

作者:京东科技 李俊兵
各位看官好,我是球神(江湖代号)。
自去年11月30日ChatGPT问世以来,迅速爆火出圈。
起初我依然以为这是和当年Transformer, Bert一样的“热点”模型,但是当一篇篇文章/报告不断推送到我的眼前,我后知后觉地发现这次真的不一样。
很直接的一点是,ChatGPT已经影响到非AI、非互联网、非计算机的每一个人了。
你会看到,众多科技界大佬,马斯克、纳德拉、李开复、李彦宏、周鸿祎等,都在发声称 ChatGPT 将改变世界;
太多的互联网公司,如微软、谷歌、百度、阿里、腾讯等正在抢占商业先机;
还有更多的学术机构、高校也开始讨论 ChatGPT 生成论文是否符合学术规范;
突然之间各行各业从业者开始担忧被 ChatGPT 替代……
「初看以为是热点,再看已成经典…」
于是我决定好好研究它一番,并力争把它写得全面而通俗易懂一点,最终就有了这篇万字长文报告,建议收藏、慢慢阅读。
文章主题关于:「ChatGPT背后的AI背景、技术门道和商业应用。」

以下是目录和正文内容:
引言
我和聊天机器人的小故事
一、 AI背景
1.1 ChatGPT的出圈和能力圈
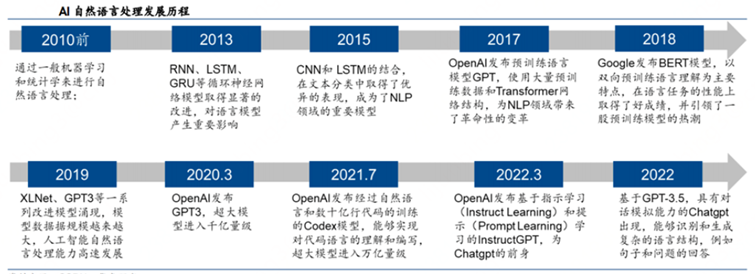
1.2 人工智能发展简史
1.3 ChatGPT背后的NLP和Transformer
二、技术门道
2.1 GPT-1到ChatGPT的演进和技术原理
2.2 ChatGPT的局限性
2.3 ChatGPT的优化和探索方向
三、商业应用
3.1 国内外资本投入层层加码
3.2 ChatGPT商业化序幕已经拉开
3.3 ChatGPT助力AIGC浪潮再起
后记
ChatGPT会引领第四次科技革命吗?
ChatGPT会给人类带来失业潮吗?
ChatGPT适合下海创业吗?
ChatGPT以及AIGC产业链有值得投资的机会吗?
参考文献
笔者相关背景简介
引言
我和聊天机器人的小故事
早在2017年末至2018年上半年,我刚拿到计算机专业研究生的入场券,同时需要完成本科毕业设计。因此,我选择提前进入研究生实验室并带回一个毕设课题:中文文本对话系统(俗称:聊天机器人)。
没错,从研究方向来说,今天文章的主角ChatGPT正好属于我那会的研究范畴—自然语言处理(NLP)。只不过后来因为一些不可控因素,我更加关注于机器学习和计算机视觉领域。
记得最后写本科毕业论文和答辩的时候,我的中文文本聊天机器人(基于Seq2Seq + Attention架构)还很low:只能保持4-5轮对话逻辑;稍微问难点答案就面目全非;对话的文本不能太长…
虽然同样在2017年,Transformer架构已经问世,但站在那个时间节点,即便是一线研究人员和工程师,恐怕也很难想象到5年后的2022年,就会有ChatGPT这样的现象级通用聊天机器人程序出现。
“科技的发展不是均匀的,而是以浪潮的形式出现”。—《浪潮之巅》,吴军
一、AI背景
1.1 ChatGPT的出圈和能力圈
尽管ChatGPT已经火爆到让很多人疯狂,我们还是希望静下心来仔细看看它现在到底能做什么,它的边界又在哪里。

各大热门平台产品月活跃用户数破亿所需时长
先看产品实际应用测试的效果:
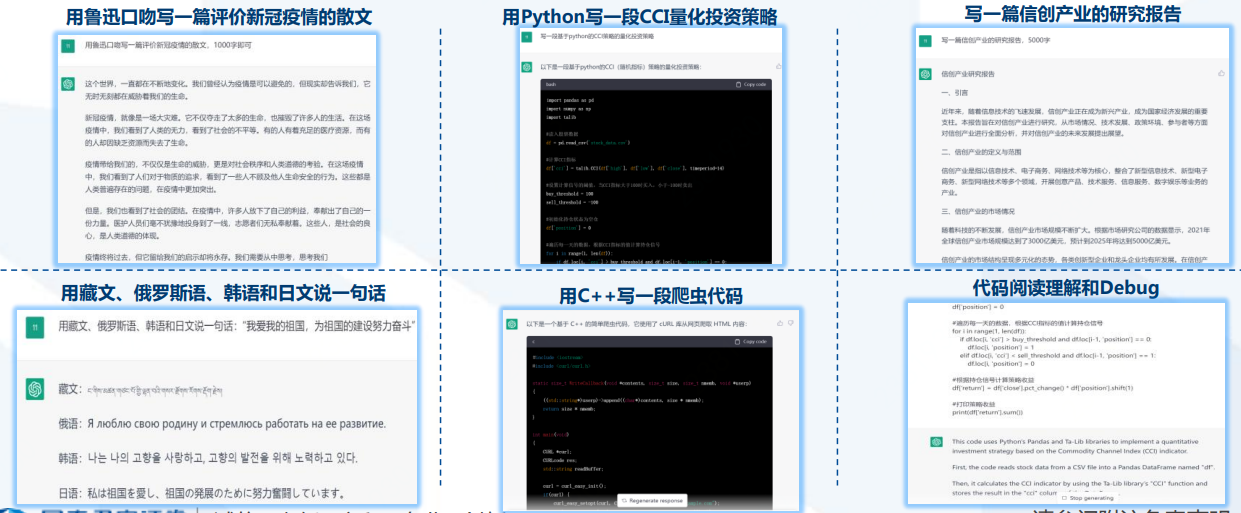
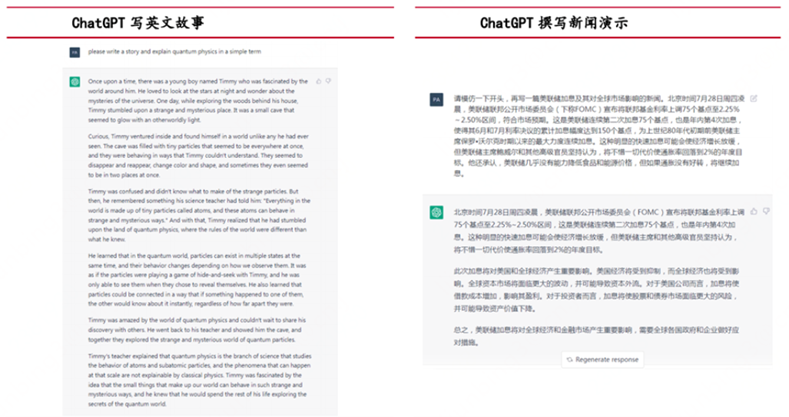
再看产品表现背后抽象出的深层次能力:
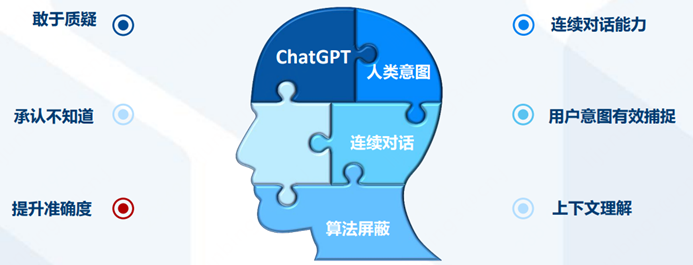
所以,从发布到现在2个多月来,ChatGPT已经证明了它的能力圈包括:自动问答、多轮聊天、文章创作、语言翻译、文本摘要、编写和debug代码等,同时这些表层能力背后反映了其具备理解人类意图、敢于质疑、承认不知道、不断学习进化等深层次ability。
并且这些能力表现已经远超过往其他AI机器人,也已经得到了包括AI研究者、工程师和各行各业产业专家们的一致认可。
不得不承认,从单项性能表现、整体功能覆盖、稳定性、时效性、鲁棒性等多个维度评价,目前的ChatGPT已经足够颠覆,它让通用AI研究和产业落地成为可能。
1.2 人工智能发展简史
提起人工智能和计算机科学,有个名字总是无法绕开。
他是英国人艾伦·图灵(Alan Turing)。
图灵(Alan Turing,1912-1954)出生的那年,他的祖国正处在“日不落”的全盛时期,占有的殖民地是本土面积的百倍有余。而在遥远的东方,中华民国临时政府在南京成立,中山先生就职临时大总统,属于中华民族的革命复兴才刚刚开始(「ChatGPT应该写不出这段」)。
1950年,时年38岁的图灵在数学和逻辑学领域已经成就颇丰,但当他在《计算机与智能》论文中提出著名的“图灵测试”构想时,后世的人们更加不会忘记他对人工智能和计算机科学领域做出的杰出贡献。
“如果第三者无法辨别人类与人工智能机器反应的差异,则可以论断该机器具备人工智能”。— 图灵, 人工智能之父
时间来到1956年8月,在美国达特茅斯学院,约翰·麦卡锡、马文·闵斯基、克劳德·香农、艾伦·纽厄尔、赫伯特·西蒙等科学家 一起讨论了用机器来模仿人类学习以及其他方面的智能等问题,首次提出了“人工智能”这个概念,也就此标志了人工智能学科的诞生。
此后,人工智能的发展经历了四次大的浪潮。
第一次浪潮(1956-1980):初次繁荣到低谷
初代AI中计算机被用于证明数学定理、解决代数应用题等领域。这一时期感知机(1957)、模式识别(1961)、人机对话(1966)、专家系统(1968)、视觉计算(1976)等理论先后被提出来。
好景不长,专家和学者们发现仅仅具有逻辑推理能力远远不够实现人工智能,许多难题并没有随着时间推移而被解决,很多AI系统一直停留在了玩具阶段。之前的过于乐观使人们预期过高,又缺乏实质性的进展,许多机构逐渐停止了对AI研究的资助。人工智能遭遇了第一次低谷。
第二次浪潮(1980-1995):二次复苏到萧条
AI 2.0时代专家系统和多层神经网络得到推广应用,人机对话机器人、语音控制打字机逐渐问世,这一时期贝叶斯网络(1985)、反向传播(BP,1986)、支持向量机(SVM,1995)等算法先后被提出来。
但是很快,专家系统所存在的应用领域狭窄、知识获取困难、维护费用居高不下等问题开始暴露出来。AI发展遭遇了一系列财政问题,进入第二次低谷。
第三次浪潮(1995-2010):平稳中积蓄力量
上个世纪90年代中期以来,随着计算机性能的高速发展和海量数据的累积,人工智能的发展正式进入现代AI时代。
1997年,IBM的国际象棋机器人深蓝(Deep Blue)战胜国际象棋世界冠军卡斯帕罗夫,引起世界范围内轰动。 随后,条件随机场(CRF,2001)、深度学习(Deep Learning, 2006)、迁移学习(Transfer Learning,2010)等理论先后被提出来。
第四次浪潮(2010-至今):爆发中走向高潮
进入21世纪的第二个十年以来,工业界开始陆续推出实打实的人工智能产品/应用。
2011年2月,IBM的问答机器人Watson在美国问答节目《Jeopardy!》上击败两位人类冠军选手;
2012年10月,微软就在“21世纪的计算”大会上展示了一个全自动同声传译系统,它将演讲者的英文演讲实时转换成与他的音色相近、字正腔圆的中文;
2016年3月,谷歌的围棋人工智能系统AlphaGo与围棋世界冠军、职业九段选手李世石进行人机大战,并以4:1的总比分获胜;
随后在2016年末-2017年初,AlphaGo又先后与中日韩数十位围棋高手进行快棋对决,连胜60局无一败绩,包括3:0完胜世界第一、中国选手柯洁。
与之对应的是,AI学术界在这十多年来可谓百家争鸣,各显神通。
2012年,Hinton(深度学习三巨头之一)和他的学生Alex Krizhevsky设计了第一个深度卷积神经网络— AlexNet,并摘得了当年ImageNet图像分类比赛的冠军;
此后,CV人相继提出了VGGNet(2014)、Inception Net(2014)、ResNet(2015)、Fast RCNN(2015)、 YOLO(2015)、 Mask RCNN(2017) 、MobileNet(2017)等base model,引领了图像分类、人脸识别、目标检测、图像分割、视频理解等领域的快速发展;
NLP人不甘示弱,他们先设计了Word2Vec(2013)类能将单词转化为向量表示的工具,随后利用LSTM(1997)系列循环神经网络,基于Seq2Seq(2014) + Attention(2015)的架构实现了机器翻译、对话系统等复杂任务,并进一步在2017年提出了Transformer这一大杀器,同时进阶产生了BERT(2018)系列性能更优更稳定的大模型。
还有另一群执着的AI者,他们更focus深度生成式网络模型。从变分自编码器(VAE,2013)到生成对抗网络(GAN,2014),再到去噪扩散模型(DDPM,2020)和生成式预训练Transformer (GPT系列,2018-至今),这些具有开创性的模型真正带动了产业界AIGC(生成式人工智能技术)的快速发展。
2017年,微软“小冰”推出世界首部由人工智能创作的诗集《阳光失了玻璃窗》; 2018年,英伟达发布StyleGAN模型可自动生成高质量图片; 2019年,Deep Mind发布DVD-GAN模型可生成连续性视频; 直到2022年11月30日,OpenAI发布ChatGPT,本文的主角终于正式登场。
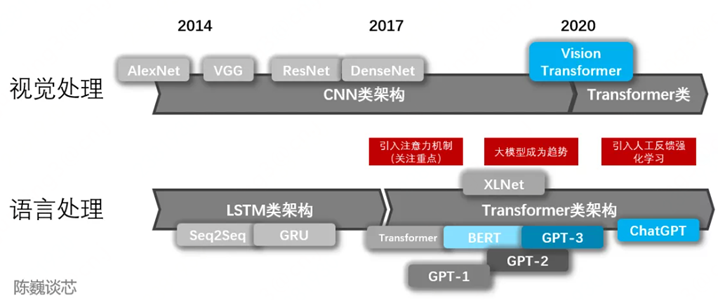
一部人工智能发展史也是一部信息技术革命发展史。
不同的是,当人工智能发展到一定阶段,它或许终将颠覆“机器帮助人”的信息化时代,引领“机器代替人”的智能化时代。
「多年以后,也许我们会看到,ChatGPT正是第四次科技革命开始的标志性事件之一。」
1.3 ChatGPT背后的NLP和Transformer
在了解ChatGPT的能力圈和人工智能的发展史之后,非AI从业者也能明白ChatGPT的研究属于自然语言处理(Natural Language Processing, NLP)领域范畴。
自然语言处理(Natural Language Processing, NLP) 被誉为“人工智能皇冠上的明珠”,一方面表明了它的重要性,另一方面也突出了它的技术难度。
简单来说,NLP要做的事就是利用计算机实现自然语言数据的智能化处理、分析和生成,以期让计算机实现听、说、读、写、译这些人类所具备的语言能力。
更具体一点,NLP领域根据下游任务不同主要包括以下几类研究方向:

细心的读者已经发现了,ChatGPT基本已经实现了以上7大类任务的中阶目标,所以NLP研究员和工程师们担心自己发明工具却抢了自己饭碗不是没有道理,其他技术含量不高的行业工作者也就更加战战兢兢。
NLP的发展也经历了三个大的阶段,即以规则学习为代表的第一阶段(1960-1990)、以统计学习为代表的第二阶段(1990-2010)和以深度学习为代表的第三阶段(2010-至今)。
而其中真正影响ChatGPT和其他大语言模型产生的无疑是Transformer架构。
可以说,Transformer的出现完全打开了大规模预训练语言模型(Pre-trained Language Model , PLM)的空间,并且奠定了生成式AI的游戏规则。
2017 年,Google 机器翻译团队在机器学习顶级会议NIPS上发表了《Attention is All You Need》论文,文章的核心正是 Transformer 模型。
Transformer相比之前论文的novalty在于:大胆地抛弃了传统的CNN和RNN基础模型,整个网络结构完全是由Attention机制组成。更准确地说,Transformer由且仅由自注意力(self-Attenion)机制和前馈神经网络(Feed Forward Neural Network)组成。
而从实际应用的角度来看,Transformer的主要贡献(contribution)在于以下几个方面:
1.突破了 RNN 模型不能并行计算的限制
2.精度和模型复杂度相比RNN/CNN + Attention系列模型更优
3.Transformer本身也可以作为base model扩展
我们站在此刻回想,ChatGPT背后的Transformer,其思想和架构恰恰印证了那句: 「大道至简」。
它首先在机器翻译任务中取得SOTA,而后成功被应用到NLP和CV等各个任务中,并获得了稳定优异的性能表现。
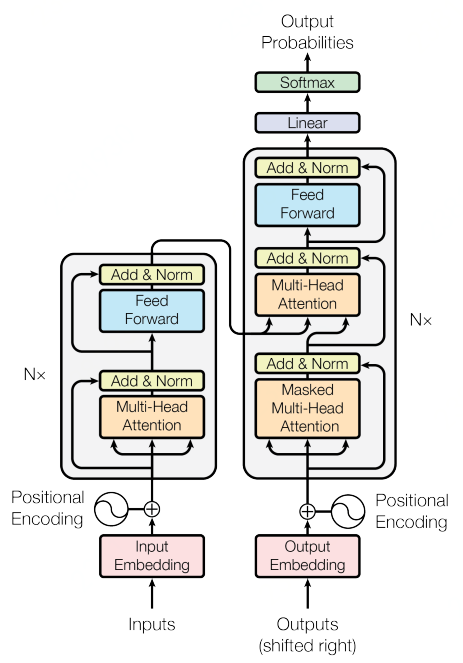
Transformer 模型架构图
后来的故事很多人都知道了,Google人再接再厉, 他们在2018年10月提出来的BERT(Bidirectional Encoder Representation from Transformers)模型再次轰动业界。
BERT在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩: 全部两个衡量指标上全面超越人类,并且在11种不同NLP测试中创出SOTA(业界最佳)表现,包括将GLUE基准推高至80.4% (绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进5.6%),成为NLP发展史上的里程碑式的模型成就。
就当所有人以为Google会在大语言模型赛道中一骑绝尘时,最终率先让世人熟知的却是来自OpenAI的GPT系列模型。

二、技术门道
2.1 GPT-1到ChatGPT的演进和技术原理
GPT(Generative Pre-training Transformer)系列模型首先选择和BERT绕道而行,尽管GPT-1(2018/06)发布的时间比BERT(2018/10)还要早。
BERT仅使用了Transformer的编码器(Encoder)部分进行训练,而GPT-1则只使用了Transformer的解码器(Decoder)部分。
由此二者各自走上了不同的道路。
GPT-1: 预训练+微调模式,117M参数、12层、2亿单词
原文:Improving Language Understanding by Generative Pre-Training
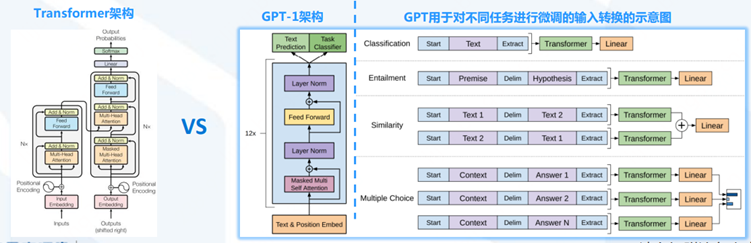
预训练阶段:基于Transformer Decoder架构,以语言建模作为训练目标(自监督,根据已知的词预测未知的词)。
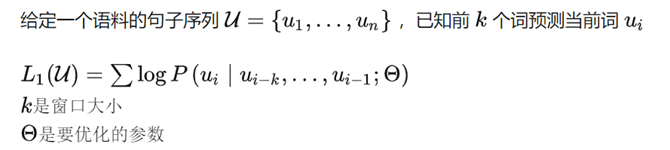
微调阶段:将训练好的Decoder参数固定,接上一层线性层,通过有监督训练任务微调线性层的参数,从而进行预测。

GPT-1的局限:微调只能用到特定任务中,如果fine-tune一个分类任务,就不能用到句子相似度任务中去。
所以能不能用一个模型去做所有NLP的任务?
这就是后续GPT-2和GPT-3的改进目标。
GPT-2: 多任务学习 + zero-shot learning,1542M参数、48层、400亿单词
原文:Language Models are Unsupervised Multitask Learners
GPT-2的目标是试图用一个模型去做多个NLP任务,它的核心思想就反映在论文标题里:语言模型=无监督多任务学习。
通俗地解释一下: 语言模型实际上是一种自监督的方式,根据已知的词预测未知的词,只是不需要显示地定义哪些字段是要预测的输出。 那如何用无监督多任务的训练方式实现语言模型自监督训练+多任务微调的效果呢? 我们只需要将input、output和task都表示为数据,例如在一个英文翻译成法语的机器翻译任务中,我们只需要将样本、标签和任务表示成如下格式,就实现了对P(output|input,task)的建模。
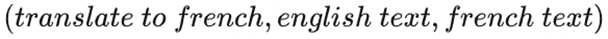
重要的是,这种方式可以实现无监督训练,并且里面的task可以变化,也就是说现在GPT-2可以实现无监督多任务训练而不需要第二阶段分不同任务有监督的微调!
所以最后我们看到,GPT-2相对于GPT-1,最大的改进就是去掉了第二阶段的微调(fine-tune)层,实现了多任务训练和zero-shot方式(Zero-shot learning,零样本学习)直接接诸多的下游任务,在多个任务下都可以取得很好的效果。
当然肉眼可见的还有数据集、网络层数、参数量、词汇表大小、初始化和LN(layer normalization)的调整。
GPT-3:in-context learning + few-shot learning,1750亿参数、96层、5000亿单词
原文:Language Models Are Few-shot Learners
GPT-3 基本继承了GPT-2的模型架构和训练模式,除了大力出奇迹的海量数据和巨型参数之外,GPT-3在模型设计层面相对于GPT-1和GPT-2主要的改进点在于:in-context learning(上下文情境学习,ICL) 和 few-shot learning(小样本学习,FSL)配合服用。
我们已经知道,GPT-1和BERT都需要对下游任务进行微调,而GPT-2通过无监督多任务和零样本学习舍弃了微调,并且验证了性能更加优越,那能否在不需要微调的前提下继续提升呢?
答案是可以,引入in-context learning(上下文情境)学习机制。
这种机制可以理解为给模型加一定的先验知识,适当对模型进行引导,教会它应当输出什么内容。
比如你希望GPT3帮你把中文翻译成英文,你可以这么向他提问:
用户输入到GPT3:请把以下中文翻译成英文:你觉得球神帅吗?
如果你希望GPT3回答你的问题,你可以换个方式问:
用户输入到GPT3:模型模型你说说:你觉得球神帅吗?
这样模型就可以根据用户提示的情境,进行针对性的回答了。
这里只是告诉了模型怎么做,能不能先给个示例呢?
用户输入到 GPT-3:请回答以下问题:你觉得球神帅吗?=> 我觉得还挺帅的呢; 你觉得科比打球帅还是欧文打球帅?=>
其中回答球神帅不帅就是一个示例,用于让模型感知应该输出什么。
基于以上,只给提示就是zero-shot,给一个示例叫做one-shot,给少量多个示例就是few-shot。
专业的读者应该能发现,这里给提示的in-context learning(上下文情境)学习跟prompt learning(提示学习)的思想很相似。
GPT-3论文里提供了3个版本的性能比较:
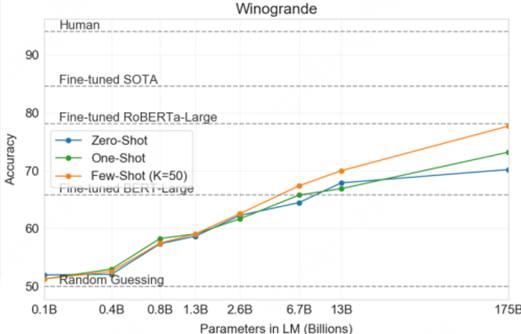
显然,in-context learning(情境学习)搭配few-shot learning(小样本学习)效果更好。
InstructGPT: RLHF(人类反馈强化学习)+ PPO(近端策略优化)
原文:Training language models to follow instructions with human feedback
InstructGPT相对GPT-3要解决的是大模型的alignment(对齐)问题。其背景是:大型语言模型会生成一些不真实、有毒(不符合人类道德伦理等)或对用户毫无帮助的输出,显然这些与用户期待的不一致。
大模型在预训练过程中见识了各种各样的数据,因此针对一个prompt/instruct(提示)会输出什么东西,也可能是多种多样的,但是预训练数据中出现的数据模式,不代表都是人类在使用模型时希望看到的模式,因此需要一个alignment(对齐)的过程,来规范模型的“言行举止”。
而实现这个过程InstructGPT引入了RLHF机制(人类反馈强化学习),实际上6年前的AlphaGo正是充分利用了强化学习,才在围棋领域实现了所到之处无敌手。
简单点说,InstructGPT就是在GPT-3基础上利用RLHF机制(人类反馈强化学习)做了微调,以解决大模型的alignment(对齐)问题。
我们不妨先想一下,应该如何解决模型输出跟人类期待不匹配的问题?
最直接的办法,就是人工构造一大批数据(标注员自己写prompt和期待的输出),完全符合人类的期待的模式,然后交给模型去学。然而,这代价显然太大了。因此,我们得想办法怎么让这个过程变得更轻松一点,RLHF机制(人类反馈强化学习)做到了这一点。
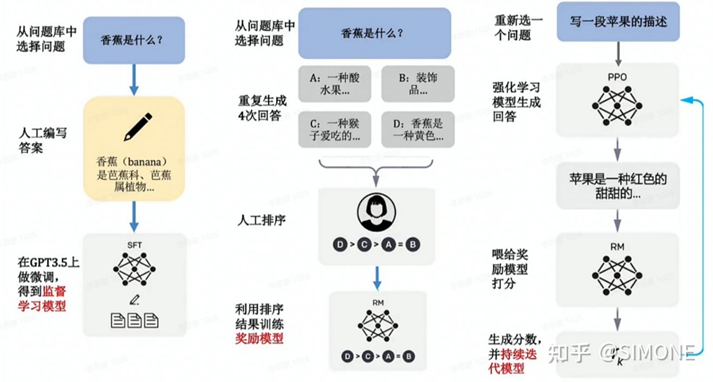
下面是InstructGPT的流程图,看懂了它也就能明白RLHF机制是如何实现的。
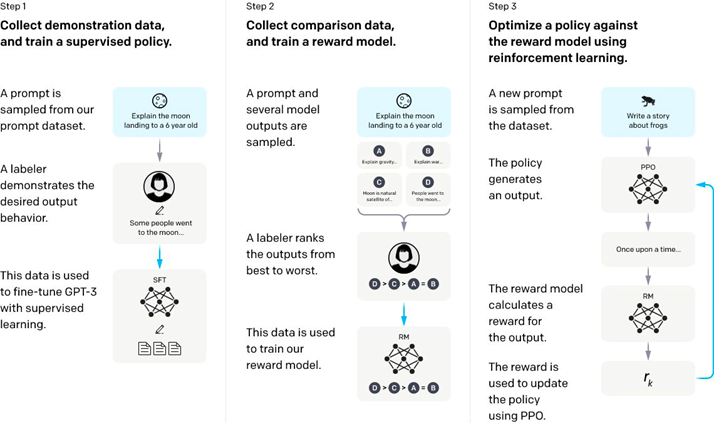
Step-1: 称初始模型为V0,也就是GPT-3。我们可以先人工构造一批数据,不用数量很大,尽其所能,然后先让模型学一学,称这个时候模型为V1。
Step-2: 然后让模型再根据一堆prompt(提示)输出,看看效果咋样,我们让模型V1对一个prompt进行多个输出,然后让人对多个输出进行打分排序,排序的过程虽然也需要人工,但是比直接让人写训练数据,还是要方便的多,因此这个过程可以更轻松地标注更多数据。然而,这个标注数据,并不能直接拿来训练模型,因为这是一个排序,但我们可以训练一个打分模型,称为RM(reward-model,也即奖励模型),RM的作用就是可以对一个
Step-3: 接下来,我们继续训练V1模型(被一个策略包装并且用PPO更新),给定一些prompt,得到输出之后,把prompt和output输入给RM,得到打分,然后借助强化学习的方法,来训练V1模型(打分会交给包着V0模型内核的策略来更新梯度),如此反复迭代,最终修炼得到V2模型,也就是最终的InstructGPT。
整体理解一下:整个过程就是老师(人类标注员)先注入一些精华知识,然后让模型试着模仿老师的喜好做出一些尝试,然后老师对模型的这些尝试进行打分,打分之后,学习一个打分机器,最后打分机器就可以和模型配合,自动化地进行模型的迭代,总体思路称为RLHF:基于人类反馈的强化学习。
其中,PPO机制( Proximal Policy Optimization,近端策略优化) 是强化学习中AC类(Actor/Critic)的经典算法,由OpenAI 2017年提出,既有Policy Gradient方法的优势,同时基于importance sampling实现experience buffer的利用,发挥类似DQN类算法的数据利用优势。
PPO是OpenAI常用的baseline方法,理论部分相当复杂,感兴趣的专业读者可以阅读原文和相关博客。
原文:Proximal policy optimization algorithms
非专业读者只需要理解到这是一种适应人类反馈强化学习(RLHF)机制完成整个流程训练的策略优化算法即可。
通过以上流程拆解,我们不难发现InstructGPT能通过这种RLHF机制实现更好的性能,有一个大的前提:就是初始模型GPT-3已经足够强大。
只有初始模型本身比较强大了,才能实现人类提供少量的精华数据,就可以开始进行模仿,同时在第二步产出较为合理的输出供人类打分。
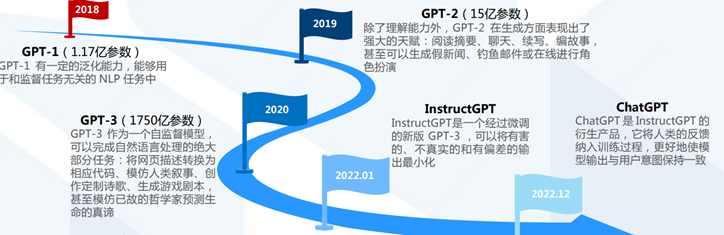
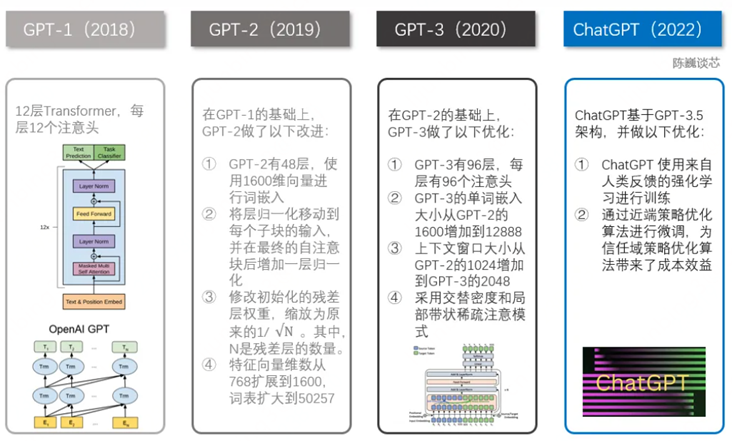
ChatGPT: 聊天升级版InstructGPT
根据OpenAI官方介绍,2022/11 发布的ChatGPT和2022/02 发布的InstructGPT在模型结构,训练方式上都完全一致,只是采集数据的方式上有所差异,但是目前没有更多的资料表明数据采集上有哪些细节不同。
所以,ChatGPT的技术原理与他的小兄弟InstructGPT基本一致,相当于InstructGPT是ChatGPT的预热版,也被称为GPT3.5,而传言即将发布的GPT-4是一个多模态模型(可以处理图片+文本+语音等多模态数据),期待。
至此,从GPT-1到ChatGPT的演进和技术原理就解释得差不多了。
import 有点爆肝
最后来一张Instruct/ChatGPT中文架构流程图,更加清晰易懂。
2.2 ChatGPT的局限性
尽管ChatGPT已经足够人工智能了,但是在众多真实智能人类的鉴定下,它目前还存在不少局限。
功能局限
1.有时答案会出现事实性错误
2.仍然会产生有偏见、与人类道德伦理不对齐的内容
3.没有与实时信息建立关联
4.有时对输入的表达方式表现敏感
5.有时回答过于冗长
以上限制主要基于以下几点复合原因:
1.ChatGPT乃至所有机器学习模型都是基于已有的数据、知识、关联、标签等做出的预测,因此只要它有所依赖和基于概率预测,错误、不准、有偏见的答案理论上都是存在的,只是精度和召回的问题;
2.ChatGPT的人工标注(包括指示和输出)准确度、表达层度、“价值观”等还可以提升,目前的AI对齐方式–RLHF机制也未必是最优;
3.ChatGPT的信息更新停留在了 2021年,它目前还无法连接搜索引擎,将最新、最实时的信息反馈给用户。
技术局限
1.再大的模型都不能无限大
2.模型受奖励模型和人工标注影响较大
这是ChatGPT技术架构的两大痛点,也是目前深度学习和强化学习研究领域的两大难点问题。
其他局限
1.数据和算力带来技术的垄断
ChatGPT训练需要的这种数据和算力体量,使得玩家基本就国外和国内那些科技巨头企业。而且目前ChatGPT也不会开源,这就使得学校和中小AI企业没得研究,这并不利于ChatGPT本身的进步。
2.模型轻量化和性能的平衡
ChatGPT的参数量已经到达千亿级,如此大的模型显然不适合大规模真实场景应用,后续的模型轻量化研究不可回避,而轻量化和性能的平衡也是一个巨大的挑战。
3.可解释性背后的AI可信
即使目前的ChatGPT在各项NLP任务上表现惊人,但是模型本身还像一个黑盒,可解释性依然是专业算法人需要深入探索的点,用户的期待依然是更加可信的AI。
2.3 ChatGPT的优化和探索方向
1.多模态扩展
ChatGPT目前所展示出来的能力还主要在文本域和少部分跨模态/域的内容生成。
下一步的趋势已经很明显,统一集成文本、图像、语音、视频等多模态理解和生成能力,像人一样,多模态思考、多模态处理。
2.不止于RLHF,探索其他AI对齐方式 RLHF(人类反馈强化学习)并不是唯一的AI对齐技术,针对强化学习的AI对齐还有很多方法、很多策略可以探索。
3.提升指示的泛化和纠错能力
除了人工标注的标签(ground truth),ChatGPT对指示(prompt)的依赖也非常明显,进一步提升模型对指示的泛化能力以及对错误指示的纠错能力,不仅能提升用户使用模型的体验,也能使模型能够适应更广泛的应用场景。
4.模型轻量化技术探索
自深度学习框架效果被广泛验证以来,CV界和NLP界为了追求性能,过去10年的研究工作总体趋势是模型层数越来越深、参数越来越多、数据量越来越大。
但是在圈里的每个人其实又都知道,到了某个阶段必须得破圈,如今,ChatGPT虽然性能爆棚,但其模型之大之深显然不适合大规模真实场景甚至在端上应用,未来对模型轻量化的研究不可回避,而轻量化和性能的平衡也非常考验AI技术是否真的走向成熟。
5.数据+算力+人工标注的降本增效
数据、算力和算法作为AI三要素,ChatGPT成功地把其中的数据、算力附加人工标注的资源成本打到高校、研究机构、其他小AI公司无法承受的水平,所以即便众多专家学者吐槽“大力出奇迹”却也无可奈何。
技术似乎又一次走在了科学的前面,这对科技本身的长期进步显然并不有利。
然而,从OpenAI等大型资本加持的巨头企业角度来看,他们也同样希望在未来能够逐步降本增效,毕竟AI开发者的终极目标还是“AI,让生活更美好”,只不过这其中会有诸如技术垄断、商业竞争等因素夹杂在其中更影响实现的时间。
三、商业应用
3.1 国内外资本投入层层加码
除了ChatGPT能做什么以及背后的技术门道,人们或许更关心它未来的产品化和商业化的过程。
而复杂且高投入的技术要想能够大规模产品化和商业化,离不开资本的助力。
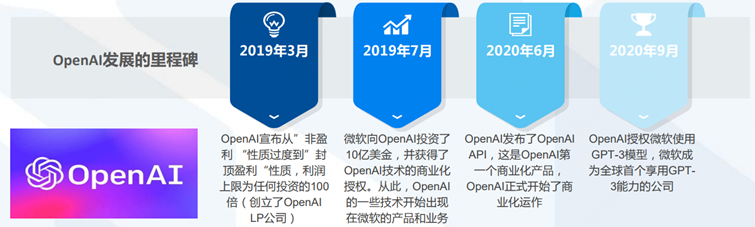
事实上,OpenAI的发展历程首先证明了这一点。
OpenAI由创业家埃隆·马斯克、美国创业孵化器Y Combinator总裁阿尔特曼、全球在线支付平台PayPal联合创始人彼得·蒂尔等人于2015年12月在旧金山创立。
起初它的定位是一家非盈利的AI研究公司,而后在2019年3月,OpenAI成立了一家叫做 OpenAI LP 的有限合伙公司,正式过度到“封顶盈利”性质。
转折点在2019年7月,微软向OpenAI豪注10亿美金,并获得了OpenAI技术商业化的授权。
所以2020年5月OpenAI成功发布了1750亿参数+45TB数据量的GPT-3语言模型,仅仅训练阶段就花费了大约 1200 万美元。
真就Money is all you need.
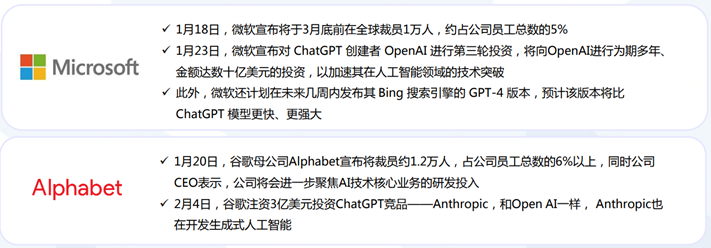
而在ChatGPT大放异彩的2023年初,微软、谷歌、亚马逊、百度、腾讯等国内外科技巨头更加不愿意错过机会,随之而来的是资本和研发投入的层层加码,烧钱 + 烧人。

3.2 ChatGPT商业化序幕已经拉开
2月1日,微软宣布推出由ChatGPT提供技术支持的视频会议及远程协作平台Teams的高级付费版Microsoft Teams Premium,订阅者可享用OpenAI GPT提供支持的大型语言模型技术,用AI自动生成会议笔记。
2月2日,OpenAI宣布,推出其人工智能聊天机器人ChatGPT的付费订阅版本,新的订阅服务名为ChatGPT Plus,月费为20美元。订阅包括在高峰使用时间访问聊天机器人。目前的免费版本在使用率高的时间段将限制对用户的服务。
2月8日,微软推出了由OpenAI提供最新技术支持的新版搜索引擎必应(Bing)和Edge浏览器。
ChatGPT 已经被亚马逊用于各种不同的工作职能中,包括回答面试问题、编写软件代码和创建培训文档等。
文案自动生成平台Jasper,其技术底层是 OpenAI 的 GPT-3,在成立仅 18 个月后就达到了 15 亿美元的高估值。
2月7日,百度宣布将在3月份完成其ChatGPT产品的内测,面向公众开放,该项目名字为文心一言(ERNIE Bot)。

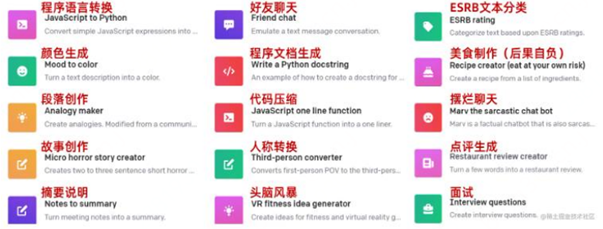
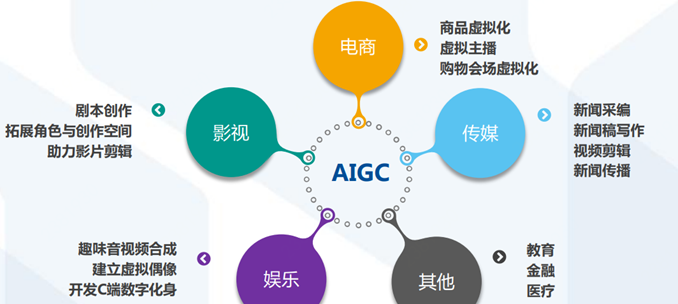
ChatGPT应用场景广泛,商业价值巨大,有望赋能传媒、影视、营销、教育、金融、医疗、科研、游戏等多个行业。
ChatGPT赋能传媒:实现智能新闻写作,提升新闻的时效性
ChatGPT可以帮助新闻媒体工作者智能生成报道,将部分劳动性的采编工作自动化,更快、更准、更智能地生成内容。

ChatGPT赋能影视:拓宽创作素材,提升作品质量
ChatGPT可以根据大众的兴趣身定制影视内容,从而更有可能吸引大众的注意力,获得更好的收视率、票房和口碑。 ChatGPT可以为剧本创作提供新思路,创作者可根据ChatGPT的生成内容再进行筛选和二次加工,从而激发创作者的灵感,开拓创作思路,缩短创作周期。
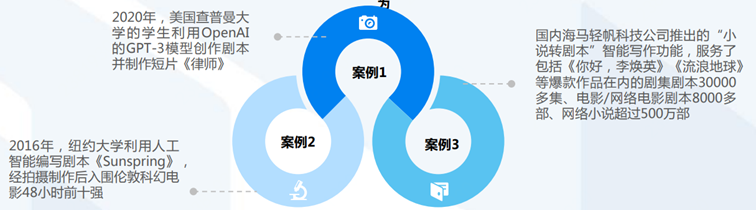
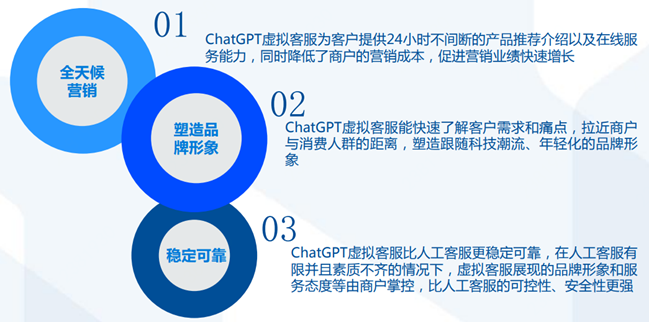
ChatGPT赋能营销:打造虚拟客服,助力售前和售后
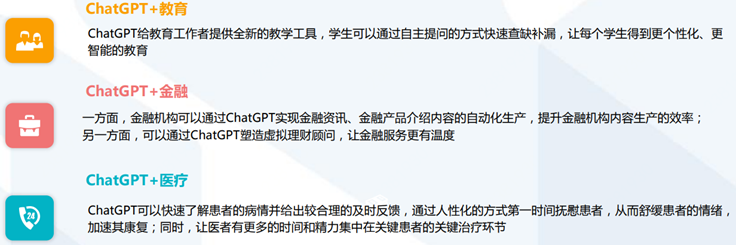
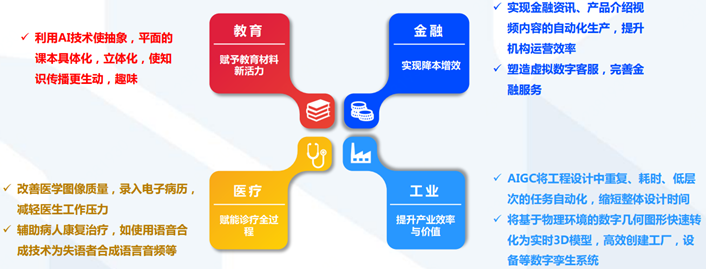
ChatGPT赋能教育金融医疗:促进数实共生,助力产业升级
ChatGPT+教育:赋予教育教材新活力,让教育方式更个性化、更智能;
ChatGPT+金融:帮助金融机构降本增效,让金融服务更有温度;
ChatGPT+医疗:赋能医疗机构诊疗全过程。
另外,ChatGPT和之前热炒的元宇宙显然还不太一样。
元宇宙到目前为止更像是一个美好的想法,还没有实际的产品和成熟的模式产生,大众甚至查阅资料都无法明白元宇宙是要做什么。
但ChatGPT以及背后的生成式人工智能(AIGC),不仅有ChatGPT这样To C触感非常强烈的产品,而且已经能看到如上述一些比较清晰的商业化模式。
现在缺的就是资本加速和技术突破。
3.3 ChatGPT助力AIGC浪潮再起
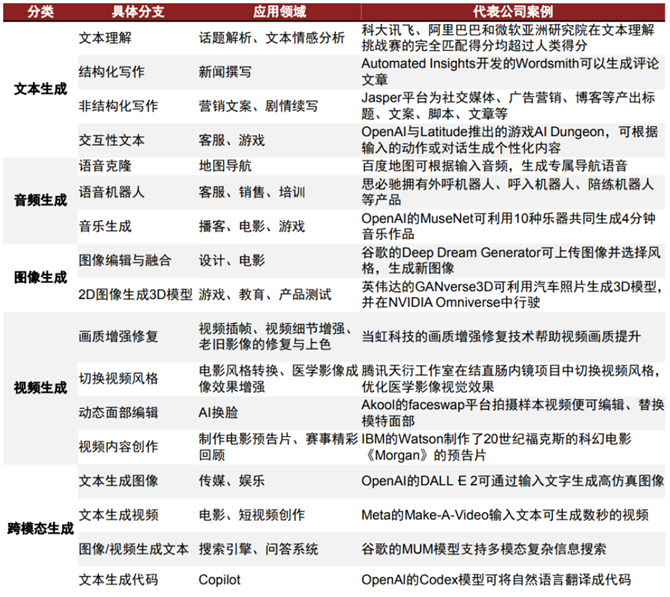
AIGC(Artificial Intelligence Generated Context),是指利用人工智能技术来生成内容,常见如AI绘画、AI写作、AI生成图片、代码、视频等。
AIGC顺着AI发展的脉络,大致经历了三个大的阶段:
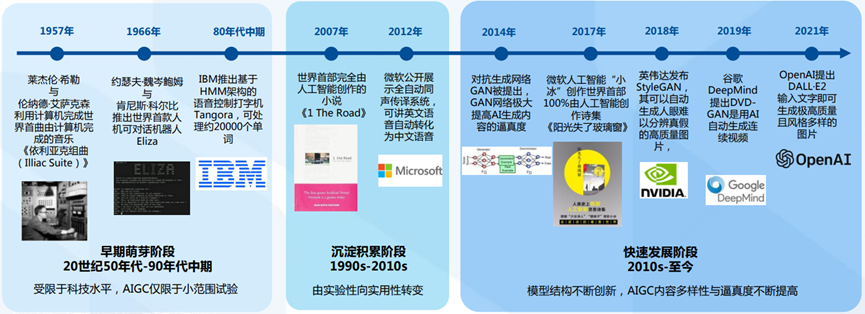
2010年以来,随着深度学习的快速突破以及数字内容的海量增长,AIGC领域相关技术打破了预定义规则的局限性,算法模型结构不断创新,使得快速便捷且智慧地输出多模态的数字内容成为可能。
从2017年微软小冰作诗到2018年英伟达StyleGAN生成高质量图片,再到2019年谷歌DeepMind DVD-E2生成连续视频,AIGC正在经历一波蓬勃发展。
直到本文的主角ChatGPT 2022年年底出场,AIGC终于迎来了突破式的拐点,新一轮的浪潮正在徐徐展开。
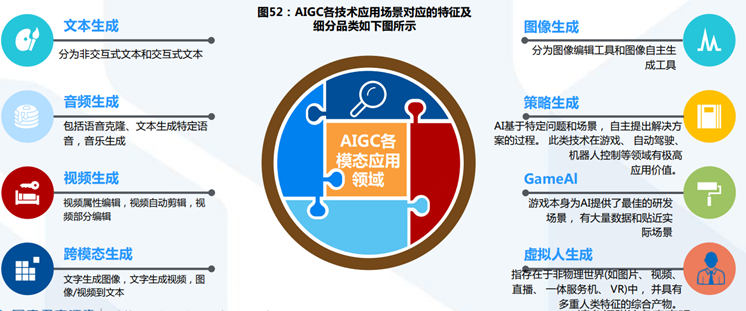
AIGC应用场景
AIGC按内容生成类别可划分为文本、代码、图像、音视频四大类,而跨模态生成技术是真正实现生成式智能的核心。
AIGC的意义在于提高内容生产力、打开内容创作想象空间,这或许也是巨头争相加码AIGC的原因所在。从现有的应用场景来看,AIGC已经可以替代部分重复劳动力,并协助部分创造性劳动,未来AI技术的发展有望不断降低内容生产成本、提高生产效率并拓展内容边界。
AIGC市场空间
2023年人工智能从学术研究逐渐走向产业化,商业与AI技术的融合形成互为支点的发展格局,进入产业规模商用期。人工智能技术将不断地对AI数字商业的各个领域进行渗透。
据量子位预测,2030年AIGC市场规模有望超过万亿元。在内容领域,人机协同,对于存量业务,AIGC的价值在于降本增效,对于增量业务,其价值在于跨模态的内容生成等。
据Gartner的“人工智能技术成熟度曲线”,生成式AI仍处于萌芽期,但其广阔的应用场景和需求空间吸引大量资本和技术的投入,预计将在2-5年内实现规模化应用。
AIGC有潜力产生数万亿元的经济价值,AIGC繁荣发展,将促进资产服务快速跟进,通过对生成内容合规评估、资产管理、产权保护、交易服务等构成AIGC完整生态链,并进行价值重塑,充分释放其商业潜力,至2025年中国生成式AI商业应用规模至2070亿元。

AIGC商业模式
过去AI发展多年,虽然在诸多领域也取得一些显著成果,但从整个AI产业来看,过去的应用更多的像是经过专业学习的“专科生”,不具备通用场景的泛化性。
但ChatGPT的问世,证明了基于大模型的AIGC已经像是一位接受过通识教育的“本科生”,虽然在发展初期在特定专业领域功能有限,却有着更强的可拓展性,能够赋能和落地各个商业领域。 并且直观来看,ChatGPT告诉世人,AI变成了一个普通人也可以轻松运用、提升效率的工具。
这意味着AIGC的商业模式更加显式化,不仅可以To B也可以To C。
AIGC To B模式主要希望解决的痛点问题在于:用AI代替人工生产,帮助企业实现降本增效。因为对B端带来的效果是快而显著的,因此客户的付费意愿较强。
而 To C模式下,对于个人用户来说,一方面AIGC应用可以作为效率工具,能够在信息获取、格式整理和工作流等各个流程提高个人用户的效率,并且AI模型作为基础设施能够集成到现有的工作流程中;另一方面可以作为创作工具,类似剪辑、修图软件一样,AIGC能够在用户原创流行的今天,大幅度降低大众用户的创作门槛,强化个人媒体的IP价值。
从商业角度而言,将AIGC作为底层基础设施的SaaS订阅将成为中长期趋势。用户选择付费的逻辑在于:更高效的信息获取方式;从辅助表达到替代表达;集成到已有的工作流;扩大用户创造力。
AIGC产业链
一方面,AIGC产业链可根据模型层次划分为基础层、中间层、应用层三层架构。
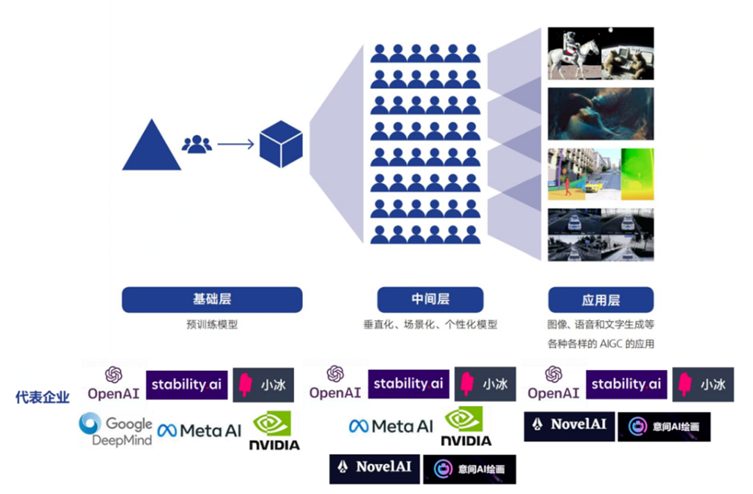
(1) 基础层:利用预训练模型搭建基础设施,该环节具备最高的进入门槛,参与者以头部企业为主
预训练模型是众多小模型的通用基底,为开发者降低AI开发与应用的门槛。预训练模型初始投入成本高、运行成本高,对软件、硬件均提出较高要求,因此涉足该环节的企业以微软、谷歌、英伟达、Meta等科技巨头以及OpenAI、Stability.ai等AI研究机构为主。
以OpenAI为例,2020年该机构训练GPT-3的硬件及电力成本达1200万美元;以Meta为例,为了提供更强大的算力支撑,Meta携手英伟达、Penguin Computing及Pure Storage打造AI超级计算机RSC,其测试数据显示,RSC训练大型NLP模型的速度提升3倍,运行计算机视觉工作的速度提升20倍。
(2) 中间层:基于预训练模型开发垂直化、场景化、个性化的模型和应用工具
中间层厂商基于预训练的大模型生成场景化定制化的小模型,帮助不同行业和垂直领域实现 AIGC 的快速部署。在预训练模型基础之上,开发者可根据不同行业、不同功能场景生成相应的小模型,基础层企业向中间层延伸为顺势而为。
此外,基础层企业还可扮演MaaS(Model-as-a-Service)服务提供方,将其模型开源给更多企业以二次开发模型,如Novel AI基于Stability.ai的开源模型Stable Diffusion开发出二次元风格AI绘画工具。
(3) 应用层:面向C端用户提供文本、图像、音视频等内容生成服务
应用层是指面向 C 端提供 AIGC 相关服务,典型企业包括微软、Meta、百度、腾讯,阿里巴巴等。基于基础层、中间层的模型及工具,应用层企业可将其重心放在满足用户需求乃至创造内容消费需求上,AI写作、AI绘画等AIGC应用已在营销、娱乐、艺术收藏等领域落地。
以国内企业为例,视觉中国依托其数字版权内容优势布局AIGC数字藏品,借力AI持续扩充艺术多元性,截至目前多轮发售的AIGC数字藏品均已售罄;蓝色光标机器人小蓝博面向广告主推出AI绘画、AI写作工具,其中AI绘画工具创意画廊可生成抽象风格画作以适配不同营销场景。
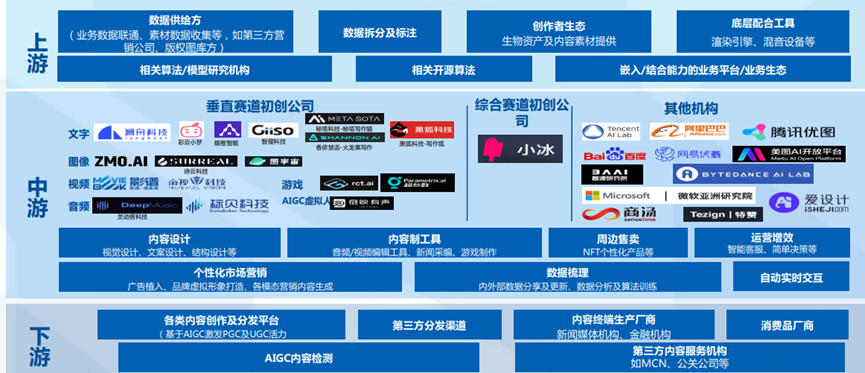
另一方面,「数据算力、算法模型和上层应用」又构成了AIGC产业链的直接上中下游关系。
AIGC上游主要包括数据供给方、算法机构、创作者生态以及底层配合工具等,中游主要是文字、图像、音频和视频处理厂商,其中玩家众多;下游主要是各类内容创作及分发平台以及内容服务机构等。
后记
ChatGPT,作为一项影响力出圈的AI技术应用,是近10年来人工智能和计算机技术快速发展、不断更新迭代、多种技术叠加在一起形成质变的产物,是自然语言处理(NLP)领域近年来研究的结晶。
ChatGPT实现了一种使机器获得语言智能的完整有效技术路线,但这个研究方向仍然面临诸多挑战,需要在科学和技术上进一步探索。
同时展望未来,它对AIGC、产业互联网、数字经济等领域的长足发展也将影响深远。
最后附上几个有争议性的话题,供读者思考和交流。
ChatGPT会引领第四次科技革命吗?
关键词:生产力、规模、效率
ChatGPT会给人类带来失业潮吗?
关键词:情感、创造力、稀缺性
ChatGPT适合下海创业吗?
关键词:技术、资金、团队、商业模式
ChatGPT及AIGC产业链有值得投资的企业吗?
关键词:纳指100、中概互联、腾讯、百度、科大讯飞
参考文献
学术论文:
Transformer: Attention Is All You Need, 2017. BERT: Bidirectional Encoder Representation from Transformers, 2018.
GPT-1: Improving Language Understanding by Generative Pre-Training, 2018.
GPT-2: Language Models are Unsupervised Multitask Learners, 2019.
GPT-3: Language Models Are Few-shot Learners, 2020.
InstructGPT: Training language models to follow instructions with human feedback, 2022.
ChatGPT: Optimizing Language Models for Dialogue, 2022.
证券研报:
1.国泰君安-计算机行业:ChatGPT 研究框架(2023)
2.华西证券-计算机行业深度研究报告:ChatGPT,开启AI新纪元
3.银河证券-计算机行业:聊天机器人顶流ChatGPT,开启自然语言处理领域新篇章
4.招商证券-计算机行业:ChatGPT快速流行,重构AI商业模式
5.国联证券-计算机行业:ChatGPT风口已至,商业化落地加速
6.东方证券-计算机行业:ChatGPT引领AI新浪潮,AIGC商业化启程
7.兴业证券-计算机行业:从AIGC到ChatGPT,原理、前景和机会
8.华泰证券-计算机行业:ChatGPT:深度拆解
9.招银国际-中国互联网行业:ChatGPT & AIGC在中国市场的发展前景
公众号文章:
慧博资讯:《ChatGPT行业深度报告》
慧博资讯:《AIGC行业深度报告》
TJUNLP:《对ChatGPT的二十点看法》,作者:熊得意老师
知乎文章:
https://zhuanlan.zhihu.com/p/589621442
https://zhuanlan.zhihu.com/p/517219229
https://zhuanlan.zhihu.com/p/34656727
https://zhuanlan.zhihu.com/p/595891945
https://zhuanlan.zhihu.com/p/597264009
https://zhuanlan.zhihu.com/p/563166533
https://zhuanlan.zhihu.com/p/606901798
https://www.zhihu.com/question/570431477/answer/2888747398
https://www.zhihu.com/question/581311491/answer/2882281060
