

Flink框架主要应用针对流式数据进行有状态计算。
Flink使用java语言开发,提供了scala编程的接口。使用java或者scala开发Flink是需要使用jdk8版本,如果使用Maven,maven版本需要使用3.0.4及以上,Flink同时也支持使用python进行开发,需要在python中安装PyFlink 包
本实例基于flink1.7.1。
创建maven工程,pom配置文件如下:
4.0.0
com.wh.flink
flink
1.0-SNAPSHOT
flink
http://www.example.com
UTF-8
1.8
1.8
1.7.1
org.apache.flink
flink-java
${flink.version}
org.apache.flink
flink-streaming-java_2.11
${flink.version}
org.apache.flink
flink-connector-kafka-0.11_2.11
${flink.version}
junit
junit
4.11
test
org.apache.flink
flink-scala_2.11
${flink.version}
org.apache.flink
flink-streaming-scala_2.11
${flink.version}
org.scala-tools
maven-scala-plugin
2.15.2
compile
testCompile
maven-assembly-plugin
2.4
jar-with-dependencies
com.lw.java.myflink.Streaming.example.FlinkReadSocketData
make-assembly
package
assembly
创建需要统计数据的words文件
hello java
hello hadoop
hello scala
hello storm
hello spark
hello flink
hello java
hello hadoop
hello scala
hello storm
hello spark
hello flink创建FlinkWorldCount 类,代码如下
public class FlinkWorldCount {
public static void main(String[] args) throws Exception {
//创建环境
StreamExecutionEnvironment env1=StreamExecutionEnvironment.getExecutionEnvironment();
LocalStreamEnvironment env2=StreamExecutionEnvironment.createLocalEnvironment();
ExecutionEnvironment env=ExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//读取文件
DataSourcedataSource=env.readTextFile("./data/words");
FlatMapOperatorwords=dataSource.flatMap(new FlatMapFunction() {
@Override
public void flatMap(String line, Collector out) throws Exception {
String []split=line.split(" ");
for (String word : split) {
out.collect(word);
}
}
});
MapOperator>map=words.map(new MapFunction>() {
@Override
public Tuple2 map(String word) throws Exception {
return new Tuple2(word,1);
}
});
UnsortedGrouping>grouping=map.groupBy(0);
DataSet>sum=grouping.sum(1);
SortPartitionOperator>result=sum.sortPartition(1, Order.DESCENDING);
//打印运行结果
sum.print();
// 将运行结果写入到文件中
// DataSink>tuple2DataSink=result.writeAsCsv("./data/reuslt",";","=", FileSystem.WriteMode.OVERWRITE);
// env.execute();
}
}执行结果如下
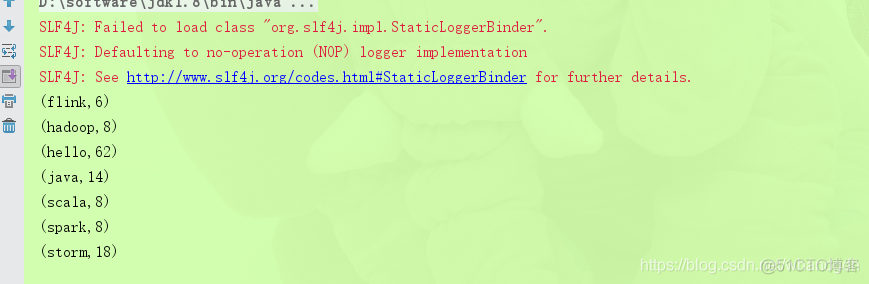
将执行结果写入到文件中,
最后代码调整如下:
//sum.print(); 【print、count、collect自带触发功能,不需要env.execute()】
// 将运行结果写入到文件中
DataSink>tuple2DataSink=result.writeAsCsv("./data/reuslt",";","=", FileSystem.WriteMode.OVERWRITE);
env.execute();执行结果
看到在data目录下创建了result文件,并将结果写入到了result文件中。

