

作者:徐奇
TiKV 推出了名为“partitioned-raft-kv”的新实验性功能,该功能采用一种新的架构,不仅可以显著提高 TiDB 的可扩展性,还能提升 TiDB 的写吞吐量和性能稳定性。
在上一篇文章中,我们介绍了 Partitioned Raft KV 这一新实验特性带来的性能和可伸缩性大幅提升。本文我们将为大家介绍为什么它可以有如此大的优势。
架构
以下是 TiKV 的架构。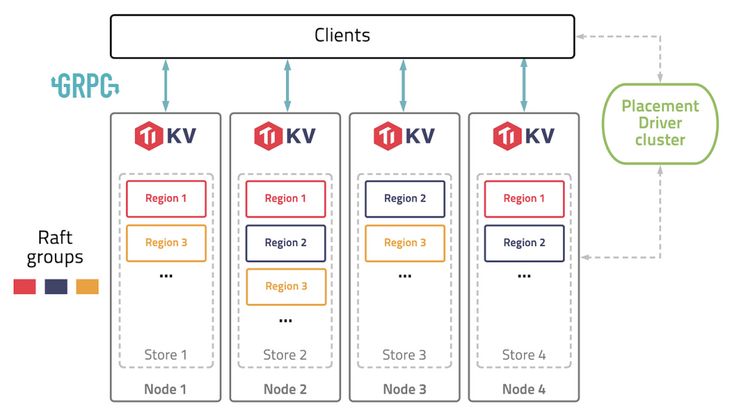
图 1 TiKV 架构 —— 逻辑数据分区
一个 TiKV 集群由许多数据分区(也称为 Region)组成。每个 Region 负责特定的数据片段,由其起始和结束键范围决定。它在不同的 TiKV 节点上拥有 3 个或更多的副本,并通过 raft 协议进行同步。在旧的 raft 引擎中,每个 TiKV 中只有一个 RocksDB 实例用于存储所有 Region 的数据。partitioned-raft-KV 特性引入了一个新的物理数据布局:每个 Region 都有自己的 RocksDB 实例。
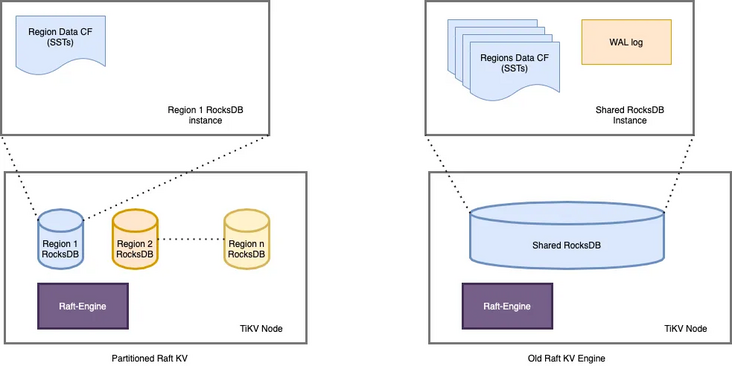
图 2:物理数据布局比较
旧 Raft KV 引擎面临的挑战
“Region” 是 TiKV 中的逻辑规模单元。每个数据访问和管理操作,如负载均衡、扩展和缩小都由 Region 进行分区。然而,在当前架构中,它是一个纯逻辑概念,物理上没有清晰的区域边界。这意味着:
- 当需要将一个 Region 的数据从一个 TiKV 移动到另一个 TiKV(也称为负载均衡)时,TiKV 需要在巨大的 RocksDB 实例中进行扫描以获取该 Region 的数据。这造成了读扩大。
- 当几个 Region 具有大量的写流量时,如果它们的键范围分散,那么很可能会触发 RocksDB 中的大型压缩,其中包括其他空闲 Region 的数据。这引入了读和写扩大。例如,SST11 是一个 1MB 大小的 SST,只有 region1 的数据,但包含相当大的键范围。当它被选中合并到 L2 时,SST21、SST22 和 SST23 都参与了压缩,它们包含了 region2、3、4 的数据。TiKV 的规模越大,读写扩大越大。
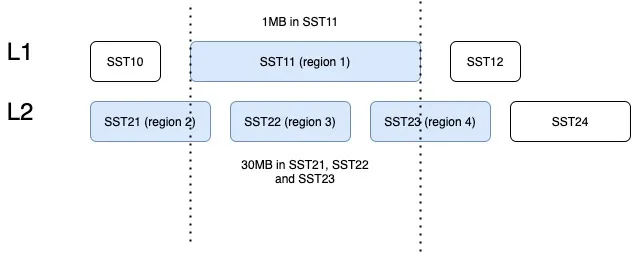
图 3:不同 Region 之间的压缩数据
- 没有 Region 隔离,因此少数热门 Region 可能会拖慢所有 Region 的性能。
因此,在旧的 raft KV 引擎中,我们可能会遇到以下问题:
- 扩所容的速度很慢,因为需要多次数据扫描。
- 由于 RocksDB 的写组是单线程的,因此写吞吐量受到限制。
- 由于数据压缩会不时发生,当 RocksDB 的数据量很大时,用户流量的延迟不稳定。
Partitioned Raft KV 引擎的改进
- 每个 Region 的数据都是一个专用的 RocksDB 实例,因此只需将 RocksDB 进行 x-copy 以进行 Region 间的负载均衡,避免了读放大的发生。
- 热点 Region 的写入流量只会触发其自己的 RocksDB 的压缩,不涉及其他 Region 的数据。因此,它有效地减少了读和写放大。
- 在将数据写入RocksDB时,写入线程之间并不会发生数据同步和锁争用,因为每个线程都在写一个不同的 RocksDB 实例。这样就消除了写入瓶颈。由于没有 WAL 日志,向 RocksDB 的写入是一个内存操作。
- 一个 RocksDB 性能不好并不会影响其他 Region。因此,Region 的性能在存储层面上是隔离的。
- 现在每个 Region 都支持更大的容量, 默认情况下为 15 GB。和过去 96MB 的 Region 大小限制相比,心跳和内存占用这一类的 Region 开销降幅高达 99%。
因此,使用 partitioned raft KV,TiDB 在扩展或缩小数据方面的速度大约快 5 倍,并且由于压缩的影响要小得多,其性能总体上更加稳定。
适用范围
一切看起来都很好。但是还有一个问题。现在我们有更多的 RocksDB 实例,因此它们的 memtable 的内存消耗要多得多,这意味着您可能需要额外的 5GB〜10GB 的内存开销才能在内存消耗和性能之间达到平衡。因此,当内存资源已经非常紧张时,通常不建议打开此功能。但是,当您在 TiKV 中有额外的内存并关心可扩展性和写入性能时,这个功能可能会对您有所帮助。
写在最后
一些客户可能会说当前版本的 TiDB 已经足够好了。所以新功能对他们来说似乎并不重要。但是,如果他们可以在一个集群中用于多个工作负载,而且每个工作负载都可以得到良好的隔离和 QoS 保证呢?这就是 7.0 版本中的“资源管控”功能。 “partitioned raft KV” 功能旨在最大化硬件性能,与“资源管控”一起使用,我们的客户将能够充分利用其硬件资源,并通过将多个工作负载合并到一个集群中来降低成本。
