

作者:京东零售 肖勇
一、 前言导读
TiDB作为NewSQL,其在对MySQL(SQL92协议)的兼容上做了很多,MySQL作为当下使用较广的事务型数据库,在IT界尤其是互联网间使用广泛,那么对于开发人员来说,1)两个数据库产品在SQL开发及调优的过程中,都有哪些差异?在系统迁移前需要提前做哪些准备? 2)TiDB的执行计划如何查看,如何SQL调优? 本文做了一个简要归纳,欢迎查阅交流。
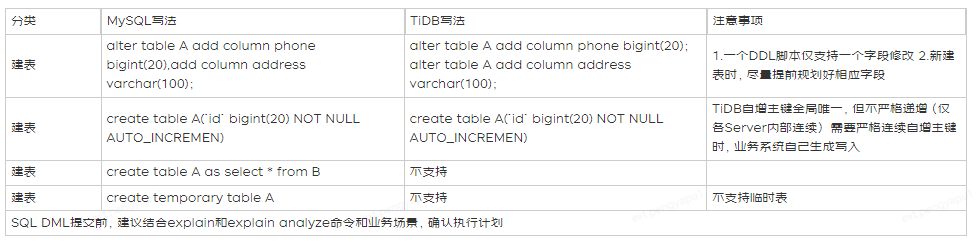
二、 建表SQL语法差异&优化建议
三、 查询SQL语法差异&优化建议

四、 SQL执行计划差异&优化建议

五、 TiDB执行计划分析简介
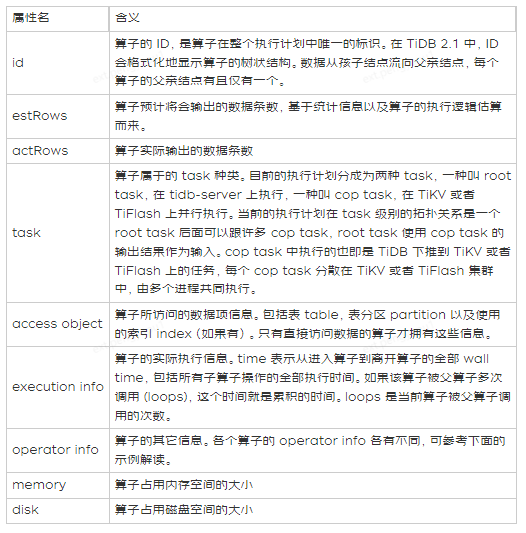
1. 在开始实际案例分析前,我们先看下执行计划中每列的含义:
引自:https://docs.pingcap.com/zh/tidb/stable/sql-statement-explain和https://docs.pingcap.com/zh/tidb/stable/sql-statement-explain-analyze
2. 执行计划优化的几个关键点:
1) 重点观察算子类型,尽量控制优化器选择性能较优的算子,读取磁盘记录的几个算子性能:TableFullScan>TableRangeScan>TableRowIDScan,IndexFullScan>IndexRangeScan
2) 尽量减小root层执行动作,下放至tikv或tiflash执行,执行计划中task属性包括root task和cop task,其中root标识动作由tidb聚合层执行(此操作除了需要等待各分片结果外,一般部署结构中tidb资源也较tikv或tiflash少),cop标识动作下放至tikv或tiflash各分片单独执行
3) 保证表分析数据完整性,避免大批量数据短时间内新增/删除,estRows为执行引擎根据情况返回的预估记录条数,特别注意:若operator info出现stats:pseudo,则标识表基本信息不完善(无法提供准确执行计划评估),后续可通过analyze表重新收集分析数据,或显示use index对sql显示优化
4) 根据实际业务(如:列模式数据统计),增加tiflash模块,通过空间换时间,提升结构化查询和实时分析能力
3. 实际场景分析
下面我们通过2个实际SQL说说TiDB的执行计划:
l SQL1
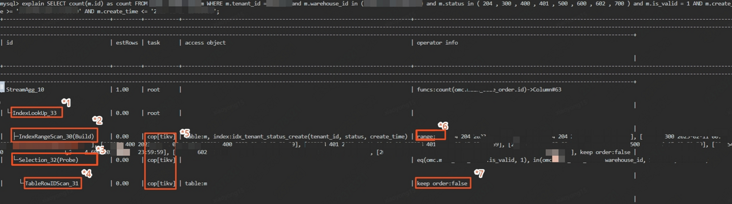
1:IndexLookUp算子:根据索引获取结果记录
2 & 3:Build算子总是优先于Probe算子执行,*2 算子根据条件从索引中获取数据,*3算子在结果中匹配结果
4:TableRowIdScan:通过 *3 算子结果中的表主键id从TiKV获取行记录
5:cop【tikv】标识将计算逻辑从tidb下放到tikv执行,同理还会有cop【tiflash】
6:tikv通过范围索引扫描出对应记录
7:根据id获取行记录后直接返回上层,无需排序
——————————————————————————————————————————
l SQL2
优化前,两表直接join:
explain analyze SELECT m.id AS id, m.order_id AS orderId, s.status AS status,m.sendpay_map as sendPayMap FROM tableA m LEFT JOIN tableB s on m.order_id = s.order_id WHERE m.id >= 100 AND m.id m.id desc limit 20,20;
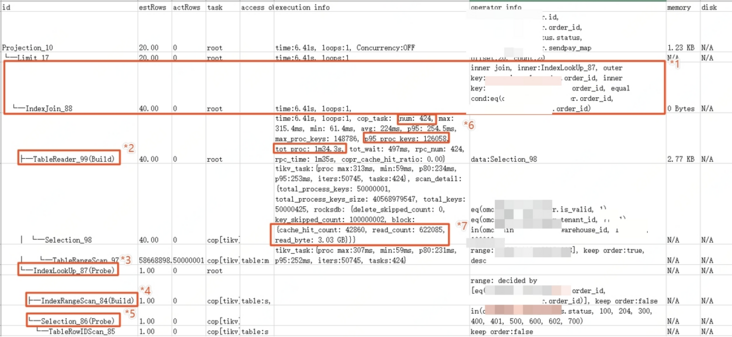
1:IndexJoin算子:根据表s索引,与表m关联起来
2 & 3:Build算子总是优先于Probe算子执行,*2 算子从表m匹配相关记录,*3算子通过表s索引获取join管理数据
4 & 5:基于*3算子join后的结果,筛选匹配s表条件的记录
6 & 7:可以看到此处表记录查询使用了TableReader,耗时6.41s(其中cop_task共424个,且使用了大量索引proc_keys),Selection_98根据索引回表查询更是读取了3.03GB记录
总结:整体sql因为是先join在limit,tidb无法将limit操作下推,导致主表大量回表查询,影响性能
优化后,先子查询再join:
explain analyze select * from (SELECT m.id AS id, m.order_id AS orderId,m.sendpay_map as sendPayMap FROM tableA m WHERE m.id >= 100 AND m.id m.id desc limit 20,20) t LEFT JOIN tableB s on t.orderId = s.order_id WHERE s.status in (100 ,200, 300, 400)
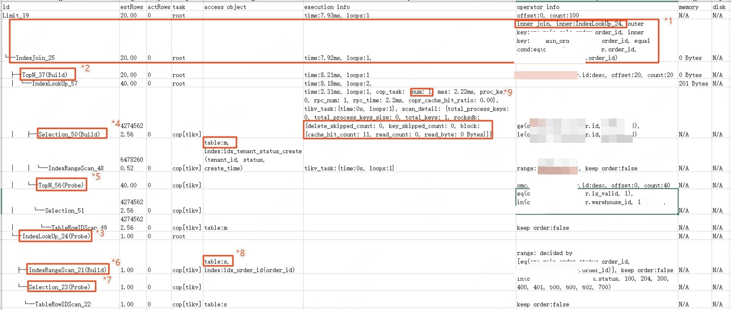
1:IndexJoin算子:根据表s索引,与表m关联起来
2:从m表结果中获取前20条记录
3:通过表s索引获取join管理数据
4:根据条件,从表m的索引中获取记录
5:从*4算子结果中获取40条记录(tikv3副本,从2个分片各获取20条,共40条)
6 & 7:基于*3算子join后的结果,筛选匹配s表条件的记录
9:可以看到,此处是直接从IndexLookUp_57索引中查询数据,cop_task=1,且rocksdb中命中了缓存cache_hit_count=11
总结:整体sql因为是先limit再join,tidb将limit下推至tikv,大大较少了主表的回表查询数据量,提升性能
六、 小结
本文旨在通过TiDB和MySQl在SQL层面的差异性讲解,帮助读者在DB迁移和评估前,清楚了解双方的差异,避免遗漏。同时,针对TiDB的执行计划,通过简介和2个案例,帮助大家快速分析SQL执行情况,以便针对性优化。
