

1.需要用到python中的os库
import os #必须导入哦!!
2.批量处理步骤(文字说明)
1)第一步:先找到你要处理的文件夹
文字说明:因为文件的是可以和其他的字符组成转义字符,所以我在第一个方法,在双引号前面加了一个r
path = r"C:UserschenzhouDesktopMouseWithoutBorders"

2)第二步:把这个文件夹里面的数据全部写到列表里面
filename_list = os.listdir(path)#存入列表
3)第三步进行for循环进行遍历(小规模的量可以,大量需要用别的方法)
我的这个文件夹有一个我新建的(姓名_身份证号(假的))的txt文件

文字说明:我为了方便区分文件名,我都是用下划线区分的
for file in filename_list:
str = file
p1, p2, p3 = str.partition('_') #我用下划线做了区分
print(p1)
print(p2)
print(p3)

4)第四步:为os.rename做准备(重要)
我先说一下:rename的工作原理为:
++++++++++++++++++++分界线++++++++++++++++++++++
student_name:原始的文件名,就是要准备修改的文件名** (需要路径哦,会用到path) **
new_name:修改以后的文件名**(需要路径哦,会用到path)**
os.rename(student_name,new_name)
+++++++++++++++++++分界线+++++++++++++++++++++++
1.student_name
student_name = path +"//"+ filename[a]#这是用到了索引,等等会说
2.new_name
new_name = path+'//'+p3#这是拿到了下划线后面的内容
#如果要拿下划线前面的数据
new_name = path+'//'+p1
3.问题点:
1.path+”//”+文件夹里面所有的文件,通过for循环进行索引(每执行一次就+1)
path就是前面的当前的文件夹路径
为什么path后面要加”//” ?
答:文件夹和子文件夹都有进行区分。所以必须加这个进行区分
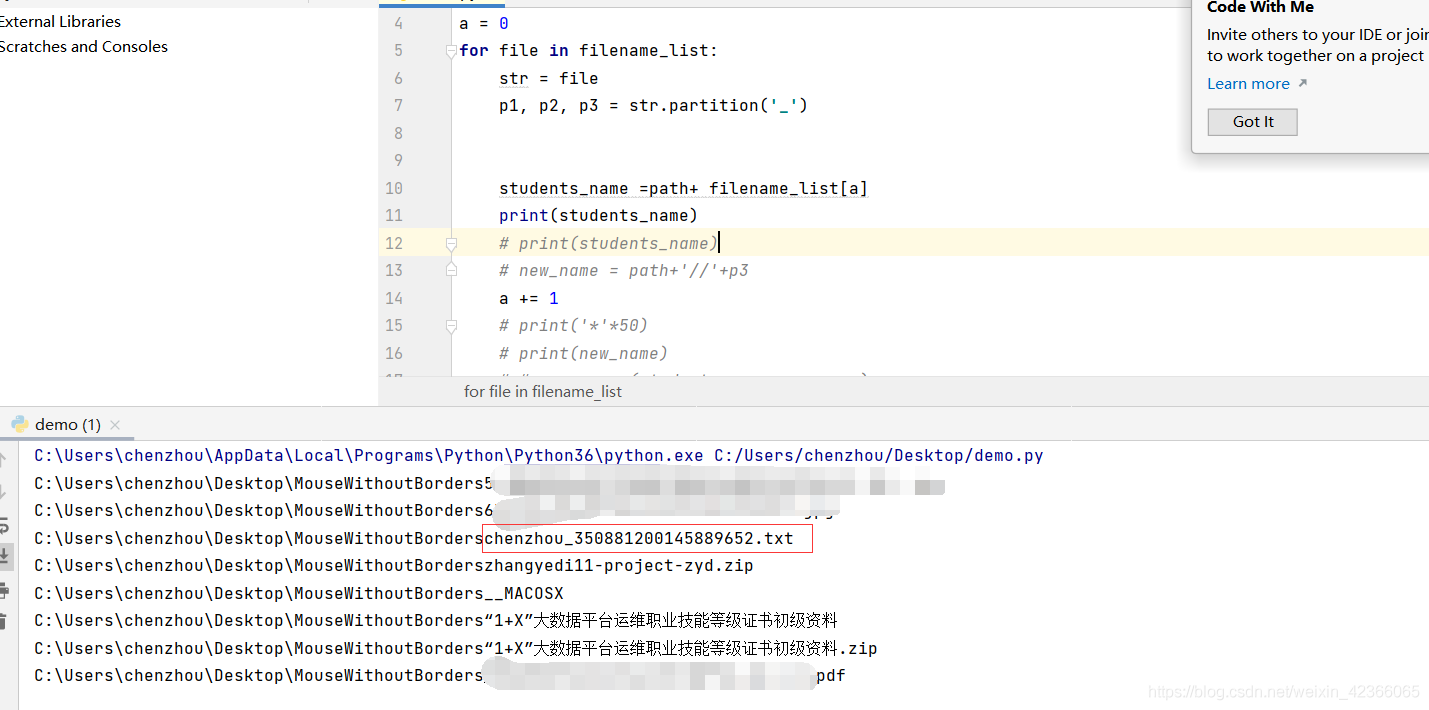
如果不加的话,父级文件夹和自己文件夹就无法区分
加了以后:

刚刚写反了,嘿嘿嘿,我还是新手,不好意思哈,下面才是对的

5.rename的使用
前面说了这么多,就是说换的文件名不能只是单纯的文件名,而是前面要接路径,路径和文件的中间必须接””
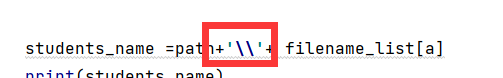
索引
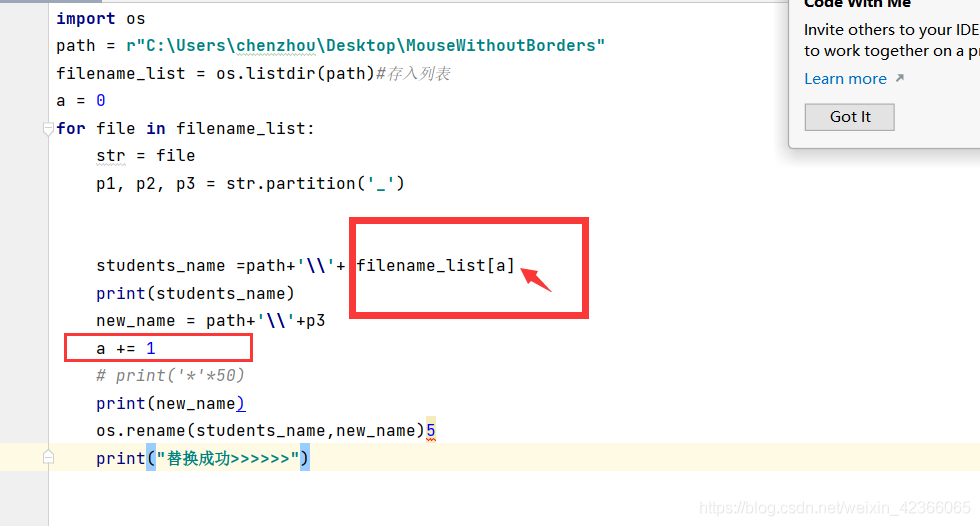
可能有人会问,这是因为文件内容非常多,path后面就只能接一个文件名,如果里面有多个文件的话,会报错,所以我们采用for循环,每循环一次就把a递增+1(从0开始索引)
