

大数据是企业数字化转型中,支撑企业经营和业绩增长的主要手段之一。而实时化、云原生化已经成为大数据技术发展的必然趋势。
4月18日,火山引擎春季 FORCE 原动力大会在上海举办。在会上,火山引擎发布了云原生大数据实时计算平台产品——流式计算 Flink 版。脱胎于字节跳动在业界最大规模的实时计算集群实践,流式计算 Flink 产品在诸如实时 ETL、实时数仓/湖、实时机器学习、实时风控等场景中均有所探索,帮助客户构建云上增长新动力,助力业务敏捷创新。

字节实践 – 日常峰值百亿 QPS
从 2017 年开始,字节跳动开始尝试使用 Flink 作为主要的流式计算引擎。在此后的两年时间,流式计算团队支撑了字节内部实时样本拼接、模型训练和推荐算法实时化等业务,更是完成了公司内 JStorm 作业的 100% 迁移。到 2019 年,字节内部 Flink 的应用迅速扩大,几乎覆盖包括抖音、头条、西瓜在内的各个产品。与此同时,团队开始积极参与到社区的共建中,在 2020 年李本超同学受邀成为 Apache Flink Committer。近两年,团队在 Flink OLAP 方向也进行了不少探索。在调度、运行时、SQL 等各个方面都进行了全方面的优化,极大提升性能,单集群可支持 200+ QPS,目前已经在 User Growth、飞书、电商等十多个业务场景落地,每天的查询规模超过 50W 次。
截止目前,基于流式计算 Flink 构建的实时业务场景已经涉及到字节几乎所有的业务和产品,包括实时数仓、实时风控、商业化、电商、游戏、小说、教育、房产、财经等,
日常实时峰值超
100
亿
QPS。与此同时
流批一体在视频云、实时计数特征、电商、SQL数据同步等场景均得到了广泛的使用和落地,已上线 6K+ Flink Batch SQL 任务。
日常实时峰值超
100
亿
QPS。与此同时
流批一体在视频云、实时计数特征、电商、SQL数据同步等场景均得到了广泛的使用和落地,已上线 6K+ Flink Batch SQL 任务。
企业级增强 – 流式计算 Flink 版
火山引擎流式计算 Flink 版依托于字节跳动在业内最大规模实时计算集群实践。火山引擎流式计算 Flink 版基于火山引擎容器服务(VKE/VCI),提供 Serverless 极致弹性,是开箱即用的
新一代
云原生
全托管
实时计算平台。在 100% 兼容开源 Flink 的前提下,深度优化 30+ 企业级产品功能增强,包含以下特性:
新一代
云原生
全托管
实时计算平台。在 100% 兼容开源 Flink 的前提下,深度优化 30+ 企业级产品功能增强,包含以下特性:
-
开发效率提升。流式计算 Flink 版支持算子级别 Debug 输出、Queryable State、Temporal Table Function DDL,在开发效率上对开源版本 Flink 有显著提升。
-
可靠性提升。流式计算 Flink 版针对单个 Task 进行 Checkpoint,提高了大并发下的 Checkpoint 成功率。单点任务恢复和节点黑名单机制功能,保障了对故障节点的快速响应,避免业务整体重启。
-
Serverless
云原生
架构。极致弹性,1‰ 核精细调度。 -
易用性增强。极简 SQL 开发,开箱即用、免运维、支持流式数据全生命周期管理。
-
高性能低价格。高性价比、高 SLA 保证、超低 TCO。
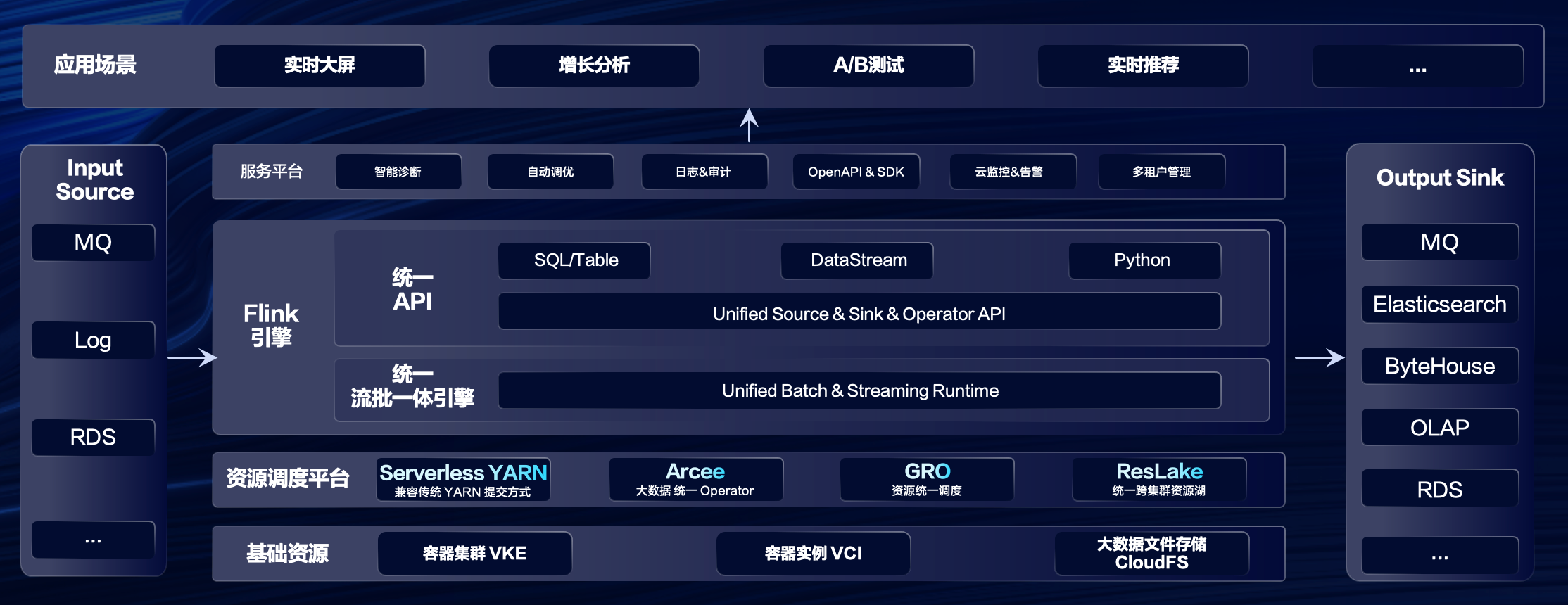
火山引擎流式计算 Flink 产品整体架构
从整体架构而言,Source/Sink 端支持多种数据存储类型,借助容器集群基础设施,构建极致弹性与灵活的资源调度平台;引擎层做到 Runtime & API 在流批一体方面的统一,并通过服务平台构建智能诊断、自动调优等高阶辅助开发能力。
目前,火山引擎流式计算 Flink 版产品已形成融合计算、存储、智能等多种能力的产品解决方案。在具备跨云及多云能力的同时,将始终坚持
大数据
技术“云原生化、实时化和智能化”的发展方向,为企业数字化转型提供的动力。
大数据
技术“云原生化、实时化和智能化”的发展方向,为企业数字化转型提供的动力。
