有了一定的灵活性。要想实现这个效果,我们只需要在需要变化的索引那天将模板重新建立即可。
- 查询范围优化
- 因为一般情况并不会查询全部时间周期的数据,那么通过切分索引,物理上减少了扫描数据的范围,也是对性能的优化。
- 创建模板
PUT _template/template_film
{"index_patterns": ["film_test*"],
"settings": {
"number_of_shards": 1
},
"aliases" : {
"{index}-query": {},
"film_test-query":{}
},
"mappings": {
"_doc": {
"properties": {
"id": {
"type": "keyword"
},
"movie_name": {
"type": "text",
"analyzer": "ik_smart"
}}
}}}- 查询所有模板
GET _cat/templates- 查询模板详情
GET _template/template_film*